02-打包代码与依赖
打包代码与依赖说明
在开发中,我们写的应用程序通常需要依赖第三方的库(即程序中引入了既不在 org.apache.spark包,也不再语言运行时的库的依赖),我们就需要确保所有的依赖在Spark应用运行时都能被找到
- 对于Python而言,安装第三方库的方法有很多种
- 可以通过包管理器(如pip)在集群中所有机器上安装所依赖的库,或者手动将依赖安装到python安装目录下的site-packages/目录在
- 我们也可以通过spark-submit 的 --py-Files 参数提交独立的库
- 如果我们没有在集群上安装包的权限,可以手动添加依赖库,但是要防范与已经安装在集群上的那些包发生冲突
注意:
提交应用时,绝不要把spark本身放在提交的依赖中。spark-submit会自动确保spark在你的程序的运行路径中
- 对于Java 和 Scala,可以通过spark-submit 的 --jars 标记提交独立的jar包依赖
- 当只有一两个库的简单依赖,并且这些库不依赖与其他库时,这种方式比较合适
- 当需要依赖很多库的使用,这种方式很笨拙,不太适用。
- 此时的常规做法时使用构建工具(如maven、sbt)生成一个比较大的jar包,这个jar包中包含应用的所有的传递依赖。
使用Maven构建Java编写的Spark Application
参考POM
<repositories><!-- 指定仓库的位置,依次为aliyun、cloudera、jboss --><repository><id>aliyun</id><url>http://maven.aliyun.com/nexus/content/groups/public/</url></repository><repository><id>cloudera</id><url>https://repository.cloudera.com/artifactory/cloudera-repos/</url></repository><repository><id>jboss</id><url>https://repository.jboss.com/nexus/content/groups/public/</url></repository>
</repositories><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><scala.version>2.12.15</scala.version><scala.binary.version>2.12</scala.binary.version><hadoop.version>3.1.3</hadoop.version><spark.version>3.2.0</spark.version><spark.scope>compile</spark.scope>
</properties><dependencies><!-- 依赖Scala语言--><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>${scala.version}</version></dependency><!-- Spark Core 依赖 --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_${scala.binary.version}</artifactId><version>${spark.version}</version></dependency><!-- Hadoop Client 依赖 --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version></dependency>
</dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.10.1</version><configuration><source>${maven.compiler.source}</source><!-- 源代码使用的JDK版本 --><target>${maven.compiler.target}</target><!-- 需要生成的目标class文件的编译版本 --><encoding>${project.build.sourceEncoding}</encoding><!-- 字符集编码 --></configuration></plugin></plugins>
</build>
使用Maven构建Scala编写的Spark Application
参考POM
<repositories><!-- 指定仓库的位置,依次为aliyun、cloudera、jboss --><repository><id>aliyun</id><url>http://maven.aliyun.com/nexus/content/groups/public/</url></repository><repository><id>cloudera</id><url>https://repository.cloudera.com/artifactory/cloudera-repos/</url></repository><repository><id>jboss</id><url>https://repository.jboss.com/nexus/content/groups/public/</url></repository>
</repositories><properties><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><scala.version>2.13.5</scala.version><scala.binary.version>2.13</scala.binary.version><spark.version>3.2.0</spark.version><hadoop.version>3.1.3</hadoop.version>
</properties><dependencies><!-- 依赖Scala语言--><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>${scala.version}</version></dependency><!-- Spark Core 依赖 --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_${scala.binary.version}</artifactId><version>${spark.version}</version></dependency><!-- Hadoop Client 依赖 --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version></dependency>
</dependencies><build><plugins><!--maven的打包插件--><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.0.0</version><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin><!--该插件用于将scala代码编译成class文件--><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>3.2.2</version><executions><!--绑定到maven的编译阶段--><execution><goals><goal>compile</goal><goal>testCompile</goal></goals></execution></executions></plugin></plugins>
</build>
使用sbt构建Scala编写的Spark Application
目前未使用,暂时未记录
依赖冲突
当我们的Spark Application与Spark本身依赖于同一个库时可能会发生依赖冲突,导致程序崩溃。
依赖冲突通常表现为:
- NoSuchMethodError
- ClassNotFoundException
- 或其他与类加载相关的JVM异常
对于这类问题,主要的两种解决方式:
1)修改Spark Application,使其使用的依赖库版本与Spark所使用的相同
2)通常使用”shading“的方式打包我们的Spark Application
相关文章:

02-打包代码与依赖
打包代码与依赖说明 在开发中,我们写的应用程序通常需要依赖第三方的库(即程序中引入了既不在 org.apache.spark包,也不再语言运行时的库的依赖),我们就需要确保所有的依赖在Spark应用运行时都能被找到 对于Python而…...

Kotlin(五) 循环语句
目录 For循环 关键字 until step downTo Java中主要有两种循环语句:while循环和for循环。而Kotlin也提供了while循环和for循环,其中while循环不管是在语法还是使用技巧上都和Java中的while循环没有任何区别,因此我们就直接跳过不进行讲解…...

数字孪生产品:数字化时代的变革引擎
数字孪生技术,作为一项前沿的科技创新,正在不断改变我们的世界。它为各行各业的发展提供了无限的可能性,成为了当今数字化时代的一大亮点。数字孪生产品,作为数字孪生技术的具体应用,将在未来发挥越来越重要的作用。 数…...
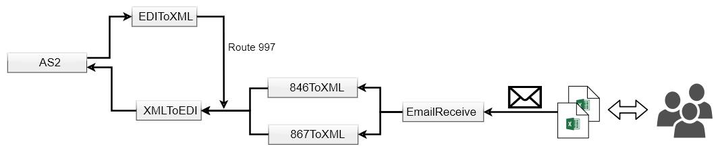
对接西部数据Western Digital EDI 系统
近期我们为国内某知名电子产品企业提供EDI解决方案,采用知行之桥 EDI 系统作为核心组件,成功与西部数据Western Digital(简称西数)建立EDI连接,实现数据安全且自动化传输。 EDI实施需求 EDI连接 传输协议:A…...
ClickHouse进阶(十):Clickhouse数据查询-4
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容! 🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客 📌订阅…...

FPGA原理与结构——FIFO IP核的使用与测试
一、前言 本文介绍FIFO Generator v13.2 IP核的具体使用与例化,在学习一个IP核的使用之前,首先需要对于IP核的具体参数和原理有一个基本的了解,具体可以参考: FPGA原理与结构——FIFO IP核原理学习https://blog.csdn.net/apple_5…...

ABB CMA120 3DDE300400面板
人机界面:ABB CMA120 3DDE300400 面板通常具有用户友好的人机界面,可用于监视和控制连接设备和系统的操作。 图形显示:该面板通常具有高分辨率的液晶显示屏,用于显示图形界面和实时数据,以便操作员更容易理解和管理工…...

【代码随想录day25】动态规划:01背包理论基础
题目 有n件物品和一个最多能背重量为w 的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品只能用一次,求解将哪些物品装入背包里物品价值总和最大。 代码 dp[i][j]: 表示从0~i个物品中选物品放到容量为j的背包中所能获得的最大价值 …...
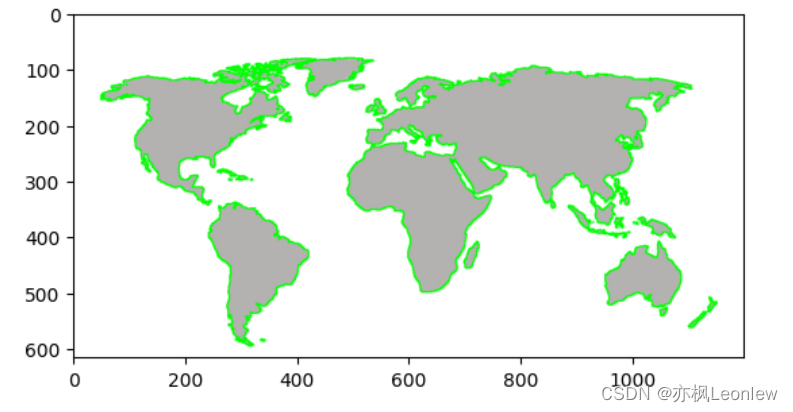
Python Opencv实践 - 轮廓检测
import cv2 as cv import numpy as np import matplotlib.pyplot as pltimg cv.imread("../SampleImages/map.jpg") print(img.shape) plt.imshow(img[:,:,::-1])#Canny边缘检测 edges cv.Canny(img, 127, 255, 0) plt.imshow(edges, cmapplt.cm.gray)#查找轮廓 #c…...

c#保留两位小数
1.使用ToString()方法和格式字符串 double number 3.1415926; string result number.ToString(“F2”); // 将number转换为字符串,并保留两位小数 Console.WriteLine(result); // 输出结果为 “3.14” 2.使用字符串插值和格式字符串 double number 3.1415926;…...
[machineLearning]非监督学习unsupervised learning
1.什么是非监督学习 常见的神经网络是一种监督学习,监督学习的主要特征即为根据输入来对输出进行预测,最终会得到一个输出数值.而非监督学习的目的不在于输出,而是在于对读入的数据进行归类,选取特征,打标签,通过对于数据结构的分析来完成这些操作, 很少有最后的输出操作. 从…...

C语言深入理解指针(非常详细)(四)
目录 字符指针变量数组指针变量数组指针变量是什么数组指针变量怎么初始化 二维数组传参的本质函数指针变量函数指针变量的创建函数指针变量的使用代码typedef关键字 函数指针数组转移表 字符指针变量 字符指针在之前我们有提到过,(字符)&am…...
知识库建设:从0到1搞定知识库建设的方法论分享
如果我们想要搭建一个知识库,前提是我们要明确知道这个知识库是干什么用的,只有了解知识库的应用场景才能知道如何去建设知识库。 知识库建设 以常见的电商客服为例,客户会经常咨询什么时候发货,怎么退货,怎么换货………...
SpringBoot+Vue 的留守儿童系统的研究与实现,2.0 版本,附数据库、教程
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝30W,Csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 文章目录 1.研究背景2. 技术栈3.系统分析4系统设计5系统的详细设计与实现5.1系统功能模块5.2管理员功能模块…...

28.考试
Description 小学期马上就要结束了,为了检验大家的学习成果,老师进行了一次考试。然而小徐前两周半都忙于练习篮球,几乎没有学习,因此考试时很可能做不完所有题目。 但小徐仍然想要拿到尽可能高的分数,因此在做题时需要…...

浏览器窗口间的通信
一、汇总 二、同源策略 三、webSocket (无跨域限制) 优点:无跨域限制 缺点:成本高 四、客户端存储 1、localStorage onStorage 例子: 2、定时器 客户端存储 例子: 缺点: 五、postMessage (无跨域…...

MATLAB 的 plot 绘图
文章目录 SyntaxDescriptionplot(X,Y)plot(X,Y,LineSpec)plot(X1,Y1,…,Xn,Yn)plot(X1,Y1,LineSpec1,...,Xn,Yn,LineSpecn)plot(Y)plot(Y,LineSpec)plot(tbl,xvar,yvar)plot(tbl,yvar)plot(ax,___)plot(___,Name,Value)p plot(___) plot: 2-D line plot Syntax plot(X,Y)plo…...
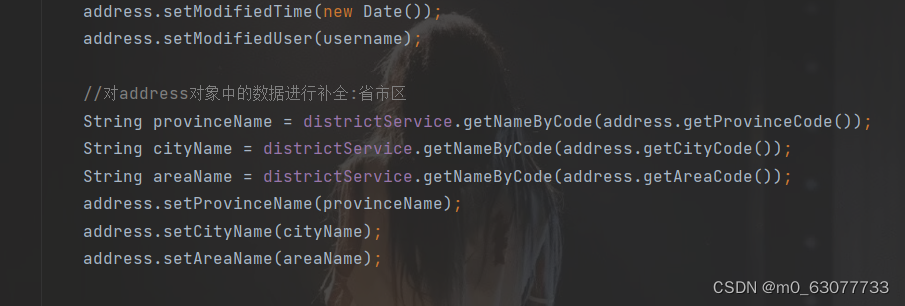
SpringBoot项目--电脑商城【获取省市区列表】
1.易错点 1.错误做法 新增收货地址页面的三个下拉列表的内容展示没有和数据库进行交互,而是通过前端实现的(将代码逻辑放在了distpicker.data.js文件中),实现方法是在加载新增收货地址页面时加载该js文件,这种做法不可取 2.正确做法 把这些数据保存到数据库中,用户点击下拉…...

使用git把本地项目关联远程代码仓库,并推送到远程仓库
你在本地新建了一个项目,写好了代码,但是没有关联远程仓库,怎么关联并上传呢? 你要先去gitee创建一个代码仓库,然后复制http地址。 首次提交项目代码到一个新建的远程仓库: 1、通过命令 git init 把这个…...
Spring+MyBatis使用collection标签的两种使用方法
目录 项目场景: 实战操作: 1.创建菜单表 2.创建实体 3.创建Mapper 4.创建xml 属性描述: 效率比较: 项目场景: 本文说明了Spring BootMyBatis使用collection标签的两种使用方法 1. 方法一: 关联查询 2. 方法…...

Arm CoreLink PCK-600电源管理套件解析与应用实践
1. Arm CoreLink PCK-600电源控制套件概述在现代SoC设计中,电源管理已经成为一个关键的技术挑战。随着移动设备和物联网应用的普及,如何在保证性能的同时最大限度地降低功耗,成为芯片设计者面临的核心问题。Arm CoreLink PCK-600电源控制套件…...

树莓派5驱动128x128 LED矩阵:打造复古PICO-8游戏艺术墙
1. 项目概述与核心思路我一直对复古游戏和像素艺术情有独钟,也一直想在家里弄一个既有科技感又能玩的装饰品。最近,我把树莓派5、四块64x64的RGB LED矩阵面板和PICO-8幻想游戏机捣鼓到了一起,成功在墙上挂起了一个128x128像素的“游戏艺术墙”…...

ARM ETMv4跟踪单元架构与寄存器详解
1. ARM ETMv4跟踪单元架构概述在嵌入式系统开发领域,指令跟踪技术是调试复杂软件问题的关键工具。ARM架构中的嵌入式跟踪宏单元(Embedded Trace Macrocell, ETM)作为处理器核心的实时跟踪组件,能够非侵入式地记录程序执行流程。ETMv4作为当前主流版本&am…...

量子优化算法在组合优化问题中的应用与性能分析
1. 量子优化算法与组合优化问题概述组合优化问题广泛存在于物流调度、网络设计、芯片布局等工业场景中,其核心挑战在于从离散解空间中高效寻找最优解。传统经典算法在面对NP难问题时往往面临计算复杂度爆炸的困境。量子优化算法通过量子叠加和纠缠等特性,…...
)
用STM32F103C8T6和HC-05蓝牙模块,从零DIY一辆蓝牙遥控小车(附完整代码与MIT App Inventor教程)
从零打造STM32蓝牙遥控小车:硬件配置到APP开发全指南 项目背景与核心价值 对于嵌入式开发初学者来说,理论知识和实际项目之间往往存在一道难以跨越的鸿沟。而一个完整的硬件项目实践,恰恰是填补这一空白的最佳方式。基于STM32F103C8T6和HC-05…...

不改变专业术语和逻辑的论文降重软件推荐|2026 实测 5 款,改写保真 + 双降达标
论文降重最怕 “改完重复率合格,术语乱改、逻辑断裂”,尤其理工科、医学、经管等专业,公式、术语、论证框架不容半点偏差。2026 年知网、维普全面升级 AIGC 检测,既要降重复率,更要保术语、保逻辑、降 AI 率。今天聚焦…...

如何快速掌握NCBI基因组批量下载:面向生物信息学新手的完整实战指南
如何快速掌握NCBI基因组批量下载:面向生物信息学新手的完整实战指南 【免费下载链接】ncbi-genome-download Scripts to download genomes from the NCBI FTP servers 项目地址: https://gitcode.com/gh_mirrors/nc/ncbi-genome-download NCBI基因组数据批量…...

3步轻松彻底卸载Microsoft Edge:专业级EdgeRemover工具使用指南
3步轻松彻底卸载Microsoft Edge:专业级EdgeRemover工具使用指南 【免费下载链接】EdgeRemover A PowerShell script that correctly uninstalls or reinstalls Microsoft Edge on Windows 10 & 11. 项目地址: https://gitcode.com/gh_mirrors/ed/EdgeRemover …...

STM32F103C8T6+ESP8266连接OneNET实战:从设备配置到数据上云完整流程解析
STM32F103C8T6ESP8266连接OneNET实战:从设备配置到数据上云完整流程解析 1. 物联网设备上云的核心价值与挑战 在智能家居、工业监测等场景中,将嵌入式设备数据实时上传至云端已成为刚需。STM32F103C8T6作为经典Cortex-M3内核MCU,搭配ESP8266 …...

RabbitMQ-C测试框架深度解析:单元测试、集成测试与模糊测试
RabbitMQ-C测试框架深度解析:单元测试、集成测试与模糊测试 【免费下载链接】rabbitmq-c RabbitMQ C client 项目地址: https://gitcode.com/gh_mirrors/ra/rabbitmq-c RabbitMQ-C是一个功能强大的RabbitMQ C客户端库,为确保其稳定性和可靠性&…...