flask中的操作数据库的插件Flask-SQLAlchemy
1、ORM 框架
Web 开发中,一个重要的组成部分便是数据库了。Web 程序中最常用的莫过于关系型数据库了,也称 SQL 数据库。另外,文档数据库(如 mongodb)、键值对数据库(如 redis)近几年也逐渐在 web 开发中流行起来,我们习惯把这两种数据库称为 NoSQL 数据库。
大多数的关系型数据库引擎(比如 MySQL、Postgres 和 SQLite)都有对应的 Python 包。在这里,我们不直接使用这些数据库引擎提供的 Python 包,而是使用对象关系映射(Object-Relational Mapper, ORM)框架,它将低层的数据库操作指令抽象成高层的面向对象操作。也就是说,如果我们直接使用数据库引擎,我们就要写 SQL 操作语句,但是,如果我们使用了 ORM 框架,我们对诸如表、文档此类的数据库实体就可以简化成对 Python 对象的操作。
Python 中最广泛使用的 ORM 框架是 SQLAlchemy,它是一个很强大的关系型数据库框架,不仅支持高层的 ORM,也支持使用低层的 SQL 操作,另外,它也支持多种数据库引擎,如 MySQL、Postgres 和 SQLite 等
2、Flask-SQLAlchemy
在 Flask 中,为了简化配置和操作,我们使用的 ORM 框架是 Flask-SQLAlchemy,这个 Flask 扩展封装了 SQLAlchemy 框架。在 Flask-SQLAlchemy 中,数据库使用 URL 指定,下表列出了常见的数据库引擎和对应的 URL
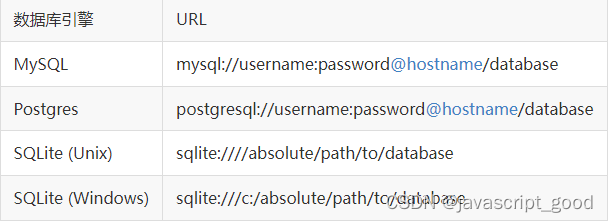
上面的表格中,username 和 password 表示登录数据库的用户名和密码,hostname 表示 SQL 服务所在的主机,可以是本地主机(localhost)也可以是远程服务器,database 表示要使用的数据库。有一点需要注意的是,SQLite 数据库不需要使用服务器,它使用硬盘上的文件名作为 database。
3、一个最小的应用
创建数据库
首先,我们使用 pip 安装 Flask-SQLAlchemy:
pip install flask-sqlalchemy
接下来,我们配置一个简单的 SQLite 数据库:
$ cat app.py
# -*- coding: utf-8 -*-
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///db/users.db'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True
db = SQLAlchemy(app)
class User(db.Model):"""定义数据模型"""__tablename__ = 'users'id = db.Column(db.Integer, primary_key=True)username = db.Column(db.String(80), unique=True)email = db.Column(db.String(120), unique=True)def __init__(self, username, email):self.username = usernameself.email = emaildef __repr__(self):return '<User %r>' % self.username
这里有几点需要注意的是:
- app 应用配置项 SQLALCHEMY_DATABASE_URI 指定了 SQLAlchemy 所要操作的数据库,这里我们使用的是 SQLite,数据库 URL 以 sqlite:/// 开头,后面的 db/users.db 表示数据库文件存放在当前目录的 db 子目录中的 users.db 文件。当然,你也可以使用绝对路径,如 /tmp/users.db 等。
- db 对象是 SQLAlchemy 类的实例,表示程序使用的数据库。
- 我们定义的 User 模型必须继承自 db.Model,这里的模型其实就对应着数据库中的表。其中,类变量__tablename__ 定义了在数据库中使用的表名,如果该变量没有被定义,Flask-SQLAlchemy 会使用一个默认名字。
接着,我们创建表和数据库。为此,我们先在当前目录创建 db 子目录和新建一个 users.db 文件,然后在交互式 Python shell 中导入 db 对象并调用 SQLAlchemy 类的 create_all() 方法:
$ mkdir db
$ python
>>> from app import db
>>> db.create_all()
我们验证一下,”users” 表是否创建成功:
$ sqlite3 db/users.db # 打开数据库文件
SQLite version 3.8.10.2 2015-05-20 18:17:19
Enter ".help" for usage hints.
sqlite> .schema users # 查看 "user" 表的 schema
CREATE TABLE users (id INTEGER NOT NULL,username VARCHAR(80),email VARCHAR(120),PRIMARY KEY (id),UNIQUE (username),UNIQUE (email)
);
插入数据
我们创建一些用户,通过使用 db.session.add()来添加数据:
@app.route('/adduser')
def add_user():user1 = User('ethan', 'ethan@example.com')user2 = User('admin', 'admin@example.com')user3 = User('guest', 'guest@example.com')user4 = User('joe', 'joe@example.com')user5 = User('michael', 'michael@example.com')db.session.add(user1)db.session.add(user2)db.session.add(user3)db.session.add(user4)db.session.add(user5)db.session.commit()return "<p>add succssfully!"
这里有一点要注意的是,我们在将数据添加到会话后,在最后要记得调用 db.session.commit() 提交事务,这样,数据才会被写入到数据库。
查询数据
查询数据主要是用 query 接口,例如 all() 方法返回所有数据,filter_by() 方法对查询结果进行过滤,参数是键值对,filter 方法也可以对结果进行过滤,但参数是布尔表达式,详细的介绍请查看这里。
>>> from app import User
>>> users = User.query.all()
>>> users
[<User u'ethan'>, <User u'admin'>, <User u'guest'>, <User u'joe'>, <User u'michael'>]
>>>
>>> user = User.query.filter_by(username='joe').first()
>>> user
<User u'joe'>
>>> user.email
u'joe@example.com'
>>>
>>> user = User.query.filter(User.username=='ethan').first()
>>> user
<User u'ethan'>
如果我们想查看 SQLAlchemy 为查询生成的原生 SQL 语句,只需要把 query 对象转化成字符串:
>>> str(User.query.filter_by(username='guest'))
'SELECT users.id AS users_id, users.username AS users_username, users.email AS users_email \nFROM users \nWHERE users.username = :username_1'
分页方法
分页方法可以采用 limit() 和 offset() 方法,比如从第 3 条记录开始取(注意是从 0 开开始算起),并最多取 1 条记录,可以这样:
users = User.query.limit(1).offset(3)
更新数据
更新数据也用 add() 方法,如果存在要更新的对象,SQLAlchemy 就更新该对象而不是添加。
>>> from app import db
>>> from app import User
>>>
>>> admin = User.query.filter_by(username='admin').first()
>>>
>>> admin.email = 'admin@hotmail.com'
>>> db.session.add(admin)
>>> db.session.commit()
>>>
>>> admin = User.query.filter_by(username='admin').first()
>>> admin.email
u'admin@hotmail.com'
删除数据
删除数据用 delete() 方法,同样要记得 delete 数据后,要调用 commit() 提交事务:
>>> from app import db
>>> from app import User
>>>
>>> admin = User.query.filter_by(username='admin').first()
>>> db.session.delete(admin)
>>> db.session.commit()
相关文章:
flask中的操作数据库的插件Flask-SQLAlchemy
1、ORM 框架 Web 开发中,一个重要的组成部分便是数据库了。Web 程序中最常用的莫过于关系型数据库了,也称 SQL 数据库。另外,文档数据库(如 mongodb)、键值对数据库(如 redis)近几年也逐渐在 w…...

arrow的使用
pandas2.0引入了pyarrow作为可选后端,比numpy的性能提高很多,所以为了改造backtrader,用cython和c++重写整个框架,准备用arrow作为底层的数据结构(backtrader现在的底层数据结构是基于python array构建的) 安装arrow推荐使用vcpkg git clone https://github.com/Microsoft…...
))
【24种设计模式】装饰器模式(Decorator Pattern(Wrapper))
装饰器模式 装饰器模式是一种结构型设计模式,用于动态地给对象添加额外的行为或责任,而不需要改变原始对象的结构。通过创建一个包装器类(装饰器),它包含原始对象的引用,并提供与原始对象相同的接口&#…...

小程序v-for与key值使用
小程序中的v-for和key与Vue中的用法基本相同。v-for用于循环渲染列表,key用于给每个循环项分配一个唯一的标识。 使用v-for时,通常建议使用wx:for代替,例如: <view wx:for"{{ items }}" wx:key"id">{…...
Qt包含文件不存在问题解决 QNetworkAccessManager
这里用到了Qt的网络模块,在.pro中添加了 QT network 但是添加 #include <QNetworkAccessManager> 会报错说找不到,可以通过在项目上右键执行qmake后,直接#include <QNetworkAccessManager>就不会报错了:...
【视频图像篇】FastStone Capture屏幕长截图软件
【视频图像篇】FastStone Capture屏幕长截图软件 FastStone Capture最常用的一款屏幕长截图软件—【蘇小沐】 文章目录 【视频图像篇】FastStone Capture屏幕长截图软件实验环境1、启动界面2、自定义工具栏3、自动保存 (一)长截图1、捕获滚动窗口2、捕获…...
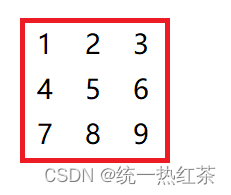
【C语言】每日一题(杨氏矩阵查找数)
目录 杨氏矩阵介绍:方法:思路:代码实现: 杨氏矩阵介绍: 既然在杨氏矩阵中查找数,那什么是杨氏矩阵呢? 矩阵的每行从左到右是递增的,矩阵从上到下是递增的。 例如: 方法…...
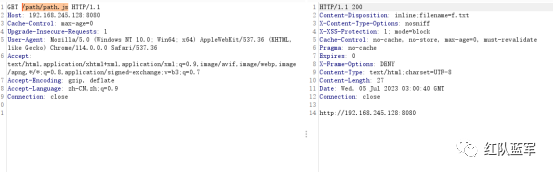
探究SpringWeb对于请求的处理过程
探究目的 在路径归一化被提出后,越来越多的未授权漏洞被爆出,而这些未授权多半跟spring自身对路由分发的处理机制有关。今天就来探究一下到底spring处理了什么导致了才导致鉴权被绕过这样严重的问题。 DispatcherServlet介绍 首先在分析spring对请求处…...
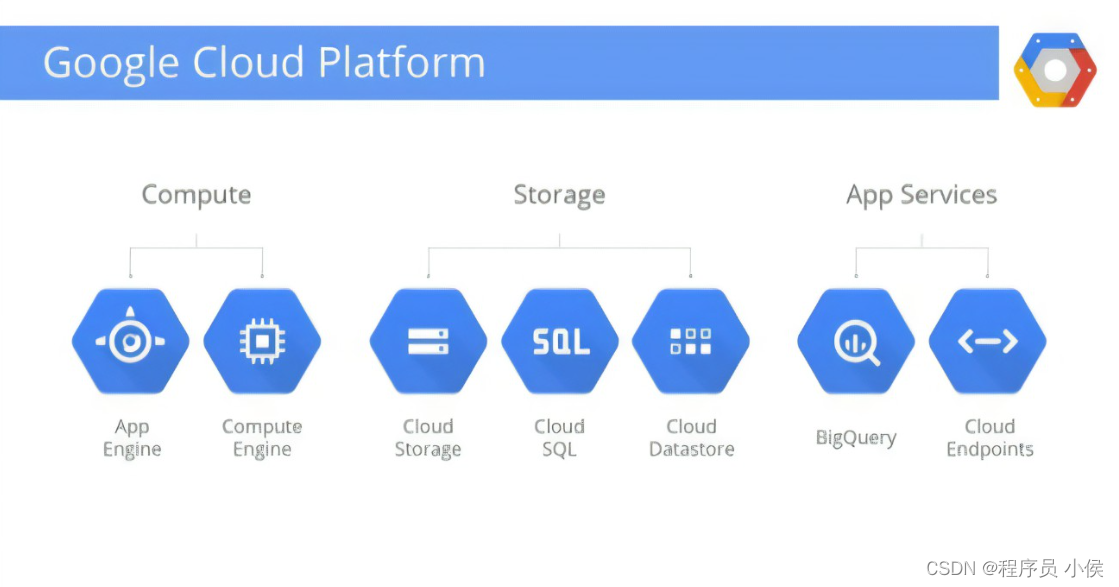
如何使用Google Compute Engine入门指南快速创建和配置您的云虚拟机实例
文章目录 步骤1:创建 Google Cloud Platform(GCP)账户步骤2:设置 GCP 项目步骤3:启用 Google Compute Engine API步骤4:安装 Google Cloud SDK步骤5:创建虚拟机实例步骤6:连接到虚拟…...

springMVC中全局异常处理
前言: 当不同方法执行时,抛出相同异常。为了简约代码和避免重复使用try{}catch{}。此时使用统一异常处理。但局部的统一异常处理只能为所在类所调用。因此产生全局异常处理,该类中统一异常处理方法可以作用于整个controller。(以…...

【Nginx24】Nginx学习:压缩模块Gzip
Nginx学习:压缩模块Gzip 又是一个非常常见的模块,Gzip 现在也是事实上的 Web 应用压缩标准了。随便打开一个网站,在请求的响应头中都会看到 Content-Encoding: gzip 这样的内容,这就表明当前这个请求的页面或资源使用了 Gzip 压缩…...
)
我的私人笔记(zookeeper分布式安装)
分布式安装 1.安装前准备 (1)下载zookeeper:Index of /dist/zookeeper(当前使用为3.4.10版本) (2)安装JDK (3)拷贝zookeeper安装包到Linux系统下 (4)解压到指定目录 tar -xzvf zookeeper-3.4.10.tar.gz -C /opt/servers/ (5)修改名称 …...

小程序排名优化全攻略
随着小程序的快速发展,小程序之间的竞争也日益激烈。如何在竞争对手众多的环境下脱颖而出,通过小程序排名优化来提高曝光率和流量转化率,已成为许多小程序开发者和运营者关注的重点。本文将全面解析小程序排名优化的方法,让您可以更好地提升小程序的搜索排名。 【名即微】 小程…...

MySQL MHA
什么是 MHA MHA(Master High Availability)是一套优秀的MySQL高可用环境下故障切换和主从复制的软件 MHA 的出现就是解决MySQL 单点故障的问题 MySQL故障切换过程中,MHA能做到0-30秒内自动完成故障切换操作 MHA能在故障切换的过程中最大程度上…...
)
Java API速记手册(持续更新ing...)
诸神缄默不语-个人CSDN博文目录 之所以干这个事原因也很简单,因为我3年没写Java了,现在在复健。 因为我最近都在用Python,所以跟Python一样的部分我就不写了。 最基本的框架public class MainClass {public static void main(String[] args…...
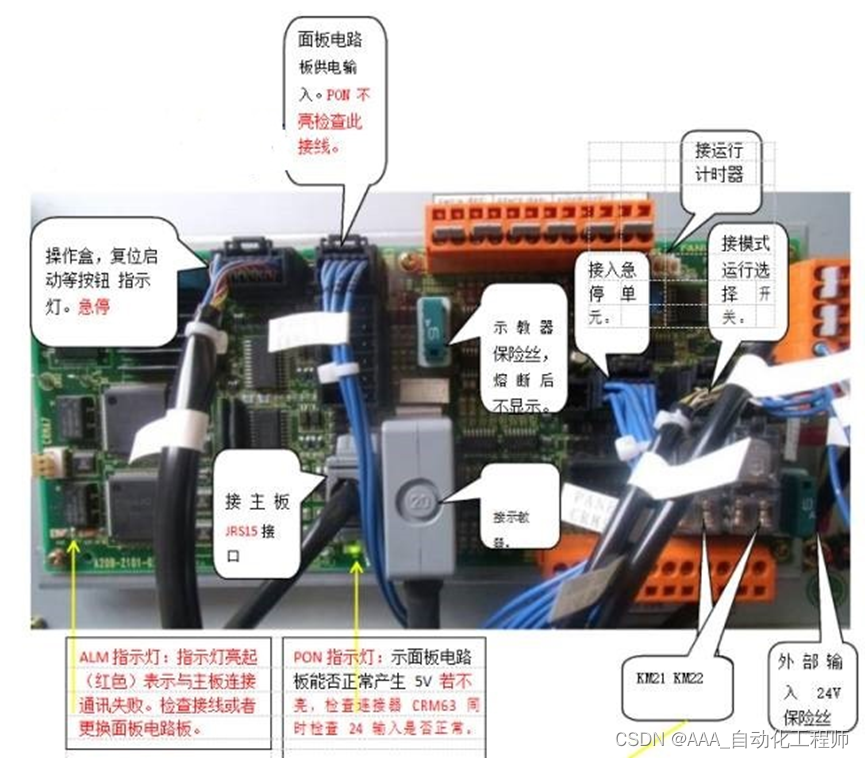
FANUC机器人电气控制柜内部硬件电路和模块详细介绍
FANUC机器人电气控制柜内部硬件电路和模块详细介绍 PSU电源单元 通过背板传输了如下电源 +5 +2.0V +3.3 +24v +24E +15V -15V 主板--接口描述: 主板内部结构: 面板电路板: 引申一下 KM21 与 KM22 的作用它们分别接至操作面板上上的急停按...

LGFormer:LOCAL TO GLOBAL TRANSFORMER FOR VIDEO BASED 3D HUMAN POSE ESTIMATION
基于视频的三维人体姿态估计的局部到全局Transformer 作者:马海峰 *,陆克 * †,薛健 *,牛泽海 *,高鹏程† * 中国科学院大学工程学院,北京100049 鹏程实验室,深圳518055 来源:202…...
数据结构零基础入门篇(C语言实现)
前言:数据结构属于C学习中较难的一部分,对应学习者的要求较高,如基础不扎实,建议着重学习C语言中的指针和结构体,万丈高楼平地起。 目录: 一,链表 1)单链表的大致结构实现 2&…...

Hugging News #0904: 登陆 AWS Marketplace
每一周,我们的同事都会向社区的成员们发布一些关于 Hugging Face 相关的更新,包括我们的产品和平台更新、社区活动、学习资源和内容更新、开源库和模型更新等,我们将其称之为「Hugging News」。本期 Hugging News 有哪些有趣的消息࿰…...
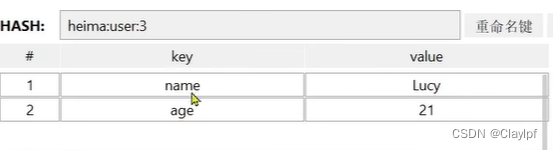
Redis Redis的数据结构 - 通用命令 - String类型命令 - Hash类型命令
目录 Redis的数据结构: Redis命令: 通用命令:(通用指令是部分数据类型的,都可以使用的指令) KEYS查询命令: DEL删除命令: EXISTS判断命令: EXPIPE有效期设置命令&…...

MCP协议实战:构建AI智能体任务管理服务器与二次开发指南
1. 项目概述:一个为AI智能体“开眼”的MCP服务器最近在折腾AI智能体(Agent)开发的朋友,估计都绕不开一个词:MCP。全称是Model Context Protocol,你可以把它理解为给大模型(比如Claude、GPT-4&am…...

长沙定制开发本地生活APP打造城市便民消费场景
随着长沙城市发展,市民对便民消费的需求越来越高,长沙本地生活APP定制开发也逐渐成为本地商家、政企单位布局数字化的重要选择。不同于通用模板APP,长沙定制本地生活APP可根据长沙本地特色,整合餐饮、生鲜、家政、休闲娱乐、政务便…...

Pega Helm Charts:Kubernetes上自动化部署Pega平台的完整指南
1. 项目概述与核心价值如果你正在或即将在Kubernetes上部署Pega Platform,那么pegasystems/pega-helm-charts这个项目绝对是你绕不开的“官方说明书”和“自动化工具箱”。简单来说,这是Pega官方维护的一套Helm Chart,专门用于将Pega Platfor…...

Notero终极指南:打通Zotero与Notion的学术工作流桥梁
Notero终极指南:打通Zotero与Notion的学术工作流桥梁 【免费下载链接】notero A Zotero plugin for syncing items and notes into Notion 项目地址: https://gitcode.com/gh_mirrors/no/notero 当你在Zotero中积累了数百篇文献,却发现整理和引用它…...

ESP32音频播放终极指南:从SD卡播放MP3到网络流媒体的完整解决方案
ESP32音频播放终极指南:从SD卡播放MP3到网络流媒体的完整解决方案 【免费下载链接】ESP32-audioI2S Play mp3 files from SD via I2S 项目地址: https://gitcode.com/gh_mirrors/es/ESP32-audioI2S 想要在ESP32上构建专业的音频播放系统吗?ESP32-…...

LayerDivider终极指南:5分钟掌握智能插画分层技术
LayerDivider终极指南:5分钟掌握智能插画分层技术 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider 你是否曾经面对一张复杂的插画作品…...

AI Agent 的难点,不在搭 Demo,而在让人敢交任务
Agent难在让人敢托付 很多团队做 Agent 的误会,是把跑通一次当成好用。 现在搭一个 Demo 确实不难。一个大模型,几段提示词,接几个搜索、表格、浏览器或数据库工具,很快就能演示一个会拆任务、会调用工具、会输出结果的流程。看起…...

从规范到验证:构建企业级环境变量与密钥安全管理体系
1. 项目概述:从“裸奔”到“装甲车”的密钥管理进化在开发一个现代应用时,我们几乎不可避免地要和一堆敏感信息打交道:数据库密码、API密钥、第三方服务的访问令牌、加密盐值……这些信息,我们通常称之为“环境变量”或“密钥”。…...
核心算法,搞定面试高频考点)
C++数据结构进阶|排序:吃透O(n log n)核心算法,搞定面试高频考点
文章目录 前言 一、希尔排序(Shell Sort)—— 插入排序的进阶优化版 二、快速排序(Quick Sort)—— C面试手写高频,实际开发首选 三、归并排序(Merge Sort)—— 稳定排序的核心选择 四、堆排…...

Windows安卓子系统终极指南:从基础配置到专业开发全流程
Windows安卓子系统终极指南:从基础配置到专业开发全流程 【免费下载链接】WSA Developer-related issues and feature requests for Windows Subsystem for Android 项目地址: https://gitcode.com/gh_mirrors/ws/WSA 想要在Windows 11上无缝运行安卓应用吗&…...