Pytorch 多卡并行(1)—— 原理简介和 DDP 并行实践
- 近年来,深度学习模型的规模越来越大,需要处理的数据也越来越多,单卡训练的显存空间和计算效率都越来越难以满足需求。因此,多卡并行训练成为了一个必要的解决方案
- 本文主要介绍使用 Pytorch 的
DistributedDataParallel(DDP)库进行分布式数据并行训练的方法
文章目录
- 1. 多卡并行简介
- 1.1 两种并行形式
- 1.2 Pytorch 中的多卡并行
- 2. 使用 DDP 进行单机多卡训练
- 2.1 原理概述
- 2.2 使用 DDP 改写单卡训练代码
1. 多卡并行简介
- 多卡并行训练主要用于解决以下几个问题:
- 相同 batch size 下加速训练:多卡并行可以将数据分为多份同时在不同的GPU上运行,从而大大加快训练速度
- 相同速度下使用更大的 batch size:多卡并行可以在多个GPU之间共享显存,允许我们设置更大的 batch size
- 增加可训练的模型规模:有些模型参数多到单卡训练无法承受,而多卡并行可以将模型放入多个GPU中,从而扩充可训练模型的规模
1.1 两种并行形式
-
多卡并行训练有数据并行和模型并行两种形式

-
数据并行:每个GPU都保存一个模型副本,训练数据划分成多份交给各个GPU计算梯度,然后汇总梯度更新模型参数。根据梯度汇总的方式,数据并行又可以分成Parameter Server和Ring All-Reduce两种,前者使用一个 master GPU 汇总梯度更新参数,再将参数分发给各个模型;后者以环的形式互相传递梯度,每个GPU都维护一个优化器,各自汇总梯度并自行更新模型参数。Ring All-Reduce 方案能更高效地利用所有卡的上下行带宽,是目前的主流方案

-
模型并行:将模型切分成多个部分放在不同的GPU上并行运行,每个GPU负责处理一部分模型参数,并将处理后的结果发送到其它GPU进行合并,从而实现整体模型的更新。这种操作目前并不常见,一是因为大部分模型单卡都放得下,二是因为通讯开销比数据并行多。根据模型切分方式,模型并行也可以分成Pipelined Parallelism和Tensor Slicing两种,前者将模型的各个层放到不同的 GPU 上运行,这种做法比较通用,但是效率不高;后者针对模型中各种模块(attention、FFN 等)的张量计算操作进行拆解,把 tensor 计算分块分散到不同的机器上进行并行,效率较高但是通用性差

-
-
关于各种并行方法的详细说明可以参考:分布式训练、混合精度训练、梯度累加…一文带你优雅地训练大型模型
1.2 Pytorch 中的多卡并行
- 随着各种深度学习框架的日趋完善,很多并行方法已经被整合其中,这让实现多卡并行加速训练变得相对简单。Pytorch 中提供了 DP(DataParallel) 和 DDP(DistributedDataParallel) 两种数据并行方法,它们的性能对比如下

红色柱子是 DP,绿色柱子是 DDP,蓝色柱子是 DDP + Apex 混合精度训练。注意到 DDP 的表现大幅优于 DP,这是因为- DP 使用 Parameter Server 方式汇聚梯度并更新参数,主卡计算负载和通信带宽需求相比其他卡都显著高,导致主卡的计算能力和上下行带宽成为性能瓶颈;
- DDP 使用更高效的 Ring All-Reduce 方案,基本实现了 “使用几块GPU就是几倍加速” 的效果
- 接下来本文会介绍使用 DDP 进行多卡加速的具体做法,参考自:Pytorch 官方教程
2. 使用 DDP 进行单机多卡训练
2.1 原理概述
- DDP 会在每个 GPU 上运行一个进程,每个进程中都有一套完全相同的 Trainer 副本(包括 model 和 optimizer),各个进程之间通过一个进程池进行通信。这里有几个术语
node:多机多卡运行时,每个机器称为一个 “node”,其中每一张卡都可以运行一个并行进程world size:所有并行进程的总数,各个 node 上并行的GPU总数rank:所有 node 的所有进程中,各个进程的标识符号,是从0开始计数的整数local rank:当前 node 的所有进程中,各个进程的标识符号,是从0开始计数的整数group:所有并行的进程组成一个 group(进程池),只有组内的进程间才可以相互通信
2.2 使用 DDP 改写单卡训练代码
-
考虑如何将以下单机单卡代码改为 DDP 单机多卡运行
# 单 GPU 训练示例 import torch import torch.nn.functional as F from torch.utils.data import Dataset, DataLoaderclass Trainer:def __init__(self,model: torch.nn.Module,train_data: DataLoader,optimizer: torch.optim.Optimizer,gpu_id: int,save_every: int, ) -> None:self.gpu_id = gpu_idself.model = model.to(gpu_id)self.train_data = train_dataself.optimizer = optimizerself.save_every = save_everydef _run_batch(self, source, targets):self.optimizer.zero_grad()output = self.model(source)loss = F.cross_entropy(output, targets)loss.backward()self.optimizer.step()def _run_epoch(self, epoch):b_sz = len(next(iter(self.train_data))[0])print(f"[GPU{self.gpu_id}] Epoch {epoch} | Batchsize: {b_sz} | Steps: {len(self.train_data)}")for source, targets in self.train_data:source = source.to(self.gpu_id)targets = targets.to(self.gpu_id)self._run_batch(source, targets)def _save_checkpoint(self, epoch):ckp = self.model.state_dict()PATH = "checkpoint.pt"torch.save(ckp, PATH)print(f"Epoch {epoch} | Training checkpoint saved at {PATH}")def train(self, max_epochs: int):for epoch in range(max_epochs):self._run_epoch(epoch)if epoch % self.save_every == 0:self._save_checkpoint(epoch)class MyTrainDataset(Dataset):def __init__(self, size):self.size = sizeself.data = [(torch.rand(20), torch.rand(1)) for _ in range(size)]def __len__(self):return self.sizedef __getitem__(self, index):return self.data[index]def load_train_objs():train_set = MyTrainDataset(2048) # load your datasetmodel = torch.nn.Linear(20, 1) # load your modeloptimizer = torch.optim.SGD(model.parameters(), lr=1e-3)return train_set, model, optimizerdef prepare_dataloader(dataset: Dataset, batch_size: int):return DataLoader(dataset,batch_size=batch_size,pin_memory=True,shuffle=True)def main(device, total_epochs, save_every, batch_size):dataset, model, optimizer = load_train_objs()train_data = prepare_dataloader(dataset, batch_size)trainer = Trainer(model, train_data, optimizer, device, save_every)trainer.train(total_epochs)if __name__ == "__main__":import argparseparser = argparse.ArgumentParser(description='simple distributed training job')parser.add_argument('--total-epochs', type=int, default=50, help='Total epochs to train the model')parser.add_argument('--save-every', type=int, default=10, help='How often to save a snapshot')parser.add_argument('--batch_size', default=32, type=int, help='Input batch size on each device (default: 32)')args = parser.parse_args()device = 0 # shorthand for cuda:0main(device, args.total_epochs, args.save_every, args.batch_size) -
将单卡训练代码改写为 DDP 并行的要点如下
- 引入 DDP 相关库
# 使用 DistributedDataParallel 进行单机多卡训练 import torch import torch.nn.functional as F from torch.utils.data import Dataset, DataLoader import os# 对 python 多进程的一个 pytorch 包装,用于后续分发进程 import torch.multiprocessing as mp # 这个 sampler 可以把采样的数据分散到各个 CPU 上 from torch.utils.data.distributed import DistributedSampler # 实现分布式数据并行的核心类 from torch.nn.parallel import DistributedDataParallel as DDP # 各个进程之间通过一个进程池进行通信,这两个方法来初始化和销毁进程池 from torch.distributed import init_process_group, destroy_process_group - 在程序入口初始化进程池;在程序出口销毁进程池
def main(rank: int, world_size: int, save_every: int, total_epochs: int, batch_size: int):# 初始化进程池ddp_setup(rank, world_size)# 进行训练dataset, model, optimizer = load_train_objs()train_data = prepare_dataloader(dataset, batch_size)trainer = Trainer(model, train_data, optimizer, rank, save_every)trainer.train(total_epochs)# 销毁进程池destroy_process_group() - 使用
DistributedDataParallel包装模型,这样模型才能在各个进程间同步参数
包装后 model 变成了一个 DDP 对象,要访问其参数得这样写self.model = DDP(model, device_ids=[gpu_id]) # model 要用 DDP 包装一下self.model.module.state_dict() - 构造 Dataloader 时使用
DistributedSampler作为 sampler,这个采样器可以自动将数量为 batch_size 的数据分发到各个GPU上,并保证数据不重叠
注意需要在各 epoch 入口调用该 sampler 对象的def prepare_dataloader(dataset: Dataset, batch_size: int):return DataLoader(dataset,batch_size=batch_size,pin_memory=True,shuffle=False, # 设置了新的 sampler,参数 shuffle 要设置为 False sampler=DistributedSampler(dataset) # 这个 sampler 自动将数据分块后送个各个 GPU,它能避免数据重叠)set_epoch()方法,否则每个 epoch 加载的样本顺序都不变 - 运行过程中单独控制某个进程进行某些操作,比如要想保存 ckpt,由于每张卡里都有完整的模型参数,所以只需要控制一个进程保存即可。需要注意的是:使用 DDP 改写的代码会在每个 GPU 上各自运行,因此需要在程序中获取当前 GPU 的 rank(gpu_id),这样才能对针对性地控制各个 GPU 的行为
if self.gpu_id == 0 and epoch % self.save_every == 0:self._save_checkpoint(epoch) - 使用
torch.multiprocessing.spawn方法将代码分发到各个 GPU 的进程中执行# 利用 mp.spawn,在整个 distribution group 的 nprocs 个 GPU 上生成进程来执行 fn 方法,并能设置要传入 fn 的参数 args # 注意不需要传入 fn 的 rank 参数,它由 mp.spawn 自动分配 world_size = torch.cuda.device_count() mp.spawn(fn=main, args=(world_size, args.save_every, args.total_epochs, args.batch_size), nprocs=world_size )
- 引入 DDP 相关库
-
完整的修改版代码如下,请参考注释自行对比
# 使用 DistributedDataParallel 进行单机多卡训练 import torch import torch.nn.functional as F from torch.utils.data import Dataset, DataLoader import os# 对 python 多进程的一个 pytorch 包装 import torch.multiprocessing as mp# 这个 sampler 可以把采样的数据分散到各个 CPU 上 from torch.utils.data.distributed import DistributedSampler # 实现分布式数据并行的核心类 from torch.nn.parallel import DistributedDataParallel as DDP # DDP 在每个 GPU 上运行一个进程,其中都有一套完全相同的 Trainer 副本(包括model和optimizer) # 各个进程之间通过一个进程池进行通信,这两个方法来初始化和销毁进程池 from torch.distributed import init_process_group, destroy_process_group def ddp_setup(rank, world_size):"""setup the distribution process groupArgs:rank: Unique identifier of each processworld_size: Total number of processes"""# MASTER Node(运行 rank0 进程,多机多卡时的主机)用来协调各个 Node 的所有进程之间的通信os.environ["MASTER_ADDR"] = "localhost" # 由于这里是单机实验所以直接写 localhostos.environ["MASTER_PORT"] = "12355" # 任意空闲端口init_process_group(backend="nccl", # Nvidia CUDA CPU 用这个 "nccl"rank=rank, world_size=world_size)torch.cuda.set_device(rank)class Trainer:def __init__(self,model: torch.nn.Module,train_data: DataLoader,optimizer: torch.optim.Optimizer,gpu_id: int,save_every: int,) -> None:self.gpu_id = gpu_idself.model = model.to(gpu_id)self.train_data = train_dataself.optimizer = optimizerself.save_every = save_every # 指定保存 ckpt 的周期self.model = DDP(model, device_ids=[gpu_id]) # model 要用 DDP 包装一下def _run_batch(self, source, targets):self.optimizer.zero_grad()output = self.model(source)loss = F.cross_entropy(output, targets)loss.backward()self.optimizer.step()def _run_epoch(self, epoch):b_sz = len(next(iter(self.train_data))[0])print(f"[GPU{self.gpu_id}] Epoch {epoch} | Batchsize: {b_sz} | Steps: {len(self.train_data)}")self.train_data.sampler.set_epoch(epoch) # 在各个 epoch 入口调用 DistributedSampler 的 set_epoch 方法是很重要的,这样才能打乱每个 epoch 的样本顺序for source, targets in self.train_data: source = source.to(self.gpu_id)targets = targets.to(self.gpu_id)self._run_batch(source, targets)def _save_checkpoint(self, epoch):ckp = self.model.module.state_dict() # 由于多了一层 DDP 包装,通过 .module 获取原始参数 PATH = "checkpoint.pt"torch.save(ckp, PATH)print(f"Epoch {epoch} | Training checkpoint saved at {PATH}")def train(self, max_epochs: int):for epoch in range(max_epochs):self._run_epoch(epoch)# 各个 GPU 上都在跑一样的训练进程,这里指定 rank0 进程保存 ckpt 以免重复保存if self.gpu_id == 0 and epoch % self.save_every == 0:self._save_checkpoint(epoch)class MyTrainDataset(Dataset):def __init__(self, size):self.size = sizeself.data = [(torch.rand(20), torch.rand(1)) for _ in range(size)]def __len__(self):return self.sizedef __getitem__(self, index):return self.data[index]def load_train_objs():train_set = MyTrainDataset(2048) # load your datasetmodel = torch.nn.Linear(20, 1) # load your modeloptimizer = torch.optim.SGD(model.parameters(), lr=1e-3)return train_set, model, optimizerdef prepare_dataloader(dataset: Dataset, batch_size: int):return DataLoader(dataset,batch_size=batch_size,pin_memory=True,shuffle=False, # 设置了新的 sampler,参数 shuffle 要设置为 False sampler=DistributedSampler(dataset) # 这个 sampler 自动将数据分块后送个各个 GPU,它能避免数据重叠)def main(rank: int, world_size: int, save_every: int, total_epochs: int, batch_size: int):# 初始化进程池ddp_setup(rank, world_size)# 进行训练dataset, model, optimizer = load_train_objs()train_data = prepare_dataloader(dataset, batch_size)trainer = Trainer(model, train_data, optimizer, rank, save_every)trainer.train(total_epochs)# 销毁进程池destroy_process_group()if __name__ == "__main__":import argparseparser = argparse.ArgumentParser(description='simple distributed training job')parser.add_argument('--total-epochs', type=int, default=50, help='Total epochs to train the model')parser.add_argument('--save-every', type=int, default=10, help='How often to save a snapshot')parser.add_argument('--batch_size', default=32, type=int, help='Input batch size on each device (default: 32)')args = parser.parse_args()world_size = torch.cuda.device_count()# 利用 mp.spawn,在整个 distribution group 的 nprocs 个 GPU 上生成进程来执行 fn 方法,并能设置要传入 fn 的参数 args# 注意不需要 fn 的 rank 参数,它由 mp.spawn 自动分配mp.spawn(fn=main, args=(world_size, args.save_every, args.total_epochs, args.batch_size), nprocs=world_size)
相关文章:
Pytorch 多卡并行(1)—— 原理简介和 DDP 并行实践
近年来,深度学习模型的规模越来越大,需要处理的数据也越来越多,单卡训练的显存空间和计算效率都越来越难以满足需求。因此,多卡并行训练成为了一个必要的解决方案本文主要介绍使用 Pytorch 的 DistributedDataParallel(…...

快速排序(重点)
前言 快排是一种比较重要的排序算法,他的思想有时候会作用到个别算法提上,公司招聘的笔试上有时候也有他的过程推导题,所以搞懂快排势在必行!!! 快速排序 基本思想: 根据基准,将数…...

python高级内置函数介绍及应用举例
目录 1. 概述2. 举例 1. 概述 Python中有许多高级内置函数,它们提供了丰富的功能和便利性,可以大大简化代码并提高效率。以下是一些常用的高级内置函数: map(): 用于将一个函数应用于一个可迭代对象的所有项,返回一…...

人体呼吸存在传感器成品,毫米波雷达探测感知技术,引领智能家居新潮流
随着科技的不断进步和人们生活质量的提高,智能化家居逐渐成为一种时尚和生活方式。 人体存在传感器作为智能家居中的重要组成部分,能够实时监测环境中人体是否存在,为智能家居系统提供更加精准的控制和联动。 在这个充满创新的时代…...
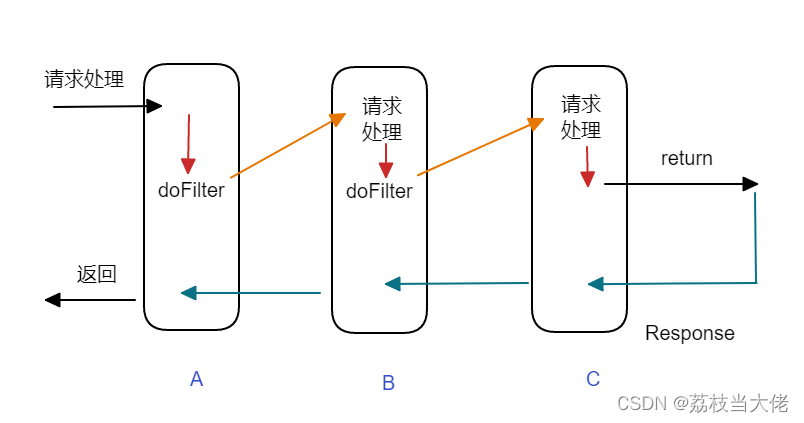
软件设计模式(三):责任链模式
前言 前面荔枝梳理了有关单例模式、策略模式的相关知识,这篇文章荔枝将沿用之前的写法根据示例demo来体会这种责任链设计模式,希望对有需要的小伙伴有帮助吧哈哈哈哈哈哈~~~ 文章目录 前言 责任链模式 1 简单场景 2 责任链模式理解 3 Java下servl…...

开发者的商业智慧:产品立项策划你知道多少?
文章目录 想法的萌芽🌟初步评估产品可行性🍊分析核心功能和特点以及竞争对手📝大健康监测📝时尚新科技产品📝准确性📝多功能📝品牌口碑📝数据分析与个性化建议📝社交互动…...
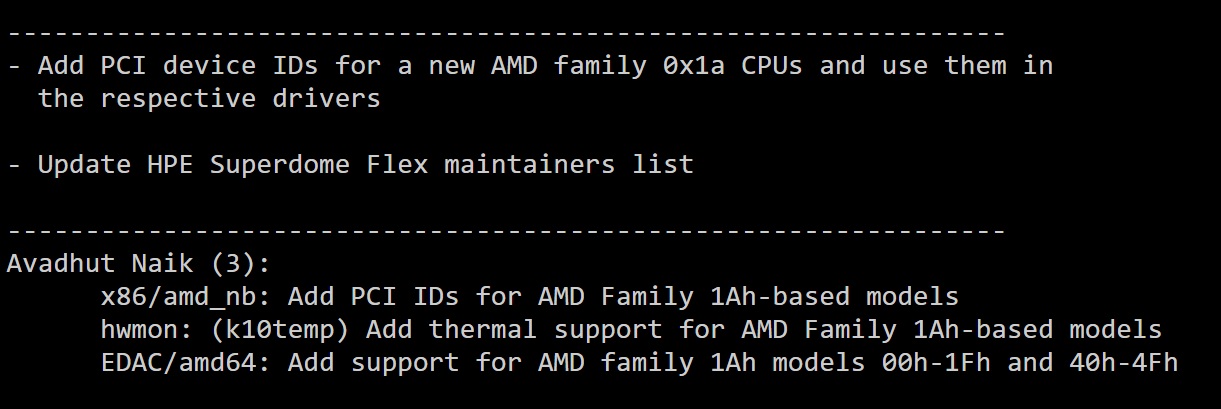
Linux 6.6 初步支持AMD 新一代 Zen 5 处理器
AMD 下一代 Zen 5 CPU 现已开始为 Linux 6.6 支持提交相关代码,最新补丁包括提供温度监控和 EDAC 报告等。 最新的 Linux 6.6 代码中已经加入了包括支持硬件监视器温度监控和 EDAC 报告的补丁。此外,新版本还加入了 x86 / misc 补丁,Phoronix…...
第五章 Linux常用应用软件
第五章 Linux常用应用软件 Ubuntu包含了日常所需的常用程序,集成了跨平台的办公套件LibreOffice和Mozila Firefox浏览器等。还提供了文本处理工具、图片处理工具等。 1.LibreOffice LibreOffice免费开源,遵照GPL分发源代码,与OpenOf…...
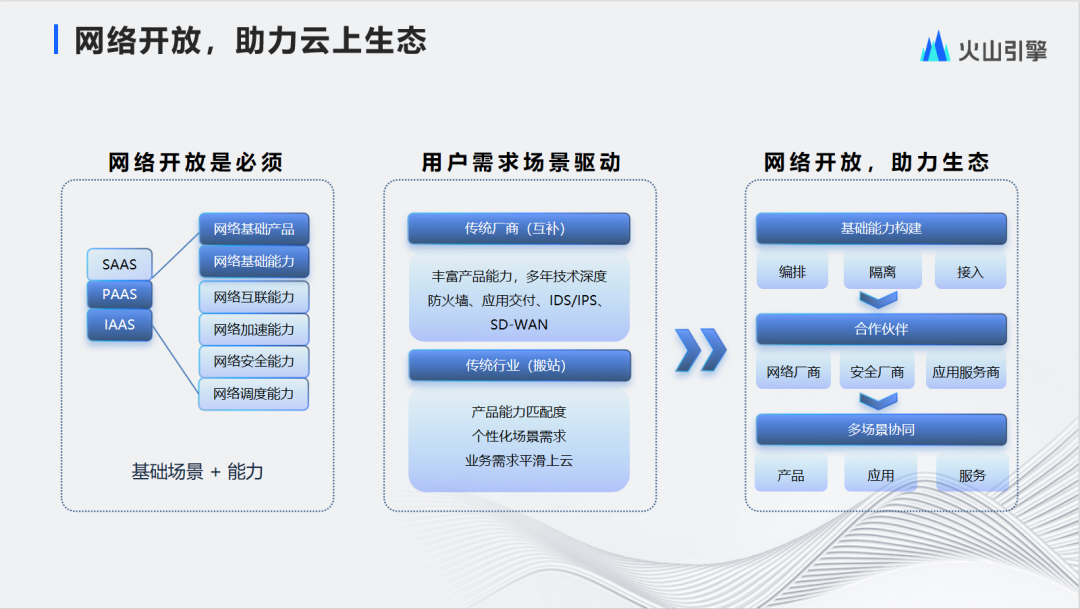
连接云-边-端,构建火山引擎边缘云网技术体系
近日,火山引擎边缘云网络产品研发负责人韩伟在LiveVideoStack Con 2023上海站围绕边缘云海量分布式节点和上百T的网络规模,结合边缘云快速发展期间遇到的各种问题和挑战,分享了火山引擎边缘云网的全球基础设施,融合开放的云网技术…...
系统架构设计师(第二版)学习笔记----系统架构设计师概述
【原文链接】系统架构设计师(第二版)学习笔记----系统架构设计师概述 文章目录 一、架构设计师的定义、职责和任务1.1 架构设计师的定义1.2 架构设计师的任务 二、架构设计师应具备的专业素质2.1 架构设计师应具备的专业知识2.2 架构设计师的知识结构2.3…...

自动化测试:Selenium中的时间等待
在 Selenium 中,时间等待指在测试用例中等待某个操作完成或某个事件发生的时间。Selenium 中提供了多种方式来进行时间等待,包括使用 ExpectedConditions 中的 presence_of_element_located 和 visibility_of_element_located 方法等待元素可见或不可见&…...

vim 替换命令 “:s“
vim 替换命令 ":s" 1. 替换光标所在行的第一个匹配串2. 替换光标所在行全部匹配项3. 替换两行之间每行的第一个匹配项4. 替换两行之间的全部匹配项5. 替换整个文件中的每个匹配串6. 查找整个文件中的每个匹配串并询问是否替换 1. 替换光标所在行的第一个匹配串 命令…...
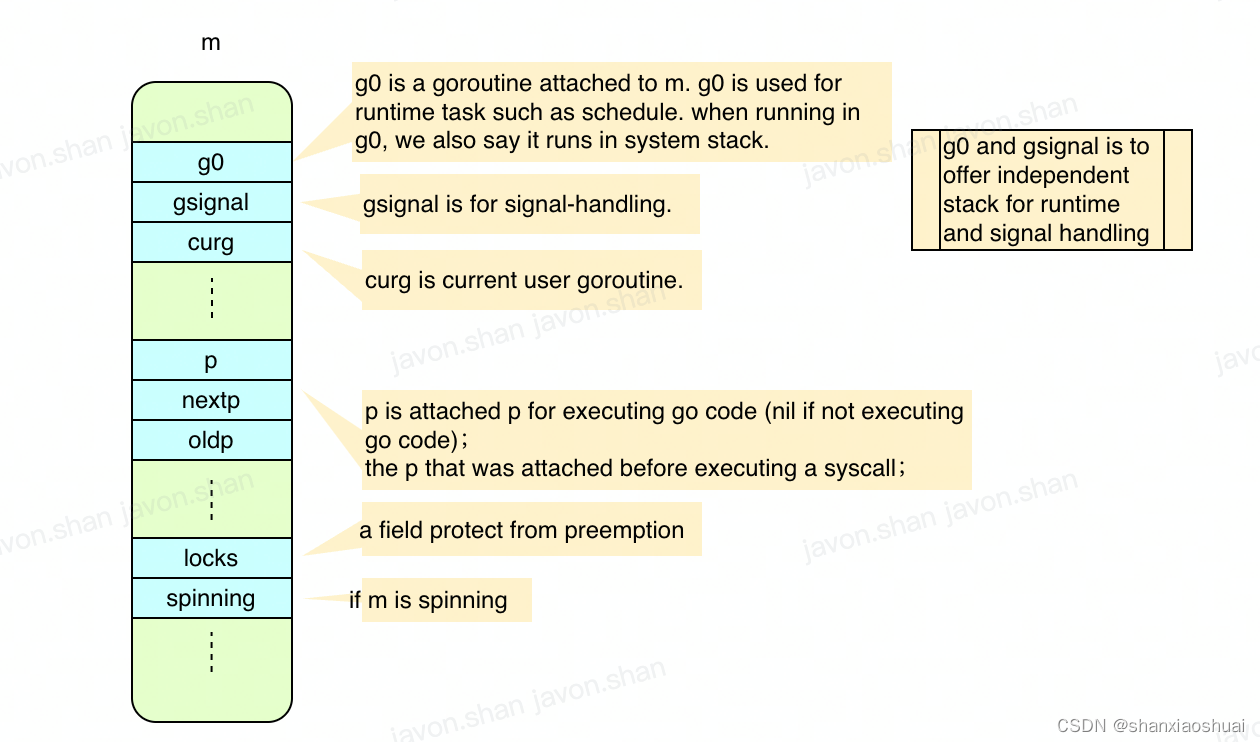
【golang】调度系列之m
调度系列 调度系列之goroutine 上一篇中介绍了goroutine,最本质的一句话就是goroutine是用户态的任务。我们通常说的goroutine运行其实严格来说并不准确,因为任务只能被执行。那么goroutine是被谁执行呢?是被m执行。 在GMP的架构中ÿ…...

可持久化线段树
可持久化线段树 模板 在某一指定版本的单点查,单点修。 开 m m m 棵线段树,每次修改复制后单点修。时间复杂度 O ( m ( n log n ) ) O(m(n\log n)) O(m(nlogn)),空间复杂度 O ( n m ) O(nm) O(nm),不如暴力。 每次修改…...

运行 Node.js 与浏览器 JavaScript
浏览器和 Node.js 都使用 JavaScript 软件语言 - 但字面上的运行时环境是不同的。 Node.js(又名服务器端 JavaScript)与客户端 JavaScript 有许多相似之处。它也有很多差异。 尽管两者都使用 JavaScript 作为软件语言,但我们可以重点关注一些关键差异,这些差异使两者之间…...

File类操作
1. 练习一 在当前模块下的 text 文件夹中创建一个 io.txt 文件 import java.io.File; import java.io.IOException;public class Practice1 {public static void main(String[] args) {File file new File("D:\\kaifamiao");File file1 new File(file, "tex…...
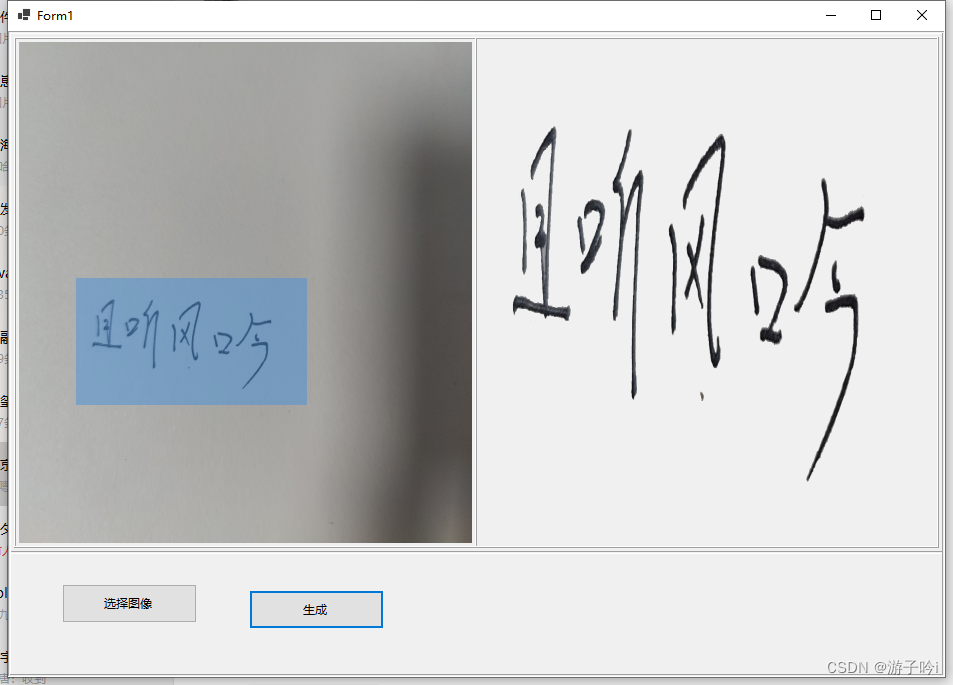
C# 实现电子签名
本项目基于Emgu.CV(C#下OpenCv的封装)开发的,编译器最新版Vs2022,编译环境x86 直接看效果图 1.主页面 2.我们先看手写的方式: 点击确认就到主界面,如下 : 点击自动适配-,再点击生成…...
小米6/6X/米8/米9手机刷入鸿蒙HarmonyOS.4.0系统-刷机包下载-遥遥领先
小米手机除了解锁root权限,刷GSI和第三方ROM也是米粉的一大爱好,这不,在华为发布了HarmonyOS.4.0系统后不久,我们小米用户也成功将自己的手机干山了HarmonyOS.4.0系统。虽然干上去HarmonyOS.4.0系统目前BUG非常多,根本…...
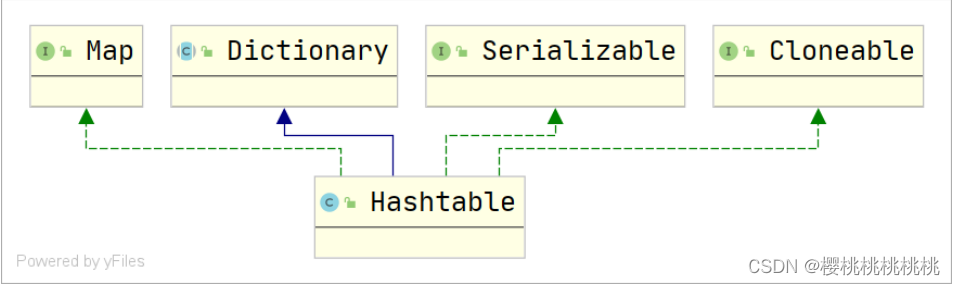
集合框架和泛型二
一、Set接口 1. Set接口概述 java.util.Set 不包含重复元素的集合、不能保证存储的顺序、只允许有一个 null。 public interface Set<E> extends Collection<E>抽象方法,都是继承自 java.util.Collection 接口。 Set 集合的实现类有很多,…...
)
thinkphp6 入门教程合集(更新中)
thinkphp6 入门(1)--安装、路由规则、多应用模式 thinkphp6 入门(1)--安装、路由规则、多应用模式_软件工程小施同学的博客-CSDN博客 thinkphp6 入门(2)--视图、渲染html页面、赋值 thinkphp6 入门&#…...
告别SIFT/ORB!用LoFTR+Transformer搞定低纹理场景的图片匹配(附Python实战代码)
低纹理场景图像匹配实战:LoFTR与Transformer的革新应用 在计算机视觉领域,图像特征匹配一直是三维重建、视觉定位等任务的基础环节。传统方法如SIFT、ORB依赖于特征检测器提取关键点,但在低纹理、重复图案或运动模糊场景中表现往往不尽如人意…...

探索Unity全功能的开源方案:UniHacker跨平台功能扩展工具深度指南
探索Unity全功能的开源方案:UniHacker跨平台功能扩展工具深度指南 【免费下载链接】UniHacker 为Windows、MacOS、Linux和Docker修补所有版本的Unity3D和UnityHub 项目地址: https://gitcode.com/GitHub_Trending/un/UniHacker Unity作为游戏开发领域的行业标…...

SDMatte Web端体验优化:首屏加载速度与模型预热机制说明
SDMatte Web端体验优化:首屏加载速度与模型预热机制说明 1. 引言 在电商、设计、内容创作等领域,高质量的图像抠图已经成为刚需。SDMatte作为一款专注于复杂边缘和透明物体处理的AI抠图工具,其Web端体验直接影响用户的使用感受。本文将详细…...

图像超分新思路:拆解SCNet的‘空间移位’操作,看它如何用零参数实现3x3卷积的效果
图像超分辨率革命:零参数空间移位如何颠覆传统卷积设计 当你在手机相册里翻出一张十年前的老照片,是否曾幻想过能一键修复那些模糊的像素?这正是图像超分辨率技术试图解决的难题。传统方法依赖计算密集的33卷积,而SCNet提出的&quo…...

单一模型可能涌现不出超级智能,但 Agent 协作体却极有可能。
当 AI 把产品能力拉齐,注意力才是唯一的护城河 你有没有这种感觉?2025 年底,用 AI 一键生成一个完整 App 已经不是什么新闻,Vibe Coding 让普通开发者一天就能上线一个产品。可产品做出来了,下载量却像石沉大海&#x…...

Matlab中的QRBiGRU分位数回归双向门控循环单元模型:多图输出与多指标评估的时间序列区间预测
Matlab实现基于QRBiGRU分位数回归双向门控循环单元的时间序列区间预测模型: 1.Matlab实现基于QRBiGRU分位数回归双向门控循环单元的时间序列区间预测模型 2.多图输出、多指标输出(MAE、RMSE、MSE、R2),多输入单输出,含不同置信区间图、概率密…...
)
Qt5新手必看:3分钟搞定你的第一个控制台程序(附完整代码)
Qt5入门实战:从零构建控制台应用的完整指南 引言:为什么选择Qt5作为开发起点? 对于刚接触C图形界面开发的程序员来说,Qt框架提供了一个绝佳的起点。它不仅拥有跨平台特性,还具备完善的工具链和丰富的模块库。控制台程序…...

RT-Thread Nano 3.0.3移植STM32F103后,第一个实战:用FinSH组件实现串口命令行调试
RT-Thread Nano 3.0.3移植STM32F103实战:FinSH组件实现串口命令行调试 当你成功将RT-Thread Nano移植到STM32F103开发板后,第一个令人兴奋的里程碑就是让系统真正"活"起来——而FinSH组件正是实现这一目标的完美起点。这个内置的命令行交互工具…...
)
YOLOv8环境搭好了,然后呢?5个实用脚本带你玩转目标检测(从预测到训练)
YOLOv8环境搭好了,然后呢?5个实用脚本带你玩转目标检测(从预测到训练) 刚完成YOLOv8环境配置的开发者常会遇到这样的困境:跑通官方demo后,面对自己的实际需求却无从下手。本文将提供五个即用型Python脚本&a…...

VSCode配置STM32标准库开发环境:手把手解决core_cm3.c编译报错与头文件路径问题
VSCode搭建STM32开发环境:解决标准库兼容性与智能感知难题 当开发者从Keil或IAR转向VSCode时,往往会遇到两个棘手的拦路虎:标准库与GCC的兼容性问题,以及代码智能感知的缺失。本文将深入解决这两个核心痛点,带你构建一…...