Pytorch学习:卷积神经网络—nn.Conv2d、nn.MaxPool2d、nn.ReLU、nn.Linear和nn.Dropout
文章目录
- 1. torch.nn.Conv2d
- 2. torch.nn.MaxPool2d
- 3. torch.nn.ReLU
- 4. torch.nn.Linear
- 5. torch.nn.Dropout
卷积神经网络详解:csdn链接
其中包括对卷积操作中卷积核的计算、填充、步幅以及最大值池化的操作。
1. torch.nn.Conv2d
对由多个输入平面组成的输入信号应用2D卷积。
官方文档:torch.nn.Conv2d
CLASS torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
主要参数:
- in_channels(int):输入图像中的通道数
- out_channels(int):卷积产生的通道数
- kernel_size(int或tuple):卷积内核的大小
默认参数:
- stride(int或tuple,可选):卷积的步幅。默认值:1
- padding(int,tuple或str,可选):添加到输入的所有四边的填充。默认值:0
- padding_mode(str,可选):‘zeros’ 、 ‘reflect’ 、 ‘replicate’ 或 ‘circular’ 。默认值: ‘zeros’
- dilation(int或tuple,可选):内核元素之间的间距。默认值:1
- groups(int,可选):从输入通道到输出通道的阻塞连接数。默认值:1
- bias(bool,可选):如果 True ,则向输出添加可学习的偏置。默认值: True
举例说明
import torch
from torch import nn# 内核方正,步调一致
m1 = nn.Conv2d(16, 33, 3, stride=2)
# 非方形内核和不等距步长,并有填充
m2 = nn.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2))
# 非方形内核和不等步长,以及填充和扩张
m3 = nn.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2), dilation=(3, 1))
卷积核通过选取内核大小,其中参数值是随机的
import torch
from torch import nnk = nn.Conv2d(1, 1, 3, stride=1)
print(list(k.parameters()))

使用CIFAR10数据进行卷积操作,并进行可视化操作
import torch
import torchvision.datasets
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter# 使用CIFAR10的训练数据
train_data = torchvision.datasets.CIFAR10("../dataset", train=True, transform=torchvision.transforms.ToTensor(),download=True)
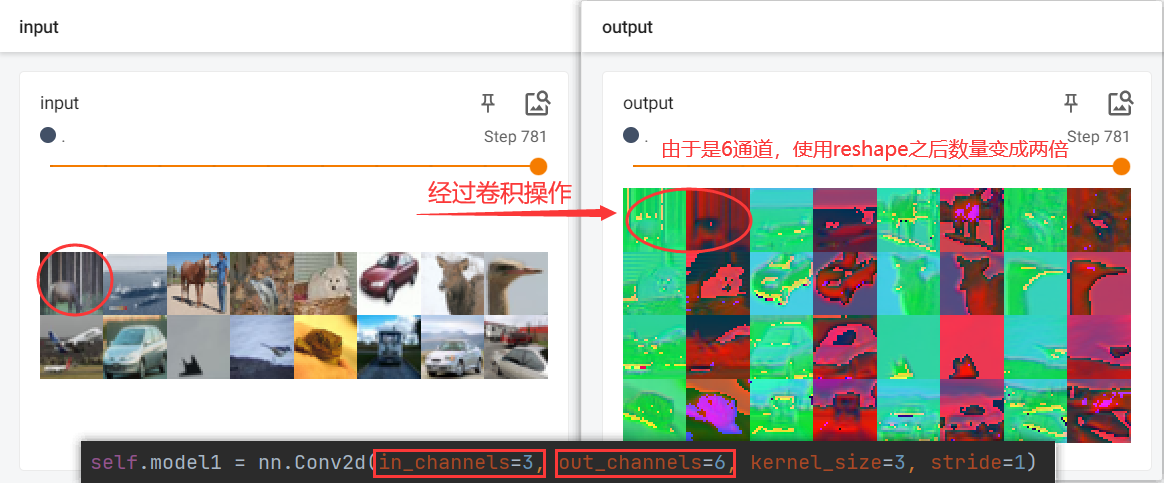
train_loader = DataLoader(train_data, batch_size=64)writer = SummaryWriter("logs")class Model(nn.Module):def __init__(self):super().__init__()self.model1 = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1)def forward(self, x):x = self.model1(x)return xstep = 0
# 创建模型
model = Model()
for data in train_loader:imgs, targets = dataoutput = model(imgs)writer.add_images("input", imgs, step)# output此时为6通道,为了可视化,现将其转换为3通道# imgs 的形状大小为 [64, 3, 32, 32]# 经过卷积操作后,output的高度和宽度为:32 - 3 + 1 = 30output = torch.reshape(output, (-1, 3, 30, 30))writer.add_images("output", output, step)step = step + 1writer.close()
打开命令行,输入以下代码,并打开TensorBoard的链接: http://localhost:6006/
tensorboard --logdir=logs
2. torch.nn.MaxPool2d
最大值池化层,对由多个输入平面组成的输入信号应用2D最大池化。
官方文档:torch.nn.MaxPool2d
CLASS torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
参数 kernel_size 、 stride 、 padding 、 dilation 可以是:
- 单个 int-在这种情况下,高度和宽度尺寸使用相同的值
- 两个int的 tuple -在这种情况下,第一个int用于高度维度,第二个int用于宽度维度
主要参数:
- kernel_size(Union[int,Tuple[int,int]])-窗口的最大值
默认参数:
- stride(Union[int,Tuple[int,int]])-窗口的步幅。默认值为 kernel_size
- padding(Union[int,Tuple[int,int]])-要在两边添加的隐式负无穷大填充
- dilation(Union[int,Tuple[int,int]])-控制窗口中元素步幅的参数
- return_indices(bool)-如果 True ,将返回最大索引沿着输出。 torch.nn.MaxUnpool2d 以后有用
- ceil_mode(bool)-当为True时,将使用ceil而不是floor来计算输出形状
最大汇聚层,也叫做最大池化层,代码实现
import torch
import torchvision.datasets
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter# 使用测试数据集
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),download=True)
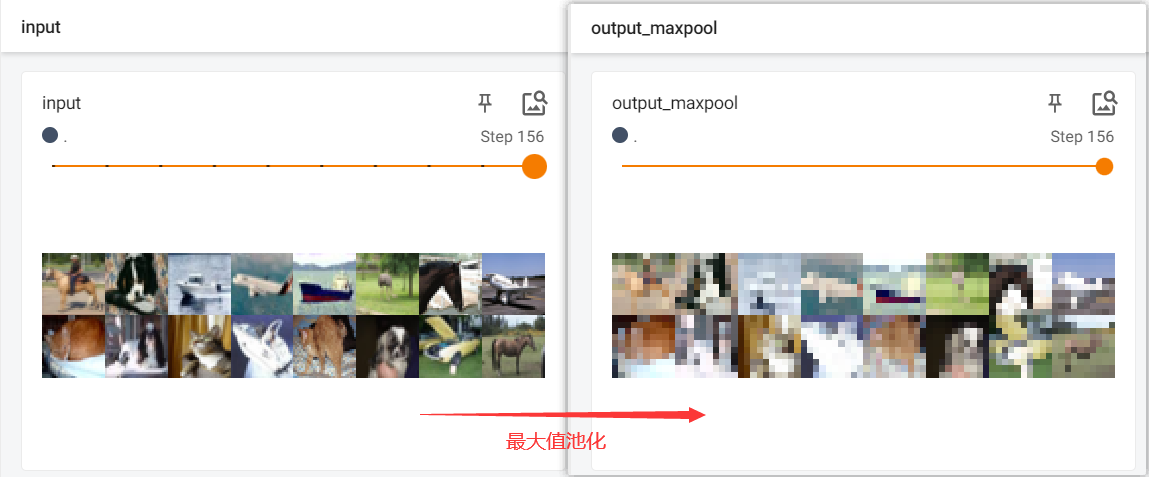
dataloader = DataLoader(dataset, batch_size=64)writer = SummaryWriter("logs")class Model(nn.Module):def __init__(self):super(Module, self).__init__()self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=False)def forward(self, input):output = self.maxpool1(input)return output# 创建模型
model = Model()
step = 0
for data in dataloader:imgs, targets = dataoutput = model(imgs)writer.add_images("input", imgs, step)writer.add_images("output_maxpool", output, step)step = step + 1writer.close()
3. torch.nn.ReLU
非线性激活函数,逐元素应用整流线性单位函数:
输入与输出形状相同
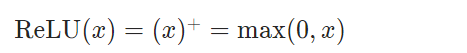
官方文档:torch.nn.ReLU
CLASS torch.nn.ReLU(inplace=False)
主要参数:
- inplace(bool):可以选择就地执行操作。默认值: False
代码实现
import torch
import torchvision.datasets
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter# 使用测试数据集
dataset = torchvision.datasets.CIFAR10("../dataset", train=False, transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64)writer = SummaryWriter("logs")class Model(nn.Module):def __init__(self):super().__init__()self.relu1 = nn.ReLU()def forward(self, input):output = self.relu1(input)return output# 创建模型
model = Model()
step = 0
for data in dataloader:imgs, targets = dataoutput = model(imgs)writer.add_images("input", imgs, step)writer.add_images("output", output, step)step = step + 1writer.close()
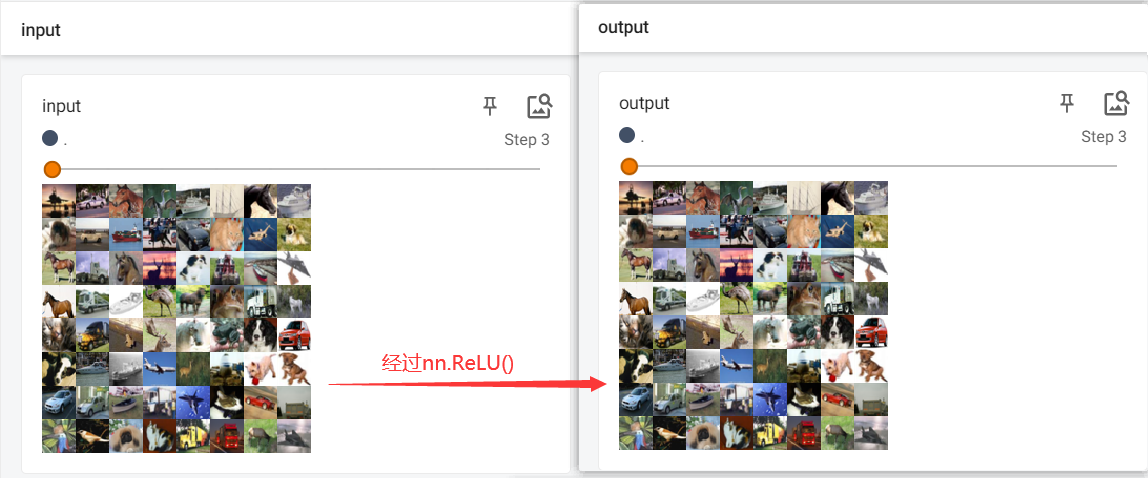
nn.ReLU()不是很明显,这里用nn.Sigmoid()更为清除
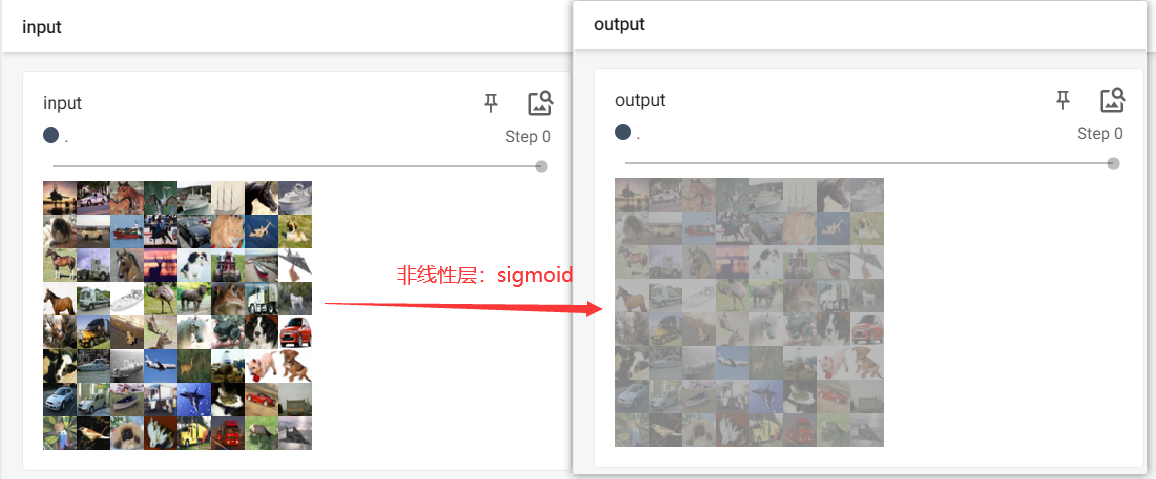
4. torch.nn.Linear
线性层,对传入数据应用线性变换: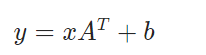
官方文档:torch.nn.Linear
CLASS torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None)
主要参数:
- in_features(int):每个输入样本的大小
- out_features(int):每个输出样本的大小
默认参数:
- bias(bool):如果设置为 False ,则层将不会学习加性偏置。默认值: True
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoaderdataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64)class Module(nn.Module):def __init__(self):super(Module, self).__init__()self.linear1 = Linear(196608, 10)def forward(self, input):output = self.linear1(input)return outputmodule = Module()for data in dataloader:imgs, targets = dataprint(imgs.shape)# output = torch.reshape(imgs, (1, 1, 1, -1))output = torch.flatten(imgs)print(output.shape)output = module(output)print(output.shape)

5. torch.nn.Dropout
在训练期间,使用来自伯努利分布的样本以概率 p 随机地将输入张量的一些元素归零。每个信道将在每次前向呼叫时独立地归零。
官方文档:torch.nn.Dropout
CLASS torch.nn.Dropout(p=0.5, inplace=False)
主要参数:
- p(float)-元素被置零的概率。默认值:0.5
- inplace(bool)-如果设置为 True ,将就地执行此操作。默认值: False
相关文章:
Pytorch学习:卷积神经网络—nn.Conv2d、nn.MaxPool2d、nn.ReLU、nn.Linear和nn.Dropout
文章目录 1. torch.nn.Conv2d2. torch.nn.MaxPool2d3. torch.nn.ReLU4. torch.nn.Linear5. torch.nn.Dropout 卷积神经网络详解:csdn链接 其中包括对卷积操作中卷积核的计算、填充、步幅以及最大值池化的操作。 1. torch.nn.Conv2d 对由多个输入平面组成的输入信号…...

水果库存系统(SSM+Thymeleaf版)
不为失败找理由,只为成功找方法。所有的不甘,因为还心存梦想,所以在你放弃之前,好好拼一把,只怕心老,不怕路长。 文章目录 一、前言二、系统架构与需求分析1、技术栈1.1 后端1.2 前端 2、需求分析 三、设计…...

如何在VueJS应用程序中设置Toast通知
通知是开发者提升应用程序互动性和改善用户体验的强大工具。通过利用通知,开发者可以在用户与应用程序互动的同时,有效地向用户传达重要事件。 通知在应用程序中起着至关重要的作用,可以及时通知用户有关各种操作和事件的信息。它们可以用于通…...
css让元素保持等比例宽高
使用新属性 aspect-ratio: 16/9; 代码示例 <style>div {width: 60%;/* 等比例宽高 */aspect-ratio: 16/9;background-color: red;margin: auto;}</style> </head><body><div></div> </body>示例 aspect-ratio兼容性...

骨传导和入耳式哪个危害大一点?入耳式和骨传导哪种好?
骨传导和入耳式这两种耳机虽然都存在一定的危害,但是入耳式耳机对人体的危害要更大一点。 入耳式耳机直接塞进耳朵这种佩戴方式,会阻塞外部声音的进入,长时间使用可能会导致耳道感染,还可能对听力造成损伤,而骨传导耳…...

介绍OpenCV
OpenCV是一个开源计算机视觉库,可用于各种任务,如物体识别、人脸识别、运动跟踪、图像处理和视频处理等。它最初由英特尔公司开发,目前由跨学科开发人员社区维护和支持。OpenCV可以在多个平台上运行,包括Windows、Linux、Android和…...
Android中的view绘制流程,简单理解
简单理解 Android中的View类代表用户界面中基本的构建块。一个View在屏幕中占据一个矩形区域、并且负责绘制和事件处理。View是所有widgets的基础类,widgets是我们通常用于创建和用户交互的组件,比如按钮、文本输入框等等。子类ViewGroup是所有布局&…...

商城开发:店铺管理系统应具备哪些功能?
电子商务的迅猛发展,越来越多的企业选择在线商城作为业务拓展的重要渠道。而要实现一个成功的在线商城,一个强大而高效的店铺管理系统是不可或缺的。店铺管理系统作为商城的核心管理工具,应具备一系列功能,以提供卓越的用户体验和…...

小白学go基础04-命名惯例对标识符进行命名
计算机科学中只有两件难事:缓存失效和命名。 命名是编程语言的要求,但是好的命名却是为了提高程序的可读性和可维护性。好的命名是什么样子的呢?Go语言的贡献者和布道师Dave Cheney给出了一个说法:“一个好笑话,如果你…...

使用iCloud和Shortcuts实现跨设备同步与自动化数据采集
在如今的数字时代,跨设备同步和自动化数据采集对于提高工作效率和便利性至关重要。苹果的iCloud和Shortcuts App为我们提供了强大的工具,可以实现跨设备同步和自动化数据采集的功能。本文将详细介绍如何利用iCloud和Shortcuts App实现这些功能࿰…...

Spring框架-基于STOMP使用Websocket
文章目录 前言一、范例演示1.注解方式2.XML方式二、可能出现错误错误: WebSocket代理中断错误: 缺少EventExecutor类错误: 缺少Publisher类错误: 缺少Scheduler类错误: WebSocket调用失败总结前言 Spring框架提供了多种WebSock消息机制,不仅包含了模拟SockJS,还提供了基…...

kafka-- 安装kafka manager及简单使用
一 、安装kafka manager 管控台: # 安装kafka manager 管控台: ## 上传 cd /usr/local/software ## 解压 unzip kafka-manager-2.0.0.2.zip -d /usr/local/ cd /usr/local/kafka-manager-2.0.0.2/conf vim /usr/local/kafka-manager-2.0.0.2/conf/appl…...
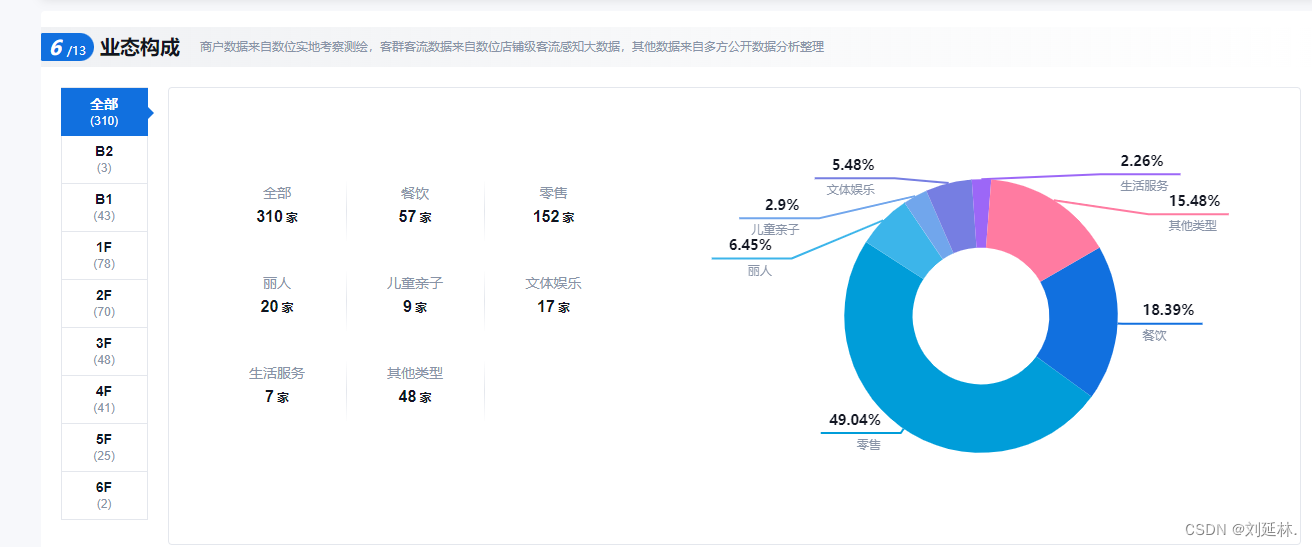
深圳-海岸城购物中心数据分析
做数据分析的时候,如果要对商场进行分析,可以从这些数据纬度进行分析,如下图所示: 截图来源于数位观察:https://www.swguancha.com/...
vue3 + elementplus Cannot read properties of null (reading ‘isCE‘)
使用命令行直接下载的element-plus,使用时会报错。 卸载掉,然后在项目根目录下,使用vue ui安装依赖, 即可使用...
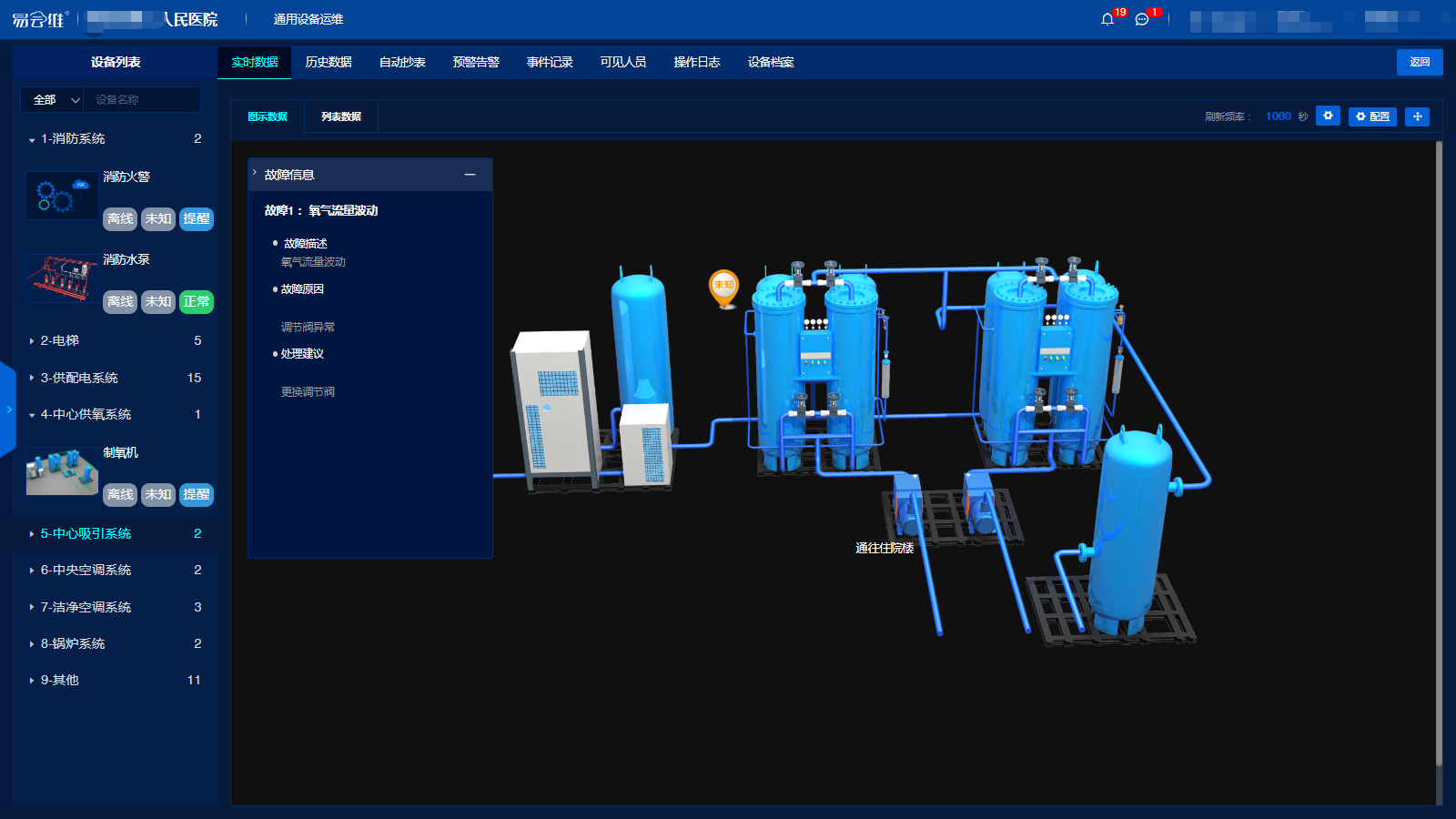
易云维®医院后勤管理系统软件利用物联网智能网关帮助实现医院设备实现智能化、信息化管理
近年来,我国医院逐渐意识到医院设备信息化管理的重要性,逐步建立医院后勤管理系统软件,以提高信息化管理水平。该系统是利用数据库技术,为医院的中央空调、洁净空调、电梯、锅炉、医疗设备等建立电子档案,把设备监控、…...

c# 定期重启程序操作
1 先说说重启//这部分是转载的 一、Restart方法 System.Windows.Forms.Application.Restart();经测试发现有时候只会关闭程序,并不会重新启动 二、Process.Start()和Exit() System.Diagnostics.Process.Start(System.Reflection.Assembly.GetExecutingAssembly()…...
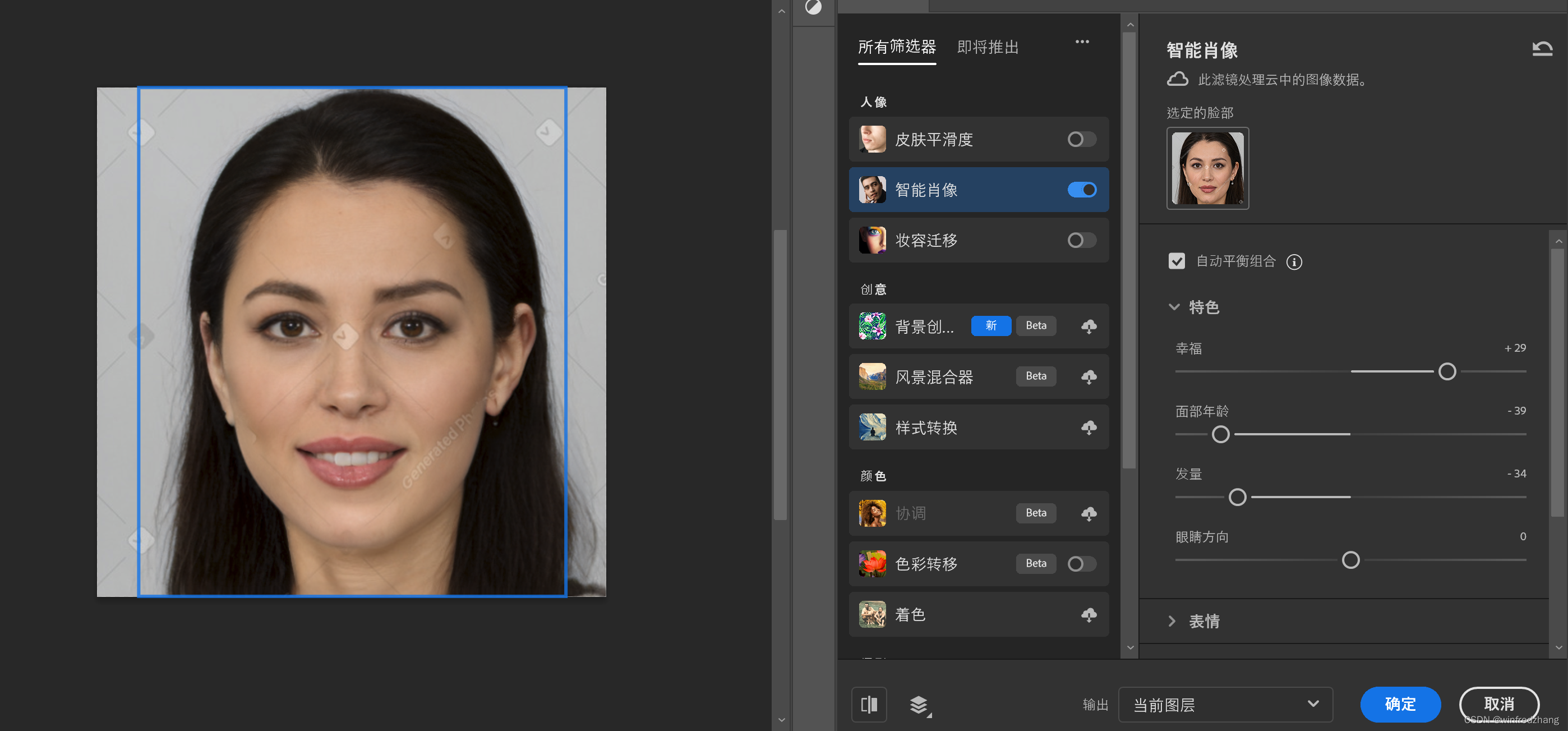
ps beta 2.5的妙用
1、https://pan.baidu.com/s/1CCw6RGlzEJ7TPWou8pPADQ?pwd2023 2、下载新便携版。 3、解压到c:\myapp文件夹下。 4、运行。 5、登录us账号。 6、使用智能移除。 效果如下: 使用滤镜。 先将C:\myApp\(新便携版)Adobe Photoshop (25.0.0 m22…...
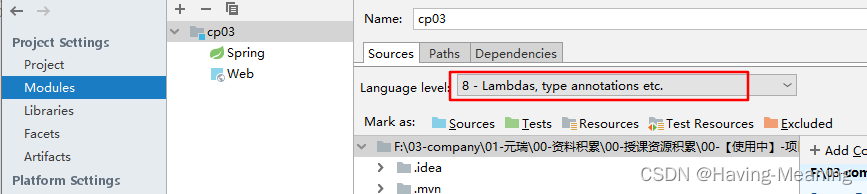
IDEA无效发行版本17
IDEA无效发行版本17 idea开发工具依赖的 jdk版本 和 项目依赖的jdk版本一定要保持 一致,不然会报错。 setting-->build-->compiler-》javaCompiler project->structure 这个也要保持一样。 在porm.xml文件中,你配置jdk版本是1.8,这…...

Ubuntu22.04安装ROS
Ubuntu22.04安装ROS_笔记大全_设计学院 Excerpt 在安装ROS之前,需要先安装Ubuntu22.04操作系统。您可以从Ubuntu官网下载Ubuntu22.04的最新版本镜像文件,并创建一个可启动的USB。您可以参考以下步骤: 一、安装Ubuntu22.04操作系统 在安装ROS…...

Linux 学习笔记(2)—— 关于文件和目录
目录 1、切换目录 2、查看系统信息 3、文本的创建和编辑 3-1)创建文件 3-2)查看文件 3-3)输出重定向和追加重定向 3-4)使用 vi 编辑器编辑文件 4、文件和文件夹的处理 4-1)对文件的处理 4-2)查看…...

美国不断自我革新的历史,为这个国家面对充满巨大机遇却又充满不确定性的未来提供了引人深思的经验教训
https://www.mckinsey.com/mgi/our-research/At-250-sustaining-Americas-competitive-edge 美国不断自我革新的历史,为这个国家面对充满巨大机遇却又充满不确定性的未来提供了引人深思的经验教训 这一切始于一场惊天动地的反抗行动。 1776年7月,来自13…...

终极D2DX宽屏补丁:让经典暗黑破坏神2在现代PC上完美重生
终极D2DX宽屏补丁:让经典暗黑破坏神2在现代PC上完美重生 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 你是否还…...

网盘下载新革命:九大平台一键直链,告别客户端束缚
网盘下载新革命:九大平台一键直链,告别客户端束缚 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘…...

OpenCore Legacy Patcher终极指南:5步让老旧Mac完美运行最新macOS系统
OpenCore Legacy Patcher终极指南:5步让老旧Mac完美运行最新macOS系统 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher OpenCore Legacy Patcher是…...

3分钟掌握Seraphine:英雄联盟智能助手完全指南
3分钟掌握Seraphine:英雄联盟智能助手完全指南 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine Seraphine是一款基于英雄联盟官方LCU API开发的智能游戏助手,通过自动BP系统和实时战绩查…...

终极游戏性能调优指南:DLSS Swapper智能管理工具深度解析
终极游戏性能调优指南:DLSS Swapper智能管理工具深度解析 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 游戏体验痛点剖析:当DLSS版本成为性能瓶颈 你是否曾在畅玩《赛博朋克2077》时…...
)
【仅剩217份】《Midjourney后印象派风格白皮书》V2.3——含17位艺术家专属LoRA适配建议、32组跨文化色彩映射表及实时风格强度校准工具(2024.06内部封测版)
更多请点击: https://intelliparadigm.com 第一章:后印象派风格的视觉基因与Midjourney语义解码 后印象派并非对自然的模仿,而是对色彩、结构与主观情绪的系统性重构——梵高旋转的星云、塞尚凝固的苹果、高更平面化的塔希提图腾,…...

Kubernetes上Jenkins全栈部署:动态Agent与生产环境调优指南
1. 项目概述:一个面向Kubernetes的Jenkins全栈部署方案在容器化和云原生技术成为主流的今天,如何高效、稳定地部署和管理持续集成/持续交付(CI/CD)流水线,是每个开发团队和运维工程师必须面对的课题。传统的单体Jenkin…...

构建团队技能仓库:从知识管理到可执行技能包的系统化实践
1. 项目概述:从“技能包”到高效能工具箱最近在梳理团队内部的技术资产时,我反复思考一个问题:如何让那些散落在个人电脑、项目文档和口头交流中的“隐性知识”和“高效技能”,变成一个团队可以随时取用、持续进化的公共资产&…...

【2024最新】ElevenLabs日语模型v2.4深度评测:对比VoiceLab、OpenJTalk与Azure Custom Neural TTS的MOS分与实时吞吐数据
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs日语模型v2.4的核心演进与技术定位 ElevenLabs 日语模型 v2.4 并非简单语音合成能力的迭代,而是面向高保真、低延迟、多语境日语语音生成的一次系统性重构。其底层架构从基于 Gri…...