【100天精通Python】Day56:Python 数据分析_Pandas数据清洗和处理(删除填充插值,数据类型转换,去重,连接与合并)
目录
数据清洗和处理
1.处理缺失值
1.1 删除缺失值:
1.2 填充缺失值:
1.3 插值:
2 数据类型转换
2.1 数据类型转换
2.2 日期和时间的转换:
2.3 分类数据的转换:
2.4 自定义数据类型的转换:
3 数据去重
4 数据合并和连接
数据清洗和处理
在数据清洗和处理方面,Pandas 提供了多种功能,包括处理缺失值、数据类型转换、数据去重以及数据合并和连接。以下是这些功能的详细描述和示例:
1.处理缺失值
在 Pandas 中处理缺失值有多种方法,包括删除缺失值、填充缺失值和插值。
1.1 删除缺失值:
删除缺失值是最简单的方法,但有时会导致数据损失。您可以使用 dropna() 方法来删除包含缺失值的行或列。
(1)删除包含缺失值的行:
import pandas as pddata = {'A': [1, 2, None, 4],'B': [5, None, 7, 8]}
df = pd.DataFrame(data)# 删除包含缺失值的行
df_cleaned = df.dropna()
print("删除包含缺失值的行的结果:\n", df_cleaned)
(2)删除包含缺失值的列:
# 删除包含缺失值的列
df_cleaned_columns = df.dropna(axis=1)
print("删除包含缺失值的列的结果:\n", df_cleaned_columns)
1.2 填充缺失值:
填充缺失值是用特定值替代缺失值的方法。您可以使用 fillna() 方法来填充缺失值。
使用特定值填充缺失值:
# 使用特定值填充缺失值
df_filled = df.fillna(0) # 用 0 填充缺失值
print("使用特定值填充缺失值的结果:\n", df_filled)
1.3 插值:
插值是一种基于数据的方法,根据已知数据点的值来估计缺失值。Pandas 提供了多种插值方法,如线性插值、多项式插值等。
(1) 线性插值:
线性插值使用已知数据点之间的线性关系来估计缺失值。这是一种简单而常见的插值方法。
import pandas as pddata = {'A': [1, 2, None, 4],'B': [5, None, 7, 8]}
df = pd.DataFrame(data)# 使用线性插值填充缺失值
df_interpolated = df.interpolate()
print("使用线性插值填充缺失值的结果:\n", df_interpolated)
(2) 多项式插值:
多项式插值使用多项式函数来逼近已知数据点,以估计缺失值。您可以指定多项式的阶数。
# 使用多项式插值填充缺失值(阶数为2)
df_poly_interpolated = df.interpolate(method='polynomial', order=2)
print("使用多项式插值填充缺失值的结果:\n", df_poly_interpolated)
(3) 时间序列插值:
对于时间序列数据,可以使用时间相关的插值方法,例如时间线性插值。
# 创建一个带有时间索引的示例 DataFrame
data = {'A': [1, 2, None, 4],'B': [5, None, 7, 8]}
dates = pd.date_range(start='2021-01-01', periods=len(data))
df_time_series = pd.DataFrame(data, index=dates)# 使用时间线性插值填充缺失值
df_time_series_interpolated = df_time_series.interpolate(method='time')
print("使用时间线性插值填充缺失值的结果:\n", df_time_series_interpolated)
2 数据类型转换
在 Pandas 中,数据类型转换是将一列或多列的数据类型更改为其他数据类型的过程。数据类型的转换可以帮助您适应特定的分析需求或确保数据的一致性。以下是一些常见的数据类型转换操作以及示例:
2.1 数据类型转换
- 使用
astype()方法将一列的数据类型转换为其他数据类型,如将整数列转换为浮点数列。 - 使用
pd.to_numeric()将列转换为数值类型,例如整数或浮点数。
import pandas as pd# 创建示例 DataFrame
data = {'A': [1, 2, 3],'B': ['4', '5', '6']}
df = pd.DataFrame(data)# 将列 'A' 从整数转换为浮点数
df['A'] = df['A'].astype(float)# 将列 'B' 从字符串转换为整数
df['B'] = pd.to_numeric(df['B'])print(df)
DataFrame 中的数据类型转换:
df.astype(dtype, copy=True, errors='raise')
dtype: 要将数据类型转换为的目标数据类型。可以是 NumPy 的数据类型(如np.float32)或 Python 数据类型(如float或int)。copy(可选,默认为 True):指定是否返回副本(True)或修改原始 DataFrame(False)。errors(可选,默认为 'raise'):指定如何处理转换错误。如果为 'raise',则会引发异常;如果为 'coerce',则将无法转换的值设置为 NaN。
Series 中的数据类型转换:
s.astype(dtype, copy=True, errors='raise')
import pandas as pd# 创建一个示例 DataFrame
data = {'A': [1, 2, 3],'B': [4, 5, 6]}
df = pd.DataFrame(data)# 将列 'A' 从整数转换为浮点数
df['A'] = df['A'].astype(float)# 将列 'B' 从整数转换为字符串
df['B'] = df['B'].astype(str)# 将列 'C' 从字符串转换为整数并处理转换错误(设置无法转换的值为 NaN)
df['C'] = pd.to_numeric(df['C'], errors='coerce').astype(int)print(df.dtypes)
上述示例中,我们演示了如何使用
astype()和pd.to_numeric()进行数据类型的转换,包括整数转浮点数、整数转字符串以及字符串转整数并处理转换错误的情况。
2.2 日期和时间的转换:
- 使用
pd.to_datetime()将列转换为日期时间类型,以便进行日期时间操作。
import pandas as pd# 创建示例 DataFrame
data = {'Date': ['2021-01-01', '2021-01-02', '2021-01-03'],'Value': [10, 15, 20]}
df = pd.DataFrame(data)# 将 'Date' 列从字符串转换为日期时间类型
df['Date'] = pd.to_datetime(df['Date'])print(df.dtypes)
2.3 分类数据的转换:
- 使用
astype('category')将列转换为分类数据类型,适用于有限的离散值。
import pandas as pd# 创建示例 DataFrame
data = {'Category': ['A', 'B', 'A', 'C']}
df = pd.DataFrame(data)# 将 'Category' 列转换为分类数据类型
df['Category'] = df['Category'].astype('category')print(df.dtypes)
2.4 自定义数据类型的转换:
- 您可以使用自定义函数来将数据转换为所需的数据类型,例如使用
apply()方法。
import pandas as pd# 创建示例 DataFrame
data = {'Numbers': ['1', '2', '3', '4']}
df = pd.DataFrame(data)# 自定义函数将字符串转换为整数并应用到 'Numbers' 列
df['Numbers'] = df['Numbers'].apply(lambda x: int(x))print(df.dtypes)
3 数据去重
在 Pandas 中,您可以使用 drop_duplicates() 方法来删除重复的行。这个方法会返回一个新的 DataFrame,其中不包含重复的行。以下是如何在 Pandas 中执行数据去重操作的示例:
import pandas as pd# 创建示例 DataFrame
data = {'Name': ['Alice', 'Bob', 'Alice', 'David', 'Bob'],'Age': [25, 30, 25, 40, 30]}
df = pd.DataFrame(data)# 执行去重操作,基于所有列
df_no_duplicates = df.drop_duplicates()print("原始 DataFrame:")
print(df)print("\n去重后的 DataFrame:")
print(df_no_duplicates)
上述示例中,drop_duplicates() 方法将基于所有列的内容来去重。如果要基于特定列进行去重,您可以通过传递 subset 参数来指定:
# 基于 'Name' 列进行去重
df_no_duplicates_name = df.drop_duplicates(subset=['Name'])print("基于 'Name' 列去重后的 DataFrame:")
print(df_no_duplicates_name)
您还可以使用 keep 参数来控制保留哪一个重复值。例如,keep='first'(默认值)将保留第一个出现的值,而 keep='last' 将保留最后一个出现的值:
# 基于 'Name' 列进行去重,保留最后一个出现的值
df_keep_last = df.drop_duplicates(subset=['Name'], keep='last')print("基于 'Name' 列去重,保留最后一个出现的值的 DataFrame:")
print(df_keep_last)
这些示例演示了如何使用 Pandas 进行数据去重。根据您的需求,您可以选择不同的去重方式。
4 数据合并和连接
在 Pandas 中,您可以使用不同的方法进行数据合并和连接,这通常用于将多个数据集组合在一起以进行分析。以下是一些常见的数据合并和连接操作以及示例:
4.1 pd.concat():
用于将多个 DataFrame 沿指定轴(通常是行轴或列轴)堆叠在一起。pd.concat() 默认在行轴(axis=0)上堆叠多个 DataFrame,也就是沿着行方向将它们连接在一起。如果您想在列轴(axis=1)上堆叠多个 DataFrame,可以通过指定 axis 参数为1 来实现。
import pandas as pd# 创建两个示例 DataFrame
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2'],'B': ['B0', 'B1', 'B2']})df2 = pd.DataFrame({'A': ['A3', 'A4', 'A5'],'B': ['B3', 'B4', 'B5']})# 在行轴上堆叠两个 DataFrame
result1 = pd.concat([df1, df2])# 在列轴上堆叠两个 DataFrame
result2 = pd.concat([df1, df2], axis=1)print(result1,result2)
输出:

4.2 pd.merge():
用于基于一个或多个键(列)将两个 DataFrame 合并在一起,类似于 SQL 的 JOIN 操作。
import pandas as pd# 创建两个示例 DataFrame
left = pd.DataFrame({'key': ['K0', 'K1', 'K2'],'value_left': ['V0', 'V1', 'V2']})right = pd.DataFrame({'key': ['K1', 'K2', 'K3'],'value_right': ['V3', 'V4', 'V5']})# 基于 'key' 列进行合并
result = pd.merge(left, right, on='key')print(result)
输出

4.3 df.join():
用于将两个 DataFrame 沿索引合并。
import pandas as pd# 创建两个示例 DataFrame
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2'],'B': ['B0', 'B1', 'B2']}, index=['I0', 'I1', 'I2'])df2 = pd.DataFrame({'C': ['C0', 'C1', 'C2'],'D': ['D0', 'D1', 'D2']}, index=['I1', 'I2', 'I3'])# 沿索引合并两个 DataFrame
result = df1.join(df2)print(result)
输出:

这些是一些常见的数据合并和连接操作示例。根据您的需求,您可以选择适当的方法来合并和连接数据集。 Pandas 提供了丰富的选项和参数,以满足不同的合并和连接需求。
相关文章:
【100天精通Python】Day56:Python 数据分析_Pandas数据清洗和处理(删除填充插值,数据类型转换,去重,连接与合并)
目录 数据清洗和处理 1.处理缺失值 1.1 删除缺失值: 1.2 填充缺失值: 1.3 插值: 2 数据类型转换 2.1 数据类型转换 2.2 日期和时间的转换: 2.3 分类数据的转换: 2.4 自定义数据类型的转换: 3 数…...
phpstudy本地快速搭建网站,并外网访问【无公网IP】
文章目录 使用工具1. 本地搭建web网站1.1 下载phpstudy后解压并安装1.2 打开默认站点,测试1.3 下载静态演示站点1.4 打开站点根目录1.5 复制演示站点到站网根目录1.6 在浏览器中,查看演示效果。 2. 将本地web网站发布到公网2.1 安装cpolar内网穿透2.2 映…...
WebSocket的那些事(5-Spring STOMP支持之连接外部消息代理)
目录 一、序言二、开启RabbitMQ外部消息代理三、代码示例1、Maven依赖项2、相关实体3、自定义用户认证拦截器4、Websocket外部消息代理配置5、ChatController6、前端页面chat.html 四、测试示例1、群聊、私聊、后台定时推送测试2、登录RabbitMQ控制台查看队列信息 五、结语 一、…...
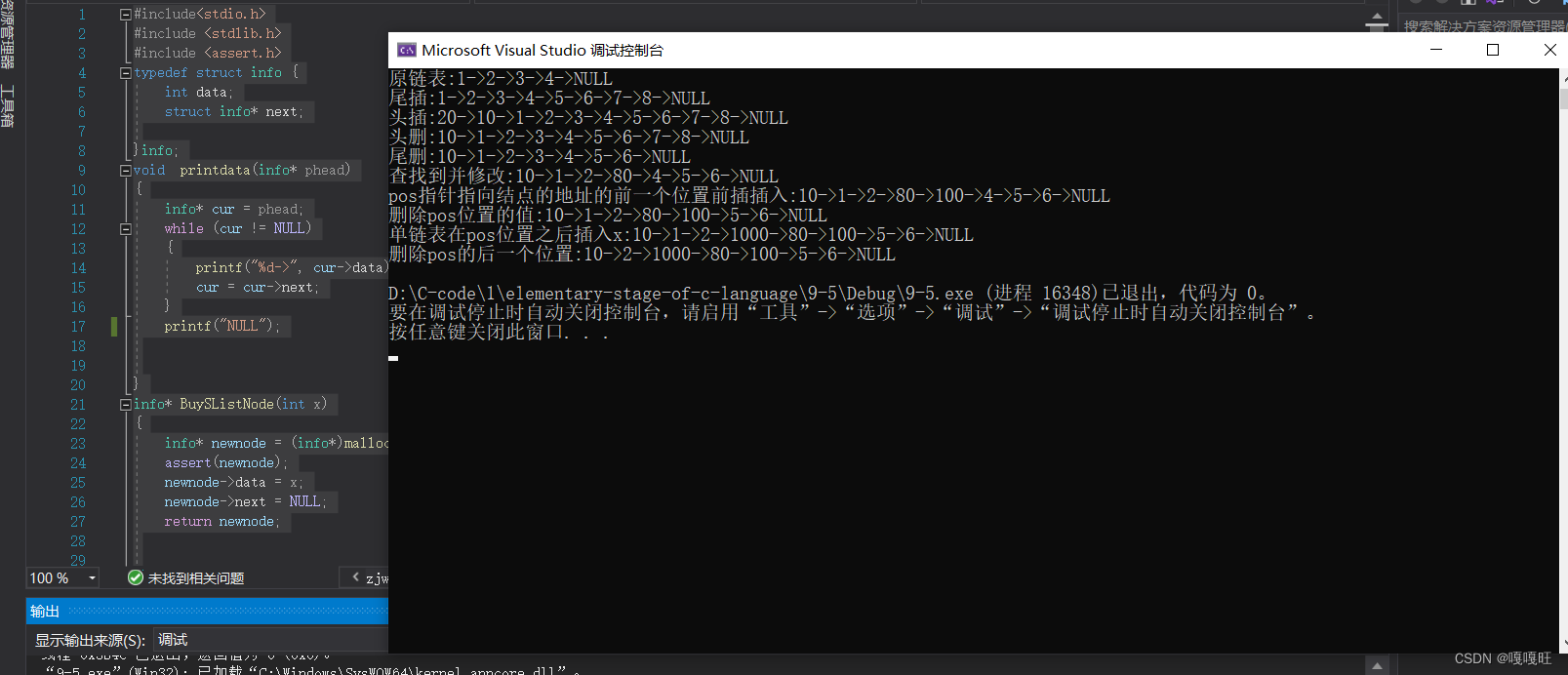
【数据结构】单链表详解
当我们学完顺序表的时候,我们发现了好多问题如下: 中间/头部的插入删除,时间复杂度为O(N)增容需要申请新空间,拷贝数据,释放旧空间。会有不小的消耗。增容一般是呈2倍的增长,势必会有一定的空间浪费。例如当…...

dql的执行顺序
在 SQL 查询语言中,DQL(Data Query Language)是用于从数据库中检索数据的部分。SQL 查询的执行顺序通常按照以下步骤进行: FROM 子句:查询首先确定要从哪些表中检索数据。在 FROM 子句中列出的表格被称为源表ÿ…...

java的动态代理如何实现
一. JdkProxy jdkproxy动态代理必须基于接口(interface)实现 接口UserInterface.java public interface UserService {String getUserName(String userCde); }原始实现类:UseServiceImpl.java public class UserServiceImpl implements UserSerice {Overridepub…...

Java--日志管理
日志管理 作用: 设置日志级别,决定什么日志信息应该被输出、什么日志信息应该被忽略。 基本工具 见的日志管理用具有:JDK logging(配置文件:logging.properties) 和log4j(配置文件:log4j.properties) 。…...
Pygame中Sprite类的使用2
4 让僵尸动起来 让僵尸能够动起来,也就是让僵尸从屏幕右边走到屏幕左边,此时只需要使用while循环,改变僵尸图片的x轴坐标即可,代码如下所示。 while True:screen.fill((255,255,255))z1.rect.x - 5z1.draw(screen)z1.update()if…...

排队时延与流量强度
流量强度 设R为传输速率,a表示分组到达队列的平均速率,假定所有分组都是由L比特组成的,则比特到达队列的平均速率为La。比率 L a R \frac{La}{R} RLa被成为流量强度。 根据流量强度的定义,我们可以很直观的得出以下结论&#x…...

mysql:如何设计互相关注业务场景
目录 业务场景 业务问题: 数据库表设计: like(关注表): friend(朋友表) 并发场景下,SQL语句执行逻辑 比较 A 和 B 的大小,如果 A执行下面的逻辑:<&…...

AI伦理:科技发展中的人性之声
文章目录 AI伦理的关键问题1. 隐私问题2. 公平性问题3. 自主性问题4. 伦理教育问题 隐私问题的拓展分析数据收集和滥用隐私泄露和数据安全 公平性问题的拓展分析历史偏见和算法模型可解释性 自主性问题的拓展分析自主AI决策伦理框架 伦理教育的拓展分析伦理培训 结论 …...

Direct3D光照
光照的组成 环境光:这种类型的光经其他表面反射到达物体表面,并照亮整个场景,要想以较低代价粗略模拟这类反射光,环境光是一个很好的选择 漫射光:这种类型光沿着特定的方向传播。当它到达某一表面时,将沿…...

编程语言排行榜
以下是2023年的编程语言排行榜(按照流行度排序): Python:Python一直以来都是非常受欢迎的编程语言,它简洁、易读且功能强大。在数据科学、机器学习、人工智能等领域有广泛应用。 JavaScript:作为前端开发…...

基于语雀编辑器的在线文档编辑与查看
概述 语雀是一个非常优秀的文档和知识库工具,其编辑器更是非常好用,虽无开源版本,但有编译好的可以使用。本文基于语雀编辑器实现在线文档的编辑与文章的预览。 实现效果 实现 参考语雀编辑器官方文档,其实现需要引入以下文件&…...
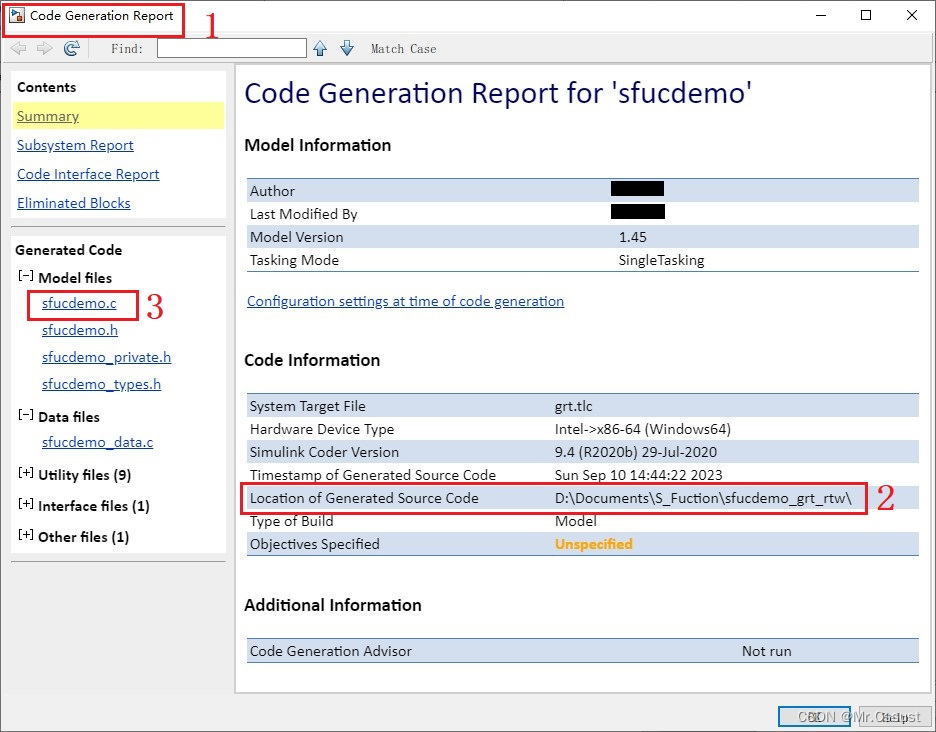
开箱报告,Simulink Toolbox库模块使用指南(六)——S-Fuction模块(TLC)
文章目录 前言 Target Language Compiler(TLC) C MEX S-Function模块 编写TLC文件 生成代码 Tips 分析和应用 总结 前言 见《开箱报告,Simulink Toolbox库模块使用指南(一)——powergui模块》 见《开箱报告&am…...
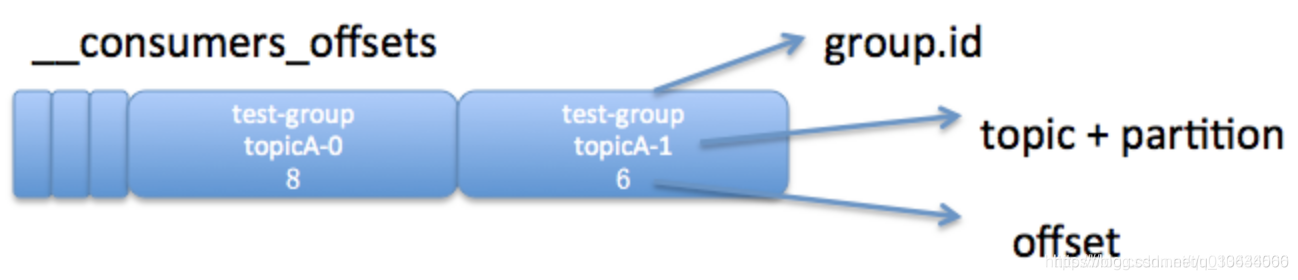
Kafka详解
目录 一、消息系统 1、点对点的消息系统 2、发布-订阅消息系统 二、Apache Kafka 简介 三、Apache Kafka基本原理 3.1 分布式和分区(distributed、partitioned) 3.2 副本(replicated ) 3.3 整体数据流程 3.4 消息传送机制…...

rabbitmq+springboot实现幂等性操作
文章目录 1.场景描述 1.1 场景11.2 场景2 2.原理3.实战开发 3.1 建表3.2 集成mybatis-plus3.3 集成RabbitMq 3.3.1 安装mq3.3.2 springBoot集成mq 3.4 具体实现 3.4.1 mq配置类3.4.2 生产者3.4.3 消费者 1.场景描述 消息中间件是分布式系统常用的组件,无论是异…...
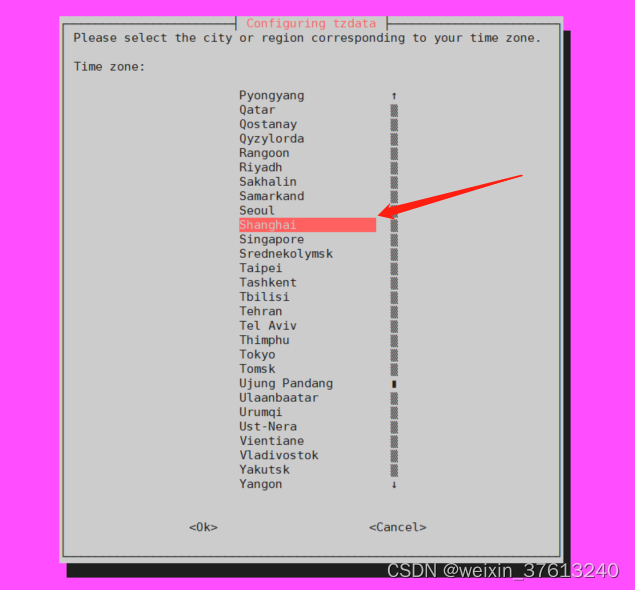
ubuntu server 更改时区:上海
1. 打开终端,在命令行中以超级用户或具有sudo权限的用户身份运行以下命令: sudo dpkg-reconfigure tzdata 这会打开一个对话框,用于选择系统的时区设置。 2. 在对话框中,使用上下箭头键在地区列表中选择"Asia"&#x…...

java 整合 swagger-ui 步骤
1.在xml 中添加Swagger 相关依赖 <!-- springfox-swagger2 --><dependency><groupId>io.springfox</groupId><artifactId>springfox-swagger2</artifactId><version>2.9.2</version></dependency><!-- springfox-swa…...

介绍两款生成神经网络架构示意图的工具:NN-SVG和PlotNeuralNet
对于神经网络架构的可视化是很有意义的,可以在很大程度上帮助到我们清晰直观地了解到整个架构,我们在前面的 PyTorch的ONNX结合MNIST手写数字数据集的应用(.pth和.onnx的转换与onnx运行时) 有介绍,可以将模型架构文件(常见的格式都可以)在线上…...

告别STM32cubeIDE的路径红波浪线:VSCode配置C/C++插件的保姆级指南
告别STM32cubeIDE的路径红波浪线:VSCode配置C/C插件的保姆级指南 对于习惯了STM32cubeIDE的嵌入式开发者来说,第一次用VSCode打开工程时,满屏的红色波浪线可能会让人瞬间崩溃。别担心,这不是你的代码有问题,而是VSCode…...

MimicFlow:可视化AI代码生成过程,弥合编程信任鸿沟
1. 项目概述:当AI写代码时,我们如何“看见”思考过程?如果你和我一样,深度使用过Cursor、GitHub Copilot或者任何基于大语言模型的AI编程助手,一定经历过这样的瞬间:你提出一个需求,AI助手瞬间生…...

Flutter 告别 Rosetta:揭秘 iOS 工具链原生适配 M 芯片的“折腾”史
如果你是 macOS 用户,一定对 Apple Silicon(M1/M2/M3)的性能赞不绝口。但在光鲜的背后,很多底层开发工具其实一直在靠 Rosetta 2 偷偷「苟延残喘」。今天,我们通过复盘近期 Flutter 官方的一个核心 PR,来看…...

Mac上如何用DistroAV插件实现无线多机位直播:NDI技术完整指南
Mac上如何用DistroAV插件实现无线多机位直播:NDI技术完整指南 【免费下载链接】obs-ndi DistroAV (formerly OBS-NDI): NDI integration for OBS Studio 项目地址: https://gitcode.com/gh_mirrors/ob/obs-ndi 还在为Mac上的OBS直播设置烦恼吗?想…...

电力系统网络安全:从风险认知到威胁建模的实战指南
1. 从日常运维到风险认知:重新审视大容量电力系统的安全基线在能源行业干了十几年,我见过太多同行把大容量电力系统(Bulk Energy System, BES)的运维简化为“确保别停电”。日常的告警处理、设备巡检、工单流转构成了工作的全部叙…...

移动通信浪潮如何重塑半导体产业格局:从高通与英特尔市值对比说起
1. 从市场估值看产业浪潮:移动通信如何重塑半导体格局2013年春天,一则消息在半导体和投资圈内引发了不小的震动:无线通信芯片巨头高通(Qualcomm)的市值,悄然与行业传统霸主英特尔(Intel…...

Linux调试利器:用addr2line精准定位程序崩溃现场
1. 当程序崩溃时,我们该如何快速定位问题? 作为一名长期奋战在Linux开发一线的程序员,我最头疼的就是遇到程序突然崩溃的情况。那种看着终端输出"Segmentation fault (core dumped)"却无从下手的无力感,相信很多开发者都…...

服务器运维与DevOps融合:迈向智能化运维的新纪元
在数字化浪潮席卷全球的今天,企业对IT基础设施的依赖程度日益加深,服务器运维作为支撑业务连续性和系统稳定性的核心环节,正面临前所未有的挑战与机遇。传统运维模式依赖人工干预、响应滞后、效率低下,已难以满足现代业务快速迭代…...

SAP ABAP开发必看:FOR ALL ENTRIES性能翻倍的隐藏参数rsdb/max_blocking_factor实战调优
SAP ABAP性能调优实战:FOR ALL ENTRIES参数优化全解析 当你在ABAP开发中处理百万级数据时,是否遇到过这样的场景:明明使用了FOR ALL ENTRIES语句,程序却像蜗牛一样缓慢?这背后隐藏着一个关键参数——rsdb/max_blocking…...

碧蓝航线Perseus补丁:零偏移设计实现全皮肤解锁的终极指南
碧蓝航线Perseus补丁:零偏移设计实现全皮肤解锁的终极指南 【免费下载链接】Perseus Azur Lane scripts patcher. 项目地址: https://gitcode.com/gh_mirrors/pers/Perseus 在碧蓝航线这款广受欢迎的海战游戏中,玩家们常常为那些精美的限定皮肤只…...