机器学习的特征工程
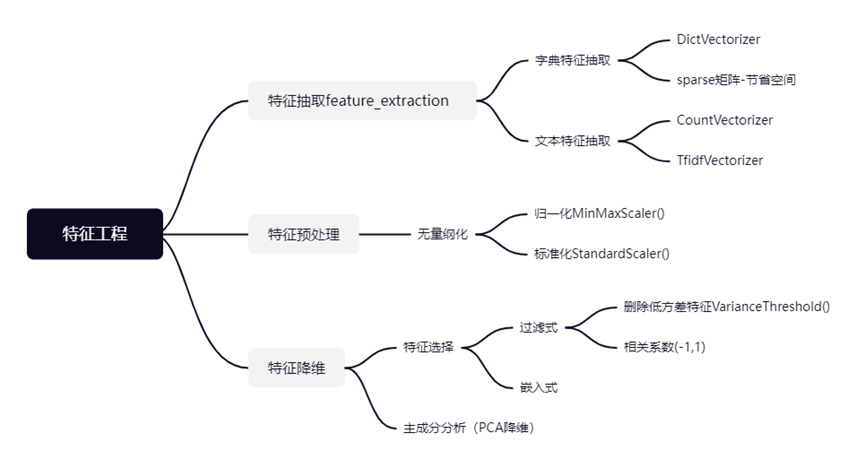
字典特征提取
def dict_demo():"""字典特征提取:return:"""data = [{'city': '北京', 'temperature': 100}, {'city': '上海', 'temperature': 60}, {'city': '深圳', 'temperature': 30}]# data = [{'city':['北京','上海','深圳']},{'temperature':["100","60","30"]}]from sklearn.feature_extraction import DictVectorizer# 1、实例化一个转换器类transfer = DictVectorizer(sparse=False) # sparse=False表示不用稀疏矩阵存储,稀疏矩阵存储的好处是节省内存,但是不方便观察,所以一般不用# 2、调用fit_transformdata_new = transfer.fit_transform(data)print(f'转换后的数据:{data_new}')print(f'特征名字:{transfer.get_feature_names_out()}') # ['city=上海' 'city=北京' 'city=深圳' 'temperature']return None结果显示
注意:如果特征中存在非数值类型数据,需要转换成字典然后使用one-hot编码
文本特征提取
def text_demo():"""文本特征提取:return:"""data = ["life is short,i like python","life is too long,i dislike python"]from sklearn.feature_extraction.text import CountVectorizer# 1、实例化一个转换器类transfer = CountVectorizer()# 2、调用fit_transformdata_new = transfer.fit_transform(data)print(f'转换后的数据:{data_new.toarray()}') # toarray()将稀疏矩阵转换成数组print(f'特征名字:{transfer.get_feature_names_out()}')return None结果显示

中文文本特征抽取
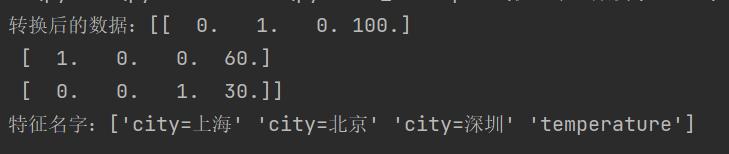
def chinese_demo():"""中文文本特征抽取:return:"""data = ["我 爱 北京 天安门","天安门 上 太阳 升"]from sklearn.feature_extraction.text import CountVectorizer# 1、实例化一个转换器类transfer = CountVectorizer(stop_words=[]) # stop_words表示停用词,不需要的词# 2、调用fit_transformdata_new = transfer.fit_transform(data)print(f'转换后的数据:{data_new.toarray()}') # toarray()将稀疏矩阵转换成数组print(f'特征名字:{transfer.get_feature_names_out()}')return None结果
中文文本抽取,自动分词
# 分词函数
import jieba
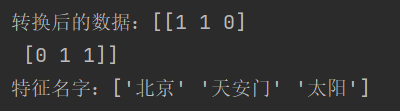
def cut_word(text):text = " ".join(list(jieba.cut(text)))return textdef chinese_demo2():"""中文文本特征抽取,自动分词:return:"""data = ["今天很残酷,明天更残酷,后天很美好,但绝对大多数是死在明天晚上,所以每个人不要放弃今天。","我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。","如果只用了一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相关联。"]# 1、分词data_new = []for sent in data:data_new.append(cut_word(sent))# print(data_new)# 2、特征抽取from sklearn.feature_extraction.text import CountVectorizer# 1、实例化一个转换器类transfer = CountVectorizer(stop_words=[]) # stop_words表示停用词,不需要的词# 2、调用fit_transformdata_final = transfer.fit_transform(data_new)print(f'转换后的数据:{data_final.toarray()}') # toarray()将稀疏矩阵转换成数组print(f'特征名字:{transfer.get_feature_names_out()}')结果

TF-IDF特征抽取
def tf_idf_demo():"""tf-idf特征抽取:return:"""data = ["今天很残酷,明天更残酷,后天很美好,但绝对大多数是死在明天晚上,所以每个人不要放弃今天。","我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。","如果只用了一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相关联。"]# 1、分词data_new = []for sent in data:data_new.append(cut_word(sent))# print(data_new)# 2、特征抽取from sklearn.feature_extraction.text import TfidfVectorizer# 1、实例化一个转换器类transfer = TfidfVectorizer(stop_words=[]) # stop_words表示停用词,不需要的词# 2、调用fit_transformdata_final = transfer.fit_transform(data_new)print(f'转换后的数据:{data_final.toarray()}') # toarray()将稀疏矩阵转换成数组print(f'特征名字:{transfer.get_feature_names_out()}')结果
归一化
data.txt
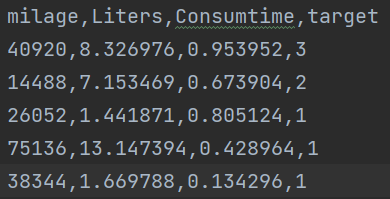
def guiyi_demo():"""归一化:return:"""import pandas as pd# 读取数据data = pd.read_csv("./data.txt")# print(data)data = data.iloc[:,:3]# print(data)# 归一化(针对特征值)from sklearn.preprocessing import MinMaxScaler# 1、实例化一个转换器类transfer = MinMaxScaler(feature_range=(0,1)) # feature_range表示归一化的范围# 2、调用fit_transformdata_new = transfer.fit_transform(data)print(f'转换后的数据:{data_new}')结果
标准化
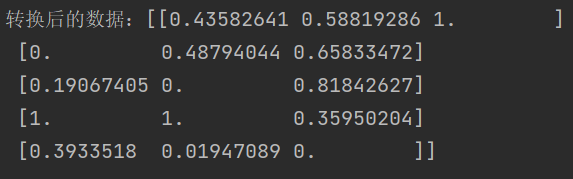
def biaozhun_demo():"""标准化:return:"""import pandas as pddata = pd.read_csv("./data.txt")data = data.iloc[:,:3]# 标准化from sklearn.preprocessing import StandardScaler# 1、实例化一个转换器类transfer = StandardScaler()# 2、调用fit_transformdata_new = transfer.fit_transform(data)print(f'转换后的数据:{data_new}')结果

低方差特征过滤
def varis_demo():"""过滤低方差特征:return:"""import pandas as pddata = pd.read_csv("./data.txt")data = data.iloc[:,1:-2]# 过滤低方差特征from sklearn.feature_selection import VarianceThreshold# 1、实例化一个转换器类transfer = VarianceThreshold(threshold=0.0) # threshold表示方差的阈值# 2、调用fit_transformdata_new = transfer.fit_transform(data)print(f'转换后的数据:{data_new}')结果
相关系数法
def xiangguan_demo():"""相关系数法:return:"""import pandas as pddata = pd.read_csv("./data.txt")data = data.iloc[:,1:-2]# 相关系数法,皮尔逊相关系数from scipy.stats import pearsonr# 1、实例化一个转换器类r = pearsonr(data['pe_ratio'],data['pb_ratio'])# 2、求出相关系数print(f'皮尔逊相关系数:{r}')# 处理方法# 1、选取其中一个特征# 2、加权求和# 3、主成分分析主成分分析
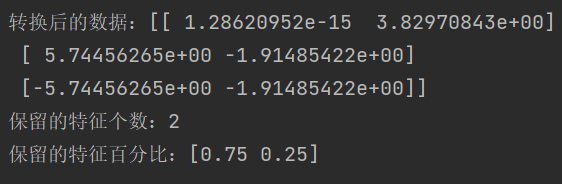
def pca_demo():"""主成分分析:return:"""data = [[2,8,4,5],[6,3,0,8],[5,4,9,1]]# 主成分分析from sklearn.decomposition import PCA# 1、实例化一个转换器类# transfer = PCA(n_components=0.9) # n_components表示保留多少特征信息transfer = PCA(n_components=2) # n_components表示保留的特征个数# 2、调用fit_transformdata_new = transfer.fit_transform(data)print(f'转换后的数据:{data_new}')print(f'保留的特征个数:{transfer.n_components_}')print(f'保留的特征百分比:{transfer.explained_variance_ratio_}')return None结果
综合案例分析
def instacart_demo():"""instacart案例分析:return:"""# 1、读取数据import pandas as pdorder_products = pd.read_csv('./instacart/order_products__prior.csv')orders = pd.read_csv('./instacart/orders.csv')products = pd.read_csv('./instacart/products.csv')aisles = pd.read_csv('./instacart/aisles.csv')# 2、合并aisles和products表,目的:aisles_id和products在一张表中table1 = pd.merge(aisles,products,on=['aisles_id','aisles_id'])table2 = pd.merge(table1,order_products,on=['product_id','product_id'])table3 = pd.merge(table2,orders,on=['order_id','order_id'])# 3、交叉表处理table = pd.crosstab(table3['user_id'],table3['aisle'])# 4、主成分分析from sklearn.decomposition import PCA# 1、实例化一个转换器类transfer = PCA(n_components=0.95) # n_components表示保留多少特征信息# 2、调用fit_transformdata_new = transfer.fit_transform(table)print(f'转换后的数据:{data_new}')print(f'保留的特征个数:{transfer.n_components_}')print(f'保留的特征百分比:{transfer.explained_variance_ratio_}')return None相关文章:
机器学习的特征工程
字典特征提取 def dict_demo():"""字典特征提取:return:"""data [{city: 北京, temperature: 100}, {city: 上海, temperature: 60}, {city: 深圳, temperature: 30}]# data [{city:[北京,上海,深圳]},{temperature:["100","6…...
python3 修改nacos的yaml配置
一、安装nacos库 pip install nacos-sdk-python 二、代码如下 import nacos import yaml# 连接地址 NACOS_SERVER_ADDRESSES "192.168.xx.xx" NACOS_SERVER_PORT 替换为你的端口号,如8848# 命名空间 NACOS_NAMESPACE "your_namespace"# 账…...

YOLOv8 : 数据组织
1. 数据源 首先YOLOv8是支持目标分类、检测和目标分割。当前以应用最为广泛的目标检测为例,简单说明数据相关的信息。 一般情况下,建议将数据划分成images和labels,其中images存储图像,labels存储标签文件(YOLO格式)。如果是VOC数…...

golang如何生成zip压缩文件
在Golang中,您可以使用标准库中的compress/zip包来生成ZIP压缩文件。下面是一个简单的示例代码,演示如何使用该包来创建一个ZIP文件并将文件添加到其中: package main import ( "archive/zip" "bytes" "fmt&qu…...

AntDesign技术指南:构建优雅的前端界面
引言 AntDesign是一款优秀的前端UI组件库,它提供了丰富的组件和功能,帮助我们快速构建漂亮、易用的前端界面。本篇博客将详细介绍AntDesign的使用方法和技巧,并展示完整的代码示例。无论你是初学者还是有经验的开发者,本篇博客都…...

机器人任务挖掘与智能超级自动化技术解析
本文为上海财经大学教授、安徽财经大学学术副校长何贤杰出席“会计科技Acctech应对不确定性挑战”高峰论坛时的演讲内容整理。何贤杰详细介绍了机器人任务挖掘与智能超级自动化技术的发展背景、关键技术和应用场景。 从本质来说,会计是非常适合智能化、自动化的。会…...

C#通过ModbusTcp协议读写西门子PLC中的浮点数
一、Modbus TCP通信概述 MODBUS/TCP是简单的、中立厂商的用于管理和控制自动化设备的MODBUS系列通讯协议的派生产品,显而易见,它覆盖了使用TCP/IP协议的“Intranet”和“Internet”环境中MODBUS报文的用途。协议的最通用用途是为诸如PLC,I/…...

19-springcloud(中)
一 服务注册发现 1 什么是服务治理 为什么需要服务治理 在没有进行服务治理前,服务之间的通信是通过服务间直接相互调用来实现的。 过程: 武当派直接调用峨眉派和华山派,同样,华山派直接调用武当派和峨眉派。如果系统不复杂,这样…...
Leetcode1090. 受标签影响的最大值
思路:根据值从大到小排序,然后在加的时候判断是否达到标签上限即可,一开始想用字典做,但是题目说是集合却连续出现两个8,因此使用元组SortedList进行解决 class Solution:def largestValsFromLabels(self, values: li…...
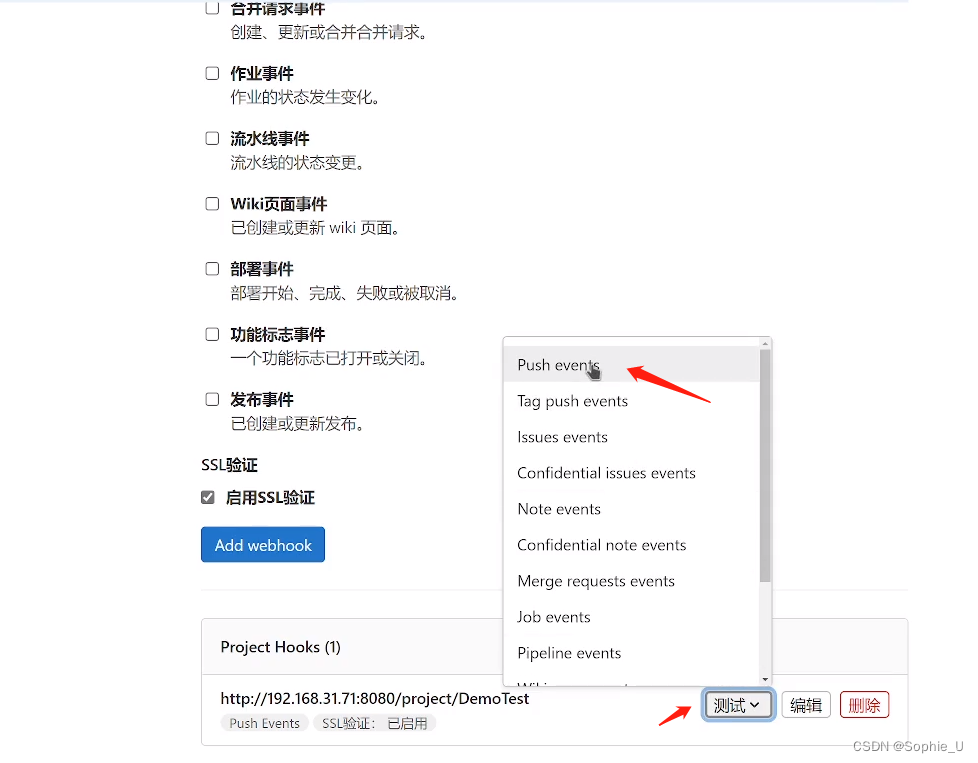
第七章:敏捷开发工具方法-part2-CI/CD工具介绍
文章目录 前言一、CI-持续集成1.1 安装部署gitlab 二、gitlab CI配置三、jenkins实现CI / CD3.1 安装jenkins3.2 配置CI3.3 配置CD3.4 其他构建方式1、定时构建2、指定参数构建3、webhook自动根据git事件进行构建 前言 什么是CI/Cd? CI-Continuous integration&…...
【自学开发之旅】Flask-回顾--对象拆分-蓝图(二)
url-统一资源定位符-不同的url对应不同的资源 作为服务端,url和视图函数的映射关系就是路由。 定义传递参数的方式: 1.创建动态url app.route("/login2/<username>/<passwd>") def login2(username, passwd):if username "…...

自动驾驶中间件
自动驾驶中间件 1. 什么是中间件2. 中间件的分类3. 自动驾驶为什么需要中间件4. 通信中间件 Reference: 自动驾驶中间件:量产落地的关键技术通俗易懂的告诉你什么是中间件 对于初入自动驾驶行业的人来说,各色各样的新型传感器、线控系统、芯…...
移植javacpp)
鲲鹏920(ARM64)移植javacpp
JavaCPP JavaCPP 使得Java 应用可以在高效的访问本地C++方法,JavaCPP底层使用了JNI技术,可以广泛的用在Java SE应用中(也包括安卓),以下两个特性是JavaCPP的关键,稍后咱们会用到: 提供一些注解,将Java代码映射为C++代码提供一个jar,用java -jar命令可以将C++代码转为…...

python打包exe实用版
pyinstaller模块用于将python项目打包成exe文件,以方便地在没有安装python环境的机器上运行。该模块使用 pip install pyinstaller 安装即可。 参数命令含义-Dpyinstaller -D demo.py默认选项。除了主程序demo.exe外,还会在在dist文件夹中生成很多依赖文…...
?解释反向代理的作用和常见应用。)
什么是反向代理(Reverse Proxy)?解释反向代理的作用和常见应用。
1、什么是反向代理(Reverse Proxy)?解释反向代理的作用和常见应用。 反向代理是一种代理服务器模型,它位于客户端和后端服务器之间。它允许将请求转发到后端服务器,并将响应返回给客户端。反向代理的主要作用如下&…...

算法通关村第十二关——不简单的字符串转换问题
前言 字符串是我们在日常开发中最常处理的数据,虽然它本身不是一种数据结构,但是由于其可以包含所有信息,所以通常作为数据的一种形式出现,由于不同语言创建和管理字符串的方式也各有差异,因此针对不同语言特征又产生…...

PROSOFT PTQ-PDPMV1网络接口模块
通信接口:PROSOFT PTQ-PDPMV1 网络接口模块通常配备了多种通信接口,以便与不同类型的设备和网络进行通信。常见的接口包括以太网、串行端口(如RS-232和RS-485)、Profibus、DeviceNet 等。 协议支持:该模块通常支持多种…...
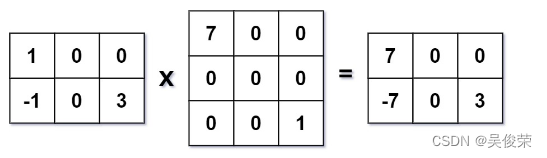
力扣(LeetCode)算法_C++——稀疏矩阵的乘法
给定两个 稀疏矩阵 :大小为 m x k 的稀疏矩阵 mat1 和大小为 k x n 的稀疏矩阵 mat2 ,返回 mat1 x mat2 的结果。你可以假设乘法总是可能的。 示例 1: 输入:mat1 [[1,0,0],[-1,0,3]], mat2 [[7,0,0],[0,0,0],[0,0,1]] 输出&am…...

华为云API人脸识别服务FRS的感知力—偷偷藏不住的你
云服务、API、SDK,调试,查看,我都行 阅读短文您可以学习到:人工智能AI人脸的识别、检测、搜索、比对 1、IntelliJ IDEA 之API插件介绍 API插件支持 VS Code IDE、IntelliJ IDEA等平台、以及华为云自研 CodeArts IDE,…...

产品技术体系
产品,是一个企业或公司针对市场客户推出的一系列相关的功能或者服务,为对应的客户解决实际问题,进而产生对应的商业、社会价值。有了这些实际的价值,企业就会获得相应的利益或者利润回报。正常来讲,这应该是一个良性的…...
)
保姆级教程:在Ubuntu 20.04上从源码编译aarch64-linux-gnu交叉工具链(GCC 9.2.0 + Glibc 2.30)
深度实践:从源码构建aarch64-linux-gnu交叉工具链全指南 在嵌入式开发领域,交叉编译工具链的构建能力是区分普通开发者与资深工程师的重要标志。当现成的预编译工具链无法满足特定需求时,从源码手动构建工具链不仅能解决兼容性问题࿰…...

避坑指南:Unity热重载插件内存占用高?可能是Windows Defender在搞鬼
Unity热重载性能优化:解决Windows Defender导致的资源占用问题 当你在Unity开发过程中频繁修改C#代码时,热重载(Hot Reload)功能无疑是提升效率的利器。它能让你在游戏运行状态下即时看到代码修改效果,避免反复重启带来的时间浪费。然而&…...

如何在3分钟内为Photoshop安装AVIF插件:让你的图片体积减半的终极方案
如何在3分钟内为Photoshop安装AVIF插件:让你的图片体积减半的终极方案 【免费下载链接】avif-format An AV1 Image (AVIF) file format plug-in for Adobe Photoshop 项目地址: https://gitcode.com/gh_mirrors/avi/avif-format 还在为网站图片加载缓慢而烦恼…...

别再让某个用户占满硬盘了!手把手教你用Linux quota给CentOS 7/8的/home目录设置磁盘限额
别再让某个用户占满硬盘了!手把手教你用Linux quota给CentOS 7/8的/home目录设置磁盘限额 想象一下这样的场景:你管理的服务器上,十几个开发人员共享着同一个存储空间。某天突然收到警报——磁盘空间不足!调查后发现,一…...

工作流编排核心原理与实践:从概念到MiniFlow系统实现
1. 项目概述:从代码仓库到工作流编排的实践最近在梳理团队内部的一些自动化流程,发现很多脚本和任务散落在各个角落,执行依赖混乱,出了问题排查起来像大海捞针。正好看到GitHub上有个叫dnh33/workflow-orchestration的项目&#x…...

g1810,g3810,ip2700,g5080,g1800,ts3380,TS8380,ts6480报错5B00,P07,E08,5b02,1704,1700,5b04,佳能v6.200,亲测有用。
下载:点这里下载 备用下载:https://pan.baidu.com/s/1WrPFvdV8sq-qI3_NgO2EvA?pwd0000 常见型号如下: G系列 G1000、G1100、G1200、G1400、G1500、G1800、G1900、G1010、G1110、G1120、G1410、G1420、G1411、G1510、G1520、G1810、G1820、…...
)
多语种出海必备,ElevenLabs菲律宾文语音质量实测对比:Wavenet vs. Instant Voice vs. Custom Model(附MOS评分表)
更多请点击: https://intelliparadigm.com 第一章:多语种出海语音技术演进与菲律宾语本地化挑战 随着全球数字服务加速出海,语音交互系统正从单语种向多语种、低资源语言深度拓展。菲律宾语(Filipino/Tagalog)作为东…...

我给了智能体$100去赚钱,结果...
你看过那些演示。一个自主智能体启动,获得一个目标,然后——跳到两周后的 Twitter 帖子——它不知怎么地就在运营一个 Shopify 店铺、写通讯和炒币了。未来已来。AGI 即将降临。买课吧。 我想找出实际发生了什么。 所以我给了一个智能体 100 美元和一个…...

DOM 浏览器
DOM 浏览器 引言 DOM(文档对象模型)是浏览器中处理HTML和XML文档的标准方式。它允许开发人员通过编程方式访问和操作网页内容。本文将详细介绍DOM的概念、其在浏览器中的运用以及相关的编程技巧。 DOM简介 什么是DOM? DOM(Document Object Model)是一种跨平台和语言独…...

告别玄学调试:用英飞凌TC37X/TC38X的DSADC做旋变软解码,这些配置坑你别再踩了
英飞凌TC37X/TC38X DSADC旋变解码实战避坑指南 从实验室到产线:那些DSADC配置中容易忽视的细节 在新能源汽车电机控制领域,旋转变压器(Resolver)作为位置传感器的主力军,其解码稳定性直接决定了矢量控制的精度。英飞凌…...