【动手学深度学习】--循环神经网络
文章目录
- 循环神经网络
- 1.算法介绍
- 1.1无隐状态的神经网络(多层感知机)
- 1.2有隐状态的循环神经网络
- 1.3基于循环神经网络的字符级语言模型
- 1.4困惑度
- 2.RNN从零开始实现
- 2.1读取数据集
- 2.2独热编码
- 2.3初始化模型参数
- 2.4循环神经网络模型
- 2.5预测
- 2.6梯度裁剪
- 2.7训练
- 3.RNN简洁实现
- 3.1读取数据集
- 3.2定义模型
- 3.3训练与预测
循环神经网络
学习视频:循环神经网络 RNN【动手学深度学习v2】
官方笔记:循环神经网络
1.算法介绍

潜变量自回归模型
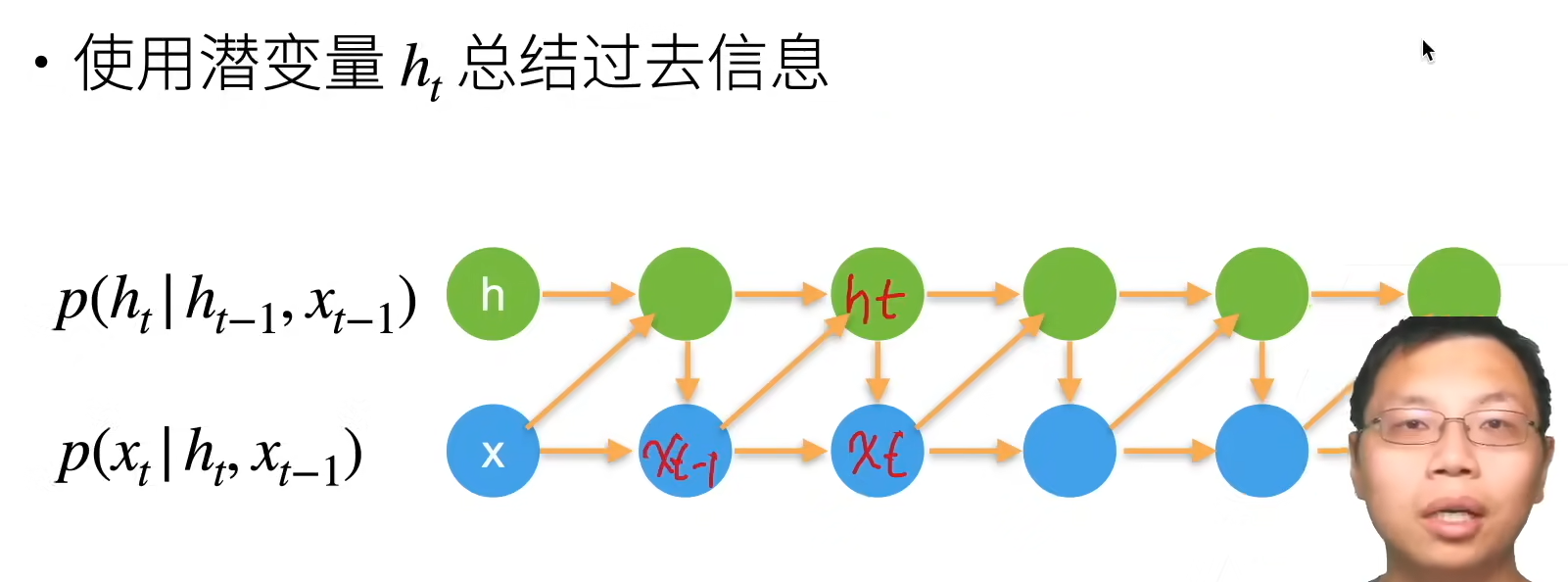
1.1无隐状态的神经网络(多层感知机)

1.2有隐状态的循环神经网络

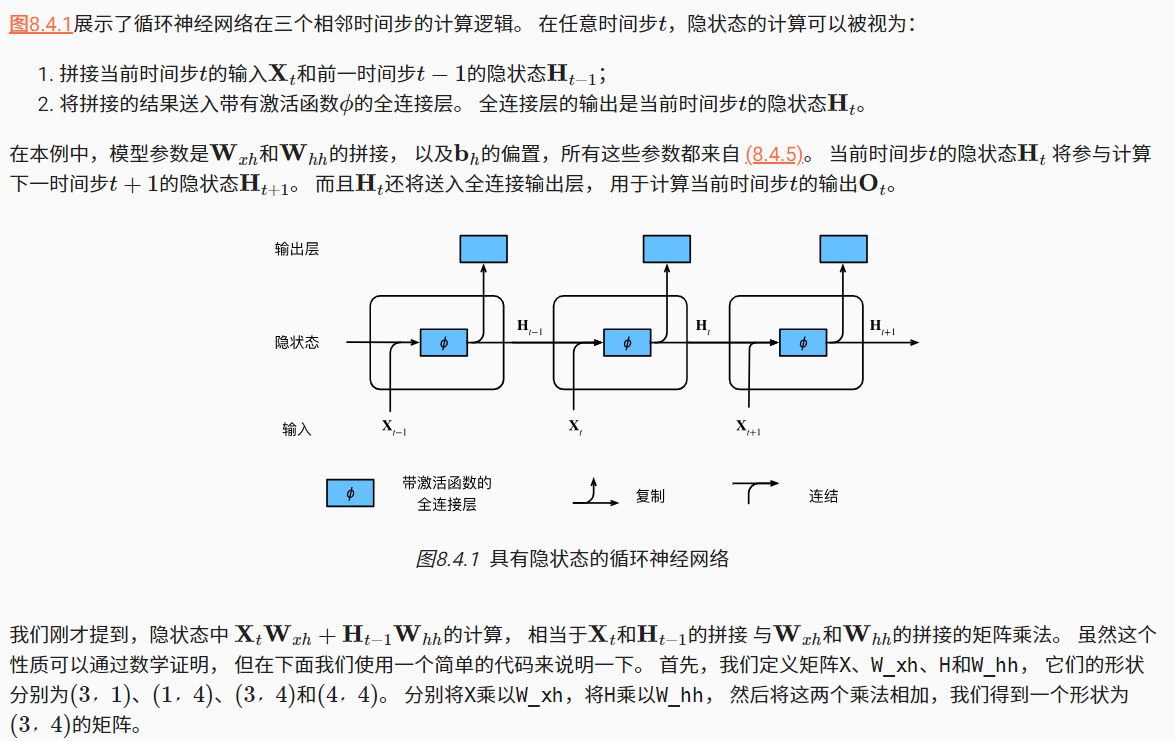
循环神经网络
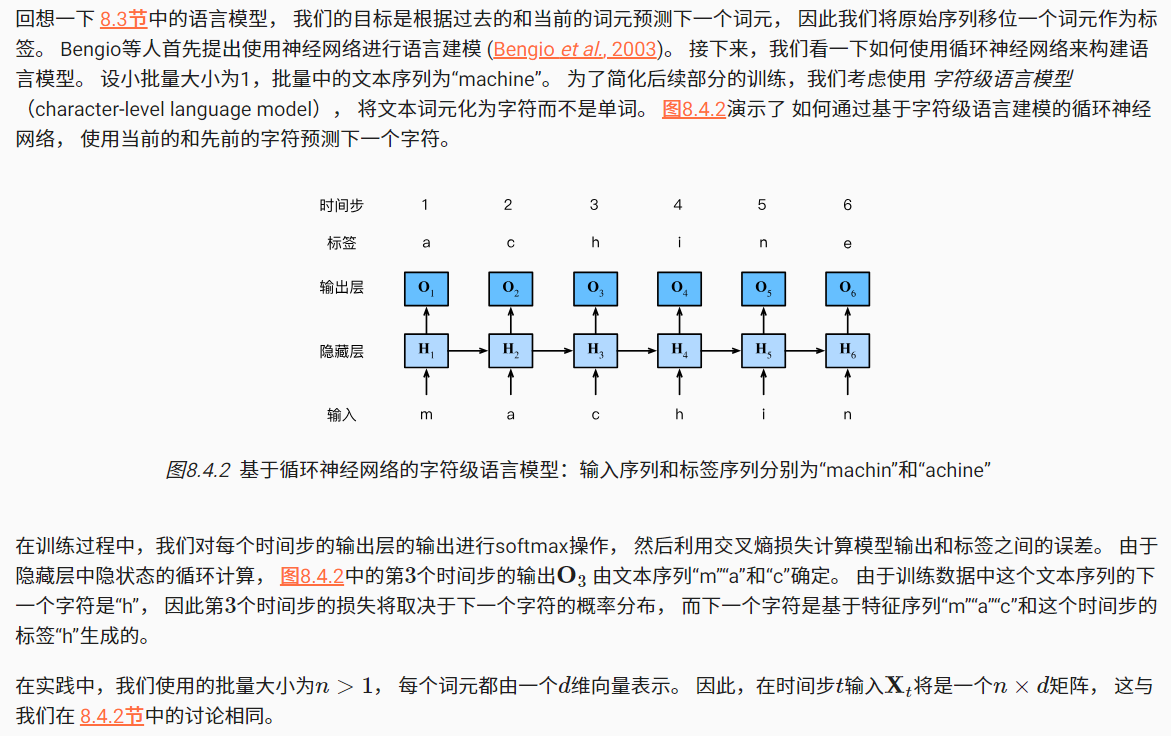
1.3基于循环神经网络的字符级语言模型
1.4困惑度


- 在最好的情况下,模型总是完美地估计标签词元的概率为1,在这种情况下,模型的困惑度为1
- 在最坏的情况下,模型总是预测标签词元的概率为0。在这种情况下,困惑度是正无穷大
- 在基线上,该模型的预测是词表的所有可用词元上的均匀分布。 在这种情况下,困惑度等于词表中唯一词元的数量。 事实上,如果我们在没有任何压缩的情况下存储序列, 这将是我们能做的最好的编码方式。 因此,这种方式提供了一个重要的上限, 而任何实际模型都必须超越这个上限。
梯度裁剪

总结:
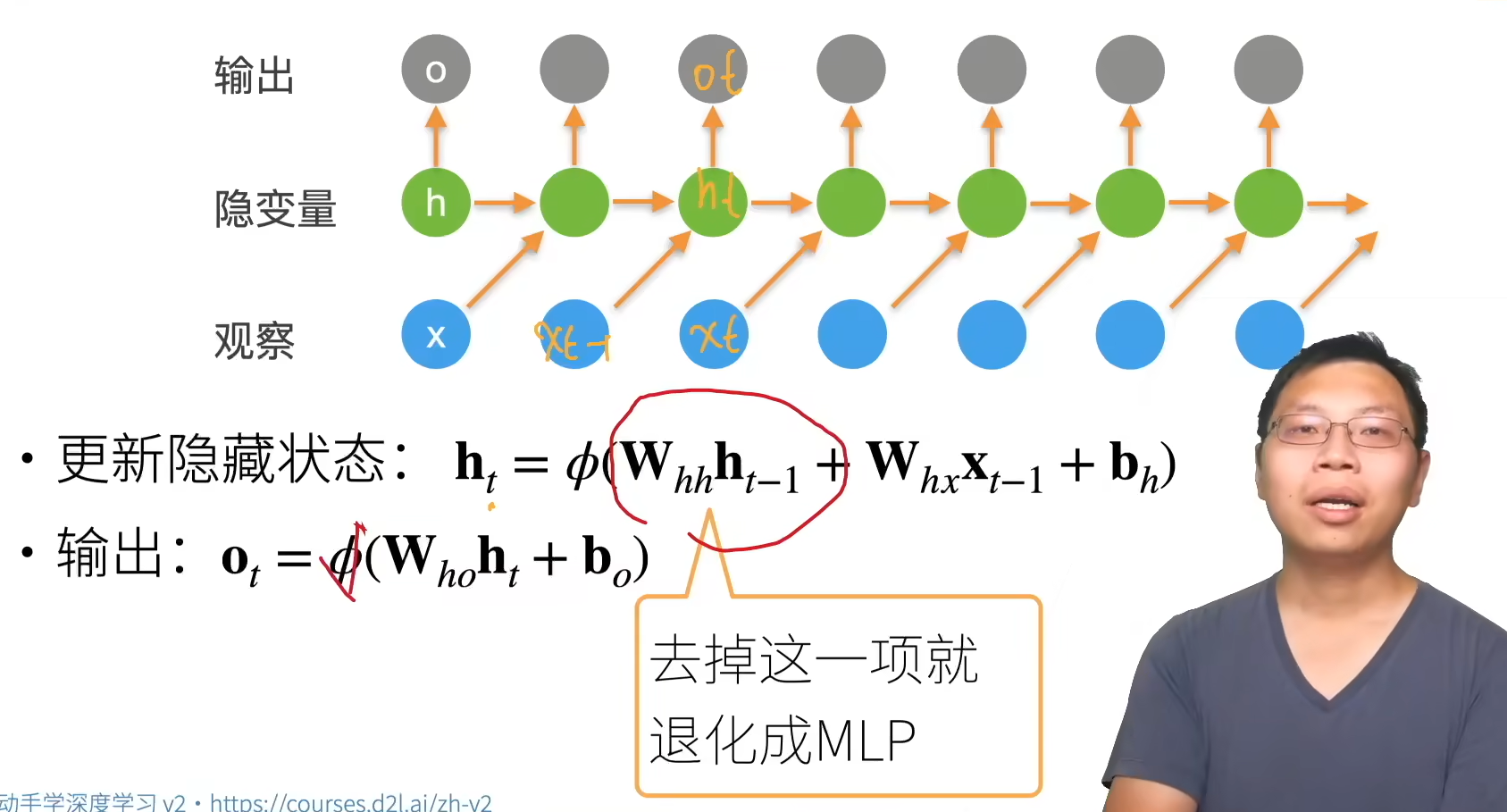
- 循环神经网络的输出取决于当下输入和前一时间的隐变量
- 应用到语言模型中,循环神经网络根据当前词预测下一次时刻词
- 通常使用困惑度来衡量语言模型的好坏
2.RNN从零开始实现
学习视频:循环神经网络 RNN 的实现【动手学深度学习v2】
官方笔记:
循环神经网络的从零开始实现
循环神经网络的简洁实现
2.1读取数据集
%matplotlib inline
import math
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2lbatch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
2.2独热编码

F.one_hot(torch.tensor([0, 2]), len(vocab))'''
tensor([[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0],[0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0]])
'''
我们每次采样的小批量数据形状是二维张量: (批量大小,时间步数)。 one_hot函数将这样一个小批量数据转换成三维张量, 张量的最后一个维度等于词表大小(len(vocab))。 我们经常转换输入的维度,以便获得形状为 (时间步数,批量大小,词表大小)的输出。 这将使我们能够更方便地通过最外层的维度, 一步一步地更新小批量数据的隐状态。
X = torch.arange(10).reshape((2, 5))
F.one_hot(X.T, 28).shape'''
torch.Size([5, 2, 28])
'''
2.3初始化模型参数
接下来,我们初始化循环神经网络模型的模型参数。 隐藏单元数num_hiddens是一个可调的超参数。 当训练语言模型时,输入和输出来自相同的词表。 因此,它们具有相同的维度,即词表的大小。
def get_params(vocab_size, num_hiddens, device):num_inputs = num_outputs = vocab_sizedef normal(shape):return torch.randn(size=shape, device=device) * 0.01# 隐藏层参数W_xh = normal((num_inputs, num_hiddens))W_hh = normal((num_hiddens, num_hiddens))b_h = torch.zeros(num_hiddens, device=device)# 输出层参数W_hq = normal((num_hiddens, num_outputs))b_q = torch.zeros(num_outputs, device=device)# 附加梯度params = [W_xh, W_hh, b_h, W_hq, b_q]for param in params:param.requires_grad_(True)return params
2.4循环神经网络模型
为了定义循环神经网络模型, 我们首先需要一个init_rnn_state函数在初始化时返回隐状态。 这个函数的返回是一个张量,张量全用0填充, 形状为(批量大小,隐藏单元数)。 在后面的章节中我们将会遇到隐状态包含多个变量的情况, 而使用元组可以更容易地处理些。
def init_rnn_state(batch_size, num_hiddens, device):return (torch.zeros((batch_size, num_hiddens), device=device), )
下面的rnn函数定义了如何在一个时间步内计算隐状态和输出。 循环神经网络模型通过inputs最外层的维度实现循环, 以便逐时间步更新小批量数据的隐状态H。 此外,这里使用tanh函数作为激活函数,当元素在实数上满足均匀分布时,tanh函数的平均值为0。
def rnn(inputs, state, params):# inputs的形状:(时间步数量,批量大小,词表大小)W_xh, W_hh, b_h, W_hq, b_q = paramsH, = stateoutputs = []# X的形状:(批量大小,词表大小)for X in inputs:H = torch.tanh(torch.mm(X, W_xh) + torch.mm(H, W_hh) + b_h)Y = torch.mm(H, W_hq) + b_qoutputs.append(Y)return torch.cat(outputs, dim=0), (H,)
定义了所有需要的函数之后,接下来我们创建一个类来包装这些函数, 并存储从零开始实现的循环神经网络模型的参数。
class RNNModelScratch: #@save"""从零开始实现的循环神经网络模型"""def __init__(self, vocab_size, num_hiddens, device,get_params, init_state, forward_fn):self.vocab_size, self.num_hiddens = vocab_size, num_hiddensself.params = get_params(vocab_size, num_hiddens, device)self.init_state, self.forward_fn = init_state, forward_fndef __call__(self, X, state):X = F.one_hot(X.T, self.vocab_size).type(torch.float32)return self.forward_fn(X, state, self.params)def begin_state(self, batch_size, device):return self.init_state(batch_size, self.num_hiddens, device)
让我们检查输出是否具有正确的形状。 例如,隐状态的维数是否保持不变
num_hiddens = 512
net = RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params,init_rnn_state, rnn)
state = net.begin_state(X.shape[0], d2l.try_gpu())
Y, new_state = net(X.to(d2l.try_gpu()), state)
Y.shape, len(new_state), new_state[0].shape'''
(torch.Size([10, 28]), 1, torch.Size([2, 512]))
'''
我们可以看到输出形状是(时间步数×批量大小,词表大小), 而隐状态形状保持不变,即(批量大小,隐藏单元数)。
2.5预测
让我们首先定义预测函数来生成prefix之后的新字符, 其中的prefix是一个用户提供的包含多个字符的字符串。 在循环遍历prefix中的开始字符时, 我们不断地将隐状态传递到下一个时间步,但是不生成任何输出。 这被称为预热(warm-up)期, 因为在此期间模型会自我更新(例如,更新隐状态), 但不会进行预测。 预热期结束后,隐状态的值通常比刚开始的初始值更适合预测, 从而预测字符并输出它们。
def predict_ch8(prefix, num_preds, net, vocab, device): #@save"""在prefix后面生成新字符"""state = net.begin_state(batch_size=1, device=device)outputs = [vocab[prefix[0]]]get_input = lambda: torch.tensor([outputs[-1]], device=device).reshape((1, 1))for y in prefix[1:]: # 预热期_, state = net(get_input(), state)outputs.append(vocab[y])for _ in range(num_preds): # 预测num_preds步y, state = net(get_input(), state)outputs.append(int(y.argmax(dim=1).reshape(1)))return ''.join([vocab.idx_to_token[i] for i in outputs])
现在我们可以测试predict_ch8函数。 我们将前缀指定为time traveller, 并基于这个前缀生成10个后续字符。 鉴于我们还没有训练网络,它会生成荒谬的预测结果。
predict_ch8('time traveller ', 10, net, vocab, d2l.try_gpu())'''
'time traveller aaaaaaaaaa'
'''
2.6梯度裁剪


def grad_clipping(net, theta): #@save"""裁剪梯度"""if isinstance(net, nn.Module):params = [p for p in net.parameters() if p.requires_grad]else:params = net.paramsnorm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))if norm > theta:for param in params:param.grad[:] *= theta / norm
2.7训练

#@save
def train_epoch_ch8(net, train_iter, loss, updater, device, use_random_iter):"""训练网络一个迭代周期(定义见第8章)"""state, timer = None, d2l.Timer()metric = d2l.Accumulator(2) # 训练损失之和,词元数量for X, Y in train_iter:if state is None or use_random_iter:# 在第一次迭代或使用随机抽样时初始化statestate = net.begin_state(batch_size=X.shape[0], device=device)else:if isinstance(net, nn.Module) and not isinstance(state, tuple):# state对于nn.GRU是个张量state.detach_()else:# state对于nn.LSTM或对于我们从零开始实现的模型是个张量for s in state:s.detach_()y = Y.T.reshape(-1)X, y = X.to(device), y.to(device)y_hat, state = net(X, state)l = loss(y_hat, y.long()).mean()if isinstance(updater, torch.optim.Optimizer):updater.zero_grad()l.backward()grad_clipping(net, 1)updater.step()else:l.backward()grad_clipping(net, 1)# 因为已经调用了mean函数updater(batch_size=1)metric.add(l * y.numel(), y.numel())return math.exp(metric[0] / metric[1]), metric[1] / timer.stop()
循环神经网络模型的训练函数既支持从零开始实现, 也可以使用高级API来实现。
#@save
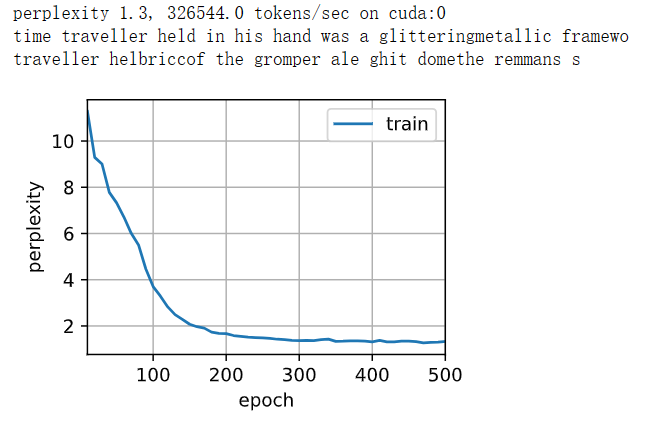
def train_ch8(net, train_iter, vocab, lr, num_epochs, device,use_random_iter=False):"""训练模型(定义见第8章)"""loss = nn.CrossEntropyLoss()animator = d2l.Animator(xlabel='epoch', ylabel='perplexity',legend=['train'], xlim=[10, num_epochs])# 初始化if isinstance(net, nn.Module):updater = torch.optim.SGD(net.parameters(), lr)else:updater = lambda batch_size: d2l.sgd(net.params, lr, batch_size)predict = lambda prefix: predict_ch8(prefix, 50, net, vocab, device)# 训练和预测for epoch in range(num_epochs):ppl, speed = train_epoch_ch8(net, train_iter, loss, updater, device, use_random_iter)if (epoch + 1) % 10 == 0:print(predict('time traveller'))animator.add(epoch + 1, [ppl])print(f'困惑度 {ppl:.1f}, {speed:.1f} 词元/秒 {str(device)}')print(predict('time traveller'))print(predict('traveller'))
现在,训练循环神经网络模型。 因为我们在数据集中只使用了10000个词元, 所以模型需要更多的迭代周期来更好地收敛。
num_epochs, lr = 500, 1
train_ch8(net, train_iter, vocab, lr, num_epochs, d2l.try_gpu())
最后,检查一下使用随机抽样方法的结果。
net = RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params,init_rnn_state, rnn)
train_ch8(net, train_iter, vocab, lr, num_epochs, d2l.try_gpu(),use_random_iter=True)
3.RNN简洁实现
3.1读取数据集
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2lbatch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
3.2定义模型
高级API提供了循环神经网络的实现。 我们构造一个具有256个隐藏单元的单隐藏层的循环神经网络层rnn_layer。 事实上,我们还没有讨论多层循环神经网络的意义,现在仅需要将多层理解为一层循环神经网络的输出被用作下一层循环神经网络的输入就足够了。
num_hiddens = 256
rnn_layer = nn.RNN(len(vocab), num_hiddens)
我们使用张量来初始化隐状态,它的形状是(隐藏层数,批量大小,隐藏单元数)。
state = torch.zeros((1, batch_size, num_hiddens))
state.shape'''
torch.Size([1, 32, 256])
'''
通过一个隐状态和一个输入,我们就可以用更新后的隐状态计算输出。 需要强调的是,rnn_layer的“输出”(Y)不涉及输出层的计算: 它是指每个时间步的隐状态,这些隐状态可以用作后续输出层的输入。
X = torch.rand(size=(num_steps, batch_size, len(vocab)))
Y, state_new = rnn_layer(X, state)
Y.shape, state_new.shape
我们为一个完整的循环神经网络模型定义了一个RNNModel类。 注意,rnn_layer只包含隐藏的循环层,我们还需要创建一个单独的输出层。
#@save
class RNNModel(nn.Module):"""循环神经网络模型"""def __init__(self, rnn_layer, vocab_size, **kwargs):super(RNNModel, self).__init__(**kwargs)self.rnn = rnn_layerself.vocab_size = vocab_sizeself.num_hiddens = self.rnn.hidden_size# 如果RNN是双向的(之后将介绍),num_directions应该是2,否则应该是1if not self.rnn.bidirectional:self.num_directions = 1self.linear = nn.Linear(self.num_hiddens, self.vocab_size)else:self.num_directions = 2self.linear = nn.Linear(self.num_hiddens * 2, self.vocab_size)def forward(self, inputs, state):X = F.one_hot(inputs.T.long(), self.vocab_size)X = X.to(torch.float32)Y, state = self.rnn(X, state)# 全连接层首先将Y的形状改为(时间步数*批量大小,隐藏单元数)# 它的输出形状是(时间步数*批量大小,词表大小)。output = self.linear(Y.reshape((-1, Y.shape[-1])))return output, statedef begin_state(self, device, batch_size=1):if not isinstance(self.rnn, nn.LSTM):# nn.GRU以张量作为隐状态return torch.zeros((self.num_directions * self.rnn.num_layers,batch_size, self.num_hiddens),device=device)else:# nn.LSTM以元组作为隐状态return (torch.zeros((self.num_directions * self.rnn.num_layers,batch_size, self.num_hiddens), device=device),torch.zeros((self.num_directions * self.rnn.num_layers,batch_size, self.num_hiddens), device=device))
3.3训练与预测
在训练模型之前,让我们基于一个具有随机权重的模型进行预测。
device = d2l.try_gpu()
net = RNNModel(rnn_layer, vocab_size=len(vocab))
net = net.to(device)
d2l.predict_ch8('time traveller', 10, net, vocab, device)'''
'time travellerialcaaiala'
'''
很明显,这种模型根本不能输出好的结果,接下来,使用之前定义的超参数调用train_ch8,并且使用高级API训练模型
num_epochs, lr = 500, 1
d2l.train_ch8(net, train_iter, vocab, lr, num_epochs, device)
相关文章:
【动手学深度学习】--循环神经网络
文章目录 循环神经网络1.算法介绍1.1无隐状态的神经网络(多层感知机)1.2有隐状态的循环神经网络1.3基于循环神经网络的字符级语言模型1.4困惑度 2.RNN从零开始实现2.1读取数据集2.2独热编码2.3初始化模型参数2.4循环神经网络模型2.5预测2.6梯度裁剪2.7训练 3.RNN简洁实现3.1读取…...

快捷支付是什么?怎么申请支付接口?
快捷支付是什么?怎么申请支付接口? 快捷支付,又称电子支付或第三方支付,在行业中得到了广泛的应用。用户只需通过银行完成交易。方便快捷意味着银行可以在任何条件下支持用户之间的转账、支付和其他即时结算服务。快捷支付意味着…...

【MySQL】数据库基础知识
本文基于Linux的MySQL 文章目录 一. 什么是数据库二. 主流数据库三. 服务器,数据库和表的关系四. MySQL架构五. SQL语句分类结束语 一. 什么是数据库 数据库本质是对数据内容存储的一套解决方案 如何理解呢? 首先,说到数据内容存储ÿ…...

算法训练day36|贪心算法 part05(重叠区间三连击:LeetCode435. 无重叠区间763.划分字母区间56. 合并区间)
文章目录 435. 无重叠区间思路分析 763.划分字母区间思路分析代码实现思考总结 56. 合并区间思路分析 435. 无重叠区间 题目链接🔥🔥 给定一个区间的集合,找到需要移除区间的最小数量,使剩余区间互不重叠。 注意: 可以认为区间的…...

[Android] AndroidManifest.xml 详解
转载自: https://www.cnblogs.com/shujk/p/14961572.html 正文: AndroidManifest.xml 是每个android程序中必须的文件,它位于整个项目的根目录。我们每天都在使用这个文件,往里面配置程序运行所必要的组件,权限&…...

idea远程debug调试
背景 有时候我们线上/测试环境出现了问题,我们本地跑却无法复现问题,使用idea的远程debug功能可以很好的解决该问题 配置 远程debug的服务,我们使用Springboot项目为例(SpringCloud作为微服务项目我们可以可以使用本地注册到远程项目&…...

离散化,树状数组,P5459 [BJOI2016] 回转寿司
P5459 [BJOI2016] 回转寿司 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 题目描述 酷爱日料的小Z经常光顾学校东门外的回转寿司店。在这里,一盘盘寿司通过传送带依次呈现在小Z眼前。 不同的寿司带给小Z的味觉感受是不一样的,我们定义小Z对每盘寿司…...

论文复现--VideoTo3dPoseAndBvh(视频转BVH和3D关键点开源项目)
分类:动作捕捉 github地址:https://github.com/HW140701/VideoTo3dPoseAndBvh 所需环境: Windows10,CUDA11.6,conda 4.13.0; 目录 环境搭建conda list配置内容演示生成文件说明 环境搭建 # 创建环境 conda…...

JS 检查某个值是否为某个类的实例
function checkIsInsByTarget(value, fun) {if (value null || value undefined || !(fun instanceof Function)) {return false;}return Object(value) instanceof fun; }这段代码的目的是检查一个对象是否是某个类(Class)的实例。它接受两个参数&…...
生动理解深度学习精度提升利器——测试时增强(TTA)
测试时增强(Test-Time Augmentation,TTA)是一种在深度学习模型的测试阶段应用数据增强的技术手段。它是通过对测试样本进行多次随机变换或扰动,产生多个增强的样本,并使用这些样本进行预测的多数投票或平均来得出最终预…...
:使用redis-cli命令测试状态)
Redis基础知识(四):使用redis-cli命令测试状态
文章目录 测试Redis服务是否启动查看Redis数据库运行状态 Redis是一款开源的高性能键值数据库,具有快速、灵活、高效、稳定的特点,广泛应用于互联网领域。在开发过程中,我们需要通过测试Redis的状态来保证其正常运行,这就需要使用…...
【web开发】4、JavaScript与jQuery
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、JavaScript与jQuery二、JavaScript常用的基本功能1.插入位置2.注释3.变量4.数组5.滚动字符 三、jQuery常用的基本功能1.引入jQuery2.寻找标签3.val、text、appe…...

关于el-date-picker组件修改输入框以及下拉框的样式
因为业务需求,从element plus直接拿过来的组件样式和整体风格不搭,所以要修改样式,直接deep修改根本不生效,最后才发现el-date-picker组件有一个popper-class属性,通过这个属性我们就能够修改下拉框的样式,…...

JSCPC f ( 期望dp
#include <bits/stdc.h> using namespace std; using VI vector<int>; double dp[2000010]; int n; string s; //可能要特判 b 1的情况 //有 a 个 材料 ,每 b 个 合成一个,俩种方案, //1 . 双倍产出 p //2 . 返还材料 q int a,b; double …...
Django(10)-项目实战-对发布会管理系统进行测试并获取测试覆盖率
在发布会签到系统中使用django开发了发布会签到系统, 本文对该系统进行测试。 django.test django.test是Django框架中的一个模块,提供了用于编写和运行测试的工具和类。 django.test模块包含了一些用于测试的类和函数,如: TestCase:这是一个基类,用于编写Django测试用…...

ABB机器人10106故障报警(维修时间提醒)的处理方法
ABB机器人10106故障报警(维修时间提醒)的处理方法 故障原因: ABB机器人智能周期保养维护提醒,用于提示用户对机器人进行必要的保养和检修。 处理方法: 完成对应的保养和检修后,要进行一个操作…...

性能测试 —— 吞吐量和并发量的关系? 有什么区别?
吞吐量(Throughput)和并发量(Concurrency)是性能测试中常用的两个指标,它们描述了系统处理能力的不同方面。 吞吐量(Throughput) 是指系统在单位时间内能够处理的请求数量或事务数量。它常用于…...
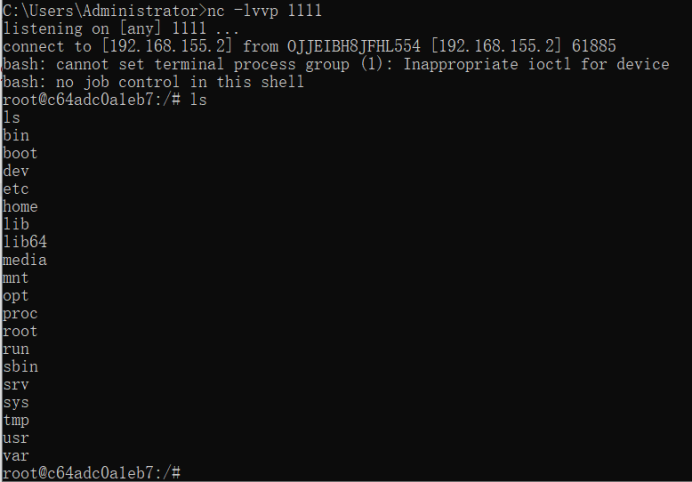
Fastjson反序列化漏洞
文章目录 一、概念二、Fastjson-历史漏洞三、漏洞原理四、Fastjson特征五、Fastjson1.2.47漏洞复现1.搭建环境2.漏洞验证(利用 dnslog)3.漏洞利用1)Fastjson反弹shell2)启动HTTP服务器3)启动LDAP服务4)启动shell反弹监听5)Burp发送反弹shell 一、概念 啥…...
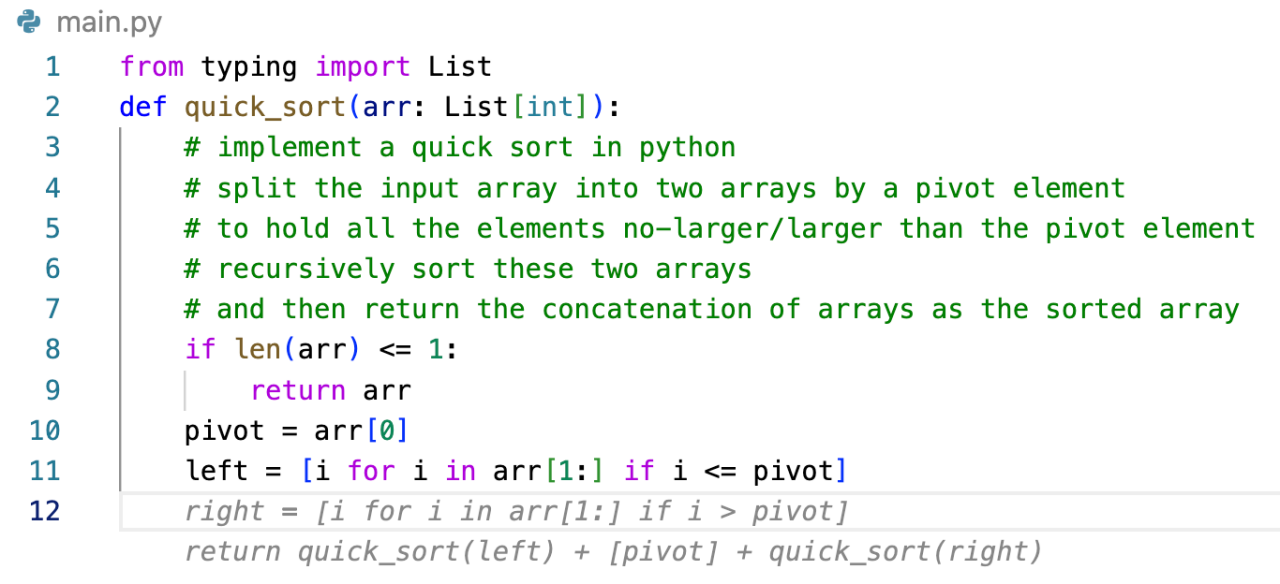
AI 帮我写代码——Amazon CodeWhisperer 初体验
文章作者:游凯超 人工智能的突破和变革正在深刻地改变我们的生活。从智能手机到自动驾驶汽车,AI 的应用已经深入到我们生活的方方面面。而在编程领域,AI 的崭新尝试正在开启一场革命。Amazon CodeWhisperer,作为亚马逊云科技的一款…...
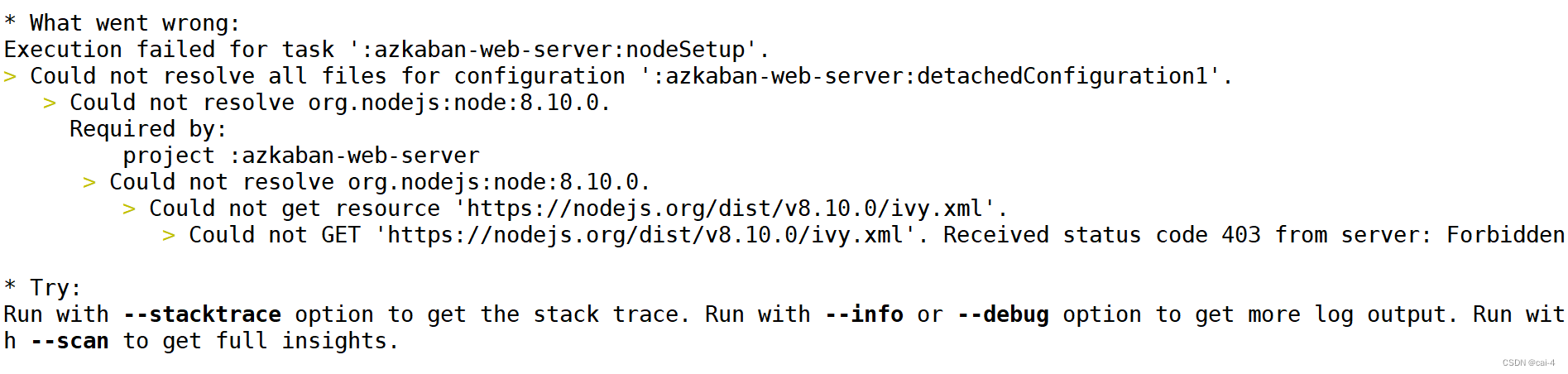
实训笔记9.1
实训笔记9.1 9.1笔记一、项目开发流程一共分为七个阶段1.1 数据产生阶段1.2 数据采集存储阶段1.3 数据清洗预处理阶段1.4 数据统计分析阶段1.5 数据迁移导出阶段1.6 数据可视化阶段 二、项目的数据产生阶段三、项目的数据采集存储阶段四、项目数据清洗预处理的实现4.1 清洗预处…...
)
GitHub新手避坑指南:从SSH Key到Personal Token,搞定本地项目上传(含大文件失败解决方案)
GitHub新手避坑指南:从SSH Key到Personal Token,搞定本地项目上传(含大文件失败解决方案) 第一次用GitHub上传项目就像玩扫雷游戏——表面风平浪静,实际暗藏玄机。上周帮实习生小李排查上传失败问题时,发现…...

FRCRN处理长音频文件实战:切片、批处理与结果合并
FRCRN处理长音频文件实战:切片、批处理与结果合并 你是不是遇到过这样的问题?手头有一段长达数小时的会议录音、访谈素材或者播客音频,背景噪音让人头疼,想用FRCRN这样的降噪模型处理一下,结果发现模型一次只能处理几…...
)
QT 5.14.0实战:手把手教你用QLineEdit打造一个带验证码的登录框(附完整样式代码)
QT 5.14.0实战:手把手教你用QLineEdit打造一个带验证码的登录框(附完整样式代码) 在GUI开发中,登录界面是最基础也最考验细节的组件之一。一个优秀的登录框不仅需要功能完整,还要在用户体验上下足功夫——比如实时输入…...

基因组变异致病性预测:从SIFT、PolyPhen到PrimateAI的算法演进
点击 “AladdinEdu,你的AI学习实践工作坊”,注册即送-H卡级别算力,沉浸式云原生集成开发环境,80G大显存多卡并行,按量弹性计费,教育用户更享超低价。 摘要:基因组变异致病性预测是精准医学的关键…...

软件测试之压力测试总结
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 一、什么是压力测试软件测试中:压力测试(Stress Test),也称为强度测试、负载测试。压力测试是模拟实际应用的软硬件…...

5大核心优势!PingFangSC字体配置完全指南:从安装到设计工具深度应用
5大核心优势!PingFangSC字体配置完全指南:从安装到设计工具深度应用 【免费下载链接】PingFangSC PingFangSC字体包文件、苹果平方字体文件,包含ttf和woff2格式 项目地址: https://gitcode.com/gh_mirrors/pi/PingFangSC 在数字设计领…...

AI五金冲压报价——让精准报价,快人一步。
传统报价熬3天?AI 8分钟给你一份带Excel明细正规PDF的报价单!还在用Excel手动算冲压报价?客户催得急,成本核不准,格式不专业丢订单?五金厂的报价痛点,我们懂!✅ 工艺PDF/3D图扔进去&…...

解锁PlotJuggler数据可视化:工业时序数据处理与分析指南
解锁PlotJuggler数据可视化:工业时序数据处理与分析指南 【免费下载链接】PlotJuggler The Time Series Visualization Tool that you deserve. 项目地址: https://gitcode.com/gh_mirrors/pl/PlotJuggler PlotJuggler是一款专业的时序数据可视化工具&#x…...

用STM32F103C8T6做个宠物喂食器:从电路图到代码的保姆级DIY教程
用STM32F103C8T6打造智能宠物喂食器:从硬件搭建到软件调优全流程解析 养宠物的朋友都知道,定时定量喂食对宠物健康至关重要。今天我们就来手把手教你如何用STM32F103C8T6单片机打造一个智能宠物喂食器,不仅能定时投喂,还能识别不…...

别再只会用FFT了!用MATLAB的czt函数实现窄带信号高分辨率频谱分析
别再只会用FFT了!用MATLAB的czt函数实现窄带信号高分辨率频谱分析 在信号处理领域,频谱分析是最基础也是最重要的技术之一。传统上,工程师们习惯使用快速傅里叶变换(FFT)来获取信号的频域信息。然而,当面对…...