DTCC 2023丨云原生环境下,需要什么样的 ETL 方案?
2023年8月16日~18日,第14届中国数据库技术大会(DTCC 2023)于北京隆重召开,拓数派受邀参与本次大会,PieCloudDB 技术专家邱培峰在大会做了《云原生虚拟数仓 PieCloudDB ETL 方案设计与实现》的主题演讲,详细介绍了 PieCloudDB 的 ETL 方案总体设计与实现,分析了 ETL 工具 pdbconduct 及相关数据库内核扩展。

对于数据库用户而言,ETL 的重要性不言而喻。 ETL( Extract, Transform, Load ),即数据的抽取、转换和加载,简单理解为数据库的数据导入过程。ETL 的本质是不同系统(数据组织形式)之间的数据移动。ETL 的过程有助于数据库用户实现数据的高效管理和优化。它确保数据库中的数据不仅仅是存储在其中,还经过了精心的处理,以满足用户的需求。
1 云原生环境下的 ETL
随着云原生时代的到来,经济实惠且可轻松扩展的对象存储解决方案成为满足用户对高弹性、高性价比需求的首选。传统 ETL(Extract, Transform, Load)是一种将数据从源系统抽取、清洗、转换,最后加载到目标系统中进行分析的过程。传统 ETL 的特点是吞吐量大,批量加载性能非常好,缺点是对源端和目标系统影响较大,通常是在非业务高峰进行,因而会有较大的数据延迟,通常为 T+1。
CDC(Change Data Capture)是指实时或者准实时捕获数据库或文件系统中发生变化的数据,并将其同步到其他数据系统中,同时确保数据的一致性和准确性。CDC 通常通过解析源端日志的方式实现,对源系统影响较小,且有较低的时延。但对目标系统,尤其是分析性数据库,相比于批量模式,会带来较大的数据更新开销。即使如此,CDC 方式在数据同步方面应用越来越广泛;同样的,传统的 ETL 模式在很多场景仍有不可替代的优势。
无论 ETL 还是 CDC 都是把数据复制作为目标的,因此不可避免的会造成一定程度的数据冗余,也存在造成数据不一致的风险;而基于湖仓技术的一写多读,zero-ETL 等技术可以完全消除数据复制造成潜在冗余和不一致风险。统一 ETL、CDC 和湖仓技术正是 PieCloudDB Database 的 ETL 方案的目标之一。
PieCloudDB 存算分离的架构使得不同系统可以直接共享同一份底层数据,避免了繁琐的数据抽取、转换和加载过程。目前,PieCloudDB 支持直接读取对象存储上的 Parquet 等格式的文件,实现了数据共享和访问方面提供了便捷性。
某些实际场景下会产生 ETL 需求,例如同一份底层原始数据使用不同系统查询时,或为不同类型的查询特化的系统会有不同的存储方式等。因此,在进行 ETL 的方案设计时需要考虑以下几个要素:
- 多种数据源:需要考虑不同系统和数据源(如生产 IoT 数据)的多样性,确保能够从不同来源(事务型数据库,HDFS,Kafka 等)抽取数据,应对不同系统的数据接入需求。
- 多种数据格式:数据可能以多种格式存在:如 CSV、JSON、Parquet、二进制等。确保 ETL 流程具备处理不同格式数据的能力,能够解析、转换和统一这些数据以适应目标系统的要求。
- 通用的数据处理/转换:使数据能够被规范地清洗、加工和转换,以满足不同系统的需要。这将提高数据质量并减少冗余的转换逻辑。
- 唯一性和事务性保证:确保在数据加载过程中维护数据的唯一性和事务性。避免重复数据的导入,同时在 ETL 过程中实现事务控制,确保数据的完整性。
- 断点续传:在 ETL 过程中,通过记录和恢复处理状态,避免数据丢失或重复处理。
- 错误处理:能够捕获、记录和处理在 ETL 过程中出现的错误,包括数据格式错误、连接问题等,保证数据的完整性和可靠性。
这些要素的设计将帮助确保数据在从抽取到加载的整个过程中得到适当处理,为数据驱动的决策和分析提供坚实的基础。
2 PieCloudDB ETL 方案总体设计与实现
2.1 PieCloudDB ETL 方案的总体设计
充分考虑到云原生时代的ETL需求,PieCloudDB 的 ETL 方案总体设计主要包括三个方面:
- 任务调度总控 pdbconduct:在 ETL 流程中,任务的调度和协调由 pdbconduct 负责。pdbconduct 充当着总控角色,管理任务的排程、执行顺序和依赖关系。通过 pdbconduct ,不同的 ETL 任务可以被智能地调度,确保整个数据流程的有效运行。
- 数据源提取(插件/客户端工具):数据源提取阶段涉及从业务系统的原始数据库中获取数据。这需要开发插件和工具,以确保从业务系统中高效导出数据。这些插件和工具能够与不同业务系统进行连接,从中抽取数据,然后将其转换成适合 ETL 流程的格式。
- 计算节点 Foreign Table 和 Formatter 解耦:在计算节点上运行Foreign Table 是 ETL 过程的核心。这一步骤将从业务系统中提取的数据传输到 PieCloudDB 中,并在计算节点上维护不同的数据格式。Foreign Table 允许将数据映射到数据库表中,为数据的转换和处理创造了环境。
通过这三个方面的设计,PieCloudDB 的 ETL 方案能够实现任务的有效调度、从业务系统提取数据以及在计算节点上处理数据的目标。整个流程确保了数据从业务系统到 PieCloudDB 的顺畅传输,并为数据的转换和处理提供了必要的基础。这使得数据在被集成、转换和加载的过程中保持了准确性和一致性,为后续分析和应用提供了高质量的数据资源。
2.2 PieCloudDB ETL 执行流程
当在 PieCloudDB 上开启 ETL 任务时,具体流程如下图所示:
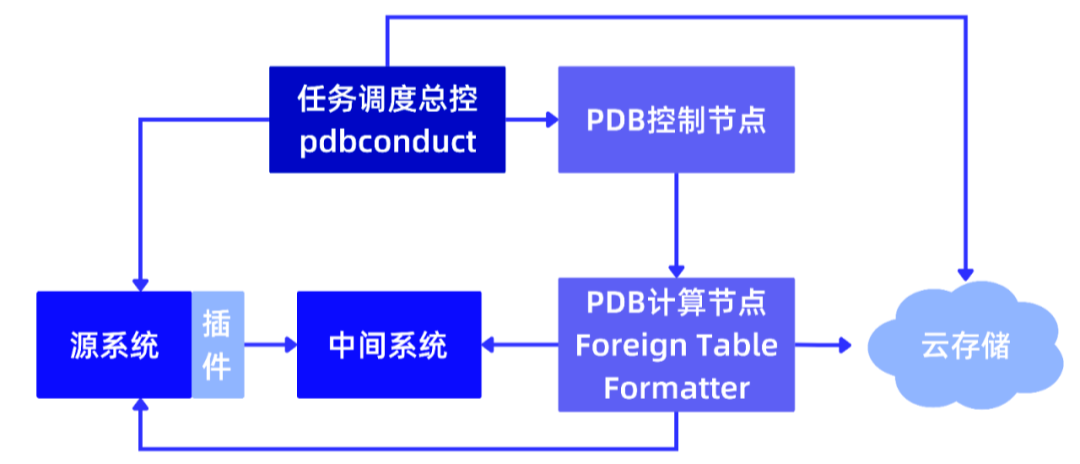
- 源系统连接和数据提取:首先,与源系统建立连接,执行 SQL 查询或其他高频操作,以提取所需数据。这一步骤有助于从源系统获取需要进行 ETL 的数据。
- 数据传输到中间系统:提取的数据可以直接传输到中间系统,其中中间系统可以是源系统的本地磁盘、PieCloudDB 的磁盘,或者其他中间存储位置。这一步骤有助于临时存储数据,以便后续处理。
- 中间系统处理:中间系统可能是云存储或服务器(例如 Kafka),具体选择根据业务场景的需要进行配置。在中间系统中,为后续的 Foreign Table 准备数据。
- Foreign Table 连接:在准备好的数据上,通过 Foreign Table 的连接机制,将数据映射到 PieCloudDB 中。这一步骤使得数据可以在 PieCloudDB 的环境下被进一步处理和分析。
- 数据加载及验证:可以进行数据的转换和处理 ,同时确保云存储上的文件是否符合预期,进行必要的验证和检查,以确保数据的完整性和正确性。
根据业务需求,任务调度总控 pdbconduct 会在适当的时间按需触发 ETL 任务,从源系统中提取所有需要进行处理的数据。这一步确保所需数据可用于后续的处理。
一旦数据导出完成,pdbconduct 将相应的 SQL 语句发送到 PieCloudDB 的控制节点。这些 SQL 语句可能包括数据转换、加载或其他操作,以准备数据进入 PieCloudDB 的环境。
在 PieCloudDB 控制节点执行 SQL 语句后,pdbconduct 收集执行结果,记录任务的进度以及任何可能的错误信息。这可以帮助监测任务的状态,并在出现问题时迅速采取适当的措施。如果在执行过程中出现错误,pdbconduct 将记录所有错误信息,并根据需要采取相应的补救措施。
2.3 INSERT/MERGE 模式
PieCloudDB 的 ETL 支持 INSERT 和 MERGE 两种常见的数据处理模式。用户可以根据业务需求、数据更新频率、和数据变化情况选择 INSERT 模式或 MERGE 模式。
2.3.1 INSERT 模式
INSERT 模式是将源系统中的数据直接插入到 PieCloudDB 中的一种模式。在这种模式下,从源系统中提取的数据会被逐行或逐批插入到 PieCloudDB 中的对应表中。INSERT 模式适用于对数据进行批量导入,或者当数据变化较小,且新增记录为主要操作时。INSERT 模式的优势在于简单直接,支持单纯的导入场景,特别擅长与现有数据没有逻辑关联的时序数据流
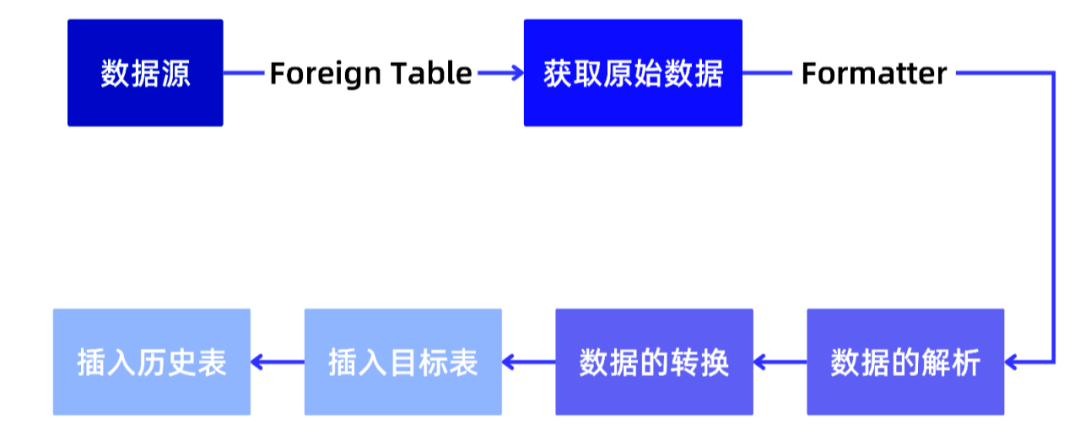
- 步骤 1:获取原始数据
首先,针对特定的数据源,需要开发适配器或插件,以便 PieCloudDB 能够连接到该数据源。可能需要开发 PostgreSQL 扩展来支持数据源的通信和数据格式解析。
接着,控制节点将读取数据源信息(包括连接参数、认证信息、数据抽取规则等),决定是否将任务进行拆分来提高并发性和效率,接着生成任务信息(查询语句、任务依赖关系等)。最后,计算节点根据任务信息读取数据源,并将原始数据和元信息返回给控制节点。
通过这些步骤,INSERT 模式下的 ETL 流程将数据从数据源中获取,并通过 Foreign Table 的方式插入到 PieCloudDB 中。
CREATE FOREIGN TABLE foreign_table(meta text, raw bytea);
SELECT meta, raw FROM foreign_table; - 步骤 2:数据的准备和解析
经过步骤 1,从 Foreign Table 中获取的原始数据需要经过解析和转换,以适应内部行格式。而这个转换过程通常是通过 Formatter 完成的。
PieCloudDB Formatter 会先对 Foreign Table 中获得的原始数据进行解析,根据数据的格式(如 CSV,JSON,XML 等),将原始数据分解成可操作的数据单元(字段、行、列等)。
接着,PieCloudDB Formatter 会将解析后的数据进行转换,以适应 PieCloudDB 的内部的行格式,生成需要的各列。
CREATE FUNCTION formatter(input bytea) RETURNS user_type …;
SELECT meta, raw FROM foreign_table
LATERAL JOIN formatter(raw); - 步骤 3:数据的转换
在步骤 3 中,会对步骤 2 中解析出的列执行数据转换操作,以确保数据的准确性和一致性,使数据能够顺利插入 PieCloudDB 表中,为后续的分析和应用提供可靠的数据基础。
SELECT r.a, r.b+r.c, func(r.d) … FROM (SELECT meta, raw FROM foreign_table
LATERAL JOIN formatter(raw) AS r) sub; - 步骤 4:插入目标表
经过前面三个步骤,数据已经完成了准备和转换,此时,将在步骤 4 中完成插入目标表。
INSERT INTO table
SELECT r.a, r.b+r.c, func(r.d) … FROM (SELECT meta, raw FROM foreign_table
LATERAL JOIN formatter(raw) AS r) sub; - 步骤 5:插入历史表,支持断点续传
最后,为了支持断点续传,会将数据插入历史表,以保存数据的变更历史(新增、更新和删除操作),从而实现对断点续传的支持。
INSERT INTO history
SELECT meta FROM foreign_table;2.3.2 MERGE 模式
PieCloudDB 的 ETL MERGE/UPSERT 模式支持 CDC(Change Data Capture)场景。这种模式可处理具有操作类型、逻辑主键和顺序键的数据,以实现数据的插入、更新和删除操作。
在MERGE模式下,数据需要包含操作字段(OP,即 INSERT/UPDATE/DELETE)、逻辑主键和顺序键。当逻辑主键不存在时,模式会执行 INSERT 操作;当逻辑主键已存在时,会执行更新或删除操作。顺序键用于确定操作的顺序,在处理多个操作时,根据顺序键确定操作的执行顺序,以防止操作间的冲突。MERGE 模式允许处理重复数据,但不可以有事务逻辑错误。
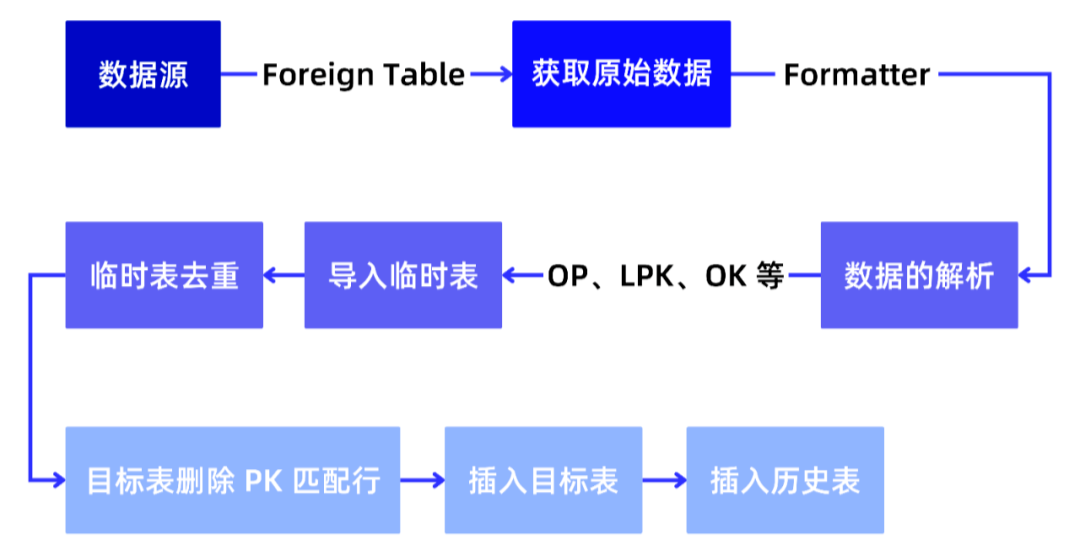
- 步骤 1:数据解析和导入临时表
首先,从外部数据源获取的原始数据经过解析,以获取包含操作字段(OP)、逻辑主键(LPK)和顺序键(OK)等的数据。接着将解析后的数据导入到与目标表类型相同的临时表中。这个临时表用于存储待合并和更新的数据。
SELECT r.a, r.b+r.c, func(r.d) … FROM (SELECT meta, raw FROM foreign_table
LATERAL JOIN formatter(raw) AS r) parsed; - 步骤 2:临时表内部去重
在临时表内部,对于具有相同逻辑主键(LPK)的行,根据顺序键(OK)选择保留 OK 最大的那行,确保只保留顺序键最大的唯一记录。
INSERT INTO temp_table
SELECT all_columns FROM ( SELECT *, row_number() OVER PARTITION BY lek
ORDER BY ok DESC FROM parsed
) AS no_dup WHERE no_dup.row_number = 1; - 步骤 3:目标表删除 PK 匹配行
在目标表中,根据逻辑主键(LPK)进行匹配,删除与临时表中的数据具有相同逻辑主键的记录。这确保了数据的更新操作。
DELETE FROM table USING temp_table
WHERE table.pk = temp_table.pk; - 步骤 4:插入目标表,完成 merge
将经过去重和操作处理后的数据插入到目标表中,完成数据的合并和更新。插入操作可能涉及 INSERT、UPDATE 或 DELETE 操作,根据数据的操作字段(OP)决定。
INSERT INTO table SELECT all_columns
FROM temp_table; 在完成 MERGE 后,同 INSERT 模式一样,会记录历史信息,这里就不再赘述。
最后,让我们通过一段视频讲解及 demo 更加具象地了解一下这个过程。
相关文章:
DTCC 2023丨云原生环境下,需要什么样的 ETL 方案?
2023年8月16日~18日,第14届中国数据库技术大会(DTCC 2023)于北京隆重召开,拓数派受邀参与本次大会,PieCloudDB 技术专家邱培峰在大会做了《云原生虚拟数仓 PieCloudDB ETL 方案设计与实现》的主题演讲,详…...

在UE4虚幻引擎中加入导航网格体边界体积后丧尸不能移动和发现玩家
UE4系列文章目录 文章目录 UE4系列文章目录前言一、用到的知识点二、问题原因 前言 最近使用ue4做第一人称视角射击游戏发现问题,加入导航网格体边界体积后丧尸不能移动和发现玩家。下图是出现的问题图片 一、用到的知识点 1.行为树:控制并显示AI的决…...

华为数通方向HCIP-DataCom H12-821题库(单选题:221-240)
第201题 BGP 协议用 beer default-route-advertise 命令来给邻居发布缺省路由,那么以下关于本地 BGP 路由表变化的描述,正确的是哪一项? A、在本地 BGP 路由表中生成一条活跃的缺省路由并下发给路由表 B、在本地 BGP 路由表中生成一条不活跃的缺省路由,但不下发给…...
aarch64 arm64 部署 stable diffusion webui 笔记 【1】准备 venv 安装pytorch 验证cuda
aarch64 pytorch(没有aarch64对应版本,自行编译) pytorch-v2.0.1 cuda arm64 aarch64 torch 2.0.1cu118 源码编译笔记【2】验证cuda安装 成功_hkNaruto的博客-CSDN博客 创建venv [rootceph3 stable-diffusion-webui]# /usr/local/Python-3.10.12/bin/python3 -m v…...

从方法到目标了解什么是机器学习?
一、什么是机器学习 1、简述 机器学习是 人工智能(AI) 和计算机科学的一个分支,专注于利用数据和算法来模仿人类的学习方式,逐步提高其准确性。过去几十年来,存储和处理能力方面的技术进步催生了一些基于机器学习的创新产品,例如 Netflix 的推荐引擎和自动驾驶汽车。 机…...
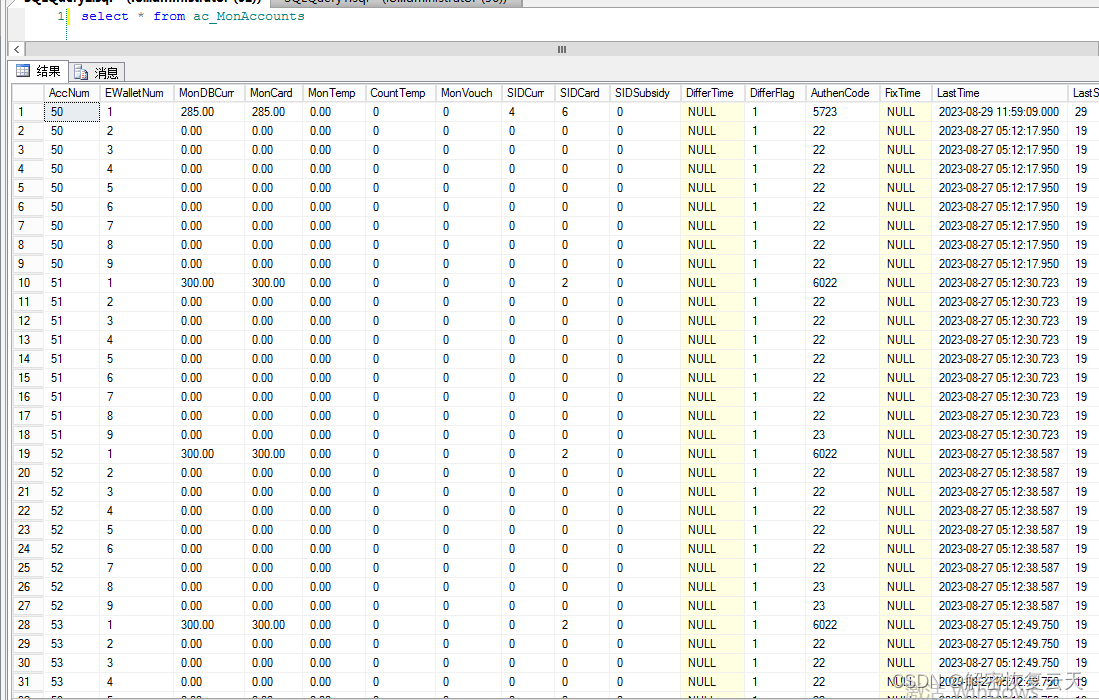
Devos勒索病毒:网络安全的新威胁,勒索病毒解密,数据恢复
随着信息技术的飞速发展,网络安全问题日益凸显。近年来,一种名为Devos的勒索病毒在全球范围内肆虐,给企业和个人带来了极大的损失。本文将详细介绍Devos勒索病毒的特点、传播途径以及预防和应对措施,帮助大家更好地认识和防范这一…...

go语言的高级特性
go语言调用C语言 go tool cgo main.go...

华为VRP系统基本操作
1.实验目的 掌握一些常见的路由命令。 2.实验步骤 查看设备版本信息 display version 修改设备的名字 进入系统视图 system-view修改设备名称 sysname Datacom-Router进入接口视图 int g0/0/1进入到接口GigabitEthernet0/0/1的视图 interface GigabitEthernet 0/0/1dis…...

Milvus Cloud扩展变更:为向量数据库注入前沿增强功能
在向量数据库的不断变化中,Milvus Cloud已成为一个改变游戏规则的先锋,革新了我们存储、搜索和分析复杂向量数据的方式。通过最新版本的Milvus Cloud2.3.0,引入了一系列重要的增强和修改,为更强大、更高效的向量数据库解决方案铺平了道路。在本文中,我们将深入探讨Milvus …...

外观模式简介
概念: 外观模式(Facade Pattern)是一种结构型设计模式,它提供了一个统一的接口,用于访问子系统中的一组接口。外观模式隐藏了子系统的复杂性,并将其封装在一个简单易用的接口中,使得客户端可以…...
web pdf 拖拽签章
web pdf 拖拽签章 主要通过火狐的pdfjs 来实现 1. 下载js 并编译 地址 https://mozilla.github.io/pdf.js/ 按照官网当下下载并编译就得到了js 2.其实也没有什么好讲的,都是用的js中的方法,官网中都有 按照步骤就能生成一个document元素,然…...

SQLAlchemy 库创建数据库引擎和会话工厂附带SQLSERVER驱动版本确认方式
SQLAlchemy 库创建数据库引擎和会话工厂 from sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker# 创建数据库引擎 engine create_engine(mssqlpyodbc://user:passhost:port/database?driverODBCDriver11forSQLServer)# 创建会话工厂 Session sess…...
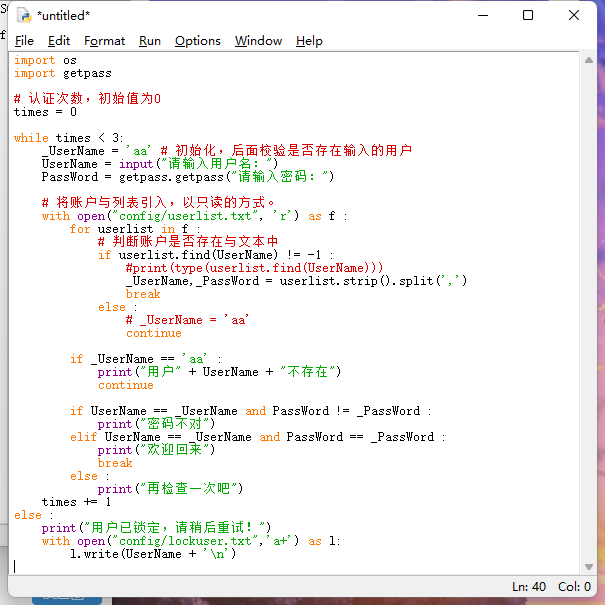
用Python登录账户
1 问题 如何利用python登录账户? 2 方法 账户和密码存放在文件夹中从文件夹中读取并比较密码密文验证三次后,如不成功则锁定用户 通过。。。。。。。。等证明提出的方法是有效的,能够解决开头提出的问题。 代码清单 1 import osimport getpas…...

梳理下我自已对Reactor与及IO多路复用的select\poll\epoll的理解
Reactor是一种设计思想的落地,其中IO多路复用的具体落地:select\poll\epoll。都是基于Reactor的延伸。它的核心是Reactor与资源处理器。Reactor负责监听与事件的分发,事件包括连接事件、读事件、写事件。 具体的流程是系统调用监听请求&…...

4. 广播变量
一、分区规则(DataStream Broadcast)和广播变量(Flink Broadcast) 1.1 DataStream Broadcast(分区规则) 分区规则是把元素广播给所有的分区,数据会被重复处理。 DataStream.broadcast()1.…...
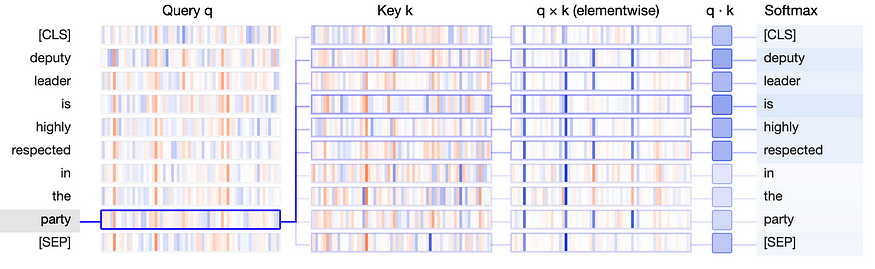
GPT 内部 — I : 了解文本生成
年轻的陀思妥耶夫斯基被介绍给生成AI,通过Midjourney创建 一、说明 我经常与不同领域的同事互动,我喜欢向几乎没有数据科学背景的人传达机器学习概念的挑战。在这里,我试图用简单的术语解释 GPT 是如何连接的,只是这次是书面形式。…...

平板触控笔哪款好用?好用的第三方apple pencil
而对于那些把ipad当做学习工具的人而言,苹果Pencil就成了必备品。但因为苹果Pencil太贵了,不少的学生们买不起。因此,最佳的选择还是平替电容笔,今天在这里整理了一些高性价比的电容笔! 一、挑选电容笔的要点…...

Mac 上更新系统PATH环境变量
目录 为什么要更新系统的PATH环境变量如何更新系统的PATH环境变量1. 确保你知道工具的实际安装位置。2. 将目录(实际安装位置)添加到PATH:export PATH$PATH:/path/to/your/tools补充:通过以下方法来确定当前正在使用的是Bash还是Z…...

Visual Studio Code 终端配置使用 MySQL
Visual Studio Code 终端配置使用 MySQL 找到 MySQL 的 bin 目录 在导航栏中搜索–》服务 找到MySQL–>双击 在终端切换上面找到的bin目录下输入指令 终端为Git Bash 输入命令 ./mysql -u root -p 接着输入密码,成功在终端使用 MySQL 数据库。...

12 | 使用 Spark SQL执行CURL
Spark SQL 是 Apache Spark 生态系统中的一个组件,它提供了用于结构化数据处理和分析的高级接口。Spark SQL 可以让用户使用 SQL 语言来查询和操作数据,同时也提供了强大的分布式计算能力。下面是关于 Spark SQL、SparkSession 和 DataFrame 的关键点: 1. Spark SQL: 定义…...

学术写作“变形记”:书匠策AI如何让课程论文从“青铜”变“王者”——解锁AI时代论文写作新姿势
论文写作,曾是无数学生的“噩梦”:选题撞车、文献堆积如山、逻辑混乱如麻、格式调整让人抓狂……如今,随着人工智能技术的爆发,学术写作的“游戏规则”正在被彻底改写。书匠策AI(官网:www.shujiangce.com&a…...

TradingAgents-CN智能交易系统:3种部署方案让你5分钟开启AI投资分析
TradingAgents-CN智能交易系统:3种部署方案让你5分钟开启AI投资分析 【免费下载链接】TradingAgents-CN 基于多智能体LLM的中文金融交易框架 - TradingAgents中文增强版 项目地址: https://gitcode.com/GitHub_Trending/tr/TradingAgents-CN 还在为复杂的金融…...

可视掏耳勺哪个牌子好?用什么掏耳朵最好?掏耳勺神器新款第一名
用什么掏耳朵最好?如今耳道护理成为家庭日常刚需,可视掏耳勺凭借“边看边清洁”的核心优势,彻底解决了传统盲掏易戳伤耳道、推深耳垢的痛点,成为越来越多人的首选。但当前可视掏耳勺市场陷入参数内卷,不少品牌盲目追求…...

Ubuntu系统资源监控实战:从命令行到图形化工具全解析
1. 为什么需要监控Ubuntu系统资源? 刚装好的Ubuntu系统跑得飞快,用着用着突然发现电脑变卡了?浏览器开多几个标签页就开始转圈?这种情况我遇到过太多次了。后来才发现,很多时候是因为某个程序偷偷吃掉了大量CPU或内存资…...

万象视界灵坛快速部署:GitLab CI流水线自动触发镜像构建与K8s滚动更新
万象视界灵坛快速部署:GitLab CI流水线自动触发镜像构建与K8s滚动更新 1. 项目概述 万象视界灵坛(Omni-Vision Sanctuary)是一款基于OpenAI CLIP技术的高级多模态智能感知平台。该平台通过创新的像素风格界面,将复杂的语义对齐过…...

2026论文写作工具红黑榜:一键生成论文工具怎么选?别再瞎找了!
2026年论文写作工具红黑榜出炉!红榜优先选千笔AI、ThouPen、豆包,适配国内学术规范,内容严谨可靠;黑榜需避开低质免费工具、无真实引用平台、过度依赖全文生成的工具。选择时可参考三维模型:需求匹配度 - 数据可信度 -…...

LoRA训练助手入门解析:为什么权重排序对LoRA训练效果影响显著
LoRA训练助手入门解析:为什么权重排序对LoRA训练效果影响显著 1. 认识LoRA训练助手 如果你正在尝试训练自己的AI绘画模型,可能会遇到一个常见问题:为什么同样的图片,用不同的标签训练出来的效果差距那么大?这就是我们…...

MedGemma-X精彩案例分享:自然语言提问触发的专业级影像分析报告
MedGemma-X精彩案例分享:自然语言提问触发的专业级影像分析报告 1. 重新定义智能影像诊断的新标杆 想象一下这样的场景:一位放射科医生面对堆积如山的X光片,只需要用自然语言问一句"这张胸片有没有肺炎迹象?"…...

intv_ai_mk11效果对比:同一Prompt下intv_ai_mk11与Qwen2.5在代码生成任务表现
intv_ai_mk11效果对比:同一Prompt下intv_ai_mk11与Qwen2.5在代码生成任务表现 1. 测试背景与目的 在当今AI技术快速发展的背景下,代码生成已成为大语言模型的重要应用场景之一。本次测试旨在对比intv_ai_mk11与Qwen2.5两款模型在相同Prompt下的代码生成…...

别再写死代码了!用MCP Tool模块5分钟搞定AI与数据库的安全对话
别再写死代码了!用MCP Tool模块5分钟搞定AI与数据库的安全对话 当AI模型需要与数据库交互时,开发者常面临两难选择:要么直接暴露数据库连接信息,要么编写大量胶水代码。这两种方案都存在明显缺陷——前者带来安全隐患,…...