C++算法 —— 分治(2)归并
文章目录
- 1、排序数组
- 2、数组中的逆序对
- 3、计算右侧小于当前元素的个数
- 4、翻转对
本篇前提条件是已学会归并排序
1、排序数组
912. 排序数组

排序数组也可以用归并排序来做。
vector<int> tmp;//写成全局是因为如果在每一次小的排序中都创建一次,更消耗时间和空间,设置成全局的就更高效vector<int> sortArray(vector<int>& nums) {tmp.resize(nums.size());mergeSort(nums, 0, nums.size() - 1);return nums;}//归并做法void mergeSort(vector<int>& nums, int left, int right){if(left >= right) return ;int mid = (left + right) / 2;mergeSort(nums, left, mid);mergeSort(nums, mid + 1, right);int cur1 = left, cur2 = mid + 1, i = 0;while(cur1 <= mid && cur2 <= right){tmp[i++] = nums[cur1] <= nums[cur2] ? nums[cur1++] : nums[cur2++];}while(cur1 <= mid) tmp[i++] = nums[cur1++];while(cur2 <= right) tmp[i++] = nums[cur2++];for(int i = left; i <= right; i++){nums[i] = tmp[i - left];}}
2、数组中的逆序对
剑指 Offer 51. 数组中的逆序对
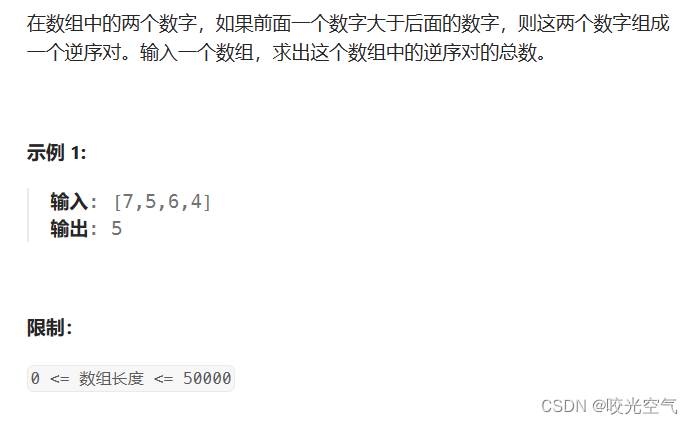
如果暴力枚举,一定是可以解决问题的,但肯定不用这个解法。选择逆序对,可以先把数组分成两部分,左半部分 + 右半部分的逆序对,以及再找左半部分的数字和右半部分数字成对的数,比如上面例子中,7和6,7和4就是这种情况。左 + 右 + 一左一右就是整体的逆序对数量。当这两半部分都处理完后,就扩大区间,继续上述操作。这个解法也就是利用归并排序,归并排序的思路就是划分到最小的区间,只有1个数,它一定是有序的,回到上一层,也就是2个数的区间,让它们排好序,在它右边的也是2个数的区间,重复和它一样的操作,这样两个区间都有序后,再往上走一层,来到4个数的区间,4个数,每一半都是有序的,将整体的4个数排成有序的,再往上走,来到8个数的区间,重复操作。
利用归并排序的思路,我们在两个区间都排成升序后,定义两个指针cur指向两个区间的开头,然后一左一右比较大小,如果cur1比cur2大,那么cur1之后都比cur2大,就可以一次性加上多个逆序对的个数。
下面的代码可以从最小的区间开始一个个代入来理解。从只有2个数的区间开始,走到递归处,分成2个只有1个数的区间,那就会返回0,两处递归走完,来到下面的循环,此时left是0,right是1,mid是0,带入进去会发现,最后的ret只会是0或者1,并且这2个数也在最后排好序了,返回后,来到上一层,也就是走左边递归的那行代码,然后再走右边,也是2个数,也是同样的操作,2个区间排好序了,4个数的区间就一左一右比较大小,找出逆序对,排好序,再走到上一层,8个数的区间也是如此。
class Solution {int tmp[50010];
public:int reversePairs(vector<int>& nums) {return mergeSort(nums, 0, nums.size() - 1);}int mergeSort(vector<int>& nums, int left, int right){if(left >= right) return 0;int ret = 0;//1. 找中间点,将数组分成两部分int mid = (left + right) >> 1;// [left, mid] [mid + 1, right]//2. 左边个数 + 排序 + 右边个数 + 排序ret += mergeSort(nums, left, mid);ret += mergeSort(nums, mid + 1, right);//3. 一左一右的个数int cur1 = left, cur2 = mid + 1, i = 0;while(cur1 <= mid && cur2 <= right)//while体内原本是归并排序的代码,现在就多加一点{if(nums[cur1] <= nums[cur2]) tmp[i++] = nums[cur1++];else{ret += mid - cur1 + 1;tmp[i++] = nums[cur2++];}}//4. 处理排序while(cur1 <= mid) tmp[i++] = nums[cur1++];while(cur2 <= right) tmp[i++] = nums[cur2++];for(int j = left; j <= right; j++){nums[j] = tmp[j - left];//排序}return ret;}
};
3、计算右侧小于当前元素的个数
315. 计算右侧小于当前元素的个数

此题和上一个题有相同之处,也是分治,也是利用归并排序,这道题可以看作,当前元素后面,有多少比我小的,而上一题则是当前元素前面,有多少比我大的。仔细想一想,上一题是排升序,这一题排降序则更为合适。这题和上一题还有不同的地方。
cur1和cur2,排成降序,如果cur1 <= cur2,cur2++,因为我们要找比当前元素小的;如果cur1 > cur2,由于是降序,那么cur2之后的肯定都小,但这里不能加上ret,我们要返回一个数组,要把这个数加在当前元素的原始下标,因为数组已经被我们给排序了,所以要找原始下标。这里的做法就是从最一开始就除了tmp外,再定义一个数组,存储着原始下标,因为这时候还没开始排序,可以找得到,然后每次原数组元素变换位置,这个下标数组也跟着变换。
我们要定义四个数组,一个是结果数组,一个是原始下标数组,一个是辅助数组,也就是tmp,记录改动过的顺序,一个是下标辅助数组,记录改动后的下标顺序。在while循环中,每次更新tmp,下标辅助数组也跟着更新。如果cur1大于cur2,那么除了更新,还需要往结果数组中写入个数,要在当前元素的原始下标处写入个数,这里最好要画图来理解,画原始下标和下标变动后的图。在最后for循环中的排序,除了原数组nums,还有原始下标数组也要排序。
vector<int> index;//原始元素下标vector<int> res;//最终结果int tmp[500010];//排序辅助数组int tmpIndex[500010];//元素下标的辅助数组
public:vector<int> countSmaller(vector<int>& nums) {int sz = nums.size();index.resize(sz);res.resize(sz);for(int i = 0; i < sz; i++){index[i] = i;}mergeSort(nums, 0, sz - 1);return res;}void mergeSort(vector<int>& nums, int left, int right){if(left >= right) return ;int mid = (left + right) >> 1;mergeSort(nums, left, mid);mergeSort(nums, mid + 1, right);int cur1 = left, cur2 = mid + 1, i = 0;while(cur1 <= mid && cur2 <= right){if(nums[cur1] <= nums[cur2]){tmp[i] = nums[cur2];tmpIndex[i++] = index[cur2++];}else {res[index[cur1]] += right - cur2 + 1;//经历了之前的排序,index已经记录下了最新的下标变动,这里就可以直接用cur1来获取正确的下标tmp[i] = nums[cur1];tmpIndex[i++] = index[cur1++];}}while(cur1 <= mid){tmp[i] = nums[cur1];tmpIndex[i++] = index[cur1++];}while(cur2 <= right){tmp[i] = nums[cur2];tmpIndex[i++] = index[cur2++];}for(int j = left; j <= right; j++){nums[j] = tmp[j - left];index[j] = tmpIndex[j - left];}}
4、翻转对
493. 翻转对
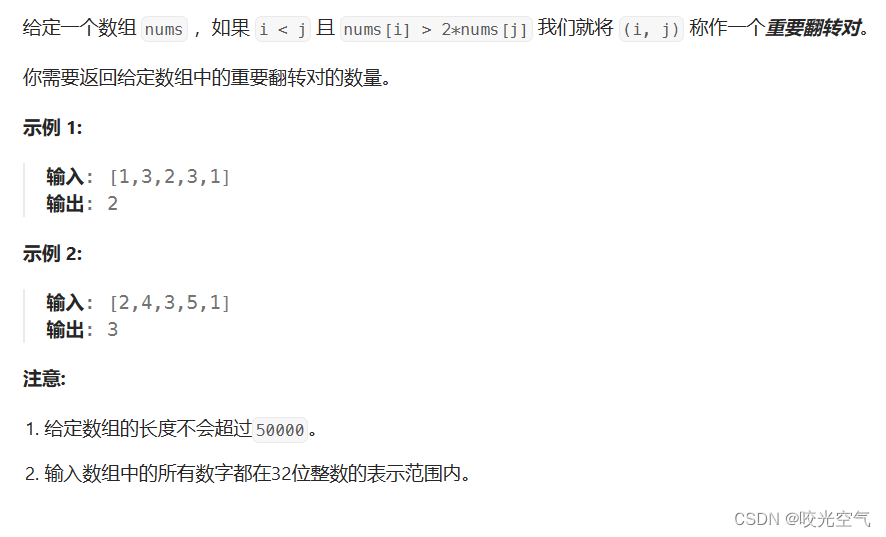
还是一样的思路。左半部分,右半部分,然后一左一右。不过这里的条件不一样。这里的解决办法有两个,一个是计算当前元素后面有多少元素的两倍比我小,另一个是计算当前元素之前,有多少元素的一半比我大,这两个的高效顺序分别是降序和升序。
第一个思路,cur1和cur2,找当前元素的后面,那就以cur1为重点,如果cur2的2倍大于等于cur1,cur2就往后走,如果小于,那么后面的肯定都小于。第二个思路,cur1和cur2,找当前元素的前面,那就以cur2为重点,如果cur1的一半比cur2小,那么cur1后的肯定都符合条件,如果cur1的一半大于cur2,那cur1往后走。最后合并两个有序数组。
int tmp[50010];
public:int reversePairs(vector<int>& nums) {return mergeSort(nums, 0, nums.size() - 1);}int mergeSort(vector<int>& nums, int left, int right){if(left >= right) return 0;int ret = 0;int mid = (left + right) >> 1;ret += mergeSort(nums, left, mid);ret += mergeSort(nums, mid + 1, right); int cur1 = left, cur2 = mid + 1, i = left;//先计算翻转对,0还是left都行/*while(cur1 <= mid)//这里排降序,也可以排升序{while(cur2 <= right && nums[cur2] >= nums[cur1] / 2.0) cur2++;//2.0是为了防止除不尽if(cur2 > right) break;ret += right - cur2 + 1;cur1++;}*/while(cur2 <= right)//升序{while(cur1 <= mid && nums[cur2] >= nums[cur1] / 2.0) cur1++;if(cur1 > mid) break;ret += mid - cur1 + 1;cur2++;}cur1 = left, cur2 = mid + 1;//归位一下,开始排序while(cur1 <= mid && cur2 <= right){tmp[i++] = nums[cur1] <= nums[cur2] ? nums[cur1++] : nums[cur2++];//tmp[i++] = nums[cur1] <= nums[cur2] ? nums[cur2++] : nums[cur1++];}while(cur1 <= mid) tmp[i++] = nums[cur1++];while(cur2 <= right) tmp[i++] = nums[cur2++];for(int j = left; j <= right; j++){nums[j] = tmp[j];}return ret;}
结束。
相关文章:
C++算法 —— 分治(2)归并
文章目录 1、排序数组2、数组中的逆序对3、计算右侧小于当前元素的个数4、翻转对 本篇前提条件是已学会归并排序 1、排序数组 912. 排序数组 排序数组也可以用归并排序来做。 vector<int> tmp;//写成全局是因为如果在每一次小的排序中都创建一次,更消耗时间和…...

Hadoop YARN HA 集群安装部署详细图文教程
目录 一、YARN 集群角色、部署规划 1.1 集群角色--概述 1.2 集群角色--ResourceManager(RM) 1.3 集群角色--NodeManager(NM) 1.4 HA 集群部署规划 二、YARN RM 重启机制 2.1 概述 2.2 演示 2.2.1 不开启 RM 重启机制…...

BBS+商城项目的数据库表设计
本文章是对于BBS商城项目的数据库的初步设计,仅供参考! -- 创建用户表 CREATE TABLE Users (id bigint(20) PRIMARY KEY COMMENT 用户ID,username varchar(255) NOT NULL COMMENT 用户名,password varchar(255) NOT NULL COMMENT 密码,status int(1) DE…...

如何使用Savitzky-Golay滤波器进行轨迹平滑
一、Savitzky-Golay滤波器介绍 Savitzky-Golay滤波器是一种数字滤波器,用于平滑数据,特别是在信号处理中。它基于最小二乘法的思想,通过拟合数据到一个滑动窗口内的低阶多项式来实现平滑。这种滤波器的优点是它可以保留数据的高频信息&#…...
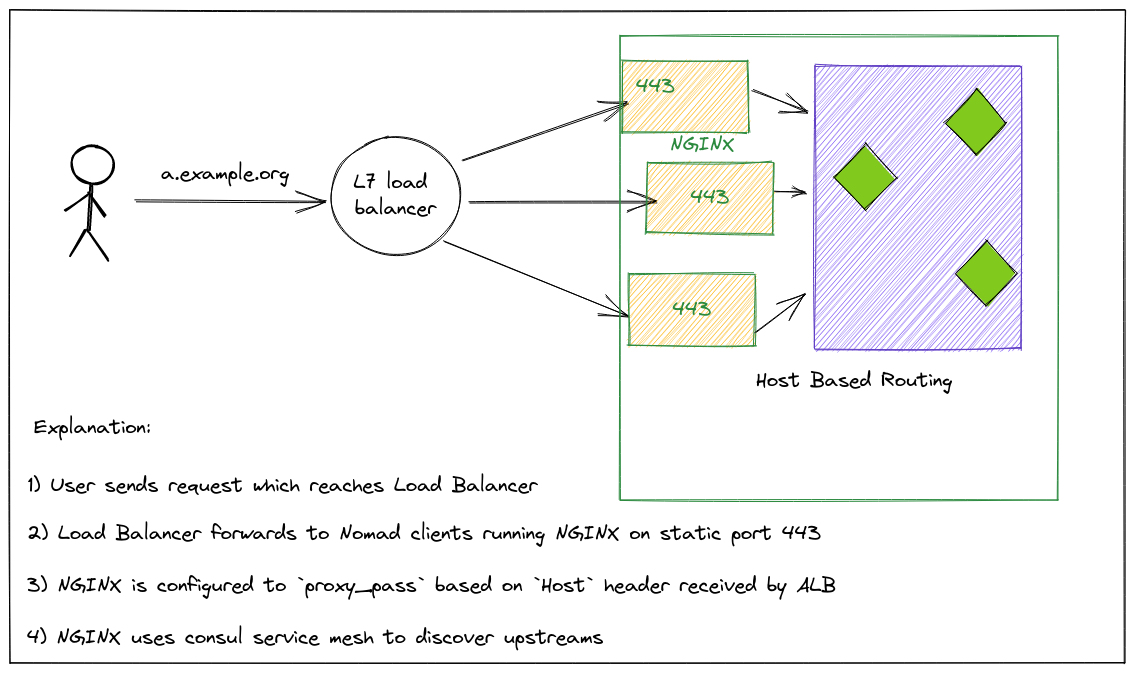
Nomad系列-Nomad网络模式
系列文章 Nomad 系列文章 概述 Nomad 的网络和 Docker 的也有很大不同, 和 K8s 的有很大不同. 另外, Nomad 不同版本(Nomad 1.3 版本前后)或是否集成 Consul 及 CNI 等不同组件也会导致网络模式各不相同. 本文详细梳理一下 Nomad 的主要几种网络模式 在Nomad 1.3发布之前&a…...

OpenCV项目开发实战--实现面部情绪识别对情绪进行识别和分类及详细讲解及完整代码实现
文末提供免费的完整代码下载链接 面部情绪识别(FER)是指根据面部表情对人类情绪进行识别和分类的过程。通过分析面部特征和模式,机器可以对一个人的情绪状态做出有根据的猜测。面部识别的这个子领域是高度跨学科的,借鉴了计算机视觉、机器学习和心理学的见解。 在这篇研究…...

Validate表单组件的封装
之前一直是直接去使用别人现成的组件库,也没有具体去了解人家的组件是怎么封装的,造轮子才会更好地提高自己,所以尝试开始从封装Form表单组件开始 一:组件需求分析 本次封装组件,主要是摸索封装组件的流程,…...

企业架构LNMP学习笔记32
企业架构LB-服务器的负载均衡之LVS实现: 学习目标和内容 1)能够了解LVS的工作方式; 2)能够安装和配置LVS负载均衡; 3)能够了解LVS-NAT的配置方式; 4)能够了解LVS-DR的配置方式&…...

基于Jetty9的Geoserver配置https证书
1.环境准备 由于Geoserver自带的jetty版本不具备https模块,所以需要下载完整版本jetty。这里需要先查看本地geoserver对应的jetty版本,进入geoserver安装目录,执行如下命令。 java -jar start.jar --version Jetty Server Classpath: -----…...

企业互联网暴露面未知资产梳理
一、互联网暴露面梳理的重要性 当前,互联网新技术的产生推动着各种网络应用的蓬勃发展,网络安全威胁逐渐蔓延到各种新兴场景中,揭示着网络安全威胁不断加速泛化。当前网络存在着许多资产,这些资产关系到企业内部的安全情况&#…...
【动态规划刷题 12】等差数列划分 最长湍流子数组
139. 单词拆分 链接: 139. 单词拆分 给你一个字符串 s 和一个字符串列表 wordDict 作为字典。请你判断是否可以利用字典中出现的单词拼接出 s 。 注意:不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。 示例 1: 输入: …...

react-redux 的使用
react-redux React Redux 是 Redux 的官方 React UI 绑定库。它使得你的 React 组件能够从 Redux store 中读取到数据,并且你可以通过dispatch actions去更新 store 中的 state 安装 npm install --save react-reduxProvider React Redux 包含一个 <Provider…...

77 # koa 中间件的应用
调用 next() 表示执行下一个中间件 const Koa require("koa");const app new Koa();app.use(async (ctx, next) > {console.log(1);next();console.log(2); });app.use(async (ctx, next) > {console.log(3);next();console.log(4); });app.use(async (ctx,…...
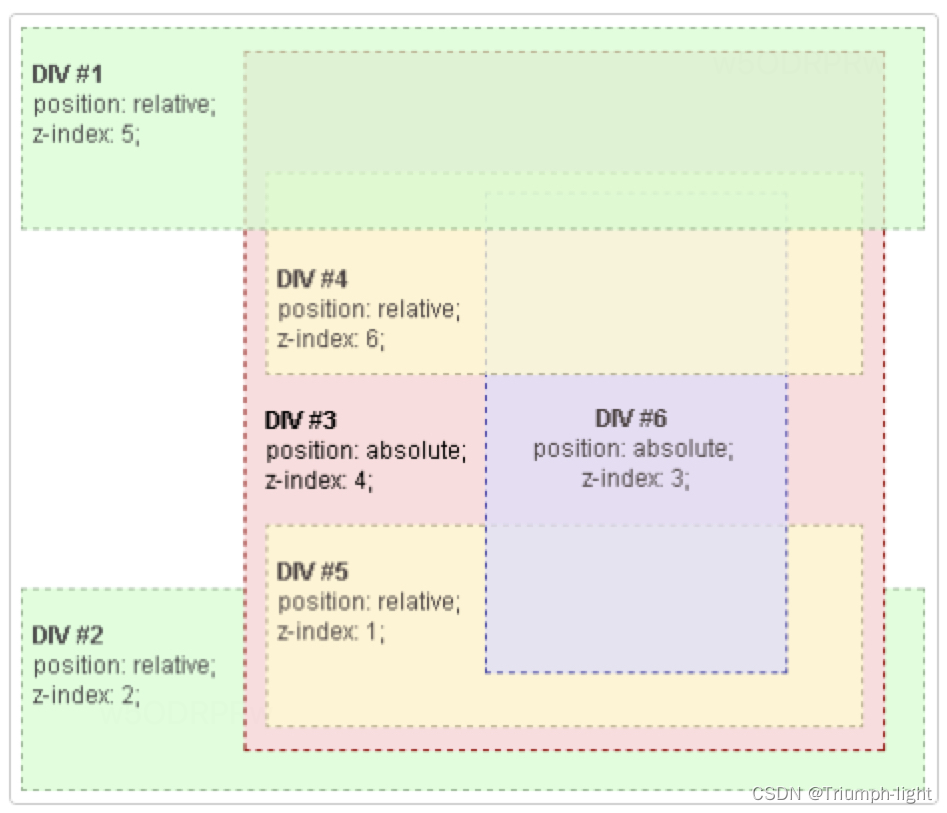
【css】z-index与层叠上下文
z-index属性用来设置元素的堆叠顺序,使用z-index有一个大的前提:z-index所作用元素的样式列表中必须有position属性并且属性值为absolute、relative或fixed中的一个,否则z-index无效。 层叠上下文 MDN讲解 我们给元素设置的z-index都是有一…...
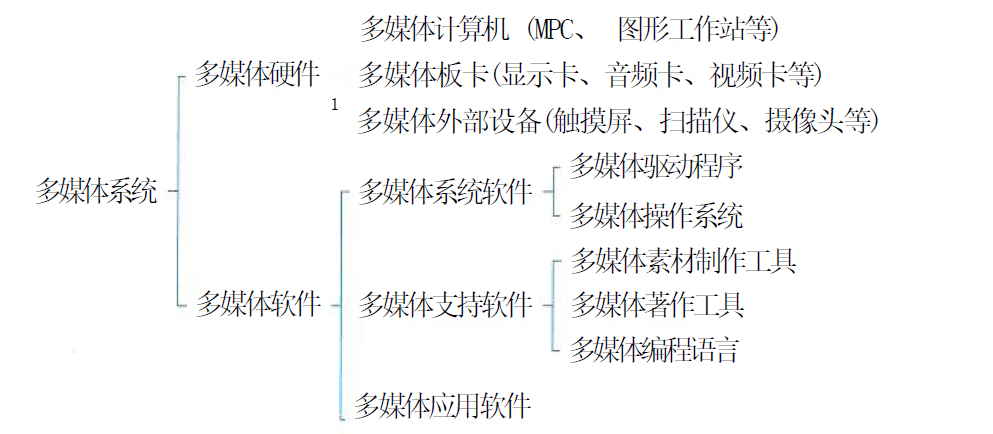
系统架构设计师(第二版)学习笔记----多媒体技术
【原文链接】系统架构设计师(第二版)学习笔记----多媒体技术 文章目录 一、多媒体概述1.1 媒体的分类1.2 多媒体的特征1.3 多媒体系统的基本组成 二、多媒体系统的关键技术2.1 多媒体系统的关键技术2.2 视频技术的内容2.3 音频技术的内容2.4 数据压缩算法…...
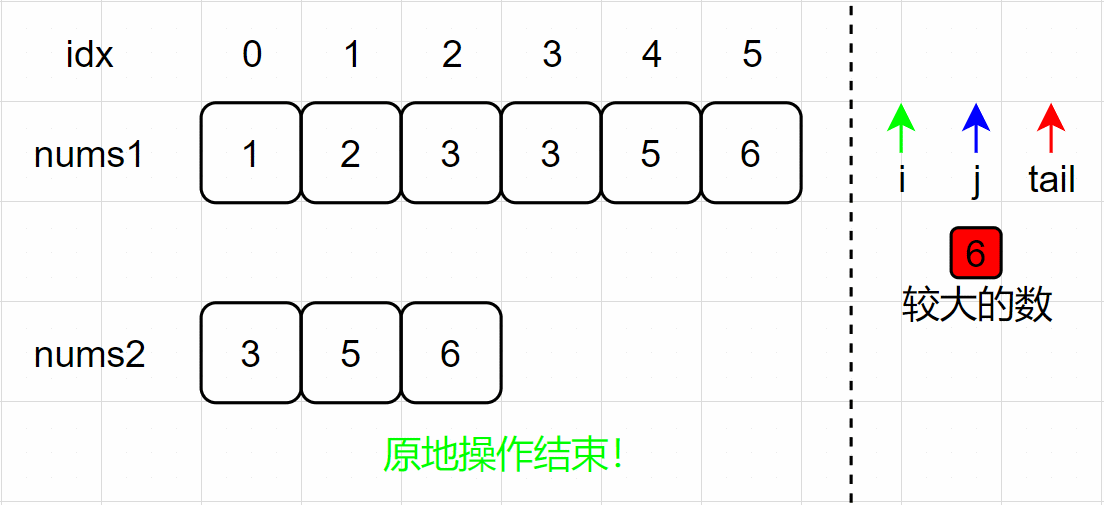
【面试经典150 | 数组】合并两个有序数组
文章目录 写在前面Tag题目来源题目解读解题思路方法一:合并排序方法二:双指针方法三:原地操作-从前往后方法四:原地操作-从后往前 写在最后 写在前面 本专栏专注于分析与讲解【面试经典150】算法,两到三天更新一篇文章…...

系统架构设计专业技能 ·操作系统
现在的一切都是为将来的梦想编织翅膀,让梦想在现实中展翅高飞。 Now everything is for the future of dream weaving wings, let the dream fly in reality. 点击进入系列文章目录 系统架构设计高级技能 操作系统 一、操作系统概述二、进程管理2.1 进程概念2.2 进…...

CSP 202209-1 如此编码
答题 题目就是字多 #include<iostream>using namespace std;int main() {int n,m;cin>>n>>m;int a[n],c[n1];c[0]1;for(int i0;i<n;i){cin>>a[i];c[i1]c[i]*a[i];}for(int i0;i<n;i){cout<<(m%c[i1]-m%c[i])/c[i]<< ;} }...
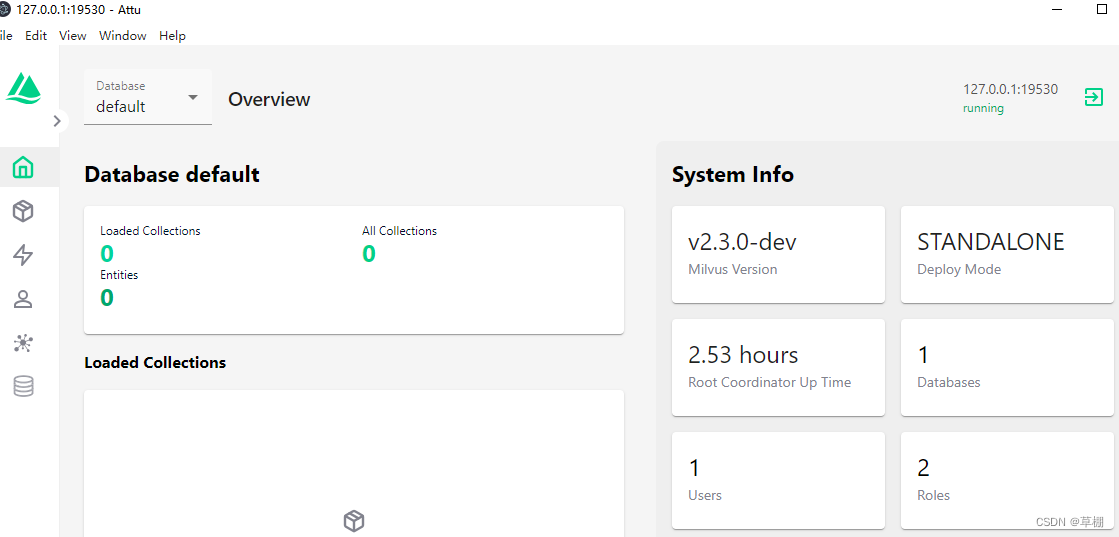
windows安装向量数据库milvus
本文介绍windows下安装milvus的方法。 一.Docker安装 1.1docker下载 首先到Docker官网上下载docker:Docker中文网 官网 1.2.安装前前期准备 先使用管理员权限打开windows powershell 然后在powershell里面输入下面那命令,启用“适用于 Linux 的 Windows 子系统”…...

Qt中,QScript对JavaScript的内置接口支持情况
支持 JSON.parse()/stringify() Object.keys() 不支持 console.info()/debug()/warn()/error() window setTimeout() clearTimeout() setInterval() clearInterval() 后续添加更多接口支持情况~...

Vitis HLS里给LED闪烁函数‘打标签’:深入解读ap_hs与ap_none协议的选择与实战影响
Vitis HLS中LED闪烁函数接口协议深度解析:ap_hs与ap_none的硬件实现差异与工程选择 在FPGA开发中,Vitis HLS作为高级综合工具,能够将C代码转换为可综合的硬件描述语言。然而,许多开发者在使用过程中常常忽略一个关键细节——函数…...

Word转Markdown踩过的那些坑:Writage插件失效、Pandoc命令报错怎么办?
Word转Markdown实战避坑指南:从工具失效到完美转换的完整方案 每次技术分享会上,总有人问我:"为什么我的Word转Markdown总出问题?"这让我想起自己刚接触文档转换时踩过的无数坑——插件神秘消失、命令行报错、格式全乱套…...

轻量级代码同步工具codesyncer:P2P架构实现跨设备实时同步
1. 项目概述:一个被低估的代码同步利器如果你和我一样,经常需要在多台开发机、服务器甚至不同的云环境之间同步代码片段、配置文件或者小型项目,那你一定对那种“这台机器上有,那台机器上没有”的混乱感同身受。手动复制粘贴&…...

在Nodejs后端服务中集成Taotoken实现稳定高效的多模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Nodejs后端服务中集成Taotoken实现稳定高效的多模型调用 对于构建AI功能的后端Node.js开发者而言,直接对接单一模型供…...

Claude Code与Cursor CLI集成:AI辅助编程工作流优化实践
1. 项目概述:Claude Code与Cursor CLI的桥梁如果你和我一样,日常开发中同时使用Claude Code和Cursor,并且对Composer 2的执行速度印象深刻,那么你很可能也面临过这样的困境:Claude Code在规划、分析和代码审查方面表现…...

安全巡检执行率能解决哪些场景痛点?一套安全巡检执行率提升方案实战
在工厂的安全管理中,安全巡检是发现隐患、预防事故的最前线。然而,很多企业的安全巡检流于形式,执行率长期低下,带来了一系列连锁反应。那么,安全巡检执行率到底能解决哪些场景痛点?如何系统性地提升执行率…...

免费图片转3D模型完整指南:5分钟学会ImageToSTL将照片变成立体浮雕
免费图片转3D模型完整指南:5分钟学会ImageToSTL将照片变成立体浮雕 【免费下载链接】ImageToSTL This tool allows you to easily convert any image into a 3D print-ready STL model. The surface of the model will display the image when illuminated from the…...
)
使用 LikeShop 搭建商城的完整流程(从0到上线)
先说结论用 LikeShop 搭建商城,本质可以拆成 5 步:👉 部署系统 → 配置基础 → 上架商品 → 打通交易 → 引流运营只要这 5 步跑通,就可以实现“可正常卖货”的商城。一、准备阶段(很多人会忽略)在动手之前…...

从帧结构到数据解析:深入理解CJ/T 188 MBUS水表通信协议
1. MBUS协议与水表通信基础 第一次接触CJ/T 188 MBUS协议时,我完全被那一串串十六进制报文搞懵了。FE FE FE 68开头的报文到底在说什么?为什么水表厂商给的文档读起来像天书?经过几个项目的实战,我发现只要掌握几个关键点…...

计算机视觉工程师的周度技术雷达:从论文到产线的工程化筛选方法
1. 这不是一份“论文清单”,而是一份计算机视觉从业者的周度技术雷达 如果你每天刷arXiv、看CVPR会议摘要、追GitHub trending,却总在“读完就忘”和“知道很重要但不知从何下手”之间反复横跳——那你不是一个人。我做CV方向的工程落地和算法选型已经十…...