面试官问:如何确保缓存和数据库的一致性?
如果你对这个问题有过研究,应该可以发现这个问题其实很好回答,如果第一次听到或者第一次遇到这个问题,估计会有点懵,今天我们来聊聊这个话题。
1、问题分析
首先我们来看看为什么会有这个问题!
我们在日常开发中,为了提高数据响应速度,可能会将一些热点数据保存在缓存中,这样就不用每次都去数据库中查询了,可以有效提高服务端的响应速度,那么目前我们最常使用的缓存就是 Redis 了。
用 Redis 做缓存,并不是一说缓存就是 Redis,还是要结合业务的具体情况,我们可以根据不同业务对数据要求的实时性不同,将数据分为三级,以电商项目为例:
- 第 1 级:订单数据和支付流水数据:这两块数据对实时性和精确性要求很高,所以一般是不需要添加缓存的,直接操作数据库即可。
- 第 2 级:用户相关数据:这些数据和用户相关,具有读多写少的特征,所以我们使用 redis 进行缓存。
- 第 3 级:支付配置信息:这些数据和用户无关,具有数据量小,频繁读,几乎不修改的特征,所以我们使用本地内存进行缓存。
选中合适的数据存入 Redis 之后,接下来,每当要读取数据的时候,就先去 Redis 中看看有没有,如果有就直接返回;如果没有,则去数据库中读取,并且将从数据库中读取到的数据缓存到 Redis 中,大致上就是这样一个流程,读取数据的这个流程实际上是比较清晰也比较简单的,没啥好说的。
然而,当数据存入缓存之后,如果需要更新的话,往往会来带另外的问题:
- 当有数据需要更新的时候,先更新缓存还是先更新数据库?如何确保更新缓存和更新数据库这两个操作的原子性?
- 更新缓存的时候该怎么更新?修改还是删除?
怎么办?正常来说,我们有四种方案:
- 先更新缓存,再更新数据库。
- 先更新数据库,再更新缓存。
- 先淘汰缓存,再更新数据库。
- 先更新数据库,再淘汰缓存。
到底使用哪种?
在回答这个问题之前,我们不妨先来看看三个经典的缓存模式:
- Cache-Aside
- Read-Through/Write through
- Write Behind
2、Cache-Aside
Cache-Aside,中文也叫旁路缓存模式,如果我们能够在项目中采用 Cache-Aside,那么就能够尽可能的解决缓存与数据库数据不一致的问题,注意是尽可能的解决,并无法做到绝对解决。
Cache-Aside 又分为读缓存和写缓存两种情况,我们分别来看。
2.1、读缓存
先来看一张流程图:
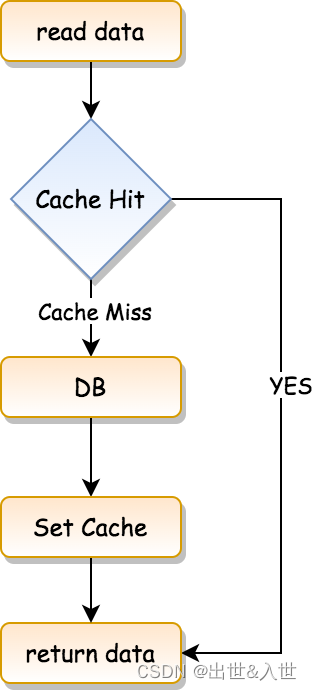
它的流程是这样:
- 读取数据。
- 检查缓存中是否有需要的数据,如果命中缓存(Cache Hit),则直接返回数据。
- 如果没有命中缓存,即 Cache Miss,那么就先去访问数据库。
- 将从数据库中读取到的数据设置到缓存中。
- 返回数据。
这是 Cache-Aside 的读缓存流程。
其实对于读缓存的流程而言,大家一般都没什么异议,有异议的主要是写流程,我们继续来看。
2.2、写缓存
先来看一张流程图:
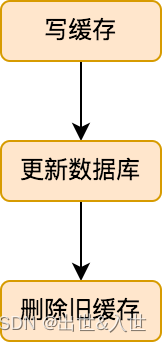
这个写缓存的流程就比较简单,先更新数据库中的数据,然后删除旧的缓存即可。
流程虽然简单,但是却引伸出来两个问题:
- 为什么是删除旧缓存而不是更新旧缓存?
- 为什么不先删除旧的缓存,然后再更新数据库?
我们来分别回答这两个问题。
为什么是删除旧缓存而不是更新旧缓存?
- 更新缓存,说着容易做起来并不容易。很多时候我们更新缓存并不是简简单单更新一个 Bean。很多时候,我们缓存的都是一些复杂操作或者计算(例如大量联表操作、一些分组计算)的结果,如果不加缓存,不但无法满足高并发量,同时也会给 MySQL 数据库带来巨大的负担。那么对于这样的缓存,更新起来实际上并不容易,此时选择删除缓存效果会更好一些。
- 对于一些写频繁的应用,如果按照
更新缓存->更新数据库的模式来,比较浪费性能,因为首先写缓存很麻烦,其次每次都要写缓存,但是可能写了十次,只读了一次,读的时候读到的缓存数据是第十次的,前面九次写缓存都是无效的,对于这种情况不如采取先写数据库再删除缓存的策略。 - 在多线程环境下,这样的更新策略还有可能会导致数据逻辑错误,来看如下一张流程图:
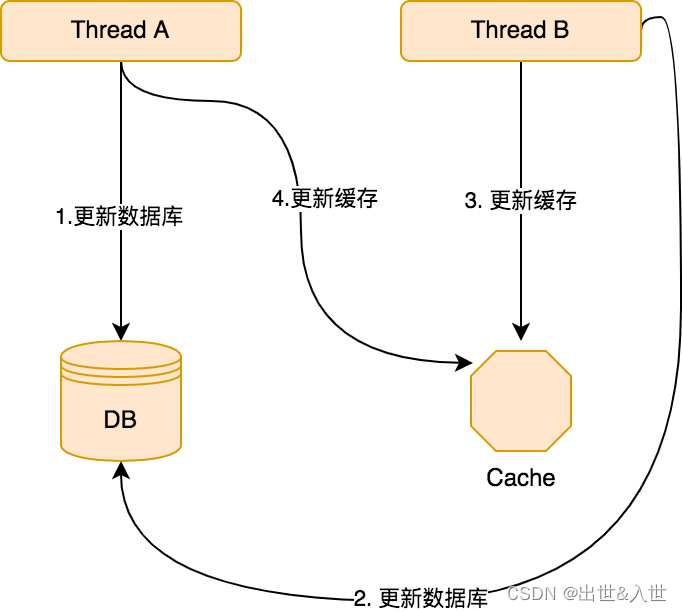
可以看到,有两个并发的线程 A 和 B:
- 首先 A 线程更新了数据库。
- 接下来 B 线程更新了数据库。
- 由于网络等原因,B 线程先更新了缓存。
- A 线程更新了缓存。
那么此时,缓存中保存的数据就是不正确的,而如果采用了删除缓存的方式,就不会发生这种问题了。
为什么不先删除旧的缓存,然后再更新数据库?
这个也是考虑到并发请求,假设我们先删除旧的缓存,然后再更新数据库,那么就有可能出现如下这种情况:
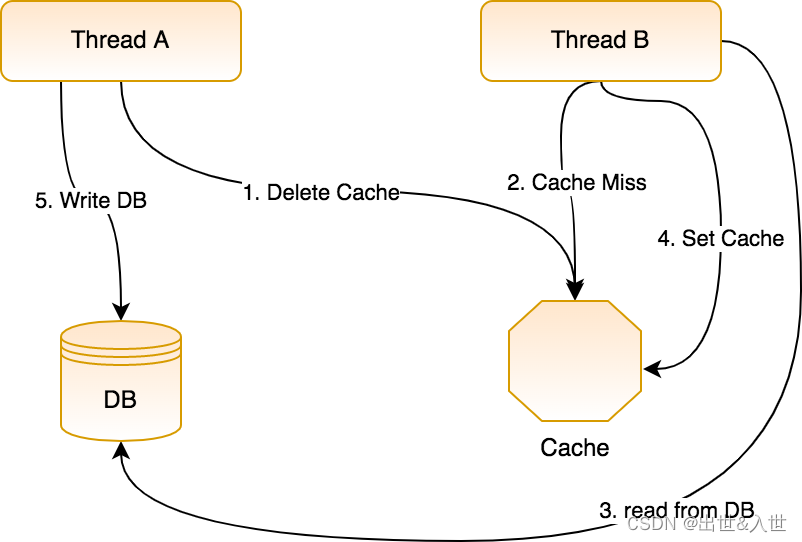
这个操作是这样的,有两个线程,A 和 B,其中 A 写数据,B 读数据,具体流程如下:
- A 线程首先删除缓存。
- B 线程读取缓存,发现缓存中没有数据。
- B 线程读取数据库。
- B 线程将从数据库中读取到的数据写入缓存。
- A 线程更新数据库。
一套操作下来,我们发现数据库和缓存中的数据不一致了!所以,在 Cache-Aside 中是先更新数据库,再删除缓存。
2.3、延迟双删
其实无论是先更新数据库再删除缓存,还是先删除缓存再更新数据库,在并发环境下都有可能存在问题:
假设有 A、B 两个并发请求:
- 先更新数据库再删除缓存:当请求 A 更新数据库之后,还未来得及进行缓存清除,此时请求 B 查询到并使用了 Cache 中的旧数据。
- 先删除缓存再更新数据库:当请求 A 执行清除缓存后,还未进行数据库更新,此时请求 B 进行查询,查到了旧数据并写入了 Cache。
当然我们前面已经分析过了,尽量先操作数据库再操作缓存,但是即使这样也还是有可能存在问题,解决问题的办法就是延迟双删。
延迟双删是这样:先执行缓存清除操作,再执行数据库更新操作,延迟 N 秒之后再执行一次缓存清除操作,这样就不用担心缓存中的数据和数据库中的数据不一致了。
那么这个延迟 N 秒,N 是多大比较合适呢?一般来说,N 要大于一次写操作的时间,如果延迟时间小于写入缓存的时间,会导致请求 A 已经延迟清除了缓存,但是此时请求 B 缓存还未写入,具体是多少,就要结合自己的业务来统计这个数值了。
2.4、如何确保原子性
但是更新数据库和删除缓存毕竟不是一个原子操作,要是数据库更新完毕后,删除缓存失败了咋办?
对于这种情况,一种常见的解决方案就是使用消息中间件来实现删除的重试。大家知道,MQ 一般都自带消费失败重试的机制,当我们要删除缓存的时候,就往 MQ 中扔一条消息,缓存服务读取该消息并尝试删除缓存,删除失败了就会自动重试。如果小伙伴们还不懂 RabbitMQ 的使用,可以在公众号江南一点雨后台回复 rabbitmq,有免费的视频+文档。
3、Read-Through/Write-Through
这种缓存操作模式,松哥印象最深的是在 Oracle Coherence 中有应用,不知道小伙伴们有没有用过 Oracle Coherence,这是一个内存数据网格,通过这个,应用开发人员和管理人员可快速访问键值数据,Coherence 可提供集群式低延迟数据存储、多语言网格计算和异步事件流处理,从而为客户企业应用赋予超高水平的可扩展性和性能。
Oracle Coherence 我们就不讨论了,我们就来说说 Read-Through。
3.1、Read-Through
这里为了省事,我就不自己画图了,网上找了一张图片,如下:
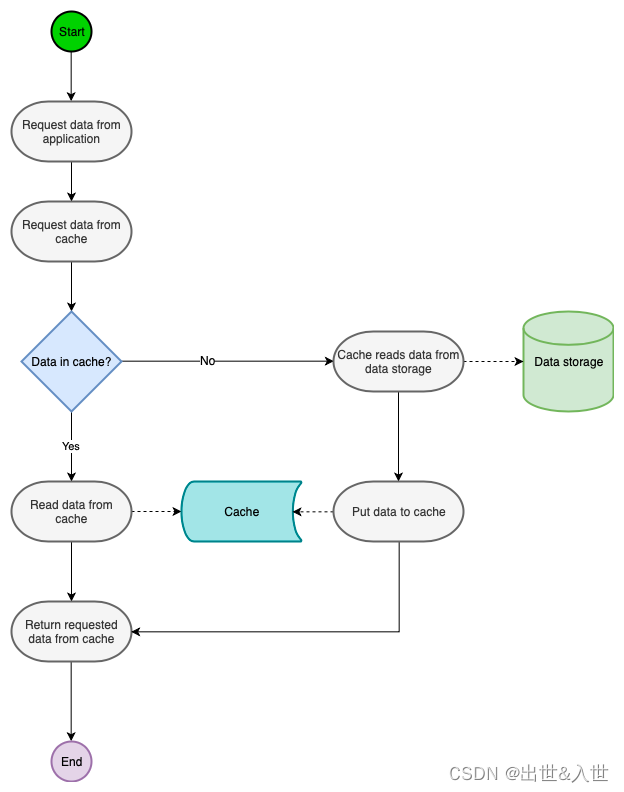
乍一看,很多人感觉这和 Cache-Aside 一样呀,没啥区别!是的,单看流程是不太容易看到区别。
Read-Through 是一种类似于 Cache-Aside 的缓存方法,区别在于,在 Cache-Aside 中,由应用程序决定去读取缓存还是读取数据库,这样就会导致应用程序中出现了很多业务无关的代码;而在 Read-Through 中,相当于多出来了一个中间层 Cache Middleware,由它去读取缓存或者数据库,应用层的代码得到了简化,松哥之前写过 Spring Cache 的用法,大家回忆下 Spring Cache 中的 @Cacheable 注解,感觉像不像 Read-Through?
我画一个简单的流程图大家来看下:

可以看到,和 Cache-Aside 相比,其实就相当于是多了一个 Cache Middleware,这样我们在应用程序中就只需要正常的读写数据就行了,并不用管底层的具体逻辑,相当于把缓存相关的代码从应用程序中剥离出来了,应用程序只需要专注于业务就行了。
3.2、Write-Through
Write-Through 其实也是差不多,所有的操作都交给 Cache Middleware 来完成,应用程序中就是一句简单的更新就行了,我们来看看流程:
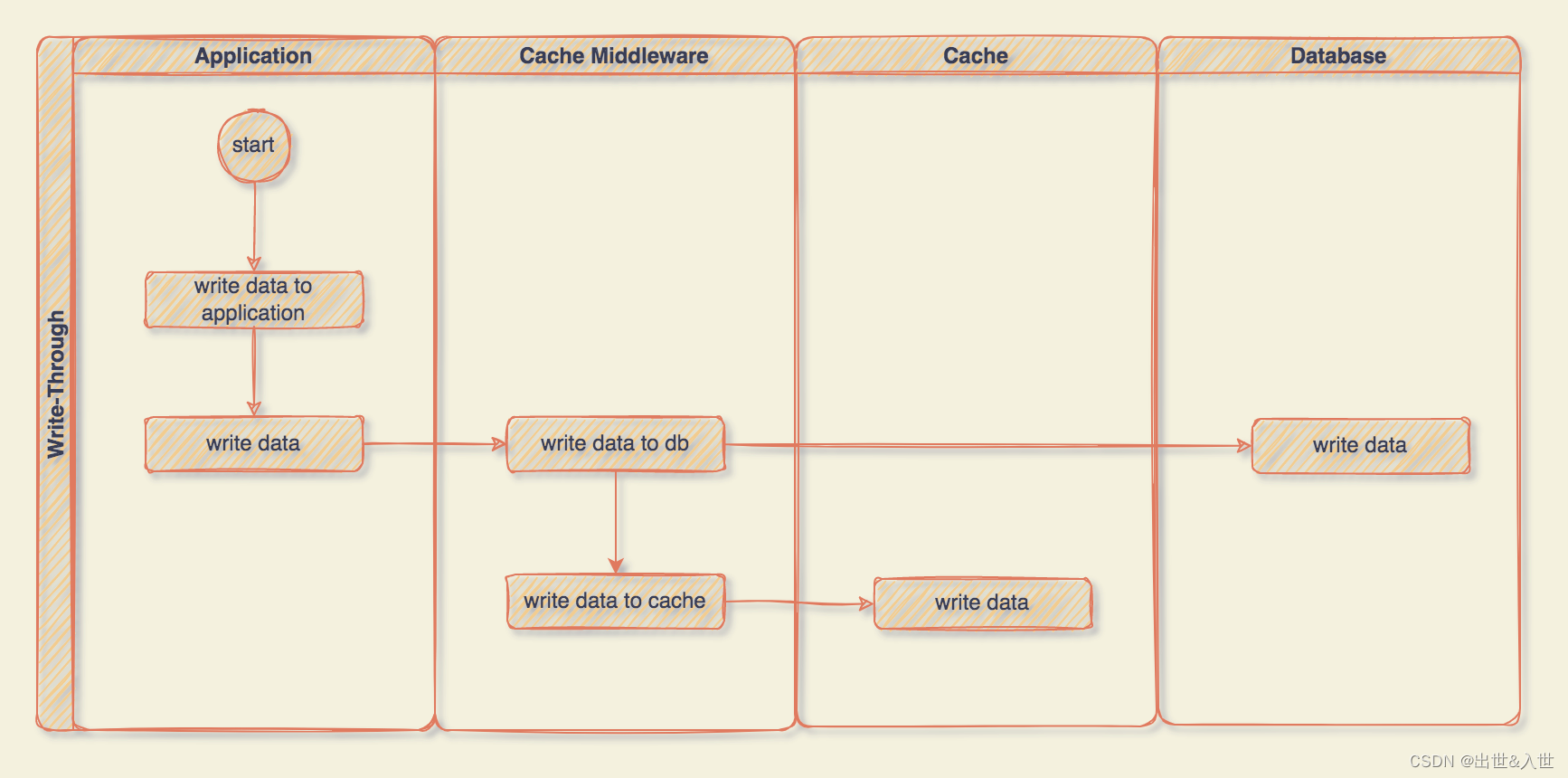
在 Write-Through 策略中,所有的写操作都经过 Cache Middleware,每次写入时,Cache Middleware 会将数据存储在 DB 和 Cache 中,这两个操作发生在一个事务中,因此,只有两个都写入成功,一切才会成功。
这种写数据的优势在于,应用程序只与 Cache Middleware 对话,所以它的代码更加干净和简单。
4、Write Behind
Write-Behind 缓存策略类似于 Write-Through 缓存,应用程序仅与 Cache Middleware 通信,Cache Middleware 会预留一个与应用程序通信的接口。
Write-Behind 与 Write-Through 最大的区别在于,前者是数据首先写入缓存,一段时间后(或通过其他触发器)再将数据写入 Database,并且这里涉及到的写入是一个异步操作。这种方式下,Cache 和 DB 数据的一致性不强,对一致性要求高的系统要谨慎使用,如果有人在数据尚未写入数据源的情况下直接从数据源获取数据,则可能导致获取过期数据,不过对于频繁写入的场景,这个其实非常适用。
将数据写入 DB 可以通过多种方式完成:
- 一种是收集所有写入操作,然后在某个时间点(例如,当 DB 负载较低时)对数据源进行批量写入。
- 另一种方法是将写入合并成更小的批次,例如每次收集五个写入操作,然后对数据源进行批量写入。
这个流程图就不想画了,在网上找了一张,小伙伴们参考下:

相关文章:
面试官问:如何确保缓存和数据库的一致性?
如果你对这个问题有过研究,应该可以发现这个问题其实很好回答,如果第一次听到或者第一次遇到这个问题,估计会有点懵,今天我们来聊聊这个话题。 1、问题分析 首先我们来看看为什么会有这个问题! 我们在日常开发中&am…...

16.数据库Redis
一、基本概念 Redis(Remote Dictionary Server)译为“远程字典服务”,它是一款基于内存实现的键值型 NoSQL 数据库, 通常也被称为数据结构服务器,这是因为它可以存储多种数据类型,比如 string(字…...

【Redis高级-集群分片】
单机安装Redis首先需要安装Redis所需要的依赖:yum install -y gcc tclRedis安装包上传到虚拟机的任意目录:我放到了/tmp目录:解压缩:tar -zxvf /tmp/redis-6.2.4.tar.gz -C /tmp解压后:进入redis目录:cd /t…...

CSDN - CSDN27题解
文章目录幸运数字题目描述解题思路AC代码投篮题目描述解题思路AC代码通货膨胀-x国货币题目描述解题思路AC代码最后一位题目描述解题思路AC代码CSDN编程竞赛报名地址:https://edu.csdn.net/contest/detail/41 这次题目描述刚开始好像有些问题,之后被修正了…...

docker拉取mysql
搜索mysql版本docker search mysql搜索获赞数(星星数量) 大于 1000 的镜像docker search --filterstars1000 mysql搜索官方发布的版本docker search --filter is-officialtrue mysql搜索版本号docker search mysql57拉取docker pull devbeta/mysql57查看下载镜像docker images启…...

在Linux上安装Python3
记录:373场景:在CentOS 7.9操作系统上,安装Python-3.8.9环境。版本:JDK 1.8 Python-3.8.9官网地址:https://www.python.org下载地址:https://www.python.org/ftp/python/1.安装基础依赖1.1安装gcc(1)安装命…...

23 种设计模式的通俗解释,看完秒懂
01 工厂方法 追 MM 少不了请吃饭了,麦当劳的鸡翅和肯德基的鸡翅都是 MM 爱吃的东西,虽然口味有所不同,但不管你带 MM 去麦当劳或肯德基,只管向服务员说「来四个鸡翅」就行了。麦当劳和肯德基就是生产鸡翅的 Factory 工厂模式&…...
如何做好需求管理?经验方法、模型、工具
需求管理能力是衡量产品经理能力的一个重要指标。因为需求是产品的基石,只有选取恰当的方法进行需求分析及管理,才能更好的构建产品方案,从而输出精准的产品定义。结合本人学习和自身经验,打算将需求管理分”需求挖掘”、”需求分…...
)
怎么用期货做风险对冲(如何利用期货对冲风险)
不同期货市场的同一期货品种的对冲交易怎么做 不同 期货市场 的同一期货品种的 对冲交易 。 因为地域和 制度环境 不同,同一种期货品种在不同市场的同一时间的价格很可能是不一样的,并且也是在不断变化的。 这样在一个市场做多头买进࿰…...

C++标准模板库type_traits源码剖析
一、type_traits源码介绍 1、type_traits是C11提供的模板元基础库。 2、type_traits可实现在编译期计算。包括添加修饰、萃取、判断查询、类型推导等等功能。 3、type_traits提供了编译期的true和false。 二、type_traits的作用 1、根据不同类型,模板匹配不同版本…...

Python获取公众号(pc客户端)数据,使用Fiddler抓包工具
前言 嗨喽~大家好呀,这里是魔王呐 ❤ ~! 今天来教大家如何使用Fiddler抓包工具,获取公众号(PC客户端)的数据。 Fiddler是一个http协议调试代理工具,它能够记录并检查所有你的电脑和互联网之间的http通讯,…...
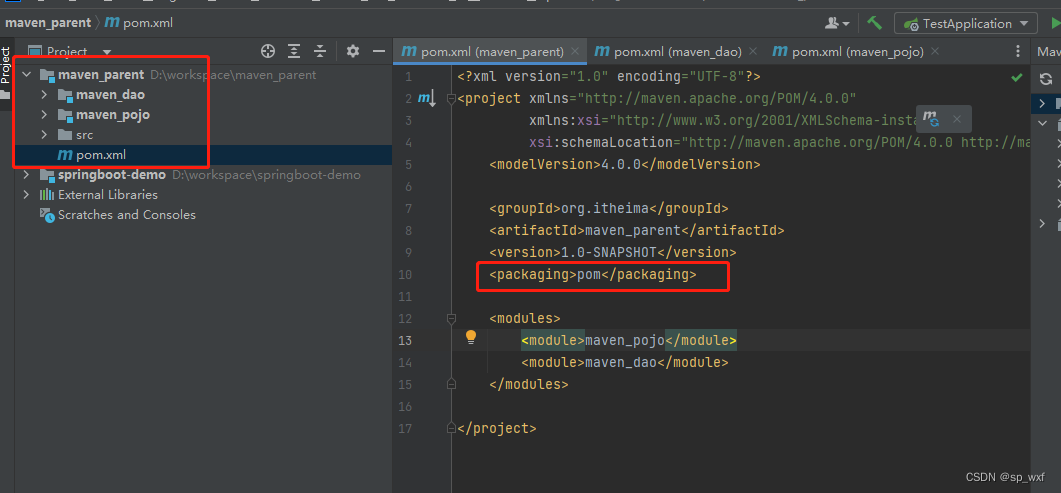
Maven进阶
这里写目录标题1.分模块开发1.1 模块更新后,会造成的影响2.依赖管理2.1 依赖传递2.2 可选依赖(隐藏自己的依赖,不让别人用)2.3 排除依赖(用别人的资源,把不用的去了)3.聚合与继承3.1 为什么要使用聚合工程?3.2 聚合工程开发2.1 聚合工程三级目录1.分模块开发 我们之前做的项目…...
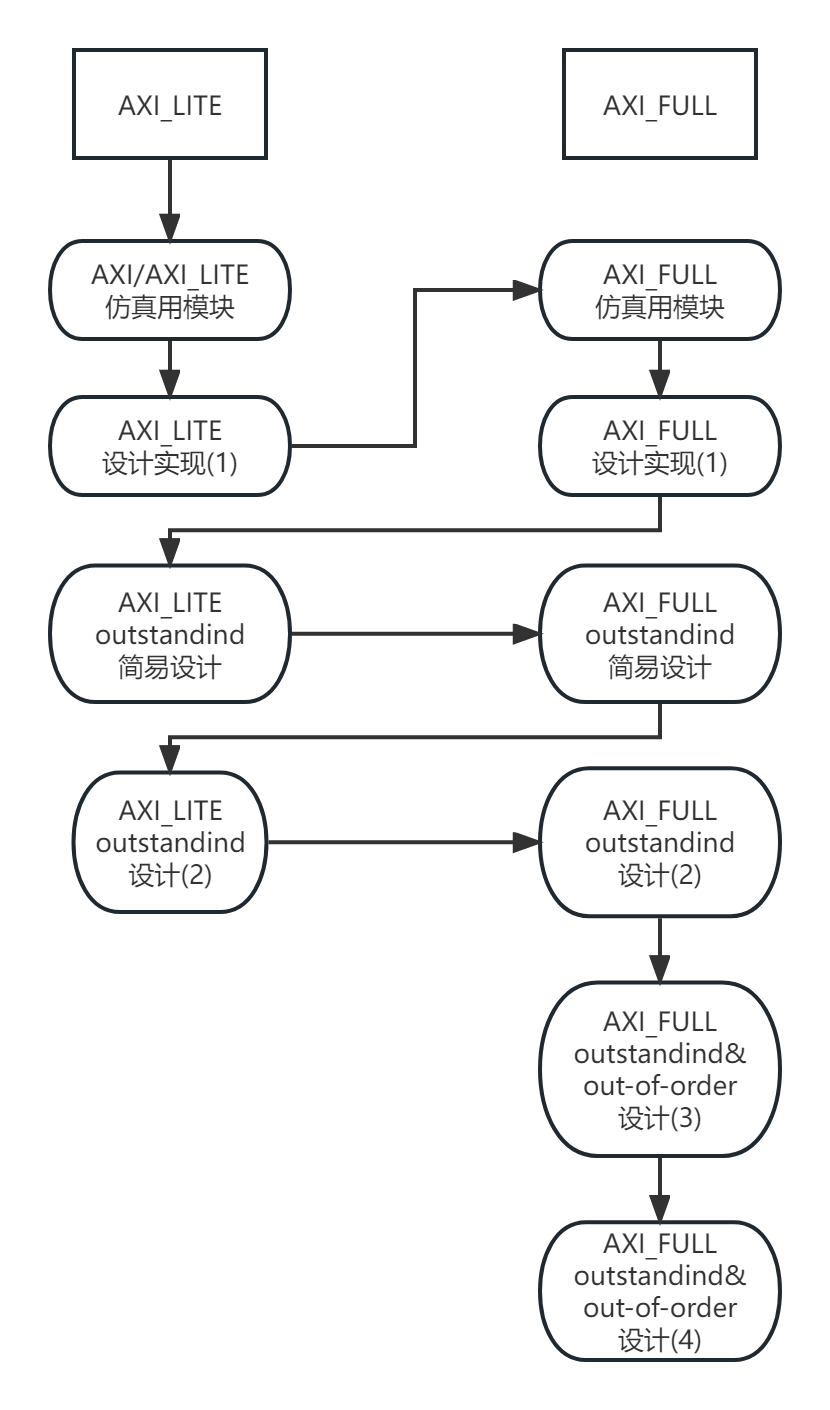
AXI实战(一)-为AXI总线搭建简单的仿真测试环境
AXI实战(一)-搭建简单仿真环境 看完在本文后,你将可能拥有: 一个可以仿真AXI/AXI_Lite总线的完美主端(Master)或从端(Slave)一个使用SystemVerilog仿真模块的船信体验小何的AXI实战系列开更了,以下是初定的大纲安排: 欢迎感兴趣的朋友关注并支持,以下为正文部分 文章目录…...
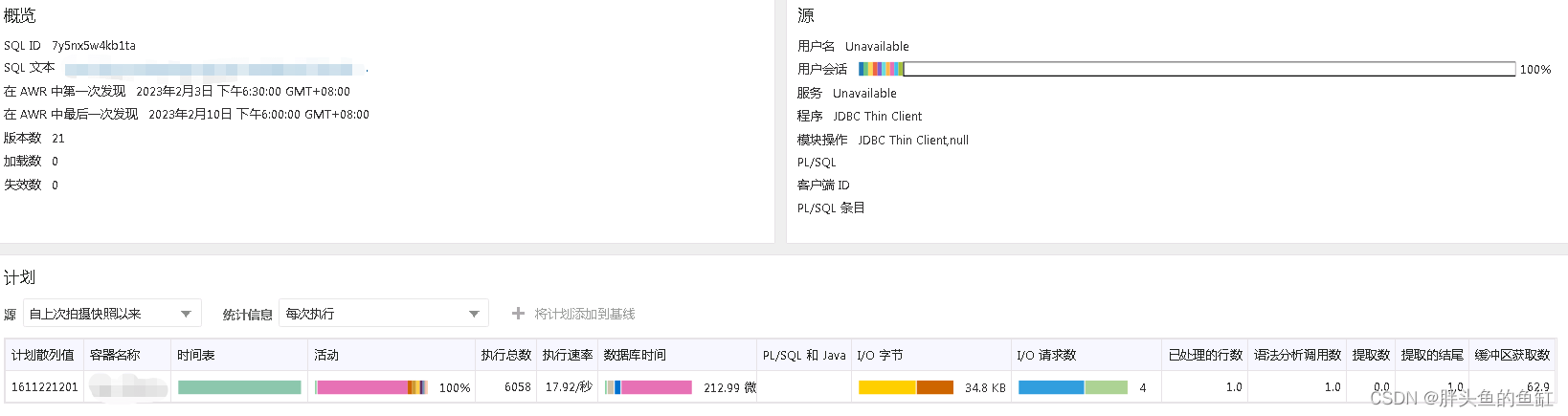
数据库管理-第五十六期 监控(20230210)
数据库管理 2023-02-10第五十六期 监控1 怎么监控2 直观3 历史分析4 另一个BUG总结第五十六期 监控 春节后的7天班过后就来到了2月份,本周对之前发现X8M上的那个bug进行补丁修复和协助从12.2迁移了一套PDB到这个一体机上面,2次割接。这周还和原厂老大哥…...
测试开发,测试架构师为什么能拿50 60k呢需要掌握哪些技能呢
这篇文章是软件工程系列知识总结的第五篇,同样我会以自己的理解来阐述软件工程中关于架构设计相关的知识。相比于我们常见的研发架构师,测试架构师是近几年才出现的一个岗位,当然岗位title其实没有特殊的含义,在我看来测试架构师其…...

Miniblink 入门
miniblink官网:入门之前强烈建议将Miniblink介绍仔细看一遍。 MB内核组件标准版接口文档:这里列举了所有的api以及简单的说明,但是本人建议还是看wke.h更方便,里面都是宏实现的,直接搜相关函数即可。 mb demo下载和参…...
[python入门㊷] - python存储数据
目录 ❤ json.dump()存储数据 ❤ json.laod()读取数据 ❤ 保存和读取用户生成的数据 ❤ 重构 JSON(JavaScript Object Notation)格式最初是为JavaScript开发的,但随后成了一种常见格式,被包括Python在内的众多语言采用 ❤ json.dump()存储数据…...

Little Fighter:旺角——NFT 系列来袭!
《小朋友齐打交 2 (LF2) 》是一款流行的格斗游戏,由 Marti Wong 和 Starsky Wong 于 1999 年创作。这是一款非常容易上瘾的游戏,具有多种游戏模式、横向卷轴格斗系统以及 24 个具有复杂动作和连击的不同角色。这款游戏在世界范围内非常受欢迎,…...
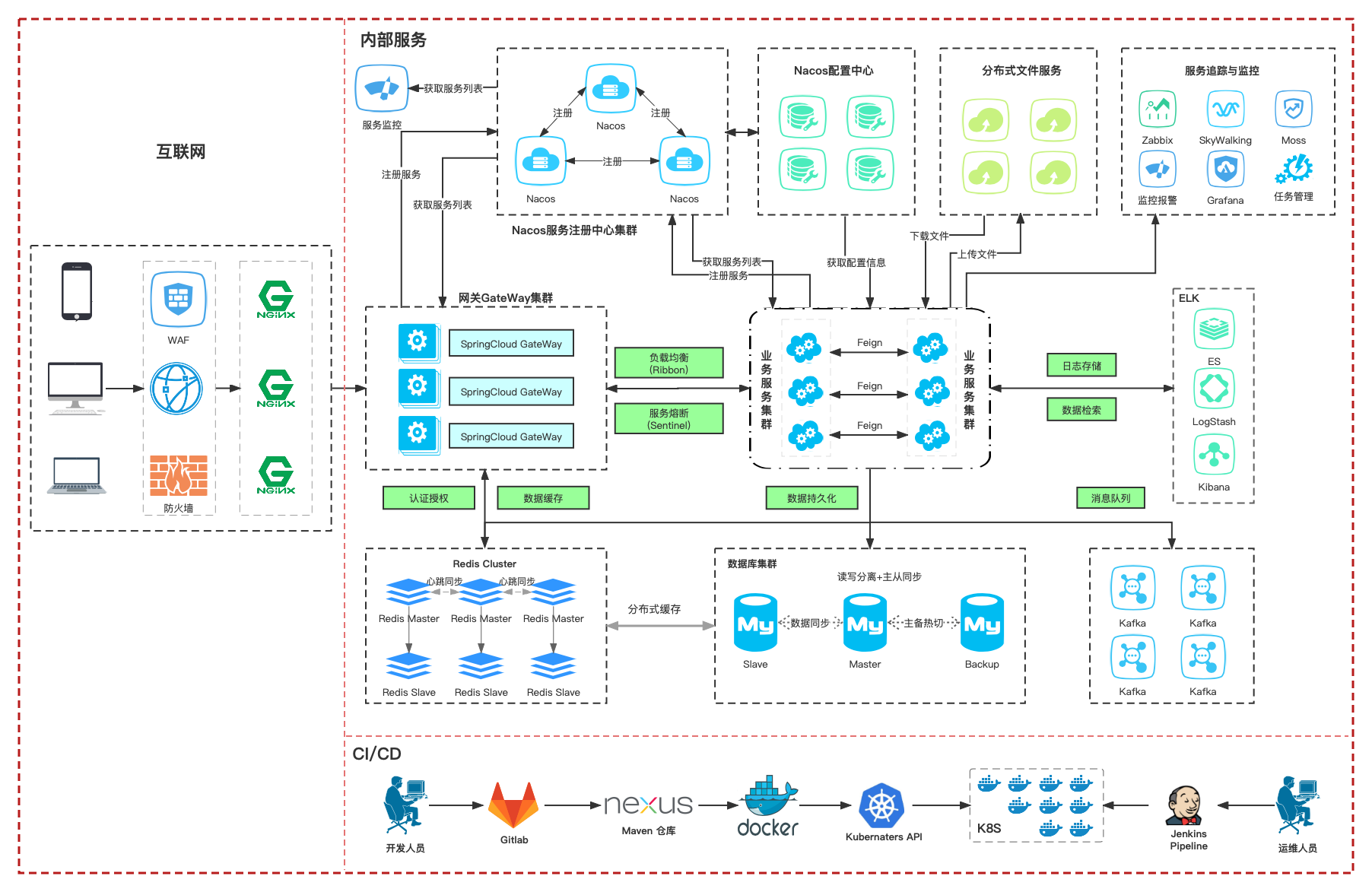
基础篇:01-微服务概述
1.单体应用与微服务架构区别 如上图左侧为单体应用架构。在传统单体应用中,所有功能模块都在一个工程中编码、部署,即使是集群部署,也只是单体应用的水平复制。 如上图右侧为微服务架构。在微服务架构的项目中,每个应用会按照领域…...
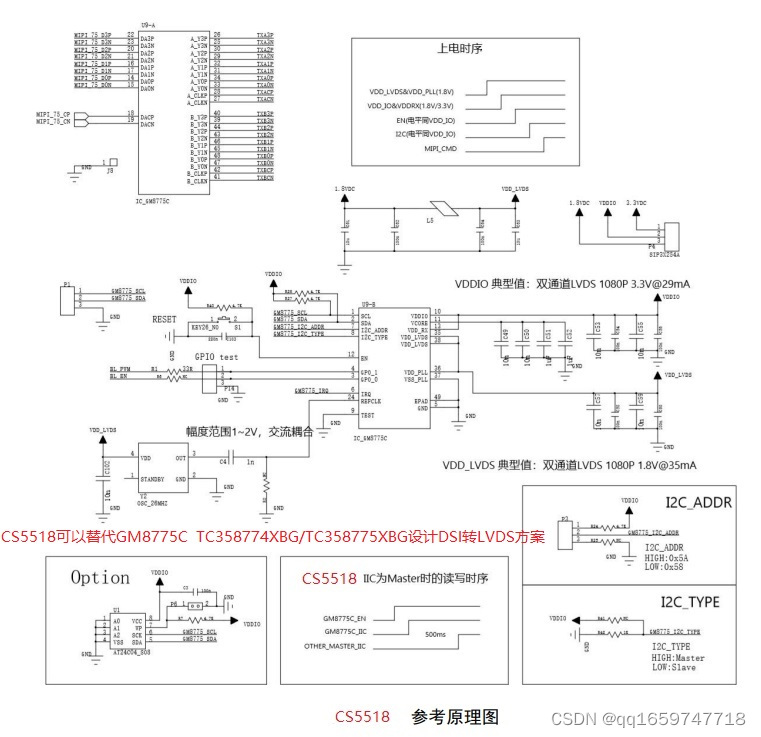
TC358775XBG替代方案|完美替代 TC358775XBG替代方案|低BOM成本DSI转LVDS方案CS5518
TC358775XBG替代方案|完美替代 TC358775XBG替代方案|低BOM成本DSI转LVDS方案CS5518 TC358775XBG芯片的主要功能是DSI到LVDS桥,通过DSI链路实现视频流输出,以驱动LVDS兼容的显示面板。该芯片支持单链路LVDS高达1366768 24位像素分辨率,双链路L…...

如何轻松解锁Cursor Pro完整功能:一键激活与无限使用的完整指南
如何轻松解锁Cursor Pro完整功能:一键激活与无限使用的完整指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached…...

ESP8266+STM32远程控制实战:如何通过华为云中转指令与数据
ESP8266STM32远程控制实战:华为云物联网全链路开发指南 在智能家居和工业监控领域,远程设备控制一直是核心技术痛点。当ESP8266遇上STM32,再通过华为云物联网平台搭建通信桥梁,这个组合能爆发出怎样的生产力?本文将带您…...
)
别再只用SCL当主时钟了!手把手教你用Verilog实现更可靠的I2C从机(附过采样方法)
突破传统:用Verilog构建高可靠I2C从机的过采样实战指南 在FPGA开发中,I2C从机接口的实现方式往往决定了系统的稳定性边界。当工程师们习惯性地将SCL信号直接作为时钟源时,却可能忽视了这种设计在真实硬件环境中暗藏的隐患——信号抖动引发的数…...

静态前端项目实战:从营销页到现代化门户的架构与实现
1. 项目概述:一个纯粹的静态前端项目最近在GitHub上看到了一个名为“Vibe Code”的项目,它的README写得非常漂亮,充满了各种炫酷的特性介绍,比如支持Claude Code、OpenAI Codex等AI编程助手,还有深色/亮色主题切换、多…...

GitHub Enterprise MCP服务器:企业级代码管理的AI智能助手
1. 项目概述:当GitHub Enterprise遇上MCP,企业级代码管理的“智能副驾”最近在折腾企业内部的开发工具链,发现一个痛点:我们团队重度依赖GitHub Enterprise Server(GHES)进行代码托管和协作,但日…...

从FLAG_ONE_SHOT到FLAG_IMMUTABLE:深入解析Android S+版本PendingIntent的强制变革
1. 当PendingIntent遇上Android S:崩溃背后的安全升级 最近不少开发者在升级targetSdkVersion到31(Android 12)后,突然遭遇这样的崩溃提示:"Targeting S requires that one of FLAG_IMMUTABLE or FLAG_MUTABLE be…...

2026年AI Agent工具淘汰预警:这7个已停止维护/降级为社区版/终止Python 3.12支持的工具请立即停用
更多请点击: https://kaifayun.com 第一章:2026年最佳AI Agent工具推荐 随着多模态推理、自主记忆与跨平台协同能力的成熟,2026年的AI Agent已从实验原型迈入生产级应用阶段。主流工具普遍支持RAG增强、动态工具调用(Tool Calli…...

解锁网络音视频传输:DistroAV插件从零构建高效工作流
解锁网络音视频传输:DistroAV插件从零构建高效工作流 【免费下载链接】obs-ndi DistroAV (formerly OBS-NDI): NDI integration for OBS Studio 项目地址: https://gitcode.com/gh_mirrors/ob/obs-ndi 在现代直播制作和视频协作场景中,跨设备高质…...

基于LLM的邮件智能体:从语义理解到自动化工作流实战
1. 项目概述:一个能“思考”的邮件智能体 最近在折腾一个挺有意思的开源项目,叫 XueJourney/mail-agent 。简单来说,它不是一个简单的邮件收发工具,而是一个能帮你“思考”和“行动”的邮件智能体。想象一下,你每天被…...

从手机5G到智能声呐:LMS自适应波束形成算法在真实场景里是怎么用的?
从手机5G到智能声呐:LMS自适应波束形成算法的工程实践 当你在嘈杂的会议室里对着智能音箱说话时,它为何能精准捕捉你的声音而忽略背景噪音?当5G基站需要同时服务数百个移动设备时,又是如何避免信号相互干扰?这些看似毫…...