Scrapy简介-快速开始-项目实战-注意事项-踩坑之路
scrapy项目模板地址:https://github.com/w-x-x-w/Spider-Project
Scrapy简介
Scrapy是什么?
- Scrapy是一个健壮的爬虫框架,可以从网站中提取需要的数据。是一个快速、简单、并且可扩展的方法。Scrapy使用了异步网络框架来处理网络通讯,可以获得较快的下载速度,因此,我们不需要去自己实现异步框架。并且,Scrapy包含了各种中间件接口,可以灵活的完成各种需求。所以我们只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页上的各种内容。
- Scrapy并不是一个爬虫,它只是一个“解决方案”,也就是说,如果它访问到一个“一无所知”的网站,是什么也做不了的。Scrapy是用于提取结构化信息的工具,即需要人工的介入来配置合适的XPath或者CSS表达式。Scrapy也不是数据库,它并不会储存数据,也不会索引数据,它只能从一堆网页中抽取数据,但是我们却可以将抽取的数据插入到数据库中。
Scrapy架构
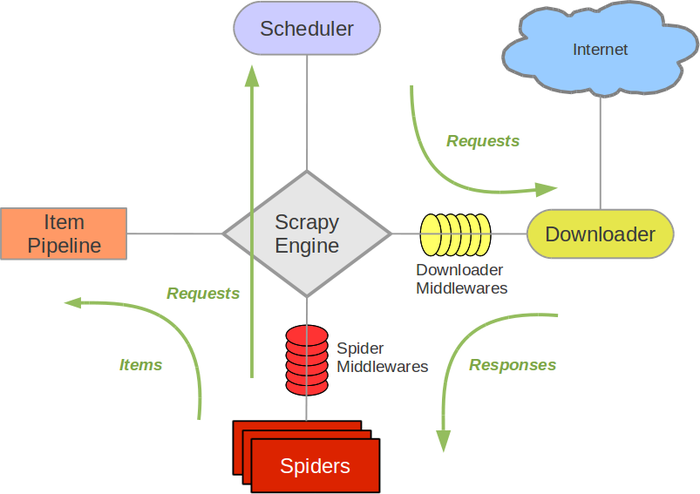
Scrapy Engine (引擎): 是框架的核心,负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。并在发生相应的动作时触发事件。
**Scheduler (调度器): **它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,提供给引擎。
**Downloader (下载器):**负责下载引擎发送的所有Requests请求,并将其获取到的Responses交还给引擎。
**Spider (爬虫):**负责处理由下载器返回的Responses,并且从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给Scrapy Engine,并且再次进入Scheduler。
**Item Pipeline (项目管道):**它负责处理Spider中获取到的Item,并进行进行后期处理(清理、验证、持久化存储)的地方.
**Downloader Middlewares (下载中间件):**引擎与下载器间的特定钩子,一个可以自定义扩展下载功能的组件。处理下载器传递给引擎的Response。
**Spider Middlewares(爬虫中间件):**引擎和Spider间的特定钩子,(处理进入Spider的Responses,和从Spider出去的Requests)
快速开始-项目实战
我们这里以某新闻网站新闻推送为例编写项目,仅用于学习,请勿恶意使用
安装 Scrapy
pip install Scrapy
创建项目
scrapy startproject 项目名
HuxiuSpider/scrapy.cfgHuxiuSpider/__init__.pyitems.pypipelines.pysettings.pyspiders/__init__.py...
这些文件分别是:
scrapy.cfg: 项目的配置文件HuxiuSpider/: 该项目的python模块。之后您将在此加入代码。HuxiuSpider/items.py: 项目中的item文件.HuxiuSpider/pipelines.py: 项目中的pipelines文件.HuxiuSpider/settings.py: 项目的设置文件.HuxiuSpider/spiders/: 放置spider代码的目录.
更改设置
- 注释robotstxt_obey
# 第21行
# Obey robots.txt rules
# ROBOTSTXT_OBEY = True
- 设置User-Agent
# 第18行
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = "HuxiuSpider (+http://www.yourdomain.com)"
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'
- 设置访问延迟
# 第29行
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 3
开启pipline
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {"HuxiuSpider.pipelines.HuxiuspiderPipeline": 300,
}
开启cookie(无需操作)(可选操作)
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
设置频率(可不操作)
# The download delay setting will honor only one of:
# 定义了每个域名同时发送的请求数量
CONCURRENT_REQUESTS_PER_DOMAIN = 2
# 定义了每个IP同时发送的请求数量
#CONCURRENT_REQUESTS_PER_IP = 16
命令行快速生成模板:
scrapy genspider huxiu_article api-article.huxiu.com
Spider是用户编写用于从单个网站(或者一些网站)爬取数据的类。
其包含了一个用于下载的初始URL,如何跟进网页中的链接以及如何分析页面中的内容, 提取生成 item 的方法。
为了创建一个Spider,您必须继承 scrapy.Spider 类, 且定义以下三个属性:
name: 用于区别Spider。 该名字必须是唯一的,您不可以为不同的Spider设定相同的名字。start_urls: 包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。(也可以删除此变量,但要重写start_requests方法)parse()是spider的一个方法。 被调用时,每个初始URL完成下载后生成的Response对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的Request对象。
以下为我们的第一个Spider代码,保存在 HuxiuSpider/spiders 目录下的 huxiu_article.py 文件中:
我们对于此段代码进行必要的解释:
向一个url发送post请求,发送一个时间戳,可以获取这个时间戳以后的新闻推送,然后就是推送数据,关于数据提取等操作可以点开链接页自行观察,太过简单。
爬虫程序模板:
新闻列表页爬虫
import json
import timeimport scrapyfrom HuxiuSpider.items import HuxiuspiderItemclass HuxiuArticleSpider(scrapy.Spider):def __init__(self):# 'https://www.huxiu.com/article/'self.url = 'https://api-article.huxiu.com/web/article/articleList'name = "huxiu_article"allowed_domains = ["api-article.huxiu.com"]def start_requests(self):timestamp = str(int(time.time()))form_data = {"platform": "www","recommend_time": timestamp,"pagesize": "22"}yield scrapy.FormRequest(url=self.url, formdata=form_data, callback=self.parse)def parse(self, response):item = HuxiuspiderItem()res = response.json()success = res['success']print(res)if success:data = res['data']is_have_next_page = data['is_have_next_page']last_dateline = data['last_dateline']total_page = data['total_page']dataList = data['dataList']for data_obj in dataList:item['url'] = 'https://www.huxiu.com/article/' + data_obj['aid'] + '.html'item['title'] = data_obj['title']item['author'] = data_obj['user_info']['username']item['allinfo'] = json.dumps(data_obj, ensure_ascii=False)item['visited'] = Falseyield itemif is_have_next_page:form_data = {"platform": "www","recommend_time": str(last_dateline),"pagesize": "22"}yield scrapy.FormRequest(url=self.url, formdata=form_data, callback=self.parse)else:raise Exception('请求新闻列表的时候失败了~')
Item模板:
Item 是保存爬取到的数据的容器;其使用方法和python字典类似, 并且提供了额外保护机制来避免拼写错误导致的未定义字段错误。
类似在ORM中做的一样,您可以通过创建一个 scrapy.Item 类, 并且定义类型为 scrapy.Field 的类属性来定义一个Item。 (如果不了解ORM, 不用担心,您会发现这个步骤非常简单)(ORM其实就是使用类的方式与数据库进行交互)
首先根据需要从huxiu.com获取到的数据对item进行建模。 我们需要从dmoz中获取名字,url,以及网站的描述。 对此,在item中定义相应的字段。编辑 HuxiuSpider 目录中的 items.py 文件:
import scrapyclass HuxiuspiderItem(scrapy.Item):url = scrapy.Field()title = scrapy.Field()author = scrapy.Field()# 存储尽量多的信息是必要的,以应对需求变更allinfo=scrapy.Field()visited=scrapy.Field()
一开始这看起来可能有点复杂,但是通过定义item, 您可以很方便的使用Scrapy的其他方法。而这些方法需要知道您的item的定义。
piplines模板:
from pymongo import MongoClient
from pymongo.errors import DuplicateKeyErrorclass HuxiuspiderPipeline:def __init__(self):self.client=MongoClient('localhost',username='spiderdb',password='password',authSource='spiderdb',authMechanism='SCRAM-SHA-1')self.db = self.client['spiderdb']self.collection = self.db['huxiu_links']self.collection.create_index("url", unique=True)def process_item(self, item, spider):item = dict(item)try:self.collection.insert_one(item)except DuplicateKeyError as e:passreturn itemdef close_spider(self, spider):self.client.close()
运行爬虫
进入项目的根目录,执行下列命令启动spider:
scrapy crawl huxiu_article
# scrapy crawl huxiu_article -o dmoz.csv
完善项目-多层爬取
yield scrapy.Request(item['url'], meta={'item': item}, callback=self.detail_parse)
https://blog.csdn.net/ygc123189/article/details/79160146
注意事项
自定义spider起始方式
也可以是查询数据库的结果,但要注意数据统一性,因为scrapy是异步爬取
自定义item类型与有无
spider爬取的结果封装到item对象中,再提交给pipeline持久化,那么当然也可以忽略item对象,传递你想要的数据格式直接到pipeline。
item与pipeline对应关系
item的意思是数据实例,一个item提交后,会经过所有的pipeline,pipeline的意思是管道,就是对数据的一系列操作,设置中的管道优先级就是管道处理数据的顺序,比如日志操作等。
如果要让某一个pipeline只处理某些类型的item,可以在item进入pipelne的时候判断一下是否是你想要处理的item类型。示例如下:
class doubanPipeline(object):def process_item(self, item, spider):#判断item是否为Item1类型if isinstance(item,doubanTextItem):# 操作itemreturn item
scrapy是异步执行的
同时运行多个爬虫
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settingssettings = get_project_settings()crawler = CrawlerProcess(settings)crawler.crawl('exercise')
crawler.crawl('ua')crawler.start()
crawler.start()
post表单数据传输需要是字符串
自定义请求头
import scrapyclass AddHeadersSpider(scrapy.Spider):name = 'add_headers'allowed_domains = ['sina.com']start_urls = ['https://www.sina.com.cn']headers = {'User-Agent': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)','Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',"Accept-Language": "zh-CN,zh;q=0.9,en-US;q=0.5,en;q=0.3","Accept-Encoding": "gzip, deflate",'Content-Length': '0',"Connection": "keep-alive"}def start_requests(self):for url in self.start_urls:yield scrapy.Request(url, headers=self.headers, callback=self.parse)def parse(self,response):print("---------------------------------------------------------")print("response headers: %s" % response.headers)print("request headers: %s" % response.request.headers)print("---------------------------------------------------------")
scrapy的FormRequest发送的是表单数据类型,如果要发送json类型需要使用Request
ts = round(time.time() * 1000)
form_data = {"nodeId": id_str,"excludeContIds": [],"pageSize": '20',"startTime": str(ts),"pageNum": '1'
}
yield scrapy.Request(url=self.url,method='POST',headers=self.headers,body=json.dumps(form_data), callback=self.parse,meta={'id_str': id_str})
相关文章:
Scrapy简介-快速开始-项目实战-注意事项-踩坑之路
scrapy项目模板地址:https://github.com/w-x-x-w/Spider-Project Scrapy简介 Scrapy是什么? Scrapy是一个健壮的爬虫框架,可以从网站中提取需要的数据。是一个快速、简单、并且可扩展的方法。Scrapy使用了异步网络框架来处理网络通讯&…...

lightdb 支持兼容Oracle的to_clob函数
文章目录 概述案例演示 概述 在信创移植的SQL语句中,有来源于Oracle数据库的SQL语句。 在ORACLE PL/SQL包中,你可以使用TO_CLOB(character)函数将RAW、CHAR、VARCHAR、VARCHAR2、NCHAR、NVARCHAR2、CLOB值转换为CLOB。 因此在LightDB 23.3版本中实现了…...

ES6中let和const关键字与var关键字之间的区别?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 变量作用域(Scope):⭐ 变量提升(Hoisting):⭐ 重复声明:⭐ 初始化:⭐ 全局对象属性:⭐ 写在最后 ⭐ 专栏简介 前端入门之旅&#…...
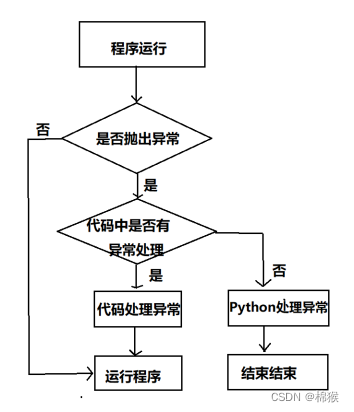
Python中的异常处理3-1
Python中的异常指的是语法上没有错误,但是代码执行时会导致错误的情况。 1 抛出异常 在图1所示的代码中,要求用户输入一个数字,该代码在语法上没有错误。 图1 出现异常的代码 但是运行该代码之后,如果用户输入的是数字…...

大数据与AI:解析智慧城市的幕后英雄
文章目录 1. 智慧城市的定义与发展2. 大数据:智慧城市的基石2.1 大数据的概念与重要性2.2 大数据的应用案例2.2.1 智能交通管理2.2.2 能源效率优化2.2.3 城市规划与土地利用 3. 人工智能:智慧城市的大脑3.1 人工智能的概念与重要性3.2 人工智能的应用案例…...
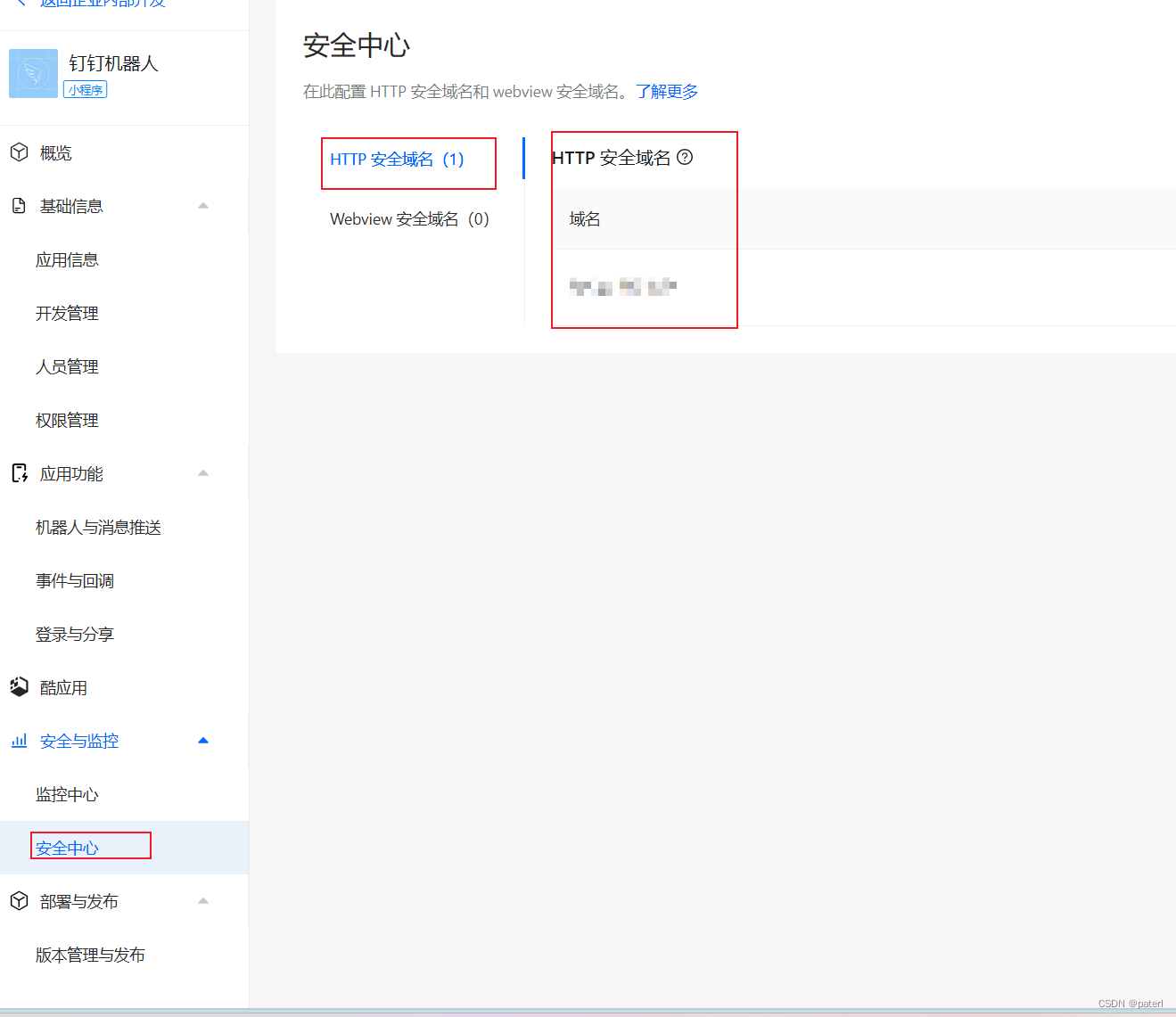
将钉钉机器人小程序从一个公司迁移至另一个公司的步骤
引言: 由于我们以前开发的钉钉小程序都在一个公司,想在想应用到另一个公司,这就牵扯出了关于钉钉小程序迁移方面的具体步骤。下面是具体步骤: 1、创建一个钉钉小程序 在这一步你需要有钉钉开放平台的开发者权限,具体…...
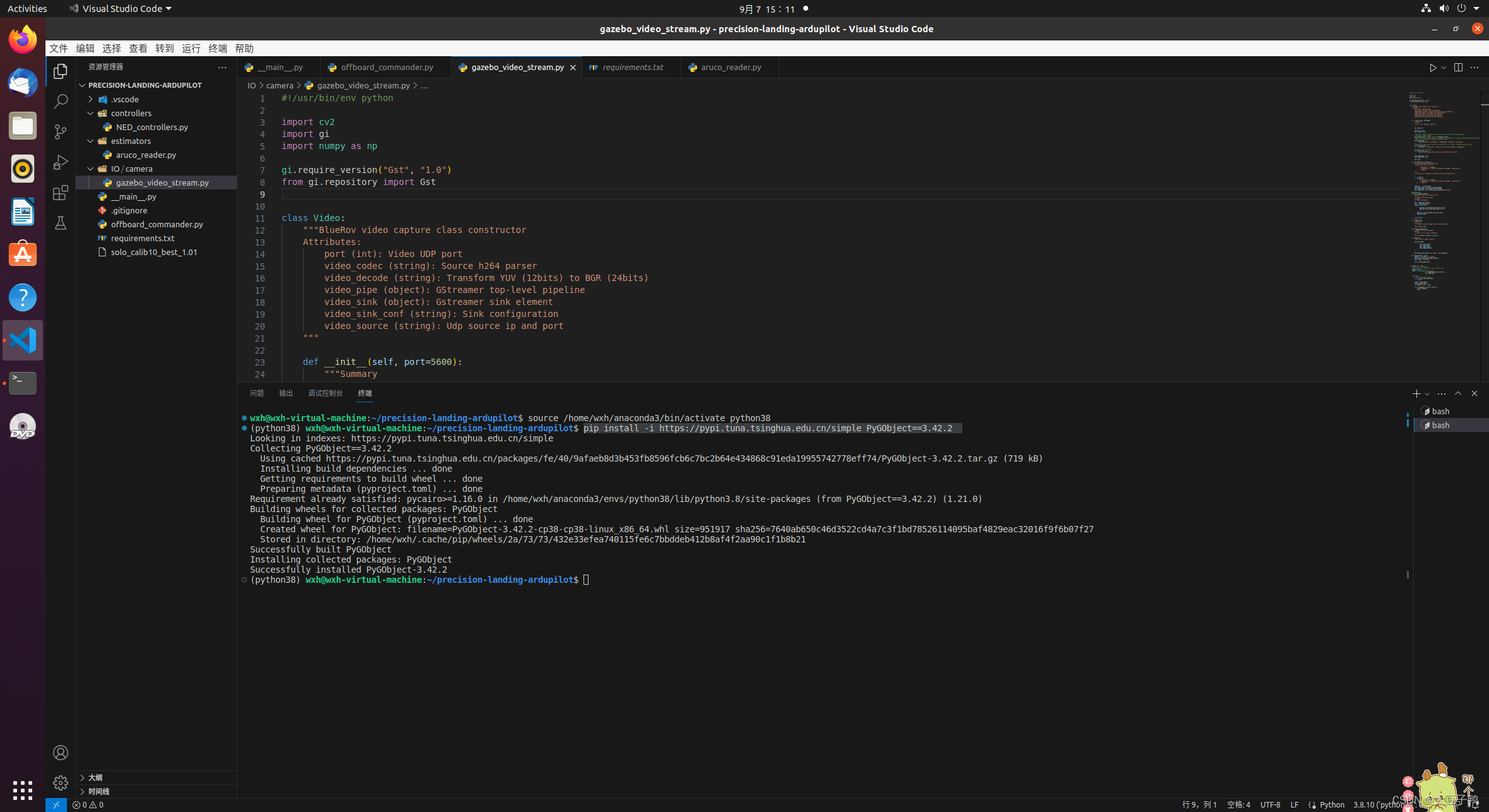
j解决Ubuntu无法安装pycairo和PyGObject
环境:虚拟机Ubuntu20.04,vscode无法安装pycairo和PyGObject 虚拟机Ubuntu20.04,vscode中运行Anaconda搭建的vens 的Python3.8.10 首先在vscode中点击ctrlshiftp,选择Python3.8.10的环境,自动激活Python 最近在搞无人…...

PBI 背景全屏规律呈现水印
想要在Power BI报表中实现全屏规律呈现斜角水印的效果,并且显示的值是用户登录的email的话,目前Power BI desktop的背景“Background”功能中暂时没有支持的直接设置方法。但是基于测试和研究,Power BI市场中有一个叫“HTML Content”的custom visual提供,它支持嵌入一些HT…...

2023年全国职业院校技能大赛信息安全管理与评估网络安全事件响应、数字取证调查、应用程序安全任务书
全国职业院校技能大赛 高等职业教育组 信息安全管理与评估 任务书 模块二 网络安全事件响应、数字取证调查、应用程序安全 比赛时间及注意事项 本阶段比赛时长为180分钟,时间为13:30-16:30。 【注意事项】 比赛结束,不得关机;选手首先需要…...
浙大陈越何钦铭数据结构08-图7 公路村村通【循环和最小堆版】
题目 现有村落间道路的统计数据表中,列出了有可能建设成标准公路的若干条道路的成本,求使每个村落都有公路连通所需要的最低成本。 输入格式: 输入数据包括城镇数目正整数N(≤1000)和候选道路数目M(≤3N)…...
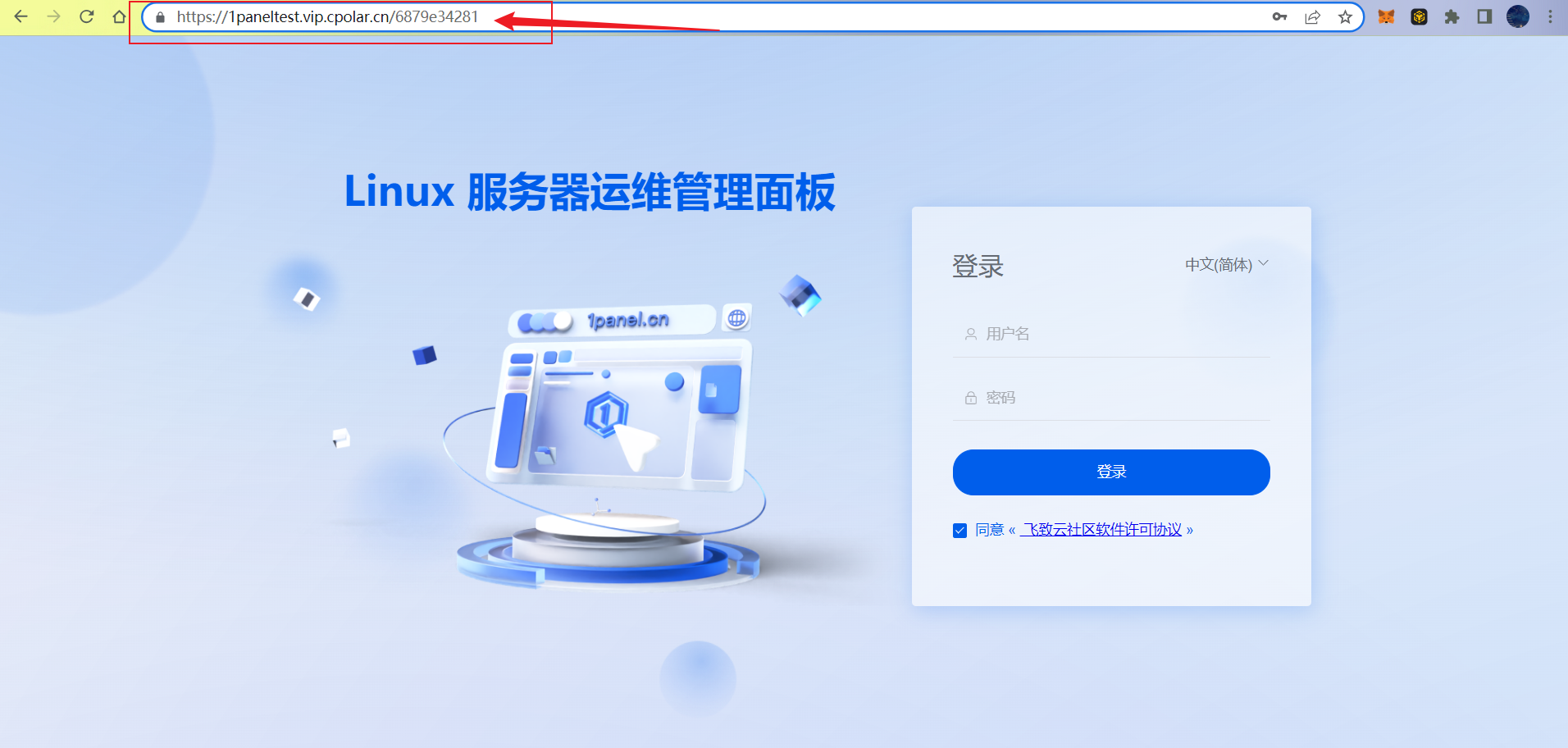
Linux 部署1Panel现代化运维管理面板远程访问
文章目录 前言1. Linux 安装1Panel2. 安装cpolar内网穿透3. 配置1Panel公网访问地址4. 公网远程访问1Panel管理界面5. 固定1Panel公网地址 前言 1Panel 是一个现代化、开源的 Linux 服务器运维管理面板。高效管理,通过 Web 端轻松管理 Linux 服务器,包括主机监控、…...

用百度云怎么重装电脑系统
用百度云怎么重装电脑系统 随着云计算技术的飞速发展,百度云成为了人们日常生活中不可或缺的一部分。百度云不仅提供了强大的文件存储和传输功能,还可以帮助人们轻松地重装电脑系统。下面就让我们来介绍一下如何用百度云重装电脑系统。 步骤一…...

SpringCloud环境搭建及入门案例
技术选型: Maven 3.8.4SpringBoot 2.7.8SpringCloud 2021.0.4SpringCloudAlibaba 2022.0.1.0Nacos 2.1.1Sentinel 1.8.5 模块设计: 父工程:SpringCloudAlibaba订单微服:order-service库存微服:stock-service 1.创建…...

什么是序列化和反序列化?
JSON(JavaScript Object Notation)和XML(eXtensible Markup Language)是两种常用的数据交换格式,用于在不同系统之间传输和存储数据。 JSON是一种轻量级的数据交换格式,它使用易于理解的键值对的形式表示数…...

React 消息文本循环展示
需求 页面上有个小喇叭,循环展示消息内容 逻辑思路 设置定时器,修改translateX属性来实现滚动,判断滚动位置,修改list位置来实现无限滚动 实现效果 代码 /** Author: Do not edit* Date: 2023-09-07 11:11:45* LastEditors: …...
java获取jenkins发布版本信息
一.需求: 系统cicd发布时首页需要展示jenkins发布的版本和优化内容 二.思路: 1.jenkins创建用户和秘钥 2.找到对应构建任务信息的api 3.RestTemplate发起http请求 三.实现: 1.创建用户和token 2.查找jenkins API 创建 Job POST http://localhost…...
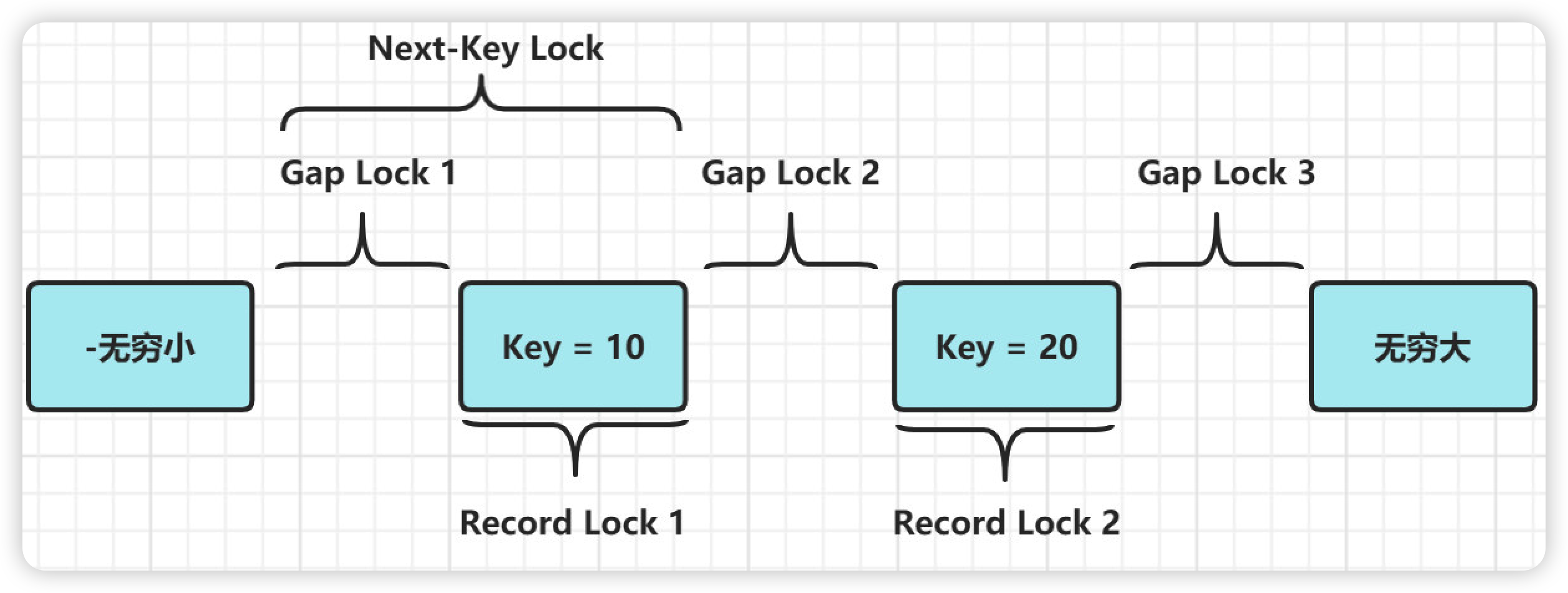
java八股文面试[数据库]——可重复读怎么实现的(MVCC)
可重复读(repeatable read)定义: 一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的。 MVCC MVCC,多版本并发控制, 用于实现读已提交和可重复读隔离级别。 MVCC的核心就是 Undo log多版本链 …...

cl 和 “clangtidy“分别是什么?是同一样东西吗?
作者:gentle_zhou 原文链接:cl 和 "clangtidy"分别是什么?是同一样东西吗?-云社区-华为云 先说结论:这两个是不同的工具,cl是编译器,clangtidy是代码检查工具,它们不是一…...

ubuntu22.04开机自启动Eureka服务
ubuntu22.04开机自启动Eureka服务 1、创建启动脚本eurekaService.sh #我们把启动脚本放在/usr/software目录下 cd /usr/software vim eurekaService.sheurekaService.sh内容为 #!/bin/sh # this is a eurekaService shell to startup at the mechian power on.echo "eu…...

【 OpenGauss源码学习 —— 列存储(analyze)(三)】
列存储(analyze) acquire_sample_rows 函数RelationGetNumberOfBlocks 函数BlockSampler_Init 函数anl_init_selection_state 函数BlockSampler_GetBlock 函数ReadBufferExtendedPageGetMaxOffsetNumber 函数HeapTupleSatisfiesVacuum 函数heapCopyTuple…...

L1正则与次梯度
L1:稀疏权重、解易落在轴上、特征选择(应用场景)、w0w0w0不可导需次梯度subgradient:∂f(x){g∣f(y)≥f(x)gT(y−x),∀ y∈dom f}\partial f(x)\{g|f(y)\geq f(x) g^T(y-x),\forall\ y\in \text{dom}\ f \}∂f(x){g∣f(y)≥f(x)g…...

ARM PMU性能监控单元原理与编程实践
1. ARM PMU性能监控基础架构解析 性能监控单元(Performance Monitoring Unit, PMU)是现代处理器微架构中的关键组件,它通过硬件计数器实现对处理器运行时行为的精确测量。在ARMv8/v9架构中,PMU的设计遵循了高度模块化和可扩展的原则,能够支持…...

ChanlunX缠论插件:5分钟实现通达信专业缠论分析的完整指南
ChanlunX缠论插件:5分钟实现通达信专业缠论分析的完整指南 【免费下载链接】ChanlunX 缠中说禅炒股缠论可视化插件 项目地址: https://gitcode.com/gh_mirrors/ch/ChanlunX ChanlunX缠论插件是一款专为通达信用户设计的智能缠论分析工具,它通过DL…...

AI写专著高效途径:选对工具,一键生成20万字专著不是梦!
一、新手研究者撰写学术专著的困境 对于首次尝试撰写学术专著的研究者来说,写作的过程就像是在“摸石头过河”,其中充满了各种未知的障碍。选题上常常感到迷茫,难以在“有意义”与“可行性”之间找到合适的平衡,选题要么过于宏大…...

华硕笔记本终极优化神器:GHelper完整使用教程
华硕笔记本终极优化神器:GHelper完整使用教程 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Expertbook…...

零基础入门:labelCloud如何让你轻松完成3D点云标注工作
零基础入门:labelCloud如何让你轻松完成3D点云标注工作 【免费下载链接】labelCloud A lightweight tool for labeling 3D bounding boxes in point clouds. 项目地址: https://gitcode.com/gh_mirrors/la/labelCloud 你是否正在寻找一款简单易用的3D点云标注…...

从一次安全扫描报告说起:聊聊SSH Banner泄露那些事儿,以及比修改Banner更重要的安全习惯
从SSH版本泄露看现代安全防御:工程师的深度实践指南 那天下午,我正在整理新部署的云服务器集群的安全扫描报告,一个看似"古老"的漏洞引起了我的注意——CVE-1999-0634,SSH版本信息可被获取。这个诞生于上世纪的安全问题…...

Cursor AI插件开发指南:构建企业级智能编码助手
1. 项目概述:一个为开发者而生的智能编码伴侣如果你是一名开发者,每天在IDE里敲代码的时间超过8小时,那你一定对“上下文切换”和“信息查找”这两件事深恶痛绝。想象一下,你正在写一个复杂的API接口,突然需要回忆上周…...

Discord审计数据流解决方案:构建高可靠事件中继与自动化处理
1. 项目概述:一个被低估的审计数据流解决方案 如果你在管理一个中等规模以上的Discord社区,或者正在开发一个需要深度集成Discord生态的机器人,那么你一定遇到过这样的痛点:如何可靠、实时地获取服务器内发生的所有关键事件&…...

Windows下Carla编译启动卡在75%?别急着重装,先检查这个隐藏的压缩包
Windows下Carla编译启动卡在75%?别急着重装,先检查这个隐藏的压缩包 当你满怀期待地在Windows上完成Carla的编译,输入make launch命令后,进度条却在75%处戛然而止,弹出一个冰冷的"Fatal error"对话框——这…...