04 卷积神经网络搭建
一、数据集
MNIST数据集是从NIST的两个手写数字数据集:Special Database 3 和Special Database 1中分别取出部分图像,并经过一些图像处理后得到的[参考]。
MNIST数据集共有70000张图像,其中训练集60000张,测试集10000张。所有图像都是28×28的灰度图像,每张图像包含一个手写数字。

1.1 准备数据
将数据集分为训练集、验证集和测试集
#训练集有60000张图片,前5000张图片作为验证集,后55000作为训练集
1. `x_train_all` 和 `y_train_all`:
- `x_train_all` 包含了完整的训练数据集的图像数据,这些图像用于训练深度学习模型。
- `y_train_all` 包含了完整的训练数据集的标签,即与 `x_train_all` 中的图像相对应的类别标签。
2. `x_test` 和 `y_test`:
- `x_test` 包含了测试数据集的图像数据,这些图像用于评估深度学习模型的性能。
- `y_test` 包含了测试数据集的标签,即与 `x_test` 中的图像相对应的类别标签。
from tensorflow import keras
import tensorflow as tf
import numpy as np
import pandas as pd
import matplotlib.pyplot as pltfashion_mnist = keras.datasets.fashion_mnist
(x_train_all, y_train_all), (x_test, y_test) = fashion_mnist.load_data()
x_valid, x_train = x_train_all[:5000], x_train_all[5000:]
y_valid, y_train = y_train_all[:5000], y_train_all[5000:]print(x_valid.shape, y_valid.shape)
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)1.2 标准化
# 标准化
from sklearn.preprocessing import StandardScalerscaler = StandardScaler()
x_train_scaled = scaler.fit_transform(x_train.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1)
x_valid_scaled = scaler.transform(x_valid.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1)x_test_scaled = scaler.transform(x_test.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1)1.3 数据集
def make_dataset(data, target, epochs, batch_size, shuffle=True):dataset = tf.data.Dataset.from_tensor_slices((data, target))if shuffle:dataset = dataset.shuffle(10000)dataset = dataset.repeat(epochs).batch(batch_size).prefetch(50)return datasetbatch_size = 64
epochs = 20
train_dataset = make_dataset(x_train_scaled, y_train, epochs, batch_size)1.4 搭建模型
model = keras.models.Sequential()
# 卷积
model.add(keras.layers.Conv2D(filters = 32, kernel_size = 3, padding = 'same',activation='relu',# batch_size, height, width, channelsinput_shape=(28, 28, 1))) # (28, 28, 32)model.add(keras.layers.Conv2D(filters = 32, kernel_size = 3, padding = 'same',activation='relu'))
# 池化
model.add(keras.layers.MaxPool2D()) # (14, 14, 32)model.add(keras.layers.Conv2D(filters = 64, kernel_size = 3, padding = 'same',activation='relu')) # (14, 14, 64)
model.add(keras.layers.Conv2D(filters = 64, kernel_size = 3, padding = 'same',activation='relu'))
# 池化
model.add(keras.layers.MaxPool2D()) # (7, 7, 64)
model.add(keras.layers.Conv2D(filters = 128, kernel_size = 3, padding = 'same',activation='relu')) # (7, 7, 128)
model.add(keras.layers.Conv2D(filters = 128, kernel_size = 3, padding = 'same',activation='relu')) # (7, 7, 128)
# 池化, 向下取整
model.add(keras.layers.MaxPooling2D()) # (3, 3, 128)model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(512, activation='relu'))
model.add(keras.layers.Dense(256, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))model.compile(loss='sparse_categorical_crossentropy',optimizer='adam',metrics=['accuracy'])print(model.summary())keras.models.Sequential()`是使用 Keras 构建神经网络模型的开始。`keras.models.Sequential()` 创建了一个 Sequential 模型对象,这是 Keras 中的一种常见模型类型。Sequential 模型是一个线性的、层叠的神经网络模型,适用于顺序层的堆叠,其中每一层都是依次添加到模型中。
一旦创建了 Sequential 模型,你可以使用 `.add()` 方法来逐层添加神经网络层,从输入层到输出层。每个层都可以通过实例化 Keras 中的层类来创建,例如
`keras.layers.Dense` 用于全连接层,
`keras.layers.Conv2D` 用于卷积层等。
以下是一个简单的例子,演示如何使用 Sequential 模型创建一个简单的前馈神经网络:
from tensorflow import keras# 创建一个 Sequential 模型 model = keras.models.Sequential()# 添加输入层和第一个隐藏层 model.add(keras.layers.Input(shape=(input_shape,))) # 输入层,input_shape 根据你的数据维度定义 model.add(keras.layers.Dense(units=128, activation='relu')) # 隐藏层1# 添加第二个隐藏层 model.add(keras.layers.Dense(units=64, activation='relu')) # 隐藏层2# 添加输出层 model.add(keras.layers.Dense(units=num_classes, activation='softmax')) # 输出层,num_classes 是输出类别的数量# 编译模型 model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])上面的代码创建了一个具有两个隐藏层和一个输出层的前馈神经网络模型,并使用了 ReLU 激活函数和 softmax 激活函数。这只是一个简单的示例,你可以根据你的任务和数据来构建更复杂的模型。一旦模型构建完成,你可以使用 `.fit()` 方法来训练模型。
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
是 Keras 中用于编译深度学习模型的代码,它设置了模型的损失函数、优化器和评估指标。让我为你解释每个参数的含义:
- `loss='sparse_categorical_crossentropy'`: 这里设置了模型的损失函数。`sparse_categorical_crossentropy` 是一种用于多类别分类问题的损失函数。它适用于目标变量是整数形式(类别标签)的情况,而不需要将目标变量进行独热编码(one-hot encoding)。模型的目标是最小化这个损失函数,从而使预测结果尽可能接近真实标签。
- `optimizer='adam'`: 这里设置了优化器,用于模型的参数更新。`'adam'` 是一种常用的优化算法,它基于梯度下降的方法,具有自适应学习率和动量的特性,通常在深度学习中表现良好。优化器的作用是最小化损失函数,从而调整模型的权重和参数以使模型更好地拟合数据。
- `metrics=['accuracy']`: 这里设置了评估指标,用于在模型训练期间监测模型性能。
`['accuracy']` 表示模型在训练期间将计算并输出准确度(accuracy),即正确分类的样本数与总样本数的比率。准确度通常用于分类问题的性能评估。
一旦模型编译完成,你可以使用 `model.fit()` 方法来训练模型,该方法会使用上述设置的损失函数、优化器和评估指标来进行训练。例如:
```python
model.fit(x_train, y_train, epochs=10, validation_data=(x_valid, y_valid))
```
1.5 train
eval_dataset = make_dataset(x_valid_scaled, y_valid, epochs=1, batch_size=32, shuffle=False)history = model.fit(train_dataset, steps_per_epoch=x_train_scaled.shape[0] // batch_size,epochs=10,validation_data=eval_dataset)
1.6 模型评估
model.evaluate(eval_dataset)
1.7 可视化
def plot_learning_curves(history):pd.DataFrame(history.history).plot(figsize=(8, 5))plt.grid(True)plt.gca().set_ylim(0, 1)plt.show()plot_learning_curves(history)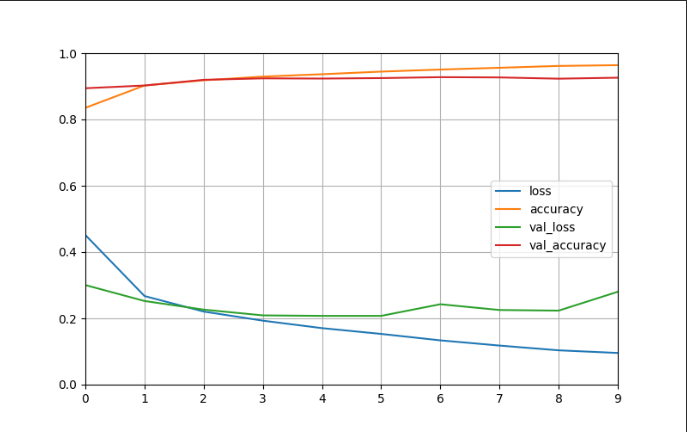
相关文章:
04 卷积神经网络搭建
一、数据集 MNIST数据集是从NIST的两个手写数字数据集:Special Database 3 和Special Database 1中分别取出部分图像,并经过一些图像处理后得到的[参考]。 MNIST数据集共有70000张图像,其中训练集60000张,测试集10000张。所有图…...

【hadoop运维】running beyond physical memory limits:正确配置yarn中的mapreduce内存
文章目录 一. 问题描述二. 问题分析与解决1. container内存监控1.1. 虚拟内存判断1.2. 物理内存判断 2. 正确配置mapReduce内存2.1. 配置map和reduce进程的物理内存:2.2. Map 和Reduce 进程的JVM 堆大小 3. 小结 一. 问题描述 在hadoop3.0.3集群上执行hive3.1.2的任…...
)
数据结构--6.5二叉排序树(插入,查找和删除)
目录 一、创建 二、插入 三、删除 二叉排序树(Binary Sort Tree)又称为二叉查找树,它或者是一棵空树,或者是具有下列性质的二叉树: ——若它的左子树不为空,则左子树上所有结点的值均小于它的根结构的值…...
无需公网IP,在家SSH远程连接公司内网服务器「cpolar内网穿透」
文章目录 1. Linux CentOS安装cpolar2. 创建TCP隧道3. 随机地址公网远程连接4. 固定TCP地址5. 使用固定公网TCP地址SSH远程 本次教程我们来实现如何在外公网环境下,SSH远程连接家里/公司的Linux CentOS服务器,无需公网IP,也不需要设置路由器。…...

Java工具类
一、org.apache.commons.io.IOUtils closeQuietly() toString() copy() toByteArray() write() toInputStream() readLines() copyLarge() lineIterator() readFully() 二、org.apache.commons.io.FileUtils deleteDirectory() readFileToString() de…...

makefile之使用函数wildcard和patsubst
Makefile之调用函数 调用makefile机制实现的一些函数 $(function arguments) : function是函数名,arguments是该函数的参数 参数和函数名用空格或Tab分隔,如果有多个参数,之间用逗号隔开. wildcard函数:让通配符在makefile文件中使用有效果 $(wildcard pattern) 输入只有一个参…...

算法通关村第十八关——排列问题
LeetCode46.给定一个没有重复数字的序列,返回其所有可能的全排列。例如: 输入:[1,2,3] 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]] 元素1在[1,2]中已经使…...

基于STM32设计的生理监测装置
一、项目功能要求 设计并制作一个生理监测装置,能够实时监测人体的心电图、呼吸和温度,并在LCD液晶显示屏上显示相关数据。 随着现代生活节奏的加快和环境的变化,人们对身体健康的关注程度越来越高。为了及时掌握自身的生理状况,…...

Go-Python-Java-C-LeetCode高分解法-第五周合集
前言 本题解Go语言部分基于 LeetCode-Go 其他部分基于本人实践学习 个人题解GitHub连接:LeetCode-Go-Python-Java-C Go-Python-Java-C-LeetCode高分解法-第一周合集 Go-Python-Java-C-LeetCode高分解法-第二周合集 Go-Python-Java-C-LeetCode高分解法-第三周合集 G…...
)
【前端知识】前端加密算法(base64、md5、sha1、escape/unescape、AES/DES)
前端加密算法 一、base64加解密算法 简介:Base64算法使用64个字符(A-Z、a-z、0-9、、/)来表示二进制数据的64种可能性,将每3个字节的数据编码为4个可打印字符。如果字节数不是3的倍数,将会进行填充。 优点࿱…...
leetcode 925. 长按键入
2023.9.7 我的基本思路是两数组字符逐一对比,遇到不同的字符,判断一下typed与上一字符是否相同,不相同返回false,相同则继续对比。 最后要分别判断name和typed分别先遍历完时的情况。直接看代码: class Solution { p…...

[CMake教程] 循环
目录 一、foreach()二、while()三、break() 与 continue() 作为一个编程语言,CMake也少不了循环流程控制,他提供两种循环foreach() 和 while()。 一、foreach() 基本语法: foreach(<loop_var> <items>)<commands> endfo…...
Mojo安装使用初体验
一个声称比python块68000倍的语言 蹭个热度,安装试试 系统配置要求: 不支持Windows系统 配置要求: 系统:Ubuntu 20.04/22.04 LTSCPU:x86-64 CPU (with SSE4.2 or newer)内存:8 GiB memoryPython 3.8 - 3.10g or cla…...

艺术与AI:科技与艺术的完美融合
文章目录 艺术创作的新工具生成艺术艺术与数据 AI与互动艺术虚拟现实(VR)与增强现实(AR)机器学习与互动性 艺术与AI的伦理问题结语 🎉欢迎来到AIGC人工智能专栏~艺术与AI:科技与艺术的完美融合 ☆* o(≧▽≦…...
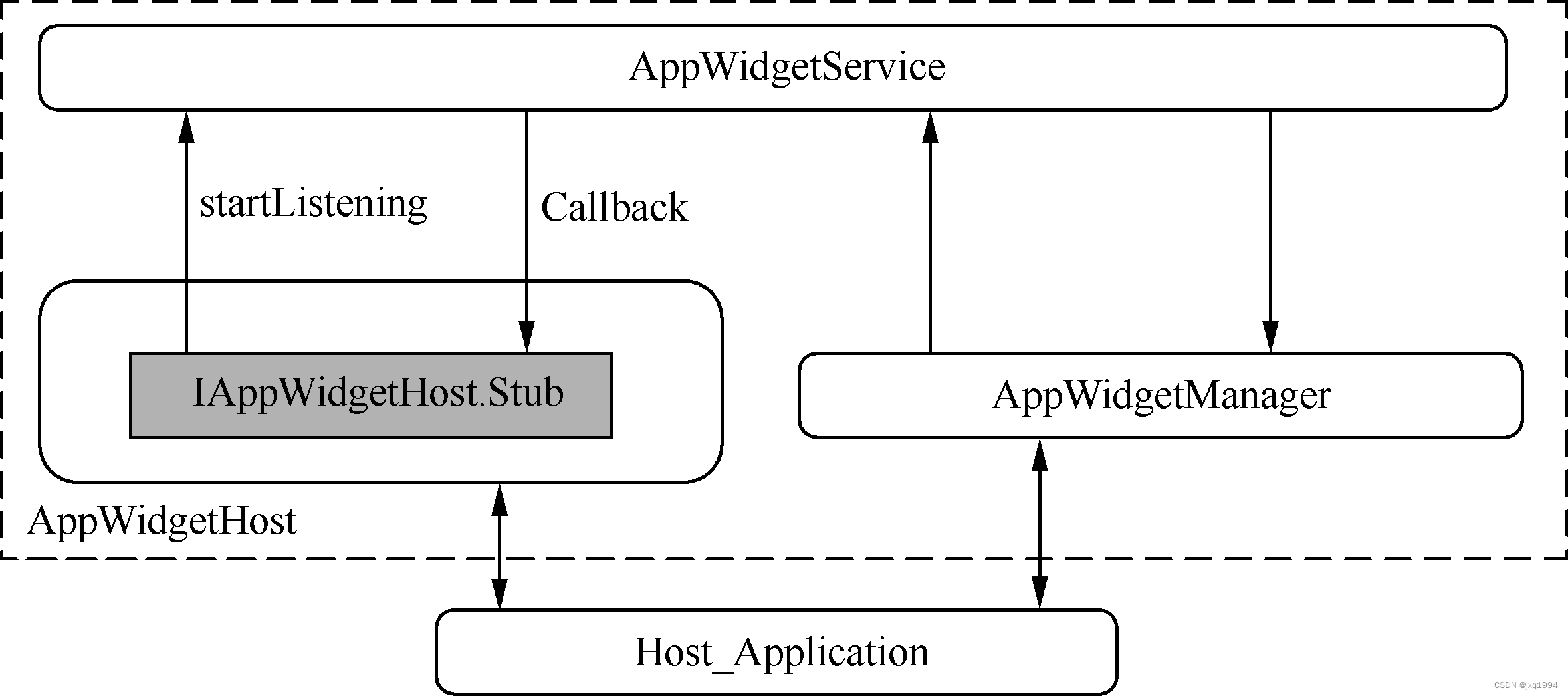
Android常用的工具“小插件”——Widget机制
Widget俗称“小插件”,是Android系统中一个很常用的工具。比如我们可以在Launcher中添加一个音乐播放器的Widget。 在Launcher上可以添加插件,那么是不是说只有Launcher才具备这个功能呢? Android系统并没有具体规定谁才能充当“Widget容器…...

探索在云原生环境中构建的大数据驱动的智能应用程序的成功案例,并分析它们的关键要素。
文章目录 1. Netflix - 个性化推荐引擎2. Uber - 实时数据分析和决策支持3. Airbnb - 价格预测和优化5. Google - 自然语言处理和搜索优化 🎈个人主页:程序员 小侯 🎐CSDN新晋作者 🎉欢迎 👍点赞✍评论⭐收藏 ✨收录专…...

jupyter 添加中文选项
文章目录 jupyter 添加中文选项1. 下载中文包2. 选择中文重新加载一下,页面就变成中文了 jupyter 添加中文选项 1. 下载中文包 pip install jupyterlab-language-pack-zh-CN2. 选择中文 重新加载一下,页面就变成中文了 这才是设置中文的正解ÿ…...

系列十、Java操作RocketMQ之批量消息
一、概述 RocketMQ可以一次性发送一组消息,那么这一组消息会被当做一个消息进行消费。 二、案例代码 2.1、pom 同系列五 2.2、RocketMQConstant 同系列五 2.3、BatchConsumer package org.star.batch.consumer;import cn.hutool.core.util.StrUtil; import lom…...

leetcode1两数之和
题目: 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。 你…...

近年GDC服务器分享合集(四): 《火箭联盟》:为免费游玩而进行的扩展
如今,网络游戏采用免费游玩(Free to Play)加内购的比例要远大于买断制,这是因为前者能带来更低的用户门槛。甚至有游戏为了获取更多的用户,选择把原来的买断制改为免费游玩,一个典型的例子就是最近的网易的…...
)
别再对着乱码发愁了!手把手教你用Python解码AIS VDM暗码(附完整代码)
从AIS暗码到可读数据:Python实战解析指南 当你第一次看到类似!AIVDM,1,1,,A,169DvlgP1R8KPtvFBfOCt3?h0RT,0*03这样的字符串时,可能会感到一头雾水。这串看似随机的字符实际上是AIS(船舶自动识别系统)传输的VDM(VHF Data-link Message)报文,…...
)
ElevenLabs Starter计划实战指南(新手必看的4步激活+2次配额翻倍技巧)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs Starter计划的核心定位与适用边界 ElevenLabs Starter 计划是面向开发者、内容创作者及小型团队推出的免费语音合成入门方案,旨在以零门槛方式提供高质量、低延迟的文本转语音&…...

【ElevenLabs API接入黄金手册】:20年AI语音工程师亲授5大避坑要点与3小时极速上线实战路径
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs API接入黄金手册:开篇导论与核心价值定位 ElevenLabs 以行业领先的语音自然度、情感表现力与多语言支持能力,成为生成式AI语音服务的事实标准。其API并非仅提供TTS基…...

学术生产力革命已来,NotebookLM Agent如何把文献综述时间压缩83%?实测数据首次公开!
更多请点击: https://intelliparadigm.com 第一章:NotebookLM Agent研究辅助 NotebookLM 是 Google 推出的基于用户上传文档进行深度理解与推理的 AI 助手,其内置的 Agent 能力可显著提升学术研究、技术调研与知识整合效率。当启用 Agent 模…...

AI应用开发平台RiserFlow实战:从架构解析到智能客服构建
1. 项目概述:从“RiserFlow”看现代AI应用开发范式的演进最近在GitHub上看到一个挺有意思的项目,叫riserlabs/riserflow。光看这个名字,可能有点摸不着头脑,但如果你点进去,会发现它其实指向一个更具体的产品ÿ…...

从ARIMA差分到MIM网络:一个老派时间序列技巧如何革新了深度学习预测
从差分思想到记忆网络:传统时间序列技巧如何重塑深度学习架构 在气象预报的雷达回波图中,降水云团的形态每秒钟都在剧烈变化;城市交通流量监测数据里,早晚高峰的波动与平峰期形成鲜明对比;股票市场的价格曲线更是以难以…...

网站国产化改造怎么做?深度解读国产化替代路径与CMS推荐
在近年来科技领域的舆论场中,“国产化”无疑是出现频率最高的关键词之一。从芯片到操作系统,从数据库到办公软件,再到企业对外展示的门户——网站,国产化替代已从“可选项”变成了很多行业的“必答题”。但国产化仅仅是“换个牌子…...

嵌入式开发实战:从ADC纹波故障看系统集成调试与EMC设计
1. 项目背景与问题缘起:当“新”设备遭遇“老”问题在工业设备开发领域,尤其是像线锯这类集精密机械、复杂电气和嵌入式软件于一体的复杂系统,有一个经典且令人头疼的场景:一款经过验证的成熟产品平台,在衍生出新机型或…...
核心原理、选型指南与EDA设计实战)
可编程逻辑器件(PLD/CPLD/FPGA)核心原理、选型指南与EDA设计实战
1. 项目概述:从怀旧到硬核,聊聊可编程逻辑的“前世今生”那天在网上闲逛,本想找点微马赛克艺术(Micromosaic)的制作视频,结果算法一个拐弯,把我带回了上世纪七八十年代的《大青蛙布偶秀》&#…...

出境游网络解决方案大揭秘:eSIM 与非 eSIM 谁更胜一筹?
海外 eSIM 怎么买?线上直接下单就行最近几年,出境游再度火热起来。每次出发前,搞定酒店和大交通后,还得买手机卡。理论上,可带三大运营商的卡出境并开国际漫游,但买当地号卡和套餐更划算。去年 iPhone Air …...