HashMap(JDK1.8)源码+底层数据结构分析
- HashMap 简介
- 底层数据结构分析
- JDK1.8 之前
- JDK1.8 之后
- HashMap 源码分析
- 构造方法
- put 方法
- get 方法
- resize 方法
- HashMap 常用方法测试
感谢 changfubai 对本文的改进做出的贡献!
HashMap 简介
HashMap 主要用来存放键值对,它基于哈希表的 Map 接口实现,是常用的 Java 集合之一。
JDK1.8 之前 HashMap 由 数组+链表 组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。
JDK1.8 之后 HashMap 的组成多了红黑树,在满足下面两个条件之后,会执行链表转红黑树操作,以此来加快搜索速度。
- 链表长度大于阈值(默认为 8)
- HashMap 数组长度超过 64
底层数据结构分析
JDK1.8 之前
JDK1.8 之前 HashMap 底层是 数组和链表 结合在一起使用也就是 链表散列。
HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。
所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。
JDK 1.8 HashMap 的 hash 方法源码:
JDK 1.8 的 hash 方法 相比于 JDK 1.7 hash 方法更加简化,但是原理不变。
static final int hash(Object key) {int h;// key.hashCode():返回散列值也就是hashcode// ^ :按位异或// >>>:无符号右移,忽略符号位,空位都以0补齐return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}
对比一下 JDK1.7 的 HashMap 的 hash 方法源码.
static int hash(int h) {// This function ensures that hashCodes that differ only by// constant multiples at each bit position have a bounded// number of collisions (approximately 8 at default load factor).h ^= (h >>> 20) ^ (h >>> 12);return h ^ (h >>> 7) ^ (h >>> 4);
}
相比于 JDK1.8 的 hash 方法 ,JDK 1.7 的 hash 方法的性能会稍差一点点,因为毕竟扰动了 4 次。
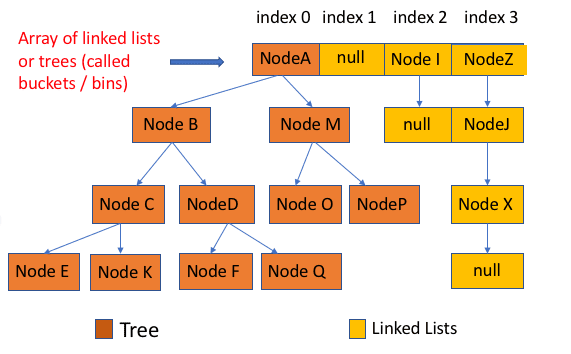
所谓 “拉链法” 就是:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cwUL252F-1677050195849)(https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-7/jdk1.8之前的内部结构.png)]
JDK1.8 之后
相比于之前的版本,JDK1.8 以后在解决哈希冲突时有了较大的变化。
当链表长度大于阈值(默认为 8)时,会首先调用 treeifyBin()方法。这个方法会根据 HashMap 数组来决定是否转换为红黑树。只有当数组长度大于或者等于 64 的情况下,才会执行转换红黑树操作,以减少搜索时间。否则,就是只是执行 resize() 方法对数组扩容。相关源码这里就不贴了,重点关注 treeifyBin()方法即可!
类的属性:
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {// 序列号private static final long serialVersionUID = 362498820763181265L;// 默认的初始容量是16static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;// 最大容量static final int MAXIMUM_CAPACITY = 1 << 30;// 默认的填充因子static final float DEFAULT_LOAD_FACTOR = 0.75f;// 当桶(bucket)上的结点数大于这个值时会转成红黑树static final int TREEIFY_THRESHOLD = 8;// 当桶(bucket)上的结点数小于这个值时树转链表static final int UNTREEIFY_THRESHOLD = 6;// 桶中结构转化为红黑树对应的table的最小大小static final int MIN_TREEIFY_CAPACITY = 64;// 存储元素的数组,总是2的幂次倍transient Node<k,v>[] table;// 存放具体元素的集transient Set<map.entry<k,v>> entrySet;// 存放元素的个数,注意这个不等于数组的长度。transient int size;// 每次扩容和更改map结构的计数器transient int modCount;// 临界值 当实际大小(容量*填充因子)超过临界值时,会进行扩容int threshold;// 加载因子final float loadFactor;
}
-
loadFactor 加载因子
loadFactor 加载因子是控制数组存放数据的疏密程度,loadFactor 越趋近于 1,那么 数组中存放的数据(entry)也就越多,也就越密,也就是会让链表的长度增加,loadFactor 越小,也就是趋近于 0,数组中存放的数据(entry)也就越少,也就越稀疏。
loadFactor 太大导致查找元素效率低,太小导致数组的利用率低,存放的数据会很分散。loadFactor 的默认值为 0.75f 是官方给出的一个比较好的临界值。
给定的默认容量为 16,负载因子为 0.75。Map 在使用过程中不断的往里面存放数据,当数量达到了 16 * 0.75 = 12 就需要将当前 16 的容量进行扩容,而扩容这个过程涉及到 rehash、复制数据等操作,所以非常消耗性能。
-
threshold
threshold = capacity * loadFactor,当 Size>=threshold的时候,那么就要考虑对数组的扩增了,也就是说,这个的意思就是 衡量数组是否需要扩增的一个标准。
Node 节点类源码:
// 继承自 Map.Entry<K,V>
static class Node<K,V> implements Map.Entry<K,V> {final int hash;// 哈希值,存放元素到hashmap中时用来与其他元素hash值比较final K key;//键V value;//值// 指向下一个节点Node<K,V> next;Node(int hash, K key, V value, Node<K,V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;}public final K getKey() { return key; }public final V getValue() { return value; }public final String toString() { return key + "=" + value; }// 重写hashCode()方法public final int hashCode() {return Objects.hashCode(key) ^ Objects.hashCode(value);}public final V setValue(V newValue) {V oldValue = value;value = newValue;return oldValue;}// 重写 equals() 方法public final boolean equals(Object o) {if (o == this)return true;if (o instanceof Map.Entry) {Map.Entry<?,?> e = (Map.Entry<?,?>)o;if (Objects.equals(key, e.getKey()) &&Objects.equals(value, e.getValue()))return true;}return false;}
}
树节点类源码:
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {TreeNode<K,V> parent; // 父TreeNode<K,V> left; // 左TreeNode<K,V> right; // 右TreeNode<K,V> prev; // needed to unlink next upon deletionboolean red; // 判断颜色TreeNode(int hash, K key, V val, Node<K,V> next) {super(hash, key, val, next);}// 返回根节点final TreeNode<K,V> root() {for (TreeNode<K,V> r = this, p;;) {if ((p = r.parent) == null)return r;r = p;}
HashMap 源码分析
构造方法
HashMap 中有四个构造方法,它们分别如下:
// 默认构造函数。public HashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted}// 包含另一个“Map”的构造函数public HashMap(Map<? extends K, ? extends V> m) {this.loadFactor = DEFAULT_LOAD_FACTOR;putMapEntries(m, false);//下面会分析到这个方法}// 指定“容量大小”的构造函数public HashMap(int initialCapacity) {this(initialCapacity, DEFAULT_LOAD_FACTOR);}// 指定“容量大小”和“加载因子”的构造函数public HashMap(int initialCapacity, float loadFactor) {if (initialCapacity < 0)throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal load factor: " + loadFactor);this.loadFactor = loadFactor;this.threshold = tableSizeFor(initialCapacity);}
putMapEntries 方法:
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {int s = m.size();if (s > 0) {// 判断table是否已经初始化if (table == null) { // pre-size// 未初始化,s为m的实际元素个数float ft = ((float)s / loadFactor) + 1.0F;int t = ((ft < (float)MAXIMUM_CAPACITY) ?(int)ft : MAXIMUM_CAPACITY);// 计算得到的t大于阈值,则初始化阈值if (t > threshold)threshold = tableSizeFor(t);}// 已初始化,并且m元素个数大于阈值,进行扩容处理else if (s > threshold)resize();// 将m中的所有元素添加至HashMap中for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {K key = e.getKey();V value = e.getValue();putVal(hash(key), key, value, false, evict);}}
}
put 方法
HashMap 只提供了 put 用于添加元素,putVal 方法只是给 put 方法调用的一个方法,并没有提供给用户使用。
对 putVal 方法添加元素的分析如下:
- 如果定位到的数组位置没有元素 就直接插入。
- 如果定位到的数组位置有元素就和要插入的 key 比较,如果 key 相同就直接覆盖,如果 key 不相同,就判断 p 是否是一个树节点,如果是就调用
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value)将元素添加进入。如果不是就遍历链表插入(插入的是链表尾部)。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Cxqqocoy-1677050195851)(https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-7/put方法.png)]
说明:上图有两个小问题:
- 直接覆盖之后应该就会 return,不会有后续操作。参考 JDK8 HashMap.java 658 行(issue#608)。
- 当链表长度大于阈值(默认为 8)并且 HashMap 数组长度超过 64 的时候才会执行链表转红黑树的操作,否则就只是对数组扩容。参考 HashMap 的
treeifyBin()方法(issue#1087)。
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);
}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;// table未初始化或者长度为0,进行扩容if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;// (n - 1) & hash 确定元素存放在哪个桶中,桶为空,新生成结点放入桶中(此时,这个结点是放在数组中)if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);// 桶中已经存在元素else {Node<K,V> e; K k;// 比较桶中第一个元素(数组中的结点)的hash值相等,key相等if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))// 将第一个元素赋值给e,用e来记录e = p;// hash值不相等,即key不相等;为红黑树结点else if (p instanceof TreeNode)// 放入树中e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);// 为链表结点else {// 在链表最末插入结点for (int binCount = 0; ; ++binCount) {// 到达链表的尾部if ((e = p.next) == null) {// 在尾部插入新结点p.next = newNode(hash, key, value, null);// 结点数量达到阈值(默认为 8 ),执行 treeifyBin 方法// 这个方法会根据 HashMap 数组来决定是否转换为红黑树。// 只有当数组长度大于或者等于 64 的情况下,才会执行转换红黑树操作,以减少搜索时间。否则,就是只是对数组扩容。if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);// 跳出循环break;}// 判断链表中结点的key值与插入的元素的key值是否相等if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))// 相等,跳出循环break;// 用于遍历桶中的链表,与前面的e = p.next组合,可以遍历链表p = e;}}// 表示在桶中找到key值、hash值与插入元素相等的结点if (e != null) {// 记录e的valueV oldValue = e.value;// onlyIfAbsent为false或者旧值为nullif (!onlyIfAbsent || oldValue == null)//用新值替换旧值e.value = value;// 访问后回调afterNodeAccess(e);// 返回旧值return oldValue;}}// 结构性修改++modCount;// 实际大小大于阈值则扩容if (++size > threshold)resize();// 插入后回调afterNodeInsertion(evict);return null;
}
我们再来对比一下 JDK1.7 put 方法的代码
对于 put 方法的分析如下:
- ① 如果定位到的数组位置没有元素 就直接插入。
- ② 如果定位到的数组位置有元素,遍历以这个元素为头结点的链表,依次和插入的 key 比较,如果 key 相同就直接覆盖,不同就采用头插法插入元素。
public V put(K key, V value)if (table == EMPTY_TABLE) {inflateTable(threshold);
}if (key == null)return putForNullKey(value);int hash = hash(key);int i = indexFor(hash, table.length);for (Entry<K,V> e = table[i]; e != null; e = e.next) { // 先遍历Object k;if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {V oldValue = e.value;e.value = value;e.recordAccess(this);return oldValue;}}modCount++;addEntry(hash, key, value, i); // 再插入return null;
}
get 方法
public V get(Object key) {Node<K,V> e;return (e = getNode(hash(key), key)) == null ? null : e.value;
}final Node<K,V> getNode(int hash, Object key) {Node<K,V>[] tab; Node<K,V> first, e; int n; K k;if ((tab = table) != null && (n = tab.length) > 0 &&(first = tab[(n - 1) & hash]) != null) {// 数组元素相等if (first.hash == hash && // always check first node((k = first.key) == key || (key != null && key.equals(k))))return first;// 桶中不止一个节点if ((e = first.next) != null) {// 在树中getif (first instanceof TreeNode)return ((TreeNode<K,V>)first).getTreeNode(hash, key);// 在链表中getdo {if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))return e;} while ((e = e.next) != null);}}return null;
}
resize 方法
进行扩容,会伴随着一次重新 hash 分配,并且会遍历 hash 表中所有的元素,是非常耗时的。在编写程序中,要尽量避免 resize。
final Node<K,V>[] resize() {Node<K,V>[] oldTab = table;int oldCap = (oldTab == null) ? 0 : oldTab.length;int oldThr = threshold;int newCap, newThr = 0;if (oldCap > 0) {// 超过最大值就不再扩充了,就只好随你碰撞去吧if (oldCap >= MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return oldTab;}// 没超过最大值,就扩充为原来的2倍else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY)newThr = oldThr << 1; // double threshold}else if (oldThr > 0) // initial capacity was placed in thresholdnewCap = oldThr;else {// signifies using defaultsnewCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}// 计算新的resize上限if (newThr == 0) {float ft = (float)newCap * loadFactor;newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE);}threshold = newThr;@SuppressWarnings({"rawtypes","unchecked"})Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];table = newTab;if (oldTab != null) {// 把每个bucket都移动到新的buckets中for (int j = 0; j < oldCap; ++j) {Node<K,V> e;if ((e = oldTab[j]) != null) {oldTab[j] = null;if (e.next == null)newTab[e.hash & (newCap - 1)] = e;else if (e instanceof TreeNode)((TreeNode<K,V>)e).split(this, newTab, j, oldCap);else {Node<K,V> loHead = null, loTail = null;Node<K,V> hiHead = null, hiTail = null;Node<K,V> next;do {next = e.next;// 原索引if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}// 原索引+oldCapelse {if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);// 原索引放到bucket里if (loTail != null) {loTail.next = null;newTab[j] = loHead;}// 原索引+oldCap放到bucket里if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}}return newTab;
}
HashMap 常用方法测试
package map;import java.util.Collection;
import java.util.HashMap;
import java.util.Set;public class HashMapDemo {public static void main(String[] args) {HashMap<String, String> map = new HashMap<String, String>();// 键不能重复,值可以重复map.put("san", "张三");map.put("si", "李四");map.put("wu", "王五");map.put("wang", "老王");map.put("wang", "老王2");// 老王被覆盖map.put("lao", "老王");System.out.println("-------直接输出hashmap:-------");System.out.println(map);/*** 遍历HashMap*/// 1.获取Map中的所有键System.out.println("-------foreach获取Map中所有的键:------");Set<String> keys = map.keySet();for (String key : keys) {System.out.print(key+" ");}System.out.println();//换行// 2.获取Map中所有值System.out.println("-------foreach获取Map中所有的值:------");Collection<String> values = map.values();for (String value : values) {System.out.print(value+" ");}System.out.println();//换行// 3.得到key的值的同时得到key所对应的值System.out.println("-------得到key的值的同时得到key所对应的值:-------");Set<String> keys2 = map.keySet();for (String key : keys2) {System.out.print(key + ":" + map.get(key)+" ");}/*** 如果既要遍历key又要value,那么建议这种方式,因为如果先获取keySet然后再执行map.get(key),map内部会执行两次遍历。* 一次是在获取keySet的时候,一次是在遍历所有key的时候。*/// 当我调用put(key,value)方法的时候,首先会把key和value封装到// Entry这个静态内部类对象中,把Entry对象再添加到数组中,所以我们想获取// map中的所有键值对,我们只要获取数组中的所有Entry对象,接下来// 调用Entry对象中的getKey()和getValue()方法就能获取键值对了Set<java.util.Map.Entry<String, String>> entrys = map.entrySet();for (java.util.Map.Entry<String, String> entry : entrys) {System.out.println(entry.getKey() + "--" + entry.getValue());}/*** HashMap其他常用方法*/System.out.println("after map.size():"+map.size());System.out.println("after map.isEmpty():"+map.isEmpty());System.out.println(map.remove("san"));System.out.println("after map.remove():"+map);System.out.println("after map.get(si):"+map.get("si"));System.out.println("after map.containsKey(si):"+map.containsKey("si"));System.out.println("after containsValue(李四):"+map.containsValue("李四"));System.out.println(map.replace("si", "李四2"));System.out.println("after map.replace(si, 李四2):"+map);}}相关文章:
HashMap(JDK1.8)源码+底层数据结构分析
HashMap 简介底层数据结构分析 JDK1.8 之前JDK1.8 之后 HashMap 源码分析 构造方法put 方法get 方法resize 方法 HashMap 常用方法测试 感谢 changfubai 对本文的改进做出的贡献! HashMap 简介 HashMap 主要用来存放键值对,它基于哈希表的 Map 接口实现…...
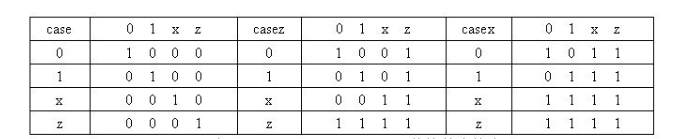
case的使用
1.x和z值 1.1.定义 x:表示不定值 z:表示高阻态,还有一种表达方式“?” 一个x/z可以用来定义十六进制(h)数的4位二进制的状态,八进制(o)数的3位,二进制&#x…...
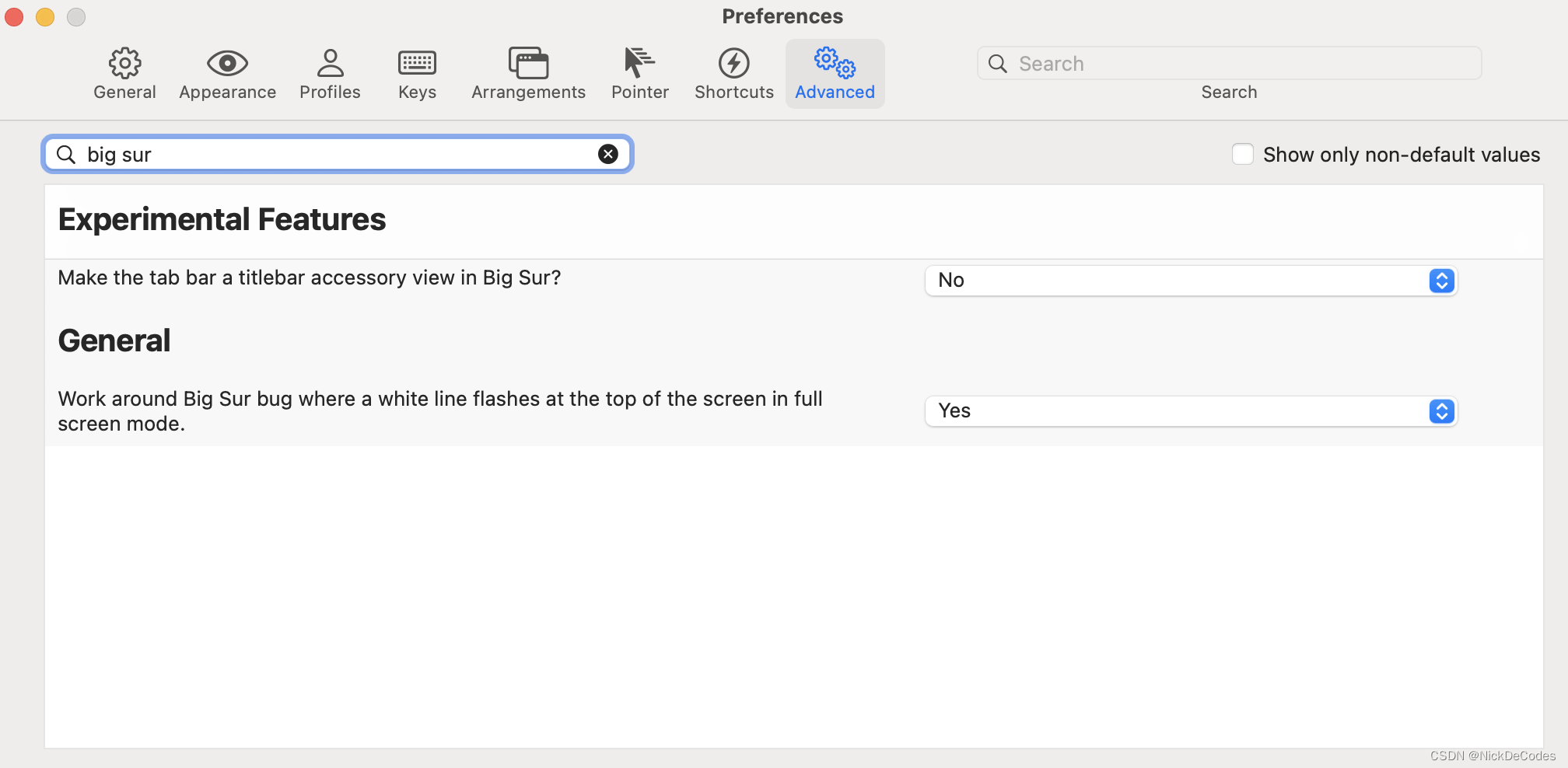
Mac配置ITerm2
Mac配置ITerm2 install-shell-integration配置lrzsz配置zsh安装Oh-My-Zsh修改皮肤文件加载皮肤添加插件配置profiles 1.expect配置文件2.shell脚本 iterm2顶部白条闪烁 install-shell-integration 安装完成之后会有一个指示标,需要弄掉Preferences > Profiles …...
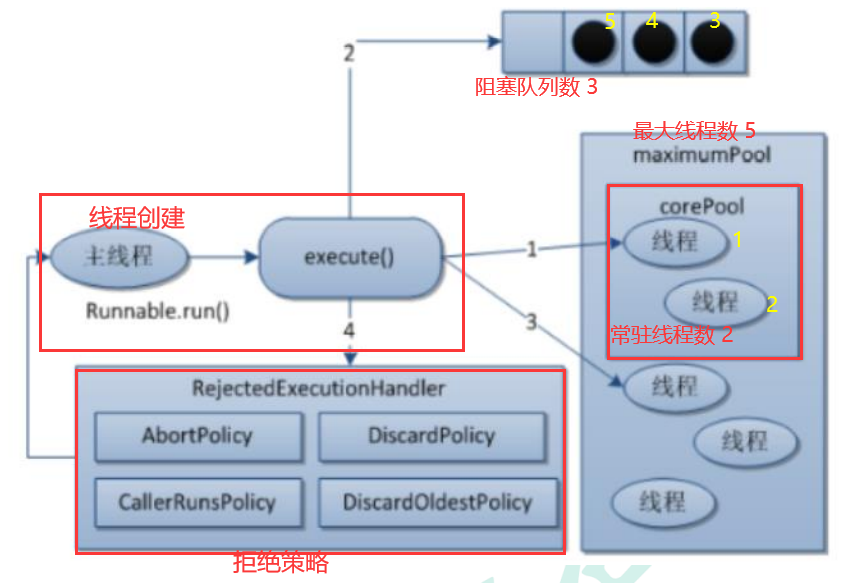
JUC并发编程(下)
✨作者:猫十二懿 ❤️🔥账号:CSDN 、掘金 、个人博客 、Github 🎉公众号:猫十二懿 学习地址 写在最前 JUC并发编程(上) JUC(Java Util Concurrent)学习内容框架&…...

API接口的基础知识
API是应用程序编程接口(Application Programming Interface)的缩写,能够起到两个软件组件之间的连接器或中介的作用。此类接口往往通过一组明确的协议,来表示各种原始的请求和响应。API文档可以向开发人员展示请求和响应是如何形成…...
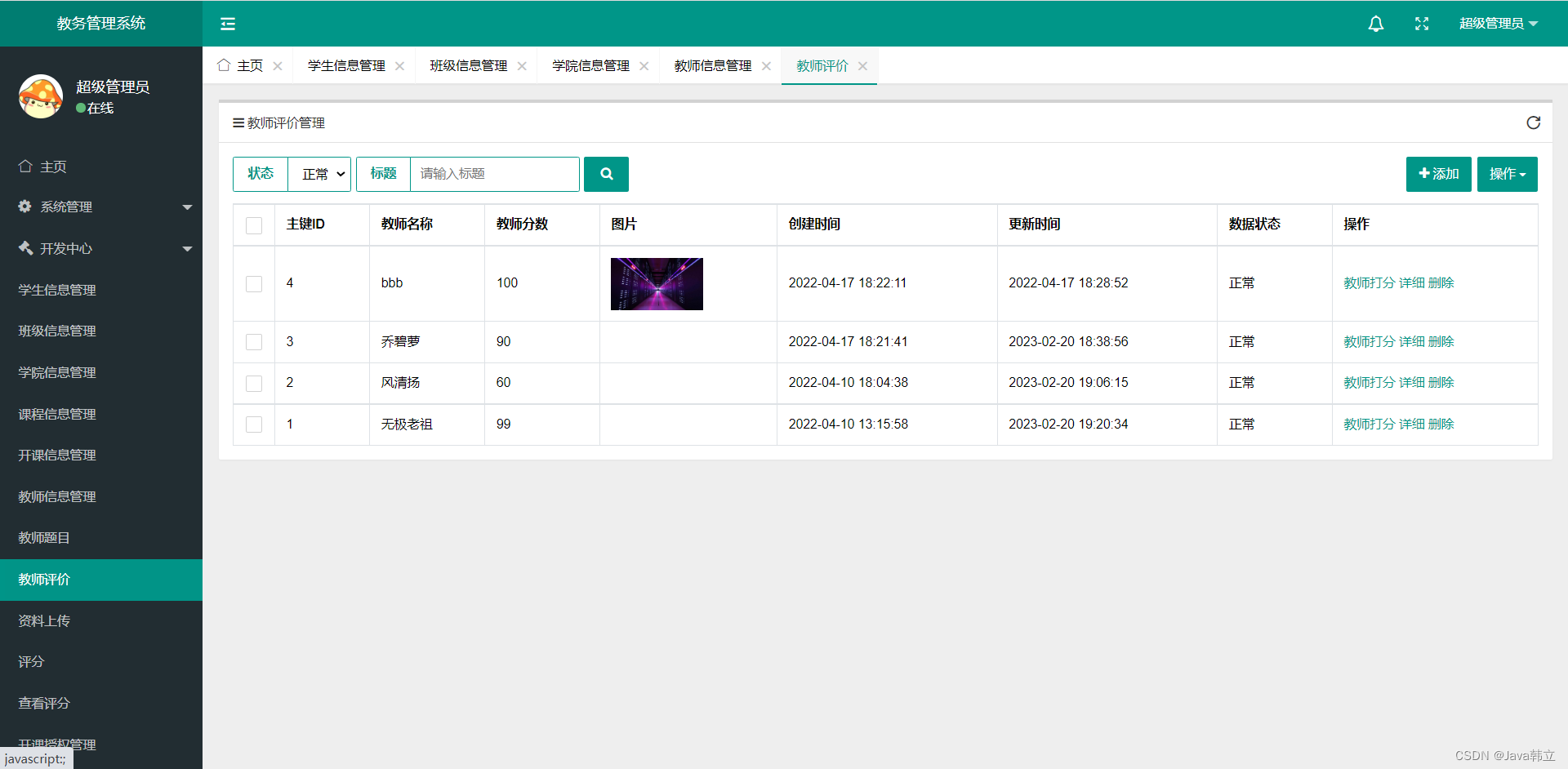
基于Spring Boot的教务管理系统
文章目录项目介绍主要功能截图:登录首页学生信息管理班级信息管理教师信息管理教师评价部分代码展示设计总结项目获取方式🍅 作者主页:Java韩立 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题…...
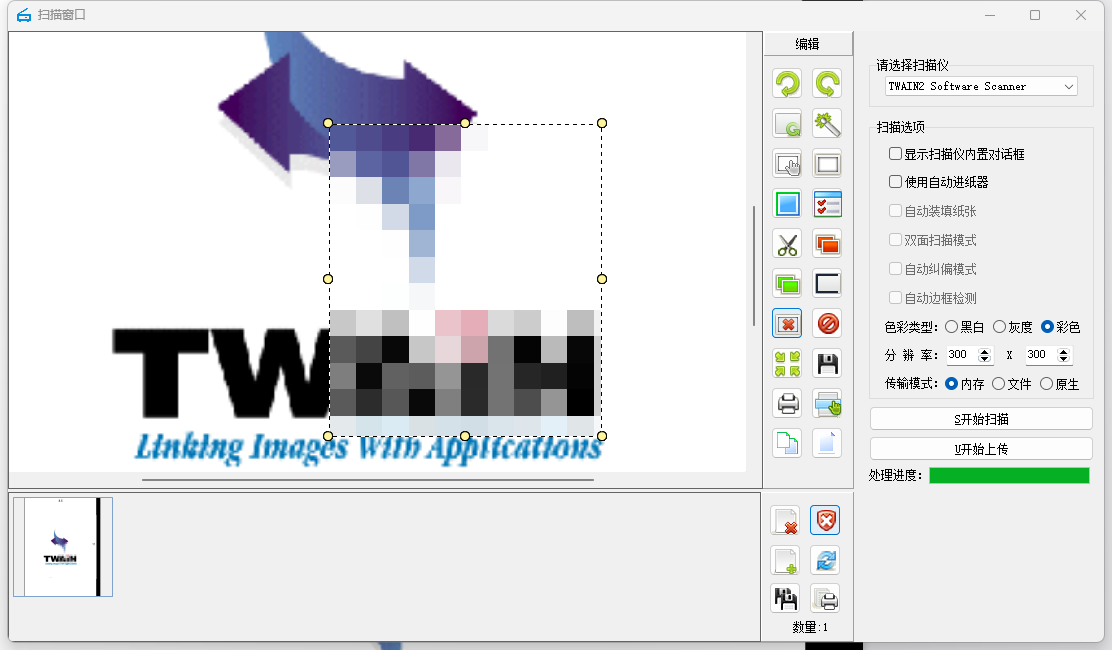
网页扫描图像并以pdf格式上传到服务器端
本文描述如何通过网页驱动扫描仪、高拍仪等图像扫描设备进行图像扫描,扫描结果经编辑修改后以pdf压缩格式上传到后台java程序中进行服务器端落盘保存。图像扫描上传如文字描述顺序所介绍,先要驱动扫描设备工作,进行纸张数据的光学扫描操作形成…...

Airbyte入门
Airbyte 后端技术栈Java 17框架:JerseyAPI: OAS3数据库:PostgreSQL单元和E2E测试:JUnit 5编排:Temporal连接器技术栈连接器可以用任何语言编写。但是,最常见的语言是:Python3.9.0Java 17前端技术…...
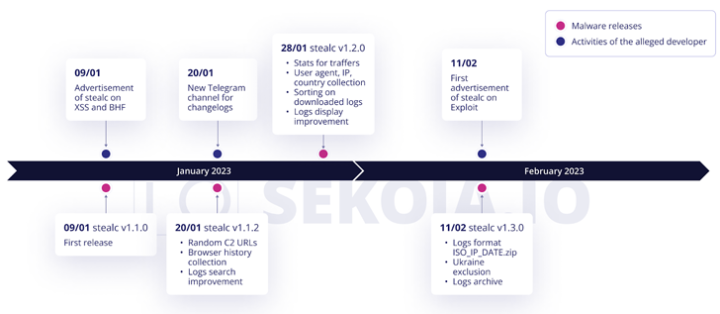
研究人员在野外发现大量的信息窃取者 “Stealc “的样本
一个名为Stealc的新信息窃取者正在暗网上做广告,它可能成为其他同类恶意软件的一个值得竞争的对象。 "SEKOIA在周一的一份报告中说:"威胁行为者将Stealc作为一个功能齐全、随时可用的窃取者,其开发依赖于Vidar、Raccoon、Mars和Re…...
数据结构——复杂度讲解(2)
作者:几冬雪来 时间:2023年2月22日 内容:数据结构复杂度讲解 目录 前言: 复杂度讲解(2): 1.空间复杂度是什么: 2.空间复杂度讲解: 结尾: 前言&#x…...
)
【LeetCode】任务调度器 [M](贪心)
621. 任务调度器 - 力扣(LeetCode) 一、题目 给你一个用字符数组 tasks 表示的 CPU 需要执行的任务列表。其中每个字母表示一种不同种类的任务。任务可以以任意顺序执行,并且每个任务都可以在 1 个单位时间内执行完。在任何一个单位时间&…...

Spring代理模式——静态代理和动态代理
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...

Anaconda和PyCharm的一些安装问题和命令
今天更新了Windows上的Anaconda到2.3.2,PyCharm到2022.3。 ——发现是纯纯的犯贱orz。出了一堆问题。在这里记录一下供后来者参考。 Anaconda安装 将.\anaconda3\Scripts 和.\anaconda3\Library\bin添加到系统环境变量中。 新建环境的目录在.\anaconda3\envs下 N…...

sql优化建议
对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。 应尽量避免在 where 子句中使用!或<>操作符,否则将引擎放弃使用索引而进行全表扫描。 应尽量避免在 where 子句中对字段进行 null 值判断&a…...

google hacker语句
哎,我就是沾边,就是不打实战( ̄o ̄) . z Z 文章目录前言一、什么是谷歌Docker?二、受欢迎的谷歌docker语句谷歌docker的例子日志文件易受攻击的 Web 服务器打开 FTP 服务器SSH私钥电子邮件列表实时摄像机MP3、电影和 PDF…...
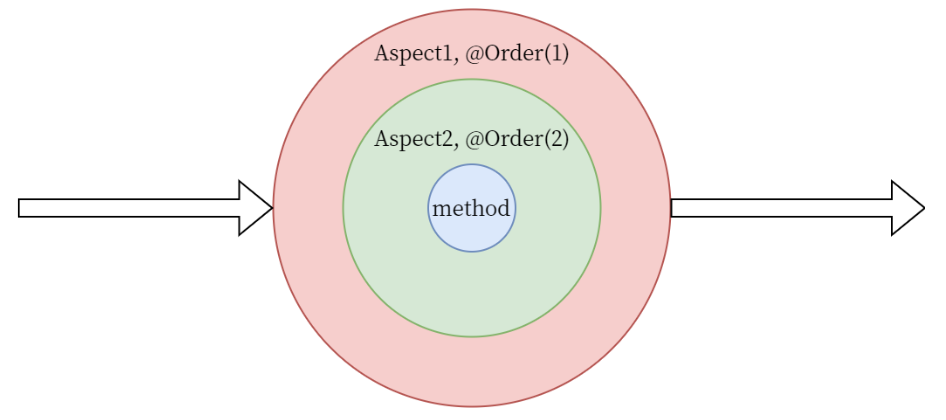
Spring AOP
Spring AOP 文章目录Spring AOP1.概念1.面向切面编程2.AOP的目的3.AOP实现的分类4.AOP 术语2. Spring AOP的特性1.能力与目标2.AOP机制1.理解SpringAOP的代理2.AOP代理类的自调用代码的粒度如何让自调用走代理?3.Enabling AspectJ Support3. 定义切面与切点1. 声明切…...

【消费战略方法论】认识消费者的恒常原理(一):消费者稳态平衡原理
“消费战略”是塔望咨询基于大量的战略与营销实践经验结合心理学、经济学、传播学等相关专业学科的知识应用进行提炼与创造形成的战略方法体系。消费战略强调以消费者为导向,进行企业、品牌战略、品牌营销的制订和落地,企业经营的每个环节和输出的每个动…...

python居然能语音控制电脑壁纸切换,只需60行代码
前言 嗨喽~大家好呀,这里是魔王呐 ❤ ~! 家在日常的电脑使用中,都会有自己喜爱类型的桌面 单纯的桌面有时候会让人觉得单调 今天,就由我带领大家只用60行代码打造一款语音壁纸切换器程序, 让大家能够通过语音的方式来控制电脑去…...

内存泄露定位手段(c语言hook malloc相关方式)
如何确定有内存泄露问题,如何定位到内存泄露位置,如何写一个内存泄漏检测工具? 1:概述 内存泄露本质:其实就是申请调用malloc/new,但是释放调用free/delete有遗漏,或者重复释放的问题。 内存…...
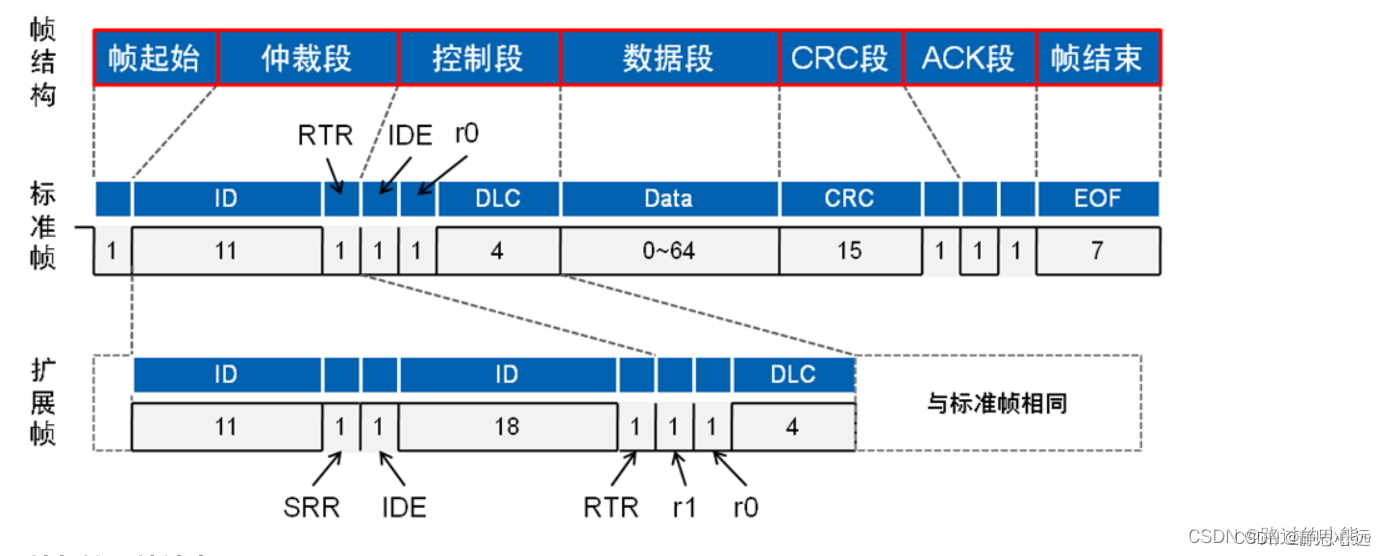
STM32 CAN波特率计算
STM32 CAN波特率计算简介CAN总线收发,中断方式接收配置代码部分reference简介 CAN通信帧共分为数据帧、远程帧、错误帧、过载帧和帧间隔,本文这里以数据帧为例。 显性电平对应逻辑0,CAN_H和CAN_L之差为2.5V左右。而隐性电平对应逻辑1&#x…...

Burp抓包失败的五大隐形墙与HTTPS解密断裂点排查指南
1. 这不是Burp用得不对,是环境链路断在了你没看见的地方“Burp抓不到包”——这句话我过去三年里听开发、测试、刚转安全的新人说了不下两百遍。但真正打开Burp一看,Proxy标签页里空空如也,连个localhost:8080的请求都没有,十有八…...

基于CNN的食双星光变曲线自动化参数初估模型EBOP MAVEN
1. 项目概述与核心价值在恒星天体物理领域,食双星系统一直扮演着“宇宙实验室”的关键角色。通过分析两颗恒星相互绕转时周期性相互遮挡产生的光变曲线,我们可以像解谜一样,精确反演出恒星的质量、半径、轨道倾角等基本物理参数。这些参数是构…...

SHAP原理与特征贡献解析
SHAP(SHapley Additive exPlanations)是一种基于博弈论中Shapley值的模型解释方法,它为机器学习模型的预测提供了一种统一、理论完备的特征归因框架。其核心思想是将模型的预测值视为所有特征协同合作的“总收益”,然后公平地分配…...
函数的计算原理(附绘图代码))
从复平面几何到Python代码:可视化理解NumPy中angle()函数的计算原理(附绘图代码)
从复平面几何到Python代码:可视化理解NumPy中angle()函数的计算原理(附绘图代码) 在数学和工程领域,复数不仅是抽象的概念,更是解决实际问题的有力工具。当我们谈论复数68j时,它不仅仅是一个符号组合——在…...

每日一书㉗ | 刻意练习:为什么有些人努力一辈子还是平庸?
“本文来自「乐想屋」公众号,系列更新[每日一书],每次5分钟,帮你把书读薄,把知识用活”先问你一个问题。你身边有没有这样的人:入行时间比你短,但能力已经甩你好几条街。他们好像没有特别刻苦,但…...

通过Taotoken用量看板清晰追踪各模型的Token消耗情况
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken用量看板清晰追踪各模型的Token消耗情况 对于依赖大模型API进行开发的个人或团队而言,成本控制与预算规划…...

<数据集>yolo高粱叶片病害识别<目标检测>
数据集下载链接https://download.csdn.net/download/qq_53332949/92902223数据集格式:VOCYOLO格式 图片数量:3242张 标注数量(xml文件个数):3242 标注数量(txt文件个数):3242 标注类别数:1 使用标注工具ÿ…...

代码跑偏白盒补漏:判定节点覆盖全路径测试
位于程序逻辑分叉处,起着关键开通作用的判定节点,意义无比重大。于程序运行进程里,每一条if语句、else语句以及switch语句背后,事实上都暗藏着一条独具特色且彼此独立的执行回路。而测试覆盖的核心使命,就是要把这些回…...

ZYNQ PS-SPI驱动W25Q80 Flash避坑指南:从寄存器配置到逻辑分析仪抓包全流程
ZYNQ PS-SPI驱动W25Q80 Flash实战避坑手册:从寄存器配置到信号抓包全解析 当你在Vitis Standalone环境下调试ZYNQ的PS-SPI与W25Q80 Flash通信时,是否遇到过这些场景:SPI时钟信号看似正常但数据始终对不上、擦除操作耗时远超预期、FIFO缓冲区莫…...

魔兽争霸III终极增强方案:WarcraftHelper完整配置与优化指南
魔兽争霸III终极增强方案:WarcraftHelper完整配置与优化指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为经典魔兽争霸III在现代…...