kafka 3.5 主题分区ISR伸缩源码
ISR(In-sync Replicas):保持同步的副本
OSR(Outof-sync Replicas):不同步的副本。最开始所有的副本都在ISR中,在kafka工作的过程中,如果某个副本同步速度慢于replica.lag.time.max.ms指定的阈值,则被踢出ISR存入OSR,如果后续速度恢复可以回到ISR中
AR(Assigned Replicas):包括所有的分区的副本,AR=ISR+OSR
不懂的可以看一下Kafka——副本(Replica)机制
- 一、在主题分区初始化时,当前主题分区所有副本都是会Leader副本的maximalIsr中
- 1、先获得leaderIsrUpdateLock写锁,在锁内
- 2、初始化ISR(只是把所有副本信息保存在maximalIsr,这时候maximalIsr也是最大的时候)
- 二、定时任务针对ISR缩容
- 1、2种启动方式
- (1)zk模式
- (2)kraft模式
- 2、定时任务具体实现
- (1) 获得leaderIsrUpdateLock的读锁判断是否需要ISR的缩容
- (2)得到leaderIsrUpdateLock的写锁开始修改ISR
- (3) 缩容后的ISR先赋值给maximalIsr,isr还是保持没有缩容前的
- 三、Follower请求Leader的Fetch数据时,会判断是否加入ISR
- 1、获得leaderIsrUpdateLock的读锁后再判断是否符合加入ISR条件
- 2、获得leaderIsrUpdateLock的写锁再执行写入操作
- 3、写入操作把新的Follower副本先加入maximalIsr,isr保持扩容前的
- 四、修改完maximalIsr后都要把信息发给其他副本
- 1、zk模式
- 定时任务修改zk节点进行传播
- 2、kraft模式
- 通过给controllerChannelManager发送请求通知
- 五、 maximalIsr和isr
- 1、PartitionState中,isr和maximalIsr两个字段的定义和为什么上面只是修改了maximalIsr
- 2、什么时候maximalIsr会给isr赋值
一、在主题分区初始化时,当前主题分区所有副本都是会Leader副本的maximalIsr中
如果不知到
becomeLeaderOrFollower方法,可以看一下kafka 3.5 主题分区的Follower创建Fetcher线程从Leader拉取数据源码
def becomeLeaderOrFollower(correlationId: Int,leaderAndIsrRequest: LeaderAndIsrRequest,onLeadershipChange: (Iterable[Partition], Iterable[Partition]) => Unit): LeaderAndIsrResponse = {//省略代码val partitionsBecomeLeader = if (partitionsToBeLeader.nonEmpty)makeLeaders(controllerId, controllerEpoch, partitionsToBeLeader, correlationId, responseMap,highWatermarkCheckpoints, topicIdFromRequest)//省略代码
}
private def makeLeaders(controllerId: Int,controllerEpoch: Int,partitionStates: Map[Partition, LeaderAndIsrPartitionState],correlationId: Int,responseMap: mutable.Map[TopicPartition, Errors],highWatermarkCheckpoints: OffsetCheckpoints,topicIds: String => Option[Uuid]): Set[Partition] = {//省略代码//更新分区信息以成为leader,成功则返回trueif (partition.makeLeader(partitionState, highWatermarkCheckpoints, topicIds(partitionState.topicName))) {//将成功成为leader的分区添加到partitionsToMakeLeaders集合中partitionsToMakeLeaders += partition}//省略代码}
1、先获得leaderIsrUpdateLock写锁,在锁内
def makeLeader(partitionState: LeaderAndIsrPartitionState,highWatermarkCheckpoints: OffsetCheckpoints,topicId: Option[Uuid]): Boolean = {//获取了一个写锁leaderIsrUpdateLock,以确保并发修改的同步。val (leaderHWIncremented, isNewLeader) = inWriteLock(leaderIsrUpdateLock) {//省略代码 controllerEpoch = partitionState.controllerEpoch//省略代码 val currentTimeMs = time.milliseconds//代码检查了isLeader是否为false,如果是,则将isNewLeader设置为true。val isNewLeader = !isLeader//代码将partitionState中的各种属性转换为Scala集合,并尝试更新分配和ISR状态。val isNewLeaderEpoch = partitionState.leaderEpoch > leaderEpochval replicas = partitionState.replicas.asScala.map(_.toInt)//遍历partitionState生成ISR,isv有此分区所有的副本的信息,包括Leader和Followerval isr = partitionState.isr.asScala.map(_.toInt).toSetval addingReplicas = partitionState.addingReplicas.asScala.map(_.toInt)val removingReplicas = partitionState.removingReplicas.asScala.map(_.toInt)//省略代码//如果分区纪元大于或等于当前分区纪元,则更新分配和 ISR updateAssignmentAndIsr(replicas = replicas,isLeader = true,isr = isr,addingReplicas = addingReplicas,removingReplicas = removingReplicas,LeaderRecoveryState.RECOVERED)//省略代码。。。。。isNewLeader}
updateAssignmentAndIsr这个会进行初始化ISR
def updateAssignmentAndIsr(replicas: Seq[Int],isLeader: Boolean,isr: Set[Int],addingReplicas: Seq[Int],removingReplicas: Seq[Int],leaderRecoveryState: LeaderRecoveryState): Unit = {if (isLeader) {//根据replicas过滤出所有非本地节点的副本标识符,存储在followers中val followers = replicas.filter(_ != localBrokerId)//通过remoteReplicasMap.keys过滤出需要移除的副本标识符,存储在removedReplicas中val removedReplicas = remoteReplicasMap.keys.filterNot(followers.contains(_))//。通过迭代followers,将新副本添加到remoteReplicasMap,如果副本已存在,则不进行任何操作。followers.foreach(id => remoteReplicasMap.getAndMaybePut(id, new Replica(id, topicPartition)))remoteReplicasMap.removeAll(removedReplicas)} else {//清空remoteReplicasMapremoteReplicasMap.clear()}assignmentState = if (addingReplicas.nonEmpty || removingReplicas.nonEmpty)OngoingReassignmentState(addingReplicas, removingReplicas, replicas)elseSimpleAssignmentState(replicas)partitionState = CommittedPartitionState(isr, leaderRecoveryState)}
通过调用CommittedPartitionState 给ISR(代码中字段是maximalIsr)赋值
2、初始化ISR(只是把所有副本信息保存在maximalIsr,这时候maximalIsr也是最大的时候)
case class CommittedPartitionState(isr: Set[Int],leaderRecoveryState: LeaderRecoveryState
) extends PartitionState {val maximalIsr = isrval isInflight = falseoverride def toString: String = {s"CommittedPartitionState(isr=$isr" +s", leaderRecoveryState=$leaderRecoveryState" +")"}
}
至于为什么赋值给maximalIsr,看一下下面第五章1节的PartitionState的定义,其实就知道,ISR还没有正式生效
二、定时任务针对ISR缩容
1、2种启动方式
(1)zk模式
kakfaServer.scala中的startup方法里会调用replicaManager.startup()
(2)kraft模式
BrokerServer.scala中startup方法------>
sharedServer.loader.installPublishers(metadataPublishers)-------->
scheduleInitializeNewPublishers(0);------------->
initializeNewPublishers------------->
publisher.onMetadataUpdate(delta, image, manifest);实现方法是BrokerMetadataPublisher.scala中的onMetadataUpdate-------------->
initializeManagers()----------------->
replicaManager.startup()
2、定时任务具体实现
首先直接看定时任务,在ReplicaManager.scala类中
def startup(): Unit = {//启动 ISR 过期线程// 从属者在从 ISR 中删除之前最多可以落后于领导者。replicaLagTimeMaxMs x 1.5scheduler.schedule("isr-expiration", () => maybeShrinkIsr(), 0L, config.replicaLagTimeMaxMs / 2)}
实现定时执行方法为maybeShrinkIsr
private def maybeShrinkIsr(): Unit = {trace("Evaluating ISR list of partitions to see which replicas can be removed from the ISR")// Shrink ISRs for non offline partitions//收缩非脱机分区的 ISR,即遍历所有在线分区的ISR,allPartitions.keys.foreach { topicPartition =>onlinePartition(topicPartition).foreach(_.maybeShrinkIsr())}}
(1) 获得leaderIsrUpdateLock的读锁判断是否需要ISR的缩容
//检查是否需要更新ISR(In-Sync Replica)列表,并在需要更新时执行更新。
def maybeShrinkIsr(): Unit = {def needsIsrUpdate: Boolean = {//检查partitionState.isInflight是否为false,并在获取leaderIsrUpdateLock的读锁内部调用needsShrinkIsr()来判断。!partitionState.isInflight && inReadLock(leaderIsrUpdateLock) {needsShrinkIsr()}}if (needsIsrUpdate) {val alterIsrUpdateOpt = inWriteLock(leaderIsrUpdateLock) {leaderLogIfLocal.flatMap { leaderLog =>//获取超过指定延迟时间的不同步副本的ID列表。val outOfSyncReplicaIds = getOutOfSyncReplicas(replicaLagTimeMaxMs)partitionState match {case currentState: CommittedPartitionState if outOfSyncReplicaIds.nonEmpty =>//省略代码//准备更新ISR的操作。Some(prepareIsrShrink(currentState, outOfSyncReplicaIds))case _ =>None}}}//submitAlterPartition在LeaderAndIsr锁之外发送AlterPartition请求,因为完成逻辑可能会增加高水位线(high watermark)并完成延迟操作。alterIsrUpdateOpt.foreach(submitAlterPartition)}}
其中needsShrinkIsr的结果决定下面是否执行修改ISR操作
private def needsShrinkIsr(): Boolean = {leaderLogIfLocal.exists { _ => getOutOfSyncReplicas(replicaLagTimeMaxMs).nonEmpty }}/*** 如果追随者已经拥有与领导者相同leo,则不会被视为不同步* 1、卡住的追随者:如果副本的 leo 尚未针对 maxLagMs ms 进行更新,则跟随者卡住,应从 ISR 中删除* 2、慢速跟随器:如果复制副本在最近 maxLagM 毫秒内未读取 leo,则跟随器滞后,应从 ISR 中删除* 这两种情况都是通过检查 lastCaughtUpTimeMs 来处理的,该 lastCaughtUpTimeM 表示副本完全赶上的最后时间。如果违反上述任一条件,则该副本将被视为不同步*如果 ISR 更新正在进行中,我们将在此处返回一个空集**/def getOutOfSyncReplicas(maxLagMs: Long): Set[Int] = {val current = partitionStateif (!current.isInflight) {val candidateReplicaIds = current.isr - localBrokerIdval currentTimeMs = time.milliseconds()val leaderEndOffset = localLogOrException.logEndOffsetcandidateReplicaIds.filter(replicaId => isFollowerOutOfSync(replicaId, leaderEndOffset, currentTimeMs, maxLagMs))} else {Set.empty}}
private def isFollowerOutOfSync(replicaId: Int,leaderEndOffset: Long,currentTimeMs: Long,maxLagMs: Long): Boolean = {getReplica(replicaId).fold(true) { followerReplica =>//这里需要注意是感叹号,结果取反!followerReplica.stateSnapshot.isCaughtUp(leaderEndOffset, currentTimeMs, maxLagMs)}
}
def isCaughtUp(leaderEndOffset: Long,currentTimeMs: Long,replicaMaxLagMs: Long): Boolean = {//如果leo==副本日志的logEndOffset或者当前时间减去最后的拉取时间间隔小于等于replicaMaxLagMs,则返回true,leaderEndOffset == logEndOffset || currentTimeMs - lastCaughtUpTimeMs <= replicaMaxLagMs}
}
(2)得到leaderIsrUpdateLock的写锁开始修改ISR
执行的操作是prepareIsrShrink方法
//在缩小 ISR 时,我们不能假设更新会成功,因为如果“AlterPartition”失败,这可能会错误地推进HW。// 因此,“PendingShrinkIsr”的“最大 ISR”是当前的 ISR。private[cluster] def prepareIsrShrink(currentState: CommittedPartitionState,outOfSyncReplicaIds: Set[Int]): PendingShrinkIsr = {//把要去掉的副本从ISR中去掉val isrToSend = partitionState.isr -- outOfSyncReplicaIds//组建一个新的ISRval isrWithBrokerEpoch = addBrokerEpochToIsr(isrToSend.toList)val newLeaderAndIsr = LeaderAndIsr(localBrokerId,leaderEpoch,partitionState.leaderRecoveryState,isrWithBrokerEpoch,partitionEpoch)val updatedState = PendingShrinkIsr(outOfSyncReplicaIds,newLeaderAndIsr,currentState)partitionState = updatedStateupdatedState}
(3) 缩容后的ISR先赋值给maximalIsr,isr还是保持没有缩容前的
PendingShrinkIsr方法会给ISR赋值
case class PendingShrinkIsr(outOfSyncReplicaIds: Set[Int],sentLeaderAndIsr: LeaderAndIsr,lastCommittedState: CommittedPartitionState
) extends PendingPartitionChange {val isr = lastCommittedState.isrval maximalIsr = isrval isInflight = truedef notifyListener(alterPartitionListener: AlterPartitionListener): Unit = {alterPartitionListener.markIsrShrink()}override def toString: String = {s"PendingShrinkIsr(outOfSyncReplicaIds=$outOfSyncReplicaIds" +s", sentLeaderAndIsr=$sentLeaderAndIsr" +s", leaderRecoveryState=$leaderRecoveryState" +s", lastCommittedState=$lastCommittedState" +")"}
}
三、Follower请求Leader的Fetch数据时,会判断是否加入ISR
在
kafkaApis.scala中的fetch请求处理逻辑中,有判断此次请求是Follower请求还是消费者的请求,或者你可以看一下kakfa 3.5 kafka服务端处理消费者客户端拉取数据请求源码
def fetchRecords(fetchParams: FetchParams,fetchPartitionData: FetchRequest.PartitionData,fetchTimeMs: Long,maxBytes: Int,minOneMessage: Boolean,updateFetchState: Boolean): LogReadInfo = {def readFromLocalLog(log: UnifiedLog): LogReadInfo = {readRecords(log,fetchPartitionData.lastFetchedEpoch,fetchPartitionData.fetchOffset,fetchPartitionData.currentLeaderEpoch,maxBytes,fetchParams.isolation,minOneMessage)}//判断获取数据的请求是否来自Followerif (fetchParams.isFromFollower) {// Check that the request is from a valid replica before doing the readval (replica, logReadInfo) = inReadLock(leaderIsrUpdateLock) {val localLog = localLogWithEpochOrThrow(fetchPartitionData.currentLeaderEpoch,fetchParams.fetchOnlyLeader)val replica = followerReplicaOrThrow(fetchParams.replicaId,fetchPartitionData)val logReadInfo = readFromLocalLog(localLog)(replica, logReadInfo)}//todo Follower副本在fetch数据后,修改一些信息if (updateFetchState && !logReadInfo.divergingEpoch.isPresent) {//如果 fetch 来自 broker 的副本同步,那么就更新相关的 log end offsetupdateFollowerFetchState(replica,followerFetchOffsetMetadata = logReadInfo.fetchedData.fetchOffsetMetadata,followerStartOffset = fetchPartitionData.logStartOffset,followerFetchTimeMs = fetchTimeMs,leaderEndOffset = logReadInfo.logEndOffset,fetchParams.replicaEpoch)}logReadInfo} //省略代码}
其中updateFollowerFetchState就是获取数据后进行一些处理
def updateFollowerFetchState(replica: Replica,followerFetchOffsetMetadata: LogOffsetMetadata,followerStartOffset: Long,followerFetchTimeMs: Long,leaderEndOffset: Long,brokerEpoch: Long): Unit = {//通过判断是否存在延迟的DeleteRecordsRequest来确定是否需要计算低水位(lowWatermarkIfLeader)。如果没有延迟的DeleteRecordsRequest,则将oldLeaderLW设为-1。val oldLeaderLW = if (delayedOperations.numDelayedDelete > 0) lowWatermarkIfLeader else -1L//获取副本的先前的跟随者日志结束偏移量val prevFollowerEndOffset = replica.stateSnapshot.logEndOffset//调用replica.updateFetchState方法来更新副本的抓取状态,包括跟随者的抓取偏移量元数据、起始偏移量、抓取时间、领导者的结束偏移量和代理节点的时期。replica.updateFetchState(followerFetchOffsetMetadata,followerStartOffset,followerFetchTimeMs,leaderEndOffset,brokerEpoch)//再次判断是否存在延迟的DeleteRecordsRequest,如果没有则将newLeaderLW设为-1。val newLeaderLW = if (delayedOperations.numDelayedDelete > 0) lowWatermarkIfLeader else -1L//检查分区的低水位是否增加,即新的低水位(newLeaderLW)是否大于旧的低水位(oldLeaderLW)。val leaderLWIncremented = newLeaderLW > oldLeaderLW//调用maybeExpandIsr方法来检查是否需要将该同步副本添加到ISR(In-Sync Replicas)中。maybeExpandIsr(replica)//检查分区的高水位是否可以增加。如果副本的日志结束偏移量(replica.stateSnapshot.logEndOffset)发生变化,val leaderHWIncremented = if (prevFollowerEndOffset != replica.stateSnapshot.logEndOffset) {//尝试增加高水位(maybeIncrementLeaderHW方法),并在leaderIsrUpdateLock锁的保护下执行该操作。inReadLock(leaderIsrUpdateLock) {leaderLogIfLocal.exists(leaderLog => maybeIncrementLeaderHW(leaderLog, followerFetchTimeMs))}} else {false}//如果低水位或高水位发生变化,则尝试完成延迟请求(tryCompleteDelayedRequests方法)。if (leaderLWIncremented || leaderHWIncremented)tryCompleteDelayedRequests()}
1、获得leaderIsrUpdateLock的读锁后再判断是否符合加入ISR条件
其中
maybeExpandIsr方法会尝试把当前副本添加到ISR,和上面定时任务触发的maybeShrinkIsr差不多
/*** //检查并可能扩展分区的 ISR。*如果副本的 LEO >= current hw,并且它在当前前导纪元内被赶到偏移量,则会将其添加到 ISR 中。* 副本必须先赶到当前领导者纪元,然后才能加入 ISR,* 否则,如果当前领导者的HW和 LEO 之间存在已提交的数据,则副本可能会在获取已提交数据之前成为领导者,并且数据将丢失。*/private def maybeExpandIsr(followerReplica: Replica): Unit = {//partitionState不在inflight状态 并且ISR不包含此Follower副本并且分区状态不是isInflight=true,再获取leaderIsrUpdateLock读锁val needsIsrUpdate = !partitionState.isInflight && canAddReplicaToIsr(followerReplica.brokerId) && inReadLock(leaderIsrUpdateLock) {//再一次判断是否符合条件到ISR的条件needsExpandIsr(followerReplica)}if (needsIsrUpdate) {//经过needsIsrUpdate的验证,Follower符合添加到ISR的条件,则获得leaderIsrUpdateLock的写锁进行操作val alterIsrUpdateOpt = inWriteLock(leaderIsrUpdateLock) {// check if this replica needs to be added to the ISRpartitionState match {case currentState: CommittedPartitionState if needsExpandIsr(followerReplica) =>//prepareIsrExpand执行加入操作Some(prepareIsrExpand(currentState, followerReplica.brokerId))case _ =>None}}// Send the AlterPartition request outside of the LeaderAndIsr lock since the completion logic// may increment the high watermark (and consequently complete delayed operations).alterIsrUpdateOpt.foreach(submitAlterPartition)}}
private def needsExpandIsr(followerReplica: Replica): Boolean = {//isFollowerInSync 会判断Follower副本的leo是否大于当前Leader的HW,大于则为truecanAddReplicaToIsr(followerReplica.brokerId) && isFollowerInSync(followerReplica)}//条件1private def canAddReplicaToIsr(followerReplicaId: Int): Boolean = {val current = partitionState!current.isInflight &&!current.isr.contains(followerReplicaId) &&isReplicaIsrEligible(followerReplicaId)}//判断副本是否符合成为ISR(In-Sync Replica)的条件private def isReplicaIsrEligible(followerReplicaId: Int): Boolean = {metadataCache match {//对于KRaft元数据缓存//1、副本没有被标记为已隔离(fenced)//2、副本不处于受控关机状态(controlled shutdown)。//3、副本的元数据缓存的Broker epoch与其Fetch请求的Broker epoch匹配,或者Fetch请求的Broker epoch为-1(绕过epoch验证)。case kRaftMetadataCache: KRaftMetadataCache =>val storedBrokerEpoch = remoteReplicasMap.get(followerReplicaId).stateSnapshot.brokerEpochval cachedBrokerEpoch = kRaftMetadataCache.getAliveBrokerEpoch(followerReplicaId)!kRaftMetadataCache.isBrokerFenced(followerReplicaId) &&!kRaftMetadataCache.isBrokerShuttingDown(followerReplicaId) &&isBrokerEpochIsrEligible(storedBrokerEpoch, cachedBrokerEpoch)//对于ZK元数据缓存,只需确保副本是存活的Broker即可。尽管这里没有检查正在关闭的Broker,但控制器会阻止它们加入ISR。case zkMetadataCache: ZkMetadataCache =>zkMetadataCache.hasAliveBroker(followerReplicaId)case _ => true}} //条件2private def isFollowerInSync(followerReplica: Replica): Boolean = {leaderLogIfLocal.exists { leaderLog =>val followerEndOffset = followerReplica.stateSnapshot.logEndOffsetfollowerEndOffset >= leaderLog.highWatermark && leaderEpochStartOffsetOpt.exists(followerEndOffset >= _)}}
2、获得leaderIsrUpdateLock的写锁再执行写入操作
方法是prepareIsrExpand
//在扩展 ISR 时,我们假设新副本将在我们收到确认之前将其放入 ISR。// 这可确保HW已经反映更新的 ISR,即使在我们收到确认之前有延迟。// 或者,如果更新失败,则不会造成任何损害,因为扩展的 ISR 对HW的推进提出了更严格的要求。private def prepareIsrExpand(currentState: CommittedPartitionState,newInSyncReplicaId: Int): PendingExpandIsr = {//将当前的ISR与新的In-Sync Replica ID相结合,得到要发送的ISR列表isrToSendval isrToSend = partitionState.isr + newInSyncReplicaId//调用addBrokerEpochToIsr方法为ISR列表中的每个副本添加Broker Epoch,并将结果存储在isrWithBrokerEpoch中。val isrWithBrokerEpoch = addBrokerEpochToIsr(isrToSend.toList)//使用localBrokerId作为新的leader,将其他参数从当前的分区状态中获取,并创建一个新的LeaderAndIsr对象newLeaderAndIsr。val newLeaderAndIsr = LeaderAndIsr(localBrokerId,leaderEpoch,partitionState.leaderRecoveryState,isrWithBrokerEpoch,partitionEpoch)//创建一个PendingExpandIsr对象updatedState,其中包含新的In-Sync Replica ID、新的LeaderAndIsr对象和当前状态val updatedState = PendingExpandIsr(newInSyncReplicaId,newLeaderAndIsr,currentState)//将partitionState更新为updatedState。//返回updatedState作为结果。partitionState = updatedStateupdatedState}
3、写入操作把新的Follower副本先加入maximalIsr,isr保持扩容前的
case class PendingExpandIsr(newInSyncReplicaId: Int,sentLeaderAndIsr: LeaderAndIsr,lastCommittedState: CommittedPartitionState
) extends PendingPartitionChange {//这个是现在正在生效的ISR集合val isr = lastCommittedState.isr//而maximalIsr包含还没有正式生效的,防止因为修改失败影响流程val maximalIsr = isr + newInSyncReplicaIdval isInflight = truedef notifyListener(alterPartitionListener: AlterPartitionListener): Unit = {alterPartitionListener.markIsrExpand()}override def toString: String = {s"PendingExpandIsr(newInSyncReplicaId=$newInSyncReplicaId" +s", sentLeaderAndIsr=$sentLeaderAndIsr" +s", leaderRecoveryState=$leaderRecoveryState" +s", lastCommittedState=$lastCommittedState" +")"}
}
四、修改完maximalIsr后都要把信息发给其他副本
上面不管是定时任务中的maybeShrinkIsr还是fetch请求中的maybeExpandIsr方法,都会执行到下面这个函数
alterIsrUpdateOpt.foreach(submitAlterPartition)
private def submitAlterPartition(proposedIsrState: PendingPartitionChange): CompletableFuture[LeaderAndIsr] = {debug(s"Submitting ISR state change $proposedIsrState")//alterIsrManager.submit是提交 ISR 状态更改,zk模式和kraft模式执行不同的函数//zk是ZkAlterPartitionManager中的submit//kraft是DefaultAlterPartitionManager中的submitval future = alterIsrManager.submit(new TopicIdPartition(topicId.getOrElse(Uuid.ZERO_UUID), topicPartition),proposedIsrState.sentLeaderAndIsr,controllerEpoch)future.whenComplete { (leaderAndIsr, e) =>var hwIncremented = falsevar shouldRetry = falseinWriteLock(leaderIsrUpdateLock) {if (partitionState != proposedIsrState) {//这意味着partitionState在我们得到AlterPartition响应之前,是通过领导者选举或其他机制更新的。我们不知道控制器上到底发生了什么,但我们知道此响应已过时,因此我们忽略它。//省略代码} else if (leaderAndIsr != null) {//修改ISR,并且返回高位水是否递增hwIncremented = handleAlterPartitionUpdate(proposedIsrState, leaderAndIsr)} else {shouldRetry = handleAlterPartitionError(proposedIsrState, Errors.forException(e))}}//高水位标记是否增加。if (hwIncremented) {tryCompleteDelayedRequests()}if (shouldRetry) {//需要重试则自己调用自己submitAlterPartition(proposedIsrState)}}}
1、zk模式
//将给定的leaderAndIsr信息写入ZooKeeper,并返回一个LeaderAndIsr对象。override def submit(topicIdPartition: TopicIdPartition,leaderAndIsr: LeaderAndIsr,controllerEpoch: Int): CompletableFuture[LeaderAndIsr]= {debug(s"Writing new ISR ${leaderAndIsr.isr} to ZooKeeper with version " +s"${leaderAndIsr.partitionEpoch} for partition $topicIdPartition")//调用ReplicationUtils.updateLeaderAndIsr方法更新ZooKeeper中的leaderAndIsr信息,并返回更新是否成功(updateSucceeded)以及新的版本号(newVersion)。val (updateSucceeded, newVersion) = ReplicationUtils.updateLeaderAndIsr(zkClient, topicIdPartition.topicPartition,leaderAndIsr, controllerEpoch)val future = new CompletableFuture[LeaderAndIsr]()if (updateSucceeded) {//使用synchronized关键字同步访问isrChangeSet,// Track which partitions need to be propagated to the controller//isrChangeSet是通过定时任务触发isrChangeSet synchronized {//将topicIdPartition.topicPartition添加到isrChangeSet中。isrChangeSet += topicIdPartition.topicPartition//使用lastIsrChangeMs记录最后一次ISR更改的时间。lastIsrChangeMs.set(time.milliseconds())}//使用leaderAndIsr.withPartitionEpoch(newVersion)更新leaderAndIsr的分区时代,并将其设置为future的结果。future.complete(leaderAndIsr.withPartitionEpoch(newVersion))} else {//省略代码}future}
定时任务修改zk节点进行传播
kakfaServer.scala中启动函数会执行如下命令
alterPartitionManager.start()
其中alterPartitionManager的实现是ZkAlterPartitionManager
实际执行的是如下代码创建定时任务
override def start(): Unit = {scheduler.schedule("isr-change-propagation", () => maybePropagateIsrChanges(), 0L,isrChangeNotificationConfig.checkIntervalMs)}
/*** 此函数定期运行以查看是否需要传播 ISR。它在以下情况下传播 ISR:* 1. 尚未传播 ISR 更改。* 2. 最近 5 秒内没有 ISR 更改,或者自上次 ISR 传播以来已超过 60 秒。* 这允许在几秒钟内传播偶尔的 ISR 更改,并避免在发生大量 ISR 更改时使控制器和其他代理不堪重负。*/private[server] def maybePropagateIsrChanges(): Unit = {val now = time.milliseconds()isrChangeSet synchronized {if (isrChangeSet.nonEmpty &&(lastIsrChangeMs.get() + isrChangeNotificationConfig.lingerMs < now ||lastIsrPropagationMs.get() + isrChangeNotificationConfig.maxDelayMs < now)) {zkClient.propagateIsrChanges(isrChangeSet)isrChangeSet.clear()lastIsrPropagationMs.set(now)}}}
2、kraft模式
override def submit(topicIdPartition: TopicIdPartition,leaderAndIsr: LeaderAndIsr,controllerEpoch: Int): CompletableFuture[LeaderAndIsr] = {val future = new CompletableFuture[LeaderAndIsr]()val alterPartitionItem = AlterPartitionItem(topicIdPartition, leaderAndIsr, future, controllerEpoch)//把要修改的LeaderAndIsr信息放入到map中val enqueued = unsentIsrUpdates.putIfAbsent(alterPartitionItem.topicIdPartition.topicPartition, alterPartitionItem) == nullif (enqueued) {maybePropagateIsrChanges()} else {future.completeExceptionally(new OperationNotAttemptedException(s"Failed to enqueue ISR change state $leaderAndIsr for partition $topicIdPartition"))}future}private[server] def maybePropagateIsrChanges(): Unit = {//如果尚未收到请求,请发送所有待处理项目。if (!unsentIsrUpdates.isEmpty && inflightRequest.compareAndSet(false, true)) {//复制当前未发送的 ISR,但不从映射中删除,它们会在响应处理程序中清除val inflightAlterPartitionItems = new ListBuffer[AlterPartitionItem]()unsentIsrUpdates.values.forEach(item => inflightAlterPartitionItems.append(item))sendRequest(inflightAlterPartitionItems.toSeq)}}通过给controllerChannelManager发送请求通知
其中
controllerChannelManager是在BrokerServer.scala初始化时执行alterPartitionManager.start(),实现类是DefaultAlterPartitionManager,执行的是start方法,方法内部是controllerChannelManager.start()
private def sendRequest(inflightAlterPartitionItems: Seq[AlterPartitionItem]): Unit = {val brokerEpoch = brokerEpochSupplier()//构建一个AlterPartition请求,并返回请求对象request以及一个映射topicNamesByIdsval (request, topicNamesByIds) = buildRequest(inflightAlterPartitionItems, brokerEpoch)debug(s"Sending AlterPartition to controller $request")//我们不会使 AlterPartition 请求超时,而是让它无限期地重试,直到收到响应,或者新的 LeaderAndIsr 覆盖现有的 isrState,从而导致忽略这些分区的响应//controllerChannelManager.sendRequest方法用于将请求发送给控制器,并提供一个ControllerRequestCompletionHandler作为回调处理程序。controllerChannelManager.sendRequest(request,new ControllerRequestCompletionHandler {override def onComplete(response: ClientResponse): Unit = {debug(s"Received AlterPartition response $response")val error = try {if (response.authenticationException != null) {// For now we treat authentication errors as retriable. We use the// `NETWORK_EXCEPTION` error code for lack of a good alternative.// Note that `BrokerToControllerChannelManager` will still log the// authentication errors so that users have a chance to fix the problem.Errors.NETWORK_EXCEPTION} else if (response.versionMismatch != null) {Errors.UNSUPPORTED_VERSION} else {//处理响应handleAlterPartitionResponse(response.requestHeader,response.responseBody.asInstanceOf[AlterPartitionResponse],brokerEpoch,inflightAlterPartitionItems,topicNamesByIds)}} finally {// clear the flag so future requests can proceedclearInFlightRequest()}//省略代码}//省略代码})}其中handleAlterPartitionResponse是处理请求后响应结果的函数
def handleAlterPartitionResponse(requestHeader: RequestHeader,alterPartitionResp: AlterPartitionResponse,sentBrokerEpoch: Long,inflightAlterPartitionItems: Seq[AlterPartitionItem],topicNamesByIds: mutable.Map[Uuid, String]): Errors = {val data = alterPartitionResp.dataErrors.forCode(data.errorCode) match {//省略代码。。。。case Errors.NONE =>//创建一个partitionResponses的可变哈希映射,用于存储分区级别的响应。val partitionResponses = new mutable.HashMap[TopicPartition, Either[Errors, LeaderAndIsr]]()data.topics.forEach { topic =>//省略代码topic.partitions.forEach { partition =>//创建一个TopicPartition对象,表示主题和分区索引。val tp = new TopicPartition(topicName, partition.partitionIndex)val apiError = Errors.forCode(partition.errorCode)debug(s"Controller successfully handled AlterPartition request for $tp: $partition")if (apiError == Errors.NONE) {//解析分区的leaderRecoveryState,如果有效,则将分区的响应存储到partitionResponses中。LeaderRecoveryState.optionalOf(partition.leaderRecoveryState).asScala match {case Some(leaderRecoveryState) =>partitionResponses(tp) = Right(LeaderAndIsr(partition.leaderId,partition.leaderEpoch,partition.isr.asScala.toList.map(_.toInt),leaderRecoveryState,partition.partitionEpoch))//省略代码 }} else {partitionResponses(tp) = Left(apiError)}}}//遍历入参的inflightAlterPartitionItems,可以和响应结果对应,inflightAlterPartitionItems.foreach { inflightAlterPartition =>partitionResponses.get(inflightAlterPartition.topicIdPartition.topicPartition) match {case Some(leaderAndIsrOrError) =>//如果找到响应,将其从unsentIsrUpdates中移除,并根据响应的类型完成inflightAlterPartition.future。unsentIsrUpdates.remove(inflightAlterPartition.topicIdPartition.topicPartition)leaderAndIsrOrError match {case Left(error) => inflightAlterPartition.future.completeExceptionally(error.exception)case Right(leaderAndIsr) => inflightAlterPartition.future.complete(leaderAndIsr)}//省略代码}}//省略代码}//省略代码}
五、 maximalIsr和isr
1、PartitionState中,isr和maximalIsr两个字段的定义和为什么上面只是修改了maximalIsr
sealed trait PartitionState {/*** 仅包括已提交到 ZK 的同步副本。*/def isr: Set[Int]/***此集可能包括扩展后未提交的 ISR 成员。此“有效”ISR 用于推进高水位线以及确定 acks=all produce 请求需要哪些副本*/def maximalIsr: Set[Int]/*** The leader recovery state. See the description for LeaderRecoveryState for details on the different values.*/def leaderRecoveryState: LeaderRecoveryState/*** 指示我们是否有正在进行的 更改分区 请求。*/def isInflight: Boolean
}
原因以maybeShrinkIsr举例:
maybeShrinkIsr方法更新的是maximalIsr变量,而不是ISR列表本身。maximalIsr是一个优化变量,用于表示在上一次调用maybeShrinkIsr方法时,ISR列表的最大长度。这样,Kafka可以通过检查当前ISR列表的长度与maximalIsr的大小来判断是否需要进行收缩操作。更新maximalIsr变量而不是直接更新ISR列表本身可以减少内存拷贝的开销,因为ISR列表可能在方法调用期间频繁地被更新。另外,只更新maximalIsr变量而不更新ISR列表本身可以保持ISR列表的稳定性,以便其他并发操作可以安全地访问ISR列表。
2、什么时候maximalIsr会给isr赋值
这里折磨了我2天,还是没找到什么时候isr中的数据会根据maximalIsr修改,网关资料都没有查到,只是说适当的时机,这个时机在哪里?或者都讲解到修改maximalIsr就结束了,就认为isr修改成功了,我连单元测试都看了,下面分析一个单元测试,大家如果有结果可以在评论里给一下答案,
@ParameterizedTest
@ValueSource(strings = Array("zk", "kraft"))
def testIsrNotExpandedIfReplicaIsFencedOrShutdown(quorum: String): Unit = { val kraft = quorum == "kraft" val log = logManager.getOrCreateLog(topicPartition, topicId = None) seedLogData(log, numRecords = 10, leaderEpoch = 4) val controllerEpoch = 0 val leaderEpoch = 5 val remoteBrokerId = brokerId + 1 val replicas = List(brokerId, remoteBrokerId) val isr = Set(brokerId) val metadataCache: MetadataCache = if (kraft) mock(classOf[KRaftMetadataCache]) else mock(classOf[ZkMetadif (kraft) { addBrokerEpochToMockMetadataCache(metadataCache.asInstanceOf[KRaftMetadataCache], replicas) } // Mark the remote broker as eligible or ineligible in the metadata cache of the leader. // When using kraft, we can make the broker ineligible by fencing it. // In ZK mode, we must mark the broker as alive for it to be eligible. def markRemoteReplicaEligible(eligible: Boolean): Unit = { if (kraft) { when(metadataCache.asInstanceOf[KRaftMetadataCache].isBrokerFenced(remoteBrokerId)).thenReturn(!eligi} else { when(metadataCache.hasAliveBroker(remoteBrokerId)).thenReturn(eligible) } } //初始化分区 val partition = new Partition( topicPartition, replicaLagTimeMaxMs = Defaults.ReplicaLagTimeMaxMs, interBrokerProtocolVersion = MetadataVersion.latest, localBrokerId = brokerId, () => defaultBrokerEpoch(brokerId), time, alterPartitionListener, delayedOperations, metadataCache, logManager, alterPartitionManager ) partition.createLogIfNotExists(isNew = false, isFutureReplica = false, offsetCheckpoints, None) assertTrue(partition.makeLeader( new LeaderAndIsrPartitionState() .setControllerEpoch(controllerEpoch) .setLeader(brokerId) .setLeaderEpoch(leaderEpoch) .setIsr(isr.toList.map(Int.box).asJava) .setPartitionEpoch(1) .setReplicas(replicas.map(Int.box).asJava) .setIsNew(true), offsetCheckpoints, None), "Expected become leader transition to succeed") assertEquals(isr, partition.partitionState.isr) assertEquals(isr, partition.partitionState.maximalIsr) markRemoteReplicaEligible(true) // Fetch to let the follower catch up to the log end offset and
// to check if an expansion is possible.
//获取以让追随者赶上日志结束偏移量和检查是否可以扩展
fetchFollower(partition, replicaId = remoteBrokerId, fetchOffset = log.logEndOffset) // Follower fetches and catches up to the log end offset.
//追随者获取并赶上日志结束偏移量。
assertReplicaState(partition, remoteBrokerId, lastCaughtUpTimeMs = time.milliseconds(), logStartOffset = 0L, logEndOffset = log.logEndOffset
) // Expansion is triggered.
//扩展被触发。
assertEquals(isr, partition.partitionState.isr)
assertEquals(replicas.toSet, partition.partitionState.maximalIsr)
assertEquals(1, alterPartitionManager.isrUpdates.size) // Controller rejects the expansion because the broker is fenced or offline.
//控制器拒绝扩展,因为代理处于受防护或脱机状态。
alterPartitionManager.failIsrUpdate(Errors.INELIGIBLE_REPLICA) // The leader reverts back to the previous ISR. //领导者将恢复到以前的 ISR。 assertEquals(isr, partition.partitionState.isr) assertEquals(isr, partition.partitionState.maximalIsr) assertFalse(partition.partitionState.isInflight) assertEquals(0, alterPartitionManager.isrUpdates.size) // The leader eventually learns about the fenced or offline broker. markRemoteReplicaEligible(false) // The follower fetches again. //追随者再次获取 fetchFollower(partition, replicaId = remoteBrokerId, fetchOffset = log.logEndOffset) // Expansion is not triggered because the follower is fenced. //不会触发扩展,因为追随者被围栏 assertEquals(isr, partition.partitionState.isr) assertEquals(isr, partition.partitionState.maximalIsr) assertFalse(partition.partitionState.isInflight) assertEquals(0, alterPartitionManager.isrUpdates.size) // The broker is eventually unfenced or brought back online. //经纪人最终被解除围栏或重新上线。 markRemoteReplicaEligible(true) // The follower fetches again. //追随者再次获取。 fetchFollower(partition, replicaId = remoteBrokerId, fetchOffset = log.logEndOffset) // Expansion is triggered. //扩展被触发。 assertEquals(isr, partition.partitionState.isr) assertEquals(replicas.toSet, partition.partitionState.maximalIsr) assertTrue(partition.partitionState.isInflight) assertEquals(1, alterPartitionManager.isrUpdates.size) // Expansion succeeds. //扩容成功。 alterPartitionManager.completeIsrUpdate(newPartitionEpoch = 1) // ISR is committed. //todo ISR 已提交。 assertEquals(replicas.toSet, partition.partitionState.isr) assertEquals(replicas.toSet, partition.partitionState.maximalIsr) assertFalse(partition.partitionState.isInflight) assertEquals(0, alterPartitionManager.isrUpdates.size)
}
注意上面alterPartitionManager.completeIsrUpdate(newPartitionEpoch = 1) ,在这条命令之前,maximalIsr已经是最新的了,而isr还是旧的,当执行完这个命令后,isr和maximalIsr已经相同了,都是最新的了
其中alterPartitionManager.completeIsrUpdate执行的是TestUtils类中如下方法,
class MockAlterPartitionManager extends AlterPartitionManager {val isrUpdates: mutable.Queue[AlterPartitionItem] = new mutable.Queue[AlterPartitionItem]()val inFlight: AtomicBoolean = new AtomicBoolean(false)//这个命令会在fetchFollower命令里面执行,执行链条//fetchFollower->fetchRecords->updateFollowerFetchState->maybeExpandIsr->submitAlterPartition->submit//主要是把数据存入isrUpdatesoverride def submit(topicPartition: TopicIdPartition,leaderAndIsr: LeaderAndIsr,controllerEpoch: Int): CompletableFuture[LeaderAndIsr]= {val future = new CompletableFuture[LeaderAndIsr]()if (inFlight.compareAndSet(false, true)) {isrUpdates += AlterPartitionItem(topicPartition,leaderAndIsr,future,controllerEpoch)} else {future.completeExceptionally(new OperationNotAttemptedException(s"Failed to enqueue AlterIsr request for $topicPartition since there is already an inflight request"))}future}def completeIsrUpdate(newPartitionEpoch: Int): Unit = {if (inFlight.compareAndSet(true, false)) {val item = isrUpdates.dequeue()//第四章节,kraft模式,inflightAlterPartition.future.complete//第四章节,zk模式,future.complete(leaderAndIsr.withPartitionEpoch(newVersion))item.future.complete(item.leaderAndIsr.withPartitionEpoch(newPartitionEpoch))} else {fail("Expected an in-flight ISR update, but there was none")}}}
其中isrUpdates.dequeue()出来的就是AlterPartitionItem,之后执行item.future.complete,之后isr修改完了,很莫名其妙,
我分析了第四章节和这个命令一样功能代码,他这里也没有future.whenComplete的后续处理,但是也修改了isr,不明白
相关文章:

kafka 3.5 主题分区ISR伸缩源码
ISR(In-sync Replicas):保持同步的副本 OSR(Outof-sync Replicas):不同步的副本。最开始所有的副本都在ISR中,在kafka工作的过程中,如果某个副本同步速度慢于replica.lag.time.max.ms指定的阈值,则被踢出ISR存入OSR&am…...
1-centOS7搭建伪分布式
前言:虚拟机快照的使用 VMware Workstation 软件可以用快照进行迅速的虚拟机状态的切换 ※. 类似于虚拟机备份, 可以使用备份进行快速恢复。 比如没安装jdk之前拍摄快照来备份 ※. 若jdk没安装好或者jdk环境变量配置的有问题, 可以用安装之…...

对开源自动化测试平台MeterSphere的使用感触
1:该平台可以通过接口,参数,配置的维护,然后继续接口自动化“一键测试”,功能还是挺强大的,具体的使用需要研究 MeterSphere的官网:MeterSphere - 专业测试云 2:一键测试在生产环境…...
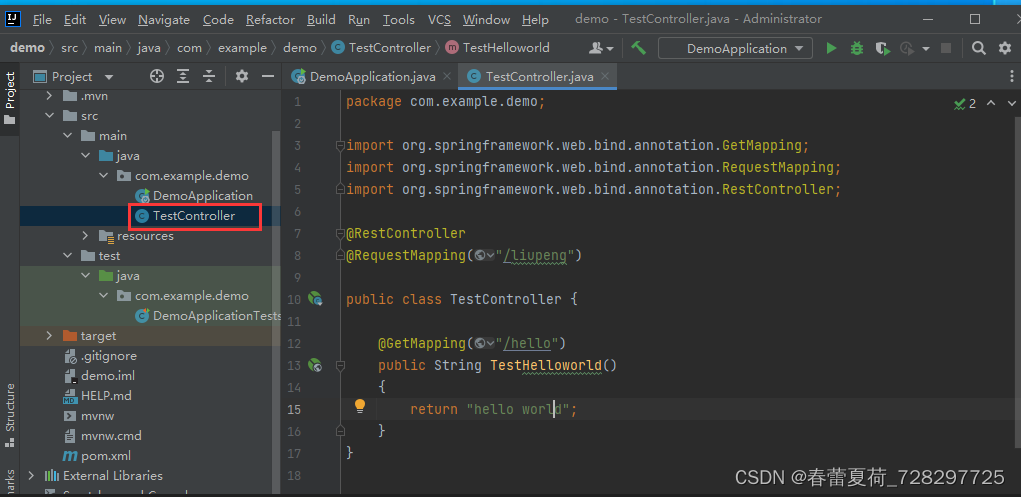
Spring boot 第一个程序
新建工程 选择spring-boot版本 右键创建类TestController: 代码如下: package com.example.demo; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RequestMapping; import org.springf…...

【SpringMVC】实现增删改查(附源码)
目录 引言 一、前期准备 1.1.搭建Maven环境 1.2.导入pom.xml依赖 1.3.导入配置文件 ①jdbc.properties ②generatorConfig.xml ③log4j2.xml ④spring-mybatis.xml ⑤spring-context.xml ⑥spring-mvc.xml ⑦修改web.xml文件 二、逆向生成增删改查 2.1.导入相关u…...

理财是什么?怎样学习理财?
大家好,我是财富智星,今天跟大家分享一下理财是什么?怎样学习理财的方法。 一、理财的基本原则 1、理财应注重投资而不是投机,要与时间为友。 让我们先考虑以下问题:什么样的回报才算是真正的高回报?假设有…...

华为云云耀云服务器L实例评测 | 开启OPC UA之旅
OPC Unified Architecture (OPC UA)是一种用于工业自动化的M2M协议(Machine-to-machine),具有平台独立性,在Windows和Linux上都可以运行。随着云服务在工业现场的不断普及,OPCUA服务也开始大量部署在云端。 本文以华为云云耀云服务器L为基础…...

帝国CMS灵动标签如何调用$ecms_hashur[‘ehref‘]函数
我们在二次开发时,后台调用链接就需要加上帝国CMS的$ecms_hashur[ehref]函数,这是帝国CMS后台的安全函数,防止外部直接访问后台页面,直接强制访问后台链接就会提示“非法来源”。 我的站长站分享下制作自定义php页面,用帝国CMS灵动标签如何调用$ecms_hashur[ehref]函数方…...

ES6 拓展(下)
一、函数的拓展 1.1、默认参数 在ES5中设置默认参数: function func(words, name) {name name || "闷墩儿";console.log(words, name); } func("大家好!我是"); func("大家好!我是", "憨憨");func(…...

TouchGFX之自定义触发条件和操作
通过TouchGFX Designer,您可以自己定义具有触发条件和操作的交互组件。 自定义容器创建自定义触发条件:通过自定义容器的属性选项卡添加自定义触发条件 使用交互系统发送自定义触发条件: 通过自定义容器的“交互”选项卡,创建新的…...
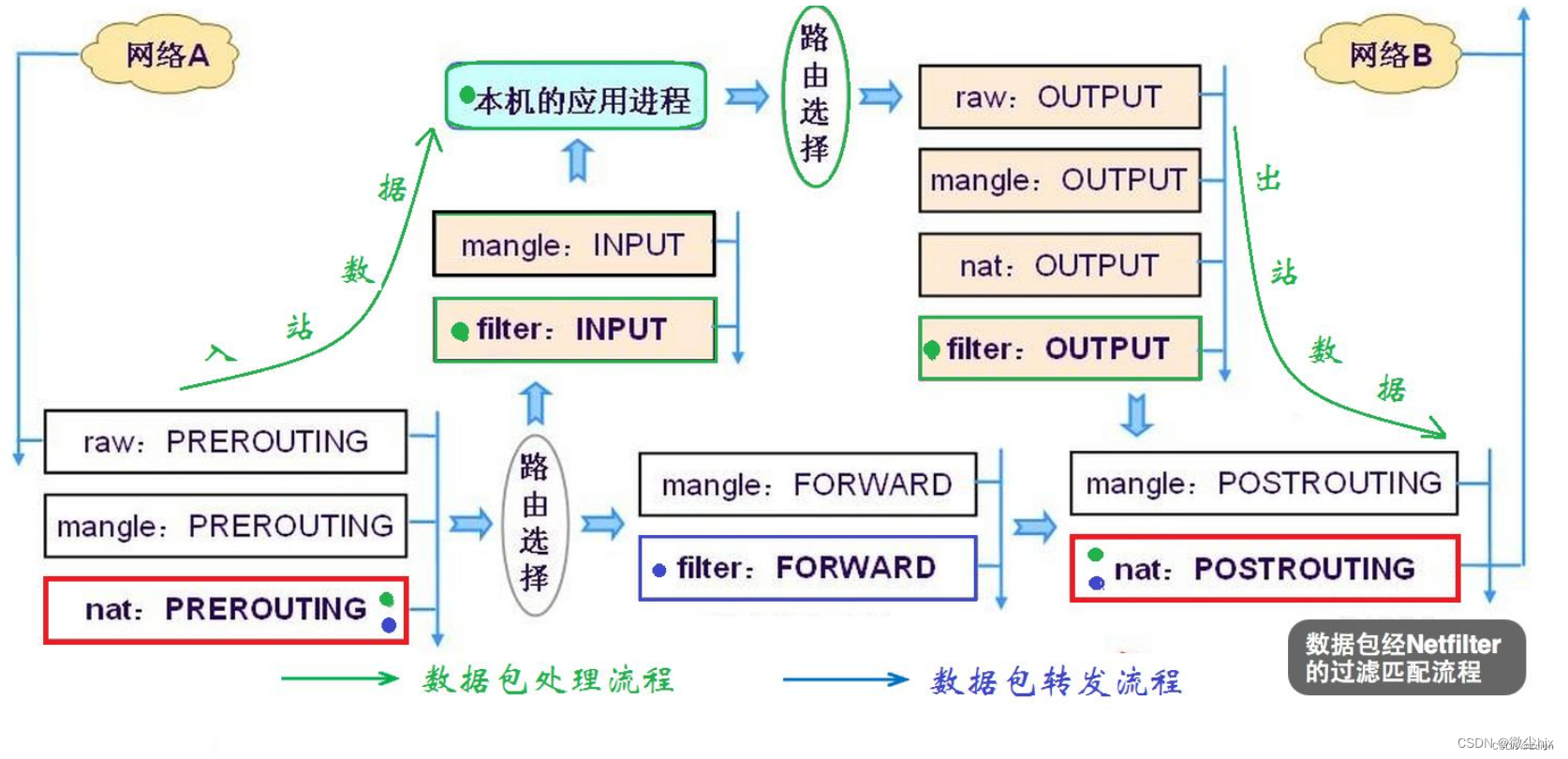
Linux防火墙(iptables)
一、linux的防火墙组成 linux的防火墙由netfilter和iptables组成。用户空间的iptables制定防火墙规则,内核空间的netfilter实现防火墙功能。 netfilter(内核空间)位于Linux内核中的包过滤防火墙功能体系,称为Linux防火墙的“内核…...
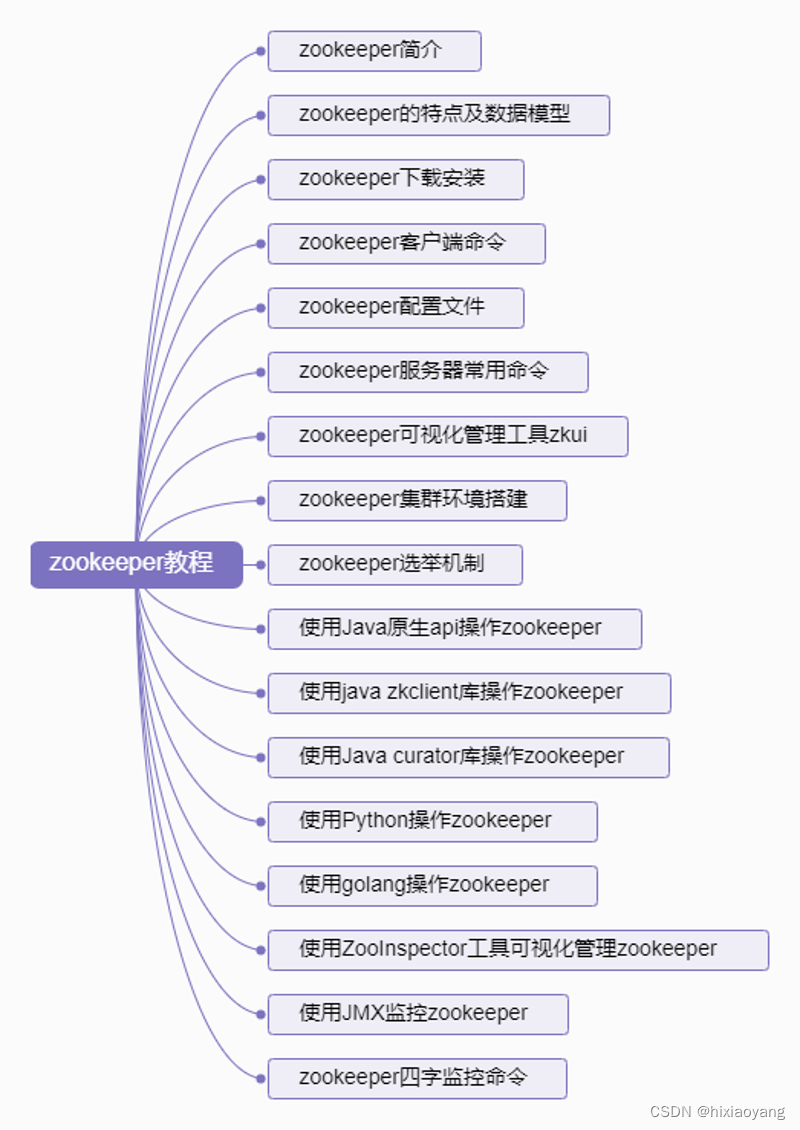
zookeeper教程
zookeeper教程 zookeeper简介zookeeper的特点及数据模型zookeeper下载安装zookeeper客户端命令zookeeper配置文件zookeeper服务器常用命令zookeeper可视化管理工具zkuizookeeper集群环境搭建zookeeper选举机制使用Java原生api操作zookeeper使用java zkclient库操作zookeeper使用…...

杭州快递物流展-2024长三角快递物流供应链与技术装备展览会(杭州)
2024快递物流创新高质量发展论坛暨 2024长三角快递物流供应链与技术装备展览会(杭州) 时间:2024年4月12-14 日 地点:杭州国际博览中心 ESYE长三角快递物流展是亚洲范围内超大规模的快递物流业展示平台,由于展会的需求 及扩大市场的影响力…...

CSP 202203-1 未初始化警告
答题 要注意是xi和yi的范围,yi可以是0为常数。 #include<iostream> using namespace std;int main() {int n,k;cin>>n>>k;bool*initializenew bool[n]{false};int result0,x,y;while(k--){cin>>x>>y;if(y&&!initialize[y-1…...
开发指导—利用组件插值器动画实现 HarmonyOS 动效
一. 组件动画 在组件上创建和运行动画的快捷方式。具体用法请参考通用方法。 获取动画对象 通过调用 animate 方法获得 animation 对象,animation 对象支持动画属性、动画方法和动画事件。 <!-- xxx.hml --><div class"container"> <di…...

树莓派入门
目录 前言系统烧录使用官方烧录工具选择操作系统选择存储卡配置 Win32DiskImager 有屏幕树莓派开机树莓派关机无屏幕树莓派开机获取树莓派IP地址通过路由器获取共享网络方式获取给树莓派配置静态IP地址查找默认网关分盘给树莓派的IP地址修改树莓派DHCP配置文件 ssh登录 让树莓派…...
算法模型嵌入式 Mendix应用的开发示例
一、前言 根据埃森哲最新一项调查,2023年67%的企业持续加大在技术方面的投入,其中数据和AI应用是重中之重。AI在企业内部应用这个话题已经保持了十多年的热度,随着ChatGPT为代表的生成式AI技术的出现,这一话题迎来又一波的高潮。…...

如何使用Cygwin编译最新版的Redis源码,生成适用于Windows的Redis
文章目录 一、准备Cygwin环境二、下载Redis源码三、编译redis-7.2.01. 执行make命令2. 重新执行make命令3. 再次执行make命令4. 将编译后的可执行文件及依赖放到同一个文件夹5. 测试编译生成的可执行程序 四、换其他redis版本重新编译1. 编译redis-7.0.122. 编译redis-6.2.133.…...

Linux 修改SSH端口
如果防火墙,或防火墙已经开启,需要先开放2222端口 firewall-cmd --add-port2222/tcp --permanent --zonepublic firewall-cmd --reload编辑文件 vim /etc/ssh/sshd_config: #Port 22 Port 2222 # 打开注释,并修改为以下值 Clien…...
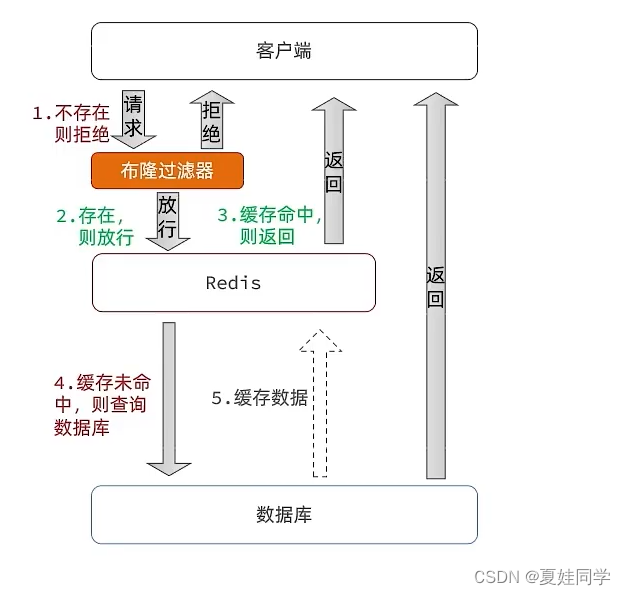
Redis经典问题:缓存穿透
(笔记总结自《黑马点评》项目) 一、产生原因 用户请求的数据在缓存中和数据库中都不存在,不断发起这样的请求,给数据库带来巨大压力。 常见的解决方式有缓存空对象和布隆过滤器。 二、缓存空对象 思路:当我们客户…...

MQTTX连接风暴下的ECONNRESET:从异常表象到服务端会话队列的深度剖析
1. 当MQTTX遭遇连接风暴:ECONNRESET异常现象解析 第一次看到控制台刷出"READ ECONNRESET"错误时,我正端着咖啡准备测试新部署的MQTT集群。这个看似简单的网络断开提示,背后隐藏着服务端会话队列的深度博弈。想象一下早高峰的地铁闸…...

告别文档迁移困境:3个关键场景解锁飞书文档批量备份新方案
告别文档迁移困境:3个关键场景解锁飞书文档批量备份新方案 【免费下载链接】feishu-doc-export 项目地址: https://gitcode.com/gh_mirrors/fe/feishu-doc-export 还在为团队协作平台切换带来的文档迁移难题而烦恼吗?当企业从飞书切换到其他办公…...
)
保姆级教程:在Windows上用CMake+QT给CloudCompare 2.13.x添加一个Standard插件(附OpenCV配置)
从零构建CloudCompare插件:Windows平台CMakeQT全流程实战指南 在三维点云处理领域,CloudCompare凭借其开源特性和丰富的插件生态,已成为研究人员和工程师的首选工具之一。但对于刚接触插件开发的初学者而言,从环境配置到成功编译第…...

Python 入门第一课:为什么选择 Python?3 分钟搭建你的第一个程序
一、先聊点人话:为啥要学 Python? 说实话,当初我选编程语言的时候也纠结过。Java?太啰嗦。C?头都大了。JavaScript?浏览器里跑着玩还行… 直到我遇见了 Python。 这玩意儿有多友好? 这么说吧&…...

为什么你的asyncio服务内存永不释放?深入CPython asyncio循环引用链,给出4行补丁级解决方案!
第一章:Shell脚本的基本语法和命令Shell脚本是Linux/Unix系统自动化任务的核心工具,以可执行文本文件形式存在,由Bash等Shell解释器逐行解析执行。其语法简洁但严谨,强调空格、换行与引号的正确使用。脚本结构与执行方式 每个Shel…...

Ollama镜像免配置原理:daily_stock_analysis启动脚本中systemd服务注册与健康检查逻辑
Ollama镜像免配置原理:daily_stock_analysis启动脚本中systemd服务注册与健康检查逻辑 1. 项目背景与核心价值 在当今AI技术快速发展的时代,本地化部署大模型成为了许多企业和开发者的迫切需求。daily_stock_analysis镜像正是基于这一需求,…...

OpenClaw批量处理妙用:Qwen3.5-9B同时校对100篇Markdown格式
OpenClaw批量处理妙用:Qwen3.5-9B同时校对100篇Markdown格式 1. 为什么需要批量Markdown校对 作为技术文档写作者,我经常需要处理大量Markdown文件。最让我头疼的问题不是内容创作,而是格式规范——标题层级错乱、中英文混排空格缺失、列表…...
基于Transformer架构解析:Nanbeige 4.1-3B 模型原理与性能调优
基于Transformer架构解析:Nanbeige 4.1-3B 模型原理与性能调优 最近在星图GPU平台上部署和测试Nanbeige 4.1-3B模型时,我发现很多朋友对Transformer架构的理解还停留在“听说过”的阶段,对模型参数、显存占用这些概念更是感到头疼。其实&…...

语音控制扩展:让OpenClaw通过nanobot响应语音指令
语音控制扩展:让OpenClaw通过nanobot响应语音指令 1. 为什么需要语音控制OpenClaw 作为一个长期使用OpenClaw的开发者,我一直在思考如何让这个强大的自动化工具更加"人性化"。键盘鼠标操作固然精确,但在某些场景下——比如双手被…...

MacOS极简部署OpenClaw:GLM-4.7-Flash云端沙盒体验
MacOS极简部署OpenClaw:GLM-4.7-Flash云端沙盒体验 1. 为什么选择云端沙盒体验 作为一个长期在本地折腾各种AI工具的技术爱好者,我最近被OpenClaw的自动化能力深深吸引。但在第一次尝试本地部署时,就被Node环境配置、依赖冲突等问题劝退。直…...