6.2.2 【MySQL】InnoDB中的索引方案
上边之所以称为一个简易的索引方案,是因为我们为了在根据主键值进行查找时使用二分法快速定位具体的目录项而假设所有目录项都可以在物理存储器上连续存储,但是这样做有几个问题:
InnoDB 是使用页来作为管理存储空间的基本单位,也就是最多能保证 16KB 的连续存储空间,而随着表中记录数量的增多,需要非常大的连续的存储空间才能把所有的目录项都放下,这对记录数量非常多的表是不现实的。
我们时常会对记录进行增删,假设我们把 页28 中的记录都删除了, 页28 也就没有存在的必要了,那意味着 目录项2 也就没有存在的必要了,这就需要把 目录项2 后的目录项都向前移动一下。
所以需要一种管理所有目录项的方式。目录项中的两个列是主键和页号,所以他们复用了之前存储用户记录的数据页来存储目录项,为了和用户记录做一下区分,我们把这些用来表示目录项的记录称为 目录项记录 。那 InnoDB 怎么区分一条记录是普通的 用户记录 还是 目录项记录 呢?别忘了记录头信息里的record_type 属性,它的各个取值代表的意思如下:
0 :普通的用户记录
1 :目录项记录
2 :最小记录
3 :最大记录

从图中可以看出来,我们新分配了一个编号为 30 的页来专门存储 目录项记录 。这里再次强调一遍 目录项记录和普通的 用户记录 的不同点:
目录项记录 的 record_type 值是1,而普通用户记录的 record_type 值是0。
目录项记录 只有主键值和页的编号两个列,而普通的用户记录的列是用户自己定义的,可能包含很多列,另外还有 InnoDB 自己添加的隐藏列。
还记得我们之前在唠叨记录头信息的时候说过一个叫 min_rec_mask 的属性么,只有在存储 目录项记录 的页中的主键值最小的 目录项记录 的 min_rec_mask 值为 1 ,其他别的记录的 min_rec_mask 值都是 0 。
除了上述几点外,这两者就没啥差别了,它们用的是一样的数据页(页面类型都是 0x45BF ,这个属性在 FileHeader 中,忘了的话可以翻到前边的文章看),页的组成结构也是一样一样的(就是我们前边介绍过的7个部分),都会为主键值生成 Page Directory (页目录),从而在按照主键值进行查找时可以使用二分法来加快查询速度。现在以查找主键为 20 的记录为例,根据某个主键值去查找记录的步骤就可以大致拆分成下边两步:
1. 先到存储 目录项记录 的页,也就是页 30 中通过二分法快速定位到对应目录项,因为 12 < 20 < 209 ,所以定位到对应的记录所在的页就是 页9 。
2. 再到存储用户记录的 页9 中根据二分法快速定位到主键值为 20 的用户记录。
虽然说 目录项记录 中只存储主键值和对应的页号,比用户记录需要的存储空间小多了,但是不论怎么说一个页只有 16KB 大小,能存放的 目录项记录 也是有限的,那如果表中的数据太多,以至于一个数据页不足以存放所有的 目录项记录 ,该咋办呢?
当然是再多整一个存储 目录项记录 的页~ 为了大家更好的理解新分配一个 目录项记录 页的过程,我们假设一个存储 目录项记录 的页最多只能存放4条 目录项记录 (请注意是假设哦,真实情况下可以存放好多条的),所以如果此时我们再向上图中插入一条主键值为 320 的用户记录的话,那就需要分配一个新的存储 目录项记录的页:
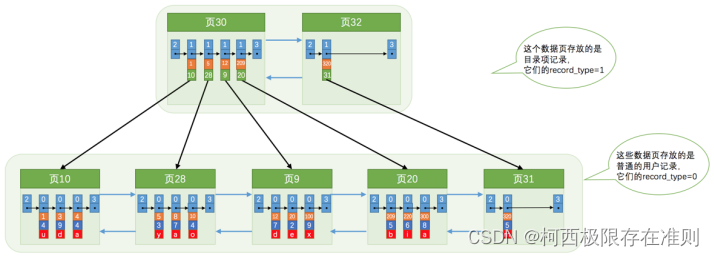
从图中可以看出,我们插入了一条主键值为 320 的用户记录之后需要两个新的数据页:
为存储该用户记录而新生成了 页31 。
因为原先存储 目录项记录 的 页30 的容量已满(我们前边假设只能存储4条 目录项记录 ),所以不得不需要一个新的 页32 来存放 页31 对应的目录项。
现在因为存储 目录项记录 的页不止一个,所以如果我们想根据主键值查找一条用户记录大致需要3个步骤,以查找主键值为 20 的记录为例:
1. 确定 目录项记录 页我们现在的存储 目录项记录 的页有两个,即 页30 和 页32 ,又因为 页30 表示的目录项的主键值的范围是[1, 320) , 页32 表示的目录项的主键值不小于 320 ,所以主键值为 20 的记录对应的目录项记录在 页30中。
2. 通过 目录项记录 页确定用户记录真实所在的页。
3. 在真实存储用户记录的页中定位到具体的记录。
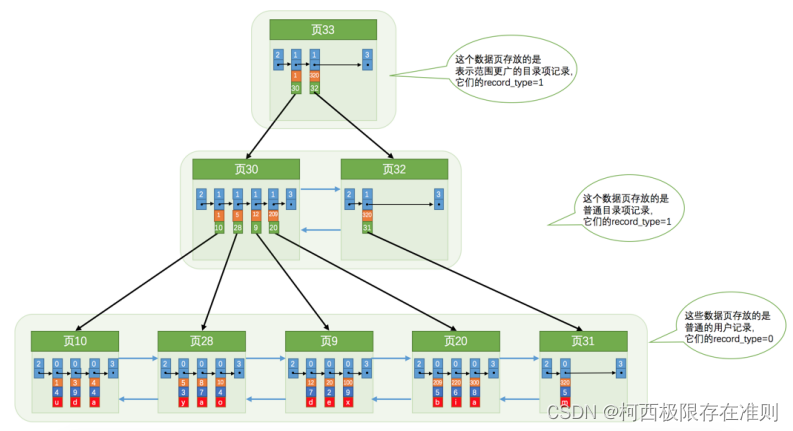
如图,我们生成了一个存储更高级目录项的 页33 ,这个页中的两条记录分别代表 页30 和 页32 ,如果用户记录的主键值在 [1, 320) 之间,则到 页30 中查找更详细的 目录项记录 ,如果主键值不小于 320 的话,就到 页32中查找更详细的 目录项记录 。随着表中记录的增加,这个目录的层级会继续增加,这个就是B+树。
不论是存放用户记录的数据页,还是存放目录项记录的数据页,我们都把它们存放到 B+ 树这个数据结构中了,所以我们也称这些数据页为 节点 。从图中可以看出来,我们的实际用户记录其实都存放在B+树的最底层的节点上,这些节点也被称为 叶子节点 或 叶节点 ,其余用来存放 目录项 的节点称为 非叶子节点 或者 内节点 ,其中 B+ 树最上边的那个节点也称为 根节点 。
不论是存放用户记录的数据页,还是存放目录项记录的数据页,我们都把它们存放到 B+ 树这个数据结构中了,所以我们也称这些数据页为 节点 。从图中可以看出来,我们的实际用户记录其实都存放在B+树的最底层的节点上,这些节点也被称为 叶子节点 或 叶节点 ,其余用来存放 目录项 的节点称为 非叶子节点 或者 内节点 ,其中 B+ 树最上边的那个节点也称为 根节点 。
6.2.2.1 聚簇索引
我们上边介绍的 B+ 树本身就是一个目录,或者说本身就是一个索引。它有两个特点:
1. 使用记录主键值的大小进行记录和页的排序,这包括三个方面的含义:
页内的记录是按照主键的大小顺序排成一个单向链表。
各个存放用户记录的页也是根据页中用户记录的主键大小顺序排成一个双向链表。
存放目录项记录的页分为不同的层次,在同一层次中的页也是根据页中目录项记录的主键大小顺序排成一个双向链表。
2. B+ 树的叶子节点存储的是完整的用户记录。
所谓完整的用户记录,就是指这个记录中存储了所有列的值(包括隐藏列)。
我们把具有这两种特性的 B+ 树称为 聚簇索引 ,所有完整的用户记录都存放在这个 聚簇索引 的叶子节点处。这种 聚簇索引 并不需要我们在 MySQL 语句中显式的使用 INDEX 语句去创建(后边会介绍索引相关的语句),InnoDB 存储引擎会自动的为我们创建聚簇索引。另外有趣的一点是,在 InnoDB 存储引擎中, 聚簇索引 就是数据的存储方式(所有的用户记录都存储在了 叶子节点 ),也就是所谓的索引即数据,数据即索引。
6.2.2.2 二级索引
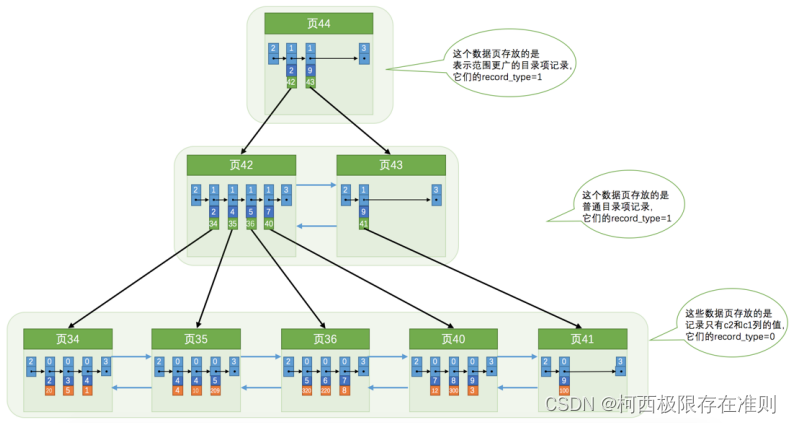
这个 B+ 树与上边介绍的聚簇索引有几处不同:
使用记录 c2 列的大小进行记录和页的排序,这包括三个方面的含义:
- 页内的记录是按照 c2 列的大小顺序排成一个单向链表。
- 各个存放用户记录的页也是根据页中记录的 c2 列大小顺序排成一个双向链表。
- 存放目录项记录的页分为不同的层次,在同一层次中的页也是根据页中目录项记录的 c2 列大小顺序排成一个双向链表。
B+ 树的叶子节点存储的并不是完整的用户记录,而只是 c2列+主键 这两个列的值。
目录项记录中不再是 主键+页号 的搭配,而变成了 c2列+页号 的搭配。
所以如果我们现在想通过 c2 列的值查找某些记录的话就可以使用我们刚刚建好的这个 B+ 树了。以查找 c2 列的值为 4 的记录为例,查找过程如下:
1. 确定 目录项记录 页
根据 根页面 ,也就是 页44 ,可以快速定位到 目录项记录 所在的页为 页42 (因为 2 < 4 < 9 )。
2. 通过 目录项记录 页确定用户记录真实所在的页。
在 页42 中可以快速定位到实际存储用户记录的页,但是由于 c2 列并没有唯一性约束,所以 c2 列值为 4 的记录可能分布在多个数据页中,又因为 2 < 4 ≤ 4 ,所以确定实际存储用户记录的页在 页34 和 页35 中。
3. 在真实存储用户记录的页中定位到具体的记录。
到 页34 和 页35 中定位到具体的记录。
4. 但是这个 B+ 树的叶子节点中的记录只存储了 c2 和 c1 (也就是 主键 )两个列,所以我们必须再根据主键值去聚簇索引中再查找一遍完整的用户记录。
联合索引
我们也可以同时以多个列的大小作为排序规则,也就是同时为多个列建立索引,比方说我们想让 B+ 树按照 c2和 c3 列的大小进行排序,这个包含两层含义:
- 先把各个记录和页按照 c2 列进行排序。
- 在记录的 c2 列相同的情况下,采用 c3 列进行排序
为 c2 和 c3 列建立的索引的示意图如下:

如图所示,我们需要注意一下几点:
- 每条 目录项记录 都由 c2 、 c3 、 页号 这三个部分组成,各条记录先按照 c2 列的值进行排序,如果记录的 c2 列相同,则按照 c3 列的值进行排序。
- B+ 树叶子节点处的用户记录由 c2 、 c3 和主键 c1 列组成。
千万要注意一点,以c2和c3列的大小为排序规则建立的B+树称为联合索引,本质上也是一个二级索引。它的意思与分别为c2和c3列分别建立索引的表述是不同的,不同点如下:
- 建立 联合索引 只会建立如上图一样的1棵 B+ 树。
- 为c2和c3列分别建立索引会分别以 c2 和 c3 列的大小为排序规则建立2棵 B+ 树。
相关文章:
6.2.2 【MySQL】InnoDB中的索引方案
上边之所以称为一个简易的索引方案,是因为我们为了在根据主键值进行查找时使用二分法快速定位具体的目录项而假设所有目录项都可以在物理存储器上连续存储,但是这样做有几个问题: InnoDB 是使用页来作为管理存储空间的基本单位,也…...

划片机实现装片、对准、切割、清洗到卸片的自动化操作
划片机是一种用于切割和分离材料的设备,通常用于光学和医疗、IC、QFN、DFN、半导体集成电路、GPP/LED氮化镓等芯片分立器件、LED封装、光通讯器件、声表器件、MEMS等行业。划片机可以实现从装片、对准、切割、清洗到卸片的自动化操作。 以下是划片机实现这些操作的步…...

OpenCV(二十五):边缘检测(一)
目录 1.边缘检测原理 2.Sobel算子边缘检测 3.Scharr算子边缘检测 4.两种算子的生成getDerivKernels() 1.边缘检测原理 其原理是基于图像中灰度值的变化来捕捉图像中的边界和轮廓。梯度则表示了图像中像素强度变化的强弱和方向。 所以沿梯度方向找到有最大梯度值的像素&…...

上行取消指示 DCI format 2_4
上篇介绍了DCI format 2_1的DL传输中断的内容,这篇就看下DCI format 2_4有关的UL 传输取消机制,值得注意的是这里的UL传输针对的是PUSCH和SRS传输。 UL cancellation DCI format 2_4相关机制引入的背景与DCI format 2_1一样,都是因为URLLC和e…...
百望云蝉联2023「Cloud 100 China 」榜单 综合实力再获认可
9月7日,2023 Cloud 100 China 榜单于上海中心正式发布,榜单由靖亚资本与崔牛会联合推出,百望云凭借着过硬的综合实力与卓越的技术创新能力,再次荣登榜单,位居第六位。 本届评选,Top 100 企业的数据指标的权…...

力扣刷题班第1节:Python语法常遗漏的知识
以下仅仅记录和后面力扣刷题相关的、且平常会遗漏的语法知识。 下面这些笔记都是点到为止,不进行深入解释。大多数学过python的朋友看到就知道什么意思的,我就不解释了 字符串 str "I am a cook"# 按照空格切分 str.split(" ") …...

GET 和 POST请求的区别是什么
GET和POST是HTTP请求的两种基本方法,要说它们的区别,接触过WEB开发的人都能说出一二。 最直观的区别就是GET把参数包含在URL中,POST通过request body传递参数。 你轻轻松松的给出了一个“标准答案”: GET在浏览器回退时是无害的…...
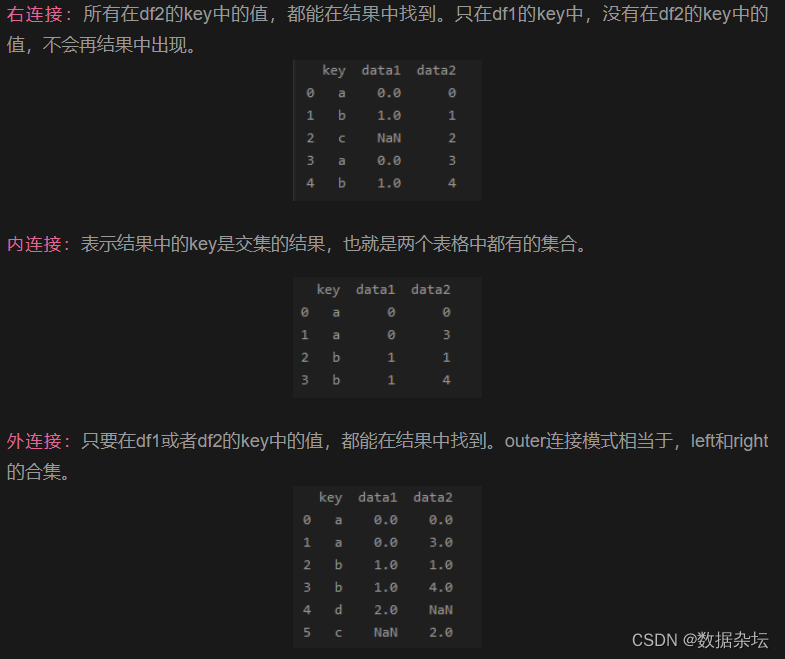
Python数据分析实战-表连接-merge四种连接方式用法(附源码和实现效果)
实现功能 表连接-merge四种连接方式用法, 将两个pandas表根据一个或者多个键(列)值进行连接。 实现代码 import pandas as pddf1 pd.DataFrame({key: [a, b, d],data1: range(3)}) print(df1)df2 pd.DataFrame({key: [a, b, c, a, b],dat…...

NFTScan 浏览器再升级:优质数据服务新体验来袭
当前,高质量的 NFT 数据服务已成为区块链用户和开发者的必需。为满足用户数据需求,NFTScan 主站近日进行全面升级,优化了数据服务板块的页面结构,实现更清晰简洁的布局和交互。 NFTScan 的改版充分考虑用户和开发者的数据体验&am…...
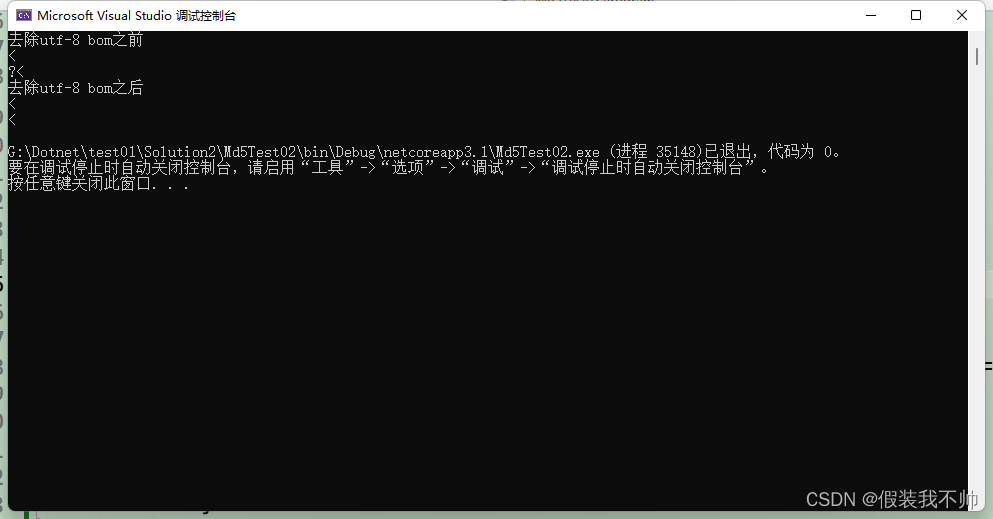
C# 去除utf-8 BOM头
static void Main(string[] args) {var a1 Encoding.UTF8.GetBytes("<");var a2 Encoding.UTF8.GetBytes("<");Console.WriteLine("去除utf-8 bom之前");Console.WriteLine(Encoding.UTF8.GetString(a1));Console.WriteLine(…...

Java注解以及自定义注解
Java注解以及自定义注解 要深入学习注解,我们就必须能定义自己的注解,并使用注解,在定义自己的注解之前,我们就必须要了解Java为 我们提供的元注解和相关定义注解的语法。 1、注解 1.1 注解的官方定义 注解是一种元数据形式。…...
[开学季]ChatPaper全流程教程
文章目录 1. 粗筛:论文全文总结1.1 使用步骤: 1.2 功能描述:2. 论文问答:2. 精读:学术版GPT的论文翻译2.0 论文精读的正确姿势2.1 使用场景1:arxiv论文完美翻译2.2 本地PDF全文翻译:2.3 关于免费…...

Spring学习笔记——4
Spring学习笔记——4 一、基于AOP的声明式事务控制1.1、Spring事务编程概述1.2、搭建测试环境1.3、基于XML声明式事务控制1.4、基于注解声明式事务控制 二、Spring整合web环境2.1、JavaWeb三大组件作用及其特点2.2、Spring整合web环境的思路及实现2.3、Spring的Web开发组件spri…...

Python数据科学入门
推荐:使用 NSDT场景编辑器 快速搭建3D应用场景 来自不同角色的人都希望保住自己的工作,因此他们将致力于发展自己的技能以适应当前的市场。这是一个竞争激烈的市场,我们看到越来越多的人对数据科学产生兴趣;该行业有数千门在线课程、训练营和…...

Ubuntu 22.04 编译 DPDK 19.11 igb_uio 和 kni 报错解决办法
由于 Ubuntu22.04 内核版本和gcc版本比较高,在编译dpdk时会报错。 我使用的编译命令是: make install Tx86_64-native-linuxapp-gcc主要有以下几个错误: 1.error: this statement may fall through Build kernel/linux/igb_uioCC [M] /roo…...

Android Studio.exe 下载 2023 最新更新,网盘下载
方便大家下载, 放到了网盘上,自己也保留一份。(最前面是最新版本的,慎用, 会有bug什么的) 个人使用4.2版本的,感觉够用稳定,其他版本有莫名奇妙的bug,让人头大࿰…...
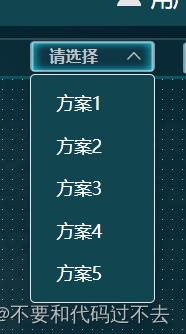
element的el-select给下拉框添加背景
第一步 :popper-append-to-body"false" <el-selectv-model"value"placeholder"请选择":popper-append-to-body"false"><el-optionv-for"item in options":key"item.value":label"item.label&quo…...

正确理解党籍和党龄;入党和转正时间
总的来说党籍、党龄、入党时间、转正时间在性质和时间阶段上均有所区别。 党籍:是指党员资格。经支部党员大会讨论,被批准为预备党员之日起,就有了党籍。若被取消预备党员资格、劝退除名、自行脱党、开除党籍的,就失去了党籍。 …...

C语言基础:printf 函数介绍;以及常用四种常用的数据类型
printf 函数介绍 #include <stdio.h> int main() { /* * %c:字符 ; %d:带符号整数; %f: 浮点数; %s: 一串字符; */ int age21; printf(“hello %s,you are %d years old\n”,“Bob”,age); int i 10; double f96.20; printf(“student number%3d,score%f\n”…...
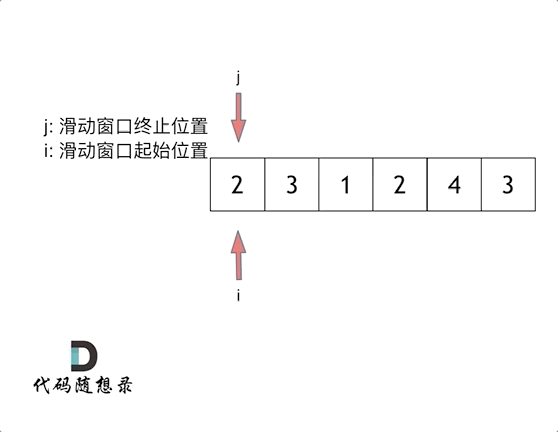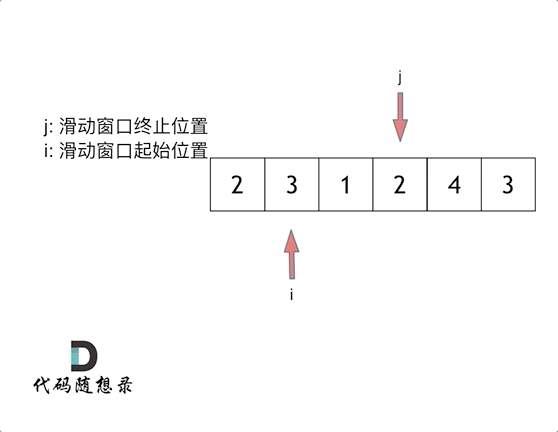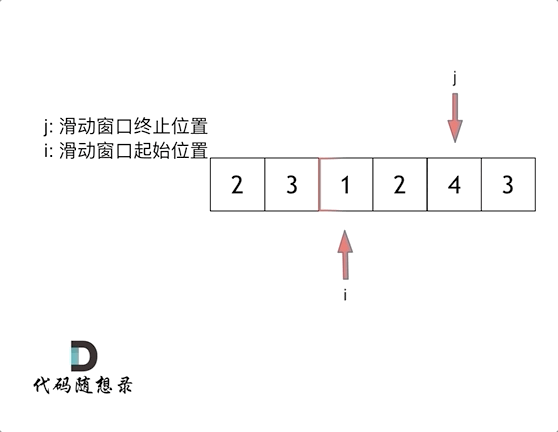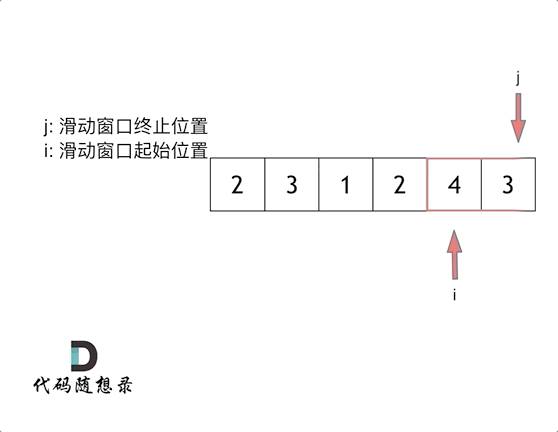
【LeetCode-中等题】209. 长度最小的子数组
文章目录 题目方法一:滑动窗口:方法二: 题目 方法一:滑动窗口: 参考图解动画:长度最小的子数组 class Solution { //方法一:滑动窗口public int minSubArrayLen(int target, int[] nums) {int n nums.l…...

为什么预训练再好的VLA,在新任务上普通SFT 并不好用?CapVector给出了原因和方案
Vision-Language-Action(VLA)模型现在已经很强了。 但一个很现实的问题是: 预训练再充分的 VLA,到了新任务上,普通 SFT 往往并不好用。 很多工作发现: 训练收敛慢少量 demonstration 不够泛化能力并没有…...

下载视频不如用Via,一分都不花
找了很长时间,没想到竟然这么简单,为啥早没发现呢! 工具的名称叫Via浏览器是个App,没错在安卓手机或平板运行的工具。 缺点:pc下用不了,有些视频下不了,如爱奇艺等。苹果手机是否能用不知道,自己试吧。 优点:操作方便、简单,即使你是小白也能熟练操作。免费,一分…...

猫眼启发的亚太赫兹超表面成像系统设计与应用
1. 猫眼启发的亚太赫兹超表面成像系统概述在电磁波成像技术领域,传统系统往往面临视场匹配困难、系统冗余度高以及实时性不足等挑战。受猫眼结构中反光膜(tapetum lucidum)的生物学启发,我们开发了一种创新的主动-被动复合孔径共享…...

深度解析Cyber Engine Tweaks:5大核心技术实现《赛博朋克2077》脚本框架逆向工程
深度解析Cyber Engine Tweaks:5大核心技术实现《赛博朋克2077》脚本框架逆向工程 【免费下载链接】CyberEngineTweaks Cyberpunk 2077 tweaks, hacks and scripting framework 项目地址: https://gitcode.com/gh_mirrors/cy/CyberEngineTweaks Cyber Engine …...

弃ReID跨镜,选镜像无感定位——打破跨镜追踪断链困局,实现全域精准无感感知
弃ReID跨镜,选镜像无感定位——打破跨镜追踪断链困局,实现全域精准无感感知在安防监控、智慧园区、商业综合体、交通枢纽等场景中,跨摄像头目标追踪是核心需求之一——无论是人员轨迹追溯、异常行为预警,还是资产安全管控、流量数…...
)
别再卡在‘Setup is running’了!PowerBuilder 9.0保姆级安装避坑指南(附安全模式备用方案)
PowerBuilder 9.0安装全攻略:从卡死困境到高效部署 "Setup is running"这个看似简单的提示框,曾让无数PowerBuilder开发者陷入漫长的等待和反复的重启循环。作为一款承载了二十余年企业级应用开发记忆的经典工具,PowerBuilder 9.0的…...

历史学博士生紧急避坑指南:NotebookLM误用导致的3类史料误读及权威校验方案
更多请点击: https://intelliparadigm.com 第一章:NotebookLM在历史学研究中的定位与风险图谱 NotebookLM 是 Google 推出的基于用户上传文档构建语义理解模型的实验性工具,其核心能力在于对私有史料(如扫描PDF、OCR文本、手稿转…...
怎么调才有效)
TCN实战避坑指南:从能源预测案例看超参数(kernel_size, dilation_base)怎么调才有效
TCN实战避坑指南:从能源预测案例看超参数调优的艺术 当你的TCN模型在能源预测任务中表现平平,先别急着换架构——很可能只是超参数没调对。上周我们团队刚用TCN完成了一个工业用电量预测项目,原始模型准确率只有72%,经过系统调参后…...
【AI大模型】Transformer 架构是什么?关键模块都有哪些
【AI大模型】Transformer 架构是什么?关键模块都有哪些? Transformer 出自 2017 年经典论文 Attention Is All You Need,它完全抛弃 RNN 结构,仅靠注意力 前馈网络实现序列建模,是现在 GPT、BERT、ViT、T5 等所有大模…...

coding 为什么成为模型前沿主战场
coding 会被推到模型前沿,不奇怪。它可能是少数同时满足三件事的场景:答案能被机器验收,任务能自然拉长,做出来的东西马上能进入真实工作流。 写作文、写报告、做营销文案也有价值,可这些任务的好坏很难稳定判分。代码…...