【大数据】Kafka 入门指南
Kafka 入门指南
- 1.Kafka 简介
- 2.Kafka 架构
- 3.分区与副本
- 4.偏移量
- 5.消费者组
- 6.总结
1.Kafka 简介
Apache Kafka 是一种高吞吐、分布式的流处理平台,由 LinkedIn 开发并于 2011 年开源。它具有 高伸缩性、高可靠性 和 低延迟 等特点,因此在大型数据处理场景中备受青睐。Kafka 可以处理多种类型的数据,如事件、日志、指标等,广泛应用于 实时数据流处理、日志收集、监控和分析 等领域。
通常用作消息队列和流处理,作为消息队列的时候,竞品有 RabbitMQ、ActiveMQ、RocketMQ、Apache Pulsar 等。
2.Kafka 架构
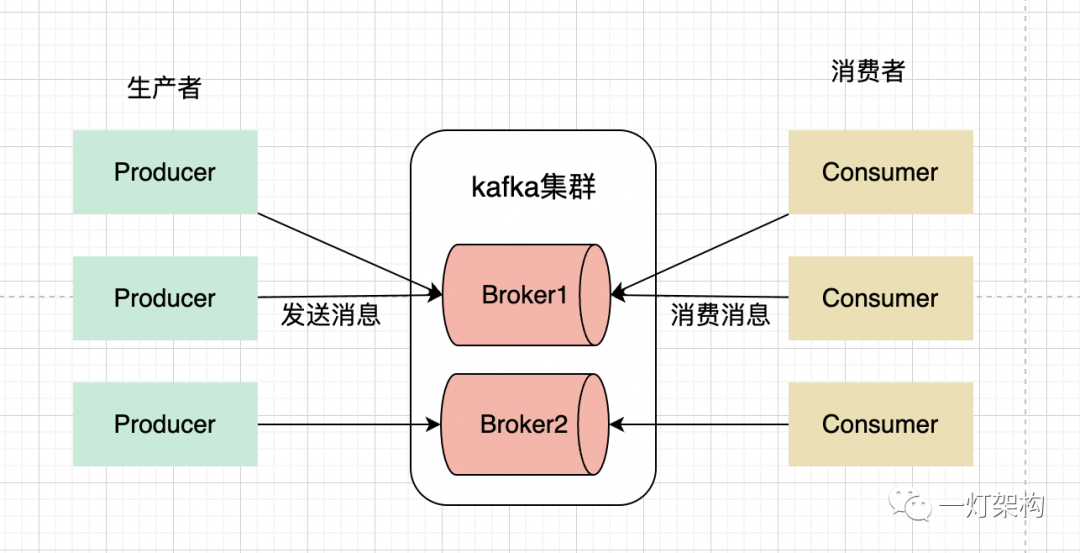
下面介绍一下 Kafka 架构中最重要的三个参与者:
Producer(生产者):生产者负责将消息发送到 Kafka 集群。Consumer(消费者):消费者负责从 Kafka 集群中拉取并消费消息。Broker(代理节点):Broker 是 Kafka 集群中的一个服务代理节点,可以看作是一台服务器。Kafka 集群通常由多个 Broker 组成,以实现负载均衡和容错。
3.分区与副本
Kafka 为了对消息进行分类,引入了 Topic(主题)的概念。生产者在发送消息的时候,需要指定发送到某个 Topic,然后消息者订阅这个 Topic 并进行消费消息。
Kafka 为了提升性能,又在 Topic 的基础上,引入了 Partition(分区)的概念。Topic 是逻辑概念,而 Partition 是物理分组。一个 Topic 可以包含多个 Partition,生产者在发送消息的时候,需要指定发送到某个 Topic 的某个 Partition,然后消息者订阅这个 Topic 并消费这个 Partition 中的消息。
Kafka 为了提高系统的吞吐量和可扩展性,把一个 Topic 的不同 Partition 放到多个 Broker 节点上,充分利用机器资源,也便于扩展 Partition。
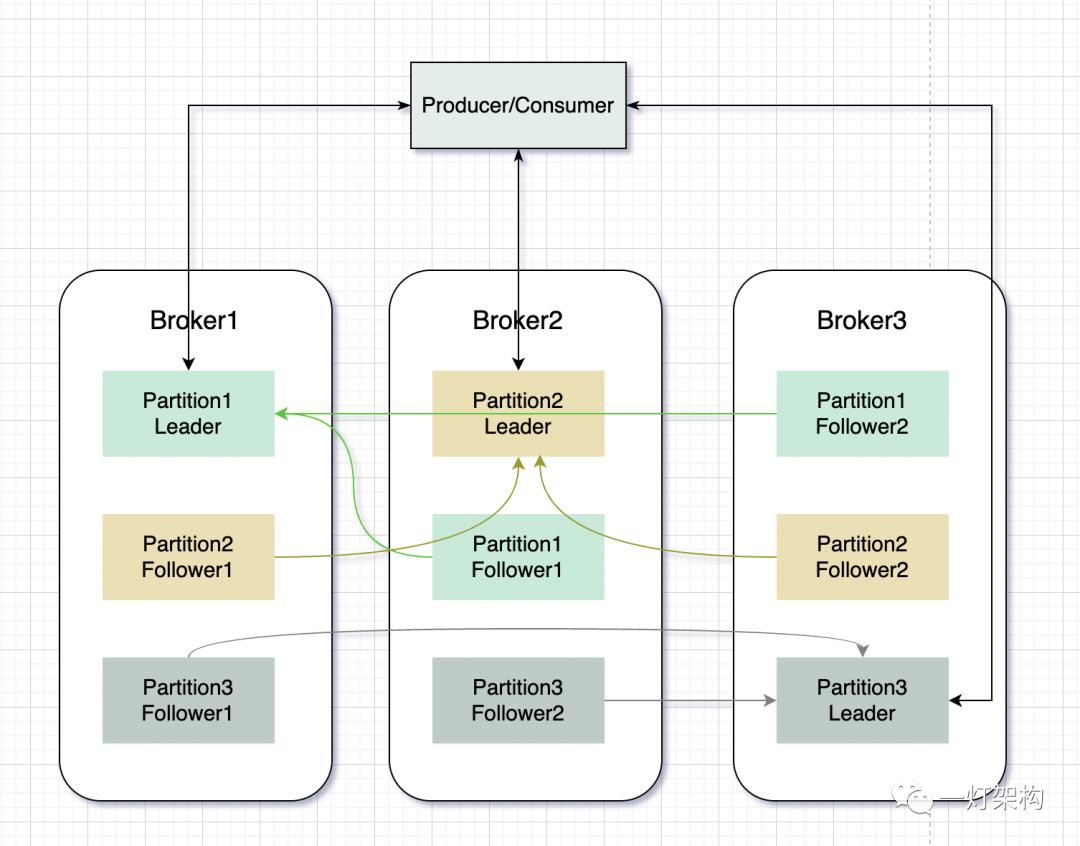
Kafka 为了保证数据的安全性和服务的高可用,又在 Partition 的基础上,引入 Replica(副本)的概念。一个 Partition 包含多个 Replica,Replica 之间是一主多从的关系,有两种类型 Leader Replica(领导者副本)和 Follower Replica(跟随者副本),Replica分布在不同的Broker节点上。
Leader Replica 负责读写请求,Follower Replica 只负责同步 Leader Replica 数据,不对外提供服务。当 Leader Replica 发生故障,就从 Follower Replica 选举出一个新的 Leader Replica 继续对外提供服务,实现了故障自动转移。
下图展示的是,同一个 Topic 的不同 Partition 在 Broker 节点的分布情况:
Kafka 为了提升 Replica 的同步效率和数据写入效率,又对 Replica 进行分类。针对一个 Partition 的所有 Replica 集合统称为 AR(Assigned Replicas,已分配的副本),包含 Leader Replica 和 Follower Replica。与 Leader Replica 保持同步的 Replica 集合称为 ISR(In-Sync Replicas,同步副本),与 Leader Replica 保持失去同步的 Replica 集合称为 OSR(Out-of-Sync Replicas,失去同步的副本),AR = ISR + OSR。
Leader Replica 将消息写入磁盘前,需要等 ISR 中的所有副本同步完成。如果 ISR 中某个 Follower Replica 同步数据落后 Leader Replica 过多,会被转移到 OSR 中。如果 OSR 中的某个 Follower Replica 同步数据追上了 Leader Replica,会被转移到 ISR 中。当 Leader Replica 发生故障的时候,只会从 ISR 中选举出新的 Leader Replica。
4.偏移量
Kafka 为了记录副本的同步状态,以及控制消费者消费消息的范围,于是引入了 LEO(Log End Offset,日志结束偏移量)和 HW(High Watermark,高水位)。
- LEO 表示分区中的下一个被写入消息的偏移量,也是分区中的最大偏移量。LEO 用于记录 Leader Replica 和 Follower Replica 之间的数据同步进度,每个副本中各有一份。
- HW 表示所有副本(Leader 和 Follower)都已成功复制的最小偏移量,是所有副本共享的数据值。换句话说,HW 之前的消息都被视为已提交,消费者可以消费这些消息。用于确保消息的一致性和只读一次。
下面演示一下 LEO 和 HW 的更新流程:
(1)初始状态,三个副本中各有 0 和 1 两条消息,LEO 都是 2,位置 2 是空的,表示是即将被写入消息的位置。HW 也都是 2,表示 Leader Replica 中的所有消息已经全部同步到 Follower Replica 中,消费者可以消费 0 和 1 两条消息。
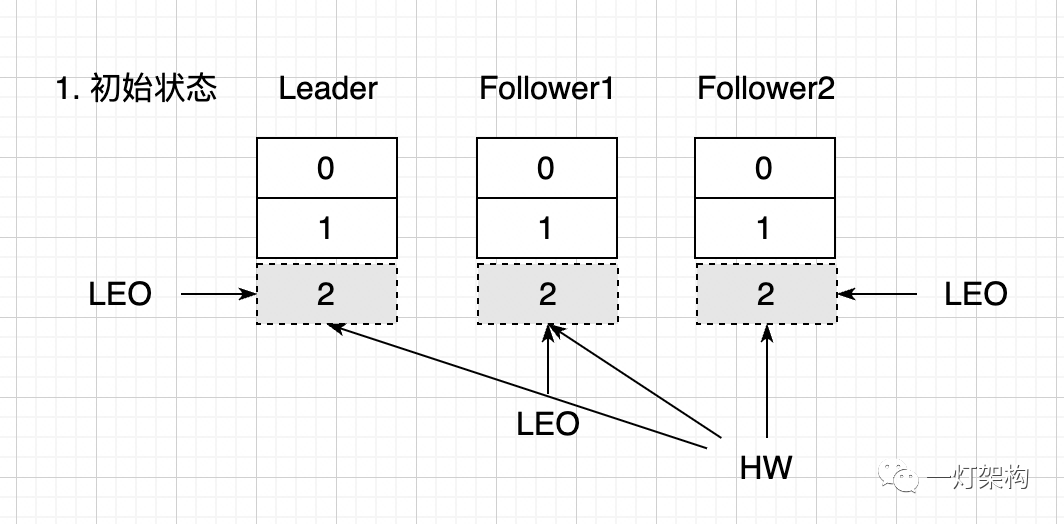
(2)生产者往 Leader Replica 中发送两条消息,此时 Leader Replica 的 LEO 的值增加 2,变成 4。由于还没有开始往 Follower Replica 同步消息,所以 HW 值和 Follower Replica 中 LEO 值都没有变。由于消费者只能消费 HW 之前的消息,也就是 0 和 1 两条消息。
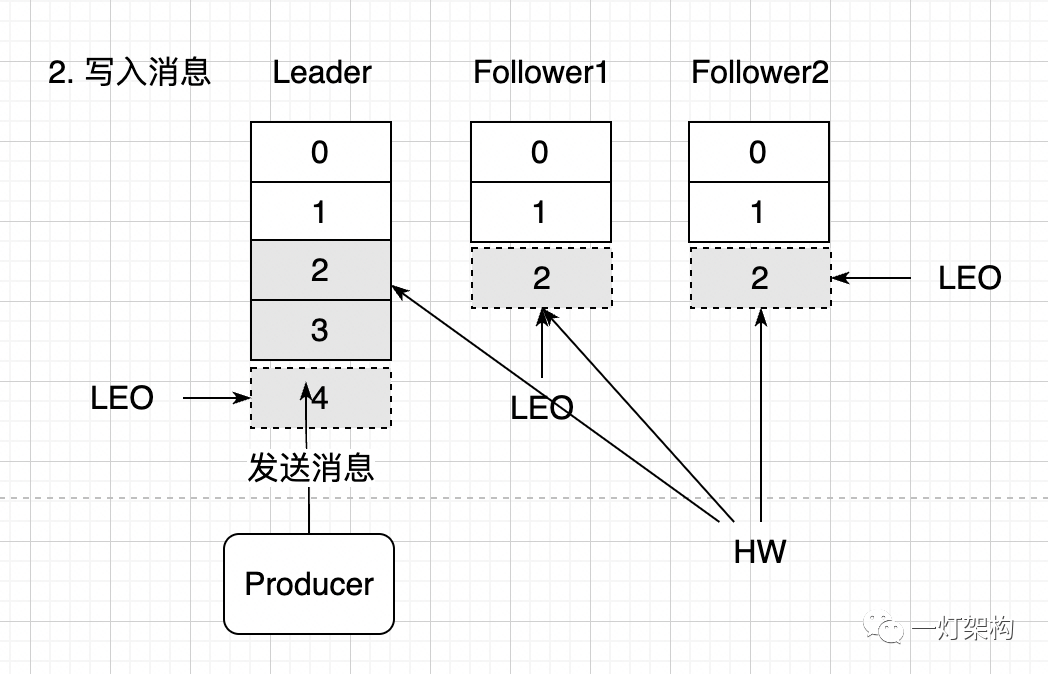
(3)Leader Replica 开始向 Follower Replica 同步消息,同步速率不同,Follower1 的两条消息 2 和 3 已经同步完成,而 Follower2 只同步了一条消息 2。此时,Leader 和 Follower1 的 LEO 都是 4,而 Follower2 的 LEO 是 3,HW 表示已成功同步的最小偏移量,值是 3,表示此时消费者只能读到 0、1、2,三条消息。
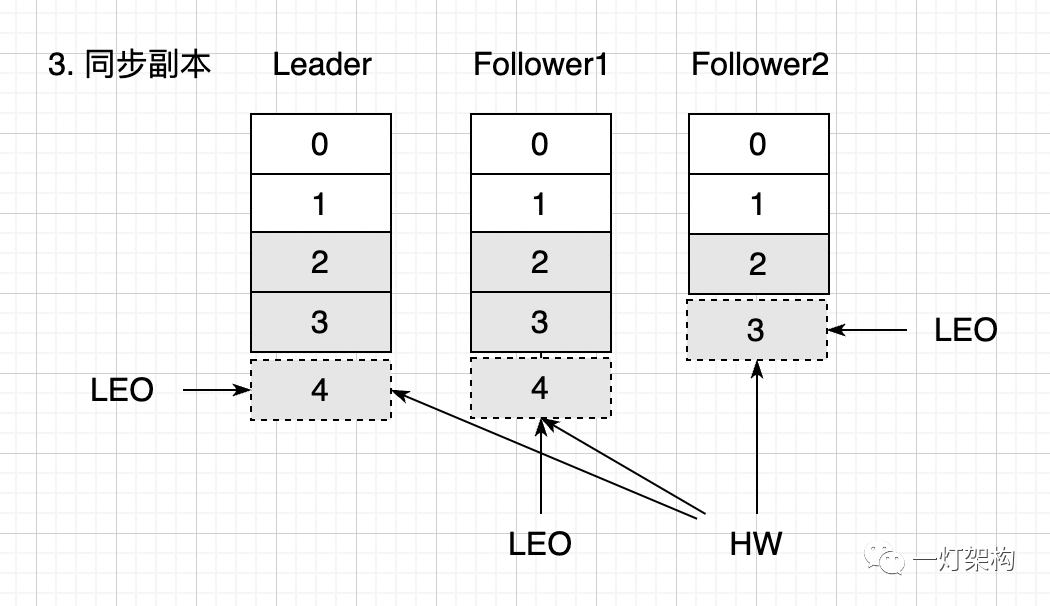
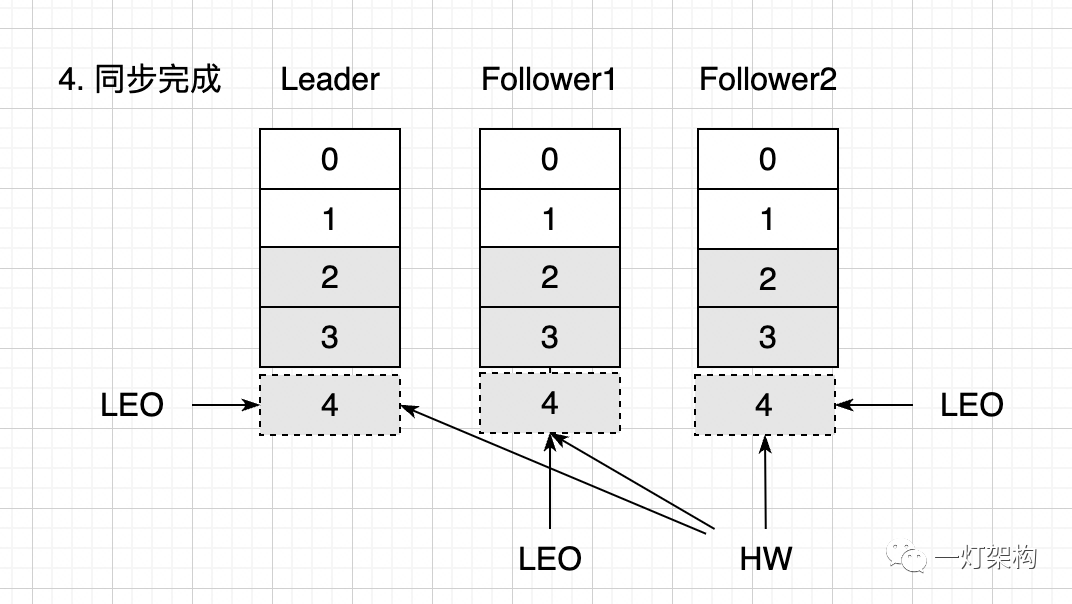
所有消息都同步完成,三个副本的 LEO 都是 4,HW 也是 4,消费者可以读到 0、1、2、3,四条消息。
5.消费者组
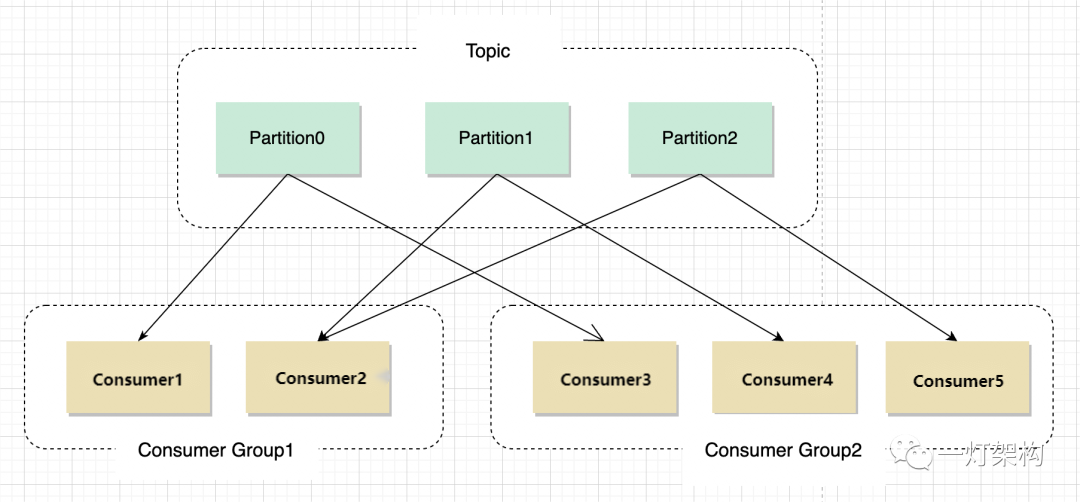
Kafka 为了提高消息的处理效率,引入了消费者组的概念。一个 消费者组(Consumer Group)包含多个消费者,一个消费者组可以同时订阅多个 Topic,一个 Topic 也可以同时被多个消费者组订阅。
为了保证同一个 Partition 的消息被顺序处理,针对一个消费者组,一个 Partition 的消息只会交给这个消息者组的一个消费者处理。
6.总结
本文简单介绍了 Kafka 架构,以及架构中涉及到底的一些名词概念,包括 Producer(生产者)、Consumer(消费者)、Broker(代理节点)、Topic(主题)、Partition(分区)、Leader Replica(领导者副本)、Follower Replica(跟随者副本)、LEO(Log End Offset,日志结束偏移量)、HW(High Watermark,高水位)、Consumer Group(消费者组)等。下篇文章再接着介绍 Kafka 如何解决消息丢失、重复消费、顺序消息、持久化消息、Leader 选举过程等。
相关文章:
【大数据】Kafka 入门指南
Kafka 入门指南 1.Kafka 简介2.Kafka 架构3.分区与副本4.偏移量5.消费者组6.总结 1.Kafka 简介 Apache Kafka 是一种高吞吐、分布式的流处理平台,由 LinkedIn 开发并于 2011 年开源。它具有 高伸缩性、高可靠性 和 低延迟 等特点,因此在大型数据处理场景…...

Qt 5.15集成Crypto++ 8.8.0(MSVC 2019)笔记
一、背景 笔者已介绍过在Qt 5.15.x中使用MinGW(8.10版本)编译并集成Crypto 8.8.0。 但是该编译出来的库(.a和.dll)不适用MSVC(2019版本)构建环境,需要重新编译(.lib或和.dll…...
)
前端面试的话术集锦第 9 篇:高频考点(webpack性能优化)
这是记录前端面试的话术集锦第九篇博文——高频考点(webpack性能优化),我会不断更新该博文。❗❗❗ 在此章节中,我不会浪费篇幅给大家讲如何写配置文件。如果你想学习这方面的内容,那么完全可以去官网学习。在这部分的内容中,我们会聚焦于以下两个知识点,并且每一个知识…...

程序员,你真热爱编程吗?
程序员的热爱与演变 我发现,程序员这个行业不像其他行业那样,很多人是因为热爱编程才去做程序员,不会被逼无奈去做程序员(要是真有就太惨了)。 热爱编程的漫长过程 热爱过、⼜不爱了、⼜爱了,这是个过程…...

算法通关村-----海量数据的处理方法
从40亿中产生一个不存在的数 问题描述 给定一个文件,包含40亿个非负整数,请你设计一个算法,产生一个不在该文件中的数字。假设你只有1GB内存。 问题分析 40亿整数,在java中,用int存储的话,大概需要40亿✖️4B,大约…...

Pytorch 多卡并行(1)—— 原理简介和 DDP 并行实践
近年来,深度学习模型的规模越来越大,需要处理的数据也越来越多,单卡训练的显存空间和计算效率都越来越难以满足需求。因此,多卡并行训练成为了一个必要的解决方案本文主要介绍使用 Pytorch 的 DistributedDataParallel(…...

快速排序(重点)
前言 快排是一种比较重要的排序算法,他的思想有时候会作用到个别算法提上,公司招聘的笔试上有时候也有他的过程推导题,所以搞懂快排势在必行!!! 快速排序 基本思想: 根据基准,将数…...

python高级内置函数介绍及应用举例
目录 1. 概述2. 举例 1. 概述 Python中有许多高级内置函数,它们提供了丰富的功能和便利性,可以大大简化代码并提高效率。以下是一些常用的高级内置函数: map(): 用于将一个函数应用于一个可迭代对象的所有项,返回一…...

人体呼吸存在传感器成品,毫米波雷达探测感知技术,引领智能家居新潮流
随着科技的不断进步和人们生活质量的提高,智能化家居逐渐成为一种时尚和生活方式。 人体存在传感器作为智能家居中的重要组成部分,能够实时监测环境中人体是否存在,为智能家居系统提供更加精准的控制和联动。 在这个充满创新的时代…...
软件设计模式(三):责任链模式
前言 前面荔枝梳理了有关单例模式、策略模式的相关知识,这篇文章荔枝将沿用之前的写法根据示例demo来体会这种责任链设计模式,希望对有需要的小伙伴有帮助吧哈哈哈哈哈哈~~~ 文章目录 前言 责任链模式 1 简单场景 2 责任链模式理解 3 Java下servl…...

开发者的商业智慧:产品立项策划你知道多少?
文章目录 想法的萌芽🌟初步评估产品可行性🍊分析核心功能和特点以及竞争对手📝大健康监测📝时尚新科技产品📝准确性📝多功能📝品牌口碑📝数据分析与个性化建议📝社交互动…...
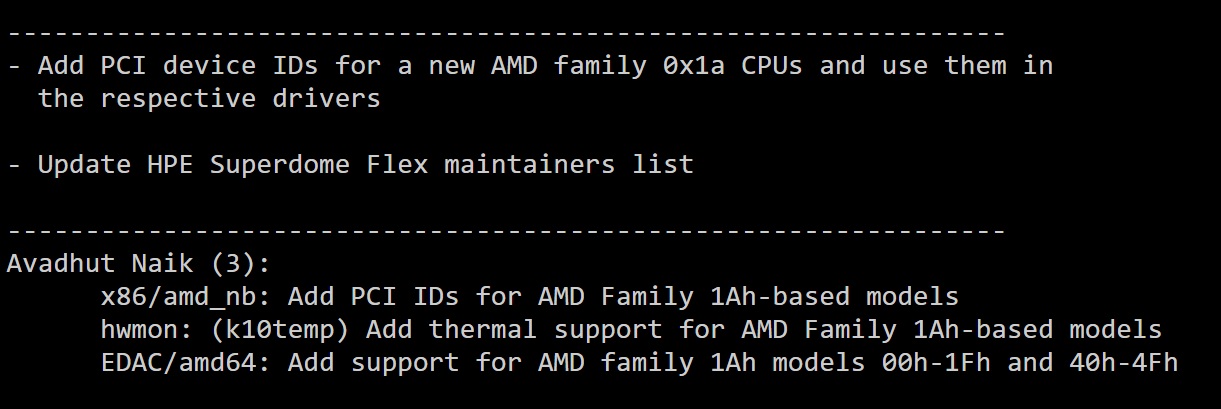
Linux 6.6 初步支持AMD 新一代 Zen 5 处理器
AMD 下一代 Zen 5 CPU 现已开始为 Linux 6.6 支持提交相关代码,最新补丁包括提供温度监控和 EDAC 报告等。 最新的 Linux 6.6 代码中已经加入了包括支持硬件监视器温度监控和 EDAC 报告的补丁。此外,新版本还加入了 x86 / misc 补丁,Phoronix…...
第五章 Linux常用应用软件
第五章 Linux常用应用软件 Ubuntu包含了日常所需的常用程序,集成了跨平台的办公套件LibreOffice和Mozila Firefox浏览器等。还提供了文本处理工具、图片处理工具等。 1.LibreOffice LibreOffice免费开源,遵照GPL分发源代码,与OpenOf…...
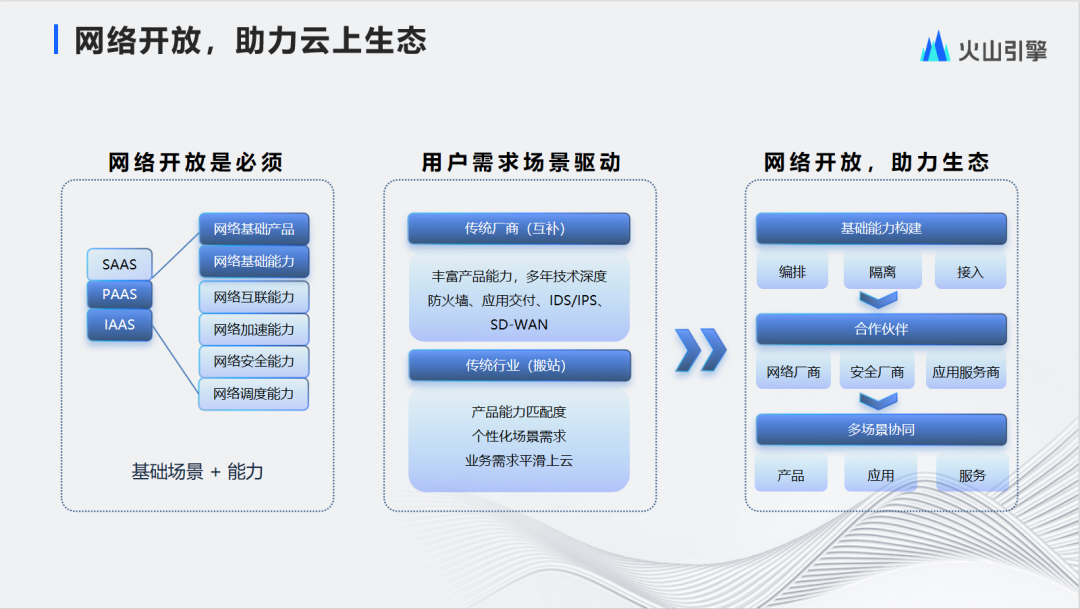
连接云-边-端,构建火山引擎边缘云网技术体系
近日,火山引擎边缘云网络产品研发负责人韩伟在LiveVideoStack Con 2023上海站围绕边缘云海量分布式节点和上百T的网络规模,结合边缘云快速发展期间遇到的各种问题和挑战,分享了火山引擎边缘云网的全球基础设施,融合开放的云网技术…...
系统架构设计师(第二版)学习笔记----系统架构设计师概述
【原文链接】系统架构设计师(第二版)学习笔记----系统架构设计师概述 文章目录 一、架构设计师的定义、职责和任务1.1 架构设计师的定义1.2 架构设计师的任务 二、架构设计师应具备的专业素质2.1 架构设计师应具备的专业知识2.2 架构设计师的知识结构2.3…...

自动化测试:Selenium中的时间等待
在 Selenium 中,时间等待指在测试用例中等待某个操作完成或某个事件发生的时间。Selenium 中提供了多种方式来进行时间等待,包括使用 ExpectedConditions 中的 presence_of_element_located 和 visibility_of_element_located 方法等待元素可见或不可见&…...

vim 替换命令 “:s“
vim 替换命令 ":s" 1. 替换光标所在行的第一个匹配串2. 替换光标所在行全部匹配项3. 替换两行之间每行的第一个匹配项4. 替换两行之间的全部匹配项5. 替换整个文件中的每个匹配串6. 查找整个文件中的每个匹配串并询问是否替换 1. 替换光标所在行的第一个匹配串 命令…...
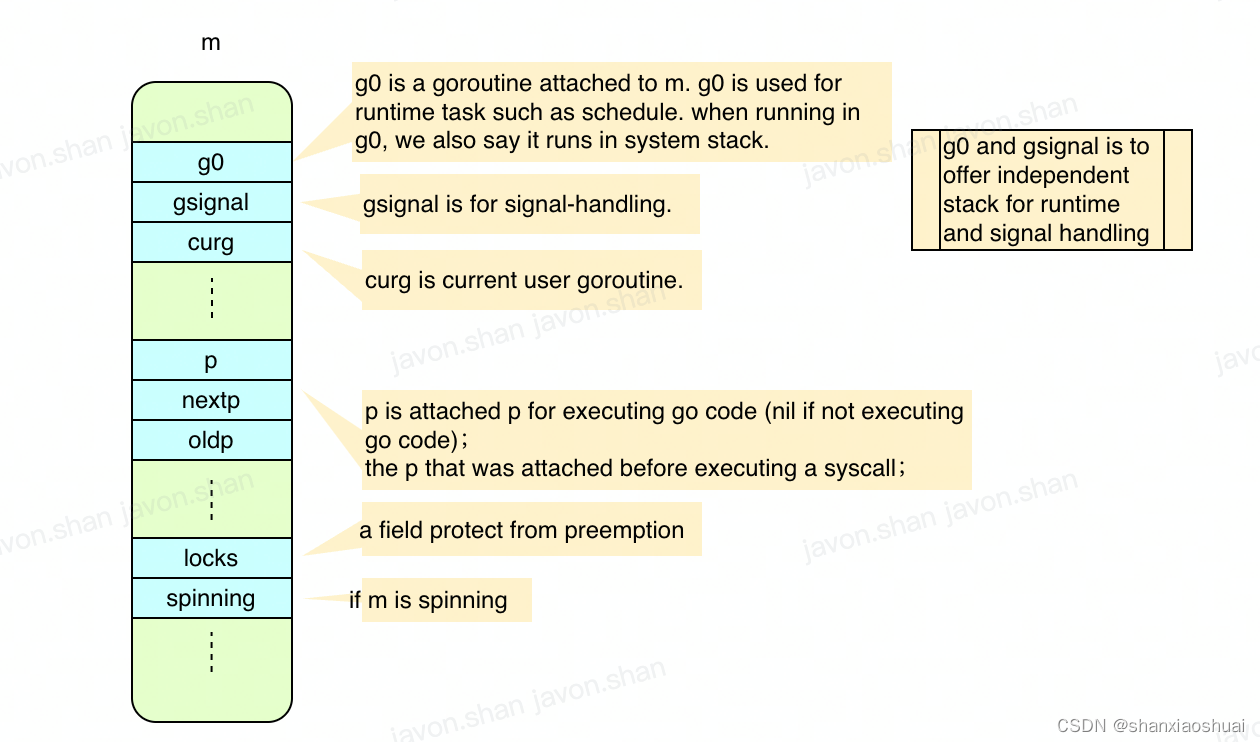
【golang】调度系列之m
调度系列 调度系列之goroutine 上一篇中介绍了goroutine,最本质的一句话就是goroutine是用户态的任务。我们通常说的goroutine运行其实严格来说并不准确,因为任务只能被执行。那么goroutine是被谁执行呢?是被m执行。 在GMP的架构中ÿ…...

可持久化线段树
可持久化线段树 模板 在某一指定版本的单点查,单点修。 开 m m m 棵线段树,每次修改复制后单点修。时间复杂度 O ( m ( n log n ) ) O(m(n\log n)) O(m(nlogn)),空间复杂度 O ( n m ) O(nm) O(nm),不如暴力。 每次修改…...

运行 Node.js 与浏览器 JavaScript
浏览器和 Node.js 都使用 JavaScript 软件语言 - 但字面上的运行时环境是不同的。 Node.js(又名服务器端 JavaScript)与客户端 JavaScript 有许多相似之处。它也有很多差异。 尽管两者都使用 JavaScript 作为软件语言,但我们可以重点关注一些关键差异,这些差异使两者之间…...

Go语言依赖管理:从GOPATH到Go Modules
Go语言依赖管理:从GOPATH到Go Modules 作为一个写了十几年代码的Go后端老兵,我经历了Go语言依赖管理的从GOPATH到Go Modules的转变,踩了不少坑。今天就来分享一下Go语言依赖管理的实践经验。 一、依赖管理的演进 1. GOPATH时代 在Go 1.11之前…...

League Akari:英雄联盟玩家的智能效率工具集,从自动秒选到战绩分析的全能助手
League Akari:英雄联盟玩家的智能效率工具集,从自动秒选到战绩分析的全能助手 【免费下载链接】League-Toolkit 兴趣使然的、简单易用的英雄联盟工具集。支持战绩查询、自动秒选等功能。基于 LCU API。 项目地址: https://gitcode.com/gh_mirrors/le/L…...

高效USB设备管理工具:一键安全弹出的专业解决方案
高效USB设备管理工具:一键安全弹出的专业解决方案 【免费下载链接】USB-Disk-Ejector A program that allows you to quickly remove drives in Windows. It can eject USB disks, Firewire disks and memory cards. It is a quick, flexible, portable alternative…...
与串口占用疑难排查实战)
ESP32-C3开发环境搭建(VSCode+ESP-IDF)与串口占用疑难排查实战
1. ESP32-C3开发环境搭建全攻略 第一次接触ESP32-C3开发板时,我和大多数开发者一样,被环境搭建这个"入门杀"折腾得够呛。特别是使用合宙经典款开发板时,USB转串口芯片带来的各种"惊喜"让人措手不及。这里分享一套经过实战…...

Wan2.2-I2V-A14B高性能实践:10核CPU+120GB内存协同优化视频推理稳定性
Wan2.2-I2V-A14B高性能实践:10核CPU120GB内存协同优化视频推理稳定性 1. 镜像概述与核心优势 Wan2.2-I2V-A14B是一款专为高性能文生视频任务优化的私有部署镜像,针对RTX 4090D 24GB显存显卡和10核CPU120GB内存配置进行了深度优化。这个镜像解决了视频生…...

暴力检测新思路:如何用HL-Net和弱监督技术提升多模态识别准确率?
多模态暴力检测技术革新:HL-Net与弱监督学习的实战解析 暴力行为检测一直是计算机视觉和音频分析领域的重要挑战。传统的暴力检测方法往往受限于单一模态输入、高昂的标注成本以及有限的场景适应性。本文将深入探讨如何通过HL-Net架构和弱监督学习技术,构…...

基于Python的网上商城的设计与实现
目录 可选框架 可选语言 内容 可选框架 J2EE、MVC、vue3、spring、springmvc、mybatis、SSH、SpringBoot、SSM、django 可选语言 java、web、PHP、asp.net、javaweb、C#、python、 HTML5、jsp、ajax、vue3 内容 随着信息化时代的到来,电子商务变得家喻户晓&…...

告别传统拍摄:THE LEATHER ARCHIVE低成本生成高质量皮衣展示图
告别传统拍摄:THE LEATHER ARCHIVE低成本生成高质量皮衣展示图 1. 时尚行业的数字革命 在时尚电商领域,商品展示图的质量直接影响消费者的购买决策。传统皮衣拍摄面临三大痛点: 高昂成本:专业模特、摄影师、场地租赁等费用动辄…...

当分包时,主包里有未被引用的文件,小程序预览【代码质量】显示包体积过大,不影响发布
1.项目加入分包后预览时显示主包体积超出?排查分包没问题,外部库方法也不会占很多空间2.代码依赖分析【显示 - 主包体积正常】主包实际体积(768KB)明明远小于 2MB 上限,但工具却提示「主包尺寸应小于 1.5M」且未通过。…...

从时频分析到信号净化:小波变换的降噪实战指南
1. 小波变换基础:从傅里叶到时频分析 第一次接触小波变换时,我和大多数工程师一样,脑子里全是傅里叶变换的影子。记得当时处理一组振动传感器数据,傅里叶变换告诉我信号里存在30Hz和50Hz的成分,但就是找不到这些频率具…...