Pytorch Advanced(三) Neural Style Transfer
神经风格迁移在之前的博客中已经用keras实现过了,比较复杂,keras版本。
这里用pytorch重新实现一次,原理图如下:

from __future__ import division
from torchvision import models
from torchvision import transforms
from PIL import Image
import argparse
import torch
import torchvision
import torch.nn as nn
import numpy as npdevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')加载图像
def load_image(image_path, transform=None, max_size=None, shape=None):"""Load an image and convert it to a torch tensor."""image = Image.open(image_path)if max_size:scale = max_size / max(image.size)size = np.array(image.size) * scaleimage = image.resize(size.astype(int), Image.ANTIALIAS)if shape:image = image.resize(shape, Image.LANCZOS)if transform:image = transform(image).unsqueeze(0)return image.to(device)这里用的模型是 VGG-19,所要用的是网络中的5个卷积层
class VGGNet(nn.Module):def __init__(self):"""Select conv1_1 ~ conv5_1 activation maps."""super(VGGNet, self).__init__()self.select = ['0', '5', '10', '19', '28'] self.vgg = models.vgg19(pretrained=True).featuresdef forward(self, x):"""Extract multiple convolutional feature maps."""features = []for name, layer in self.vgg._modules.items():x = layer(x)if name in self.select:features.append(x)return features模型结构如下,可以看到使用序列模型来写的VGG-NET,所以标号即层号,我们要保存的是['0', '5', '10', '19', '28'] 的输出结果。
VGG((features): Sequential((0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU(inplace)(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(3): ReLU(inplace)(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(6): ReLU(inplace)(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(8): ReLU(inplace)(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(11): ReLU(inplace)(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(13): ReLU(inplace)(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(15): ReLU(inplace)(16): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(17): ReLU(inplace)(18): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(19): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(20): ReLU(inplace)(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(22): ReLU(inplace)(23): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(24): ReLU(inplace)(25): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(26): ReLU(inplace)(27): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(29): ReLU(inplace)(30): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(31): ReLU(inplace)(32): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(33): ReLU(inplace)(34): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(35): ReLU(inplace)(36): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))(classifier): Sequential((0): Linear(in_features=25088, out_features=4096, bias=True)(1): ReLU(inplace)(2): Dropout(p=0.5)(3): Linear(in_features=4096, out_features=4096, bias=True)(4): ReLU(inplace)(5): Dropout(p=0.5)(6): Linear(in_features=4096, out_features=1000, bias=True))
)训练:
接下来对训练过程进行解释:
1、加载风格图像和内容图像,我们在之前的博客中使用的一幅加噪图进行训练,这里是用的内容图像的拷贝。
2、我们需要优化的就是作为目标的内容图像拷贝,可以看到target需要求导。
3、VGGnet参数是不需要优化的,所以设置为验证状态。
4、将3幅图像输入网络,得到总共15个输出(每个图像有5层的输出)
5、内容损失:这里是遍历5个层的输出来计算损失,而在keras版本中只用了第4层的输出计算损失
6、风格损失:同样计算格拉姆风格矩阵,将每一层的风格损失叠加,得到总的风格损失,计算公式同样和keras版本有所不一样
7、反向传播
def main(config):# Image preprocessing# VGGNet was trained on ImageNet where images are normalized by mean=[0.485, 0.456, 0.406] and std=[0.229, 0.224, 0.225].# We use the same normalization statistics here.transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225))])# Load content and style images# Make the style image same size as the content imagecontent = load_image(config.content, transform, max_size=config.max_size)style = load_image(config.style, transform, shape=[content.size(2), content.size(3)])# Initialize a target image with the content imagetarget = content.clone().requires_grad_(True)optimizer = torch.optim.Adam([target], lr=config.lr, betas=[0.5, 0.999])vgg = VGGNet().to(device).eval()for step in range(config.total_step):# Extract multiple(5) conv feature vectorstarget_features = vgg(target)content_features = vgg(content)style_features = vgg(style)style_loss = 0content_loss = 0for f1, f2, f3 in zip(target_features, content_features, style_features):# Compute content loss with target and content imagescontent_loss += torch.mean((f1 - f2)**2)# Reshape convolutional feature maps_, c, h, w = f1.size()f1 = f1.view(c, h * w)f3 = f3.view(c, h * w)# Compute gram matrixf1 = torch.mm(f1, f1.t())f3 = torch.mm(f3, f3.t())# Compute style loss with target and style imagesstyle_loss += torch.mean((f1 - f3)**2) / (c * h * w) # Compute total loss, backprop and optimizeloss = content_loss + config.style_weight * style_loss optimizer.zero_grad()loss.backward()optimizer.step()if (step+1) % config.log_step == 0:print ('Step [{}/{}], Content Loss: {:.4f}, Style Loss: {:.4f}' .format(step+1, config.total_step, content_loss.item(), style_loss.item()))if (step+1) % config.sample_step == 0:# Save the generated imagedenorm = transforms.Normalize((-2.12, -2.04, -1.80), (4.37, 4.46, 4.44))img = target.clone().squeeze()img = denorm(img).clamp_(0, 1)torchvision.utils.save_image(img, 'output-{}.png'.format(step+1))写在if __name__=="__main__"后面的语句只会在本脚本中才能被执行,被调用时是不会被执行的。
python的命令行工具:argparse,很优雅的添加参数
但是由于jupyter不支持添加外部参数,所以使用了外部博客的方法来支持(记住更改读取图片的位置)
import sys
if __name__ == "__main__":#解决方案来自于博客if '-f' in sys.argv:sys.argv.remove('-f')parser = argparse.ArgumentParser()parser.add_argument('--content', type=str, default='png/content.png')parser.add_argument('--style', type=str, default='png/style.png')parser.add_argument('--max_size', type=int, default=400)parser.add_argument('--total_step', type=int, default=2000)parser.add_argument('--log_step', type=int, default=10)parser.add_argument('--sample_step', type=int, default=500)parser.add_argument('--style_weight', type=float, default=100)parser.add_argument('--lr', type=float, default=0.003)#config = parser.parse_args()config = parser.parse_known_args()[0] #参考博客 https://blog.csdn.net/ken_for_learning/article/details/89675904print(config)main(config)相关文章:
Pytorch Advanced(三) Neural Style Transfer
神经风格迁移在之前的博客中已经用keras实现过了,比较复杂,keras版本。 这里用pytorch重新实现一次,原理图如下: from __future__ import division from torchvision import models from torchvision import transforms from PIL…...
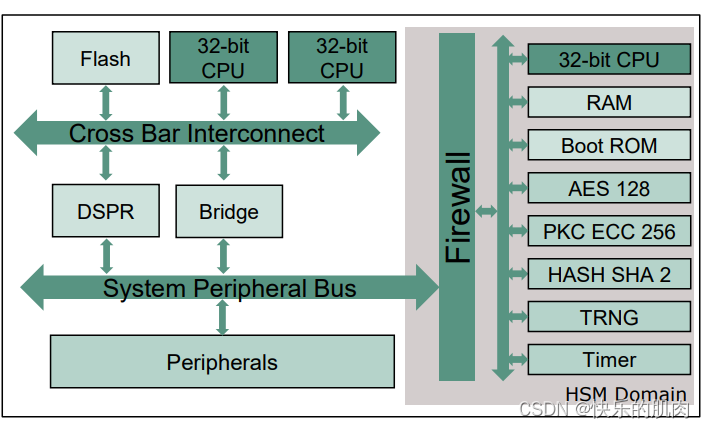
英飞凌TC3xx--深度手撕HSM安全启动(三)--TC3xx HSM系统架构
今天聊TC3xx HSM系统,包括所用内核、UCB相关信息、Host和HSM交互方式。 1、HSM系统架构 下图来源于英飞凌官网培训材料。 TC3xx的HSM内核是一颗32位的ARM Cortex M3,主频可达100MHz,支持对称算法AES128、非对称算法PKC(Public Key Crypto) ECC256、Hash SHA2,以及T…...
黑马JVM总结(五)
(1)方法区 它是所有java虚拟机 线程共享的区,存储着跟类的结构相关的信息,类的成员变量,方法数据,成员方法,构造器方法,特殊方法(类的构造器) 方法区在虚拟机…...

C语言入门Day_18 判断和循坏的小结
目录 前言: 1.判断 2.循环 3.课堂笔记 4.思维导图 前言: 判断语句和循环语句都可以大致分为三个部分,第一个部分是固定的语法格式;第二部分是代码的执行顺序,第三部分是判断和循环成立与否的判断条件。 1.判断 1…...

mac 好用的工具推荐
mac 好用的工具推荐 落雪:全网的音乐畅听,下载地址:https://github.com/lyswhut/lx-music-desktopMotrix: 免费下载工具,下载地址:https://xclient.info/s/motrix.html#versionsDownie:视频下载工具&#x…...
星际争霸之小霸王之小蜜蜂(十二)--猫有九条命
系列文章目录 星际争霸之小霸王之小蜜蜂(十一)--杀杀杀 星际争霸之小霸王之小蜜蜂(十)--鼠道 星际争霸之小霸王之小蜜蜂(九)--狂鼠之灾 星际争霸之小霸王之小蜜蜂(八)--蓝皮鼠和大…...

【软件分析/静态分析】chapter8 课程11/12 指针分析—上下文敏感(Pointer Analysis - Context Sensitivity)
🔗 课程链接:李樾老师和谭天老师的: 南京大学《软件分析》课程11(Pointer Analysis - Context Sensitivity I)_哔哩哔哩_bilibili 南京大学《软件分析》课程12(Pointer Analysis - Context Sensitivity II&…...

时间复杂度与空间复杂度详解
时间复杂度与空间复杂度详解🦖 一、算法效率1.1 如何衡量一个算法的好坏1.2 算法的复杂度 二、时间复杂度2.1 时间复杂度的定义2.2 大O的渐进表示法2.3 如何记录表示算法复杂度 三、空间复杂度3.1 空间复杂度的定义3.2 小试牛刀 一、算法效率 1.1 如何衡量一个算法…...

目录操作函数
mkdir函数 rmdir函数 删除空目录 rename函数 换名 chdir函数 修改当前的工作目录 getcwd函数 获取当前工作的路径...
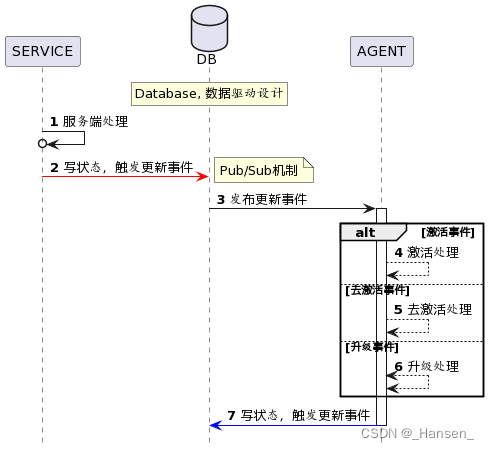
PlantUML入门教程:画时序图
软件工程中会用到各种UML图,例如用例图、时序图等。那我们能不能像写代码一样去画图呢? 今天推荐一款软件工程师的作图利器--PlantUML,它能让你用写代码的方式快速画出UML图。 一、什么是PlantUML? PlantUML是一个允许你快速作出…...

C#范围运算符
C#8.0语法中,范围运算符是一种用于快速截取序列的运算符,其语法为 “start…end”,表示从序列的 “start” 索引处开始,一直截取到"end" 索引处为止(包括 “end” 索引处的元素)。范围运算符主要…...
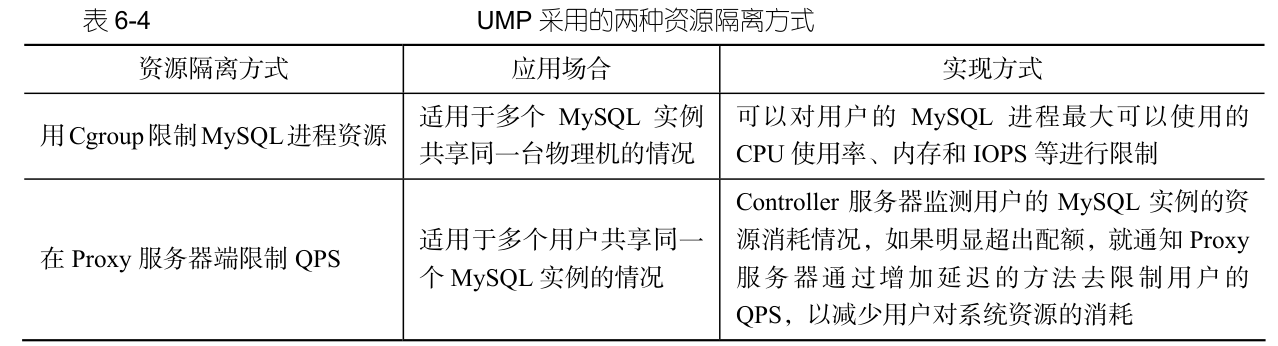
云数据库知识学习——云数据库产品、云数据库系统架构
一、云数据库产品 1.1、云数据库厂商概述 云数据库供应商主要分为三类。 ① 传统的数据库厂商,如 Teradata、Oracle、IBM DB2 和 Microsoft SQL Server 等。 ② 涉足数据库市场的云供应商,如 Amazon、Google、Yahoo!、阿里、百度、腾讯…...

C++中引用详解!
前言: 本文旨在讲解C中引用的相关操作,以及引用的一些注意事项!搬好小板凳,干货来了! 引用的概念 何谓引用呢?引用其实很容易理解,比如李华这个同学,他因为很调皮,所以…...

VUE3+TS项目无法找到模块“../version/version.js”的声明文件
问题描述 在导入 ../version/version.js 文件时,提示无法找到模块 解决方法 将version.js改为version.ts可以正常导入 注意,因为version.js是我自己写的模块,我可以直接该没有关系,但是如果是引入的其他的第三方包,…...

数据结构-堆的实现及应用(堆排序和TOP-K问题)
数据结构-堆的实现及应用[堆排序和TOP-K问题] 一.堆的基本知识点1.知识点 二.堆的实现1.堆的结构2.向上调整算法与堆的插入2.向下调整算法与堆的删除 三.整体代码四.利用回调函数避免对向上和向下调整算法的修改1.向上调整算法的修改2.向下调整算法的修改3.插入元素和删除元素函…...

Spring 条件注解没生效?咋回事
条件注解相信各位小伙伴都用过,Spring 中的多环境配置 profile 底层就是通过条件注解来实现的,松哥在之前的 Spring 视频中也有和大家详细介绍过条件注解的使用,感兴趣的小伙伴戳这里:Spring源码应该怎么学?。 从 Spr…...

96. 不同的二叉搜索树
class Solution { public:int numTrees(int n) {if (n0) {return 1;}vector<int> dp(n1, 0);dp[0] 1;dp[1] 0;for (int i 1; i < n; i) {for (int j 0; j < i; j) {dp[i] dp[j] * dp[i - 1 - j];}}return dp[n];} };...

Android Jetpack 中Hilt的使用
Hilt 是 Android 的依赖项注入库,可减少在项目中执行手动依赖项注入的样板代码。执行 手动依赖项注入 要求您手动构造每个类及其依赖项,并借助容器重复使用和管理依赖项。 Hilt 通过为项目中的每个 Android 类提供容器并自动管理其生命周期,…...

批量采集的时间管理与优化
在进行大规模数据采集时,如何合理安排和管理爬取任务的时间成为了每个专业程序员需要面对的挑战。本文将分享一些关于批量采集中时间管理和优化方面的实用技巧,帮助你提升爬虫工作效率。 1. 制定明确目标并设置合适频率 首先要明确自己所需获取数据的范…...

uniApp监听左右滑动事件
监听左右滑动事件的步骤 1. 添加需要监听滑动事件的元素 在你的页面中,添加需要监听滑动事件的元素。这可以是一个 view、swiper 或其他组件,取决于你的需求。例如: <template><view class"body" touchstart"touc…...

数学竞赛资源合集
《高中数学•竞赛教程》四册(第三版) 文件大小: 1.1GB内容特色: 四册高清笔记真题拆解,省队教练亲授适用人群: 想一年冲省一的高一高二竞赛党核心价值: 刷完这套,一试二试不再丢分下载链接: https://pan.quark.cn/s/7a64da5c8d8d 浙大优学-高中数学竞赛…...

专利价值评估实战:从技术保护到商业竞争的核心方法论
1. 专利资产价值评估:从“纸面权利”到“商业武器”的实战拆解在科技行业摸爬滚打十几年,我见过太多公司手握一堆专利证书,却说不清它们到底值多少钱。这感觉就像你家里藏了一箱古董,只知道它们“可能很值钱”,但具体哪…...

经营分析≠财务分析,经营分析必看的3条路径分析
每个月开经营分析会,我最怕看到什么?就是财务把利润表从头到尾念了一遍,收入多少、成本多少、费用多少,然后开始读PPT。念完就散会。问题解决了吗?没有。说实话,我第一次看这种汇报也觉得数据很全ÿ…...

创业沟通陷阱:从“一切顺利”到“坦诚求助”的工程化实践
1. 项目概述:当“独角兽”闭上嘴,“彩虹”褪了色在科技创业圈混了十几年,从硅谷到深圳,从硬件孵化器到软件路演日,我见过太多这样的场景。你走进一个挤满创业者的房间,空气里弥漫着咖啡因和焦虑混合的独特气…...

计算机专业不想“敲代码”,都来冲这个行业
计算机专业不想“敲代码”,都来冲这个行业 在这个信息爆炸的时代,计算机专业作为热门选择之一,吸引了无数学子的目光。但与此同时,也有相当一部分同学心存疑虑:自己是计算机专业的,却对写代码提不起兴趣&a…...
)
分享!关于虚拟机性能优化实战的技术文(进击篇 学习资料自提取)
一、 综述与基础理论类文献 (帮助构建背景和原理部分大纲) 虚拟化技术综述: 查找标题包含“虚拟化技术综述”、“虚拟化原理与发展”等关键词的中文学术论文或书籍章节。这些文献通常会涵盖CPU虚拟化、内存虚拟化、I/O虚拟化等核心技术,为理解性能瓶颈和…...

扰动补偿自触发MPC控制器设计【附代码】
✨ 长期致力于永磁同步电机、模型预测控制、扰动补偿、死区时间优化、自触发控制研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于预测误差驱动的扰…...

iPad协议开发老哥的避坑指南
兄弟们,在微信私域开发这条路上摸爬滚打了好几年,试过各种方案踩过无数坑,今天终于能给大家分享一个真正用着顺手、技术扎实的「宝藏工具」了——wechatapi 的 iPad 协议接口。作为过来人,真心想把这份「避坑指南」和开发经验掏心…...

探索Windows上的安卓应用部署:APK Installer技术实践指南
探索Windows上的安卓应用部署:APK Installer技术实践指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上直接运行安卓应用,却…...

PasteMD:一键解决AI内容到Office文档的格式转换难题
1. 项目概述与痛点解析如果你经常需要写论文、做报告,或者整理从各种AI助手(比如ChatGPT、DeepSeek、Kimi)那里得到的答案,那你一定遇到过这个让人头疼的问题:辛辛苦苦从网页上复制下来的内容,一粘贴到Word…...