Document-Level event Extraction via human-like reading process 论文解读
Document-Level event Extraction via human-like reading process

论文:2202.03092v1.pdf (arxiv.org)
代码:无
期刊/会议:ICASSP 2022
摘要
文档级事件抽取(DEE)特别困难,因为它提出了两个挑战:论元分散和多事件。第一个挑战意味着一个事件记录的论元可能存在于文档中的不同句子中,而第二个挑战反映了一个文档可能同时包含多个这样的事件记录。本文以人类的阅读认知为动机,提出了一种HRE (Human reading inspired Extractor for Document Events)方法,将DEE分解为粗略阅读和精细阅读两个迭代阶段。具体来说,第一个阶段浏览文档以检测事件的发生,第二个阶段用于抽取特定的事件论元。对于每个具体的事件角色,详细阅读从句子到字符分层工作,在句子中定位论元,从而解决了论元分散的问题。同时,对粗读进行多轮探索,发现未检测到的事件,从而解决多事件问题。实验结果表明,该方法优于现有的竞争方法。
关键词:自然语言处理,信息抽取,事件抽取,文档级事件抽取
1、简介
事件抽取(EE)旨在识别特定类型的事件,并从给定的文本中抽取相应的事件论元。尽管成功地[1,2,3,4,5,6,7]在句子中抽取事件,也就是句子级EE (SEE),但这些方法似乎在现实场景中妥协,因为事件通常是在句子中表达的。因此,SEE正在向文档级EE发展,即文档级EE (DEE)。
通常,DEE面临两个挑战,论元分散和多事件。如图1所示,第一个挑战表明,一个事件记录的事件论元可能存在于不同的句子中,因此无法从单个句子中抽取事件。第二种反映了文档可能同时包含多个这样的事件记录,这就要求对文档有一个整体的理解,并理解事件之间的相互依赖关系。迄今为止,大多数DEE方法[8,9,10,11]主要关注第一个挑战,而忽略了第二个挑战。虽然zheng等人[12] (2019)首次提出Doc2EDAG来同时解决这两个挑战,提出的面向实体的方法不能充分模拟多事件之间的依赖关系,导致最终性能不理想。

近年来,模拟人类的阅读认知过程来解决特定的自然语言处理(NLP)任务[13,14]已经实现了更好的效果。人类的阅读过程通常分为三个阶段[15,16,17]:pre-reading、careful reading和post-reading。在pre-reading过程中,人类读者对整个文档进行预览,形成对文档内容的一般认知。在careful reading中,人类读者会根据自己的阅读目的仔细阅读每句话,找到详细的信息。在post-reading中,对文档进行回顾,检查遗漏的细节并完成对文档的理解。从粗到细的多阶段阅读过程理解文档,这使得在整个文档中抽取事件事实变得有效。然而,到目前为止,很少有文献探讨DEE的阅读过程。
为了模拟上述思想,本文提出了一种名为HRE (Human Reading inspired Extractor for Document Events)的DEE方法,将人类的阅读过程重新格式化为粗读(rough reading) 和 精读(elaborate reading) 两个阶段。对于每个特定的事件类型,首先进行粗读以检测事件的发生。如果检测到事件,则应用精读以论元方式抽取完整的事件记录。具体来说,对于每个事件角色,精读首先定位对应的论元在哪个句子中,然后抽取出来。每个抽取的事件论元都由内存机制存储,该机制模拟了多事件之间的相互依赖关系,并使HRE能够意识到先前抽取的事件。在获得一个完整的事件记录后,HRE再次粗读文档,以检查相同事件类型的缺失事件,并且内存机制使它能够检测到与之前抽取的事件没有冗余的事件。如果感知到另一个事件发生,将再次应用精读,否则,HRE将通过上述相同的逻辑处理下一个事件类型,直到处理所有事件类型。通过对多个事件之间相互依赖关系的记忆机制建模,对粗读的多轮探索释放了多事件挑战。同时,对于每个事件角色,精读分别搜索与论元相关的句子,这样句子间的论元都能被定位,自然地解决了论元分散的问题。在最大DEE数据集[12]上的实验结果表明,HRE实现了一种新的最先进的性能。
2、方法
DEE的最终目标是抽取所有事件记录,并正确判断事件类型和论元。算法1展示了HRE的整体工作流程。请注意,内存机制被设计为在两个读取阶段工作,其中,对于每个事件类型,我们使用一个可训练的事件类型特定的嵌入eee_eee来初始化内存张量mem_eme,并且通过附加以下抽取的事件论元来更新mem_eme。内存张量对事件之间的相互依赖进行建模,使粗读能够区分丢失的事件和抽取的事件,并支持使用论元级上下文进行精读。

2.1 基础编码
给定一个包含NNN个句子的文档DDD,基本编码包括三个步骤来生成字符、句子和文档的上下文表示。首先,对每个句子SjS_jSj分别采用一个句子编码器,推导出每个句子中的字符表示为Sj=[cj,1,cj,2,…,cj,n]S_j = [c_{j,1}, c_{j,2},\ldots, c_{j,n}]Sj=[cj,1,cj,2,…,cj,n],其中cj,k∈Rdc_{j,k} \in \mathbb{R}^dcj,k∈Rd, nnn为SjS_jSj中的字符数,ddd为字符表示的维数。接下来,max-pooling应用于每个句子SjS_jSj,以获得原始句子表示sjrs^r_jsjr,然后,使用文档编码器用于[s1r,s2r,…,sNr][s^r_1, s^r_2,\ldots, s^r_N][s1r,s2r,…,sNr],得到文档感知的句子表示s=[s1,s2,…,sN],sj∈Rd,s∈RN×ds = [s_1, s_2,\ldots, s_N], s_j \in \mathbb{R}^d, s\in \mathbb{R}^{N×d}s=[s1,s2,…,sN],sj∈Rd,s∈RN×d。最后,对sss应用max-pooling,生成文档表示D∈RdD \in \mathbb{R}^dD∈Rd。
2.2 粗读
粗读可以检测事件的发生。正如算法1所示,粗读也用于检查缺失的事件,它需要内存来避免与之前抽取的事件进行冗余检测。具体来说,我们利用内存张量mem_eme上的内存编码器来实现事件之间的信息流,并细化先前的eee类型事件,如下所示:
m^e=SumPooling(MemEnc(me))\hat m_e = \text{SumPooling}(\text{MemEnc}(m_e)) m^e=SumPooling(MemEnc(me))
其中m^e∈Rd\hat m^e∈\mathbb{R}^dm^e∈Rd为汇总内存。当第一次对eee类型事件应用粗读时,me∈R(1)×dm_e∈\mathbb{R}^{(1)×d}me∈R(1)×d仅包含随机初始化的事件类型嵌入eee_eee;当应用粗读来检查缺失的事件时,me∈R(1+lm)×dm_e∈\mathbb{R}^{(1+l_m)×d}me∈R(1+lm)×d包含eee_eee和lml_mlm抽取的事件论元表示。
我们从文档中删除有关先前事件的信息,并计算文档中未抽取的eee类型事件发生的概率pep_epe,如下所示:
D^=D−m^e,pe=sigmoid(Ws(tanh(WdD^+Wtee)))\hat D=D-\hat m_e,\\ p_e=\text{sigmoid}(W_s(tanh(W_d \hat D +W_t e_e))) D^=D−m^e,pe=sigmoid(Ws(tanh(WdD^+Wtee)))
其中D∈RdD∈\mathbb{R}^dD∈Rd和D^∈Rd\hat D∈\mathbb{R}^dD^∈Rd分别是原始的和可感知冗余的文档表示,Ws,Wd,WtW_s, W_d, W_tWs,Wd,Wt是可训练参数。如果pep_epe大于预定义的阈值,HRE会感知到一个未抽取的eee类型事件,然后利用精读来抽取论元,否则,HRE将处理下一个事件类型。
在训练过程中,我们使用二进制交叉熵损失对pep_epe进行粗读,以检测事件的发生。由于在一个文档中使用了多次粗读,因此我们将每次粗读的所有损失相加为LrrL_{rr}Lrr。
2.3 精读
在HRE检测到一个eee类型事件的发生后,详细的读取工作将按照预定义的事件角色顺序[12]逐个抽取具体的事件论元。对于每个事件角色,将构造一个查询来明确读取目标,该查询细化了当前事件角色和先前抽取的论元之间的相互依赖关系。具体来说,我们利用Memory-Encoder将先前的论元上下文表示注入到角色嵌入中,如下所示:
[r‾ei;m‾e]=MemEncc(rei;me)[\overline r_e^i;\overline m_e]=\text{MemEncc}(r_e^i;m_e) [rei;me]=MemEncc(rei;me)
其中[⋅;⋅][·;·][⋅;⋅]表示连接操作,rei∈R1×dr^i_e∈\mathbb{R}^{1×d}rei∈R1×d是eee型事件的第iii个角色的可训练的角色特定嵌入,me∈R(1+lm)×dm_e∈ \mathbb{R}^{(1+l_m)×d}me∈R(1+lm)×d是原始内存张量,MemEnc是等式1中使用的编码器。我们利用r‾ei∈R1×d\overline r^i_e∈\mathbb{R}^{1×d}rei∈R1×d作为key来抽取当前事件角色的论元。
句子定位模块定位目标论元所在的句子。在一个句子中,共享相同事件角色的论元在某种程度上彼此语义相似,因此我们首先对先前抽取的论元信息进行过滤,如下所示:
g=sigmoid(Wl([m^e;sj])),s^j=sj−sj∗gg=\text{sigmoid}(W_l([\hat m_e;s_j])),\\ \hat s_j=s_j - s_j *g g=sigmoid(Wl([m^e;sj])),s^j=sj−sj∗g
其中m^e∈Rd\hat m_e∈\mathbb{R}^dm^e∈Rd是等式1中相同的记忆概括,sj∈Rds_j∈\mathbb{R}^dsj∈Rd是句子表示,“[·;·]”是产生[m^e;sj]∈R2d[\hat m_e;s_j]∈\mathbb{R}^{2d}[m^e;sj]∈R2d, ggg为控制信息冗余的门。然后,HRE选择第jjj句为:
zs=Attention(r‾ei,s^)=softmax(r‾eis^Td),j=argmax(zs)z_s=\text{Attention}(\overline r_e^i,\hat s)=\text{softmax}(\frac{\overline r_e^i \hat s^T}{\sqrt{d}}),\\ j=\text{argmax}(z_s) zs=Attention(rei,s^)=softmax(dreis^T),j=argmax(zs)
其中:s∈RN×ds∈\mathbb{R}^{N×d}s∈RN×d是文档中所有句子的冗余感知句子表示,zs∈RN×1z_s∈\mathbb{R}^{N×1}zs∈RN×1是通过缩放的点积[18]注意力计算出的每个句子的相关性得分,并选择得分最高的句子进行相应的论元抽取。
在训练中,我们使用对zsz_szs的交叉熵损失来指导句子的位置,正确句索引作为标签。在一个文档中,我们将每个句子位置的所有损失相加为LslL_{sl}Lsl。
论元抽取模块的目的是抽取特定的事件论元并更新内存张量。对于一个事件角色,假设HRE决定从第jjj句中抽取论元,将进行一些初步操作作为准备。首先,将查询嵌入r‾ei\overline r_e^irei添加到每个字符表示cj,kc_{j,k}cj,k中,用事件相关知识丰富句子。然后在句子后面加上一个符号“[STOP]”,表示为对应的角色嵌入reir^i_erei,表示抽取的结束。这两个操作可以表述为:
S^j=[cj,1+r‾ei,cj,2+r‾ei,…,cj,n+r‾ei,rei]\hat S_j=[c_{j,1}+\overline r_e^i,c_{j,2}+\overline r_e^i,\ldots,c_{j,n}+\overline r_e^i,r_e^i] S^j=[cj,1+rei,cj,2+rei,…,cj,n+rei,rei]
论元由一系列字符复制操作从json中抽取,如下所示:
v0=r‾ei,k=argmax(AttnScore(vtS^j)),vt+1=S^j[k]v_0=\overline r_e^i,\\ k=\text{argmax}(AttnScore(v_t \hat S_j)),\\ v_{t+1}=\hat S_j[k] v0=rei,k=argmax(AttnScore(vtS^j)),vt+1=S^j[k]
第jjj句中的第kkk个字符被复制。v0v_0v0被初始化为r‾ei\overline r_e^irei来定位目标论元的第一个字符,在每一个时间步ttt中,得到最大分数的字符被复制并用作vt+1v_{t+1}vt+1。复制操作直到“[STOP]”被复制才会结束。假设复制字符cj,k,cj,k+1,cj,k+2c_{j,k}, c_{j,k+1}, c_{j,k+2}cj,k,cj,k+1,cj,k+2和“[STOP]”,对有效标记应用最大池化,导出参数表示argrei∈Rd\text{arg}_{r_e^i}∈\mathbb{R}^dargrei∈Rd为:
argrei=MaxPooling([cj,k;cj,k+1;cj,k+2])arg_{r_e^i}=\text{MaxPooling}([c_{j,k};c_{j,k+1};c_{j,k+2}]) argrei=MaxPooling([cj,k;cj,k+1;cj,k+2])
在训练中,我们使用对AttnScore(vt,S^j)AttnScore(v_t, \hat S_j)AttnScore(vt,S^j)的交叉熵损失来指导论元字符复制过程,其中,在每个时间步ttt中,使用标准论元字符索引作为标签。我们将每个文档中的所有字符拷贝损失相加为LaeL_{ae}Lae。
内存更新模块将每个抽取的论元附加到内存张量mem_eme,使每个读取阶段都知道先前抽取的论元。由于单个实体的语义可能很少,我们将实体和相应的句子表示融合在一起,以如下方式更新内存:
me=[me;(argrei+si)]m_e=[m_e;(\arg_{r_e^i}+s_i)] me=[me;(argrei+si)]
其中更新的内存张量me∈R(lm+2)×dm_e∈\mathbb{R}^{(l_m+2)×d}me∈R(lm+2)×d包含lm+1l_m+ 1lm+1个论元,将在下一个读取阶段使用。
2.4 训练目标
我们将精读中粗读、句子定位和论点抽取的损失总和为Lall=λ1Lrr+λ2Lsl+λ3LaeL_{all} = λ_1L_{rr} + λ_2L_{sl} + λ_3L_{ae}Lall=λ1Lrr+λ2Lsl+λ3Lae,并共同优化。λ1=1.0,λ2=1.0,λ3=0.9λ_1=1.0,λ_2=1.0,λ_3=0.9λ1=1.0,λ2=1.0,λ3=0.9为平衡不同子任务的系数。
3、实验
3.1 实验设置
数据集和评估指标:中文金融文档级事件抽取数据集;Precision、Recall、F1-score。
实验细节:我们遵循Zheng等人(2019)[12]来设置超参数。我们将字符嵌入的维度设置为768,事件发生的粗读阈值设置为0.5。最大句子数和句子长度分别为64句和128句。句子编码器、文档编码器和记忆编码器采用Transformer编码器[18]。
Baseline:DCFEE、Doc2EDAG、GreedyDec、ArgSpan。
3.2 主要的实验结果


3.3 详细分析
消融实验:为了探究不同成分的贡献,我们分别对粗读和精读进行了分析。表2反映了:(1)删除等式2中的内存探索会导致最差的性能,因为HRE总是判断是否有缺失的事件,并从文档中检测先前抽取的事件。(2)在原句子表示上进行句子定位,而不是在冗余意识表示上进行句子定位,结果在F1上下降了1.9%。这证实了删除冗余信息的必要性。(3)查询是必不可少的,它细化了之前事件之间的相互依赖关系,因为消融实验对F1造成了2.4%的伤害。(4)在没有将查询添加到字符表示的情况下,结果降级显示了事件相关信息在论元抽取中的重要性。

计算成本分析。我们从两个方面讨论了HRE和Doc2EDAG之间的计算开销。(1)我们将推理速度作为时间计算成本,推理速度是指在模型推理过程中,模型每秒可以处理的文档数量。具体来说,HRE的推理速度为5.9Docs/s,而Doc2EDAG的推理速度为7.2Docs/s。(2)利用模型参数的数量来表示空间计算代价。其中HRE的参数量为70.5 m, Doc2EDAG的参数量为66.8M。虽然HRE的成本略高于Doc2EDAG,但我们认为HRE的额外成本是值得的,因为它在整体F1上比Doc2EDAG提高了2.3%,并且在DEE的两个挑战上表现出色。
3.4 实例分析

4、总结
在本文中,我们提出了针对DEE任务的HRE (Human Reading inspired Extractor for Document Events)。HRE包括两个阶段,粗读检测事件的发生,精读抽取具体的事件论元。据我们所知,我们率先探索了DEE的阅读认知过程,实验证明了其有效性。在未来,我们希望进一步将HRE应用于文档级关系抽取任务。
相关文章:
Document-Level event Extraction via human-like reading process 论文解读
Document-Level event Extraction via human-like reading process 论文:2202.03092v1.pdf (arxiv.org) 代码:无 期刊/会议:ICASSP 2022 摘要 文档级事件抽取(DEE)特别困难,因为它提出了两个挑战:论元分散和多事件。第一个挑战…...
H5盲盒抽奖系统源码
盲盒抽奖系统4.0,带推广二维码防洪炮灰功能和教程。 支持微信无限回调登录 标价就是源码价格,vuetp5框架编写,H5网页,前后端分离 此源码为正规开发,正版产品已申请软著。 开源无加密无授权,可以二开使用…...
低代码平台和无代码平台哪个更适合开发企业管理系统?
编者按:本文分析了开发企业管理系统所需要的平台特性,并根据这些特点和低代码无代码的优劣比较,得出低代码平台更适合开发企业管理系统。关键词:私有化部署,可视化设计,源码交付,数据集成&#…...

75岁彪马再发NFT 复活美洲狮IP
在“运动品牌Web3”的潮流里,彪马(PUMA)绝对算是发烧友级别。2月22日,这家德国服装品牌的新NFT又来了,总量10000个Super PUMA NFT中,将有4000个以0.15 ETH(约为255美元)价格正式公售…...

大学生成人插画培训机构盘点
成人插画培训机构哪个好,成人学插画如何选培训班?给大家梳理了国内较好的插画培训机构排名,各有优势和特色,供大家参考! 一:国内成人插画培训机构排名 1、轻微课(五颗星) 主打课程有…...
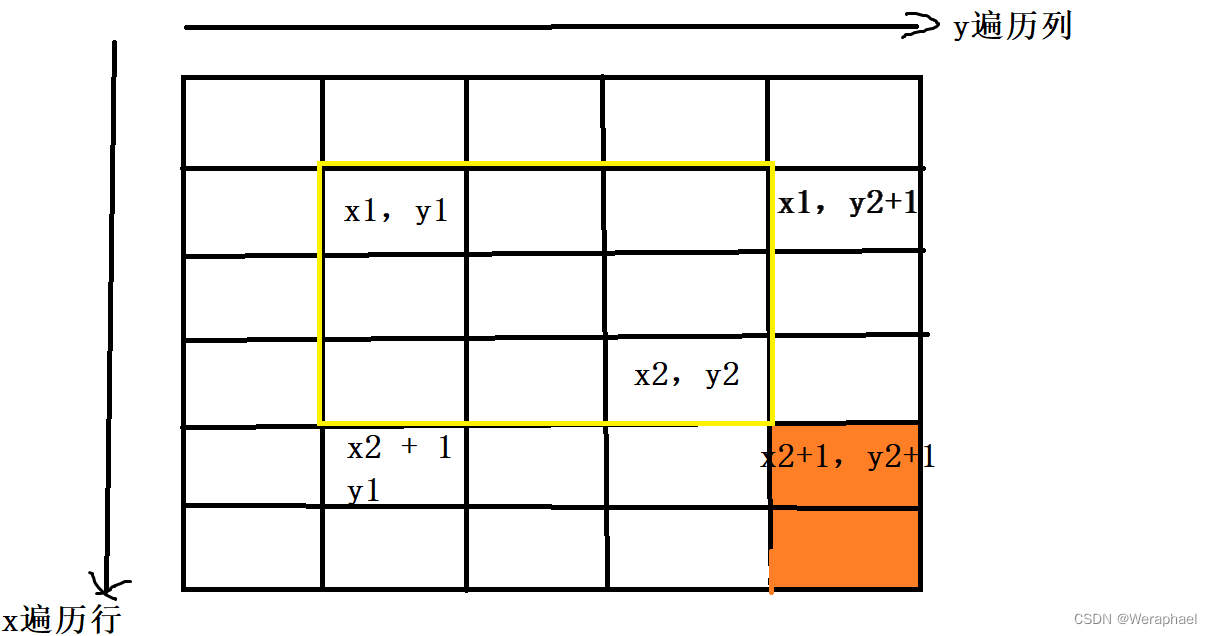
【算法基础】一维差分 + 二维差分
👦个人主页:Weraphael ✍🏻作者简介:目前正在学习c和算法 ✈️专栏:【C/C】算法 🐋 希望大家多多支持,咱一起进步!😁 如果文章有啥瑕疵 希望大佬指点一二 如果文章对你有…...

游戏服务器框架 技能buff篇
游戏服务器框架 技能buff篇 1.状态 state 全局API 用于定义各种状态检查 bool IsDead(){ // 死亡buff if (buff->id 10001){ return true; } return false; } bool IsInvincible(){ if (buff->id 20001 || buff->id 20002){…...
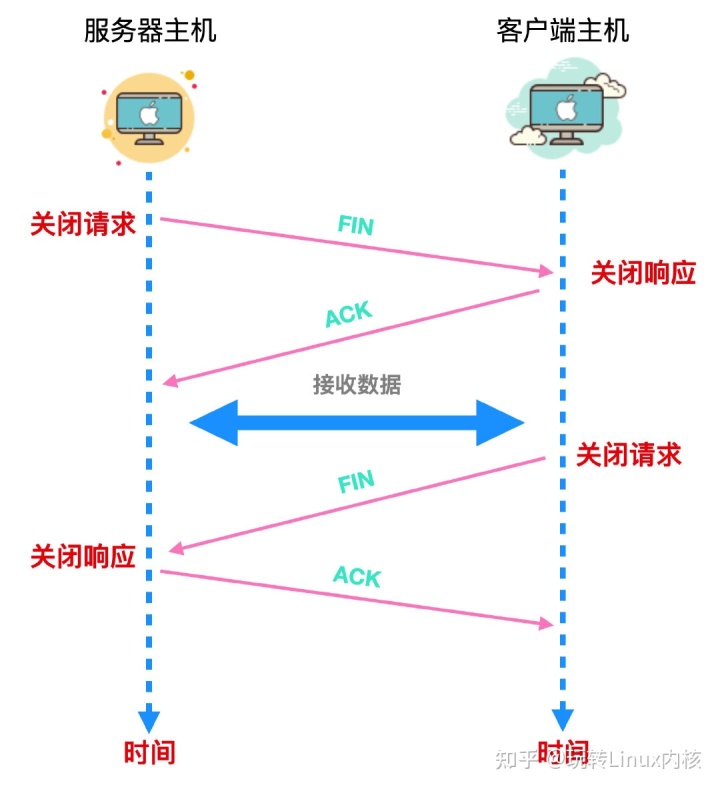
网友说socket通信讲的不彻底,原来这才是Socket
关于对 Socket 的认识,大致分为下面几个主题,Socket 是什么,Socket 是如何创建的,Socket 是如何连接并收发数据的,Socket 套接字的删除等。 Socket 是什么以及创建过程 一个数据包经由应用程序产生,进入到…...
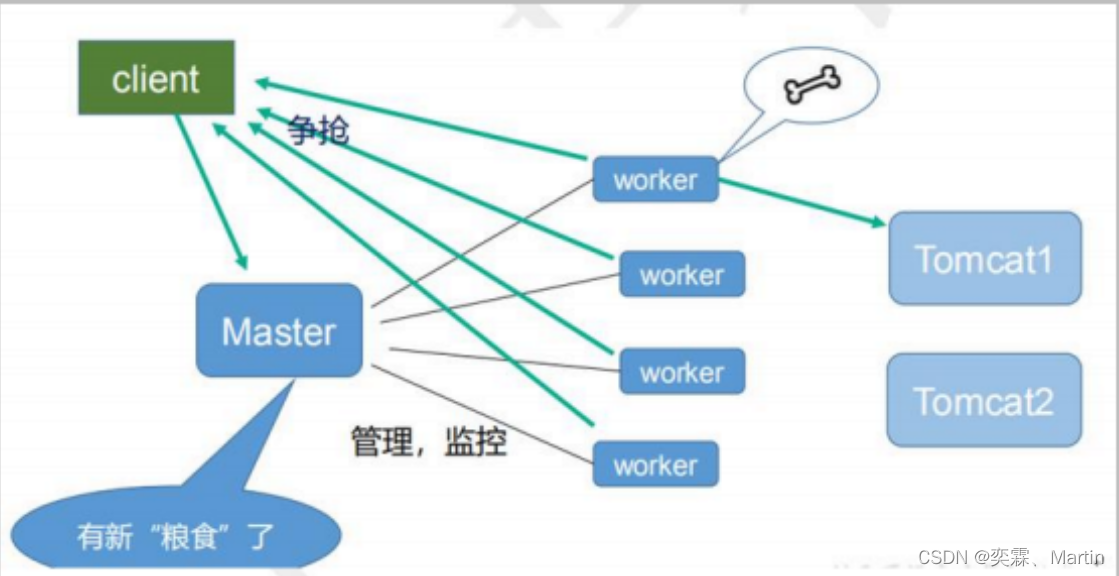
Nginx第二讲
目录 二、Nginx02 2.1 keepalived和heartbeat介绍 2.1.1 两者的介绍 2.1.2 keepalived简介 2.1.3 VRRP协议与工作原理 2.1.4 Keepalvied的工作原理 2.2 安装环境及keepalived 2.3 启动与验证keepalived 2.4 keepalived测试 2.4.1 环境准备 2.4.2 配置keepalived 2.…...
redis(win版)
1. 前言1.1 什么是RedisRedis是一个基于内存的key-value结构数据库。Redis 是互联网技术领域使用最为广泛的存储中间件,它是「Remote Dictionary Service」的首字母缩写,也就是「远程字典服务」。基于内存存储,读写性能高适合存储热点数据&am…...
【Linux】编辑器——vim(最小集+指令集+自动化配置)
目录 1.vim最小集 1.1 vim的三种模式 1.2 vim的基本操作 2.vim指令集 2.1 命令模式指令集 移动光标 删除文字 复制 替换 撤销上一次操作 更改 跳至指定的行 2.2 底行模式指令集 列出行号 跳到文件中的某一行 查找字符 保存文件 多文件操作 3.如何配置vim 配…...

Centos7+Xshell+Jenkins堆装
windows系统崩坏,重装测试类工具,心情崩了 windows硬盘损坏前,运行应用具慢。。。。。。慢着慢着就走了 从前部署在本地的jenkins,python,gitblit等相关脚本都凉透了,所以这次把服务部署到Centos7上…...

Android system实战 — Android R(11) 进程保活白名单
Android system实战 — Android R 进程保活白名单0. 前言1. 具体实现1.1 准备工作1.2 源码实现1.2.1 源码1.2.2 diff文件0. 前言 最近在Android R上实现一些需求,进行记录一下,关于进程保活的基础知识可以参考Android system — 进程生命周期与ADJ&#…...

oracle表 分组,并查每组第一条
oracle主要用到的函数:OVER(PARTITION BY) mysql主要用到的函数:LIMIT (用到3个地方:分组列、组内排序列、表名) oracle: select t.* from ( select a.*, ROW_NUMBER() OVER (PARTITION BY 分组列 ORDER BY 组内排…...
)
Java代码弱点与修复之——DE: Dropped or ignored exception(无视或忽略异常)
弱点描述 Dropped or ignored exception(DE)指的是在代码中抛出的异常被捕获后被无视或忽略了,而不是被适当地处理。这种情况通常发生在程序员没有处理异常或处理异常时不小心忽略了异常的情况下。 Dropped or ignored exception会导致程序无法正常工作,因为异常会阻塞程…...
JavaEE简单示例——动态SQL之更新操作<set>元素
简单介绍: 在之前我们做的学生管理系统的时候,曾经有一个环节是修改学生的数据。我们在修改的时候是必须将student对象的三个属性全部填入信息,然后全部修改才可以,这样会造成一个问题就是在我们明明只需要修改一个属性的时候却要…...
【极海APM32替代笔记】低功耗模式配置及配置汇总
【极海APM32替代笔记】低功耗模式配置及配置汇总 文章总结:(后续更新以相关文章为准) 【STM32笔记】低功耗模式、WFI命令等进入不了休眠的可能原因(系统定时器SysTick一直产生中断) 【STM32笔记】HAL库低功耗模式配置…...

攻击者失手,自己杀死了僵尸网络 KmsdBot
此前,Akamai 的安全研究员披露了 KmsdBot 僵尸网络,该僵尸网络主要通过 SSH 爆破与弱口令进行传播。在对该僵尸网络的持续跟踪中,研究人员发现了一些有趣的事情。 C&C 控制 对恶意活动来说,最致命的就是夺取对 C&C 服务…...

东阿县高新技术企业认定条件和优惠政策 山东同邦科技分享
东阿县高新技术企业认定条件和优惠政策 山东同邦科技分享 高新技术企业 在《国家重点支持的高新技术领域》内,持续进行研究开发与技术成果转化,形成企业核心自主知识产权,并以此为基础开展经营活动,在中国境内(不包…...

【基础算法】哈希表(拉链法)
🌹作者:云小逸 📝个人主页:云小逸的主页 📝Github:云小逸的Github 🤟motto:要敢于一个人默默的面对自己,强大自己才是核心。不要等到什么都没有了,才下定决心去做。种一颗树,最好的时间是十年前…...

Windows Cleaner深度解析:从C盘爆红到系统性能全面优化的完整方案
Windows Cleaner深度解析:从C盘爆红到系统性能全面优化的完整方案 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner Windows Cleaner是一款完全免费开源…...

智能识别告警系统完整方案
智能识别告警系统完整方案 一、整体业务目标 摄像头实时抓拍/上传图片 → 服务器AI推理识别 → 判定是否佩戴厨师帽、是否违规洗澡、人员靠近闯入等行为 → 违规自动告警推送 → 识别效果不佳时走标准化模型/数据集调优流程 二、全流程业务链路 前端采集层:现场摄像…...

Pico手柄+XRI 2.5交互系统实战:射线点击与抓取避坑指南
1. 这不是“拖拽组件就能跑通”的Demo,而是真正在Pico设备上能稳定抓取杯子、推开箱子、精准点击UI的交互系统Unity XR Interaction Toolkit(简称XRI)这两年在XR开发圈里热度很高,但很多人一上手就卡在“手柄动了,但啥…...

2026年怎么安装OpenClaw?阿里云部署及配置Token Plan保姆级指南
2026年怎么安装OpenClaw?阿里云部署及配置Token Plan保姆级指南。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token Plan兼容主…...

ARMv9 SME指令集:FDOT浮点点积操作深度解析
1. SME指令集与浮点点积操作概述在当代处理器架构设计中,向量化计算能力已成为衡量芯片性能的关键指标。作为ARMv9架构的重要扩展,SME(Scalable Matrix Extension)指令集专门针对矩阵运算进行了深度优化,其中多向量浮点…...

CentOS 7无线网络配置避坑指南:wpa_supplicant vs NetworkManager,我该选哪个?
CentOS 7无线网络配置终极方案:从命令行到GUI的完整决策树在Linux服务器管理领域,无线网络配置始终是个充满挑战的话题。当你在数据中心角落发现一台需要无线连接的CentOS 7服务器,或是需要在无网线接入的会议室临时部署服务时,选…...
原理与边缘计算应用实践)
脉冲神经网络(SNN)原理与边缘计算应用实践
1. 脉冲神经网络技术解析:从生物启发的计算范式到普适计算实践脉冲神经网络(SNN)作为第三代神经网络模型,其设计灵感直接来源于生物神经系统的运作机制。与传统人工神经网络(ANN)相比,SNN最显著…...

Unity安卓游戏开发实战:从构建失败到上线合规的工程化路径
1. 为什么“精通Unity安卓游戏开发”不是一句口号,而是一道必须拆解的工程题很多人看到“精通Unity安卓游戏开发”这个标题,第一反应是:不就是用Unity写个游戏,然后点一下Build Android?我做过三个小游戏,打…...

Keil C51中绝对地址变量初始化问题解析
1. 问题背景与核心需求在嵌入式开发中,特别是使用Keil C51这类经典工具链时,开发者经常需要将变量精确分配到特定的内存地址。这种需求在硬件寄存器映射、共享内存区域或特定外设控制等场景下尤为常见。最近我在一个8051项目开发中就遇到了这样的需求&am…...

用100行PyTorch代码实现扩散模型:从理论到实战的完整指南
用100行PyTorch代码实现扩散模型:从理论到实战的完整指南 【免费下载链接】Diffusion-Models-pytorch Pytorch implementation of Diffusion Models (https://arxiv.org/pdf/2006.11239.pdf) 项目地址: https://gitcode.com/gh_mirrors/di/Diffusion-Models-pytor…...