44、Flink之module模块介绍及使用示例和Flink SQL使用hive内置函数及自定义函数详细示例--网上有些说法好像是错误的
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例
14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性
15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Elasticsearch示例(2)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Kafka示例(3)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Hive示例(6)
20、Flink SQL之SQL Client: 不用编写代码就可以尝试 Flink SQL,可以直接提交 SQL 任务到集群上
22、Flink 的table api与sql之创建表的DDL
24、Flink 的table api与sql之Catalogs
30、Flink SQL之SQL 客户端(通过kafka和filesystem的例子介绍了配置文件使用-表、视图等)
41、Flink之Hive 方言介绍及详细示例
42、Flink 的table api与sql之Hive Catalog
43、Flink之Hive 读写及详细验证示例
44、Flink之module模块介绍及使用示例和Flink SQL使用hive内置函数及自定义函数详细示例–网上有些说法好像是错误的
文章目录
- Flink 系列文章
- 一、模块Modules
- 1、模块介绍
- 2、模块类别Module Types
- 1)、CoreModule
- 2)、HiveModule
- 3)、User-Defined Module
- 3、模块生命周期和解析顺序Module Lifecycle and Resolution Order
- 4、模块Modules的使用
- 1)、SQL方式
- 2)、编码方式-java
- 二、Hive Functions内置函数和自定义函数使用
- 1、通过 HiveModule 使用 Hive 内置函数
- 2、使用原生的hive 聚合函数Native Hive Aggregate Functions
- 3、hive的自定义函数介绍
- 4、hive的自定义函数使用-示例
- 1)、定义函数
- 1、UDF实现
- 2、GenericUDF实现
- 2)、hive中注册函数并使用
- 3)、flink sql中使用
本文介绍了Flink的module功能以及Flink SQl使用hive的内置函数和hive的自定义函数功能。
本文依赖hadoop、hive、flink集群能正常使用,其版本分别是3.1.4、3.1.2和1.13.6,内容是按照1.17版本写的。
本文分为2个部分,即介绍了Flink 的Module和Flink SQL 使用Hive的内置函数及自定义函数,并提供了完整的可验证通过的示例。
一、模块Modules
1、模块介绍
模块允许用户扩展 Flink 的内置对象,例如定义行为类似于 Flink 内置函数的函数。它们是可插拔的,虽然 Flink 提供了一些预构建的模块,但用户可以编写自己的模块。
例如,用户可以定义自己的地理函数,并将它们作为内置函数插入 Flink 中,用于 Flink SQL 和表 API。另一个例子是用户可以加载一个现成的 Hive 模块,将 Hive 内置函数用作 Flink 内置函数。
此外,模块可以提供内置的表源( table source)和接收器工厂(sink factories),这些工厂禁用了基于 Java 服务提供程序接口 (SPI) 的 Flink 默认发现机制,或者影响如何在没有相应目录的情况下创建临时表的连接器。
模块提供的对象被视为 Flink 系统(内置)对象的一部分;因此,它们没有任何命名空间。
2、模块类别Module Types
1)、CoreModule
CoreModule 包含 Flink 的所有系统(内置)功能,默认情况下加载并启用。
2)、HiveModule
HiveModule 为 SQL 和 Table API 用户提供了 Hive 内置函数作为 Flink 的系统函数。Flink 的 Hive 文档提供了有关设置模块的完整详细信息。
3)、User-Defined Module
用户可以通过实现模块接口来开发自定义模块。若要在 SQL CLI 中使用自定义模块,用户应通过实现模块工厂接口来开发模块及其相应的模块工厂。
模块工厂定义一组属性,用于在 SQL CLI 引导时配置模块。属性将传递给发现服务,该服务尝试将属性与 ModuleFactory 匹配并实例化相应的模块实例。
3、模块生命周期和解析顺序Module Lifecycle and Resolution Order
可以加载、启用、禁用和卸载模块。当 TableEnvironment 最初加载模块时,默认情况下会启用该模块。Flink 支持多个模块,并跟踪加载顺序以解析元数据。此外,Flink 只解析启用模块之间的功能。例如,当两个模块中存在两个同名的函数时,将有三个条件,如下。
- 如果两个模块都启用了,那么 Flink 会根据模块的解析顺序解析函数。
- 如果其中一个被禁用,则 Flink 会将函数解析为启用的模块。
- 如果两个模块都被禁用,那么 Flink 就无法解析该功能。
用户可以通过使用不同声明顺序的模块来更改解析顺序。例如,用户可以指定 Flink 通过 USE MODULES Hive、core 首先在 Hive 中查找函数。
此外,用户还可以通过不声明模块来禁用模块。例如,用户可以指定 Flink 通过 USE MODULES hive 禁用核心模块(但是,强烈建议不要禁用核心模块)。禁用模块不会卸载它,用户可以使用它时再次启用它。例如,用户可以带回核心模块并将其放置在第一个通过USE MODULES core,hive。仅当模块已加载时,才能启用该模块。使用卸载的模块将引发异常。最终,用户可以卸载模块。
禁用和卸载模块的区别在于,TableEnvironment 仍然保留已禁用的模块,用户可以列出所有已加载的模块以查看已禁用的模块。
4、模块Modules的使用
一般有2种使用方式,即sql方式和开发语言编程方式,如java、scala、python。
用户可以使用 SQL 在表 API 和 SQL CLI 中加载/卸载/使用/列出模块。
用户可以使用 Java、Scala 或 Python 以编程方式加载/卸载/使用/列出模块。
1)、SQL方式
sql的方式本文列出了三种,即通过客户端直接使用、java语言中编写sql和配置文件方式。
- SQL cli
Flink SQL> SHOW MODULES;
+-------------+
| module name |
+-------------+
| core |
+-------------+
1 row in setFlink SQL> SHOW FULL MODULES;
+-------------+------+
| module name | used |
+-------------+------+
| core | true |
+-------------+------+
1 row in setFlink SQL> LOAD MODULE hive WITH ('hive-version' = '3.1.2');
[INFO] Execute statement succeed.Flink SQL> SHOW MODULES;
+-------------+
| module name |
+-------------+
| core |
| hive |
+-------------+
2 rows in setFlink SQL> SHOW FULL MODULES;
+-------------+------+
| module name | used |
+-------------+------+
| core | true |
| hive | true |
+-------------+------+
2 rows in setFlink SQL> USE MODULES hive, core ;
[INFO] Execute statement succeed.Flink SQL> SHOW MODULES;
+-------------+
| module name |
+-------------+
| hive |
| core |
+-------------+
2 rows in setFlink SQL> SHOW FULL MODULES;
+-------------+------+
| module name | used |
+-------------+------+
| hive | true |
| core | true |
+-------------+------+
2 rows in setFlink SQL> UNLOAD MODULE hive;
[INFO] Execute statement succeed.Flink SQL> SHOW MODULES;
+-------------+
| module name |
+-------------+
| core |
+-------------+
1 row in setFlink SQL> SHOW FULL MODULES;
+-------------+------+
| module name | used |
+-------------+------+
| core | true |
+-------------+------+
1 row in set- java
EnvironmentSettings settings = EnvironmentSettings.inStreamingMode();
TableEnvironment tableEnv = TableEnvironment.create(settings);// Show initially loaded and enabled modules
tableEnv.executeSql("SHOW MODULES").print();
// +-------------+
// | module name |
// +-------------+
// | core |
// +-------------+
tableEnv.executeSql("SHOW FULL MODULES").print();
// +-------------+------+
// | module name | used |
// +-------------+------+
// | core | true |
// +-------------+------+// Load a hive module
tableEnv.executeSql("LOAD MODULE hive WITH ('hive-version' = '...')");// Show all enabled modules
tableEnv.executeSql("SHOW MODULES").print();
// +-------------+
// | module name |
// +-------------+
// | core |
// | hive |
// +-------------+// Show all loaded modules with both name and use status
tableEnv.executeSql("SHOW FULL MODULES").print();
// +-------------+------+
// | module name | used |
// +-------------+------+
// | core | true |
// | hive | true |
// +-------------+------+// Change resolution order
tableEnv.executeSql("USE MODULES hive, core");
tableEnv.executeSql("SHOW MODULES").print();
// +-------------+
// | module name |
// +-------------+
// | hive |
// | core |
// +-------------+
tableEnv.executeSql("SHOW FULL MODULES").print();
// +-------------+------+
// | module name | used |
// +-------------+------+
// | hive | true |
// | core | true |
// +-------------+------+// Disable core module
tableEnv.executeSql("USE MODULES hive");
tableEnv.executeSql("SHOW MODULES").print();
// +-------------+
// | module name |
// +-------------+
// | hive |
// +-------------+
tableEnv.executeSql("SHOW FULL MODULES").print();
// +-------------+-------+
// | module name | used |
// +-------------+-------+
// | hive | true |
// | core | false |
// +-------------+-------+// Unload hive module
tableEnv.executeSql("UNLOAD MODULE hive");
tableEnv.executeSql("SHOW MODULES").print();
// Empty set
tableEnv.executeSql("SHOW FULL MODULES").print();
// +-------------+-------+
// | module name | used |
// +-------------+-------+
// | hive | false |
// +-------------+-------+
- yaml
使用 YAML 定义的所有模块都必须提供指定类型的类型属性。现支持以下类型

modules:- name: coretype: core- name: hivetype: hive
使用SQL方式时,模块的名称是用于加载模块的,所以是模块的唯一标识,并且大小写敏感
2)、编码方式-java
EnvironmentSettings settings = EnvironmentSettings.inStreamingMode();
TableEnvironment tableEnv = TableEnvironment.create(settings);// Show initially loaded and enabled modules
tableEnv.listModules();
// +-------------+
// | module name |
// +-------------+
// | core |
// +-------------+
tableEnv.listFullModules();
// +-------------+------+
// | module name | used |
// +-------------+------+
// | core | true |
// +-------------+------+// Load a hive module
tableEnv.loadModule("hive", new HiveModule());// Show all enabled modules
tableEnv.listModules();
// +-------------+
// | module name |
// +-------------+
// | core |
// | hive |
// +-------------+// Show all loaded modules with both name and use status
tableEnv.listFullModules();
// +-------------+------+
// | module name | used |
// +-------------+------+
// | core | true |
// | hive | true |
// +-------------+------+// Change resolution order
tableEnv.useModules("hive", "core");
tableEnv.listModules();
// +-------------+
// | module name |
// +-------------+
// | hive |
// | core |
// +-------------+
tableEnv.listFullModules();
// +-------------+------+
// | module name | used |
// +-------------+------+
// | hive | true |
// | core | true |
// +-------------+------+// Disable core module
tableEnv.useModules("hive");
tableEnv.listModules();
// +-------------+
// | module name |
// +-------------+
// | hive |
// +-------------+
tableEnv.listFullModules();
// +-------------+-------+
// | module name | used |
// +-------------+-------+
// | hive | true |
// | core | false |
// +-------------+-------+// Unload hive module
tableEnv.unloadModule("hive");
tableEnv.listModules();
// Empty set
tableEnv.listFullModules();
// +-------------+-------+
// | module name | used |
// +-------------+-------+
// | hive | false |
// +-------------+-------+
二、Hive Functions内置函数和自定义函数使用
关于Flink sql使用hive的内置函数可以参考文章:41、Flink之Hive 方言介绍及详细示例
1、通过 HiveModule 使用 Hive 内置函数
HiveModule 为 Flink SQL 和 Table API 用户提供了 Hive 内置函数作为 Flink 系统(内置)函数。
- java 代码示例
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tenv = StreamTableEnvironment.create(env);String moduleName = "myhive";String hiveVersion = "3.1.2";tenv.loadModule(moduleName, new HiveModule(hiveVersion));
- yaml配置示例
modules:- name: coretype: core- name: myhivetype: hive
- hive内置函数使用示例
CREATE CATALOG alan_hivecatalog WITH ('type' = 'hive','default-database' = 'testhive','hive-conf-dir' = '/usr/local/bigdata/apache-hive-3.1.2-bin/conf'
);
use catalog alan_hivecatalog;
set table.sql-dialect=hive;
load module hive;
use modules hive,core;
select explode(array(1,2,3));
create table tbl (key int,value string);
set execution.runtime-mode=streaming;
insert into table tbl values (5,'e'),(1,'a'),(1,'a'),(3,'c'),(2,'b'),(3,'c'),(3,'c'),(4,'d');
select * from tbl;--------------------flink sql 操作
Flink SQL> select explode(array(1,2,3));
Hive Session ID = 7d3ae2d5-24f3-4d97-9897-83c8a9abda9b
[ERROR] Could not execute SQL statement. Reason:
org.apache.hadoop.hive.ql.parse.SemanticException: Invalid function explodeFlink SQL> set table.sql-dialect=hive;Flink SQL> select explode(array(1,2,3));
Hive Session ID = c0b87333-4957-4c18-b197-27649a3f2ae2
[ERROR] Could not execute SQL statement. Reason:
org.apache.hadoop.hive.ql.parse.SemanticException: Invalid function explodeFlink SQL> load module hive;Flink SQL> use modules hive,core;Flink SQL> select explode(array(1,2,3));+----+-------------+
| op | col |
+----+-------------+
| +I | 1 |
| +I | 2 |
| +I | 3 |
+----+-------------+
Received a total of 3 rowsFlink SQL> create table tbl (key int,value string);Flink SQL> insert overwrite table tbl values (5,'e'),(1,'a'),(1,'a'),(3,'c'),(2,'b'),(3,'c'),(3,'c'),(4,'d');
Hive Session ID = 12fe08fa-5e63-44b2-8fc3-a90064959451
[INFO] Submitting SQL update statement to the cluster...
[ERROR] Could not execute SQL statement. Reason:
java.lang.IllegalStateException: Streaming mode not support overwrite.Flink SQL> set execution.runtime-mode=batch;
Hive Session ID = 4f17cc70-165c-4540-a299-874b66458521
[INFO] Session property has been set.Flink SQL> insert overwrite table tbl values (5,'e'),(1,'a'),(1,'a'),(3,'c'),(2,'b'),(3,'c'),(3,'c'),(4,'d');
Hive Session ID = 1923623f-03d3-44b4-93ab-ee8498c5da06
[INFO] Submitting SQL update statement to the cluster...
[ERROR] Could not execute SQL statement. Reason:
java.lang.IllegalArgumentException: Checkpoint is not supported for batch jobs.Flink SQL> set execution.runtime-mode=streaming; Flink SQL> insert into table tbl values (5,'e'),(1,'a'),(1,'a'),(3,'c'),(2,'b'),(3,'c'),(3,'c'),(4,'d');Flink SQL> select * from tbl;
+----+-------------+--------------------------------+
| op | key | value |
+----+-------------+--------------------------------+
| +I | 5 | e |
| +I | 1 | a |
| +I | 1 | a |
| +I | 3 | c |
| +I | 2 | b |
| +I | 3 | c |
| +I | 3 | c |
| +I | 4 | d |
+----+-------------+--------------------------------+
Received a total of 8 rows一些hive的内置函数存在线程安全问题,建议更新hive的版本修复它
2、使用原生的hive 聚合函数Native Hive Aggregate Functions
如果 HiveModule 加载的优先级高于 CoreModule,Flink 会先尝试使用 Hive 内置函数。然后对于 Hive 内置的聚合函数,Flink 现在只能使用基于排序的聚合算子。从 Flink 1.17 开始,我们引入了一些原生的 Hive 聚合函数,可以使用基于哈希的聚合运算符来执行。目前仅支持5个函数,即sum/count/avg/min/max,未来将支持更多聚合函数。用户可以通过打开选项 table.exec.hive.native-agg-function.enabled 来使用原生的聚合函数,这为作业带来了显著的性能改进。

原生的聚合函数(native aggregation functions)的功能现在与 Hive 内置聚合函数不完全一致,例如,不支持某些数据类型。如果性能不是瓶颈,则无需启用此选项。此外,通过 SqlClient 使用时,无法为每个作业打开 table.exec.hive.native-agg-function.enabled 选项,目前仅支持模块级别。用户应先启用此选项,然后加载 HiveModule。此问题将在将来修复。
3、hive的自定义函数介绍
用户可以在 Flink 中使用他们现有的 Hive 用户定义函数。
当前支持的用户自定义函数包括如下:
- UDF
- GenericUDF
- GenericUDTF
- UDAF
- GenericUDAFResolver2
在查询计划和执行时,Hive 的 UDF 和 GenericUDF 会自动转换为 Flink 的 ScalarFunction,Hive 的 GenericUDTF 会自动转换为 Flink 的 TableFunction,Hive 的 UDAF 和 GenericUDAFResolver2 会自动转换为 Flink 的 AggregateFunction。
若要使用 Hive 用户定义函数,前提条件如下:
- 设置由 Hive metastore支持的 HiveCatalog,该目录包含该函数作为会话的当前目录
- 在 Flink 的类路径中包含包含该函数的 jar
- 使用 Blink planner (1.14版本以后没有这个限制)
4、hive的自定义函数使用-示例
关于hive自定义函数的开发过程详见文章关于自定义函数的部分:7、hive shell客户端与属性配置、内置运算符、函数(内置运算符与自定义UDF运算符)
简单来说分为如下几步:
- 写一个java类,继承UDF,并重载evaluate方法,方法中实现函数的业务逻辑(重载意味着可以在一个java类中实现多个函数功能)
- 程序打成jar包,上传HS2服务器本地或者HDFS
- 客户端命令行中添加jar包到Hive的classpath: hive>add JAR /xxxx/udf.jar
- 注册成为临时函数(给UDF命名):create temporary function 函数名 as ‘UDF类全路径’
- HQL中使用函数
1)、定义函数
本函数实现功能如下:
- 能够对输入数据进行非空判断、手机号位数判断
- 能够实现校验手机号格式,把满足规则的进行****处理
- 对于不符合手机号规则的数据直接返回,不处理
- 代码 -有两种实现方式即UDF和GenericUDF
1、UDF实现
public class EncryptPhoneNumber extends UDF {/*** 重载evaluate方法 实现函数的业务逻辑* @param phoNum 入参:未加密手机号* @return 返回:加密后的手机号字符串*/public String evaluate(String phoNum){String encryptPhoNum = null;//手机号不为空 并且为11位if (StringUtils.isNotEmpty(phoNum) && phoNum.trim().length() == 11 ) {//判断数据是否满足中国大陆手机号码规范String regex = "^(1[3-9]\\d{9}$)";Pattern p = Pattern.compile(regex);Matcher m = p.matcher(phoNum);if (m.matches()) {//进入这里都是符合手机号规则的//使用正则替换 返回加密后数据encryptPhoNum = phoNum.trim().replaceAll("(\\d{3})\\d{4}(\\d{4})","$1****$2");}else{//不符合手机号规则 数据直接原封不动返回encryptPhoNum = phoNum;}}else{//不符合11位 数据直接原封不动返回encryptPhoNum = phoNum;}return encryptPhoNum;}
}
2、GenericUDF实现
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.JavaStringObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.StringObjectInspector;public class EncryptPhoneNumber extends GenericUDF {StringObjectInspector elementOI;/*** Initialize this GenericUDF. This will be called once and only once per* GenericUDF instance.*/@Overridepublic ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {// 1. 检查该记录是否传过来正确的参数数量if (arguments.length != 1) {throw new UDFArgumentException("输入参数错误,必须是一个参数。");}// 2. 检查该条记录是否传过来正确的参数类型ObjectInspector a = arguments[0];if (!(a instanceof StringObjectInspector)) {throw new UDFArgumentException("輸入參數錯誤,需要是一個字符串");}// 3. 检查通过后,将参数赋值给成员变量ObjectInspector,为了在evaluate()中使用this.elementOI = (StringObjectInspector) a;return PrimitiveObjectInspectorFactory.javaStringObjectInspector;}/*** Evaluate the GenericUDF with the arguments. 重载evaluate方法 实现函数的业务逻辑*/@Overridepublic Object evaluate(DeferredObject[] arguments) throws HiveException {String phoNum = elementOI.getPrimitiveJavaObject(arguments[0].get()).toString();String encryptPhoNum = null;// 手机号不为空 并且为11位if (StringUtils.isNotEmpty(phoNum) && phoNum.trim().length() == 11) {// 判断数据是否满足中国大陆手机号码规范String regex = "^(1[3-9]\\d{9}$)";Pattern p = Pattern.compile(regex);Matcher m = p.matcher(phoNum);if (m.matches()) {// 进入这里都是符合手机号规则的// 使用正则替换 返回加密后数据encryptPhoNum = phoNum.trim().replaceAll("(\\d{3})\\d{4}(\\d{4})", "$1****$2");} else {// 不符合手机号规则 数据直接原封不动返回encryptPhoNum = phoNum;}} else {// 不符合11位 数据直接原封不动返回encryptPhoNum = phoNum;}return encryptPhoNum;}/*** Get the String to be displayed in explain.*/@Overridepublic String getDisplayString(String[] children) {return "this is a EncryptPhoneNumber pro.";}public static void main(String[] args) throws Exception {EncryptPhoneNumber ep = new EncryptPhoneNumber();JavaStringObjectInspector stringOI = PrimitiveObjectInspectorFactory.javaStringObjectInspector;JavaStringObjectInspector resultInspector = (JavaStringObjectInspector) ep.initialize(new ObjectInspector[] { stringOI });Object result = ep.evaluate(new DeferredObject[] { new DeferredJavaObject("13917885967") });System.out.println("result:" + result);}}2)、hive中注册函数并使用
本处简单的描述过程和命令。
- 打包
mvn package -Dmaven.test.skip=true
- 添加jar包到Hive的classpath
0: jdbc:hive2://server4:10000> add jar /usr/local/bigdata/testjar/hive-0.0.1-SNAPSHOT.jar;
No rows affected (0.01 seconds)- 注册成为永久函数
该处需要特别注意,同时需要注册函数的时候带上数据库名称,否则默认为default.函数名称,如:default.encryptphonenumber
-- alan_testdatabase 为hive中一个数据库名称
CREATE FUNCTION alan_testdatabase.encryptPhoneNumber AS 'org.hive.udf.EncryptPhoneNumber';0: jdbc:hive2://server4:10000> CREATE FUNCTION alan_testdatabase.encryptPhoneNumber AS 'org.hive.udf.EncryptPhoneNumber';
No rows affected (0.023 seconds)- 验证hive的自定义函数功能
0: jdbc:hive2://server4:10000> select alan_testdatabase.encryptPhoneNumber("13788889999");
+--------------+
| _c0 |
+--------------+
| 137****9999 |
+--------------+3)、flink sql中使用
前提:需要将hive 自定义函数的jar包(也就是第二步中注册为函数的那个jar包)放在flink的lib目录下,并重启集群。
- 在hive中查看自定义的函数
0: jdbc:hive2://server4:10000> show functions;
+---------------------------------------+
| tab_name |
+---------------------------------------+
......
| aes_decrypt |
| aes_encrypt |
| alan_testdatabase.encryptphonenumber |
| and |
| array |
........
- 设置Flink sql的环境
Flink SQL> LOAD MODULE hive WITH ('hive-version' = '3.1.2');
[INFO] Execute statement succeed.Flink SQL> use modules hive,core;
[INFO] Execute statement succeed.Flink SQL> SHOW FULL MODULES;
+-------------+------+
| module name | used |
+-------------+------+
| hive | true |
| core | true |
+-------------+------+
2 rows in setFlink SQL> use catalog alan_hivecatalog;
[INFO] Execute statement succeed.Flink SQL> set table.sql-dialect=hive;
[INFO] Session property has been set.Flink SQL> SET sql-client.execution.result-mode = tableau;
[INFO] Session property has been set.- 在flink中查看函数
Flink SQL> use alan_testdatabase;
[INFO] Execute statement succeed.Flink SQL> show functions;
Hive Session ID = 5d34cbf8-5984-4ec0-8527-e06a948ad7ca
+--------------------------------+
| function name |
+--------------------------------+
.........
| encryptphonenumber |
.........
- 在flink sql中验证hive 的自定义函数
Flink SQL> select alan_testdatabase.encryptPhoneNumber("13788889999");
+----+--------------------------------+
| op | _o__c0 |
+----+--------------------------------+
| +I | 137****9999 |
+----+--------------------------------+
Received a total of 1 row
以上,介绍了Flink的module功能以及Flink SQl使用hive的内置函数和hive的自定义函数功能。
相关文章:
44、Flink之module模块介绍及使用示例和Flink SQL使用hive内置函数及自定义函数详细示例--网上有些说法好像是错误的
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...

电脑入门: 路由器初学者完全教程
路由器初学者完全教程 本文以Cisco2620为例,讲述了路由器的初始化配置以及远程接入的配置方法,探讨了如何使用内部网络的DHCP服务功能为远程拨入的用户分配地址信息以及路由器常见故障的排除技巧。 (本文假定Cisco2620路由器为提供远…...
如何查找GNU C语言参考手册
快捷通道 标准C/C参考手册 GNU C参考手册HTML版 GNU C参考手册PDF版本 HTML版本部分目录预览 从GNU官网找那个GNU C参考手册 访问gnu.org 点击软件 下滑找到gnu-c-manual或者在这个页面Ctrl-f搜索"manual" 点进去即可看到HTML版本和PDF版本...
弄懂软件设计模式(一):单例模式和策略模式
前言 软件设计模式和设计原则是十分重要的,所有的开发框架和组件几乎都使用到了,比如在这小节中的单例模式就在SpringBean中被使用。在这篇文章中荔枝将会仔细梳理有关单例模式和策略模式的相关知识点,其中比较重要的是掌握单例模式的常规写法…...

Redis----布隆过滤器
目录 背景 解决方案 什么是布隆过滤器 布隆过滤器的原理 一些其他运用 背景 比如我们在观看新闻或者刷微博的时候,会不停地给我们推荐新的内容,我们发现几乎没有重复的,说明后台已经进行了去重处理,基于如何去重,…...
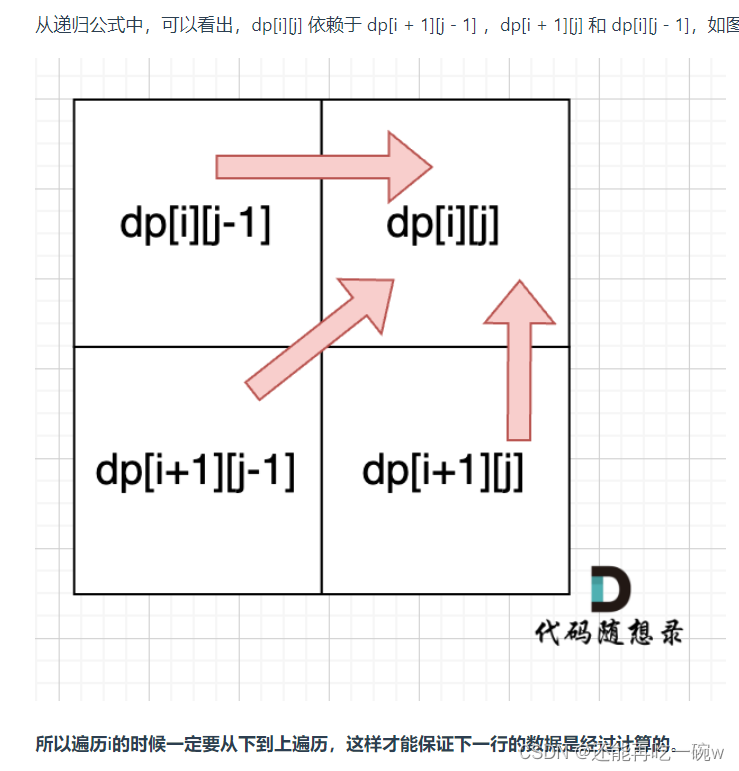
day 49 | 647. 回文子串 ● 516.最长回文子序列
647. 回文子串 dp含义:dp如果是表示i-j的序列中回文子串的个数的话,当新来一个后只能判定出来是整体的回文,内部的无法判断,所以用bool表示整体比较恰当。 递推公式:由于i,j是由i1,j-1决定的,所…...
【网络编程】C++实现网络通信服务器程序||计算机网络课设||Linux系统编程||TCP协议(附源码)
TCP网络服务器 🐍 1.程序简洁🦎2. 服务端ServerTcp程序介绍🦖3.线程池ThreadPool介绍🦕 4.任务类Task介绍🐙5. 客户端Client介绍🦑6.运行结果:🦐 7. 源码🦞7.1 serverTcp…...

C语言类型占内存大小
C语言类型占内存大小 C语言数据类型sizeof测试基本数据类型所占字符大小运行结果数据模型 C语言数据类型 sizeof测试基本数据类型所占字符大小 #include <stdio.h>int main() {char a;short b;int c;long d;float e;double f;printf("char %d\n", sizeof (a…...
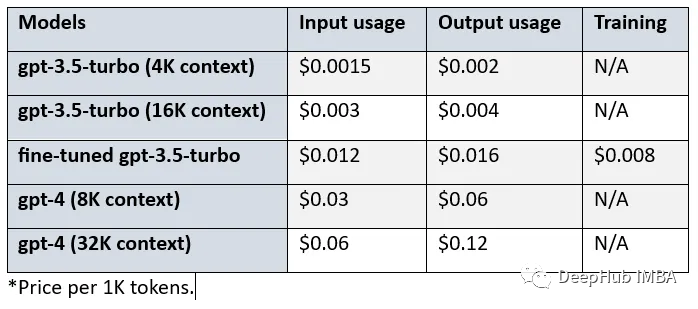
使用GPT-4生成训练数据微调GPT-3.5 RAG管道
OpenAI在2023年8月22日宣布,现在可以对GPT-3.5 Turbo进行微调了。也就是说,我们可以自定义自己的模型了。然后LlamaIndex就发布了0.8.7版本,集成了微调OpenAI gpt-3.5 turbo的功能 也就是说,我们现在可以使用GPT-4生成训练数据&a…...

RUST 每日一省:模式匹配
我们经常使用let 语句创建新的变量绑定——但是 let 的功能并不仅限于此。事实上, let 语句是一个模式匹配语句。它允许我们根据内部结构对值进行操作和判断,或者可以用于从代数数据类型中提取值。 let tuple (1_i32, false, 3f32); let (head, center…...

利用Jmeter做接口测试(功能测试)全流程分析
利用Jmeter做接口测试怎么做呢?过程真的是超级简单。 明白了原理以后,把零碎的知识点填充进去就可以了。所以在学习的过程中,不管学什么,我一直都强调的是要循序渐进,和明白原理和逻辑。这篇文章就来介绍一下如何利用…...
依赖导入失败场景和解决方案
在使用 Maven 构建项目时,可能会发生依赖项下载错误的情况,主要原因有以下几种: 下载依赖时出现网络故障或仓库服务器宕机等原因,导致无法连接至 Maven 仓库,从而无法下载依赖。 依赖项的版本号或配置文件中的版本号错…...

DiffBIR: Towards Blind Image Restoration with Generative Diffusion Prior
DiffBIR: 基于生成扩散先验的盲图像恢复 论文链接:https://arxiv.org/abs/2308.15070 项目链接:https://github.com/XPixelGroup/DiffBIR Abstract 我们提出了DiffBIR,它利用预训练的文本到图像扩散模型来解决盲图像恢复问题。我们的框架采…...

pycharm如何配置 .gitignore 文件
参考:https://zongweizhou1.github.io/2019/06/16/pycharm-gitignore/ .gitignore 文件本身不需要纳入版本控制,在 .gitignore 文件中写入“.gitignore"忽略即可...
【Spring面试题】AOP相关面试题:概念?使用场景?如何使用?核心?
什么是AOP AOP是面向切面,面向切面编程,是通过预编译方式和运行期动态代理实现程序功能的统一维护的一种技术。对多个对象共同行为封装成一个模块叫切面,然后某个方法为切点。 通俗的讲:就是在一些代码中做重复操作的时候,我们为了…...

Yolov5的tensorRT加速(python)
地址:https://github.com/wang-xinyu/tensorrtx/tree/master/yolov5 下载yolov5代码 方法一:使用torch2trt 安装torch2trt与tensorRT 参考博客:https://blog.csdn.net/dou3516/article/details/124538557 先从github拉取torch2trt源码 ht…...
设计模式(1) - UML类图
1、前言 最近在阅读 Android 源码,时常碰到代码中有一些巧妙的写法,简单的如 MediaPlayerService 中的 IFactory,我知道它是工厂模式,但是却不十分清楚它为什么这么用;复杂点的像 NuPlayer 中的 DeferredActions 机制…...
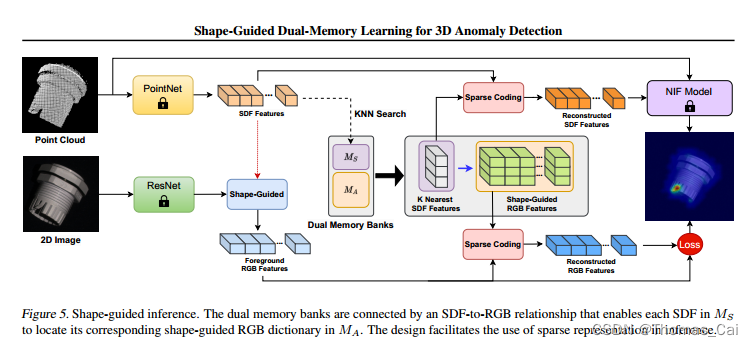
3D异常检测论文笔记 | Shape-Guided Dual-Memory Learning for 3D Anomaly Detection
文章目录 摘要一、介绍三、方法3.1. 形状引导专家学习3.2. Shape-Guided推理 摘要 我们提出了一个形状引导的专家学习框架来解决无监督的三维异常检测问题。我们的方法是建立在两个专门的专家模型的有效性和他们的协同从颜色和形状模态定位异常区域。第一个专家利用几何信息通…...
如何将枯燥的大数据进行可视化处理?
在数字时代,大数据已经成为商业、科学、政府和日常生活中不可或缺的一部分。然而,大数据本身往往是枯燥的、难以理解的数字和文字,如果没有有效的方式将其可视化,就会错失其中的宝贵信息。以下是一些方法,可以将枯燥的…...

linux bash中 test命令详解
test命令用于检查某个条件是否成立。它可以进行数值、字符和文件三方面的测试。 1、数值测试 -eq 等于-ne 不等于-gt 大于-ge 大于或等于-lt 小于-le 小于或等于 例如,我们可以测试两个变量是否相等: num1100 num2200 if test $num1 -eq $num2 thene…...

穿越机老鸟踩坑实录:MPU6000传感器在F4飞控上的IMU方向“玄学”配置
穿越机IMU方向配置实战:从MPU6000异常自旋到飞控底层校准 当你的穿越机在通电瞬间像被无形大手狠狠抽了一记耳光般疯狂自旋,而Betaflight地面站里陀螺仪数据却显示"一切正常"时,这往往意味着你正遭遇IMU方向配置的"量子纠缠态…...

FanControl终极指南:免费开源的风扇控制神器,轻松解决Windows散热与噪音问题
FanControl终极指南:免费开源的风扇控制神器,轻松解决Windows散热与噪音问题 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https:…...

SimulinkVeriStandLabVIEW协同开发——从模型编译到交互式仪表盘部署
1. 工具链协同开发的核心价值 在电力电子和工业控制领域,快速原型开发往往需要跨越建模、实时测试和人机交互三个关键环节。Simulink、VeriStand和LabVIEW组成的工具链,就像汽车制造的流水线——Simulink是设计图纸的工程师,VeriStand是组装车…...

单元体幕墙计算方法研究
单元体幕墙计算方法研究 一、单元板块计算 选择隔离的单个单元进行计算,不需要考虑周边单元的影响。 单元之间的相互影响,来自于左右立柱的变形不一致,在截面选择上反应的就是左右立柱的截面参数的不同。 所以,单元间的相互影响,可以通过控制左右立柱截面参数的相近而进…...

Touchpoint:命令行工具集中管理工作上下文,提升开发效率
1. 项目概述:一个被低估的开发者效率工具如果你和我一样,日常开发工作需要在多个代码仓库、项目管理工具(如Jira、Linear)、文档平台(如Confluence、Notion)和沟通软件(如Slack)之间…...

FPGA高速ADC数据采集实战——基于AD9253 LVDS接口与ISERDESE2设计
1. AD9253高速ADC核心特性解析 AD9253这颗14位125MSPS四通道ADC芯片,在通信和医疗成像领域堪称经典。我经手过的多个雷达项目中,它的信噪比表现总能带来惊喜——75.3dBFS的实测数据比手册标称值还要稳定。但真正让工程师们又爱又恨的,是它那个…...
)
用51单片机和HC-SR04超声波模块DIY一个倒车雷达(附完整代码和立创EDA原理图)
51单片机与HC-SR04超声波模块实战:打造高精度倒车雷达系统 在汽车电子和智能硬件领域,倒车雷达作为基础安全装置,其DIY实现不仅能帮助理解超声波测距原理,更是掌握嵌入式系统开发的绝佳实践。本文将手把手教你使用经典的STC89C52单…...

窗口大小控制神器:3分钟掌握WindowResizer的终极窗口调整技巧
窗口大小控制神器:3分钟掌握WindowResizer的终极窗口调整技巧 【免费下载链接】WindowResizer 一个可以强制调整应用程序窗口大小的工具 项目地址: https://gitcode.com/gh_mirrors/wi/WindowResizer 还在为那些顽固的应用程序窗口而束手无策吗?是…...

轻量级HTTP代理monica-proxy:精准流量转发与多场景部署指南
1. 项目概述与核心价值最近在折腾一些需要跨网络环境访问特定服务的项目,发现一个挺有意思的工具叫ycvk/monica-proxy。这本质上是一个基于 Go 语言开发的轻量级 HTTP/HTTPS 代理服务器,但它和我们常见的那些“全能型”代理不太一样。它的设计初衷非常聚…...

基于MCP协议构建AI金融数据可视化服务器:从原理到实战部署
1. 项目概述:一个为AI智能体提供实时金融数据可视化的MCP服务器最近在折腾AI智能体(Agent)的生态,发现一个挺有意思的痛点:当你想让AI帮你分析股票、基金或者加密货币时,它往往只能给你干巴巴的数字和文字描…...