使用GPT-4生成训练数据微调GPT-3.5 RAG管道
OpenAI在2023年8月22日宣布,现在可以对GPT-3.5 Turbo进行微调了。也就是说,我们可以自定义自己的模型了。然后LlamaIndex就发布了0.8.7版本,集成了微调OpenAI gpt-3.5 turbo的功能
也就是说,我们现在可以使用GPT-4生成训练数据,然后用更便宜的API(gpt-3.5 turbo)来进行微调,从而获得更准确的模型,并且更便宜。所以在本文中,我们将使用NVIDIA的2022年SEC 10-K文件来仔细研究LlamaIndex中的这个新功能。并且将比较gpt-3.5 turbo和其他模型的性能。
RAG vs 微调
微调到底是什么?它和RAG有什么不同?什么时候应该使用RAG和微调?以下两张总结图:

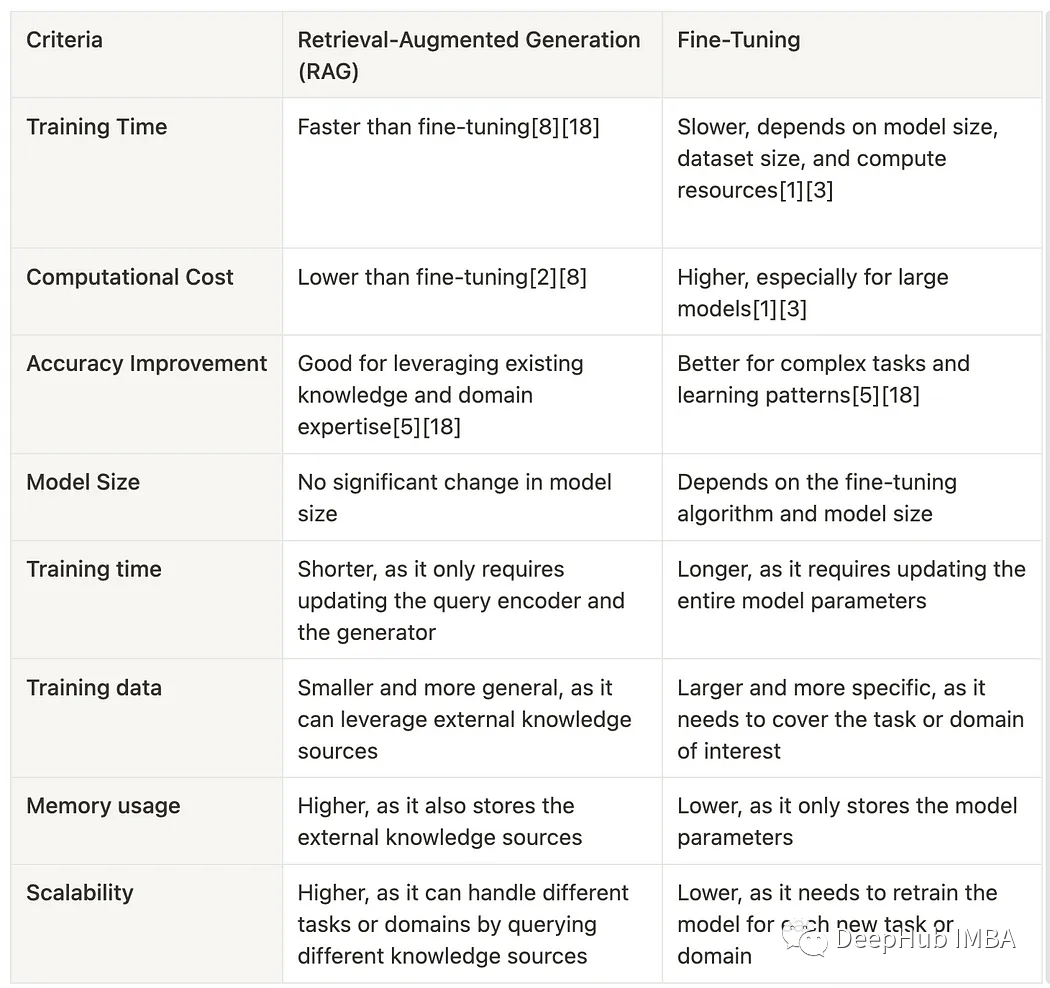
这两个图像总结了它们基本的差别,为我们选择正确的工具提供了很好的指导。
但是,RAG和微调并不相互排斥。将两者以混合方式应用到同一个应用程序中是完全可行的。
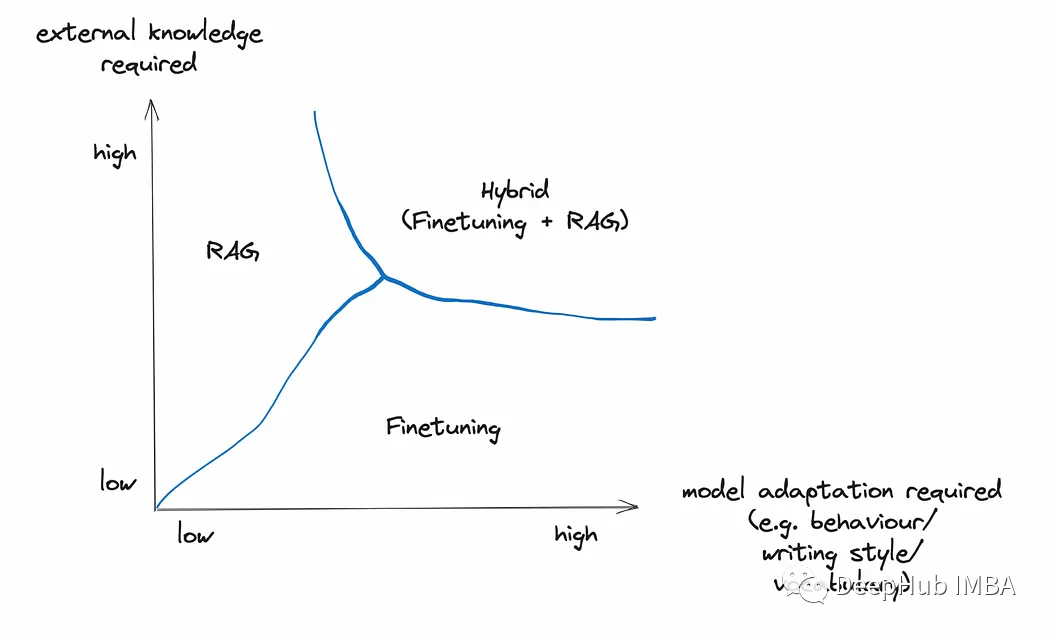
RAG/微调混合方法
LlamaIndex提供了在RAG管道中微调OpenAI gpt-3.5 turbo的详细指南。从较高的层次来看,微调可以实现下图中描述的关键任务:
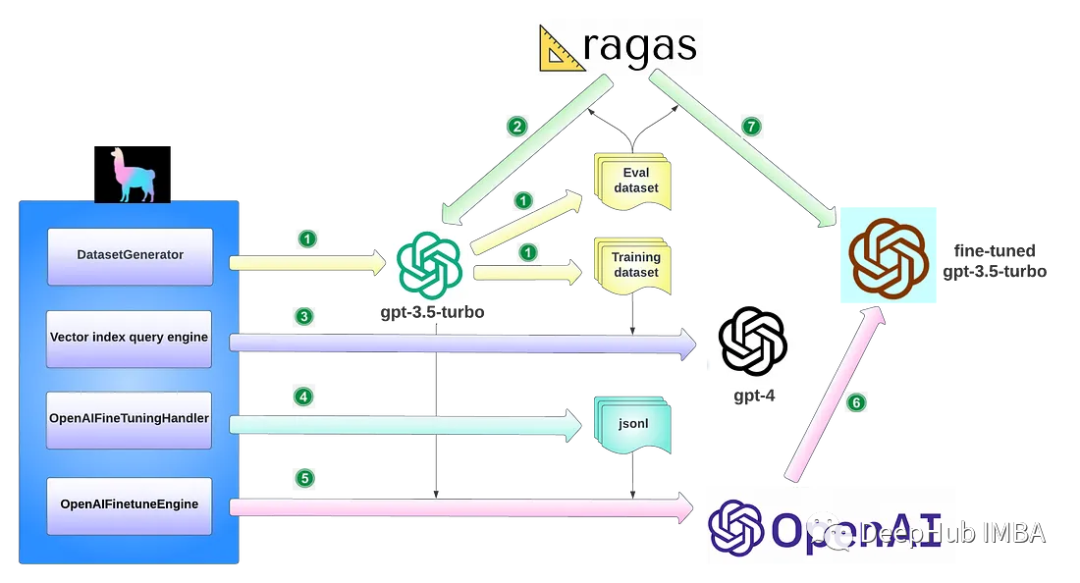
- 使用DatasetGenerator实现评估数据集和训练数据集的数据生成自动化。
- 在微调之前,使用第1步生成的Eval数据集对基本模型gpt-3.5-turbo进行Eval。
- 构建向量索引查询引擎,调用gpt-4根据训练数据集生成新的训练数据。
- 回调处理程序OpenAIFineTuningHandler收集发送到gpt-4的所有消息及其响应,并将这些消息保存为.jsonl (jsonline)格式,OpenAI API端点可以使用该格式进行微调。
- OpenAIFinetuneEngine是通过传入gpt-3.5-turbo和第4步生成的json文件来构造的,它向OpenAI发送一个微调调用,向OpenAI发起一个微调作业请求。
- OpenAI根据您的要求创建微调的gpt-3.5-turbo模型。
- 通过使用从第1步生成的Eval数据集来对模型进行微调。
简单的总结来说就是,这种集成使gpt-3.5 turbo能够对gpt-4训练的数据进行微调,并输出更好的响应。
步骤2和7是可选的,因为它们仅仅是评估基本模型与微调模型的性能。
我们下面将演示这个过程,在演示时,使用NVIDIA 2022年的SEC 10-K文件。
主要功能点
1、OpenAIFineTuningHandler
这是OpenAI微调的回调处理程序,用于收集发送到gpt-4的所有训练数据,以及它们的响应。将这些消息保存为.jsonl (jsonline)格式,OpenAI的API端点可以使用该格式进行微调。
2、OpenAIFinetuneEngine
微调集成的核心是OpenAIFinetuneEngine,它负责启动微调作业并获得一个微调模型,可以直接将其插件到LlamaIndex工作流程的其余部分。
使用OpenAIFinetuneEngine, LlamaIndex抽象了OpenAI api进行微调的所有实现细节。包括:
- 准备微调数据并将其转换为json格式。
- 使用OpenAI的文件上传微调数据。创建端点并从响应中获取文件id。
- 通过调用OpenAI的FineTuningJob创建一个新的微调作业。创建端点。
- 等待创建新的微调模型,然后使用新的微调模型。
我们可以使用OpenAIFinetuneEngine的gpt-4和OpenAIFineTuningHandler来收集我们想要训练的数据,也就是说我们使用gpt-4的输出来训练我们的自定义的gpt-3.5 turbo模型
from llama_index import ServiceContextfrom llama_index.llms import OpenAIfrom llama_index.callbacks import OpenAIFineTuningHandlerfrom llama_index.callbacks import CallbackManager# use GPT-4 and the OpenAIFineTuningHandler to collect data that we want to train on.finetuning_handler = OpenAIFineTuningHandler()callback_manager = CallbackManager([finetuning_handler])gpt_4_context = ServiceContext.from_defaults(llm=OpenAI(model="gpt-4", temperature=0.3),context_window=2048, # limit the context window artifically to test refine processcallback_manager=callback_manager,)# load the training questions, auto generated by DatasetGeneratorquestions = []with open("train_questions.txt", "r") as f:for line in f:questions.append(line.strip())from llama_index import VectorStoreIndex# create index, query engine, and run query for all questionsindex = VectorStoreIndex.from_documents(documents, service_context=gpt_4_context)query_engine = index.as_query_engine(similarity_top_k=2)for question in questions:response = query_engine.query(question)# save fine-tuning events to jsonl filefinetuning_handler.save_finetuning_events("finetuning_events.jsonl")from llama_index.finetuning import OpenAIFinetuneEngine# construct OpenAIFinetuneEngine finetune_engine = OpenAIFinetuneEngine("gpt-3.5-turbo","finetuning_events.jsonl")# call finetune, which calls OpenAI API to fine-tune gpt-3.5-turbo based on training data in jsonl file.finetune_engine.finetune()# check current job statusfinetune_engine.get_current_job()# get fine-tuned modelft_llm = finetune_engine.get_finetuned_model(temperature=0.3)
需要注意的是,微调函数需要时间,对于我测试的169页PDF文档,从在finetune_engine上启动finetune到收到OpenAI的电子邮件通知我新的微调工作已经完成,这段时间大约花了10分钟。下面的电子邮件如下。

在收到该电子邮件之前,如果在finetune_engine上运行get_finetuned_model,会得到一个错误,提示微调作业还没有准备好。
3、ragas框架
ragas是RAG Assessment的缩写,它提供了基于最新研究的工具,使我们能够深入了解RAG管道。
ragas根据不同的维度来衡量管道的表现:忠实度、答案相关性、上下文相关性、上下文召回等。对于这个演示应用程序,我们将专注于衡量忠实度和答案相关性。
忠实度:衡量给定上下文下生成的答案的信息一致性。如果答案中有任何不能从上下文推断出来的主张,则会被扣分。
答案相关性:指回答直接针对给定问题或上下文的程度。这并不考虑答案的真实性,而是惩罚给出问题的冗余信息或不完整答案。
在RAG管道中应用ragas的详细步骤如下:
- 收集一组eval问题(最少20个,在我们的例子中是40个)来形成我们的测试数据集。
- 在微调之前和之后使用测试数据集运行管道。每次使用上下文和生成的输出记录提示。
- 对它们中的每一个运行ragas评估以生成评估分数。
- 比较分数就可以知道微调对性能的影响有多大。
代码如下:
contexts = []answers = []# loop through the questions, run query for each questionfor question in questions:response = query_engine.query(question)contexts.append([x.node.get_content() for x in response.source_nodes])answers.append(str(response))from datasets import Datasetfrom ragas import evaluatefrom ragas.metrics import answer_relevancy, faithfulnessds = Dataset.from_dict({"question": questions,"answer": answers,"contexts": contexts,})# call ragas evaluate by passing in dataset, and eval categoriesresult = evaluate(ds, [answer_relevancy, faithfulness])print(result)import pandas as pd# print result in pandas dataframe so we can examine the question, answer, context, and ragas metricspd.set_option('display.max_colwidth', 200)result.to_pandas()
评估结果
最后我们可以比较一下微调前后的eval结果。
基本gpt-3.5-turbo的评估请看下面的截图。answer_relevance的评分不错,但忠实度有点低。
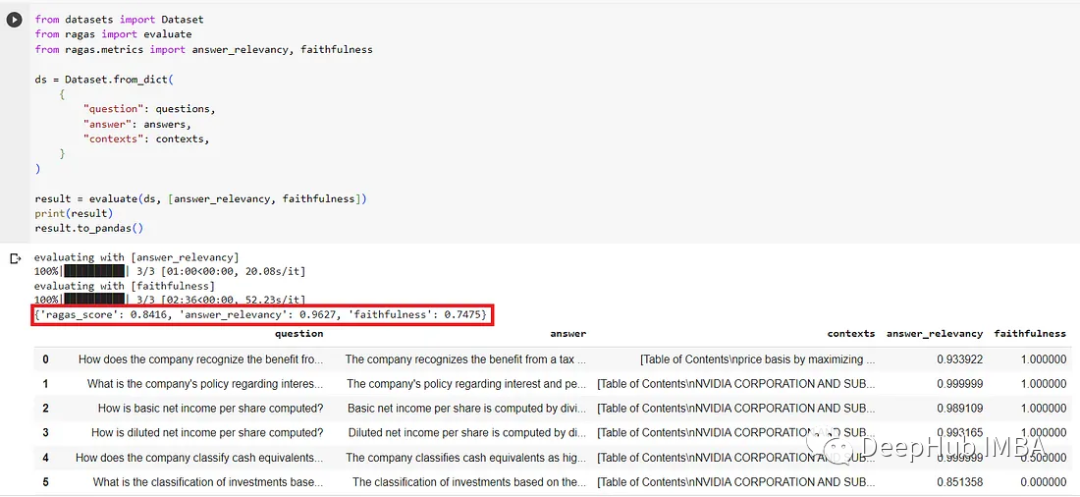
经过微调,模型的性能在答案相关性中略有提高,从0.7475提高到0.7846,提高了4.96%。
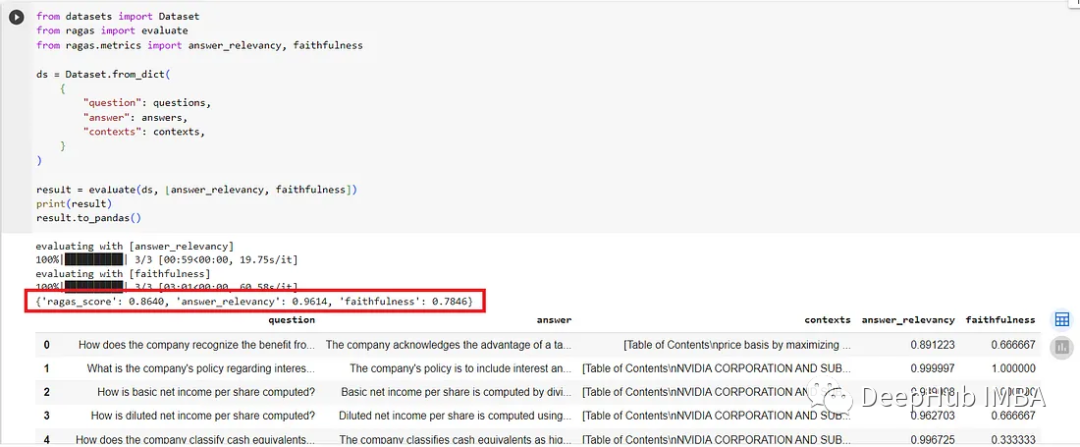
使用gpt-4生成训练数据对gpt-3.5 turbo进行微调确实看到了改善。
一些有趣的发现
1、对小文档进行微调会导致性能下降
最初用一个小的10页PDF文件进行了实验,我发现eval结果与基本模型相比性能有所下降。然后又继续测试了两轮,结果如下:
第一轮基本模型:Ragas_score: 0.9122, answer_relevance: 0.9601, faithfulness: 0.8688
第一轮微调模型:Ragas_score: 0.8611, answer_relevance: 0.9380, faithfulness: 0.7958
第二轮基本模型:Ragas_score: 0.9170, answer_relevance: 0.9614, faithfulness: 0.8765
第二轮微调模型:Ragas_score: 0.8891, answer_relevance: 0.9557, faithfulness: 0.8313
所以换衣小文件可能是微调模型比基本模型表现更差的原因。所以使用了NVIDIA长达169页的SEC 10-K文件。对上面的结果做了一个很好的实验——经过微调的模型表现得更好,忠实度增加了4.96%。
2、微调模型的结果不一致
原因可能是数据的大小和评估问题的质量
尽管169页文档的微调模型获得了预期的评估结果,但我对相同的评估问题和相同的文档运行了第二轮测试,结果如下:
第二轮基本模型:Ragas_score: 0.8874, answer_relevance: 0.9623, faithfulness: 0.8233
第二轮微调模型:Ragas_score: 0.8218, answer_relevance: 0.9498, faithfulness: 0.7242
是什么导致了eval结果的不一致?
数据大小很可能是导致不一致的微调计算结果的根本原因之一。“至少需要1000个微调数据集的样本。”这个演示应用显然没有那么多的微调数据集。
另一个根本原因很可能在于数据质量,也就是eval问题的质量。我将eval结果打印到一个df中,列出了每个问题的问题、答案、上下文、answer_relevance和忠实度。
通过目测,有四个问题在忠实度中得分为0。而这些答案在文件中没有提供上下文。这四个问题质量很差,所以我从eval_questions.txt中删除了它们,重新运行了评估,得到了更好的结果:
基本模型eval:Ragas_score: 0.8947, answer_relevance: 0.9627, faithfulness: 0.8356

微调模型eval:Ragas_score: 0.9207, answer_relevance: 0.9596, faithfulness: 0.8847

可以看到在解决了这四个质量差的问题后,微调版的上升了5.9%。所以评估问题和训练数据需要更多的调整,以确保良好的数据质量。这确实是一个非常有趣的探索领域。
3、微调的成本
经过微调的gpt-3.5-turbo的价格高于基本模型的。我们来看看基本模型、微调模型和gpt-4之间的成本差异:
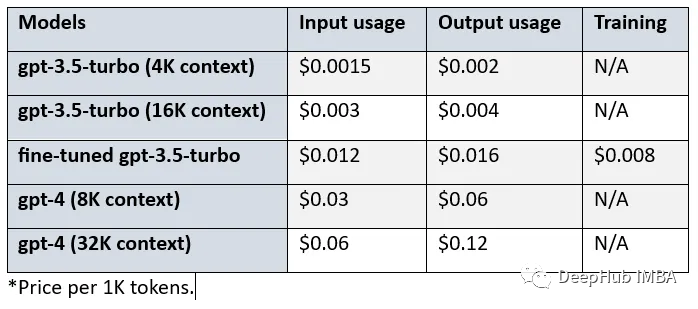
比较gpt-3.5-turbo (4K环境)、微调gpt-3.5-turbo和gpt-4 (8K环境),可以看到:
- 经过微调的gpt-3.5 turbo在输入和输出使用方面的成本是基本模型的8倍。
- 对于输入使用,Gpt-4的成本是微调模型的2.5倍,对于输出使用则是3.75倍。
- 对于输入使用,Gpt-4的成本是基本模型的20倍,对于输出使用情况是30倍。
- 另外使用微调模型会产生$0.008/1K 令牌的额外成本。
总结
本文探索了LlamaIndex对OpenAI gpt-3.5 turbo微调的新集成。我们通过NVIDIA SEC 10-K归档分析的RAG管道,测试基本模型性能,然后使用gpt-4收集训练数据,创建OpenAIFinetuneEngine,创建了一个新的微调模型,测试了它的性能,并将其与基本模型进行了比较。
可以看到,因为GPT4和gpt-3.5 turbo的巨大成本差异(20倍),在使用微调后,我们可以得到近似的效果,并且还能节省不少成本(2.5倍)
如果你对这个方法感兴趣,源代码在这里:
https://avoid.overfit.cn/post/0a4ae4d87e69457dbd899d7a9af07237
作者:Wenqi Glantz
相关文章:
使用GPT-4生成训练数据微调GPT-3.5 RAG管道
OpenAI在2023年8月22日宣布,现在可以对GPT-3.5 Turbo进行微调了。也就是说,我们可以自定义自己的模型了。然后LlamaIndex就发布了0.8.7版本,集成了微调OpenAI gpt-3.5 turbo的功能 也就是说,我们现在可以使用GPT-4生成训练数据&a…...

RUST 每日一省:模式匹配
我们经常使用let 语句创建新的变量绑定——但是 let 的功能并不仅限于此。事实上, let 语句是一个模式匹配语句。它允许我们根据内部结构对值进行操作和判断,或者可以用于从代数数据类型中提取值。 let tuple (1_i32, false, 3f32); let (head, center…...

利用Jmeter做接口测试(功能测试)全流程分析
利用Jmeter做接口测试怎么做呢?过程真的是超级简单。 明白了原理以后,把零碎的知识点填充进去就可以了。所以在学习的过程中,不管学什么,我一直都强调的是要循序渐进,和明白原理和逻辑。这篇文章就来介绍一下如何利用…...
依赖导入失败场景和解决方案
在使用 Maven 构建项目时,可能会发生依赖项下载错误的情况,主要原因有以下几种: 下载依赖时出现网络故障或仓库服务器宕机等原因,导致无法连接至 Maven 仓库,从而无法下载依赖。 依赖项的版本号或配置文件中的版本号错…...

DiffBIR: Towards Blind Image Restoration with Generative Diffusion Prior
DiffBIR: 基于生成扩散先验的盲图像恢复 论文链接:https://arxiv.org/abs/2308.15070 项目链接:https://github.com/XPixelGroup/DiffBIR Abstract 我们提出了DiffBIR,它利用预训练的文本到图像扩散模型来解决盲图像恢复问题。我们的框架采…...

pycharm如何配置 .gitignore 文件
参考:https://zongweizhou1.github.io/2019/06/16/pycharm-gitignore/ .gitignore 文件本身不需要纳入版本控制,在 .gitignore 文件中写入“.gitignore"忽略即可...
【Spring面试题】AOP相关面试题:概念?使用场景?如何使用?核心?
什么是AOP AOP是面向切面,面向切面编程,是通过预编译方式和运行期动态代理实现程序功能的统一维护的一种技术。对多个对象共同行为封装成一个模块叫切面,然后某个方法为切点。 通俗的讲:就是在一些代码中做重复操作的时候,我们为了…...

Yolov5的tensorRT加速(python)
地址:https://github.com/wang-xinyu/tensorrtx/tree/master/yolov5 下载yolov5代码 方法一:使用torch2trt 安装torch2trt与tensorRT 参考博客:https://blog.csdn.net/dou3516/article/details/124538557 先从github拉取torch2trt源码 ht…...
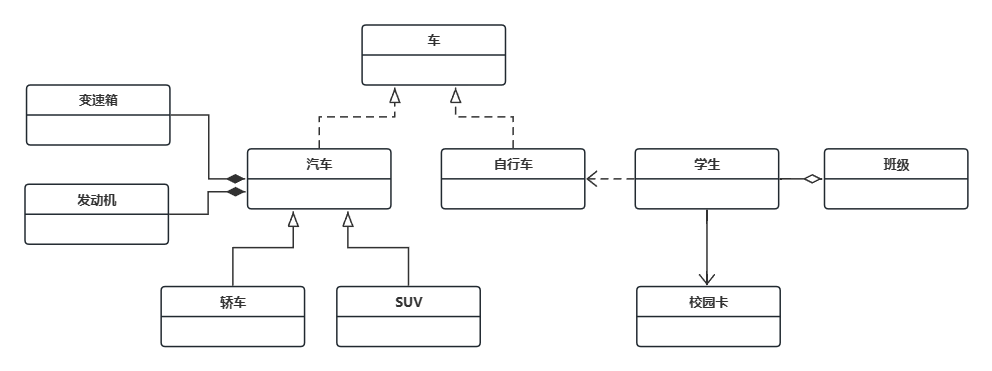
设计模式(1) - UML类图
1、前言 最近在阅读 Android 源码,时常碰到代码中有一些巧妙的写法,简单的如 MediaPlayerService 中的 IFactory,我知道它是工厂模式,但是却不十分清楚它为什么这么用;复杂点的像 NuPlayer 中的 DeferredActions 机制…...
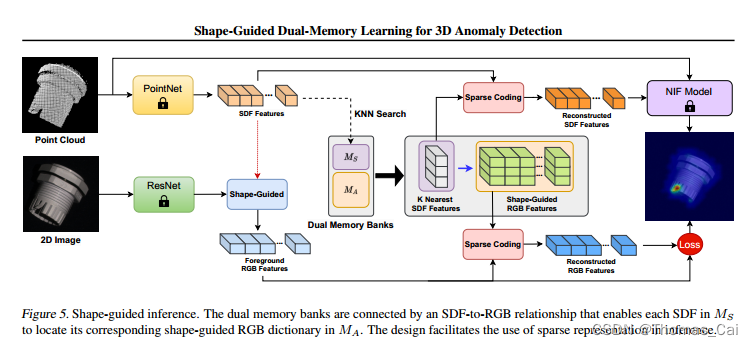
3D异常检测论文笔记 | Shape-Guided Dual-Memory Learning for 3D Anomaly Detection
文章目录 摘要一、介绍三、方法3.1. 形状引导专家学习3.2. Shape-Guided推理 摘要 我们提出了一个形状引导的专家学习框架来解决无监督的三维异常检测问题。我们的方法是建立在两个专门的专家模型的有效性和他们的协同从颜色和形状模态定位异常区域。第一个专家利用几何信息通…...
如何将枯燥的大数据进行可视化处理?
在数字时代,大数据已经成为商业、科学、政府和日常生活中不可或缺的一部分。然而,大数据本身往往是枯燥的、难以理解的数字和文字,如果没有有效的方式将其可视化,就会错失其中的宝贵信息。以下是一些方法,可以将枯燥的…...

linux bash中 test命令详解
test命令用于检查某个条件是否成立。它可以进行数值、字符和文件三方面的测试。 1、数值测试 -eq 等于-ne 不等于-gt 大于-ge 大于或等于-lt 小于-le 小于或等于 例如,我们可以测试两个变量是否相等: num1100 num2200 if test $num1 -eq $num2 thene…...

获取当前时间并转换为想要的格式
转换为YYYY-MM-DD格式 function getCurrentDate() {var today new Date();var year today.getFullYear();var month today.getMonth() 1; // 月份从0开始,需要加1var day today.getDate();return year - (month < 10 ? (0 month) : month) - (day &…...

如何实现自动化测试?
一、首先我们要清楚自动化测试的分类 以实现方式可分为UI自动化和接口自动化。UI自动化可用selenium等工具实现,接口自动化可用使用RobotFramework和Jmeter等工具实现,Jmeter也可做性能自动化,压力测试。 二、平时自动化测试怎么做 1. UI和…...

c++中的对齐问题
c中的对齐问题 需要对齐的原因 尽管内存是以字节为单位,但是大部分处理器并不是按字节块来存取内存的.它一般会以双字节,四字节,8字节,16字节甚至32字节为单位来存取内存,我们将上述这些存取单位称为内存存取粒度. 现在考虑4字节存取粒度的处理器取in…...
算法_C++—— 存在重复元素)
力扣(LeetCode)算法_C++—— 存在重复元素
给你一个整数数组 nums 。如果任一值在数组中出现 至少两次 ,返回 true ;如果数组中每个元素互不相同,返回 false 。 示例 1: 输入:nums [1,2,3,1] 输出:true 示例 2: 输入:nums …...
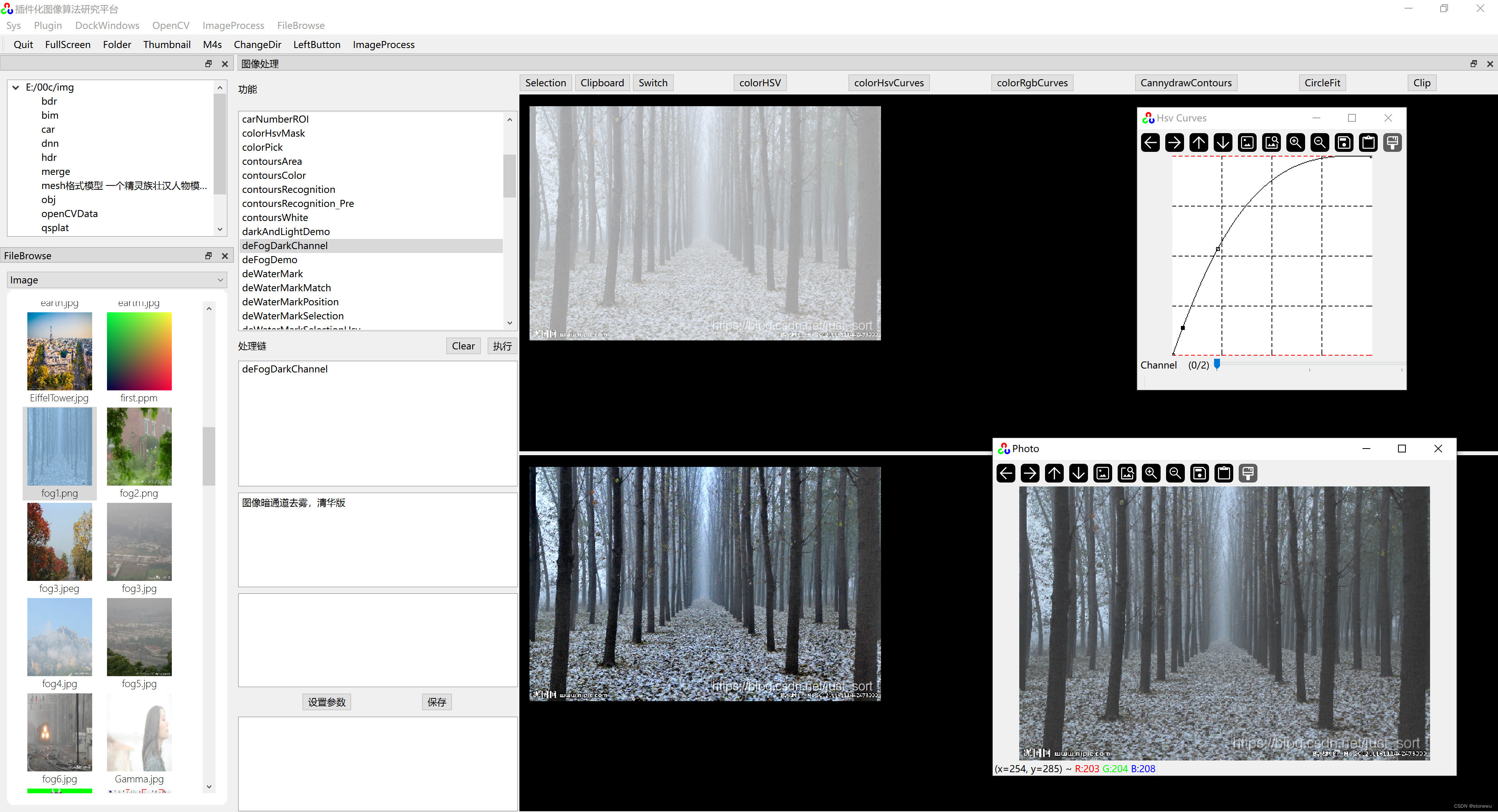
OpenCV实现Photoshop曲线调整
《QT 插件化图像算法研究平台》有仿Photoshop曲线调整图像的功能,包括RGB曲线调整和HSV曲线调整。 Photoshop曲线调整原理:RGB、HSV各通道曲线,可以理解为一个值映射(值转换)函数。X轴是输入,Y轴是输出。x0…...

【探索Linux】—— 强大的命令行工具 P.8(进程优先级、环境变量)
阅读导航 前言一、进程优先级1. 优先级概念2. Linux查看系统进程3. PRI(Priority)和NI(Nice) 二、环境变量1. 概念2. 查看环境变量方法3. 环境变量的组织方式4.通过代码获取环境变量5. 环境变量的特点 总结温馨提示 前言 前面我们…...
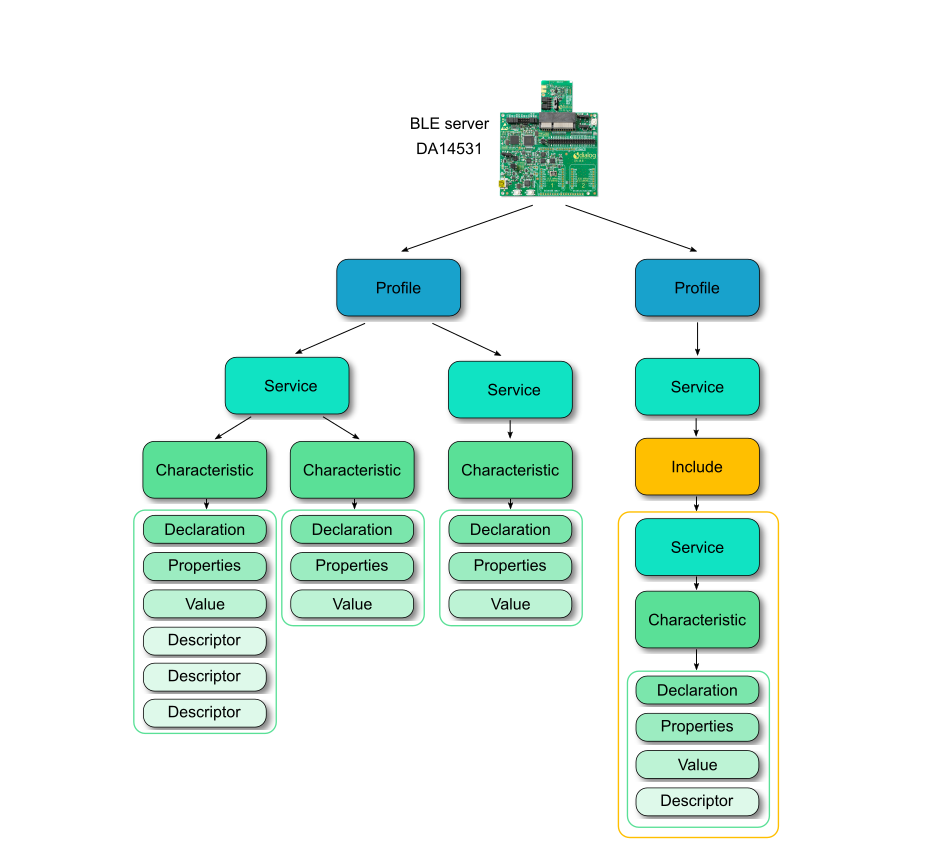
蓝牙协议栈BLE
前言 这阵子用到蓝牙比较多,想写一个专栏专门讲解蓝牙协议及其应用,本篇是第一篇文章,讲解低功耗蓝牙和蓝牙协议栈。 参考网上各大神文章,及瑞萨的文章,参考GPT,并且加入了一些本人的理解。 图片部分源自…...
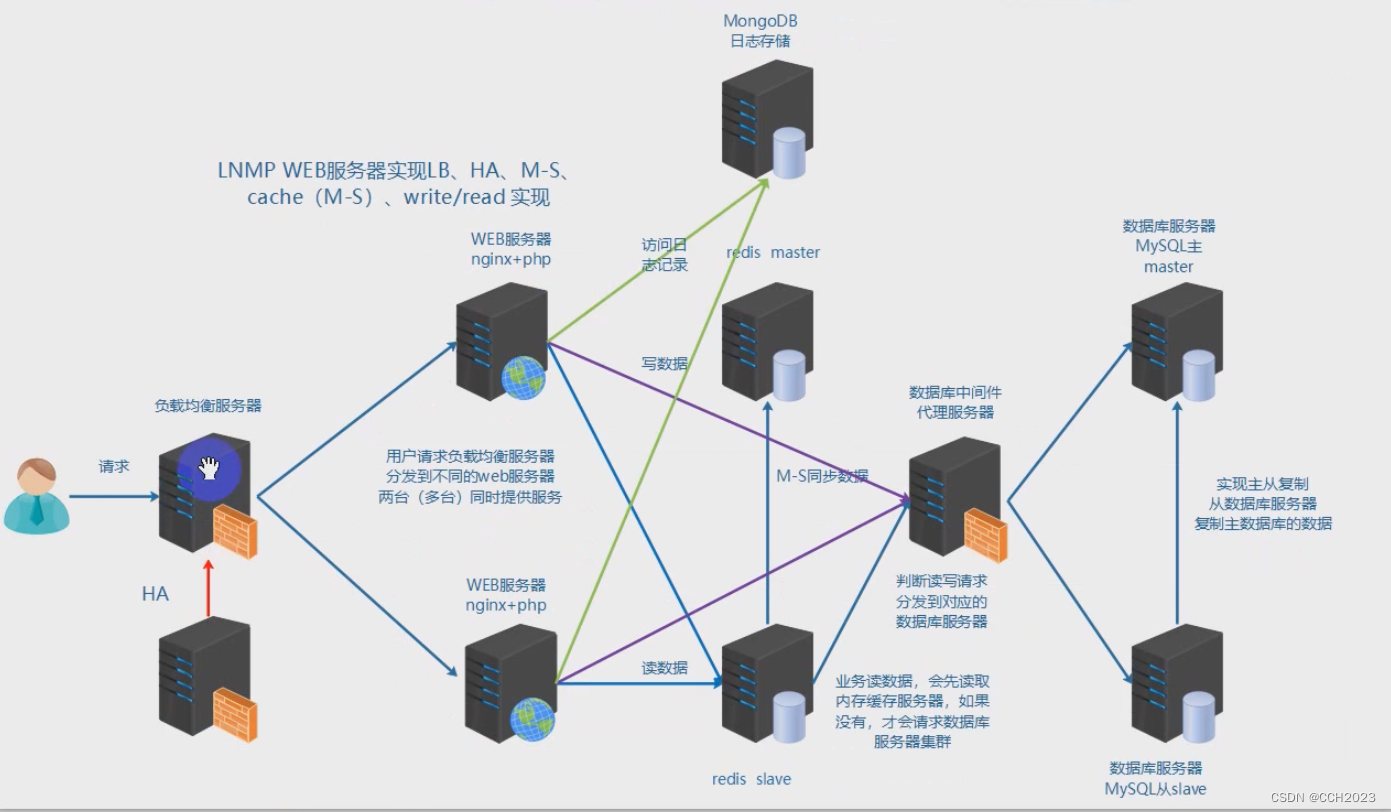
企业架构LNMP学习笔记17
反向代理: 反向代理服务器和真实访问的服务器是在一起的,有关联的。 根据实际业务需求,分发代理页面到不同的解释器。常见于代理后端服务器。 安装apache服务器: yum install -y httpd 修改配置文件: vim /et/http…...

告别showSoftInput失效:一文读懂Android 11+的WindowInsetsController输入法控制
Android输入法控制演进:从InputMethodManager到WindowInsetsController的深度解析 在移动应用开发中,输入法交互是最基础却又最容易被忽视的细节之一。许多开发者都曾遇到过这样的场景:精心设计的登录界面,光标在输入框闪烁&#…...

芯片老化座的工作温度范围?
在芯片测试领域,老化座(Burn-in Socket)是保障半导体器件长期可靠性的关键设备。它不仅要在极端温度下稳定工作,还要确保测试数据的精准度。今天,我们以HMILU(深圳市鸿怡电子有限公司)为例&…...

移动端AI助手开发实战:混合架构、模型部署与性能优化
1. 项目概述:一个移动端AI助手的诞生 最近在移动端AI应用开发圈子里,一个名为 copaw-mobile 的项目开始引起不少同行的注意。这个由 xmingai 团队开源的项目,定位非常清晰——它要做的,就是将一个功能强大的AI助手,…...

CompressO:终极跨平台视频图片压缩神器,轻松解决存储难题
CompressO:终极跨平台视频图片压缩神器,轻松解决存储难题 【免费下载链接】compressO Convert any video/image into a tiny size. 100% free & open-source. Available for Mac, Windows & Linux. 项目地址: https://gitcode.com/gh_mirrors/…...

Helm-Intellisense:VS Code智能补全插件,提升values.yaml编写效率
1. 项目概述:为什么我们需要一个Helm智能补全工具?如果你和我一样,日常工作中大量使用Helm来管理Kubernetes应用,那你一定对编写values.yaml文件时那种“盲人摸象”的感觉深有体会。面对一个动辄几十上百行配置的Helm Chart&#…...
)
别再手动调色了!用Matlab bar3函数一键生成论文级渐变三维柱状图(附完整代码)
别再手动调色了!用Matlab bar3函数一键生成论文级渐变三维柱状图(附完整代码) 科研图表的美观程度直接影响论文的第一印象,而三维柱状图在展示多维度数据时尤为常见。传统手动调整每个柱体的颜色、透明度、光照效果不仅耗时&#…...

结构化数字工作空间:提升创意工作效率的目录设计与自动化实践
1. 项目概述:一个为创意工作者量身定制的数字工作空间 如果你是一名设计师、开发者、内容创作者,或者任何需要处理大量数字资产、管理复杂项目流程的创意工作者,那么“Workspace-di-Yivo”这个名字可能会让你眼前一亮。这不仅仅是一个简单的文…...
基于CircuitPython与NeoPixel打造可编程LED亚克力灯牌:从硬件选型到代码实现
1. 项目概述:打造你的专属可编程光之铭牌在创客和电子爱好者的世界里,总有一些项目能完美地融合软件编程的灵活性与硬件制作的实体成就感。今天要分享的,就是这样一个让我爱不释手的小玩意儿:一个基于CircuitPython和NeoPixel的可…...

g1810,g3810,ip2700,g5080,g1800,ts3380,TS8380,ts6480报错5B00,P07,E08,5b02,1704,1700,5b04,佳能v6.200,亲测有用。
下载:点这里下载 备用下载:https://pan.baidu.com/s/1WrPFvdV8sq-qI3_NgO2EvA?pwd0000 常见型号如下: G系列 G1000、G1100、G1200、G1400、G1500、G1800、G1900、G1010、G1110、G1120、G1410、G1420、G1411、G1510、G1520、G1810、G1820、…...

Bun用Rust重写核心代码,百万行新增代码直接把GitHub干爆了!
Bun 项目刚刚完成了一次惊人的技术跨越。5月14日,Bun 正式宣布其核心运行时已从 Zig 重写为 Rust——这个版本包含 6755 个 commit,二进制文件体积缩小 3-8 MB,性能测试在各个平台上均达到或超越原有水平。Jarred Sumner(Bun 的创…...