图神经网络教程之GCN(pyG)
图神经网络-pyG版本的GCN
Data(数据)
data.x、data.edge_index、data.edge_attr、data.y、data.pos
- 举个例子

import torch
from torch_geometric.data import Data
edge_index = torch.tensor([[0, 1, 1, 2],[1, 0, 2, 1]], dtype=torch.long)
#代表0-1 1-0 和 1-2 2-1 ,因为是无向图,所以有双向边
x = torch.tensor([[-1], [0], [1]], dtype=torch.float)
# 代表每个节点
data = Data(x=x, edge_index=edge_index)
>>> Data(edge_index=[2, 4], x=[3, 1])
# 数据构成
其中edge_index也可以这么构建
edge_index = torch.tensor([[0, 1],[1, 0],[1, 2],[2, 1]], dtype=torch.long)
- 一些实用函数
print(data.keys())
>>> ['x', 'edge_index']
print(data['x'])
>>> tensor([[-1.0],[0.0],[1.0]])
for key, item in data:print(f'{key} found in data')
>>> x found in data
>>> edge_index found in data
'edge_attr' in data
>>> False
data.num_nodes
>>> 3
data.num_edges
>>> 4
data.num_node_features
>>> 1
data.has_isolated_nodes()
>>> False
data.has_self_loops()
>>> False
data.is_directed()
>>> False
# Transfer data object to GPU.
device = torch.device('cuda')
data = data.to(device)
- 包含一些数据集
from torch_geometric.datasets import TUDataset
dataset = TUDataset(root='/tmp/ENZYMES', name='ENZYMES')
- 数据转换
转换是torchvision中转换图像和执行增强的常见方式,pyG带有自己的转换。
#对ShapeNet数据集的转换。
from torch_geometric.datasets import ShapeNet
dataset = ShapeNet(root='/tmp/ShapeNet', categories=['Airplane'])
dataset[0]
>>> Data(pos=[2518, 3], y=[2518])
通过转换从点云生成最近邻图,将点云数据集转换为图数据集
import torch_geometric.transforms as T
from torch_geometric.datasets import ShapeNet
dataset = ShapeNet(root='/tmp/ShapeNet', categories=['Airplane'],pre_transform=T.KNNGraph(k=6))
dataset[0]
>>> Data(edge_index=[2, 15108], pos=[2518, 3], y=[2518])
- 图表上的表示学习
-
导入所需的库和模块:
torch:PyTorch的主要库。torch.nn.functional as F:PyTorch的神经网络函数模块,用于定义神经网络的层和操作。torch_geometric.nn:PyTorch Geometric库中的神经网络模块,包括图卷积网络(GCN)的实现。torch_geometric.datasets:PyTorch Geometric中的数据集模块,用于加载图数据集。
-
加载Cora数据集:
dataset = Planetoid(root='/tmp/Cora', name='Cora')这行代码加载了Cora数据集,这是一个用于节点分类的图数据集。数据集将被下载到
/tmp/Cora目录中。 -
定义了一个名为
GCN的神经网络类:class GCN(torch.nn.Module):这个类继承自PyTorch的
torch.nn.Module基类,表示它是一个神经网络模型。 -
在
GCN类的构造函数中,定义了两个图卷积层(GCNConv):def __init__(self):super(GCN, self).__init__()self.conv1 = GCNConv(dataset.num_node_features, 16)self.conv2 = GCNConv(16, dataset.num_classes)GCNConv层是图卷积层,用于从图数据中提取特征。self.conv1是第一个GCNConv层,它将输入特征的维度设置为dataset.num_node_features(Cora数据集中节点的特征维度)并输出16维特征。self.conv2是第二个GCNConv层,将16维特征映射到数据集的类别数。
-
检查并设置GPU或CPU设备:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')这段代码会检查你的系统是否有可用的GPU,并将
device设置为GPU或CPU,以便在相应的设备上运行模型。 -
创建并将模型和数据移动到所选设备上:
model = GCN().to(device) data = dataset[0].to(device)这将实例化之前定义的GCN模型,并将模型的参数和计算移动到GPU或CPU上。
-
定义优化器(这里使用Adam优化器):
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)这行代码创建一个Adam优化器,并将模型的参数传递给它,用于模型参数的更新。
lr是学习率,weight_decay是L2正则化项的权重。 -
将模型设置为训练模式:
model.train()这行代码将模型切换到训练模式,这对于启用训练特定的层(例如,dropout)非常重要。
-
开始训练循环,训练模型200个epoch:
for epoch in range(200):这是一个训练循环,将模型训练200次。
-
在每个epoch中,首先将优化器的梯度清零:
optimizer.zero_grad()这行代码用于清除之前的梯度信息,以准备计算新的梯度。
-
通过模型前向传播计算预测结果:
out = model(data)这会将数据传递给你的GCN模型,然后返回模型的预测结果。
-
计算损失函数,这里使用负对数似然损失(Negative Log-Likelihood Loss):
loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])这行代码计算了在训练节点子集上的负对数似然损失。
data.train_mask指定了用于训练的节点子集,data.y是节点的真实标签。 -
反向传播和参数更新:
loss.backward() optimizer.step()这两行代码用于计算梯度并执行梯度下降,更新模型的参数,以最小化损失函数。
-
将模型设置为评估模式:
model.eval()这行代码将模型切换到评估模式,以便在测试数据上进行预测。
-
在测试集上进行预测:
pred = model(data).argmax(dim=1)这行代码用于在测试数据上进行预测,并找到每个节点最可能的类别。
-
计算模型的准确性:
correct = (pred[data.test_mask] == data.y[data.test_mask]).sum() acc = int(correct) / int(data.test_mask.sum()) print(f'Accuracy: {acc:.4f}')这段代码计算了模型在测试集上的准确性,并打印出来。
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
from torch_geometric.datasets import Planetoid# 加载 Cora 数据集
dataset = Planetoid(root='/tmp/Cora', name='Cora')# 定义 GCN 模型
class GCN(torch.nn.Module):def __init__(self):super(GCN, self).__init__()self.conv1 = GCNConv(dataset.num_node_features, 16)self.conv2 = GCNConv(16, dataset.num_classes)def forward(self, data):x, edge_index = data.x, data.edge_indexx = self.conv1(x, edge_index)x = F.relu(x)x = F.dropout(x, training=self.training)x = self.conv2(x, edge_index)return F.log_softmax(x, dim=1)# 检查并设置 GPU 或 CPU 设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 创建并将模型和数据移动到所选设备上
model = GCN().to(device)
data = dataset[0].to(device)# 定义优化器
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)# 将模型设置为训练模式
model.train()# 训练模型
for epoch in range(200):optimizer.zero_grad()out = model(data)loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])loss.backward()optimizer.step()# 将模型设置为评估模式
model.eval()# 在测试集上进行预测
pred = model(data).argmax(dim=1)# 计算模型的准确性
correct = (pred[data.test_mask] == data.y[data.test_mask]).sum()
acc = int(correct) / int(data.test_mask.sum())
print(f'Accuracy: {acc:.4f}')optimizer.step()# 将模型设置为评估模式
model.eval()# 在测试集上进行预测
pred = model(data).argmax(dim=1)# 计算模型的准确性
correct = (pred[data.test_mask] == data.y[data.test_mask]).sum()
acc = int(correct) / int(data.test_mask.sum())
print(f'Accuracy: {acc:.4f}')
相关文章:
图神经网络教程之GCN(pyG)
图神经网络-pyG版本的GCN Data(数据) data.x、data.edge_index、data.edge_attr、data.y、data.pos 举个例子 import torch from torch_geometric.data import Data edge_index torch.tensor([[0, 1, 1, 2],[1, 0, 2, 1]], dtypetorch.long) #代表…...

python中的逻辑运算
逻辑运算 逻辑运算符是python用来进行逻辑判断的运算符,虽然运算符只有and、or、not三种,但是理解这三个运算符的原理才是最重要的 python中对false的认定 逻辑运算符是python用来进行逻辑判断的运算符,虽然运算符只有and、or、not三种&…...
TortoiseGit设置作者信息和用户名、密码存储
前言 Git 客户端每次与服务器交互,都需要输入密码,但是我们可以配置保存密码,只需要输入一次,就不再需要输入密码。 操作说明 在任意文件夹下,空白处,鼠标右键点击 在弹出菜单中按照下图点击 依次点击下…...

Fragment.OnPause的事情
我们知道Fragment的生命周期依附于相应Activity的生命周期,如果activity A调用了onPause,则A里面的fragment也会相应收到onPause回调,这里以support27.1.1版本的源码来说明Fragment生命周期onPause的事情。 当activity执行onPause时ÿ…...
【C++基础】5. 变量作用域
文章目录 【 1. 局部变量 】【 2. 全局变量 】【 3. 局部变量和全局变量的初始化 】 作用域是程序的一个区域,一般来说有三个地方可以定义变量: 在函数或一个代码块内部声明的变量,称为局部变量。 在函数参数的定义中声明的变量,称…...

Python列表排序
介绍一个关于列表排序的sort方法,看下面的案例: """ 列表的sort方法来对列表进行自定义排序 """# 准备列表 my_list [["a", 33], ["b", 55], ["c", 11]]# 排序,基于带名函数 …...
(云HIS)云医院管理系统源码 SaaS模式 B/S架构 基于云计算技术
通过提供“一个中心多个医院”平台,为集团连锁化的医院和区域医疗提供最前沿的医疗信息化云解决方案。 一、概述 云HIS系统源码是一款满足基层医院各类业务需要的健康云产品。该系统能帮助基层医院完成日常各类业务,提供病患预约挂号支持、收费管理、病…...

sql:SQL优化知识点记录(十一)
(1)用Show Profile进行sql分析 新的一个优化的方式show Profile 运行一些查询sql: 查看一下我们执行过的sql 显示sql查询声明周期完整的过程: 当执行过程出现了下面这4个中的时,就会有问题导致效率慢 8这个sql创建…...

leetcode-链表类题目
文章目录 链表(Linked List) 链表(Linked List) 定义:链表(Linked List)是一种线性表数据结构,他用一组任意的存储单元来存储数据,同时存储当前数据元素的直接后继元素所…...

数据结构——哈希
哈希表 是一种使用哈希函数组织数据的数据结构,它支持快速插入和搜索。 哈希表(又称散列表)的原理为:借助 哈希函数,将键映射到存储桶地址。更确切地说, 1.首先开辟一定长度的,具有连续物理地址…...

效果好的it监控系统特点
一个好的IT监控系统应该具备以下特点: 全面性:IT监控系统应该能够监视和管理IT系统的所有方面,包括网络、服务器、应用程序和数据库等。这样可以确保系统的各个方面都得到充分的监视和管理。 可靠性:IT监控系统需要保持高可…...

leetcode1288. 删除被覆盖区间(java)
删除被覆盖区间 题目描述贪心法代码演示 题目描述 难度 - 中等 leetcode1288. 删除被覆盖区间 给你一个区间列表,请你删除列表中被其他区间所覆盖的区间。 只有当 c < a 且 b < d 时,我们才认为区间 [a,b) 被区间 [c,d) 覆盖。 在完成所有删除操作…...

Python 虚拟环境相关命令
一 激活 在 cd venv/scripts 进入虚拟环境 执行命令 activate 1、创建虚拟环境 $ python -m venv 2、激活虚拟环境 $ source <venv>/bin/activate 3、关闭虚拟环境 $ deactivate...

使用U盘同步WSL2中的git项目
1、将U盘挂载到WSL2中 假设U盘在windows资源管理器中被识别为F盘,需要在WSL2中创建一个目录挂载U盘 sudo mkdir /mnt/f sudo mount -t drvfs F: /mnt/f后续所有的操作都完成后,拔掉U盘前,可以使用下面的命令从WSL2中安全的移除U盘 umount …...
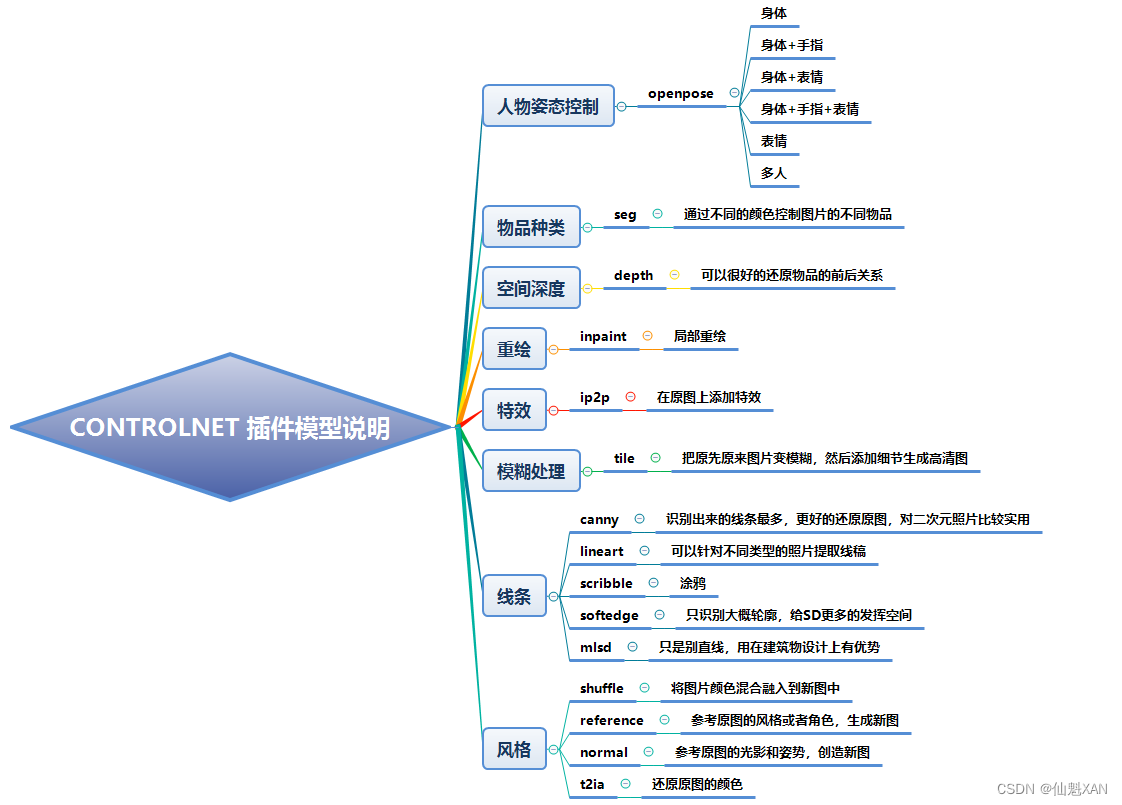
Stable Diffuse AI 绘画 之 ControlNet 插件及其对应模型的下载安装
Stable Diffuse AI 绘画 之 ControlNet 插件及其对应模型的下载安装 目录 Stable Diffuse AI 绘画 之 ControlNet 插件及其对应模型的下载安装 一、简单介绍 二、ControlNet 插件下载安装 三、ControlNet 插件模型下载安装 四、ControlNet 插件其他的下载安装方式 五、Co…...
CMAK学习
VS中的cmake_cmake vs_今天也要debug的博客-CSDN博客 利用vs2017 CMake开发跨平台C项目实战_cmake vs2017_神气爱哥的博客-CSDN博客 【【入门】在VS中使用CMake管理若干程序】https://www.bilibili.com/video/BV1iz4y117rZ?vd_source0aeb782d0b9c2e6b0e0cdea3e2121eba...

Python 推导式
Python 推导式 Python 推导式是一种独特的数据处理方式,可以从一个数据序列构建另一个新的数据序列的结构体。 Python 支持各种数据结构的推导式: 列表(list)推导式字典(dict)推导式集合(set)推导式元组(tuple)推导式 列表推导式 列表推导式格式为&…...

es6的新特性有哪些
ES6(ECMAScript 2015)是JavaScript的一个重要版本,引入了许多新的语法和功能。以下是ES6的一些主要特性: 块级作用域(Block Scope):引入了let和const关键字,可以在块级作用域中声明变…...

logstash 消费kafka数据,转发到tcp端口
1, logstash 配置文件 [roothost1: ] cat /opt/logstash/kafka-to-tcp.yml input { kafka {bootstrap_servers > "192.168.0.11:9092" #这里可以是kafka集群,如"192.168.149.101:9092,192.168.149.102:9092"consumer_threads &…...

航天智信:严控航天系统研发安全,助力建设“航天强国”
航天智信作为中国航天科工三院在信息装备领域“做大做强”的重要布局,主要从事系统运用与联合体系研究,复杂信息系统的顶层设计、总体论证及研制生产,提供体系级、系统级信息系统整体解决方案,以及信息安全系统的设计研发与集成验…...

Bash脚本自动化部署ROS机械臂环境:OpenClaw一键安装实践
1. 项目概述:一个为中文用户定制的自动化安装脚本如果你在GitHub上搜索过与机械臂、机器人操作系统(ROS)或类似开源硬件项目相关的资源,大概率会看到过“OpenClaw”这个名字。它是一个开源的、模块化的机械爪项目,设计…...

BOX工控机在无人机机载系统中有什么优势?这 3 点是普通工控机比不了的
现在的无人机机载系统,越来越多的人选择用 BOX工控机。很多人问我,BOX工控机到底是什么?它和普通的工控机有什么区别?为什么大家都在用它?今天我就跟大家好好聊聊这个话题。我会从一个 17 年工控人的角度,给大家讲透 BOX工控机在无人机机载…...
基于Circuit Playground Express与NeoPixel打造交互式太空头盔全流程指南
1. 项目概述:打造你的专属太空头盔如果你和我一样,是个对太空探索和创客DIY都充满热情的“技术宅”,那么把科幻电影里的装备搬到现实世界,绝对是一件让人肾上腺素飙升的事。今天要聊的,就是一个能让你过足“宇航员瘾”…...

YOLO26可运行项目,有上百个模块,都是我自己之前发SCI二区时,集成的一些模块,适合需要算法创新,模块改进的朋友。
智慧改进巡检-YOLO26可运行项目,有上百个模块,发SCI二区时,集成的一些模块,适合需要算法创新,模块改进的朋友。 目标检测,语义分割,关键点识别通用项目。 项目中的所有改进已经按功能类别进…...

API Key认证系统设计:企业级API开放平台实践
API Key认证系统设计:企业级API开放平台实践 摘要:当AI应用从内部工具转向对外开放时,如何确保接口安全、防止滥用并实现精细化权限控制?本文基于一个真实的跑步教练AI项目,详细解析如何构建一套生产级的API Key认证系…...

开发团队如何通过 Taotoken 实现 API 密钥的统一管理与审计
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 开发团队如何通过 Taotoken 实现 API 密钥的统一管理与审计 对于开发团队而言,安全、高效地管理大模型 API 密钥是一项…...

开源监控面板OpenClaw:从架构设计到生产部署实战指南
1. 项目概述:一个开源监控面板的诞生 在运维和开发的世界里,监控面板就像是驾驶舱里的仪表盘。没有它,你就是在盲飞。今天要聊的这个项目 xingrz/openclaw-dashboard ,就是一个由社区驱动的开源监控面板解决方案。它的名字很有意…...
)
告别数据错位:用Verilog在Xilinx FPGA上搞定AD7961回声时钟模式(附完整代码)
告别数据错位:用Verilog在Xilinx FPGA上搞定AD7961回声时钟模式(附完整代码) 高速数据采集系统中,时序同步问题往往是工程师的噩梦。当AD7961工作在回声时钟模式时,数据信号与时钟信号的微妙相位关系可能导致采样结果出…...

LVGUI字体瘦身实战:如何为你的IoT设备定制一个超小的中文字体库
LGVUI字体瘦身实战:为IoT设备定制超小中文字体库的工程化解决方案 在嵌入式物联网设备开发中,每一KB的Flash和RAM都弥足珍贵。当你的智能温控器需要显示"当前温度:25℃"或者电子秤要呈现"净重:0.5kg"时&#…...

进化算法驱动机械爪设计优化:从原理到EvoClaw项目实践
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“EvoClaw”。光看这个名字,可能有点摸不着头脑,但点进去一看,发现这是一个关于“进化算法驱动的机械爪设计优化”的开源项目。简单来说,就是利用计算机…...