Spark【Spark SQL(二)RDD转换DataFrame、Spark SQL读写数据库 】
从 RDD 转换得到 DataFrame
Saprk 提供了两种方法来实现从 RDD 转换得到 DataFrame:
- 利用反射机制推断 RDD 模式
- 使用编程方式定义 RDD 模式
下面使用到的数据 people.txt :
Tom, 21
Mike, 25
Andy, 181、利用反射机制推断 RDD 模式
在利用反射机制推断 RDD 模式的过程时,需要先定义一个 case 类,因为只有 case 类才能被 Spark 隐式地转换为DataFrame对象。
object Tese{// 反射机制推断必须使用 case 类,case class 必须放到main方法之外case class Person(name: String,age: Long) //定义一个case类def main(args: Array[String]): Unit = {val spark = SparkSession.builder().master("local[*]").appName("rdd to df 1").getOrCreate()import spark.implicits._ //这里的spark不是org.apache.spark这个包 而是我们创建的SparkSession对象 它支持把一个RDD隐式地转换为一个 DataFrame对象val rdd: RDD[Person] = spark.sparkContext.textFile("data/sql/people.txt").map(line => line.split(",")).map(t => Person(t(0), t(1).trim.toInt))// 将RDD对象转为DataFrame对象val df: DataFrame = rdd.toDF()df.createOrReplaceTempView("people")spark.sql("SELECT * FROM people WHERE age > 20").show()spark.stop()}
}注意事项1:
case 类必须放到伴生对象下,main方法之外,因为在隐式转换的时候它会自动通过 伴生对象名.case类名 来调用case类,如果放到main下面就找不到了。
注意事项2:
import spark.implicits._这里的spark不是org.apache.spark这个包 而是我们上面创建的SparkSession对象 它支持把一个RDD隐式地转换为一个 DataFrame对象
2、使用编程方式定义 RDD 模式
反射机制推断时需要定义 case class,但当无法定义 case 类时,就需要采用编程式来定义 RDD 模式了。这种方法看起来比较繁琐,但是很好用,不容易报错。
我们现在同样加载 people.txt 中的数据,生成 RDD 对象,再把RDD对象转为DataFrame对象,进行SparkSQL 查询。主要包括三个步骤:
- 制作表头 schema: StructType
- 制作表中记录 rowRDD: RDD[Row]
- 合并表头和记录 df:DataFramw
def main(args: Array[String]): Unit = {val spark = SparkSession.builder().master("local[*]").appName("rdd to df 2").getOrCreate()//1.制作表头-也就是定义表的模式val schema: StructType = StructType(Array(StructField("name", StringType, true),StructField("age", IntegerType, true)))//2.加载表中的记录-也就是读取文件生成RDDval rowRdd: RDD[Row] = spark.sparkContext.textFile("data/sql/people.txt").map(_.split(",")).map(attr => Row(attr(0), attr(1).trim.toInt))//3.把表头和记录拼接在一起val peopleDF: DataFrame = spark.createDataFrame(rowRdd, schema)peopleDF.createOrReplaceTempView("people")spark.sql("SELECT * FROM people WHERE age > 20").show()spark.stop()}运行结果:
+----+---+
|name|age|
+----+---+
| Tom| 21|
|Mike| 25|
+----+---+Spark SQL读取数据库
导入依赖
根据自己本地的MySQL版本导入对应的驱动。
注意:mysql8.0版本在JDBC中的url是:" com.mysql.cj.jdbc.Driver "
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.31</version></dependency>读取 MySQL 中的数据
def main(args: Array[String]): Unit = {val spark = SparkSession.builder().master("local[*]").appName("jdbc spark sql").getOrCreate()val mysql: DataFrame = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/spark").option("driver", "com.mysql.cj.jdbc.Driver").option("dbtable", "student").option("user", "root").option("password", "Yan1029.").load()mysql.show()spark.stop()}运行结果:
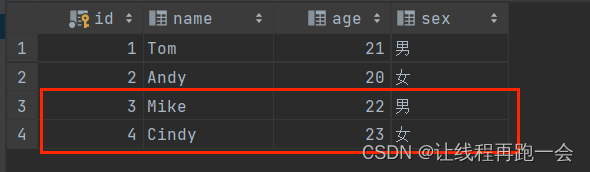
默认显示整张表
+---+----+---+---+
| id|name|age|sex|
+---+----+---+---+
| 1| Tom| 21| 男|
| 2|Andy| 20| 女|
+---+----+---+---+向 MySQL 写入数据
def main(args: Array[String]): Unit = {val spark = SparkSession.builder().master("local[*]").appName("jdbc spark sql").getOrCreate()//导入两条student信息val rdd: RDD[Array[String]] = spark.sparkContext.parallelize(Array("3 Mike 22 男", "4 Cindy 23 女")).map(_.split(" "))//设置模式信息-创建表头val schema: StructType = StructType(Array(StructField("id", IntegerType, true),StructField("name", StringType, true),StructField("age", IntegerType, true),StructField("sex", StringType, true)))//创建Row对象 每个 Row对象都是表中的一行-创建记录val rowRDD = rdd.map(stu => Row(stu(0).toInt, stu(1), stu(2).toInt, stu(3)))//创建DataFrame对象 拼接表头和记录val df = spark.createDataFrame(rowRDD, schema)//创建一个 prop 变量 用来保存 JDBC 连接参数val prop = new Properties()prop.put("user","root")prop.put("password","Yan1029.")prop.put("driver","com.mysql.cj.jdbc.Driver")//写入数据 采用 append 模式追加df.write.mode("append").jdbc("jdbc:mysql://localhost:3306/spark","spark.student",prop)spark.stop()}运行结果:
总结
今天上午就学到这里,本想着今天专门看看StructType、StructField和Row这三个类的,没想到就在这节课。这一篇主要学了RDD对象向DataFrame对象的转换以及Spark SQL如何读取数据库、写入数据库。
下午学完这一章最后的DataSet。
相关文章:
Spark【Spark SQL(二)RDD转换DataFrame、Spark SQL读写数据库 】
从 RDD 转换得到 DataFrame Saprk 提供了两种方法来实现从 RDD 转换得到 DataFrame: 利用反射机制推断 RDD 模式使用编程方式定义 RDD 模式 下面使用到的数据 people.txt : Tom, 21 Mike, 25 Andy, 18 1、利用反射机制推断 RDD 模式 在利用反射机制…...
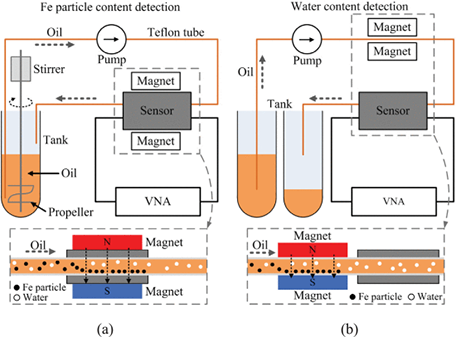
LabVIEW检测润滑油中的水分和铁颗粒
LabVIEW检测润滑油中的水分和铁颗粒 润滑油广泛应用于现代机械设备,由于工作环境日益恶劣,润滑油经常被水分乳化,加速对机械设备的腐蚀。此外,润滑油还受到机械零件摩擦中产生的Fe颗粒的污染,削弱了其机械润滑效果。润…...

【新版】系统架构设计师 - 软件架构设计<SOA与微服务>
个人总结,仅供参考,欢迎加好友一起讨论 架构 - 软件架构设计<SOA与微服务> 考点摘要 面向服务SOA(★★★★)微服务(★★★★) 基于/面向服务的(SOA) 在SO…...
React+Typescript+react-router 6 创建路由操作
本文我们来看看路由的安装 其实路由的操作没有什么变化 但是还是给大家讲一下 那么我们打开项目 在项目终端输入 npm install --save react-router react-router-dom安装 一下 react-router 和 react-router-dom 这都是react开发很基本的插件了 不过大家安装前先注意好我的版…...
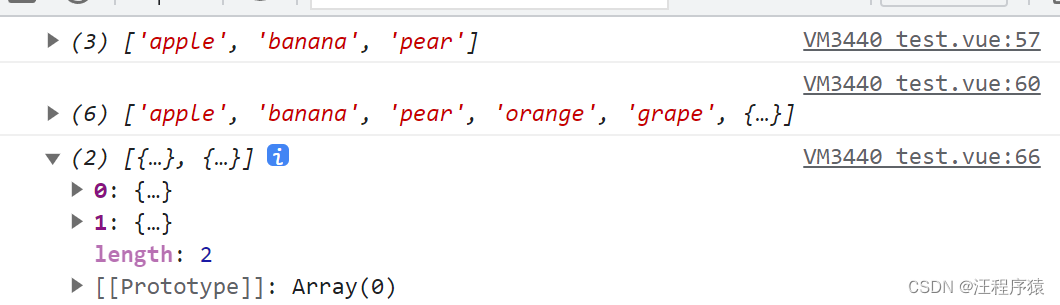
前端list.push,封装多个对象
js var fruit [apple, banana];fruit.push(pear);console.log(fruit); // [apple, banana, pear]现在为对象 data1:{addUser: 1,editUser: 1,addTime: null,editTime: 1527410579000,userId: 3,systemNo: mc,userName: zengzhuo,userPassword: e10adc3949ba59abbe56e057f20f88…...

指令延迟隐藏
一、指令延迟隐藏 1. 延迟和延迟隐藏 指令延迟指计算指令从调度到指令完成所需的时钟周期如果在每个时钟周期都有就绪的线程束可以被执行,此时GPU处于满符合状态指令延迟被GPU满负荷计算状态所掩盖的现象称为延迟隐藏延迟隐藏对GPU编程开发很重要,GPU设…...

《React vs. Vue vs. Angular:2023年的全面比较》
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...
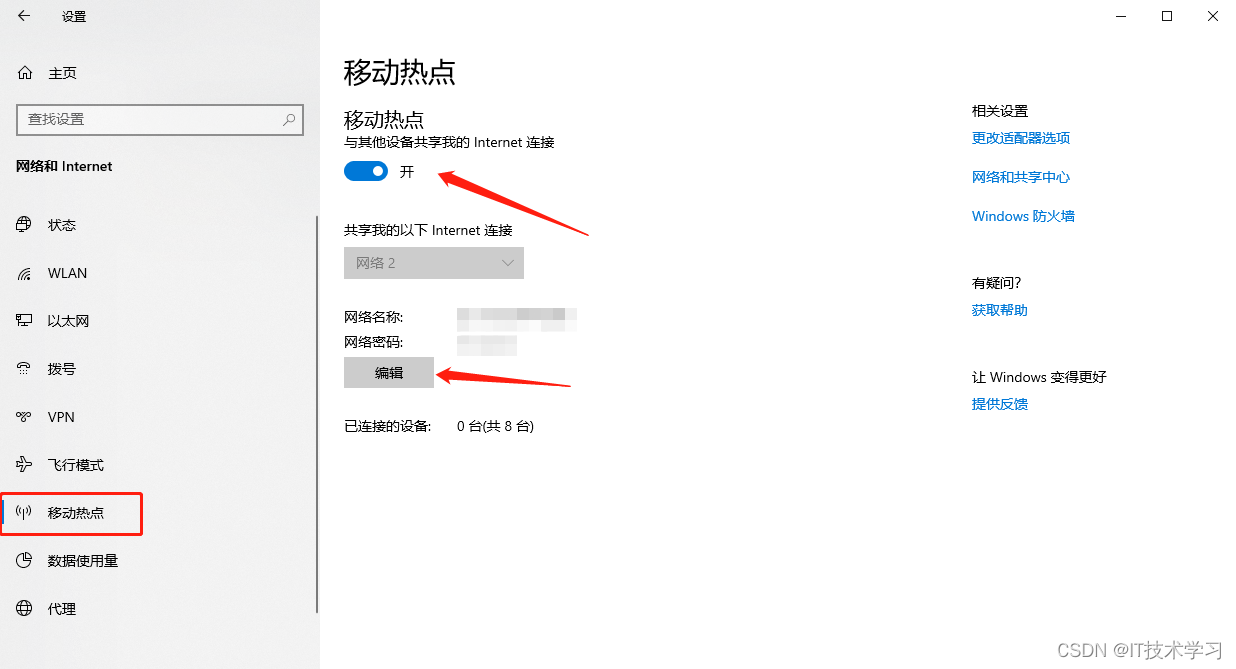
win10自带wifi共享功能
1、按下【wini】组合键打开windows设置,点击【网络和internet】; 2、按照下图,打开个移动热点,设置名称、密码。...
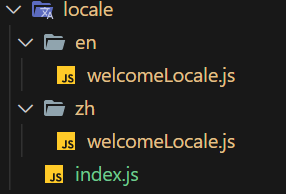
React如何实现国际化?
目录 一、Redux准备工作 commonTypes.js commonActions.js commonReducer.js rootReducer.js 二、然后定义SelectLang组件 index.js index.less 三、创建语言包 welcomeLocale.js index.js 四、使用 react的入口文件 App.js welcome.js 附 关于如何实现国际…...

netrw模拟nerdtree的go命令连续打开多个文件
vim9自带的文件浏览器netrw功能很强大。过去用惯了nerdtree的我,对netrw的文件操作还要适应一些时间。 使用netrw一段时间后发现它没有nerdtree的go命令的替代操作,今天就自制一个。 一、制作go命令: nerdtree的go命令功能:就是…...
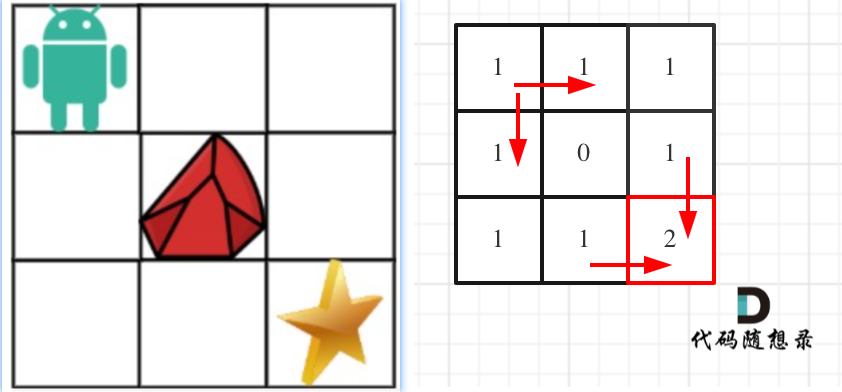
算法通关村第十九关——动态规划高频问题(白银)
算法通关村第十九关——动态规划高频问题(白银) 前言1 最少硬币数2 最长连续递增子序列3 最长递增子序列4 完全平方数5 跳跃游戏6 解码方法7 不同路径 II 前言 摘自:代码随想录 动态规划五部曲: 确定dp数组(dp tabl…...
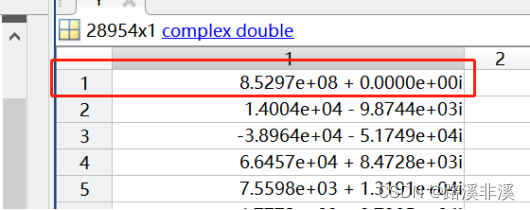
Matlab如何导入Excel数据并进行FFT变换
如果你发现某段信号里面有干扰,想要分析这段信号里面的频率成分,就可以使用matlab导入Excel数据后进行快速傅里叶变换(fft)。 先直接上使用方法,后面再补充理论知识。 可以通过串口将需要分析的数据发送到串口助手&a…...
华为mate60 上线 媒介盒子多家媒体报道
为什么你的品牌营销不见效?如何能推动品牌破圈?让媒介盒子给你一些启发。本期盒子要跟大家分享地新机上市,数码科技行业企业该如何做线上宣传。 HUAWEI Mate 60系列8月29日官宣发布,出色的拍照功能、强大的性能表现和持久的续航能…...

Java知识总结(持续更新)
一、JDK、JRE、JVM三者之间的关系? 1. **JDK (Java Development Kit)**: JDK 是 Java 开发工具包,它包含了用于开发 Java 应用程序的所有必要工具和库。这包括 Java 编译器(javac)、Java 核心类库、开发工具&#x…...

缓存技术:加速应用,提高用户体验
本文总结前期某个系统中使用到的缓存使用经验—仅此而已,效果还不错。 缓存技术在系统架构设计中扮演着至关重要的角色,它不仅可以显著提高系统的性能,还可以改善用户体验。在本文章中,我们将探讨不同类型的缓存、缓存失效以及缓存淘汰等关键概念,帮助在后期的架构设计中…...

MySQL中分区与分表的区别
MySQL中分区与分表的区别 一、分区与分表的区别 分区和分表是在处理大规模数据时的两种技术手段,尽管它们的目标都是提升系统的性能和数据管理的效率,但它们的实现方式和应用场景略有不同。 1. 分区 分区是将一个大表分割为多个更小的子表,…...
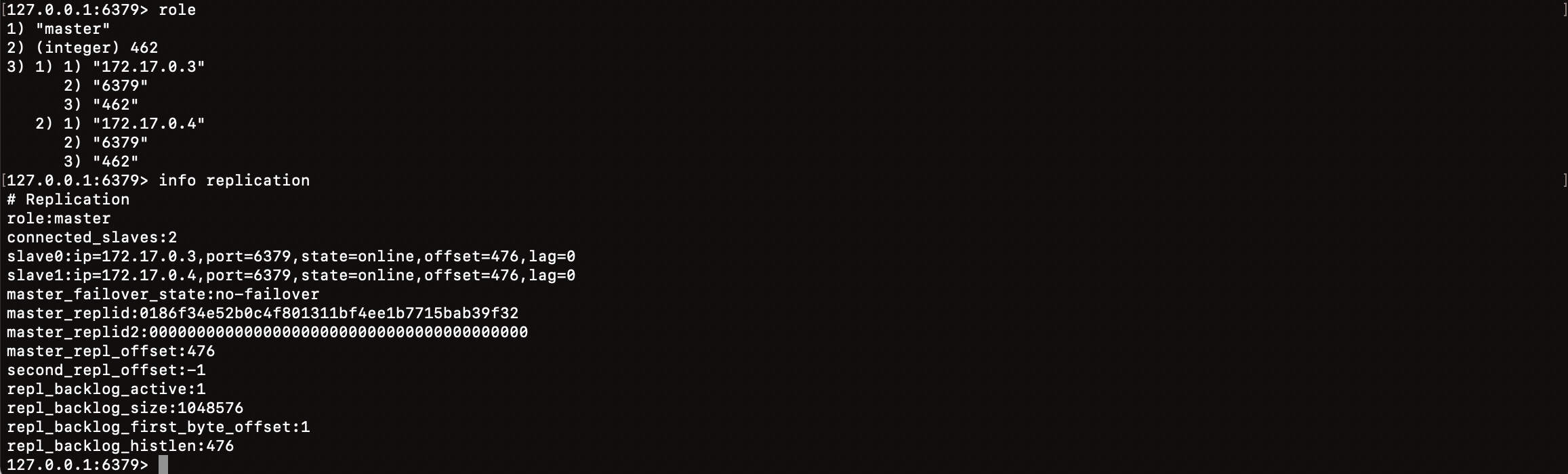
Redis主从复制集群的介绍及搭建
在现代的软件开发中,数据的可靠性和可用性是至关重要的。Redis,作为一个开源的、内存中的数据结构存储系统,以其出色的性能和灵活的数据结构,赢得了开发者们的广泛喜爱。而 Redis 的主从复制功能,更是为我们提供了一种…...

MAC M1芯片安装mounty读写移动硬盘中的文件
因为移动硬盘中的文件是微软公司NTFS格式,MAC只支持自己的APFS或者HFS,与微软的NTFS不兼容,所以需要第三方的软件来支持读写硬盘中的文件,经过一上午的折腾,最终选择安装mounty这个免费的第三方软件 工具网址连接&am…...

原生Js Canvas去除视频绿幕背景
Js去除视频背景 注: 这里的去除视频背景并不是对视频文件进行操作去除背景 如果需要对视频扣除背景并导出可以使用ffmpeg等库,这里仅作播放用所以采用这种方法 由于uniapp中的canvas经过封装,且 uniapp 的 drawImage 无法绘制视频帧画面&…...
每天10个小知识点)
Vue知识系列(1)每天10个小知识点
目录 系列文章目录知识点**1. Vue修饰符**的概念、作用、原理、特性、优点、缺点、区别、使用场景**2. 双向数据绑定**的概念、作用、原理、特性、优点、缺点、区别、使用场景**3. MVVM、MVC、MVP** 的概念、作用、原理、特性、优点、缺点、区别、使用场景**4. slot** 的概念、…...

Android跨平台文件同步技术实现:WebDAV桥接工具架构深度解析
Android跨平台文件同步技术实现:WebDAV桥接工具架构深度解析 【免费下载链接】webdav-provider An Android app that can expose WebDAV storage to other apps through Androids Storage Access Framework (SAF) 项目地址: https://gitcode.com/gh_mirrors/we/we…...

知识竞赛代表队分组方法详解
🎲 知识竞赛代表队分组方法详解公平 均衡 策略 让每一支队伍都在合适的起点🎯 引言知识竞赛中,代表队的合理分组是赛事公平与精彩的基础。无论是学校比赛、企业活动还是大型公开赛,组织者都需要根据队伍数量和赛制选择合适的分…...

Winhance中文版:Windows系统优化终极指南,3分钟让电脑焕然一新
Winhance中文版:Windows系统优化终极指南,3分钟让电脑焕然一新 【免费下载链接】Winhance-zh_CN A Chinese version of Winhance. C# application designed to optimize and customize your Windows experience. 项目地址: https://gitcode.com/gh_mir…...

终极指南:3分钟学会用Onekey下载Steam游戏清单,告别手动烦恼
终极指南:3分钟学会用Onekey下载Steam游戏清单,告别手动烦恼 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 想要快速获取Steam游戏清单却苦于复杂操作?Oneke…...

GHelper终极指南:3步掌握华硕笔记本性能控制秘籍
GHelper终极指南:3步掌握华硕笔记本性能控制秘籍 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Expertb…...

DDoS攻击:企业与个人都应了解的基本知识
一、DDoS攻击的基本原理 DDoS攻击的基本原理在于通过超载目标系统、服务或网络的资源,使其无法正常响应合法用户的请求。这类攻击通常涉及大量计算机或设备,这些设备被操纵成一个庞大的“僵尸网络”(botnet)。攻击者利用这个庞大…...

桌面端酷安社区体验:Coolapk UWP 完整使用指南
桌面端酷安社区体验:Coolapk UWP 完整使用指南 【免费下载链接】Coolapk-UWP 一个基于 UWP 平台的第三方酷安客户端 项目地址: https://gitcode.com/gh_mirrors/co/Coolapk-UWP 你是否曾经希望在电脑大屏幕上舒适地浏览酷安社区,摆脱手机小屏幕的…...

基于RAG与本地LLM的智能代码库管理工具部署与优化指南
1. 项目概述:一个为开发者打造的智能代码库管理工具最近在整理自己过去几年的项目代码时,我遇到了一个几乎所有开发者都会头疼的问题:代码库越来越多,但想快速找到某个特定功能的实现、或者想复用一段之前写过的优质代码时&#x…...

Beyond Compare 5 开源密钥生成器:逆向工程与授权机制的深度解析
Beyond Compare 5 开源密钥生成器:逆向工程与授权机制的深度解析 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 在软件安全与逆向工程领域,授权验证机制始终是开发者与安…...

Ryujinx模拟器三部曲:从新手到专家的Switch游戏PC体验进阶指南
Ryujinx模拟器三部曲:从新手到专家的Switch游戏PC体验进阶指南 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx 你是否曾梦想在电脑上畅玩《塞尔达传说:旷野之息…...