生动理解深度学习精度提升利器——测试时增强(TTA)
测试时增强(Test-Time Augmentation,TTA)是一种在深度学习模型的测试阶段应用数据增强的技术手段。它是通过对测试样本进行多次随机变换或扰动,产生多个增强的样本,并使用这些样本进行预测的多数投票或平均来得出最终预测结果。
为了直观理解TTA执行的过程,这里我绘制了流程示意图如下所示:
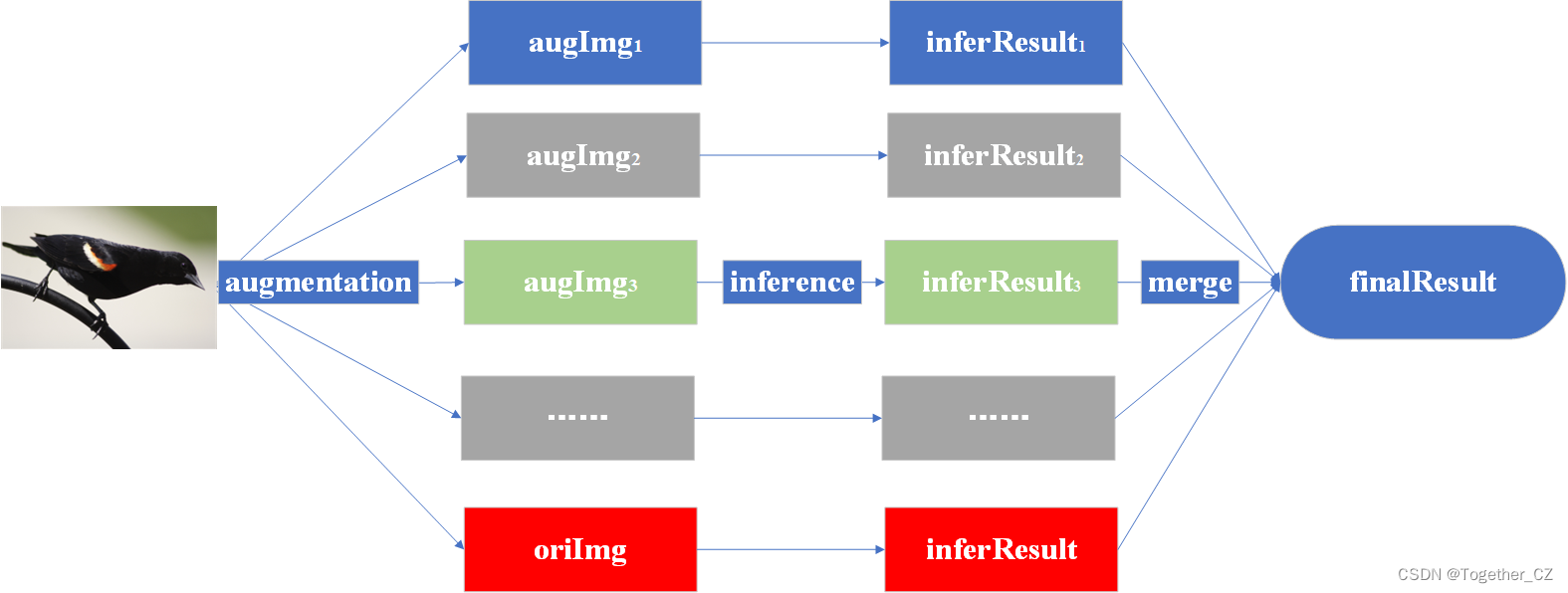
TTA的过程如下:
-
数据增强:
- 在测试时,对每个测试样本应用随机的变换或扰动操作,生成多个增强样本。
- 常用的数据增强操作包括随机翻转、随机旋转、随机裁剪、随机缩放等。这些操作可以增加样本的多样性,模拟真实世界中的不确定性和变化。
-
多次预测:
- 使用训练好的模型对生成的增强样本进行多次预测。
- 对于每个增强样本,都会得到一个预测结果。
-
预测结果集成:
- 对多次预测的结果进行集成,常用的集成方式有多数投票和平均。
- 对于分类任务,多数投票即选择预测结果中出现次数最多的类别作为最终的预测类别。对于回归任务,平均即将多次预测结果进行平均。
接下来针对性地对比分析下使用TTA带来的优点和缺点:
优点:
- 提高鲁棒性:通过应用数据增强,TTA可以增加样本的多样性和泛化能力,提高模型在面对未见过的输入分布和未知变化时的鲁棒性。
- 提高准确性:通过多次预测和集成,TTA可以减少预测结果的随机性和偶然误差,提高最终预测结果的稳定性和准确性。
- 模型评估和排名:TTA可以改变模型预测的不确定性,使得模型评估更可靠,能够更好地对不同模型进行性能排名。
缺点:
- 计算开销:生成和预测多个增强样本会增加计算量。特别是在大型模型和复杂任务中,可能导致推理时间的显著增加,限制了TTA的实际应用。
- 可能造成过拟合:对于已包含在训练数据中的变换或扰动,如果在测试时反复应用,可能会导致模型对这些特定样本的过拟合,从而影响模型的泛化能力。
TTA是一种常用的技术手段,通过应用数据增强和集成预测结果,可以提高深度学习模型在测试阶段的性能和鲁棒性。然而,TTA的应用需要平衡计算开销和预测准确性,并谨慎处理可能导致模型过拟合的问题。根据具体任务和需求,可以灵活选择合适的增强操作和集成策略来使用TTA。
下面是demo代码实现,如下所示:
import numpy as np
import torch
import torchvision.transforms as transformsdef test_time_augmentation(model, image, n_augmentations):# 定义数据增强的变换transform = transforms.Compose([transforms.ToTensor(),# 在此添加你需要的任何其他数据增强操作])# 存储多次预测结果的列表predictions = []# 对图像应用多次增强和预测for _ in range(n_augmentations):augmented_image = transform(image)augmented_image = augmented_image.unsqueeze(0) # 增加一个维度作为批次with torch.no_grad():# 切换模型为评估模式,确保不执行梯度计算model.eval()# 使用增强的图像进行预测output = model(augmented_image)_, predicted = torch.max(output.data, 1)predictions.append(predicted.item())# 执行多数投票并返回最终预测结果final_prediction = np.bincount(predictions).argmax()return final_prediction在前文鸟类细粒度识别项目实验中测试发现,应用TTA技术后,对应的评估指标上有明显的涨点,但是很明显地可以发现:在整个测试过程中资源消耗增加明显,且耗时显著增长,这也是TTA无法避免的劣势,在对精度要求较高的场景下可以有限考虑引入TTA,但是对于计算时耗要求较高的场景则不推荐使用TTA。
开源社区里面也有一些优秀的实现,这里推荐一个,地址在这里,如下所示:
目前有将近1k的star量,还是蛮不错的。
安装方法如下所示:
pip安装:
pip install ttach源码安装:
pip install git+https://github.com/qubvel/ttach Input| # input batch of images / / /|\ \ \ # apply augmentations (flips, rotation, scale, etc.)| | | | | | | # pass augmented batches through model| | | | | | | # reverse transformations for each batch of masks/labels\ \ \ / / / # merge predictions (mean, max, gmean, etc.)| # output batch of masks/labelsOutput目前支持分割、分类、关键点检测三种任务,实例使用如下所示:
Segmentation model wrapping [docstring]:
import ttach as tta
tta_model = tta.SegmentationTTAWrapper(model, tta.aliases.d4_transform(), merge_mode='mean')Classification model wrapping [docstring]:
tta_model = tta.ClassificationTTAWrapper(model, tta.aliases.five_crop_transform())Keypoints model wrapping [docstring]:
tta_model = tta.KeypointsTTAWrapper(model, tta.aliases.flip_transform(), scaled=True)data transforms 实例实现如下所示:
# defined 2 * 2 * 3 * 3 = 36 augmentations !
transforms = tta.Compose([tta.HorizontalFlip(),tta.Rotate90(angles=[0, 180]),tta.Scale(scales=[1, 2, 4]),tta.Multiply(factors=[0.9, 1, 1.1]), ]
)tta_model = tta.SegmentationTTAWrapper(model, transforms)Custom model (multi-input / multi-output)实现如下所示:
# Example how to process ONE batch on images with TTA
# Here `image`/`mask` are 4D tensors (B, C, H, W), `label` is 2D tensor (B, N)for transformer in transforms: # custom transforms or e.g. tta.aliases.d4_transform() # augment imageaugmented_image = transformer.augment_image(image)# pass to modelmodel_output = model(augmented_image, another_input_data)# reverse augmentation for mask and labeldeaug_mask = transformer.deaugment_mask(model_output['mask'])deaug_label = transformer.deaugment_label(model_output['label'])# save resultslabels.append(deaug_mask)masks.append(deaug_label)# reduce results as you want, e.g mean/max/min
label = mean(labels)
mask = mean(masks)Transforms详情如下所示:
| Transform | Parameters | Values |
|---|---|---|
| HorizontalFlip | - | - |
| VerticalFlip | - | - |
| Rotate90 | angles | List[0, 90, 180, 270] |
| Scale | scales interpolation | List[float] "nearest"/"linear" |
| Resize | sizes original_size interpolation | List[Tuple[int, int]] Tuple[int,int] "nearest"/"linear" |
| Add | values | List[float] |
| Multiply | factors | List[float] |
| FiveCrops | crop_height crop_width | int int |
支持的结果融合方法如下:
mean
gmean (geometric mean)
sum
max
min
tsharpen (temperature sharpen with t=0.5)相关文章:
生动理解深度学习精度提升利器——测试时增强(TTA)
测试时增强(Test-Time Augmentation,TTA)是一种在深度学习模型的测试阶段应用数据增强的技术手段。它是通过对测试样本进行多次随机变换或扰动,产生多个增强的样本,并使用这些样本进行预测的多数投票或平均来得出最终预…...
:使用redis-cli命令测试状态)
Redis基础知识(四):使用redis-cli命令测试状态
文章目录 测试Redis服务是否启动查看Redis数据库运行状态 Redis是一款开源的高性能键值数据库,具有快速、灵活、高效、稳定的特点,广泛应用于互联网领域。在开发过程中,我们需要通过测试Redis的状态来保证其正常运行,这就需要使用…...
【web开发】4、JavaScript与jQuery
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、JavaScript与jQuery二、JavaScript常用的基本功能1.插入位置2.注释3.变量4.数组5.滚动字符 三、jQuery常用的基本功能1.引入jQuery2.寻找标签3.val、text、appe…...

关于el-date-picker组件修改输入框以及下拉框的样式
因为业务需求,从element plus直接拿过来的组件样式和整体风格不搭,所以要修改样式,直接deep修改根本不生效,最后才发现el-date-picker组件有一个popper-class属性,通过这个属性我们就能够修改下拉框的样式,…...

JSCPC f ( 期望dp
#include <bits/stdc.h> using namespace std; using VI vector<int>; double dp[2000010]; int n; string s; //可能要特判 b 1的情况 //有 a 个 材料 ,每 b 个 合成一个,俩种方案, //1 . 双倍产出 p //2 . 返还材料 q int a,b; double …...
Django(10)-项目实战-对发布会管理系统进行测试并获取测试覆盖率
在发布会签到系统中使用django开发了发布会签到系统, 本文对该系统进行测试。 django.test django.test是Django框架中的一个模块,提供了用于编写和运行测试的工具和类。 django.test模块包含了一些用于测试的类和函数,如: TestCase:这是一个基类,用于编写Django测试用…...

ABB机器人10106故障报警(维修时间提醒)的处理方法
ABB机器人10106故障报警(维修时间提醒)的处理方法 故障原因: ABB机器人智能周期保养维护提醒,用于提示用户对机器人进行必要的保养和检修。 处理方法: 完成对应的保养和检修后,要进行一个操作…...

性能测试 —— 吞吐量和并发量的关系? 有什么区别?
吞吐量(Throughput)和并发量(Concurrency)是性能测试中常用的两个指标,它们描述了系统处理能力的不同方面。 吞吐量(Throughput) 是指系统在单位时间内能够处理的请求数量或事务数量。它常用于…...
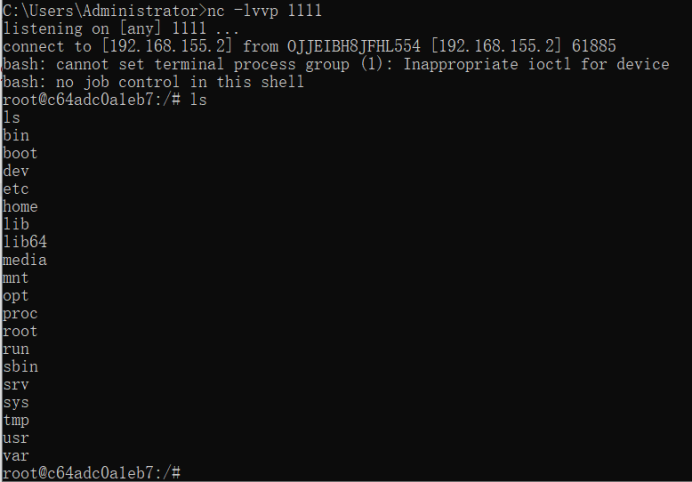
Fastjson反序列化漏洞
文章目录 一、概念二、Fastjson-历史漏洞三、漏洞原理四、Fastjson特征五、Fastjson1.2.47漏洞复现1.搭建环境2.漏洞验证(利用 dnslog)3.漏洞利用1)Fastjson反弹shell2)启动HTTP服务器3)启动LDAP服务4)启动shell反弹监听5)Burp发送反弹shell 一、概念 啥…...
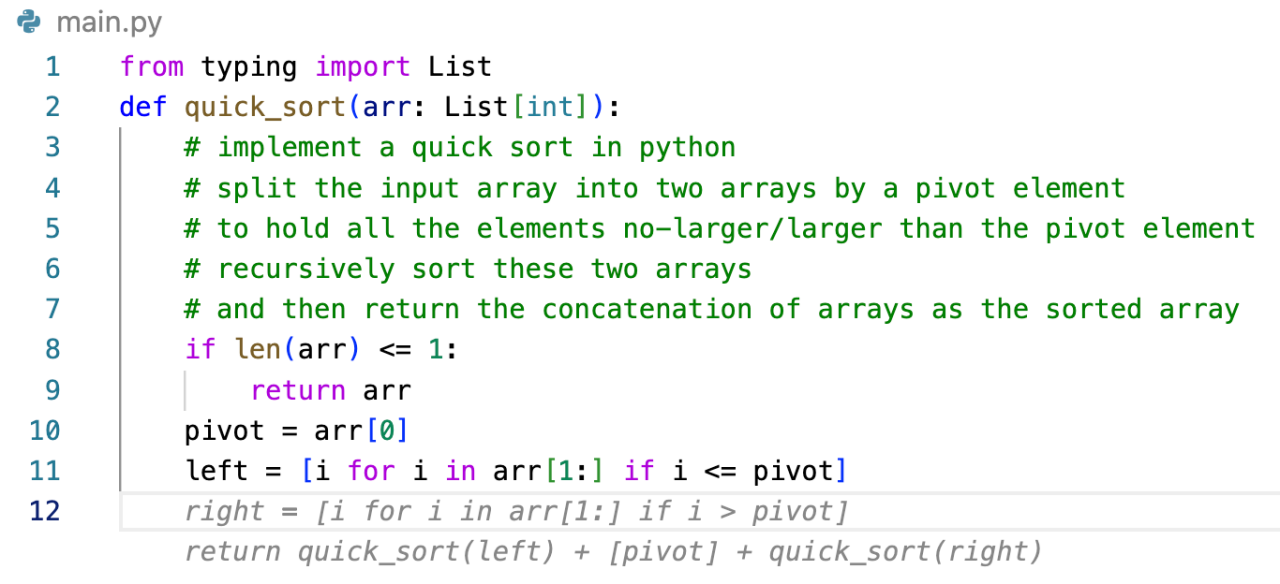
AI 帮我写代码——Amazon CodeWhisperer 初体验
文章作者:游凯超 人工智能的突破和变革正在深刻地改变我们的生活。从智能手机到自动驾驶汽车,AI 的应用已经深入到我们生活的方方面面。而在编程领域,AI 的崭新尝试正在开启一场革命。Amazon CodeWhisperer,作为亚马逊云科技的一款…...
实训笔记9.1
实训笔记9.1 9.1笔记一、项目开发流程一共分为七个阶段1.1 数据产生阶段1.2 数据采集存储阶段1.3 数据清洗预处理阶段1.4 数据统计分析阶段1.5 数据迁移导出阶段1.6 数据可视化阶段 二、项目的数据产生阶段三、项目的数据采集存储阶段四、项目数据清洗预处理的实现4.1 清洗预处…...

汽车SOA架构
文章目录 一、汽车SOA架构的基本概念二、汽车SOA架构的优势三、从设计、开发和测试方面介绍汽车SOA架构四、SOA技术在汽车行业的应用 汽车SOA架构是指汽车软件架构采用面向服务的架构(Service-Oriented Architecture,简称SOA)的设计模式。SOA…...

L1-017 到底有多二 C++解法
题目 一个整数“犯二的程度”定义为该数字中包含2的个数与其位数的比值。如果这个数是负数,则程度增加0.5倍;如果还是个偶数,则再增加1倍。例如数字-13142223336是个11位数,其中有3个2,并且是负数,也是偶数…...

motionface respeak视频一键对口型
语音驱动视频唇部动作和视频对口型是两项不同的技术,但是它们都涉及到将语音转化为视觉效果。 语音驱动视频唇部动作(语音唇同步): 语音驱动视频唇部动作是一种人工智能技术,它可以将语音转化为实时视频唇部动作。这…...
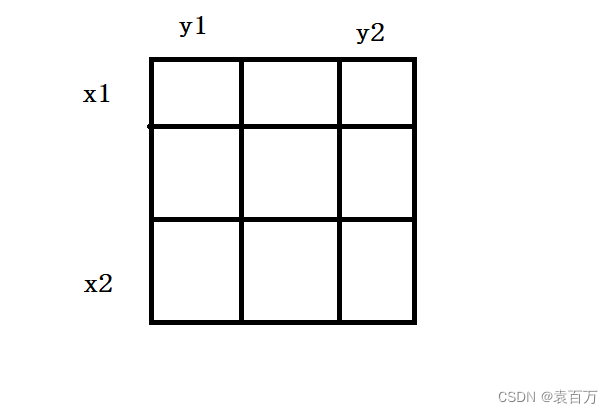
LeetCode——顺时针打印矩形
题目地址 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 题目解析 按照顺时针一次遍历,遍历外外层遍历里层。 代码如下 class Solution { public:vector<int> spiralOrder(vector<vector<int>>& matrix) {if(…...
C语言课程作业
本科期间c语言课程作业代码整理: Josephus链表实现 Josephus 层序遍历树 二叉树的恢复 哈夫曼树 链表的合并 中缀表达式 链接:https://pan.baidu.com/s/1Q7d-LONauNLi7nJS_h0jtw?pwdswit 提取码:swit...
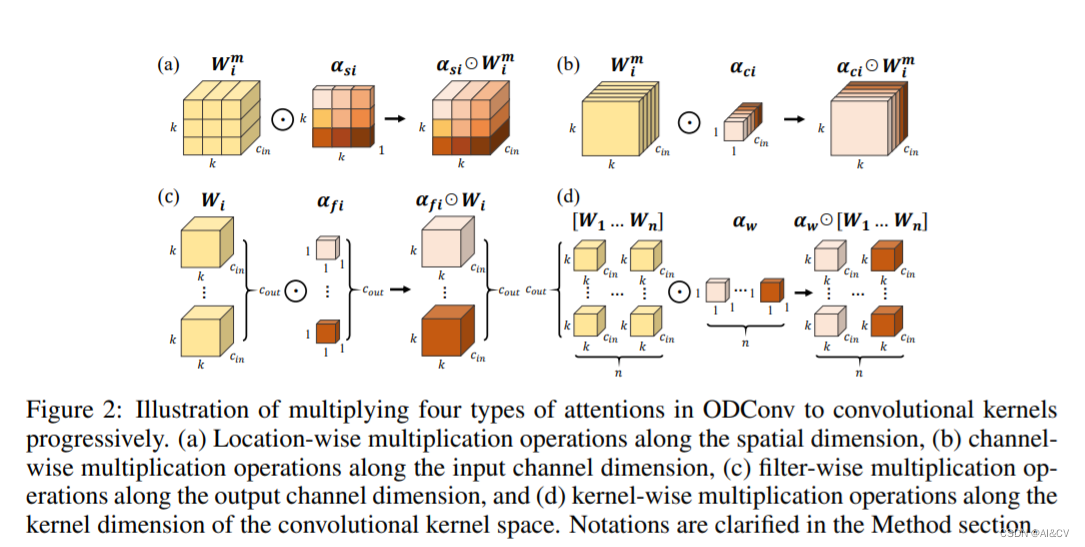
Yolov8魔术师:卷积变体大作战,涨点创新对比实验,提供CVPR2023、ICCV2023等改进方案
💡💡💡本文独家改进:提供各种卷积变体DCNV3、DCNV2、ODConv、SCConv、PConv、DynamicSnakeConvolution、DAT,引入CVPR2023、ICCV2023等改进方案,为Yolov8创新保驾护航,提供各种科研对比实验 &am…...

基于小波神经网络的空气质量预测,基于小波神经网络的PM2.5预测,基于ANN的PM2.5预测
目标 背影 BP神经网络的原理 BP神经网络的定义 BP神经网络的基本结构 BP神经网络的神经元 BP神经网络的激活函数, BP神经网络的传递函数 小波神经网络(以小波基为传递函数的BP神经网络) 代码链接:基于小波神经网络的PM2.5预测,ann神经网络pm2.5预测资源-CSDN文库 https:/…...

Vue / Vue CLI / Vue Router / Vuex / Element UI
Vue Vue是一种流行的JavaScript前端框架,用于构建用户界面 它被设计为易于学习和使用,并且具有响应式的数据绑定和组件化的架构 Vue具有简洁的语法和灵活的功能,可以帮助开发人员构建高效、可扩展的Web应用程序 它也有一个大型的生态系统和活…...

Lesson4-2:OpenCV图像特征提取与描述---Harris和Shi-Tomas算法
学习目标 理解Harris和Shi-Tomasi算法的原理能够利用Harris和Shi-Tomasi进行角点检测 1 Harris角点检测 1.1 原理 H a r r i s Harris Harris角点检测的思想是通过图像的局部的小窗口观察图像,角点的特征是窗口沿任意方向移动都会导致图像灰度的明显变化ÿ…...

OpenRocket:革新性全流程火箭设计的开源技术突破实践
OpenRocket:革新性全流程火箭设计的开源技术突破实践 【免费下载链接】openrocket Model-rocketry aerodynamics and trajectory simulation software 项目地址: https://gitcode.com/GitHub_Trending/op/openrocket OpenRocket作为一款基于Java开发的开源火…...

Qwen3-TTS多语言语音合成实测:一键部署,生成10种语言的逼真语音
Qwen3-TTS多语言语音合成实测:一键部署,生成10种语言的逼真语音 1. 开篇:语音合成新体验 想象一下,只需输入一段文字,就能让电脑用10种不同语言"开口说话",而且声音自然得几乎分辨不出是机器生…...
)
手把手教你用Cline插件5分钟搞定DeepSeek-R1模型接入(附硅基流动平台2000万Token福利)
5分钟极速上手:用Cline插件无缝对接DeepSeek-R1大模型实战指南 当你第一次听说只需要5分钟就能让一个强大的AI模型为你工作时,可能会觉得这像是某种夸张的营销话术。但作为一个曾经花了整整三天时间才搞定第一个模型接入的开发者,我可以负责任…...

别再只用柱状图了!用Python的Matplotlib画个酷炫的雷达图,5分钟搞定你的个人技能展示
用Python打造专业级技能雷达图:5步提升你的职场竞争力 简历上那些千篇一律的柱状图和百分比条已经让招聘官审美疲劳了?试试用Matplotlib绘制一个令人眼前一亮的雷达图来展示你的核心技能组合。这种可视化方式不仅能清晰呈现你在各个领域的熟练程度&#…...

Amlogic S9XXX设备系统改造完全指南:从入门到进阶
Amlogic S9XXX设备系统改造完全指南:从入门到进阶 【免费下载链接】amlogic-s9xxx-armbian Supports running Armbian on Amlogic, Allwinner, and Rockchip devices. Support a311d, s922x, s905x3, s905x2, s912, s905d, s905x, s905w, s905, s905l, rk3588, rk35…...

Lingbot-Depth-Pretrain-ViTL-14 Anaconda环境搭建:创建隔离的Python开发与推理环境
Lingbot-Depth-Pretrain-ViTL-14 Anaconda环境搭建:创建隔离的Python开发与推理环境 你是不是也遇到过这种情况:好不容易跟着教程跑通了一个AI项目,结果过两天想跑另一个项目时,发现各种库版本冲突,报错满天飞&#x…...

SAM 3在内容创作中的应用:快速分离图片视频主体,提升剪辑效率
SAM 3在内容创作中的应用:快速分离图片视频主体,提升剪辑效率 1. 引言:内容创作者的痛点与解决方案 在当今内容爆炸的时代,视频创作者和设计师们面临着一个共同的挑战:如何高效地从复杂背景中分离出主体对象。传统方…...
)
运放跟随器:电路设计中最容易被低估的‘保镖‘(隔离驱动全解析)
运放跟随器:电路设计中最容易被低估的"保镖"(隔离&驱动全解析) 在硬件工程师的日常设计中,运放跟随器常常被视为一个"可有可无"的组件——毕竟它的电压增益仅为1,看起来似乎只是将输入信号原封…...
Java微服务集成TranslateGemma:企业级翻译中台构建
Java微服务集成TranslateGemma:企业级翻译中台构建 1. 为什么需要企业级翻译中台 最近在给一家跨境电商平台做技术咨询时,客户提到一个很实际的问题:他们的客服系统、商品管理系统、营销内容平台各自维护着不同的翻译逻辑。客服用的是第三方…...

Qwen3.5-2B效果展示:对含中英混排、公式符号的PDF截图进行精准语义还原
Qwen3.5-2B效果展示:对含中英混排、公式符号的PDF截图进行精准语义还原 1. 模型概览 Qwen3.5-2B是通义千问团队推出的轻量化多模态基础模型,属于Qwen3.5系列的小参数版本(20亿参数)。这个模型主打低功耗、低门槛部署特性&#x…...