重磅| Falcon 180B 正式在 Hugging Face Hub 上发布!

引言
我们很高兴地宣布由 Technology Innovation Institute (TII) 训练的开源大模型 Falcon 180B 登陆 Hugging Face! Falcon 180B 为开源大模型树立了全新的标杆。作为当前最大的开源大模型,有180B 参数并且是在在 3.5 万亿 token 的 TII RefinedWeb 数据集上进行训练,这也是目前开源模型里最长的单波段预训练。
你可以在 Hugging Face Hub 中查阅模型以及其 Space 应用。
模型:
https://hf.co/tiiuae/falcon-180B
https://hf.co/tiiuae/falcon-180B-chat
Space 应用地址:
https://hf.co/spaces/tiiuae/falcon-180b-demo
从表现能力上来看,Falcon 180B 在自然语言任务上的表现十分优秀。它在开源模型排行榜 (预训练) 上名列前茅,并可与 PaLM-2 等专有模型相差无几。虽然目前还很难给出明确的排名,但它被认为与 PaLM-2 Large 不相上下,这也使得它成为目前公开的能力最强的 LLM 之一。
我们将在本篇博客中通过评测结果来探讨 Falcon 180B 的优势所在,并展示如何使用该模型。
Falcon 180B 是什么?
从架构维度来看,Falcon 180B 是 Falcon 40B 的升级版本,并在其基础上进行了创新,比如利用 Multi-Query Attention 等来提高模型的可扩展性。可以通过回顾 Falcon 40B 的博客 Falcon 40B 来了解其架构。Falcon 180B 是使用 Amazon SageMaker 在多达 4096 个 GPU 上同时对 3.5 万亿个 token 进行训练,总共花费了约 7,000,000 个 GPU 计算时,这意味着 Falcon 180B 的规模是 Llama 2 的 2.5 倍,而训练所需的计算量是 Llama 2 的 4 倍。
其训练数据主要来自 RefinedWeb 数据集 (大约占 85%),此外,它还在对话、技术论文和一小部分代码 (约占 3%) 等经过整理的混合数据的基础上进行了训练。这个预训练数据集足够大,即使是 3.5 万亿个标记也只占不到一个时期 (epoch)。
已发布的 聊天模型 在对话和指令数据集上进行了微调,混合了 Open-Platypus、UltraChat 和 Airoboros 数据集。
‼️ 商业用途: Falcon 180b 可用于商业用途,但条件非常严格,不包括任何“托管用途”。如果您有兴趣将其用于商业用途,我们建议您查看 许可证 并咨询您的法律团队。
Falcon 180B 的优势是什么?
Falcon 180B 是当前最好的开源大模型。在 MMLU上 的表现超过了 Llama 2 70B 和 OpenAI 的 GPT-3.5。在 HellaSwag、LAMBADA、WebQuestions、Winogrande、PIQA、ARC、BoolQ、CB、COPA、RTE、WiC、WSC 及 ReCoRD 上与谷歌的 PaLM 2-Large 不相上下。
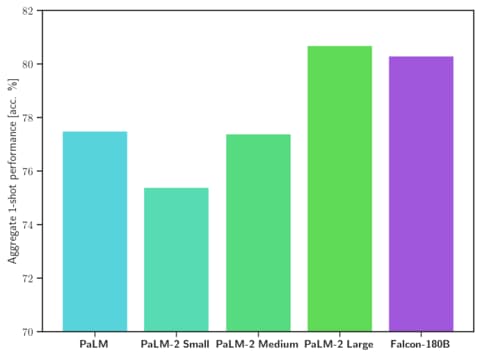
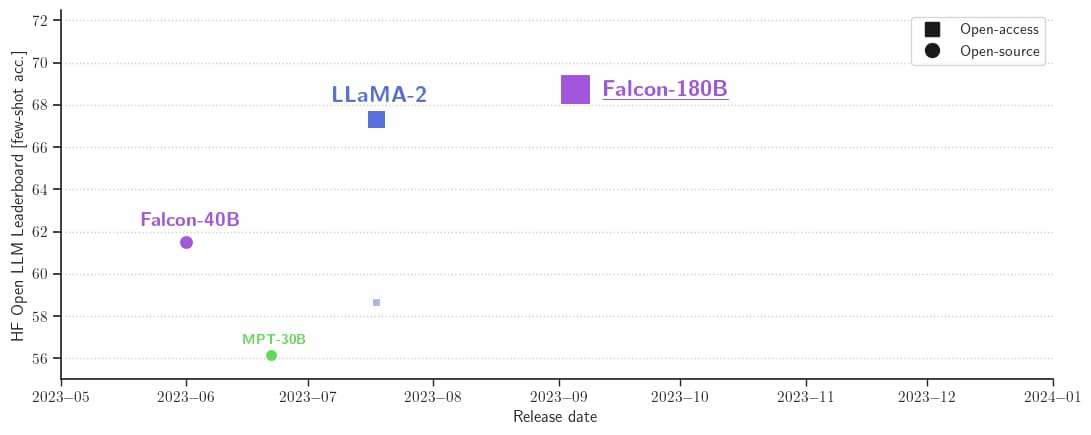
它在 Hugging Face 开源大模型榜单上以 68.74 的成绩被认为是当前评分最高的开放式大模型,评分超过了 Meta 的 LlaMA 2 (67.35)。
| Model | Size | Leaderboard score | Commercial use or license | Pretraining length |
|---|---|---|---|---|
| Falcon | 180B | 68.74 | 🟠 | 3,500B |
| Llama 2 | 70B | 67.35 | 🟠 | 2,000B |
| LLaMA | 65B | 64.23 | 🔴 | 1,400B |
| Falcon | 40B | 61.48 | 🟢 | 1,000B |
| MPT | 30B | 56.15 | 🟢 | 1,000B |
如何使用 Falcon 180B?
从 Transfomers 4.33 开始,Falcon 180B 可以在 Hugging Face 生态中使用和下载。
Demo
你可以在 这个 Hugging Face Space 或以下场景中体验 Falcon 180B 的 demo。
硬件要求
| 类型 | 种类 | 最低要求 | 配置示例 | |
|---|---|---|---|---|
| Falcon 180B | Training | Full fine-tuning | 5120GB | 8x 8x A100 80GB |
| Falcon 180B | Training | LoRA with ZeRO-3 | 1280GB | 2x 8x A100 80GB |
| Falcon 180B | Training | QLoRA | 160GB | 2x A100 80GB |
| Falcon 180B | Inference | BF16/FP16 | 640GB | 8x A100 80GB |
| Falcon 180B | Inference | GPTQ/int4 | 320GB | 8x A100 40GB |
Prompt 格式
其基础模型没有 Prompt 格式,因为它并不是一个对话型大模型也不是通过指令进行的训练,所以它并不会以对话形式回应。预训练模型是微调的绝佳平台,但或许你不该直接使用。其对话模型则设有一个简单的对话模式。
System: Add an optional system prompt here
User: This is the user input
Falcon: This is what the model generates
User: This might be a second turn input
Falcon: and so on
Transformers
随着 Transfomers 4.33 发布,你可以在 Hugging Face 上使用 Falcon 180B 并且借助 HF 生态里的所有工具,比如:
训练和推理脚本及示例
安全文件格式 (safetensor)
与 bitsandbytes (4 位量化)、PEFT (参数高效微调) 和 GPTQ 等工具集成
辅助生成 (也称为“推测解码”)
RoPE 扩展支持更大的上下文长度
丰富而强大的生成参数
在使用这个模型之前,你需要接受它的许可证和使用条款。请确保你已经登录了自己的 Hugging Face 账号,并安装了最新版本的 transformers:
pip install --upgrade transformers
huggingface-cli login
bfloat16
以下是如何在 bfloat16 中使用基础模型的方法。Falcon 180B 是一个大型模型,所以请注意它的硬件要求。
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torchmodel_id = "tiiuae/falcon-180B"tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id,torch_dtype=torch.bfloat16,device_map="auto",
)prompt = "My name is Pedro, I live in"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")output = model.generate(input_ids=inputs["input_ids"],attention_mask=inputs["attention_mask"],do_sample=True,temperature=0.6,top_p=0.9,max_new_tokens=50,
)
output = output[0].to("cpu")
print(tokenizer.decode(output)
这可能会产生如下输出结果:
My name is Pedro, I live in Portugal and I am 25 years old. I am a graphic designer, but I am also passionate about photography and video.
I love to travel and I am always looking for new adventures. I love to meet new people and explore new places.
使用 8 位和 4 位的 bitsandbytes
Falcon 180B 的 8 位和 4 位量化版本在评估方面与 bfloat16 几乎没有差别!这对推理来说是个好消息,因为你可以放心地使用量化版本来降低硬件要求。请记住,在 8 位版本进行推理要比 4 位版本快得多。
要使用量化,你需要安装“bitsandbytes”库,并在加载模型时启用相应的标志:
model = AutoModelForCausalLM.from_pretrained(model_id,torch_dtype=torch.bfloat16,**load_in_8bit=True,**device_map="auto",
)
对话模型
如上所述,为跟踪对话而微调的模型版本使用了非常直接的训练模板。我们必须遵循同样的模式才能运行聊天式推理。作为参考,你可以看看聊天演示中的 format_prompt 函数:
def format_prompt(message, history, system_prompt):prompt = ""if system_prompt:prompt += f"System: {system_prompt}\n"for user_prompt, bot_response in history:prompt += f"User: {user_prompt}\n"prompt += f"Falcon: {bot_response}\n"prompt += f"User: {message}\nFalcon:"return prompt
如你所见,用户的交互和模型的回应前面都有 User: 和 Falcon: 分隔符。我们将它们连接在一起,形成一个包含整个对话历史的提示。我们可以提供一个系统提示来调整生成风格。
其他资源
- 模型页面
- Space 应用
- Falcon 180B 已登陆 Hugging Face 生态系统 (本文)
- 官方公告
鸣谢
在我们的生态中发布并持续支持与评估这样一个模型离不开众多社区成员的贡献,这其中包括 Clémentine 和 Eleuther Evaluation Harness 对 LLM 的评估; Loubna 与 BigCode 对代码的评估; Nicolas 对推理方面的支持; Lysandre、Matt、Daniel、Amy、Joao 和 Arthur 将 Falcon 集成到 transformers 中。感谢 Baptiste 和 Patrick 编写开源示例。感谢 Thom、Lewis、TheBloke、Nouamane 和 Tim Dettmers 鼎力贡献让这些能发布。最后,感谢 HF Cluster 为运行 LLM 推理和一个开源免费的模型 demo 提供的大力支持。
相关文章:
重磅| Falcon 180B 正式在 Hugging Face Hub 上发布!
引言 我们很高兴地宣布由 Technology Innovation Institute (TII) 训练的开源大模型 Falcon 180B 登陆 Hugging Face! Falcon 180B 为开源大模型树立了全新的标杆。作为当前最大的开源大模型,有180B 参数并且是在在 3.5 万亿 token 的 TII RefinedWeb 数…...

Linux命令行
目录 CLI GUI 命令行界面 图形界面 命令行提示符 # $ 编辑 命令一般由三个部分组成 历史命令,使用上下键,或者使用history,ctrlr搜索历史命令 通配符 *,? 切换用户 su 作业管理 &,jobs,bg,fg CLI GUI 命令行界面 …...

[持续更新]计算机经典面试题基础篇Day1
[通用]计算机经典面试题基础篇Day1 1、jvm的组成 类加载器(Class Loader):负责将编译后的Java类加载到JVM中,并在运行时动态加载所需的类。运行时数据区(Runtime Data Area):是JVM的内存管理区…...
ProcessWindowFunction 结合自定义触发器的陷阱
背景: flink中常见的需求如下:统计某个页面一天内的点击率,每10秒输出一次,我们如果采用ProcessWindowFunction 结合自定义触发器如何实现呢?如果这样实现问题是什么呢? ProcessWindowFunction 结合自定义触发器实现…...

什么是jvm
一、初识JVM(虚拟机) JVM是Java Virtual Machine(Java虚拟机)的缩写,JVM是一种用于计算设备的规范,它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。 引入Jav…...
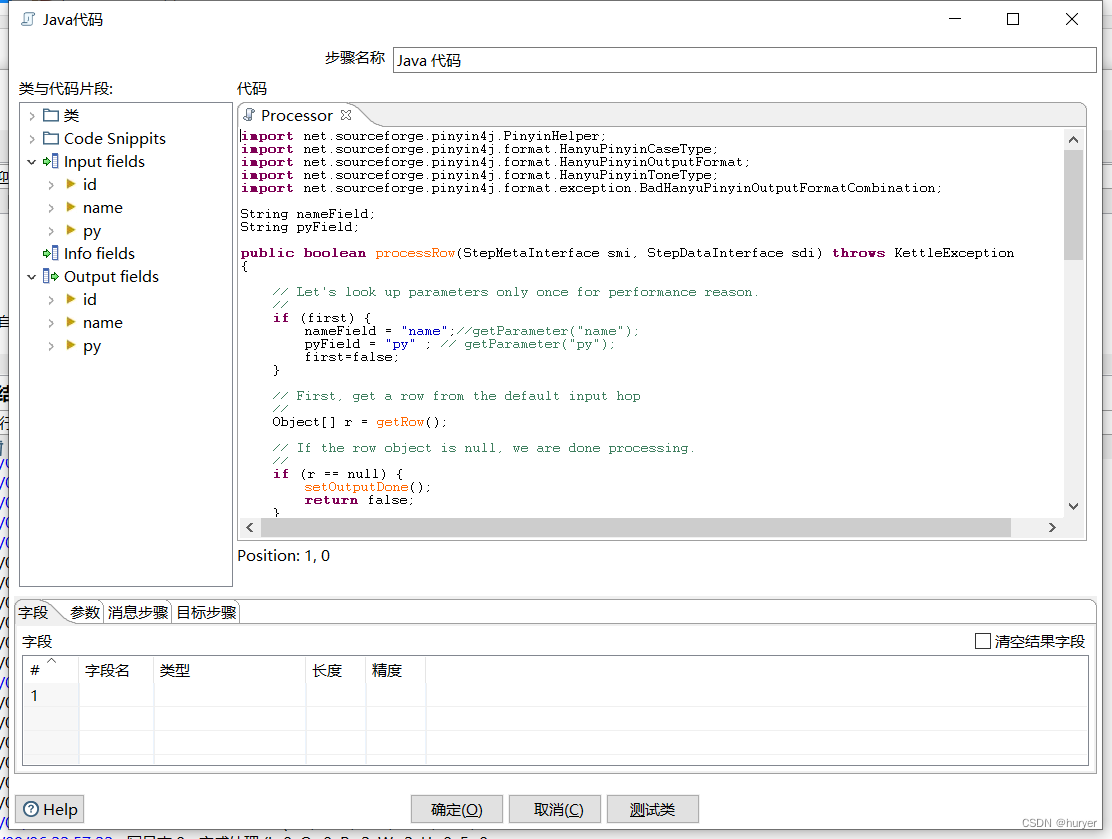
kettle通过java步骤获取汉字首拼
kettle通过java步骤获取汉字首拼 用途描述 一组数据,需要获取汉字首拼后,输出; 实现效果 添加jar包 pinyin4j-2.5.0.jar 自定义常量数据 Java代码 完整代码: import net.sourceforge.pinyin4j.PinyinHelper; import net.sou…...

Conformer: Local Features Coupling Global Representationsfor Visual Recognition
论文链接:https://arxiv.org/abs/2105.03889 代码链接:https://github.com/pengzhiliang/Conformer 参考博文:Conformer论文以及代码解析(上)_conformer代码_从现在开始壹并超的博客-CSDN博客 摘要 在卷积神经网络…...

java8-Stream流常用API
什么是 Stream Stream(流)是 Java 8 引入的一个新的抽象概念,它代表着一种处理数据的序列。简单来说,Stream 是一系列元素的集合,这些元素可以是集合、数组、I/O 资源或者其他数据源。 Stream API 提供了丰富的操作方…...

React 任务调度
React 任务池 不同的fiber任务有不同的优先级,为了用户体验,React需要先处理优先级高的任务。 为了存储这些任务,React中有两个任务池: // Tasks are stored on a min heap var taskQueue []; // 存储立即要执行的任务 var tim…...
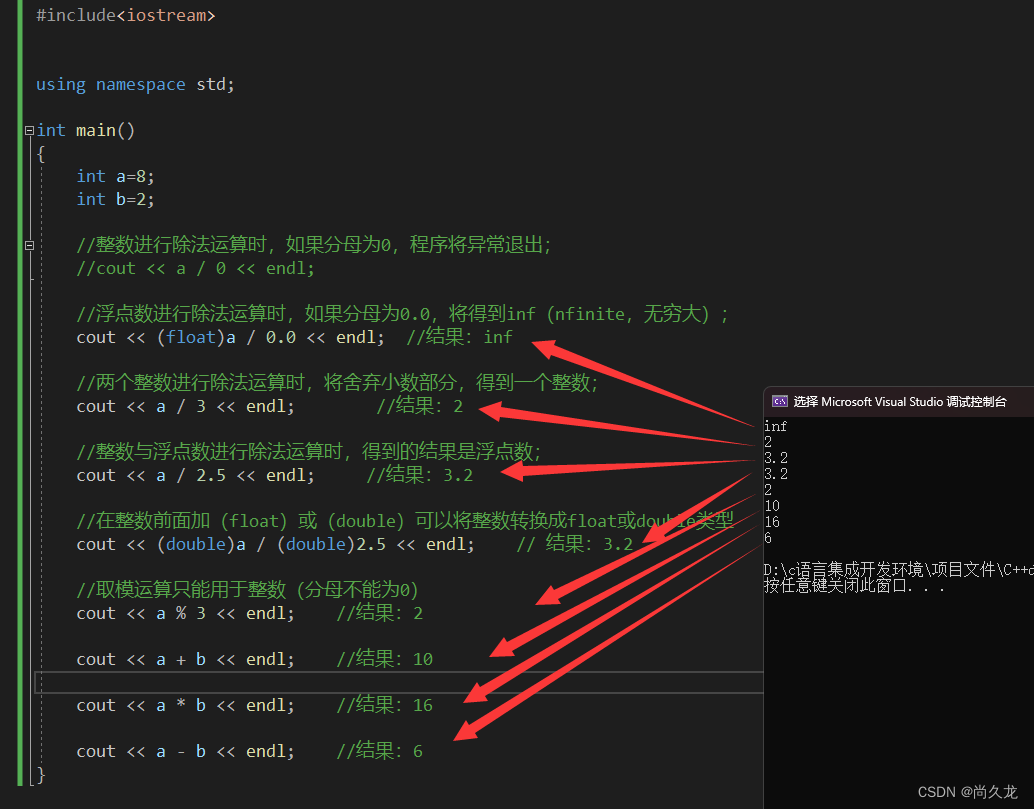
小白开始学习C++
第一节:控制台输出hello word! #include<iostream> //引入库文件 int main() { //控制台输出 hello word! 之后回车 std::cout << "hello word!\n"; #include<iostream> //引入库文件int main() {//控制…...
SpringMVC入门的注解、参数传递、返回值和页面跳转---超详细教学
前言: 欢迎阅读Spring MVC入门必读!在这篇文章中,我们将探索这个令人兴奋的框架,它为您提供了一种高效、灵活且易于维护的方式来构建Web应用程序。通过使用Spring MVC,您将享受到以下好处:简洁的代码、强大…...

【复习socket】每天40min,我们一起用70天稳扎稳打学完《JavaEE初阶》——28/70 第二十八天
专注 效率 记忆 预习 笔记 复习 做题 欢迎观看我的博客,如有问题交流,欢迎评论区留言,一定尽快回复!(大家可以去看我的专栏,是所有文章的目录) 文章字体风格: 红色文字表示:重难点★✔ 蓝色文字表示:思路以及想法★✔ 如果大家觉得有帮助的话,感谢大家帮忙 点…...
vue2踩坑之项目:生成二维码使用vue-print-nb打印二维码
1. vue2安装 npm install vue-print-nb --save vue3安装 npm install vue3-print-nb --save 2. //vue2 引入方式 全局 main.js import Print from vue-print-nb Vue.use(Print) ------------------------------------------------------------------------------------ //vue2 …...

【iVX】十五分钟制作一款小游戏,iVX真有怎么神?
个人主页:【😊个人主页】 新人博主,喜欢就关注一下呗~ 文章目录 前言iVX介绍初上手布置背景制作可移动物体总结(完善步骤) 前言 在上篇文章中,我向大家介绍了一种打破常规的编程方式——iVX,可…...

SpringMVC常用注解、参数传递、返回值
目录 前言 一、常用注解 二、参数传递 编辑 1. 基础类型String类型 2. 复杂类型 3. RequestParam 4. PathVariable 5.RequestBody 6. RequestHeader 三、方法返回值 一:void 二:String 三:Stringmodel 四:ModelAndVi…...

新公司第一次上架新APP需要提前准备哪些材料?
目录 前言一、需要上架的应用市场二、需要准备的资料总结 前言 前不久,使用一家新公司刚刚上架了一款新的APP项目。特此记录一下,现在第一次上架一款APP需要提前准备的各项材料。 一、需要上架的应用市场 现在,上架一款新的APP主流的应用市…...

『C语言进阶』指针进阶(一)
🔥博客主页: 小羊失眠啦 🔖系列专栏: C语言 🌥️每日语录:无论你怎么选,都难免会有遗憾。 ❤️感谢大家点赞👍收藏⭐评论✍️ 前言 在C语言初阶中,我们对指针有了一定的…...
)
2605. 从两个数字数组里生成最小数字(Java)
给你两个只包含 1 到 9 之间数字的数组 nums1 和 nums2 ,每个数组中的元素 互不相同 ,请你返回 最小 的数字,两个数组都 至少 包含这个数字的某个数位。 示例 1: 输入:nums1 [4,1,3], nums2 [5,7] 输出:1…...

深度解析 PostgreSQL Protocol v3.0(一)
引言 PostgreSQL 使用基于消息的协议在前端(也可以称为客户端)和后端(也可以称为服务器)之间进行通信。该协议通过 TCP/IP 和 Unix 域套接字支持。 《深度解析 PostgreSQL Protocol v3.0》系列技术贴,将带大家深度了…...

Mysql中having语句与where语句的用法与区别
分析&回答 我们在写sql语句的时候,经常会使用where语句,很少会用到having,其实在mysql中having子句也是设定条件的语句与where有相似之处但也有区别。having子句在查询过程中慢于聚合语句(sum,min,max,avg,count)。而where子句在查询过程中则快于聚合语句(sum,min,max,avg…...

CAXA 中心线
位置命令属性自由(方式)1、触发命令;2、属性如下;3、点击对象;(例如这里点击圆弧)4、输入定位点,或移动鼠标;5、点击确定中心线大小;指定延长线长度ÿ…...

2026届必备的五大AI科研神器实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 人工智能技术迅猛发展,论文AI工具在学术研究领域正慢慢变成重要辅助,…...

基于SpringBoot的民宿预订与评价系统毕业设计
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot与Vue框架的民宿预订与评价系统以解决当前旅游住宿服务领域存在的信息不对称问题用户体验碎片化问题以及数据管理分散化问题该…...

AI写教材高效秘籍!低查重AI工具助力,快速完成教材编写任务!
AI写教材:解决传统教材创作痛点,提升教学价值 许多教材的编写者都面临这样一个问题:他们投入了大量时间和精力来精心打磨正文内容,却因缺乏必要的配套资源,导致整体教学效果不理想。课后练习的设计需要具有梯度性的题…...

从SystemTap到ftrace:为什么Linux内核‘原装’的追踪工具更适合日常调试?
从SystemTap到ftrace:为什么Linux内核原生追踪工具更适合日常调试? 在Linux内核开发与性能优化领域,追踪工具的选择往往决定了问题排查的效率与系统稳定性。当面对SystemTap、eBPF/BCC和ftrace等工具时,资深开发者常陷入选择困境—…...

OpenDAN个人AI操作系统:从零构建智能体协作框架
1. 项目概述:个人AI操作系统的诞生与愿景最近在GitHub上看到一个项目,叫“OpenDAN-Personal-AI-OS”,第一眼看到这个标题,我就被吸引住了。作为一个在软件开发和AI应用领域摸爬滚打了十多年的从业者,我见过太多“AI助手…...

告别卡顿!手把手教你配置UE5+Cesium子关卡,打造流畅的大型开放世界
告别卡顿!UE5Cesium子关卡实战:打造流畅的大型开放世界 当你在UE5中构建一个横跨多个城市的开放世界时,是否遇到过这样的场景:镜头拉到高空俯瞰时帧率骤降,或者角色在城市间快速移动时出现明显的加载卡顿?这…...

如何通过DriverStore Explorer解决Windows驱动管理的三大核心难题
如何通过DriverStore Explorer解决Windows驱动管理的三大核心难题 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 作为一名系统管理员或技术爱好者,你是否曾面临这样的困境&…...

Windows Cleaner:拯救C盘爆红的终极免费解决方案
Windows Cleaner:拯救C盘爆红的终极免费解决方案 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 当你的电脑屏幕突然弹出"C盘空间不足"的红…...
RWKV:融合RNN与Transformer优势的高效语言模型架构解析与实践
1. 项目概述:一个“非Transformer”的现代语言模型 如果你最近在关注大语言模型(LLM)的开源生态,除了那些基于Transformer架构的“巨无霸”,可能还听说过一个名字有点特别的项目: RWKV 。这个由开发者Bli…...