hive解决了什么问题
hive出现的原因
Hive 出现的原因主要有以下几个:
- 传统数据仓库无法处理大规模数据:传统的数据仓库通常采用关系型数据库作为底层存储,这种数据库在处理大规模数据时效率较低。
- MapReduce 难以使用:MapReduce 是一种分布式计算框架,它可以用于处理大规模数据,但 MapReduce 的编程模型比较复杂,难以使用。
- 需要一种统一的查询接口:传统的数据仓库和 MapReduce 都提供了数据查询的接口,但这些接口相互独立,难以统一管理。
为了解决这些问题,Facebook 在 2008 年开发了 Hive,Hive 是一种基于 Hadoop 的分布式数据仓库管理系统,它提供了一种 SQL 语法来访问存储在 Hadoop 分布式文件系统 (HDFS) 中的数据。Hive 的出现,解决了传统数据仓库无法处理大规模数据的问题,也简化了 MapReduce 的使用,并提供了一种统一的查询接口。
Hive 的出现,对大数据处理产生了重大影响,它使大数据处理变得更加简单、高效、可扩展。
hive执行过程
- 编写 Hive SQL 程序:首先,需要编写 Hive SQL 程序,这个程序可以通过 Hive CLI、Hive WebUI 等工具进行编写。Hive SQL 程序可以包含各种数据查询语句,例如 select、insert、update、delete 等。
- 提交 Hive SQL 程序:编写完成后,需要将 Hive SQL 程序提交到 Hive 服务器。Hive 服务器会根据 Hive SQL 程序的语法和逻辑进行解析,并生成 MapReduce 任务。
- 执行 MapReduce 任务:MapReduce 任务会将 Hive SQL 程序中的查询语句转换为 Map 和 Reduce 任务。Map 任务会将数据分割成小块,并将数据进行预处理。Reduce 任务会将 Map 任务的输出结果进行合并和聚合。
- 生成查询结果:MapReduce 任务完成后,Hive 服务器会将查询结果生成到 HDFS 中。
- 从 HDFS 中取数:最后,可以通过 Hive CLI、Hive WebUI 等工具从 HDFS 中取出查询结果。
具体来说,Hive SQL 程序的执行过程如下:
- SqlParser 将 Hive SQL 程序解析为 AST(抽象语法树)
- SemanticAnalyzer 对 AST 进行语义分析
- Optimizer 对 AST 进行优化
- Planner 生成执行计划
- Driver 将执行计划发送到 MapReduce 框架
- MapReduce 框架启动 Map 和 Reduce 任务
- Map 和 Reduce 任务生成查询结果
- Hive 服务器将查询结果写入 HDFS
- 用户从 HDFS 中取出查询结果
这个过程可以分为两个阶段:
- Hive SQL 解析和执行阶段:这个阶段是 Hive SQL 程序执行的核心阶段,包括 Hive SQL 程序的解析、优化、计划、执行等过程。
- HDFS 写入和读取阶段:这个阶段是将查询结果写入 HDFS 以及从 HDFS 中取出查询结果的过程。
需要注意的是,Hive SQL 程序的执行过程可以根据 Hive 服务器的配置进行调整。例如,可以通过配置 Hive 的参数来控制 MapReduce 任务的数量和并行度。
hive服务器包含哪些部分
HiveServer2
HiveServer2 是 Hive 的服务器端,它负责接收用户的 Hive SQL 请求,并将这些请求转换为 MapReduce 任务
HiveServer2 的转换步骤如下:
- 解析阶段:HiveServer2 会使用 ANTLR 解析器来解析 Hive SQL 请求,生成抽象语法树 (AST)。AST 是 Hive SQL 请求的结构化表示,它包含了 Hive SQL 请求的语法信息。
- 语义分析阶段:HiveServer2 会使用 SemanticAnalyzer 来对 AST 进行语义分析,检查 Hive SQL 请求的语义是否正确。语义分析会检查 Hive SQL 请求中的变量、常量、表达式等是否正确,以及 Hive SQL 请求是否符合 Hive 的语义规则。
- 优化阶段:HiveServer2 会使用 Optimizer 来对 AST 进行优化,提高 Hive SQL 请求的执行效率。优化会根据 Hive SQL 请求的语义和数据分布情况,生成最优的执行计划。
- 生成执行计划阶段:HiveServer2 会使用 Planner 来生成执行计划。执行计划是 Hive SQL 请求的执行指南,它包含了 MapReduce 任务的数量、分区、输入输出等信息。
- 执行阶段:HiveServer2 会将执行计划发送到 MapReduce 框架,由 MapReduce 框架执行 Hive SQL 请求。MapReduce 框架会将 Hive SQL 请求拆分为多个 Map 和 Reduce 任务,并在多个节点上并行执行。
Hive Metastore
Hive Metastore 是 Hive 的元数据存储,它存储了 Hive 数据库、表、列、分区等元数据信息
Hive Metastore 使用 MySQL 存储元数据,提供以下优点:
可扩展性:MySQL 是一个可扩展的数据库,可以支持大量的并发连接。
可靠性:MySQL 支持 ACID 事务,保证了数据的一致性和完整性。
性能:MySQL 是一个高性能的数据库,可以满足 Hive 的性能需求。
性能优化
要尽可能减少生成的 MapReduce 任务量,在编写 HiveSQL 时应该注意以下几点:
- 尽量使用 join 而不是 union。 union 操作会导致两个表的数据分别作为 MapReduce 任务的输入,而 join 操作只会生成一个 MapReduce 任务。
- 尽量使用 where 子句来过滤数据。 where 子句可以过滤掉不需要的数据,减少 MapReduce 任务处理的数据量。
- **尽量使用分区表。**分区表可以将数据分布到多个文件中,减少 MapReduce 任务之间的数据 shuffle 量。
- 使用 coalesce 函数合并小文件。 coalesce 函数可以将多个小文件合并为一个大文件,减少 MapReduce 任务之间的数据 shuffle 量。
- 使用 mapjoin 操作。 mapjoin 操作可以将 Map 任务和 Reduce 任务合并为一个任务,减少 MapReduce 任务的数量。
以下是一些具体的示例:
- 使用 join 而不是 union:
# 使用 union,生成两个 MapReduce 任务
select * from table1 union all select * from table2;# 使用 join,生成一个 MapReduce 任务
select * from table1 join table2 on table1.id = table2.id;
- 使用 where 子句来过滤数据:
# 不使用 where 子句,生成一个 MapReduce 任务
select * from table1;# 使用 where 子句,生成一个 MapReduce 任务
select * from table1 where id = 1;
- 使用分区表:
# 使用不分区表,生成一个 MapReduce 任务
select * from table1;# 使用分区表,生成多个 MapReduce 任务
select * from table1 partition(d1, d2, d3);
- 使用 coalesce 函数合并小文件:
# 不使用 coalesce 函数,生成多个 MapReduce 任务
select * from table1;# 使用 coalesce 函数,生成一个 MapReduce 任务
select * from table1 coalesce(1000);
- 使用 mapjoin 操作:
# 不使用 mapjoin 操作,生成两个 MapReduce 任务
select * from table1 join table2 on table1.id = table2.id;# 使用 mapjoin 操作,生成一个 MapReduce 任务
select * from table1 mapjoin table2 on table1.id = table2.id;
总结
也就是说,hive sql通过将sql转换成map reduce任务,使得开发人员可以通过编写sql来替代写map reduce代码,由于sql是通用的,很多数据分析人员都有此技术栈,相对写map reduce代码要容易上手很多。对于同样一个取数需求,hive sql编写方式的不同,会导致Map Reduce任务的创建量不同,所以尽可能编写少的Map Reduce的任务的SQL也是性能优化需要关注的点。
相关文章:

hive解决了什么问题
hive出现的原因 Hive 出现的原因主要有以下几个: 传统数据仓库无法处理大规模数据:传统的数据仓库通常采用关系型数据库作为底层存储,这种数据库在处理大规模数据时效率较低。MapReduce 难以使用:MapReduce 是一种分布式计算框架…...

Lumion 和 Enscape 应该选择怎样的笔记本电脑?
Lumion 和 Enscape实时渲染对配置要求高,本地配置不够,如何快速解决: 本地普通电脑可一键申请高性能工作站,资产安全保障,供软件中心,各种软件插件一键获取,且即开即用,使用灵活&am…...
ICCV 2023 | MoCoDAD:一种基于人体骨架的运动条件扩散模型,实现高效视频异常检测
论文链接: https://arxiv.org/abs/2307.07205 视频异常检测(Video Anomaly Detection,VAD)扩展自经典的异常检测任务,由于异常情况样本非常少见,因此经典的异常检测通常被定义为一类分类问题(On…...
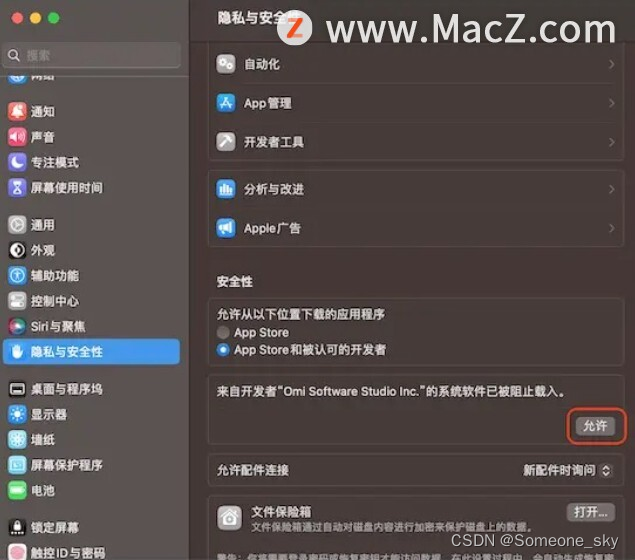
Mac电脑怎么使用NTFS磁盘管理器 NTFS磁盘详细使用教程
Mac是可以识别NTFS硬盘的,但是macOS系统虽然能够正确识别NTFS硬盘,但只支持读取,不支持写入。换句话说,Mac不支持对NTFS硬盘进行编辑、创建、删除等写入操作,比如将Mac里的文件拖入NTFS硬盘,在NTFS硬盘里新…...
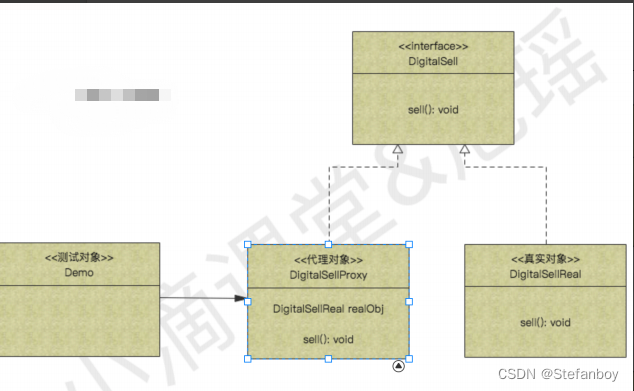
Java设计模式-结构性设计模式(代理设计模式)
简介 为其他对象提供⼀种代理以控制对这个对象的访问,属于结构型模式。客户端并不直接调⽤实际的对象,⽽是通过调⽤代理,来间接的调⽤实际的对象应用场景 各⼤数码专营店,代理⼚商进⾏销售对应的产品,代理商持有真正的…...

线性空间、子空间、基、基坐标、过渡矩阵
线性空间的定义 满足加法和数乘封闭。也就是该空间的所有向量都满足乘一个常数后或者和其它向量相加后仍然在这个空间里。进一步可以理解为该空间中的所有向量满足加法和数乘的组合封闭。即若 V 是一个线性空间,则首先需满足: 注:线性空间里面…...
【MySQL】CRUD (增删改查) 基础
CRUD(增删改查)基础 一. CRUD二. 新增 (Create)1. 单行数据 全列插入2. 多行数据 指定列插入 三. 查询(Retrieve)1. 全列查询2. 指定列查询3. 查询字段为表达式4. 别名5. 去重:DISTINCT6. 排序…...

Socks5代理IP:保障跨境电商的网络安全
在数字化时代,跨境电商已成为全球商业的重要一环。然而,随着其发展壮大,网络安全问题也逐渐浮出水面。为了确保跨境电商的安全和隐私,Socks5代理IP技术成为了一项不可或缺的工具。本文将深入探讨Socks5代理IP在跨境电商中的应用&a…...
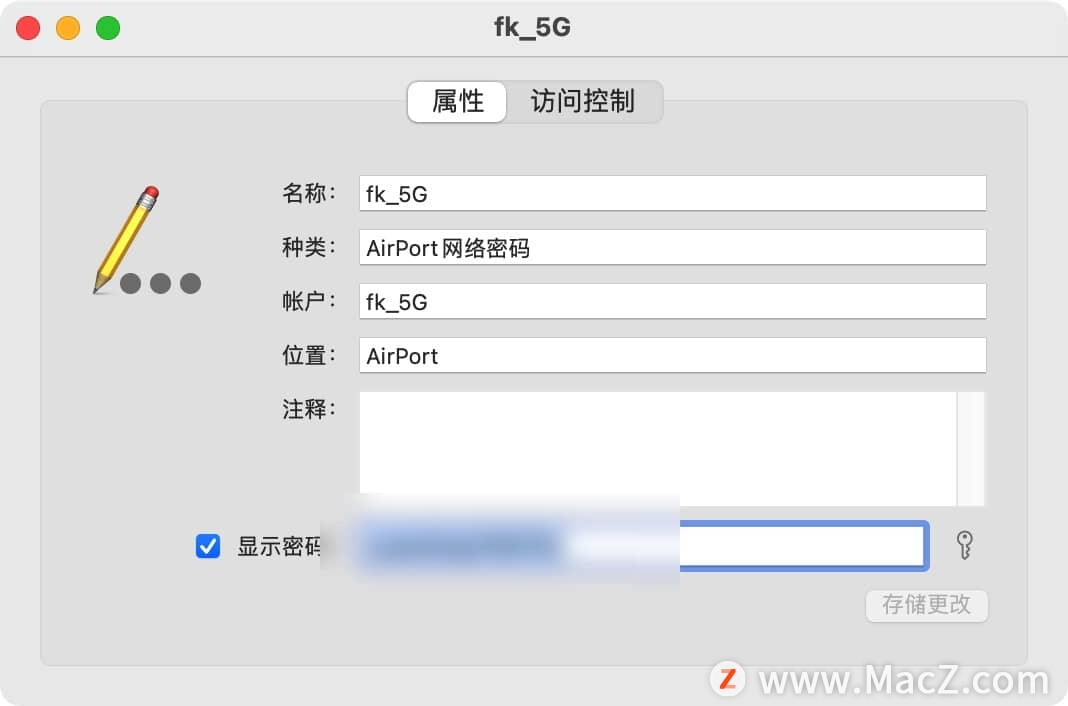
macOS通过钥匙串访问找回WiFi密码
如果您忘记了Mac电脑上的WiFi密码,可以通过钥匙串访问来找回它。具体步骤如下: 1.打开Mac电脑的“启动台”,然后在其他文件中找到“钥匙串访问”。 2.运行“钥匙串访问”应用程序,点击左侧的“系统”,然后在右侧找到…...
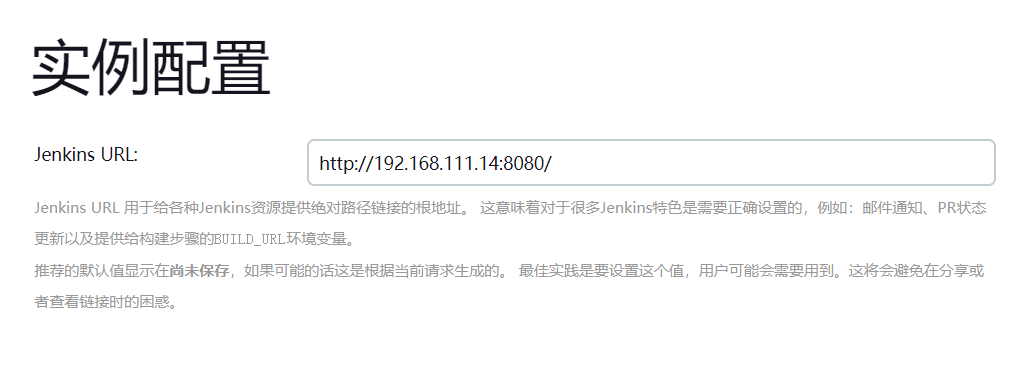
Debian11之稳定版本Jenkins安装
官方网址 系统要求 机器要求 256 MB 内存,建议大于 512 MB 10 GB 的硬盘空间(用于 Jenkins 和 Docker 镜像)软件要求 Java 8 ( JRE 或者 JDK 都可以) Docker (导航到网站顶部的Get Docker链接以访问适合您平台的Docker下载安装…...

kakfa 3.5 kafka服务端处理消费者客户端拉取数据请求源码
一、服务端接收消费者拉取数据的方法二、遍历请求中需要拉取数据的主题分区集合,分别执行查询数据操作,1、会选择合适的副本读取本地日志数据(2.4版本后支持主题分区多副本下的读写分离) 三、会判断当前请求是主题分区Follower发送的拉取数据请求还是消费…...

【Linux】进程概念I --操作系统概念与冯诺依曼体系结构
Halo,这里是Ppeua。平时主要更新C语言,C,数据结构算法…感兴趣就关注我吧!你定不会失望。 本篇导航 1. 冯诺依曼体系结构为什么这样设计? 2. 操作系统概念为什么我们需要操作系统呢?操作系统怎么进行管理? 计算机是由两部分组…...
BRAM/URAM资源介绍
BRAM/URAM资源简介 Bram和URAM都是FPGA(现场可编程门阵列)中的RAM资源。 Bram是Block RAM的缩写,是Xilinx FPGA中常见的RAM资源之一,也是最常用的资源之一。它是一种单独的RAM模块,通常用于存储大量的数据࿰…...

分享一个基于python的个性推荐餐厅系统源码 餐厅管理系统代码
💕💕作者:计算机源码社 💕💕个人简介:本人七年开发经验,擅长Java、Python、PHP、.NET、Node.js、微信小程序、爬虫、大数据等,大家有这一块的问题可以一起交流! …...

Mysql5.7开启SSL认证且支持Springboot客户端验证
Mysql5.7开启SSL认证 一、查看服务端mysql环境 1.查看是否开启了ssl,"have_ssl" 为YES的时候,数据库是开启加密连接方式的。 show global variables like %ssl%;2.查看数据库版本 select version();3.查看数据库端口 show variables like port;4.查看数据库存放…...

微信小程序的页面滚动事件监听
微信小程序中可以通过 Page 的 onPageScroll 方法来监听页面滚动事件。具体步骤如下: 在页面的 onLoad 方法中注册页面滚动事件监听器: Page({onLoad: function () {wx.pageScrollTo({scrollTop: 0,duration: 0});wx.showLoading({title: 加载中,});wx…...

数据可视化:四大发明的现代转化引擎
在科技和工业的蓬勃发展中,中国的四大发明——造纸术、印刷术、火药和指南针,早已不再是古代创新的象征,而是催生了众多衍生行业的崭新可能性。其中,数据可视化技术正成为这些行业的一颗璀璨明珠,开启了全新的时代。 1…...

HarmonyOS实现几种常见图片点击效果
一. 样例介绍 HarmonyOS提供了常用的图片、图片帧动画播放器组件,开发者可以根据实际场景和开发需求,实现不同的界面交互效果,包括:点击阴影效果、点击切换状态、点击动画效果、点击切换动效。 相关概念 image组件:图片…...
)
3D视觉测量:计算两个平面之间的夹角(附源码)
文章目录 1. 基本内容2. 代码实现文章目录:形位公差测量关键内容:通过视觉方法实现平面之间夹角的计算1. 基本内容 要计算两个平面之间的夹角,首先需要知道这两个平面的法向量。假设有两个平面,它们的法向量分别为 N 1 和 N 2 N_1 和 N_2...
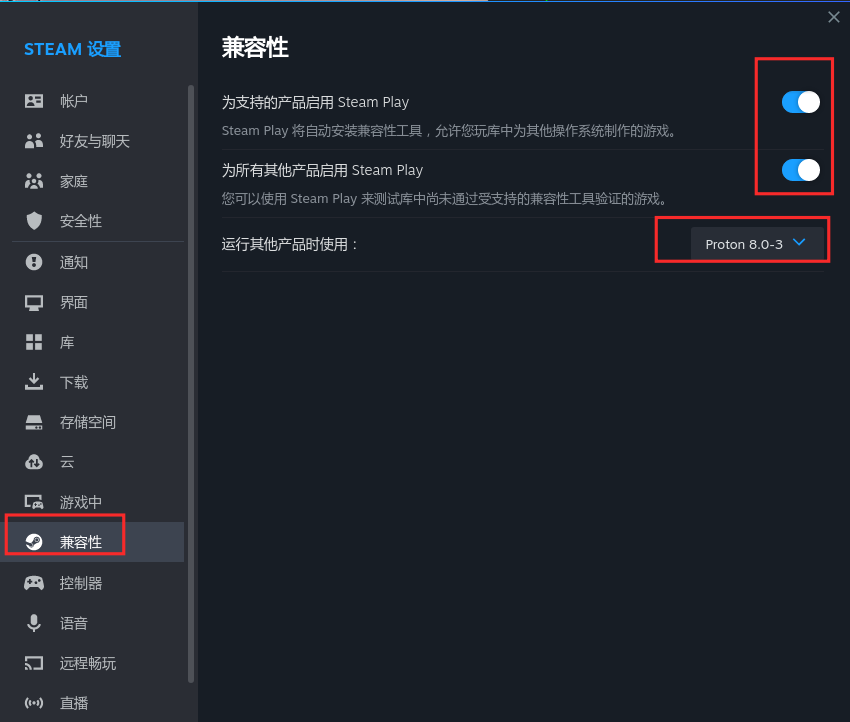
deepin V23通过flathub安装steam畅玩游戏
deepin V23缺少32位库,在星火商店安装的steam,打开报错,无法使用! 通过flathub网站安装steam,可以正常使用,详细教程如下: flathub网址:主页 | Flathub 注意:flathub下载速度慢,只…...

从玩具到生产:基于run-llama/rags构建模块化RAG系统的工程实践
1. 项目概述:从“玩具”到“生产力”的RAG系统构建如果你最近在关注大语言模型的应用落地,那么“RAG”这个词一定高频出现在你的视野里。RAG,即检索增强生成,它试图解决大模型“一本正经胡说八道”和“知识陈旧”两大核心痛点。简…...

gogoclaw:基于文件与技能的自主智能体运行时设计与实践
1. 项目概述:一个以文件为基石的自主智能体运行时如果你和我一样,对市面上那些“黑盒”式的AI智能体框架感到厌倦,总觉得它们把太多逻辑和状态藏在运行时深处,调试和扩展起来像在拆盲盒,那么gogoclaw这个项目可能会让你…...

Vivado 伪双口RAM IP核的配置精髓与实战避坑指南
1. 伪双口RAM的本质与真双口RAM的差异 第一次接触伪双口RAM(Simple Dual Port RAM)时,很多人会疑惑它和真双口RAM(True Dual Port RAM)到底有什么区别。这个问题困扰了我很久,直到在实际项目中踩了几个坑才…...

2026 流量卡办理全攻略:从下单、激活到售后,新手一遍看懂不踩坑
现在人人都离不开手机流量,不管是日常刷视频、追剧观影,还是备用机上网冲浪,一张划算又正规的通用流量卡,已经成为大众刚需。但很多新手第一次在线办理优惠号卡,普遍一头雾水:分不清流量卡是否正规靠谱、办…...

从CMake报错到编译成功:一站式解决absl依赖配置难题
1. 当CMake突然报错:absl依赖缺失的紧急处理 第一次看到这个报错时,我正赶着在截止日期前完成gRPC服务的部署。控制台突然弹出的红色错误让我心头一紧:"Could not find a package configuration file provided by absl"。这种依赖缺…...

AI Agent自动化修复GitHub Issue:从问题定位到PR提交全流程解析
1. 项目概述:一个能自动修复GitHub Issue并提交PR的AI技能 最近在折腾AI编程助手的时候,发现了一个挺有意思的东西,叫 issue-to-pr 。简单来说,这玩意儿是一个AI Agent的“技能包”,你把它装在你的AI编程工具&#…...

MarkdownReader:重构浏览器文档阅读体验的渐进式渲染引擎
MarkdownReader:重构浏览器文档阅读体验的渐进式渲染引擎 【免费下载链接】markdownReader markdownReader is a extention for chrome, used for reading markdown file. 项目地址: https://gitcode.com/gh_mirrors/ma/markdownReader 在当今技术文档创作与…...
)
保姆级教程:手把手教你下载、解压与解析ILSVRC2015 VID数据集(附Python脚本)
计算机视觉实战:ILSVRC2015 VID数据集处理全流程指南 当你第一次打开ILSVRC2015 VID数据集时,可能会被它的规模吓到——超过100万张图像、数千个视频序列和复杂的XML标注结构。这份指南将带你从零开始,像处理日常项目一样轻松驾驭这个庞然大…...

Windows 11终极优化指南:一键清理系统臃肿,免费提升51%性能
Windows 11终极优化指南:一键清理系统臃肿,免费提升51%性能 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to …...

Linux桌面便签神器Sticky:3分钟告别灵感遗忘的终极解决方案
Linux桌面便签神器Sticky:3分钟告别灵感遗忘的终极解决方案 【免费下载链接】sticky A sticky notes app for the linux desktop 项目地址: https://gitcode.com/gh_mirrors/stic/sticky 你是否曾经有过这样的经历?在编码时突然想到一个绝妙的算法…...