论文浅尝 | 训练语言模型遵循人类反馈的指令

笔记整理:吴亦珂,东南大学硕士,研究方向为大语言模型、知识图谱
链接:https://arxiv.org/abs/2203.02155
1. 动机
大型语言模型(large language model, LLM)可以根据提示完成各种自然语言处理任务。然而,这些模型可能会展现出与人类意图不一致的行为,例如编造事实、生成带有偏见或有害信息,或者不遵循用户的指令。这种情况的原因在于LLM的训练目标是预测下一个标记(token),而不是有针对性地、安全地遵循用户的指令。这导致LLM与人类指令的对齐不足,而这一点对于在各种应用中部署和使用LLM至关重要。因此,本文的动机在于通过训练LLM,使其与用户意图保持一致。为了实现这一目标,本文采用了微调方法,提出了基于人类反馈的强化学习策略(reinforcement learning from human feedback, RLHF),该技术将人类偏好作为激励信号来微调模型。作者的方法大致分为三个部分:
(1)将GPT-3作为模型骨架,采用监督学习的方式训练,作为基线模型。
(2)人工对GPT-3的输出基于生成质量排序,在基线模型基础上训练一个能够符合人类偏好的奖励模型。
(3)将奖励模型作为奖励函数,采用极大化奖励的方式基于PPO算法微调基线模型。
通过上述3个阶段,实现了GPT-3到人类偏好的对齐,作者将微调后的模型称为InstructGPT。
2. 贡献
(1)提出了一种基于人类反馈的强化学习策略RLHF,使得LLM能够更好地符合人类的偏好,从而使模型更加有用、安全和诚实。
(2)InstructGPT相较于GPT-3,生成的结果更符合人类的偏好,具有更高的真实性和更低的潜在有害性。
(3)实验结果表明,通过RLHF微调,LLM可以更好的服从人类的指令,并且具备更强的指令泛化能力。
3. 方法
本研究基于用户在OpenAI API上提交的文本提示和人工编写的文本提示,创建了三个不同的数据集,用于微调过程:(1)监督微调数据集,用于训练监督模型,其中包含13k个训练样例;(2)奖励模型数据集,人工对模型的输出进行排序,用于训练奖励模型,该数据集包含33k个样例;(3)PPO数据集,没有人工标注,用于进行基于人类反馈的强化学习训练,该数据集包含31k个样例。图1展示了这三个数据集中任务的分布情况。
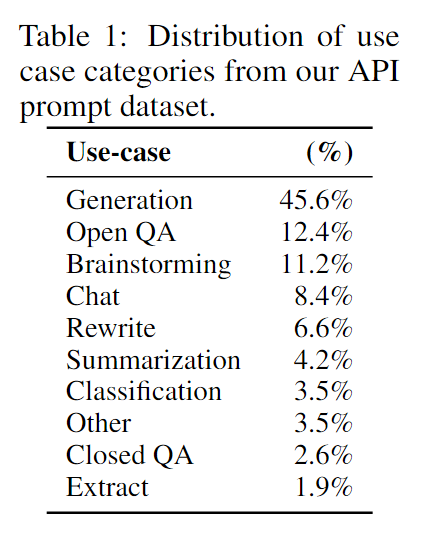
图1 数据集的任务分布
本研究将GPT-3作为基本预训练模型,采用三个策略训练,训练框架如图2所示:
(1) 监督微调(SFT, supervised fine-tuning):采用监督学习方法微调GPT-3,利用验证集上的奖励模型分数选择最佳的SFT模型。
(2) 奖励模型(RM, reward modeling):输入提示和回答,训练模型输出量化的奖励。本研究采用6B模型作为基础模型,因为作者发现175B模型可能不够稳定,且在强化学习中不适合作为价值函数。为了提高训练效率,不同于传统奖励模型每次对两个模型输出进行比较,本研究要求标注者对4到9个回答进行排序。设K为排序的数量,则标注者一共需要进行 次比较。由于每个标注任务中的比较具有很高的相关性,如果简单地将比较混合成一个数据集进行训练,可能导致奖励模型过拟合。因此,本研究将每个提示的所有 个比较作为单个批次训练。这种做法避免了过拟合,并且在计算上更加高效,因为每次完成只需要对奖励模型进行一次前向传递,而不是 次。奖励模型的损失函数定义如下:
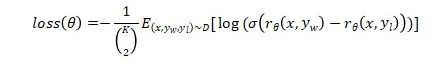
其中, θ 是奖励模型对于指令x和回答y给出的量化奖励, 是 和 中更符合人类偏好的输出,D为奖励模型训练数据集。
(3) 强化学习(RL, reinforcement learning):采用PPO算法对SFT模型进行微调。模型基于随机的指令产生回答,奖励模型根据指令和回答生成奖励信号,指导模型的微调过程。为了防止过拟合,作者对每个生成的标记增加了逐标记的KL散度惩罚。通过这种方式训练的模型被称为PPO模型。此外,作者还尝试将预训练模型的梯度与PPO梯度进行混合,以缓解在公开自然语言处理数据集上性能下降的问题。这种方式训练的模型被称为PPO-ptx模型。强化学习训练旨在最大化以下目标:
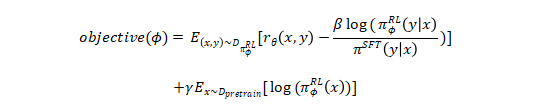
其中, πφ 是强化学习策略, π 是监督训练模型, 是预训练分布。KL奖励系数β和预训练损失系数γ分别控制 KL 惩罚和预训练梯度的强度。
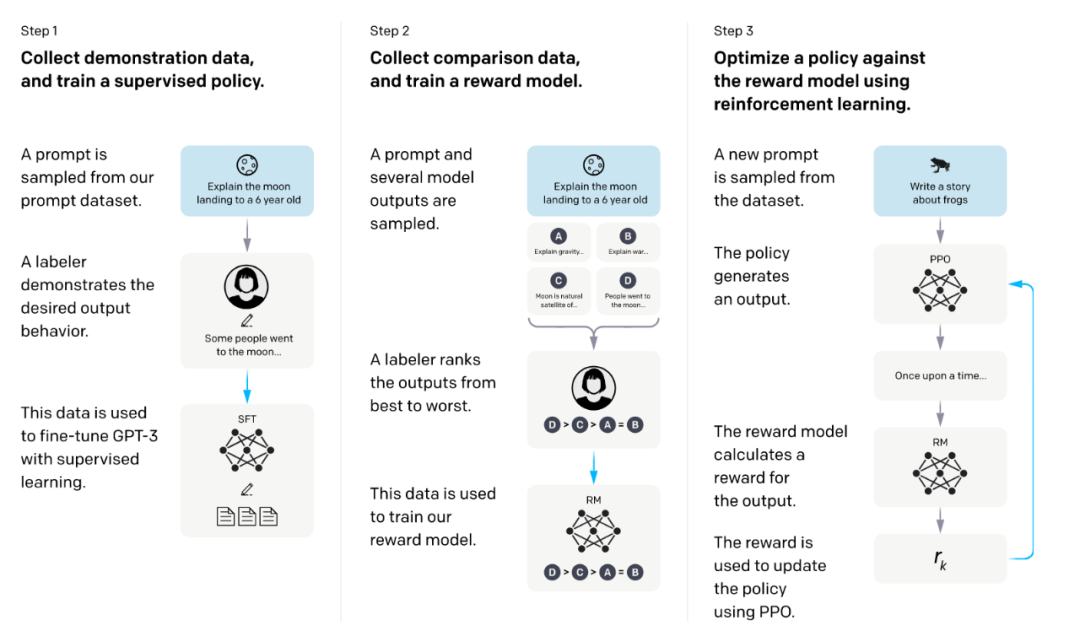
图2 RLHF训练框架
4. 实验
4.1 对比模型
本研究主要对经过RLHF训练的PPO模型与SFT模型、原版GPT-3模型以及GPT-3-prompted模型(模型输入时加上若干例子构成前缀,引导模型遵循指令)进行了比较。同时,还将InstructGPT模型与在FLAN和T0数据集上微调后的175B GPT-3模型进行了对比。
4.2 评测方法
本研究采用定量评估和定性评估相结合的评估方法。其中,定量评估包括基于API提示数据的评估和在公开自然语言处理数据集上的评估。
(1)基于API提示数据的评估。数据来源于用户在InstructGPT API和GPT-3 API输入的提示。作者将175B SFT模型作为基线模型,计算模型输出优于基线模型的频率。此外,人工对于模型输出基于李克特量表进行打分。
(2)公开自然语言处理数据集上的评估。数据集主要分为两类:一是反映模型在安全性、真实性、有害性和偏差性等方面表现的数据集;二是衡量模型在传统自然语言处理任务上的零样本性能的数据集。
(3)定性评估。通过人工编写若干测试用例评测模型,包括评估模型的泛化能力等。
4.3 结果
(1)基于API提示的评估
InstructGPT模型更符合人类偏好。实验中,本研究将175B的SFT模型作为基线模型,并统计了PPO模型、PPO-ptx模型、GPT-3模型和GPT-3-prompted模型相对于基线模型,在人工评估中产生更高质量输出的频率。具体实验结果如图3所示。结果显示,本文提出的PPO模型和PPO-ptx模型在GPT分布和Instruct分布下都表现最好。

图3 基于API提示的评估结果
InstructGPT在与人类偏好的对齐方面展现了一定的泛化能力。为了验证InstructGPT是否仅仅符合标注人员的偏好,本研究选择没有进行数据标注的人对模型输出结果进行了评估,并得出了一致的结论:InstructGPT显著优于基线模型GPT-3。
公开的自然语言处理数据集无法完全反映语言模型的使用情况。为了进一步评估InstructGPT的性能,本研究将其与在FLAN和T0数据集上微调的175B GPT-3进行了比较。实验结果表明,微调后的175B GPT-3模型优于原版GPT-3,与经过精心设计输入提示的GPT-3性能相当,但不及SFT模型和InstructGPT。作者认为,InstructGPT相对于微调后的GPT-3模型更具优势的原因有两个方面:(1)公开数据集主要涵盖分类和问答等任务,而在实际用户使用的数据中,这两种任务只占很小比例。(2)公开的自然语言处理数据集无法包含足够多样性的输入。
(2)基于公开自然语言处理数据集的评估
相较于GPT-3模型,InstructGPT在真实性方面有所提升。本研究通过在TruthfulQA数据集上进行人工评估,发现PPO模型相对于GPT-3表现出一定的提升。此外,本研究还采用了“Instruction+QA”提示的方式,引导模型在面临不确定正确答案的情况下回答“I have no comment”。实验结果显示,在这两种设定下,InstructGPT相对于GPT-3具有更好的性能,具体实验结果见图4。
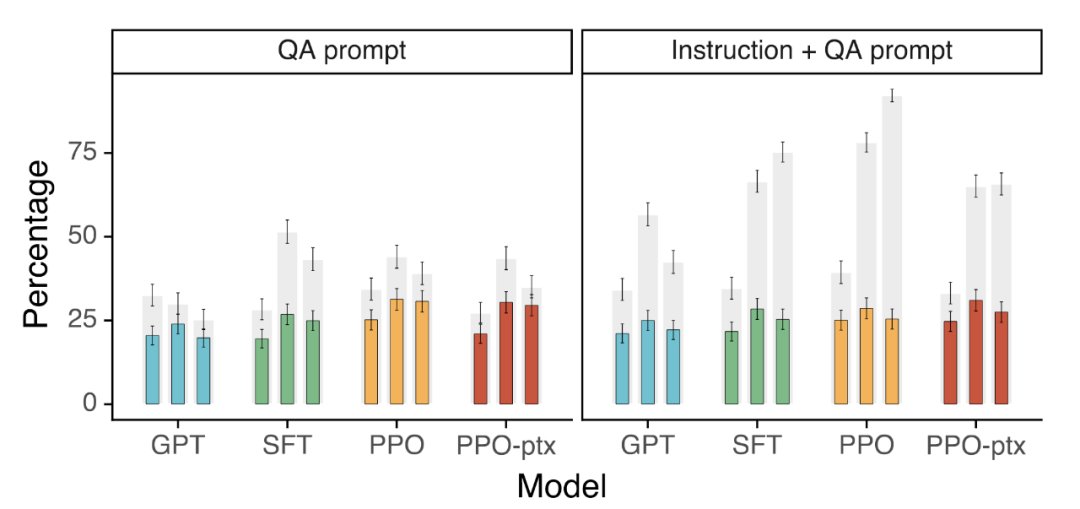
图4 TruthfulQA数据集的评估结果
相较于GPT-3模型,InstructGPT生成的有害内容更少。本研究通过在RealToxicityPrompts数据集上进行评估,从两个方面考察模型的性能:(1)采用数据集标准的自动评估方法,获取有害性分数。(2)人工对模型生成的回答进行有害性打分。在模型输入方面,研究采用了两种设置:不加入提示内容和加入提示内容以引导模型生成无害的内容(respectful prompt)。实验结果如图5所示。两种评估方法都表明,在加入respectful prompt的设定下,InstructGPT表现更好,但在没有提示内容的情况下,InstructGPT和GPT-3的性能相近。
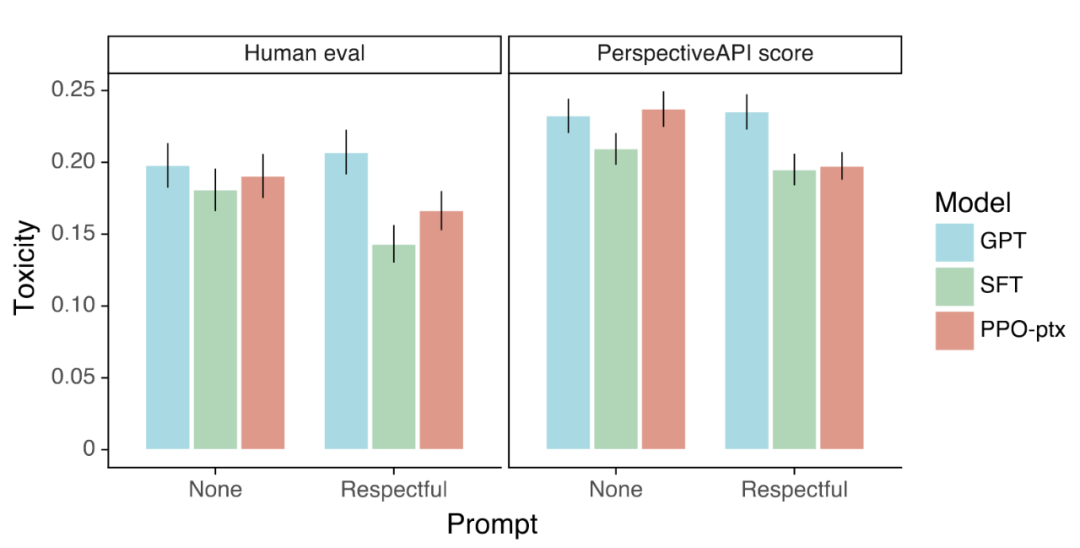
图5 RealToxicityPrompts数据集上的评估结果
通过改进RLHF的微调过程,可以减少在公开数据集上的性能下降。作者指出,经过RLHF训练的PPO模型在多个公开自然语言处理数据集上可能受到“对齐税”的影响而性能下降。为了解决这个问题,在PPO微调过程中引入了预训练更新,这种模型称之为“PPO-ptx”。具体的实验结果如图6所示。实验结果表明,相对于PPO模型,PPO-ptx在HellaSwag数据集上表现出更好的性能,超过了GPT-3模型。然而,在其他任务上,PPO-ptx的性能仍然不如GPT-3模型。
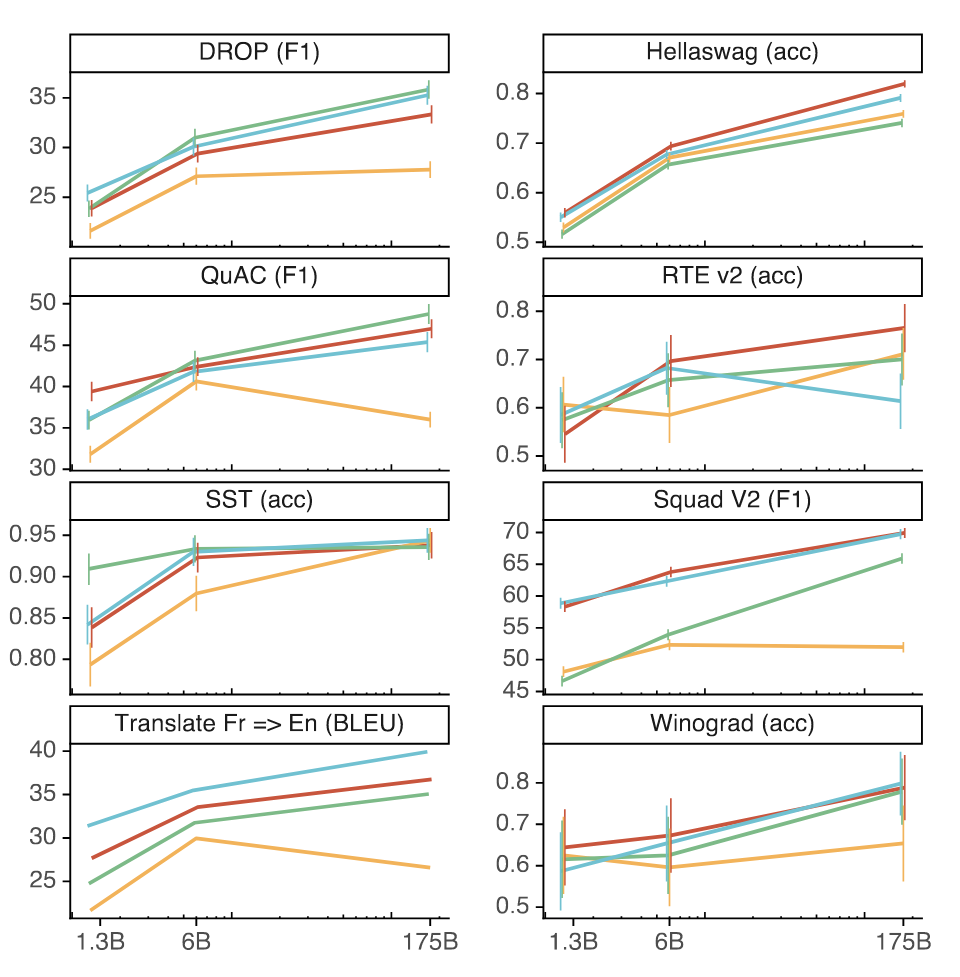
图6 多个公开自然语言处理数据集上模型的少样本性能
(3)定性评估
InstructGPT展现了对于指令的强大泛化能力。作者通过编写多个用例发现,InstructGPT能够遵循非英语语言的指令,进行总结和回答代码相关问题。这些任务在训练数据中仅占很小比例,这表明通过对齐的方法,模型能够生成出未经直接监督学习的行为。相比之下,GPT-3需要经过精心设计的提示才能执行这些任务,并且在代码相关任务以及非英语语言的指令任务等方面表现较弱。
InstructGPT仍然会出现简单的错误。这些错误包括:将错误的假设视为正确,对于简单问题不给出答案或给出多个答案,以及在处理包含多个明确约束的指令时表现不佳。
5. 总结
本研究旨在解决LLM存在的编造事实和生成有害文本等问题,通过基于人类反馈的强化学习方法微调语言模型,使其与人类偏好对齐。实验证明,经过强化学习微调后的模型生成的内容更可信,有害内容减少,对人类指令具有更好的泛化能力。然而,在公开自然语言处理数据集上,模型的性能有所下降,作者将其称为“对齐税”,并通过引入预训练数据来缓解性能下降的问题。未来的研究可以探索更有效的LLM对齐方法,并开发减少“对齐税”的策略。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。
相关文章:
论文浅尝 | 训练语言模型遵循人类反馈的指令
笔记整理:吴亦珂,东南大学硕士,研究方向为大语言模型、知识图谱 链接:https://arxiv.org/abs/2203.02155 1. 动机 大型语言模型(large language model, LLM)可以根据提示完成各种自然语言处理任务。然而&am…...

【云计算网络安全】解析DDoS攻击:工作原理、识别和防御策略 | 文末送书
文章目录 一、前言二、什么是 DDoS 攻击?三、DDoS 攻击的工作原理四、如何识别 DDoS 攻击五、常见的 DDoS 攻击有哪几类?5.1 应用程序层攻击5.1.1 攻击目标5.1.2 应用程序层攻击示例5.1.3 HTTP 洪水 5.2 协议攻击5.2.1 攻击目标5.2.2 协议攻击示例5.2.3 …...

64位Linux系统上安装64位Oracle10gR2及Oracle11g所需的依赖包
在64位Linux系统上安装64位Oracle 10gR2,到底需要装哪些包? 这不是一个完整的安装教程,仅仅探讨在64位CentOS 5.8系统上安装64位Oracle 10gR2,到底需要装哪些RPM包. 实验环境VMWare Workstation 8.0 Linux发行版: CentOS 5.8 x86_64 Kernel版本: 2.6.18-308.el5 Oracle Dat…...

Unity InputSystem 基础使用之鼠标交互
资料 官方文档 导入InputSystem包 Package Manager 搜索Input System进行下载启用该包,会重启Unity Editor 注意 InputSystem可以和旧版输入系统一起使用 设置:Project Settings->Player->Other Settings->Configuration->Active Input…...

《算法竞赛·快冲300题》每日一题:“二进制数独”
《算法竞赛快冲300题》将于2024年出版,是《算法竞赛》的辅助练习册。 所有题目放在自建的OJ New Online Judge。 用C/C、Java、Python三种语言给出代码,以中低档题为主,适合入门、进阶。 文章目录 题目描述题解C代码Java代码Python代码 “ 二…...
CnosDB 签约京清能源,助力分布式光伏发电解决监测系统难题。
近日,京清能源采购CnosDB,升级其“太阳能光伏电站一体化监控平台”。该平台可以实现电站设备统一运行监控,数据集中管理,为操作人员、维护人员、管理人员提供全面、便捷、差异化的数据和服务。 京清能源集团有限公司(…...

汇编:lea 需要注意的一点
lea和mov的效用上不一样,如果当前%rsi的值是0, lea 0x28(%rsi),%rax ,这个只是计算一个地址,而不是去做地址访问。 mov 0x8(%rsi),%rsi,而这个mov,在计算完地址,还要访问内存地址。如果rsi是0&a…...
SQL语言的分类:DDL(数据库、表的增、删、改)、DML(数据的增、删、改)
数据库管理系统(数据库软件)功能非常多,不仅仅是存储数据,还要包含:数据的管理、表的管理、库的管理、账户管理、权限管理等。 操作数据库的SQL语言,基于功能,划分为4类: 1、数据定…...

微信小程序精准扶贫数据收集小程序平台设计与实现
摘 要 近些年以来,随着我国的互联网技术的不断进步,计算机科学技术的发展也在不断的快速发展。在当下“互联网”的带动下,我国的各行各业,上到政府机关下到小微企业都通过互联网的发展带动取得了很好的发展势头。我国这两年来通过…...

PostgreSQL 流复制搭建
文章目录 前言1. 配置环境1.1 环境介绍1.2 主库白名单1.3 主库参数配置 2. 流复制搭建2.1 备份恢复2.2 创建复制用户2.3 参数修改2.4 启动并检查2.5 同步流复制2.6 同步复制级别 3. 流复制监控3.1 角色判断3.2 主库查看流复制3.3 延迟监控3.4 备库查询复制信息 前言 PostgreSQ…...

机器学习笔记之最优化理论与方法(十)无约束优化问题——共轭梯度法背景介绍
机器学习笔记之最优化理论与方法——共轭梯度法背景介绍 引言背景:共轭梯度法线性共轭梯度法共轭方向共轭VS正交共轭方向法共轭方向法的几何解释 引言 本节将介绍共轭梯度法,并重点介绍共轭方向法的逻辑与几何意义。 背景:共轭梯度法 关于…...

Mybatis核心对象及工作流程
目录 一、mybatis核心对象 (1)SqlSession对象直接操作数据库 (2)SqlSession对象通过代理对象操作数据库 二、mybatis工作流程 一、mybatis核心对象 (1)SqlSessionFactoryBuilder SqlSession工厂构建者对…...
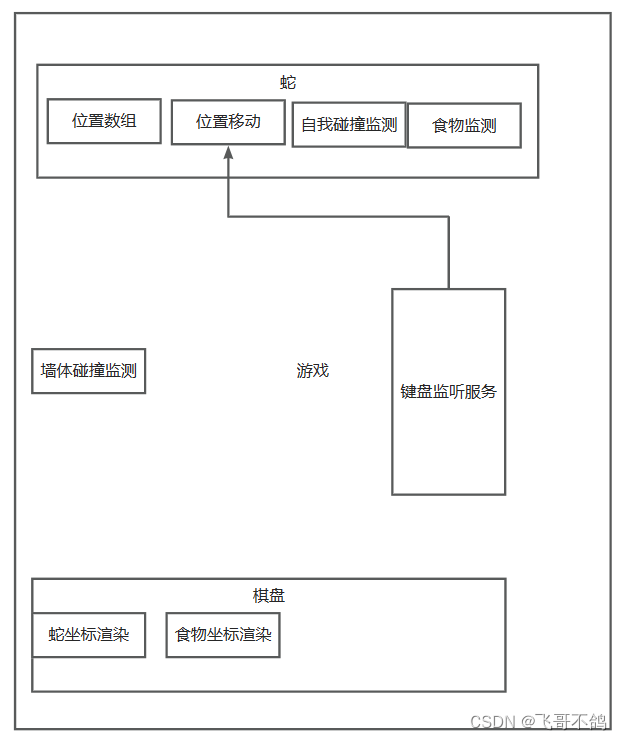
无swing,高级javaSE毕业之贪吃蛇游戏(含模块构建,多线程监听服务),已录制视频
JavaSE,无框架实现贪吃蛇 B站已发视频:无swing,纯JavaSE贪吃蛇游戏设计构建 文章目录 JavaSE,无框架实现贪吃蛇1.整体思考2.可能的难点思考2.1 如何表示游戏界面2.2 如何渲染游戏界面2.3 如何让游戏动起来2.4 蛇如何移动 3.流程图…...
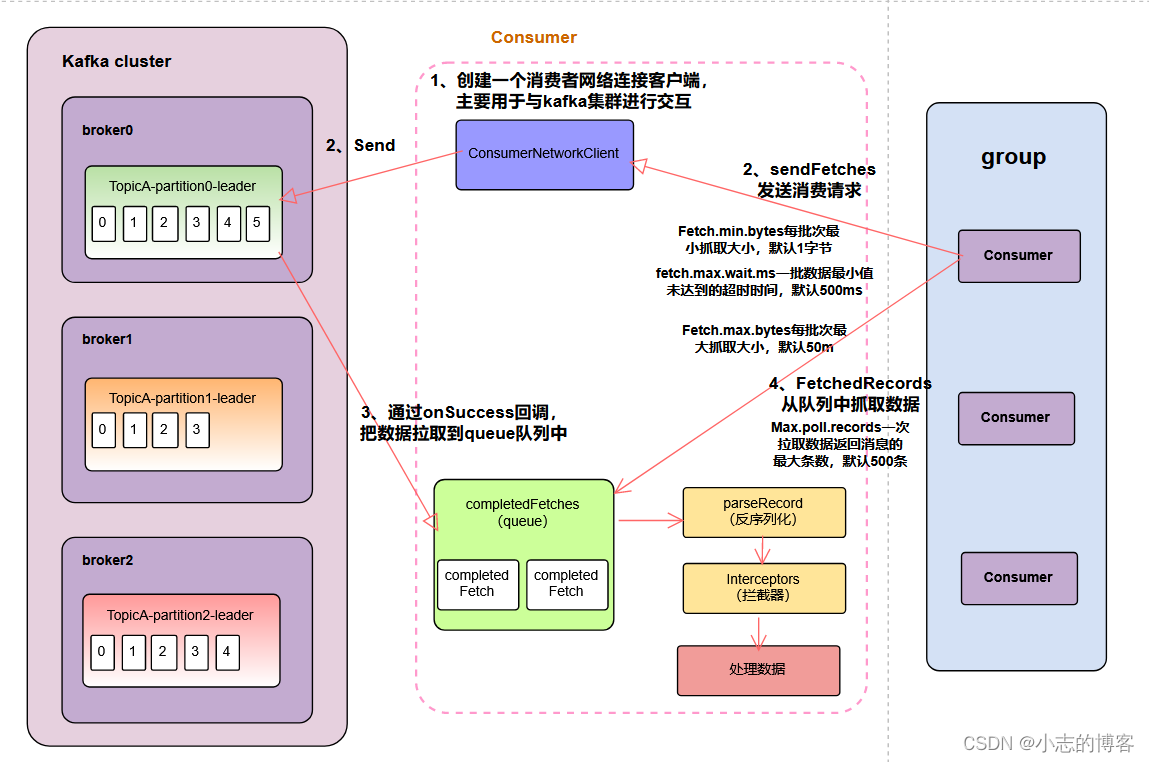
Kafka3.0.0版本——消费者(消费者组详细消费流程图解及消费者重要参数)
目录 一、消费者组详细消费流程图解二、消费者的重要参数 一、消费者组详细消费流程图解 创建一个消费者网络连接客户端,主要用于与kafka集群进行交互,如下图所示: 调用sendFetches发送消费请求,如下图所示: (1)、Fet…...

算法通关村-----位运算在海量元素中查找重复元素的妙用
用4KB内存寻找重复元素 问题描述 给定一个数组,包含从1到N的整数,N最大为32000,数组可能还有重复值,且N的取值不定,若只有4KB内存可用,如何打印数组中所有的重复元素。 问题分析 Java中存储整数使用int…...

RabbitMQ: Publish/Subscribe结构
生产者 package com.qf.mq2302.publishSub;import com.qf.mq2302.utils.MQUtils;import com.rabbitmq.client.Channel; import com.rabbitmq.client.Connection;public class EmitLog {private static final String EXCHANGE_NAME "logs";public static void main…...

单片机-蜂鸣器
简介 蜂鸣器是一种一体化结构的电子讯响器,采用直流电压供电 蜂鸣器主要分为 压电式蜂鸣器 和 电磁式蜂鸣器 两 种类型。 压电式蜂鸣器 主要由多谐振荡器、压电蜂鸣片、阻抗匹配器及共鸣箱、外壳等组成。多谐振荡器由晶体管或集成电路构成,当接通电源后&…...

华为云云耀云服务器L实例评测 | 分分钟完成打地鼠小游戏部署
前言 在上篇文章【华为云云耀云服务器L实例评测 | 快速部署MySQL使用指南】中,我们已经用【华为云云耀云服务器L实例】在命令行窗口内完成了MySQL的部署并简单使用。但是后台有小伙伴跟我留言说,能不能用【华为云云耀云服务器L实例】来实现个简单的小游…...

Android——数据存储(二)(二十二)
1. SQLite数据库存储 1.1 知识点 (1)了解SQLite数据库的基本作用; (2)掌握数据库操作辅助类:SQLiteDatabase的使用; (3)可以使用命令操作SQLite数据库; …...

appium环境搭建
一.appium环境搭建 1.python3 python3的下载安装这里就不多做介绍了,当然你也可以选择自己喜欢的语音,比如java… 2.jdk 1)下载地址 官网(需登录账号): https://www.oracle.com/java/technologies/downloads/ 百度网盘&…...

Yaskawa JACP-317800输入输出模块
安川JACP-317800是一款高性能逻辑输入输出模块,隶属于安川CP-317系列PLC系统,专为工业自动化领域的数字信号采集与控制而设计。产品特点:产品类型为逻辑输入输出模块,作为PLC与现场设备之间的信号接口模块重量仅0.3公斤࿰…...

Cerebro:为AI构建持久记忆与认知能力的本地化MCP工具系统
1. 项目概述:为AI赋予持久记忆与认知能力如果你和我一样,每天都在和Claude、ChatGPT这类大语言模型打交道,那你一定遇到过这个让人头疼的问题:每次开启一个新的对话会话,AI就像得了“健忘症”,之前聊过的项…...

2篇3章3节:Trae 的高效小说创作与文件管理实操
在人工智能辅助小说创作的过程中,工具操作方式、内容生成逻辑与文件管理体系,直接决定写作效率与文稿质量。Trae作为适配小说创作的专业工具,不仅支持单章、全章智能化生成正文内容,适配短篇、长篇不同创作场景,还具备多屏拆分、标签页管理、规范化文件收纳等实用功能。熟…...

LVGL列表控件实战:5分钟搞定一个带图标和事件响应的菜单界面
LVGL列表控件实战:5分钟打造高交互性嵌入式菜单界面 在嵌入式设备的人机交互设计中,菜单界面是最基础也最关键的组件之一。想象一下,当你需要为智能家居控制面板设计一个简洁明了的操作菜单,或者为工业设备开发一个功能选择界面时…...

ClawGuard:为Clawdbot AI智能体打造的安全监控与熔断防护系统
1. 项目概述:ClawGuard 是什么,以及为什么你需要它如果你正在使用或开发基于 Clawdbot 框架的 AI 智能体,那么“安全”和“可控”这两个词,大概率已经在你脑海里盘旋过无数次了。我接触过不少团队,从最初的兴奋于 AI 智…...

如何快速找回压缩包密码:ArchivePasswordTestTool完整使用指南
如何快速找回压缩包密码:ArchivePasswordTestTool完整使用指南 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 你是否曾经遇到过…...

从极坐标栅格到地面点云:一种基于坡度与邻域一致性的分割实践
1. 极坐标栅格构建:自动驾驶的"地面扫描仪" 想象你正在玩一款赛车游戏,车辆需要自动识别哪些是能开的平坦路面,哪些是必须绕开的障碍物。现实中自动驾驶车辆面临同样的挑战,而极坐标栅格就是它的"地面扫描仪"…...

告别AT指令恐惧症:用ESP-01S和51单片机,5分钟搞定手机远程开关灯
从零到一的智能家居初体验:ESP-01S与51单片机极简联动方案 第一次接触物联网硬件开发时,那些密密麻麻的AT指令确实容易让人望而生畏。但当我真正用ESP-01S模块配合最基础的51单片机,在五分钟内实现了手机远程开关LED灯的那一刻,所…...

基于图特征选择与XGBoost的电动公交预测性维护模型构建
1. 项目概述:从数据洪流到精准预警的挑战在电动公交的日常运营中,车辆控制器局域网(CAN)总线每秒都在产生海量的传感器数据,从电池电压、电机温度到刹车片厚度,这些数据流如同车辆的“生命体征”。预测性维…...

终极指南:Python通达信数据接口MOOTDX完整使用教程
终极指南:Python通达信数据接口MOOTDX完整使用教程 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx MOOTDX是一款基于Python的高效通达信数据接口封装,专为量化投资和金融数…...