GPT 内部 — I : 了解文本生成

年轻的陀思妥耶夫斯基被介绍给生成AI,通过Midjourney创建
一、说明
我经常与不同领域的同事互动,我喜欢向几乎没有数据科学背景的人传达机器学习概念的挑战。在这里,我试图用简单的术语解释 GPT 是如何连接的,只是这次是书面形式。
在ChatGPT流行的魔术背后,有一个不受欢迎的逻辑。你给 ChatGPT 写一个提示,它会生成文本,无论它是否准确,它都类似于人类的答案。它如何能够理解您的提示并生成连贯且易于理解的答案?请看本文。
二、变压器神经网络
该架构旨在处理大量非结构化数据,在我们的例子中是文本。当我们说架构时,我们的意思本质上是一系列并行在几层中进行的数学运算。通过这个方程组,引入了一些创新,帮助我们克服了长期存在的文本生成挑战。直到 5 年前,我们一直在努力解决的挑战。
如果 GPT 已经在这里存在了 5 年(确实 GPT 论文是在 2018 年发表的),那么 GPT 不是旧消息吗?为什么它最近变得非常受欢迎?GPT 1、2、3、3.5 (ChatGPT ) 和 4 有什么区别?
所有 GPT 版本都构建在相同的架构上。但是,每个后续模型都包含更多参数,并使用更大的文本数据集进行训练。显然,后来的 GPT 版本引入了其他新颖性,尤其是在训练过程中,例如通过人类反馈进行强化学习,我们将在本博客系列的第 3 部分中解释。
2.1 向量、矩阵、张量。
所有这些花哨的词本质上都是包含数字块的单位。这些数字经过一系列数学运算(主要是乘法和求和),直到我们达到最佳输出值,这是可能结果的概率。
输出值?从这个意义上说,它是语言模型生成的文本,对吧?是的。那么,输入值是什么?是我的提示吗?是的,但不完全是。那么背后还有什么呢?
在继续讨论不同的文本解码策略(这将是以下博客文章的主题)之前,消除歧义很有用。让我们回到我们一开始问的基本问题。它如何理解人类语言?
2.2 生成式预训练变压器。
GPT 缩写代表的三个词。我们触摸了上面的转换器部分,它代表了进行大量计算的架构。但是我们到底计算了什么?你甚至从哪里得到数字?它是一个语言模型,您要做的就是输入一些文本。如何计算文本?
数据是不可知的。所有数据都是相同的,无论是文本、声音还是图像形式。
2.3 令牌
我们将文本拆分为小块(令牌),并为每个块分配一个唯一的编号(令牌ID)。模特不认识文字、图像或录音。他们学会用大量的数字(参数)来表示它们,这可以作为我们以数字形式说明事物特征的工具。令牌是传达含义的语言单位,令牌 ID 是编码令牌的唯一数字。
显然,我们如何标记语言可能会有所不同。词汇化可能涉及将文本拆分为句子、单词、单词的一部分(子单词)甚至单个字符。
让我们考虑一个场景,我们的语言语料库中有 50,000 个代币(类似于 GPT-2 有 50,257 个)。标记化后我们如何表示这些单位?
Sentence: "students celebrate the graduation with a big party"
Token labels: ['[CLS]', 'students', 'celebrate', 'the', 'graduation', 'with', 'a', 'big', 'party', '[SEP]']
Token IDs: tensor([[ 101, 2493, 8439, 1996, 7665, 2007, 1037, 2502, 2283, 102]])上面是一个被标记成单词的示例句子。令牌化方法在实现上可能有所不同。对于我们现在来说,重要的是要了解我们通过其相应的令牌 ID 获取语言单位(标记)的数字表示。那么,现在我们有了这些令牌 ID,我们是否可以简单地将它们直接输入到进行计算的模型中?
基数在数学 101 和 2493 中很重要,因为令牌表示对模型很重要。因为请记住,我们所做的主要是大块数字的乘法和求和。因此,将数字乘以 101 或 2493 很重要。那么,我们如何确保用数字 101 表示的代币的重要性不亚于 2493,只是因为我们碰巧任意地标记了它?我们如何在不导致虚构排序的情况下对单词进行编码?
2.4 单热编码。
令牌的稀疏映射。独热编码是我们将每个令牌投影为二进制向量的技术。这意味着向量中只有一个元素是 1(“热”),其余元素是 0(“冷”)。

作者图片:独热编码向量示例
令牌用一个向量表示,该向量在我们的语料库中具有总令牌的长度。简单来说,如果我们的语言中有 50k 个令牌,则每个标记都由一个向量 50k 表示,其中只有一个元素为 1,其余元素为 0。由于此投影中的每个向量仅包含一个非零元素,因此将其命名为稀疏表示。但是,您可能认为这种方法效率非常低。是的,我们设法删除了令牌 ID 之间的人工基数,但我们无法推断有关单词语义的任何信息。我们无法通过使用稀疏向量来理解“派对”一词是指庆祝活动还是政治组织。此外,用大小为 50k 的向量表示每个代币将意味着总共 50k 个长度为 50k 的向量。这在所需的内存和计算方面效率非常低。幸运的是,我们有更好的解决方案。
2.5 嵌入。
令牌的密集表示形式。标记化单元通过嵌入层,其中每个标记都转换为固定大小的连续向量表示。例如,在 GPT 3 的情况下,中的每个标记都由 768 个数字的向量表示。这些数字是随机分配的,然后在看到大量数据(训练)后被模型学习。
Token Label: “party”
Token : 2283
Embedding Vector Length: 768
Embedding Tensor Shape: ([1, 10, 768])Embedding vector:tensor([ 2.9950e-01, -2.3271e-01, 3.1800e-01, -1.2017e-01, -3.0701e-01,-6.1967e-01, 2.7525e-01, 3.4051e-01, -8.3757e-01, -1.2975e-02,-2.0752e-01, -2.5624e-01, 3.5545e-01, 2.1002e-01, 2.7588e-02,-1.2303e-01, 5.9052e-01, -1.1794e-01, 4.2682e-02, 7.9062e-01,2.2610e-01, 9.2405e-02, -3.2584e-01, 7.4268e-01, 4.1670e-01,-7.9906e-02, 3.6215e-01, 4.6919e-01, 7.8014e-02, -6.4713e-01,4.9873e-02, -8.9567e-02, -7.7649e-02, 3.1117e-01, -6.7861e-02,-9.7275e-01, 9.4126e-02, 4.4848e-01, 1.5413e-01, 3.5430e-01,3.6865e-02, -7.5635e-01, 5.5526e-01, 1.8341e-02, 1.3527e-01,-6.6653e-01, 9.7280e-01, -6.6816e-02, 1.0383e-01, 3.9125e-02,-2.2133e-01, 1.5785e-01, -1.8400e-01, 3.4476e-01, 1.6725e-01,-2.6855e-01, -6.8380e-01, -1.8720e-01, -3.5997e-01, -1.5782e-01,3.5001e-01, 2.4083e-01, -4.4515e-01, -7.2435e-01, -2.5413e-01,2.3536e-01, 2.8430e-01, 5.7878e-01, -7.4840e-01, 1.5779e-01,-1.7003e-01, 3.9774e-01, -1.5828e-01, -5.0969e-01, -4.7879e-01,-1.6672e-01, 7.3282e-01, -1.2093e-01, 6.9689e-02, -3.1715e-01,-7.4038e-02, 2.9851e-01, 5.7611e-01, 1.0658e+00, -1.9357e-01,1.3133e-01, 1.0120e-01, -5.2478e-01, 1.5248e-01, 6.2976e-01,-4.5310e-01, 2.9950e-01, -5.6907e-02, -2.2957e-01, -1.7587e-02,-1.9266e-01, 2.8820e-02, 3.9966e-03, 2.0535e-01, 3.6137e-01,1.7169e-01, 1.0535e-01, 1.4280e-01, 8.4879e-01, -9.0673e-01,… … … ])上面是单词“party”的嵌入向量示例。
现在我们有 50,000x786 大小的矢量,相比之下,50,000x50,000 个独热编码的效率要高得多。
嵌入向量将是模型的输入。由于密集的数字表示,我们将能够捕获单词的语义,相似的标记的嵌入向量将彼此更接近。
如何在上下文中衡量两个语言单元的相似性?有几个函数可以测量相同大小的两个向量之间的相似性。让我们用一个例子来解释它。
考虑一个简单的例子,我们有标记“猫”、“狗”、“汽车”和“香蕉”的嵌入向量。为了简化起见,我们使用嵌入大小 4。这意味着将有四个学习的数字来表示每个令牌。
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity# Example word embeddings for "cat" , "dog", "car" and "banana"
embedding_cat = np.array([0.5, 0.3, -0.1, 0.9])
embedding_dog = np.array([0.6, 0.4, -0.2, 0.8])
embedding_car = np.array([0.5, 0.3, -0.1, 0.9])
embedding_banana = np.array([0.1, -0.8, 0.2, 0.4])
使用上面的向量,让我们使用余弦相似度来计算相似度分数。人类逻辑会发现“狗”和“猫”这个词比“香蕉汽车”这两个词彼此更相关。我们可以期望数学来模拟我们的逻辑吗?
# Calculate cosine similarity
similarity = cosine_similarity([embedding_cat], [embedding_dog])[0][0]print(f"Cosine Similarity between 'cat' and 'dog': {similarity:.4f}")# Calculate cosine similarity
similarity_2 = cosine_similarity([embedding_car], [embedding_banana])[0][0]print(f"Cosine Similarity between 'car' and 'banana': {similarity:.4f}")"Cosine Similarity between 'cat' and 'dog': 0.9832"
"Cosine Similarity between 'car' and 'banana': 0.1511"我们可以看到,单词“cat”和“dog”的相似度得分非常高,而单词“car”和“banana”的相似度得分非常低。现在想象一下,对于我们的语言语料库中的每 50000 个标记,嵌入长度为 768 而不是 4 个的向量。这就是我们如何找到彼此相关的单词的方式。
现在,我们来看看下面两个语义复杂度较高的句子。
"students celebrate the graduation with a big party""deputy leader is highly respected in the party"第一句和第二句中的“党”一词传达了不同的含义。大型语言模型如何能够区分作为政治组织的“政党”和作为庆祝社会活动的“政党”之间的区别?
我们能否通过 token 嵌入来区分同一个 token 的不同含义?事实是,尽管嵌入为我们提供了一系列优势,但它们不足以解决人类语言语义挑战的全部复杂性。
自我关注。变压器神经网络再次提供了解决方案。我们生成一组新的权重(参数的另一个名称),即查询矩阵、键矩阵和值矩阵。这些权重学习将标记的嵌入向量表示为一组新的嵌入。如何?只需取原始嵌入的加权平均值即可。每个标记“关注”输入句子中的每个其他标记(包括其自身),并计算一组注意力权重,或者换句话说,新的所谓“上下文嵌入”。
它所做的只是通过分配使用标记嵌入计算的新数字集(注意力权重)来映射输入句子中单词的重要性。

作者提供的图片:不同上下文中 token 的注意力权重(BertViz 注意力头视图)
上面的可视化用两句话展示了令牌“方”对其余令牌的“关注”。连接的大胆性表明了代币的重要性或相关性。注意和“出席”是指代一系列新的数字(注意参数)及其大小的术语,我们用它来用数字表示单词的重要性。在第一句中,“聚会”一词最关注“庆祝”一词,而在第二句中,“代表”一词最受关注。这就是模型如何能够通过检查周围的单词来合并上下文。
正如我们在注意力机制中提到的,我们推导出新的权重矩阵集,即:查询、键和值(简称 q,k,v)。它们是相同大小(通常小于嵌入向量)的级联矩阵,被引入到体系结构中以捕获语言单元的复杂性。学习注意力参数是为了揭开单词,单词对,单词对和单词对对等之间的关系的神秘面纱。下面是查找最相关单词的查询、键和值矩阵的可视化效果。
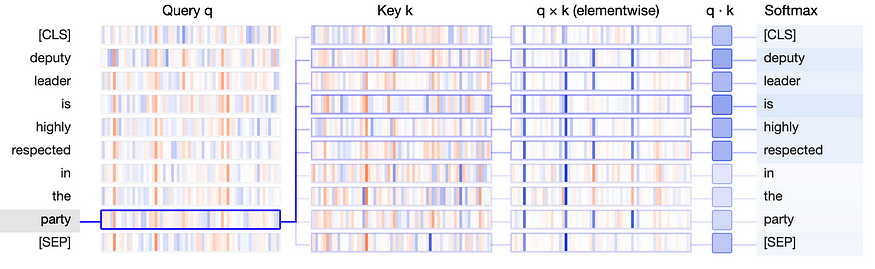
图片由作者提供:查询键值矩阵及其最终概率图示(BertViz q,k,v 视图)
可视化将 q 和 k 向量表示为垂直波段,其中每个波段的粗体反映了其幅度。令牌之间的连接表示由注意力决定的权重,表明“party”的q向量与“is”,“deputy”和“respected”的k向量最显着地对齐。
为了使注意力机制和q,k和v的概念不那么抽象,想象一下你去参加一个聚会,听到了一首你爱上的惊人歌曲。派对结束后,您渴望找到这首歌并再次收听,但您只记得歌词中的 5 个单词和歌曲旋律的一部分(查询)。要找到这首歌,您决定浏览派对播放列表(键)并收听(相似性功能)派对上播放的列表中的所有歌曲。当您最终认出这首歌时,您会记下歌曲的名称(值)。
转换器引入的最后一个重要技巧是将位置编码添加到向量嵌入中。仅仅因为我们想捕获单词的位置信息。它增强了我们更准确地预测下一个标记的机会,以达到真实的句子上下文。这是基本信息,因为经常交换单词会完全改变上下文。例如,“蒂姆追了一辈子的云”和“云追了蒂姆一辈子”这句话在本质上是绝对不同的。
到目前为止,我们在基本级别上探索的所有数学技巧,其目标是在给定输入令牌序列的情况下预测下一个令牌。事实上,GPT 是在一个简单的任务上进行训练的,即文本生成,或者换句话说,下一个令牌预测。问题的核心是,我们衡量代币的概率,给定它之前出现的代币序列。
您可能想知道模型如何从随机分配的数字中学习最佳数字。这可能是另一篇博客文章的主题,但这实际上是理解的基础。此外,这是一个很好的迹象,表明您已经在质疑基础知识。为了消除不明确性,我们使用了一种优化算法,该算法根据称为损失函数的指标调整参数。此指标是通过将预测值与实际值进行比较来计算的。该模型跟踪指标的机会,并根据损失值的大小调整数字。这个过程一直完成,直到给定我们在称为超参数的算法中设置的规则,损失不能更小。一个示例超参数可以是,我们想要计算损失和调整权重的频率。这是学习背后的基本思想。
我希望在这篇简短的文章中,我至少能够稍微清除图片。本博客系列的第二部分将重点介绍解码策略,即为什么您的提示很重要。第三部分也是最后一部分将专门讨论 ChatGPT 成功的关键因素,即通过人类反馈进行强化学习。非常感谢您的阅读。直到下次。
三、引用:
A.瓦斯瓦尼,N.沙泽尔,N.帕尔马,J.乌什科雷特,L.琼斯,A.N.戈麦斯,Ł。Kaiser和I. Polosukhin,“注意力是你所需要的一切”,神经信息处理系统进展30(NIPS 2017),2017。
J. Vig,“转换器模型中注意力的多尺度可视化”,计算语言学协会第 57 届年会论文集:系统演示,第 37-42 页,意大利佛罗伦萨,计算语言学协会,2019 年。
L. Tunstall、L. von Werra 和 T. Wolf,“使用变形金刚进行自然语言处理,修订版”,O'Reilly Media, Inc.,2022 年 9781098136796 月发布,ISBN:<>。
1 -懒惰的程序员博客
相关文章:
GPT 内部 — I : 了解文本生成
年轻的陀思妥耶夫斯基被介绍给生成AI,通过Midjourney创建 一、说明 我经常与不同领域的同事互动,我喜欢向几乎没有数据科学背景的人传达机器学习概念的挑战。在这里,我试图用简单的术语解释 GPT 是如何连接的,只是这次是书面形式。…...

平板触控笔哪款好用?好用的第三方apple pencil
而对于那些把ipad当做学习工具的人而言,苹果Pencil就成了必备品。但因为苹果Pencil太贵了,不少的学生们买不起。因此,最佳的选择还是平替电容笔,今天在这里整理了一些高性价比的电容笔! 一、挑选电容笔的要点…...

Mac 上更新系统PATH环境变量
目录 为什么要更新系统的PATH环境变量如何更新系统的PATH环境变量1. 确保你知道工具的实际安装位置。2. 将目录(实际安装位置)添加到PATH:export PATH$PATH:/path/to/your/tools补充:通过以下方法来确定当前正在使用的是Bash还是Z…...

Visual Studio Code 终端配置使用 MySQL
Visual Studio Code 终端配置使用 MySQL 找到 MySQL 的 bin 目录 在导航栏中搜索–》服务 找到MySQL–>双击 在终端切换上面找到的bin目录下输入指令 终端为Git Bash 输入命令 ./mysql -u root -p 接着输入密码,成功在终端使用 MySQL 数据库。...

12 | 使用 Spark SQL执行CURL
Spark SQL 是 Apache Spark 生态系统中的一个组件,它提供了用于结构化数据处理和分析的高级接口。Spark SQL 可以让用户使用 SQL 语言来查询和操作数据,同时也提供了强大的分布式计算能力。下面是关于 Spark SQL、SparkSession 和 DataFrame 的关键点: 1. Spark SQL: 定义…...
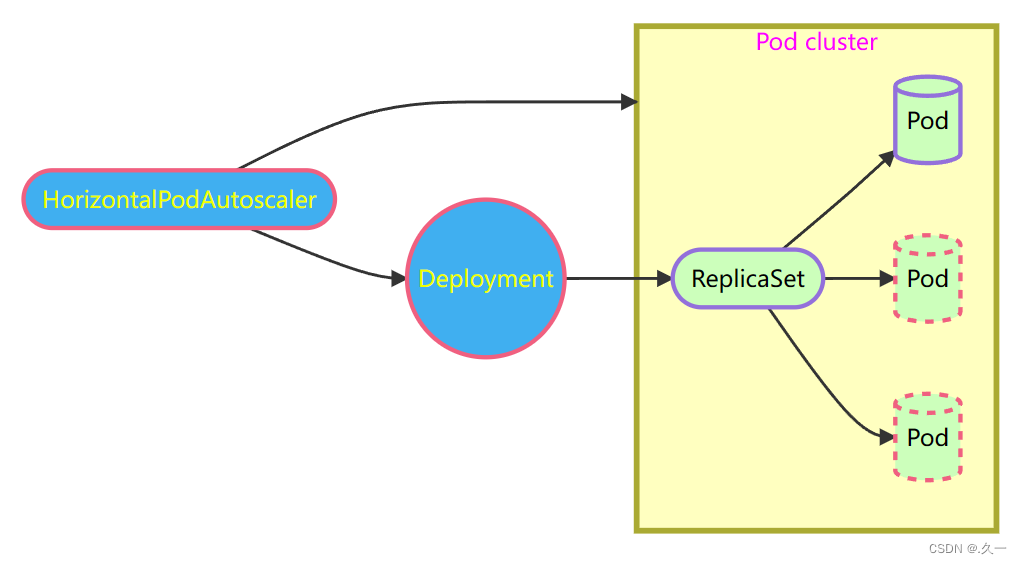
容器编排学习(七)控制器介绍与使用
一 控制器 控制器是 k8s内置的管理工具。可以帮助用户实现 Pod的自动部署、自维护、扩容、滚动更新等功能的自动化程序。 为什么要使用控制器? 有大量的 Pod需要维护管理需要维护 Pod的健康状态控制器可以像机器人一样可以替用户完成维护管理的工作 二 Deployment 1 概…...
一文看懂微信小程序新版隐私协议(附带弹窗组件)
一、前言 微信小程序近期又迎来了一次改革–9月15日之后如果小程序涉及调用微信的隐私接口获取用户的信息的,需要用户手动同意协议后才可正常调用接口,否则会返回报错信息。 隐私接口目前常用的有:手机号快捷获取、读取照片、获取用户的头像…...
Java认识异常(超级详细)
目录 异常的概念和体系结构 异常的概念 异常的体系结构 异常的分类 1.编译时异常 2.运行时异常 异常的处理 防御式编程 LBYL EAFP 异常的抛出 异常的捕获 异常声明throws try-catch捕获并处理 finally 异常的处理流程 异常的概念和体系结构 异常的概念 在Java中…...

危险边缘:揭示 Python 编程中易被忽视的四个安全陷阱
今天我们将要谈论一个非常重要的话题:Python 编程中的安全问题。作为一门广受欢迎的编程语言,Python 已经成为了许多开发者、计算机专业学生以及打工人的必备技能。 原文链接食用更佳 危险边缘:揭示 Python 编程中易被忽视的四个安全问题 然…...
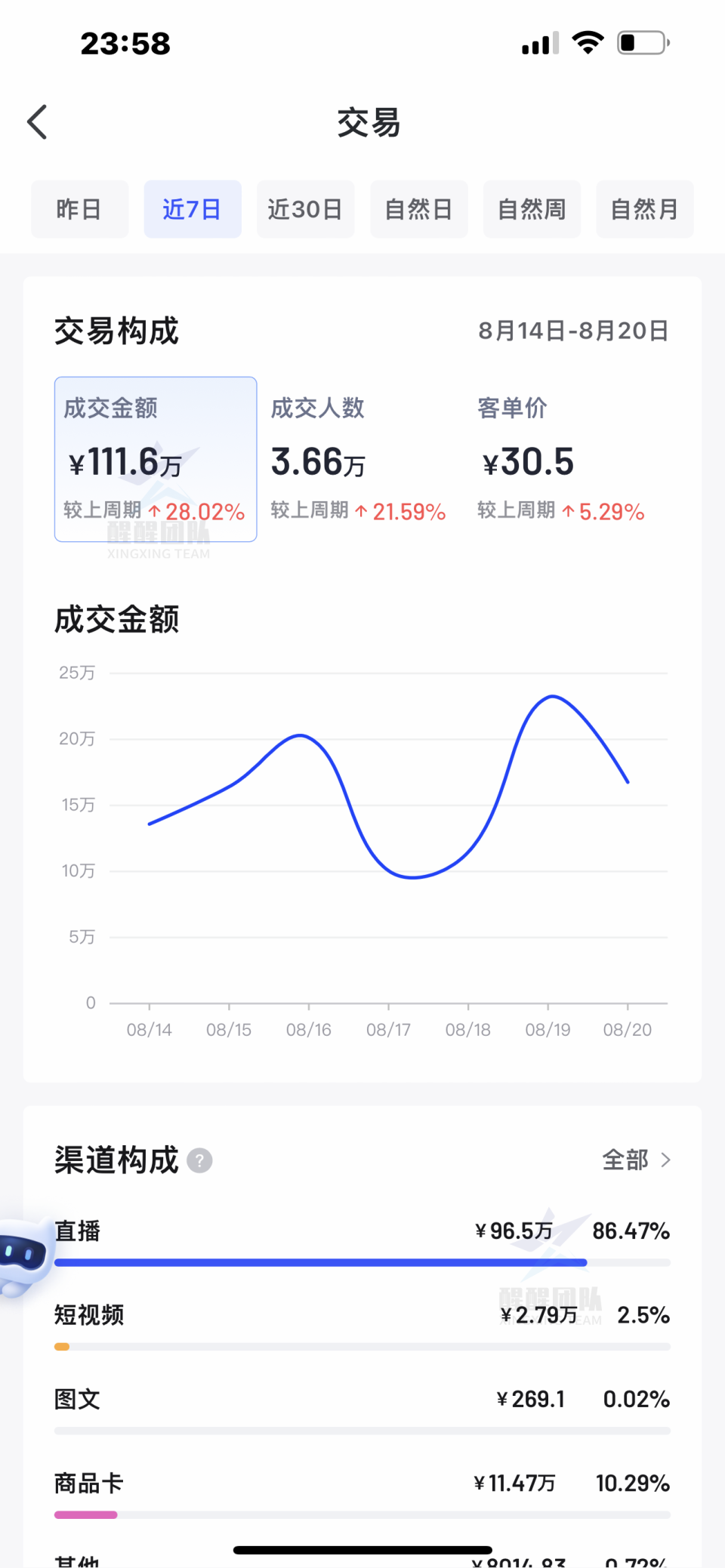
抖店开通后,新手必须要知道的几个做店技巧,建议认真看完
我是王路飞。 抖店的运营,无非就是围绕【产品】【流量】展开的。 你要是能把这两个点给搞明白,新店快速出单、真是爆单就不再是问题了。 今天就给你们说一下,抖店开通后,作为一个新手商家,你必须要知道的几个做店技…...
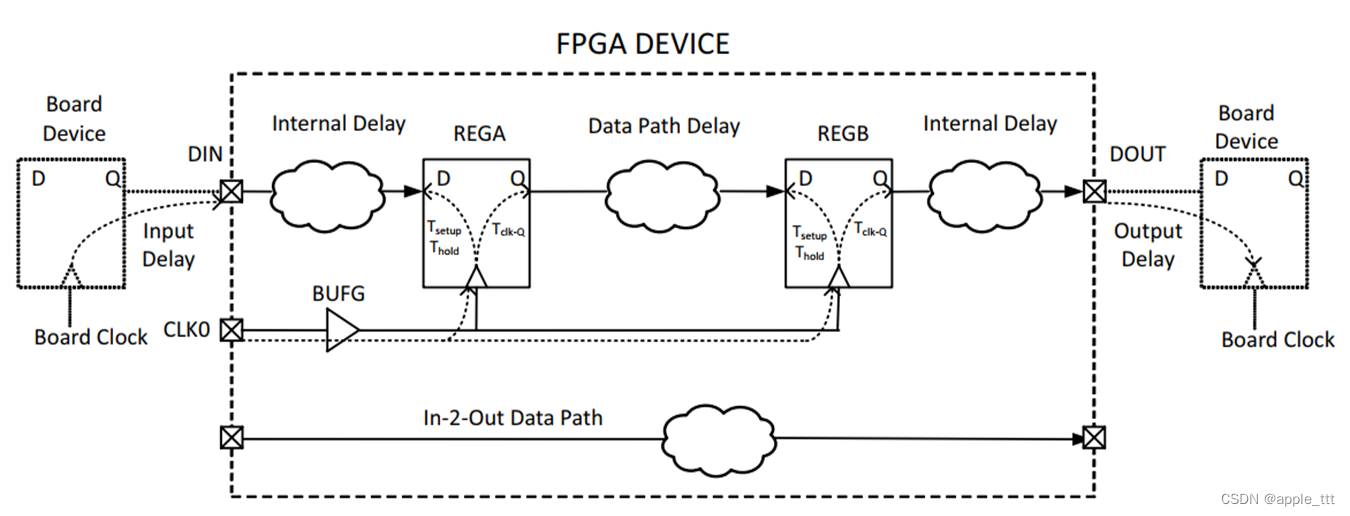
FPGA时序分析与约束(5)——时序路径
一、前言 在之前的文章中我们分别介绍了组合电路的时序,时序电路的时序和时钟的时序问题,我们也对于时序分析,时序约束和时序收敛几个基本概念进行了区分,在这篇文章中,我们将介绍时序约束相关的最后一部分基本概念&am…...

Flutter:构建跨平台应用的未来选择
随着移动设备的普及和技术的不断发展,跨平台移动应用开发成为了一个热门的需求。Flutter作为一款由Google开发的开源移动应用开发框架,受到了越来越多的关注。本文将带你了解Flutter的优势、应用场景以及如何使用Flutter进行开发。 一、Flutter的优势 …...
08_瑞萨GUI(LVGL)移植实战教程之LVGL对接串口打印
本系列教程配套出有视频教程,观看地址:https://www.bilibili.com/video/BV1gV4y1e7Sg 8. LVGL对接串口打印 本次实验我们为LVGL库对接串口的打印功能。 8.1 复制工程 上次实验得出的工程我们可以通过复制在原有的基础上得到一个新的工程。 如果你不清…...
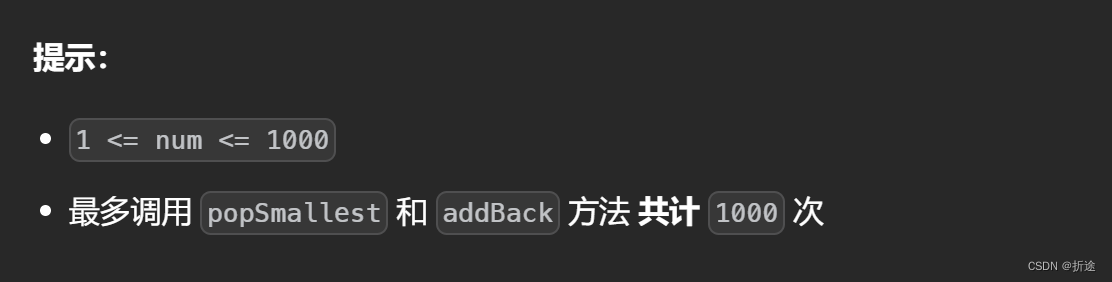
【LeetCode75】第五十题 无限集中的最小数字
目录 题目: 示例: 分析: 代码: 题目: 示例: 分析: 这是我们在LeetCode75里遇到的第二道设计类题目,难度比上一次的设计题目要难上一些。 题目假设我们拥有一个从1开始的无限集…...
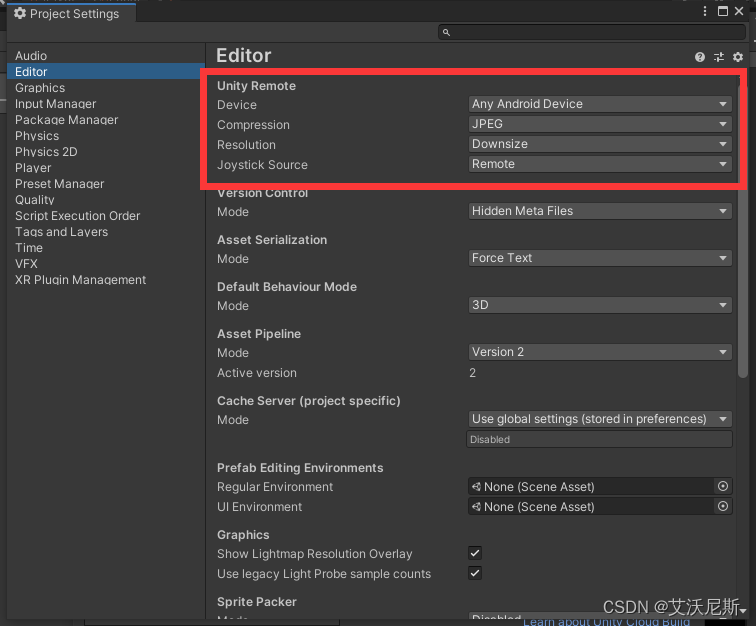
关于 Unity 连接 MuMu 模拟器上的 Unity Remote 5 的方法
在使用 Unity 开发 Android 的过程中,可以通过使用 Unity Remote 这个 app 来和真机连接,进而在真实环境下进行测试性能等工作,而本次则是由于其他问题引出的一个小坑,记录以备后续查询。 这次是由于在自学过程中遇到的一个工程&…...
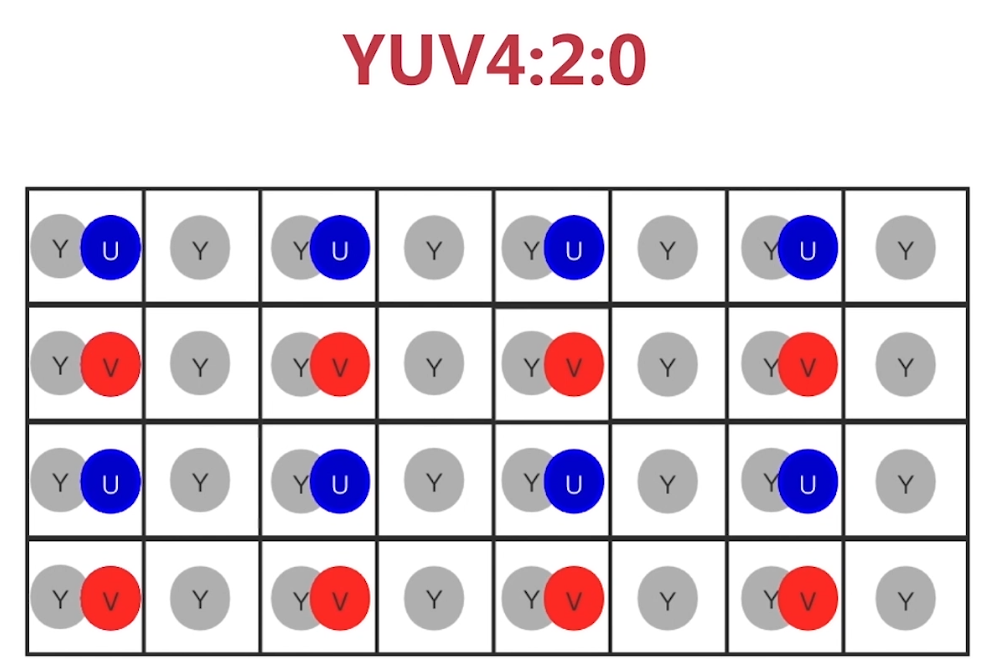
OpenCV 02(色彩空间)
一、OpenCV的色彩空间 1.1 RGB和BGR 最常见的色彩空间就是RGB, 人眼也是基于RGB的色彩空间去分辨颜色的. OpenCV默认使用的是BGR. BGR和RGB色彩空间的区别在于图片在色彩通道上的排列顺序不同. 显示图片的时候需要注意适配图片的色彩空间和显示环境的色彩空间.比如传入的图片…...
【动手学深度学习】--循环神经网络
文章目录 循环神经网络1.算法介绍1.1无隐状态的神经网络(多层感知机)1.2有隐状态的循环神经网络1.3基于循环神经网络的字符级语言模型1.4困惑度 2.RNN从零开始实现2.1读取数据集2.2独热编码2.3初始化模型参数2.4循环神经网络模型2.5预测2.6梯度裁剪2.7训练 3.RNN简洁实现3.1读取…...

快捷支付是什么?怎么申请支付接口?
快捷支付是什么?怎么申请支付接口? 快捷支付,又称电子支付或第三方支付,在行业中得到了广泛的应用。用户只需通过银行完成交易。方便快捷意味着银行可以在任何条件下支持用户之间的转账、支付和其他即时结算服务。快捷支付意味着…...

【MySQL】数据库基础知识
本文基于Linux的MySQL 文章目录 一. 什么是数据库二. 主流数据库三. 服务器,数据库和表的关系四. MySQL架构五. SQL语句分类结束语 一. 什么是数据库 数据库本质是对数据内容存储的一套解决方案 如何理解呢? 首先,说到数据内容存储ÿ…...

算法训练day36|贪心算法 part05(重叠区间三连击:LeetCode435. 无重叠区间763.划分字母区间56. 合并区间)
文章目录 435. 无重叠区间思路分析 763.划分字母区间思路分析代码实现思考总结 56. 合并区间思路分析 435. 无重叠区间 题目链接🔥🔥 给定一个区间的集合,找到需要移除区间的最小数量,使剩余区间互不重叠。 注意: 可以认为区间的…...

VIBE革命性视频人体姿态估计:CVPR2020获奖论文完整实现解析
VIBE革命性视频人体姿态估计:CVPR2020获奖论文完整实现解析 【免费下载链接】VIBE Official implementation of CVPR2020 paper "VIBE: Video Inference for Human Body Pose and Shape Estimation" 项目地址: https://gitcode.com/gh_mirrors/vi/VIBE …...

高效音频录制实战:如何为你的Web应用选择最佳编码方案
高效音频录制实战:如何为你的Web应用选择最佳编码方案 【免费下载链接】Recorder html5 js 录音 mp3 wav ogg webm amr g711a g711u 格式,支持pc和Android、iOS部分浏览器、Hybrid App(提供Android iOS App源码)、微信,…...
Unity3D物体缩放避坑指南:为什么你的Transform.localScale总是不生效?
Unity3D物体缩放避坑指南:为什么你的Transform.localScale总是不生效? 在Unity3D开发中,Transform.localScale属性看似简单,却隐藏着许多让开发者头疼的陷阱。不少开发者都遇到过这样的场景:明明代码里设置了localScal…...

如何使用USearch构建自动驾驶传感器数据的实时向量搜索系统
如何使用USearch构建自动驾驶传感器数据的实时向量搜索系统 【免费下载链接】usearch Fastest Open-Source Search & Clustering engine for Vectors & 🔜 Strings in C, C, Python, JavaScript, Rust, Java, Objective-C, Swift, C#, GoLang, and Wolfra…...
)
实战:用MAF的“人机协同”功能,给你的AI工具调用加上一道安全锁(附C#代码)
企业级AI代理安全实践:基于MAF的人机协同审批架构设计 当财务系统自动驳回了一笔高管差旅报销,或是订单管理系统未经确认修改了客户历史数据时,企业往往需要付出高昂的信任成本来修复这类"自动化事故"。Microsoft Agent Framework&…...

解锁高效无水印备份:抖音视频批量下载的完整指南
解锁高效无水印备份:抖音视频批量下载的完整指南 【免费下载链接】douyin-downloader 项目地址: https://gitcode.com/GitHub_Trending/do/douyin-downloader 直面内容管理痛点:三个真实用户的困境 场景一:学习资源的系统性流失 教…...
:3D重建模型压缩终极指南)
Torch-Pruning支持神经辐射场(NERF):3D重建模型压缩终极指南
Torch-Pruning支持神经辐射场(NERF):3D重建模型压缩终极指南 【免费下载链接】Torch-Pruning [CVPR 2023] Towards Any Structural Pruning; LLMs / Diffusion / Transformers / YOLOv8 / CNNs 项目地址: https://gitcode.com/gh_mirrors/to/Torch-Pruning 神…...

StructBERT情感分类实操手册:自定义示例文本添加方法
StructBERT情感分类实操手册:自定义示例文本添加方法 1. 引言:为什么需要自定义示例? 当你第一次打开StructBERT情感分类的Web界面,可能会觉得它已经内置了不少例子,用起来挺方便。但用着用着,你就会发现…...

OWL ADVENTURE应用场景解析:如何用AI助手提升工作效率
OWL ADVENTURE应用场景解析:如何用AI助手提升工作效率 1. 为什么选择OWL ADVENTURE作为AI助手 在当今快节奏的工作环境中,我们每天都要处理大量视觉信息——从产品图片到数据图表,从设计稿到文档扫描件。传统的工作流程往往需要人工逐一查看…...

ScintillaNET:打造专业级代码编辑器的终极Windows Forms解决方案
ScintillaNET:打造专业级代码编辑器的终极Windows Forms解决方案 【免费下载链接】ScintillaNET A Windows Forms control, wrapper, and bindings for the Scintilla text editor. 项目地址: https://gitcode.com/gh_mirrors/sc/ScintillaNET ScintillaNET是…...