Python爬虫——新手使用代理ip详细教程
Python代理IP爬虫是一种可以让爬虫拥有更多网络访问权限的技术。代理IP的作用是可以为爬虫提供多个IP地址,从而加快其爬取数据的速度,同时也可以避免因为访问频率过高而被网站封禁的问题。本文将介绍如何使用Python实现代理IP的爬取和使用。

一、代理IP的获取
首先我们需要找到一个可用的代理IP源。这里我们以站大爷代理ip为例,站大爷代理提供了收费代理和普通免费的代理IP,使用起来非常方便。
站大爷代理ip的API接口地址:`https://www.zdaye.com/free/inha/1/`
通过请求上面的API接口,我们可以获取到一页代理IP信息,包括IP地址和端口号。我们可以通过requests库的get方法获取到API返回的信息,示例代码如下:
import requestsurl = 'https://www.zdaye.com/free/inha/1/'
response = requests.get(url)
print(response.text)上面代码执行后,我们可以看到获取到的代理IP信息。但是我们需要对返回值进行解析,只提取出有用的IP地址和端口。
import requests
from bs4 import BeautifulSoupurl = 'https://www.zdaye.com/free/inha/1/'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')proxies = []
for tr in soup.find_all('tr')[1:]:tds = tr.find_all('td')proxy = tds[0].text + ':' + tds[1].textproxies.append(proxy)print(proxies)
上面代码中,我们使用BeautifulSoup库对返回的HTML文本进行解析,获取到所有的`<tr>`标签,然后通过循环遍历每一个`<tr>`标签,提取出其中的IP地址和端口信息,并将其保存到一个列表中。
二、代理IP的验证
获取到代理IP后,我们需要进行测试,判断这些代理IP是否可用。这里我们通过requests库的get方法进行测试,如果返回200则说明该代理IP可用。我们使用代理IP的方法是通过向requests.get方法传入proxies参数来实现,示例代码如下:
import requestsurl = 'http://www.baidu.com'proxies = {'http': 'http://222.74.237.246:808','https': 'https://222.74.237.246:808',
}
try:response = requests.get(url, proxies=proxies, timeout=10)if response.status_code == 200:print('代理IP可用:', proxies)
except:print('代理IP不可用:', proxies)
在上面的代码中,我们向`http://www.baidu.com`发送请求,并使用了一个代理IP进行访问。如果返回HTTP状态码为200,则说明代理IP可用,否则说明不可用。
如果我们需要验证每一个代理IP,那么就需要对上面的代码进行循环遍历,例如:
import requests
from bs4 import BeautifulSoupurl = 'https://www.zdaye.com/free/inha/1/'response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')proxies = []
for tr in soup.find_all('tr')[1:]:tds = tr.find_all('td')proxy = tds[0].text + ':' + tds[1].textproxies.append(proxy)for proxy in proxies:proxies_dict = {'http': 'http://' + proxy,'https': 'https://' + proxy,}try:response = requests.get(url, proxies=proxies_dict, timeout=10)if response.status_code == 200:print('代理IP可用:', proxies_dict)except:print('代理IP不可用:', proxies_dict)
上面的循环代码中,我们先遍历了所有的代理IP,然后对每一个代理IP进行验证。如果该代理IP可用,则打印出来,否则输出不可用信息。
三、代理IP的测试
获取到可用的代理IP后,我们需要对其进行进一步的测试,确保其真正可用,然后再进行爬取。我们可以使用百度、360搜索等常用搜索引擎进行测试。在这里我们以百度为例,测试代理IP是否真正可用。
import requestsurl = 'http://www.baidu.com'proxies = {'http': 'http://222.74.237.246:808','https': 'https://222.74.237.246:808',
}
try:response = requests.get(url, proxies=proxies, timeout=10)if response.status_code == 200:if '百度一下' in response.text:print('代理IP可用:', proxies)else:print('代理IP不可用:', proxies)else:print('代理IP不可用:', proxies)
except:print('代理IP不可用:', proxies)上面代码中,我们向百度发送了一个请求,并通过判断返回的HTML页面中是否含有‘百度一下’这个关键字来验证代理IP是否真正可用。
四、代理IP的使用
当我们获取到了可用的代理IP后,我们就可以使用它们来进行爬取了。在使用代理IP进行爬取时,我们需要将其作为proxies参数传入requests.get方法中,示例代码如下:
import requestsurl = 'http://www.baidu.com'proxies = {'http': 'http://222.74.201.49:9999','https': 'https://222.74.201.49:9999',
}
response = requests.get(url, proxies=proxies)
print(response.text)上面代码中,我们使用了一个代理IP进行访问百度网站,并将其作为proxies参数传入requests.get方法中。如果该代理IP可用,则请求将会使用该代理IP进行访问。
五、完整代码
下面是一份完整的代码,包括代理IP的获取、验证、测试和使用,大家可以参考一下:
import requests
from bs4 import BeautifulSoup# 1. 获取代理IP列表
def get_proxy_list():# 构造请求头,模拟浏览器请求headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36"}# 请求代理IP网页url = "http://www.zdaye.com/"response = requests.get(url, headers=headers)# 解析网页获取代理IP列表soup = BeautifulSoup(response.text, "html.parser")proxy_list = []table = soup.find("table", {"id": "ip_list"})for tr in table.find_all("tr"):td_list = tr.find_all("td")if len(td_list) > 0:ip = td_list[1].text.strip()port = td_list[2].text.strip()type = td_list[5].text.strip()proxy_list.append({"ip": ip,"port": port,"type": type})return proxy_list# 2. 验证代理IP可用性
def verify_proxy(proxy):# 构造请求头,模拟浏览器请求headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36"}# 请求目标网页并判断响应码url = "http://www.baidu.com"try:response = requests.get(url, headers=headers, proxies=proxy, timeout=5)if response.status_code == 200:return Trueelse:return Falseexcept:return False# 3. 测试代理IP列表可用性
def test_proxy_list(proxy_list):valid_proxy_list = []for proxy in proxy_list:if verify_proxy(proxy):valid_proxy_list.append(proxy)return valid_proxy_list# 4. 使用代理IP发送请求
def send_request(url, headers, proxy):# 发送请求并返回响应结果response = requests.get(url, headers=headers, proxies=proxy)return response.text# 程序入口
if __name__ == "__main__":# 获取代理IP列表proxy_list = get_proxy_list()# 验证代理IP可用性valid_proxy_list = test_proxy_list(proxy_list)# 输出可用代理IPprint("有效代理IP列表:")for proxy in valid_proxy_list:print(proxy)# 使用代理IP发送请求url = "http://www.baidu.com"headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36"}proxy = {"http": "http://" + valid_proxy_list[0]["ip"] + ":" + valid_proxy_list[0]["port"],"https": "https://" + valid_proxy_list[0]["ip"] + ":" + valid_proxy_list[0]["port"]}response = send_request(url, headers, proxy)print(response)在上面的代码中,我们首先通过爬取西刺代理网站获取代理IP列表。然后,我们对每一个代理IP进行验证,判断其是否可用,并将可用的代理IP存入一个列表中。最后,我们选择一个可用的代理IP,并使用该代理IP发送请求。
六、总结
本文介绍了代理IP的基本概念、免费代理IP获取方法、Python使用代理IP的方法及示例代码,以及代理IP使用的注意事项。希望能够对爬虫的使用者有所帮助。
相关文章:
Python爬虫——新手使用代理ip详细教程
Python代理IP爬虫是一种可以让爬虫拥有更多网络访问权限的技术。代理IP的作用是可以为爬虫提供多个IP地址,从而加快其爬取数据的速度,同时也可以避免因为访问频率过高而被网站封禁的问题。本文将介绍如何使用Python实现代理IP的爬取和使用。 一、代理IP的…...
idea VCS配置多个远程仓库
Idea VCS配置多个远程仓库 首先要有连个远程仓库地址 idea 添加数据源 查看推送记录 添加数据源 ok之后填写账号密码 推送本地项目 选择不同远程地址 push 查看不同远程地址的 不同分支的 推送记录 不期而遇的温柔: 应用开源架构进行项目开发,特别是那…...

LKPNR: LLM and KG for Personalized News Recommendation Framework
本文是LLM系列文章,针对《LKPNR: LLM and KG for Personalized News Recommendation Framework》的翻译。 LKPNR:LLM和KG的个性化新闻推荐框架 摘要1 引言2 相关工作3 问题定义4 框架5 实验6 案例7 结论 摘要 准确地向用户推荐候选新闻文章是个性化新闻推荐系统面…...
Xshell只能打开一个会话、左边栏消失不见、高级设置在哪儿、快捷键设置解决
Xshell只能打开一个会话、左边会话栏消失不见、高级设置在哪儿解决 1.问题: xshell会话(窗口)上方切换栏不见了的处理办法 解决方法:ctrl shift t 2.问题: 左边会话管理器不见了 解决方法: 3.问题…...

Android Retrofit 高级使用与原理
简介 在 Android 开发中,网络请求是一个极为关键的部分。Retrofit 作为一个强大的网络请求库,能够简化开发流程,提供高效的网络请求能力。本文将深入介绍 Retrofit 的高级使用与原理,帮助读者更全面地理解和应用这一库。 什么是…...
Unity3D开发流程及注意事项
使用Unity3D开发游戏需要遵循一定的流程和注意事项,以确保项目的顺利进行并获得良好的结果。以下是一般的游戏开发流程以及一些注意事项,希望对大家有所帮助。北京木奇移动技术有限公司,专业的软件外包开发公司,欢迎交流合作。 游…...
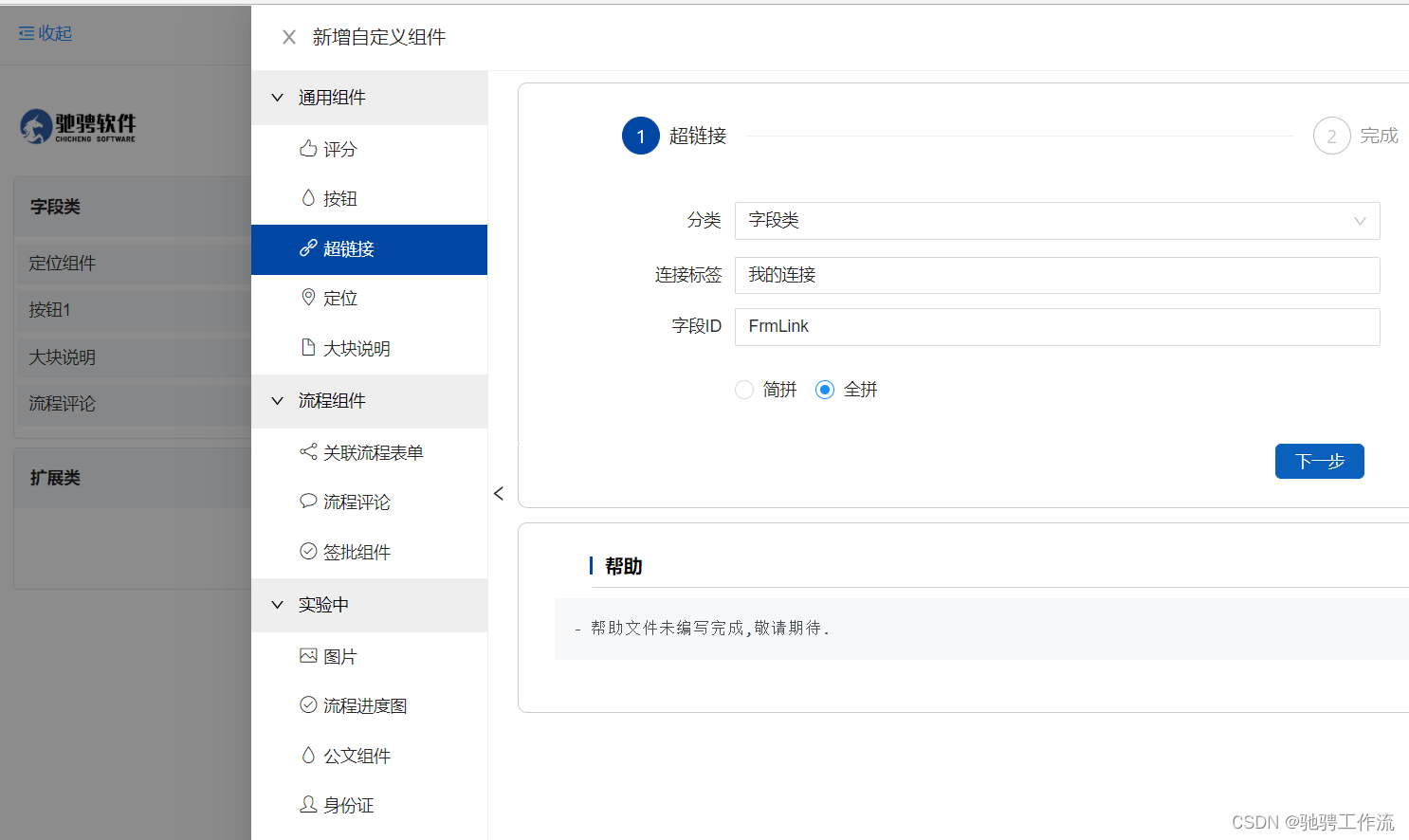
表单引擎的自定义控件的概念与设计
基本概念 概述 控件的定义:用于展示或者采集数据的表单元素,称为控件,比如:文本框、下拉框、单选按钮、从表等.自定义控件:表单引擎提供的基础控件之外的控件称为自定义控件, 这些控件由开发人员自己定义,比如&#…...

leetcode刷题--栈与递归
文章目录 1. 682 棒球比赛2. 71 简化路径3. 388 文件的最长绝对路径4. 150 逆波兰表达式求值5. 227. 基本计算器II6. 224. 基本计算器7. 20. 有效的括号8. 636. 函数的独占时间9. 591. 标签验证器10. 32.最长有效括号12. 341. 扁平化嵌套列表迭代器13. 394.字符串解码 1. 682 棒…...
自然语言处理——数据清洗
一、什么是数据清洗 数据清洗是指发现并纠正数据文件中可识别的错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值等。与问卷审核不同,录入后的数据清理一般是由计算机而不是人工完成。 ——百度百科 二、为什么要数据清洗 现实生…...

MySql学习笔记07——存储引擎介绍
存储引擎 Mysql中特有的术语,Oracle中没有。 存储引擎就是一个表存储/组织数据的方式。不同的存储引擎,表存储数据的方式不同。 指定存储引擎 在建表的时候可以在最后小括号的")"的右边使用: ENGINE来指定存储引擎。 CHARSET来…...

Java基础学习笔记-1
前言 Java 是一门强大而广泛应用的编程语言,它的灵活性和跨平台特性使其成为许多开发者的首选。无论您是刚刚入门编程,还是已经有一些编程经验,掌握 Java 的基础知识都是构建更复杂程序的关键。 本学习笔记旨在帮助您深入了解 Java 编程语言…...

以太坊虚拟机
1.概述 以太坊虚拟机 EVM 是智能合约的运行环境。它不仅是沙盒封装的,而且是完全隔离的,也就是说在 EVM 中运行代码是无法访问网络、文件系统和其他进程的。甚至智能合约之间的访问也是受限的。 2.账户 以太坊中有两类账户(它们共用同一个…...

说说BTree和B+Tree
分析&回答 B树索引是B树在数据库中的一种实现,是最常见也是数据库中使用最为频繁的一种索引。B树中的B代表平衡(balance),而不是二叉(binary),因为B树是从最早的平衡二叉树演化而来的。 接…...

8.1.3 Bit representation and coding - 解读
这段描述定义了一些序列,并规定了它们在编码信息时的使用方式。下面是对每个序列的解析: 1. 序列X:在位持续时间的一半之后,将发生一个“暂停”。这个序列用于表示逻辑“1”。 2. 序列Y:在整个位持续时间内,…...

spring 理解
spring容器 程序启动时,会给spring容器一个清单,清单中列出了需要创建的对象以及对象依赖关系,spring容器会创建和组装好清单中的对象,然后将这些对象存放在spring容器中,当程序中需要使用的时候,可以到容…...

实战SpringMVC之CRUD
目录 一、前期准备 1.1 编写页面跳转控制类 二、实现CRUD 2.1 相关依赖 2.2 配置文件 2.3 逆向生成 2.4 后台代码完善 2.4.1 编写切面类 2.4.2 编写工具类 2.4.3 编写biz层 2.4.4 配置mapper.xml 2.4.5 编写相应接口类(MusicMapper) 2.4.6 处…...
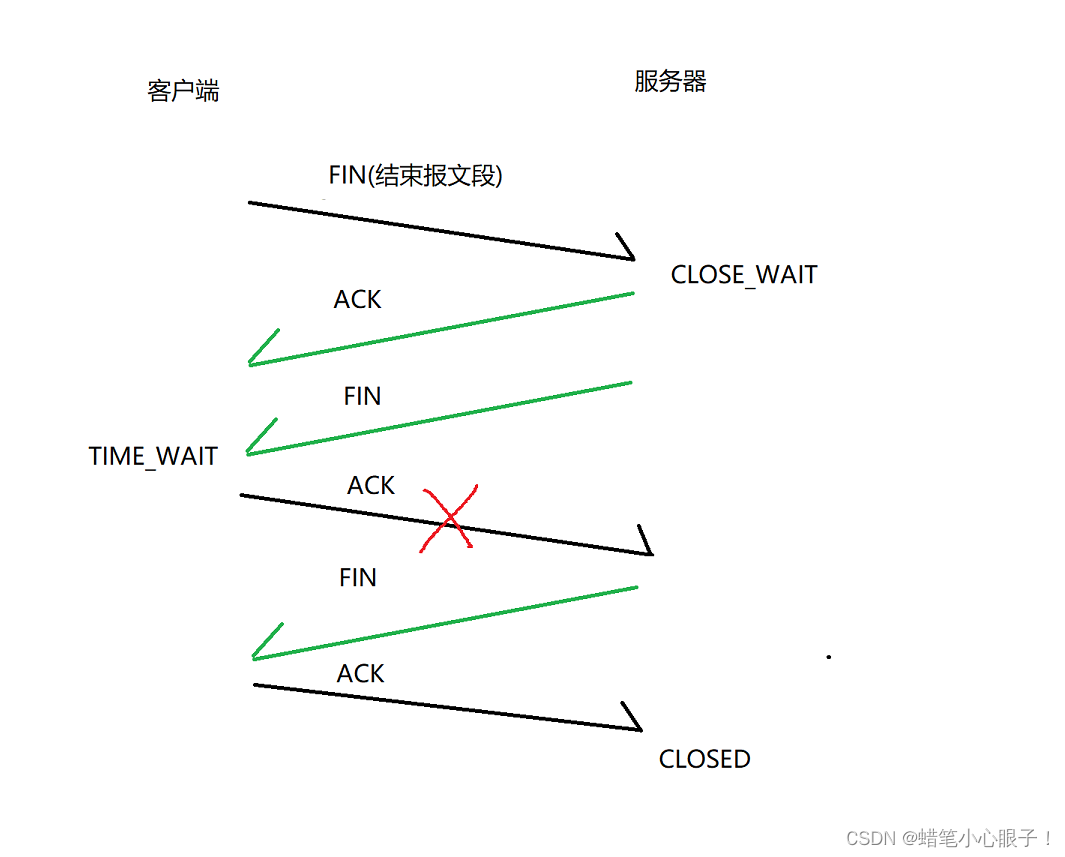
TCP机制之连接管理(三次握手和四次挥手详解)
TCP的连接管理机制描述了连接如何创建以及如何断开! 建立连接(三次握手) 三次握手的过程 所谓建立连接就是通信双方各自要记录对方的信息,彼此之间要相互认同;这里以A B双方确立男女朋友关系为例: 从图中可以看出,通信双方各自向对方发起一个"建立连接"的请求,同时…...
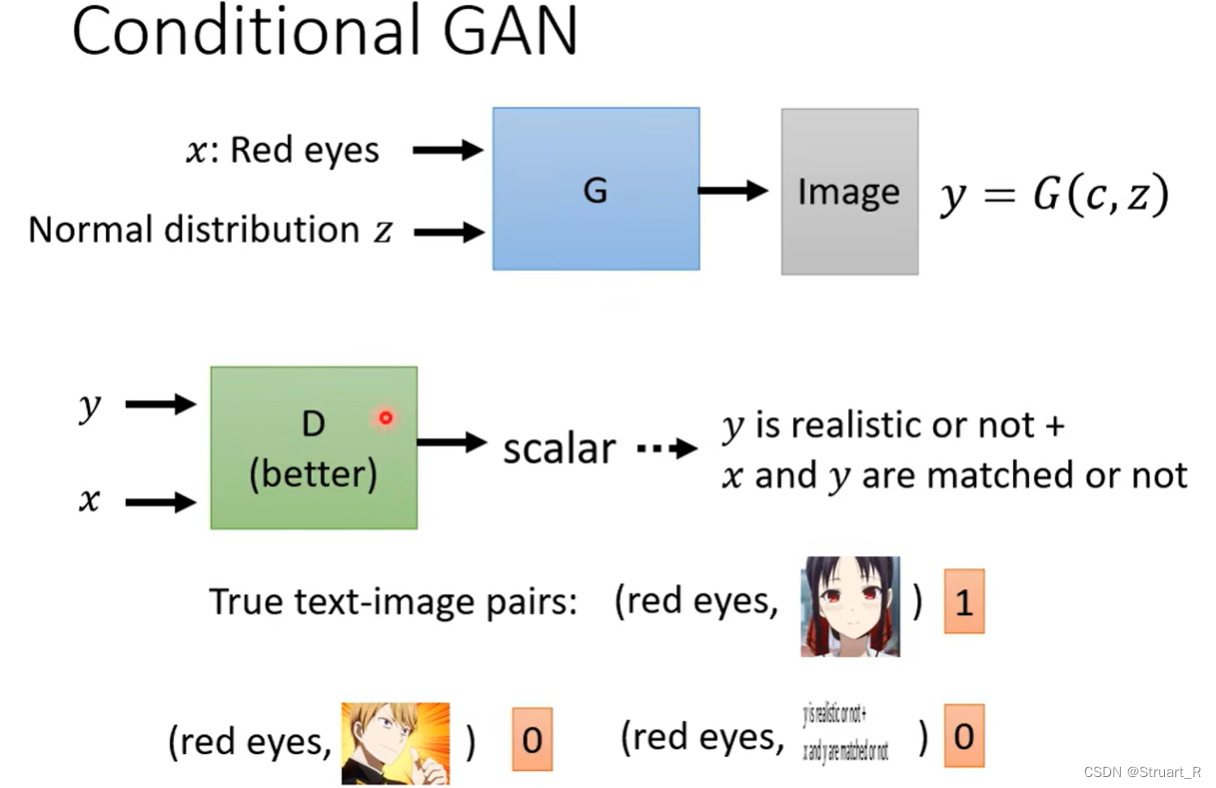
NLP(3)--GAN
目录 一、概述 二、算法过程 三、WGAN 1、GAN的不足 2、JS散度、KL散度、Wasserstein距离 3、WGAN设计 四、Mode Collapse and Mode Dropping 1、Mode Collapse 2、Mode Dropping 3、FID 四、Conditional GAN 一、概述 GAN(Generative Adversial Networ…...

无涯教程-JavaScript - IMLOG2函数
描述 IMLOG2函数以x yi或x yj文本格式返回复数的以2为底的对数。可以从自然对数计算复数的以2为底的对数,如下所示- $$\log_2(x yi)(log_2e)\ln(x yi)$$ 语法 IMLOG2 (inumber)争论 Argument描述Required/OptionalInumberA complex number for which you want the bas…...
拦截器(HandlerInterceptor)的用法)
SpringBoot复习:(61)拦截器(HandlerInterceptor)的用法
一、自定义拦截器: package cn.edu.tju.interceptor;import org.springframework.stereotype.Component; import org.springframework.web.servlet.HandlerInterceptor;import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletRespo…...

避坑指南:海康摄像头WS流接入H5播放器的那些‘坑’与最佳实践
海康摄像头WS流H5播放器实战:从协议解析到高可用架构设计 当监控视频流需要跨越浏览器边界时,技术挑战往往接踵而至。最近在金融园区项目中,我们通过H5播放器接入海康威视WS协议流时,发现看似简单的视频播放背后隐藏着协议兼容、网…...

Godot资源解压器godotdec:从游戏资源保护到开发分析的技术实践
Godot资源解压器godotdec:从游戏资源保护到开发分析的技术实践 【免费下载链接】godotdec An unpacker for Godot Engine package files (.pck) 项目地址: https://gitcode.com/gh_mirrors/go/godotdec 在游戏开发与资源管理领域,Godot引擎的.pck…...

FDTD复现Science正刊:二次谐波产生的奇妙之旅
FDTD复现Science正刊,二次谐波产生 嘿,大家好!今天来聊聊用FDTD方法复现Science正刊中二次谐波产生的相关研究,这可是个超有趣的领域。 什么是二次谐波产生? 二次谐波产生(Second Harmonic Generation&a…...

DeepSeek-Coder-V2本地化部署指南:构建企业级代码智能助手
DeepSeek-Coder-V2本地化部署指南:构建企业级代码智能助手 【免费下载链接】DeepSeek-Coder-V2 DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence 项目地址: https://gitcode.com/GitHub_Trending/de/DeepSeek-Coder-V2 …...

ai辅助开发新体验:在快马平台用对话创建智能天气应用
最近在做一个天气应用的小项目时,遇到了一个很实际的问题:GitHub经常打不开,导致想参考的开源代码库无法访问。这时候,我发现InsCode(快马)平台的AI辅助开发功能简直是个救星,完全改变了我的开发方式。 需求分析阶段 以…...

针对C++开源项目的AI工具讲解。我将它们分为两大类,便于理解
以下是针对C开源项目的AI工具讲解。我将它们分为两大类,便于理解: C开发者使用AI工具来提升开源项目开发效率(代码补全、调试、重构、文档生成等)。用C开发的开源AI工具/框架(这些工具本身是C开源项目,常用…...

模型蒸馏与量化:为什么大厂急需能把大模型跑在边缘端的SDE?
在2026年的北美科技求职市场中,人工智能的下半场战役已经悄然转移了阵地。当行业内绝大多数求职者还在简历上堆砌“熟练调用大语言模型API”或“基于LangChain构建应用”时,北美头部科技公司(如Apple、Google、Meta)的招聘重心已经…...

别再死记硬背了!用‘借位法’5分钟搞定子网划分,网工面试必看
别再死记硬背了!用‘借位法’5分钟搞定子网划分,网工面试必看 刚入行的网络工程师最怕什么?十个人里有九个会说是子网划分。那些密密麻麻的二进制数字、复杂的计算公式,简直像天书一样让人望而生畏。但今天我要告诉你一个秘密&…...

别再只用NodePort了!手把手教你用MetalLB在本地K8s集群实现LoadBalancer服务暴露
突破本地Kubernetes限制:MetalLB实现LoadBalancer全实战指南 当你第一次在本地Minikube或自建Kubernetes集群中尝试创建LoadBalancer类型的Service时,那个永恒的"Pending"状态是否让你感到困惑?云厂商提供的LoadBalancer服务在本地…...

【AI智能体】Dify 实战:构建企业级自然语言SQL查询引擎
1. 从个人工具到企业级解决方案的跨越 第一次接触Dify的自然语言转SQL功能时,我被它的便捷性惊艳到了。只需要输入"显示上季度销售额最高的产品",系统就能自动生成正确的SQL语句。但当我尝试在团队中推广使用时,各种问题接踵而至&a…...