pytorch-构建卷积神经网络
构建卷积神经网络
- 卷积网络中的输入和层与传统神经网络有些区别,需重新设计,训练模块基本一致
import torch import torch.nn as nn import torch.optim as optim import torch.nn.functional as F from torchvision import datasets,transforms import matplotlib.pyplot as plt import numpy as np %matplotlib inline首先读取数据
- 分别构建训练集和测试集(验证集)
- DataLoader来迭代取数据
# 定义超参数 input_size = 28 #图像的总尺寸28*28 num_classes = 10 #标签的种类数 num_epochs = 3 #训练的总循环周期 batch_size = 64 #一个撮(批次)的大小,64张图片# 训练集 train_dataset = datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True) # 测试集 test_dataset = datasets.MNIST(root='./data', train=False, transform=transforms.ToTensor())# 构建batch数据 train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True) test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=True)卷积网络模块构建
- 一般卷积层,relu层,池化层可以写成一个套餐
- 注意卷积最后结果还是一个特征图,需要把图转换成向量才能做分类或者回归任务
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.conv1 = nn.Sequential( # 输入大小 (1, 28, 28)nn.Conv2d(in_channels=1, # 灰度图out_channels=16, # 要得到几多少个特征图kernel_size=5, # 卷积核大小stride=1, # 步长padding=2, # 如果希望卷积后大小跟原来一样,需要设置padding=(kernel_size-1)/2 if stride=1), # 输出的特征图为 (16, 28, 28)nn.ReLU(), # relu层nn.MaxPool2d(kernel_size=2), # 进行池化操作(2x2 区域), 输出结果为: (16, 14, 14))self.conv2 = nn.Sequential( # 下一个套餐的输入 (16, 14, 14)nn.Conv2d(16, 32, 5, 1, 2), # 输出 (32, 14, 14)nn.ReLU(), # relu层nn.Conv2d(32, 32, 5, 1, 2),nn.ReLU(),nn.MaxPool2d(2), # 输出 (32, 7, 7))self.conv3 = nn.Sequential( # 下一个套餐的输入 (16, 14, 14)nn.Conv2d(32, 64, 5, 1, 2), # 输出 (32, 14, 14)nn.ReLU(), # 输出 (32, 7, 7))self.out = nn.Linear(64 * 7 * 7, 10) # 全连接层得到的结果def forward(self, x):x = self.conv1(x)x = self.conv2(x)x = self.conv3(x)x = x.view(x.size(0), -1) # flatten操作,结果为:(batch_size, 32 * 7 * 7)output = self.out(x)return output准确率作为评估标准
def accuracy(predictions, labels):pred = torch.max(predictions.data, 1)[1] rights = pred.eq(labels.data.view_as(pred)).sum() return rights, len(labels)训练网络模型
# 实例化 net = CNN() #损失函数 criterion = nn.CrossEntropyLoss() #优化器 optimizer = optim.Adam(net.parameters(), lr=0.001) #定义优化器,普通的随机梯度下降算法#开始训练循环 for epoch in range(num_epochs):#当前epoch的结果保存下来train_rights = [] for batch_idx, (data, target) in enumerate(train_loader): #针对容器中的每一个批进行循环net.train() output = net(data) loss = criterion(output, target) optimizer.zero_grad() loss.backward() optimizer.step() right = accuracy(output, target) train_rights.append(right) if batch_idx % 100 == 0: net.eval() val_rights = [] for (data, target) in test_loader:output = net(data) right = accuracy(output, target) val_rights.append(right)#准确率计算train_r = (sum([tup[0] for tup in train_rights]), sum([tup[1] for tup in train_rights]))val_r = (sum([tup[0] for tup in val_rights]), sum([tup[1] for tup in val_rights]))print('当前epoch: {} [{}/{} ({:.0f}%)]\t损失: {:.6f}\t训练集准确率: {:.2f}%\t测试集正确率: {:.2f}%'.format(epoch, batch_idx * batch_size, len(train_loader.dataset),100. * batch_idx / len(train_loader), loss.data, 100. * train_r[0].numpy() / train_r[1], 100. * val_r[0].numpy() / val_r[1]))当前epoch: 0 [0/60000 (0%)] 损失: 2.300918 训练集准确率: 10.94% 测试集正确率: 10.10% 当前epoch: 0 [6400/60000 (11%)] 损失: 0.204191 训练集准确率: 78.06% 测试集正确率: 93.31% 当前epoch: 0 [12800/60000 (21%)] 损失: 0.039503 训练集准确率: 86.51% 测试集正确率: 96.69% 当前epoch: 0 [19200/60000 (32%)] 损失: 0.057866 训练集准确率: 89.93% 测试集正确率: 97.54% 当前epoch: 0 [25600/60000 (43%)] 损失: 0.069566 训练集准确率: 91.68% 测试集正确率: 97.68% 当前epoch: 0 [32000/60000 (53%)] 损失: 0.228793 训练集准确率: 92.85% 测试集正确率: 98.18% 当前epoch: 0 [38400/60000 (64%)] 损失: 0.111003 训练集准确率: 93.72% 测试集正确率: 98.16% 当前epoch: 0 [44800/60000 (75%)] 损失: 0.110226 训练集准确率: 94.28% 测试集正确率: 98.44% 当前epoch: 0 [51200/60000 (85%)] 损失: 0.014538 训练集准确率: 94.78% 测试集正确率: 98.60% 当前epoch: 0 [57600/60000 (96%)] 损失: 0.051019 训练集准确率: 95.14% 测试集正确率: 98.45% 当前epoch: 1 [0/60000 (0%)] 损失: 0.036383 训练集准确率: 98.44% 测试集正确率: 98.68% 当前epoch: 1 [6400/60000 (11%)] 损失: 0.088116 训练集准确率: 98.50% 测试集正确率: 98.37% 当前epoch: 1 [12800/60000 (21%)] 损失: 0.120306 训练集准确率: 98.59% 测试集正确率: 98.97% 当前epoch: 1 [19200/60000 (32%)] 损失: 0.030676 训练集准确率: 98.63% 测试集正确率: 98.83% 当前epoch: 1 [25600/60000 (43%)] 损失: 0.068475 训练集准确率: 98.59% 测试集正确率: 98.87% 当前epoch: 1 [32000/60000 (53%)] 损失: 0.033244 训练集准确率: 98.62% 测试集正确率: 99.03% 当前epoch: 1 [38400/60000 (64%)] 损失: 0.024162 训练集准确率: 98.67% 测试集正确率: 98.81% 当前epoch: 1 [44800/60000 (75%)] 损失: 0.006713 训练集准确率: 98.69% 测试集正确率: 98.17% 当前epoch: 1 [51200/60000 (85%)] 损失: 0.009284 训练集准确率: 98.69% 测试集正确率: 98.97% 当前epoch: 1 [57600/60000 (96%)] 损失: 0.036536 训练集准确率: 98.68% 测试集正确率: 98.97% 当前epoch: 2 [0/60000 (0%)] 损失: 0.125235 训练集准确率: 98.44% 测试集正确率: 98.73% 当前epoch: 2 [6400/60000 (11%)] 损失: 0.028075 训练集准确率: 99.13% 测试集正确率: 99.17% 当前epoch: 2 [12800/60000 (21%)] 损失: 0.029663 训练集准确率: 99.26% 测试集正确率: 98.39% 当前epoch: 2 [19200/60000 (32%)] 损失: 0.073855 训练集准确率: 99.20% 测试集正确率: 98.81% 当前epoch: 2 [25600/60000 (43%)] 损失: 0.018130 训练集准确率: 99.16% 测试集正确率: 99.09% 当前epoch: 2 [32000/60000 (53%)] 损失: 0.006968 训练集准确率: 99.15% 测试集正确率: 99.11%
相关文章:

pytorch-构建卷积神经网络
构建卷积神经网络 卷积网络中的输入和层与传统神经网络有些区别,需重新设计,训练模块基本一致 import torch import torch.nn as nn import torch.optim as optim import torch.nn.functional as F from torchvision import datasets,transforms impor…...
)
点云从入门到精通技术详解100篇-点云滤波算法及单木信息提取(续)
目录 3.3 点云滤波算法原理概述 3.3.1 坡度滤波算法 3.3.2 基于不规则三角网滤波 3.3.3 数学形态学滤波...

Gartner发布中国科技报告:数据编织和大模型技术崭露头角
近日,全球知名科技研究和咨询机构Gartner发布了关于中国数据分析与人工智能技术的最新报告。报告指出,中国正迎来数据分析与人工智能领域的蓬勃发展,预计到2026年,将有超过30%的白领工作岗位重新定义,生成式人工智能技…...

java八股文面试[数据库]——explain
使用 EXPLAIN 关键字可以模拟优化器来执行SQL查询语句,从而知道MySQL是如何处理我们的SQL语句的。分析出查询语句或是表结构的性能瓶颈。 MySQL查询过程 通过explain我们可以获得以下信息: 表的读取顺序 数据读取操作的操作类型 哪些索引可以被使用 …...

Kafka3.0.0版本——增加副本因子
目录 一、服务器信息二、启动zookeeper和kafka集群2.1、先启动zookeeper集群2.2、再启动kafka集群 三、增加副本因子3.1、增加副本因子的概述3.2、增加副本因子的示例3.2.1、创建topic(主题)3.2.2、手动增加副本存储 一、服务器信息 四台服务器 原始服务器名称原始服务器ip节点…...
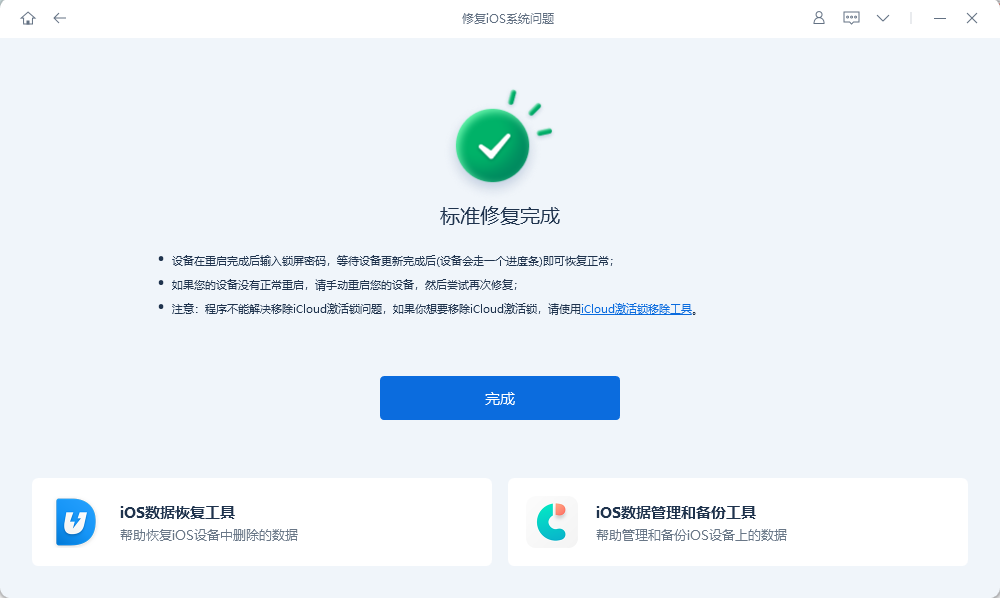
升级iOS 17出现白苹果、不断重启等系统问题怎么办?
iOS 17发布后了,很多果粉都迫不及待的将iphone/ipad升级到最新iOS17系统,体验新系统功能。 但部分果粉因硬件、软件的各种情况,导致升级系统后出现故障,比如白苹果、不断重启、卡在系统升级界面等等问题。 如果遇到了这些系统问题…...

6. `Java` 并发基础之`ReentrantReadLock`
前言:随着多线程程序的普及,线程同步的问题变得越来越常见。Java中提供了多种同步机制来确保线程安全,其中之一就是ReentrantLock。ReentrantLock是Java中比较常用的一种同步机制,它提供了一系列比synchronized更加灵活和可控的操…...
float浮动布局大战position定位布局
华子目录 布局方式普通文档流布局浮动布局(浮动主要针对与black,inline元素)float属性浮动用途浮动元素父级高度塌陷 position属性定位篇相对定位(relative为属性值,配合left属性,和top属性使用)…...
算法 数据结构 递归插入排序 java插入排序 递归求解插入排序算法 如何用递归写插入排序 插入排序动图 插入排序优化 数据结构(十)
1. 插入排序(insertion-sort): 是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入 算法稳定性: 对于两个相同的数,经过…...
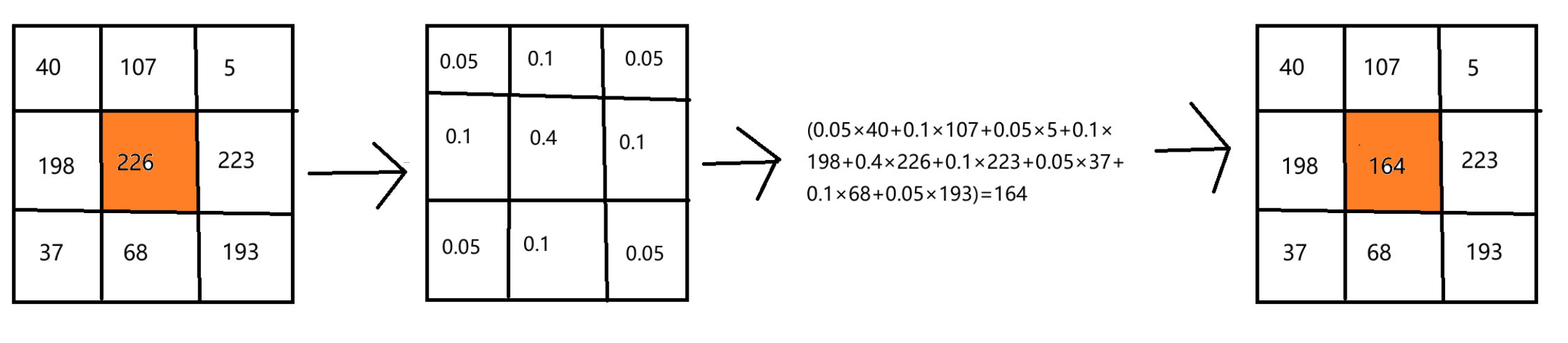
OpenCV(二十二):均值滤波、方框滤波和高斯滤波
目录 1.均值滤波 2.方框滤波 3.高斯滤波 1.均值滤波 OpenCV中的均值滤波(Mean Filter)是一种简单的滤波技术,用于平滑图像并减少噪声。它的原理非常简单:对于每个像素,将其与其周围邻域内像素的平均值作为新的像素值…...
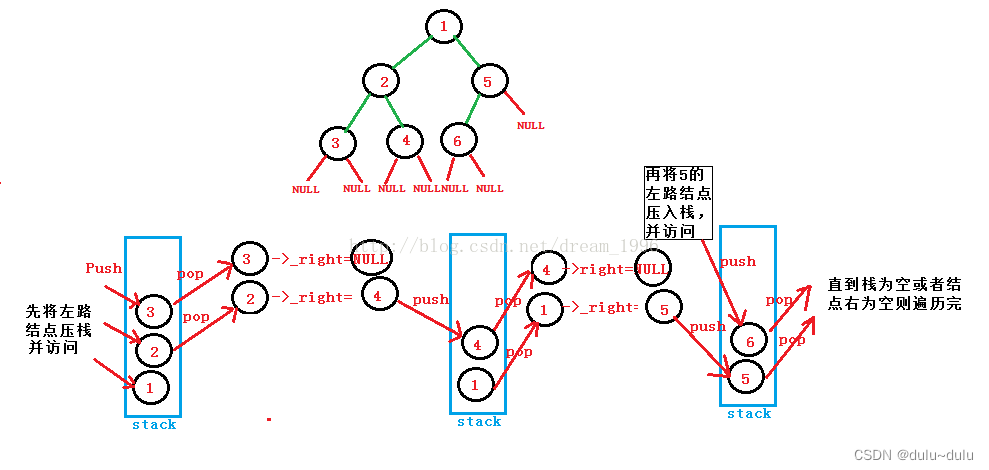
二叉树的递归遍历和非递归遍历
目录 一.二叉树的递归遍历 1.先序遍历二叉树 2.中序遍历二叉树 3.后序遍历二叉树 二.非递归遍历(栈) 1.先序遍历 2.中序遍历 3.后序遍历 一.二叉树的递归遍历 定义二叉树 #其中TElemType可以是int或者是char,根据要求自定 typedef struct BiNode{TElemType data;stru…...

JDK17:未来已来,你准备好了吗?
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...

K8s和Docker
Kubernetes(简称为K8s)和Docker是两个相关但又不同的技术。 一、Docker 1、Docker是一种容器化平台,用于将应用程序及其依赖项打包成可移植的容器。 2、Docker容器可以在任何支持Docker的操作系统上运行 好处:提供了一种轻量级…...

使用物理机服务器应该注意的事项
使用物理机服务器应该注意的事项 如今云计算的发展已经遍布各大领域,尽管现在的云服务器火遍全网,但是仍有一些大型企业依旧选择使用独立物理服务器,你知道这是为什么吗?壹基比小鑫来告诉你吧。 独立物理服务器托管业务适合大中…...

py脚本解决ArcGIS Server服务内存过大的问题
在一台服务器上,使用ArcGIS Server发布地图服务,但是地图服务较多,在发布之后,服务器的内存持续处在95%上下的高位状态,导致服务器运行状态不稳定,经常需要重新启动。重新启动后重新进入这种内存高位的陷阱…...

Go语言Web开发入门指南
Go语言Web开发入门指南 欢迎来到Go语言的Web开发入门指南。Go语言因其出色的性能和并发支持而成为Web开发的热门选择。在本篇文章中,我们将介绍如何使用Go语言构建简单的Web应用程序,包括路由、模板、数据库连接和静态文件服务。 准备工作 在开始之前…...

保姆级教程——VSCode如何在Mac上配置C++的运行环境
vscode官方下载: 点击官网链接,下载对应的pkg,安装打开; https://code.visualstudio.com/插件安装 点击箭头所指插件商店按钮,yyds; 下载C/C 插件; 
Java 操作FTP服务器进行下载文件
用Java去操作FTP服务器去做下载,本文章里面分为单个下载和批量下载,批量下载只不过多了一层循环,为了方便参考,我代码都贴出来了。 不管单个下载还是多个,一定要记得,远程服务器的直接写文件夹路径…...

物理机服务器应该注意的事
物理机服务器应该注意的事 1、选址 服务器是个非常重要的硬件产品,对机房的也是有一定的要求的,比如温度、安全性,噪音、电源稳定性等等问题都需要解决!但是不是每个人都会选择自己建立一个机房,毕竟各方面加起来的成本都太高。这…...

信息化发展24
信息技术的发展 1 )在计算机软硬件方面, 计算机硬件技术将向超高速、超小型、平行处理、智能化的方向发展, 计算机硬件设备的体积越来越小、速度越来越高、容量越来越大、功耗越来越低、可靠性越来越高。 2 )计算机软件越来越丰富…...

ClawX:基于RAG的智能代码助手,实现项目级上下文感知编程
1. 项目概述:ClawX,一个面向开发者的智能代码助手最近在GitHub上看到一个挺有意思的项目,叫ClawX。乍一看这个名字,可能会联想到“爪子”或者“抓取”,但它的定位其实是一个AI驱动的代码助手。作为一个在开发一线摸爬滚…...
—— 参数初始化策略(Xavier/Kaiming/正交)(三十六))
深度学习优化算法(四)—— 参数初始化策略(Xavier/Kaiming/正交)(三十六)
1. 定位导航 第 33-35 篇讨论了训练过程——但还有一个关键问题被忽略了:从哪里开始? Goodfellow 的警告: 训练深度模型是一个足够困难的问题,以至于大多数算法都很大程度地受到初始化选择的影响。初始点能够决定算法是否收敛、收敛速度、最终的代价值。 本篇专攻怎么挑一…...

别再为WinPcap头疼了!手把手教你用SOEM 1.3.1在Windows上搞定EtherCAT主站开发环境
告别WinPcap困扰:SOEM 1.3.1在Windows下的EtherCAT主站开发全攻略 当第一次接触EtherCAT主站开发时,许多工程师都会遇到一个共同的"拦路虎"——WinPcap环境配置。这个看似简单的网络抓包工具,在实际开发中却可能耗费数小时甚至数天…...

通过curl命令直接调用Taotoken大模型API的排错指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令直接调用Taotoken大模型API的排错指南 对于需要在无SDK环境下进行快速测试、调试或集成的开发者而言,直接…...

并行LLM推理技术:Hogwild! Inference原理与应用
1. 并行LLM推理的技术背景与挑战在传统Transformer架构中,语言模型的推理过程本质上是顺序执行的——每个新token的生成都严格依赖于之前所有token的注意力计算结果。这种串行特性导致两个显著瓶颈:首先,硬件计算资源利用率低下,特…...

基于PIR传感器与LIFX智能灯泡的物联网运动感应照明系统实战
1. 项目概述与核心价值如果你对智能家居自动化感兴趣,并且想亲手打造一个既实用又有趣的照明项目,那么这个基于Adafruit FunHouse和LIFX智能灯泡的运动感应照明系统,绝对是一个绝佳的起点。它不仅仅是一个“开灯关灯”的简单触发器࿰…...

3分钟上手RePKG:轻松提取Wallpaper Engine壁纸资源的终极指南
3分钟上手RePKG:轻松提取Wallpaper Engine壁纸资源的终极指南 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg 你是否曾经遇到过这样的困扰?在Wallpaper Engi…...

3D打印乐高手机支架:低成本打造高清视频会议摄像头方案
1. 项目概述与核心思路如果你和我一样,对视频会议、直播时笔记本自带摄像头那“感人”的画质感到无奈,同时又觉得单独购买一个高品质的网络摄像头是一笔不小的开销,那么这个项目绝对值得你花上一个周末的时间来折腾。它的核心思路非常巧妙&am…...

终极指南:如何为你的Mac鼠标安装强大定制功能
终极指南:如何为你的Mac鼠标安装强大定制功能 【免费下载链接】mac-mouse-fix Mac Mouse Fix - Make Your $10 Mouse Better Than an Apple Trackpad! 项目地址: https://gitcode.com/GitHub_Trending/ma/mac-mouse-fix Mac Mouse Fix是一款革命性的开源工具…...

DS3502 I2C数字电位器:从原理到Arduino/Python实战应用
1. 项目概述:告别手动旋钮,拥抱数字控制如果你和我一样,厌倦了在面包板上反复拧动电位器旋钮来调试电路,或者正在寻找一种能够通过程序精确控制电阻值的方法,那么DS3502这类I2C数字电位器绝对是你的“梦中情芯”。它本…...