(二十一)大数据实战——Flume数据采集之复制和多路复用案例实战
前言
本节内容我们完成Flume数据采集的一个多路复用案例,使用三台服务器,一台服务器负责采集本地日志数据,通过使用Replicating ChannelSelector选择器,将采集到的数据分发到另外俩台服务器,一台服务器将数据存储到hdfs,另外一台服务器将数据存储在本机,使用Avro的方式完成flume之间采集数据的传输。整体架构如下:

正文
①在hadoop101服务器的/opt/module/apache-flume-1.9.0/job目录下创建job-file-flume-avro.conf配置文件,用于监控hive日志并传输到avro sink
- job-file-flume-avro.conf配置文件
# Name the components on this agent a1.sources = r1 a1.sinks = k1 k2 a1.channels = c1 c2 # 将数据流复制给所有 channel a1.sources.r1.selector.type = replicating # Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /tmp/hadoop/hive.log a1.sources.r1.shell = /bin/bash -c # Describe the sink # sink 端的 avro 是一个数据发送者 a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop102 a1.sinks.k1.port = 4141 a1.sinks.k2.type = avro a1.sinks.k2.hostname = hadoop103 a1.sinks.k2.port = 4142 # Describe the channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.channels.c2.type = memory a1.channels.c2.capacity = 1000 a1.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 c2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c2

②在hadoop102服务器的/opt/module/apache-flume-1.9.0/job目录下创建job-avro-flume-hdfs.conf配置文件,将监控数据传输到hadoop的hdfs系统
- job-avro-flume-hdfs.conf配置文件
# Name the components on this agent a2.sources = r1 a2.sinks = k1 a2.channels = c1 # Describe/configure the source # source 端的 avro 是一个数据接收服务 a2.sources.r1.type = avro a2.sources.r1.bind = hadoop102 a2.sources.r1.port = 4141 # Describe the sink a2.sinks.k1.type = hdfs a2.sinks.k1.hdfs.path = hdfs://hadoop101:8020/flume2/%Y%m%d/%H #上传文件的前缀 a2.sinks.k1.hdfs.filePrefix = flume2- #是否按照时间滚动文件夹 a2.sinks.k1.hdfs.round = true #多少时间单位创建一个新的文件夹 a2.sinks.k1.hdfs.roundValue = 1 #重新定义时间单位 a2.sinks.k1.hdfs.roundUnit = hour #是否使用本地时间戳 a2.sinks.k1.hdfs.useLocalTimeStamp = true #积攒多少个 Event 才 flush 到 HDFS 一次 a2.sinks.k1.hdfs.batchSize = 100 #设置文件类型,可支持压缩 a2.sinks.k1.hdfs.fileType = DataStream #多久生成一个新的文件 a2.sinks.k1.hdfs.rollInterval = 30 #设置每个文件的滚动大小大概是 128M a2.sinks.k1.hdfs.rollSize = 134217700 #文件的滚动与 Event 数量无关 a2.sinks.k1.hdfs.rollCount = 0 # Describe the channel a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1

③在hadoop103服务器的/opt/module/apache-flume-1.9.0/job目录下创建job-avro-flume-dir.conf配置文件,将监控数据传输到/opt/module/apache-flume-1.9.0/flume3目录下
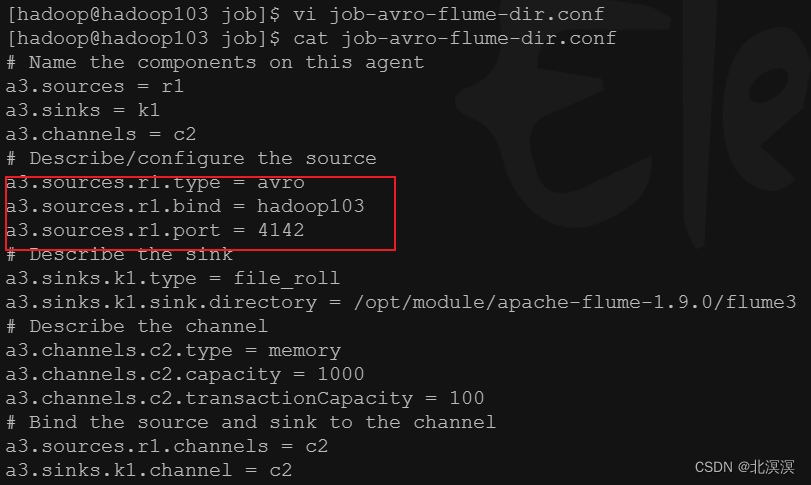
- job-avro-flume-dir.conf配置文件
# Name the components on this agent a3.sources = r1 a3.sinks = k1 a3.channels = c2 # Describe/configure the source a3.sources.r1.type = avro a3.sources.r1.bind = hadoop103 a3.sources.r1.port = 4142 # Describe the sink a3.sinks.k1.type = file_roll a3.sinks.k1.sink.directory = /opt/module/apache-flume-1.9.0/flume3 # Describe the channel a3.channels.c2.type = memory a3.channels.c2.capacity = 1000 a3.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r1.channels = c2 a3.sinks.k1.channel = c2
- 创建数据存储目录/opt/module/apache-flume-1.9.0/flume3
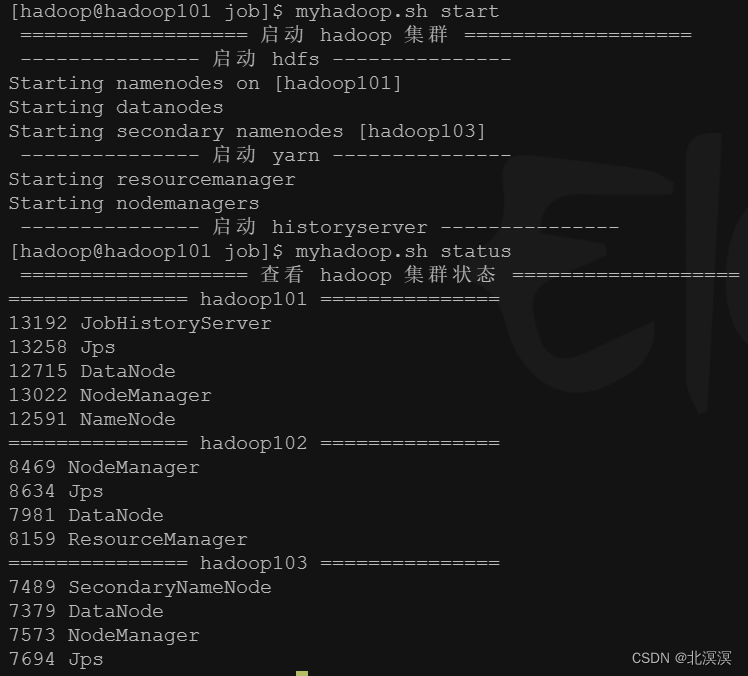
④启动hadoop集群
⑤启动hadoop102上的flume任务job-avro-flume-hdfs.conf
- 命令:
bin/flume-ng agent -c conf/ -n a2 -f job/job-avro-flume-hdfs.conf -Dflume.root.logger=INFO,console

⑥启动hadoop103上的flume任务job-avro-flume-dir.conf
- 命令:
bin/flume-ng agent -c conf/ -n a3 -f job/job-avro-flume-dir.conf -Dflume.root.logger=INFO,console
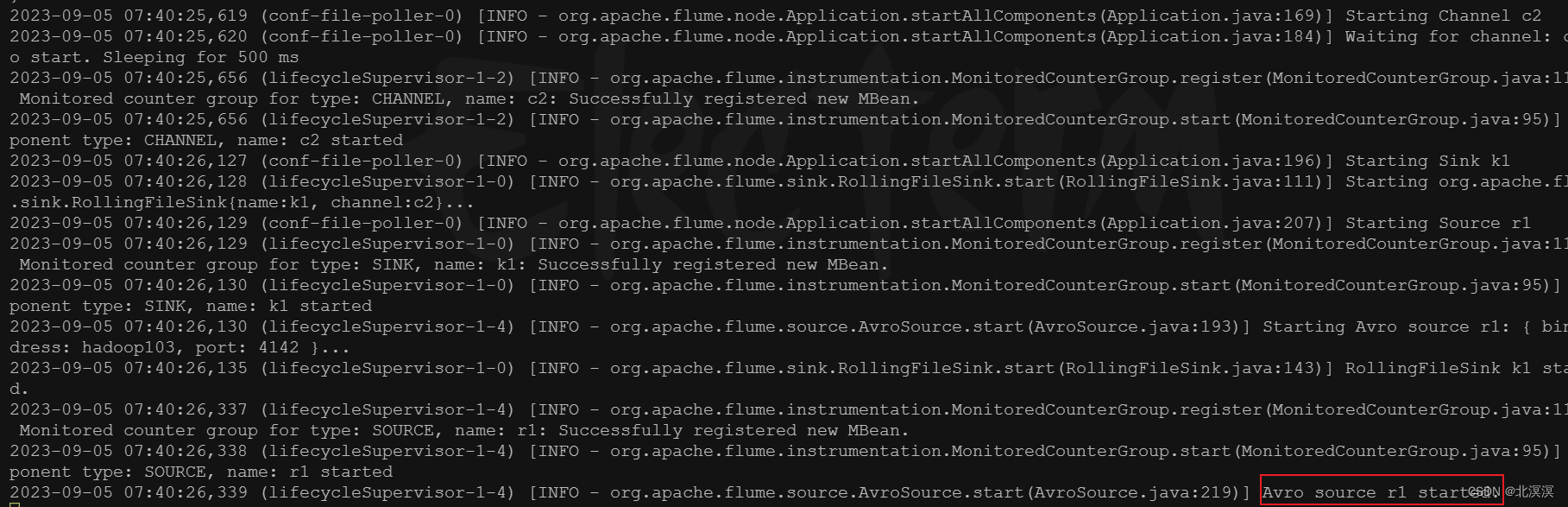
⑦启动hadoop101上的flume任务job-file-flume-avro.conf
- 命令:
bin/flume-ng agent -c conf/ -n a1 -f job/job-file-flume-avro.conf -Dflume.root.logger=INFO,console

⑧启动hive

⑨查看监控结果
- 查看hdfs
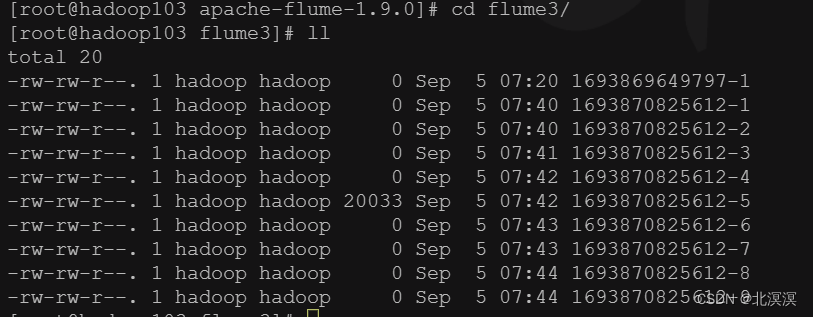
- 查看存储目录/opt/module/apache-flume-1.9.0/flume3下的文件

结语
至此,关于Flume数据采集之复制和多路复用案例实战到这里就结束了,我们下期见。。。。。。
相关文章:
(二十一)大数据实战——Flume数据采集之复制和多路复用案例实战
前言 本节内容我们完成Flume数据采集的一个多路复用案例,使用三台服务器,一台服务器负责采集本地日志数据,通过使用Replicating ChannelSelector选择器,将采集到的数据分发到另外俩台服务器,一台服务器将数据存储到hd…...

VM安装RedHat7虚机ens33网络不显示IP问题解决
1、今天在VMware中安装RedHat7.4虚拟机,网络连接使用的是 NAT 连接方式,刚开始安装成功之后输入ifconfig 还能看到ens33自动分配的IP地址,但是当虚机关机重启后,再查看IP发现原来的ens33网络已经没有了,只变成了这两个…...

Leetcode 第 362 场周赛题解
Leetcode 第 362 场周赛题解 Leetcode 第 362 场周赛题解题目1:2848. 与车相交的点思路代码复杂度分析 题目2:2849. 判断能否在给定时间到达单元格思路代码复杂度分析 题目3:2850. 将石头分散到网格图的最少移动次数思路代码复杂度分析 题目4…...
)
蓝桥杯官网练习题(0的个数)
问题描述 给定一个正整数 n ,请问 n 的十进制表示中末尾总共有几个 0 ? 输入格式 输入一行包含一个正整数 n。 输出格式 输出一个整数,表示答案。 样例输入 20220000样例输出 4评测用例规模与约定 对于所有评测用例,1 &l…...

计算线段上距离线段外某一点最近的点
一、问题 已知 p 0 = ( x 0 , y 0 ) p_0=(x_0, y_0) p...

港联证券股票分析:经济拐点显现 积极提升仓位
港联证券指出,商场底部上升的方向不变,当时稳增加和活跃资本商场的活跃方针仍在持续落地,一起也看到了一些经济数据边沿企稳的迹象,跟着方针作用的进一步闪现,商场情绪有望持续好转,上市公司基本面也有望得…...
)
不同的图像质量评价指标(IQA)
一、NR-IQA 这是一种方法不是指标 “Non-Reference Image Quality Assessment”(NR-IQA)是一种图像质量评价(Image Quality Assessment, IQA)方法,通常用于评估图像的质量,而无需使用参考图像(…...

linux命令-tar 命令
tar 命令 tar 命令一般用来打包文件 ,文件夹 , 方便传输使用. tar命令是在Linux和UNIX系统上用于创建、查看和提取tar归档文件的工具。它通常与gzip一起使用,以便在创建归档文件时进行压缩或解压缩。 -c: 创建归档文件 -x: 提取文件 -z: 告诉 tar 命令使用 gzip …...

selenium元素定位---ElementClickInterceptedException(元素点击交互异常)解决方法
1、异常原因 在编写ui自动化时,执行报错元素无法点击:ElementClickInterceptedException 具体报错:selenium.common.exceptions.ElementClickInterceptedException: Message: element click intercepted: Element <span class"el-c…...

05_css选择器的使用
一、css选择器的类型 1、标签选择器 用法:直接写 写标签名:标签名{} 示例: <!-- <!DOCTYPE html --> <html><head><meta charset"utf-8"><title>标签选择器</title><style type"te…...

跨平台游戏引擎 Axmol-2.0.0 正式发布
下载 https://github.com/axmolengine/axmol/releases/tag/v2.0.0 更新日志 添加实验性的 WebAssembly 构建支持(WebGL 2.0),由 nowasm 贡献 已知问题 WebGL context lost 尚未处理 部署在 github pages 的 demo 可快速预览,注意:由于 Git…...

面试总结归纳
面试总结 注:循序渐进,由点到面,从技术点的理解到项目中的使用, 要让面试官知道,我所知道的要比面试官更多 一、Mybatis 为ORM半持久层框架,它封装了JDBC,开发时只需要关注sql语句就可以了…...
【刷题篇】贪心算法(一)
文章目录 分割平衡字符串买卖股票的最佳时机Ⅱ跳跃游戏钱币找零 分割平衡字符串 class Solution { public:int balancedStringSplit(string s) {int lens.size();int cnt0;int balance0;for(int i0;i<len;i){if(s[i]R){balance--;}else{balance;}if(balance0){cnt;}}return …...

从维基百科通过关键字爬取指定文本内容
通过输入搜索的关键字,和搜索页数范围,爬出指定文本内内容并存入到txt文档。代码逐行讲解。 使用re、res、BeautifulSoup包读取,代码已测,可以运行。txt文档内容不乱码。 import re import requests from bs4 import BeautifulS…...
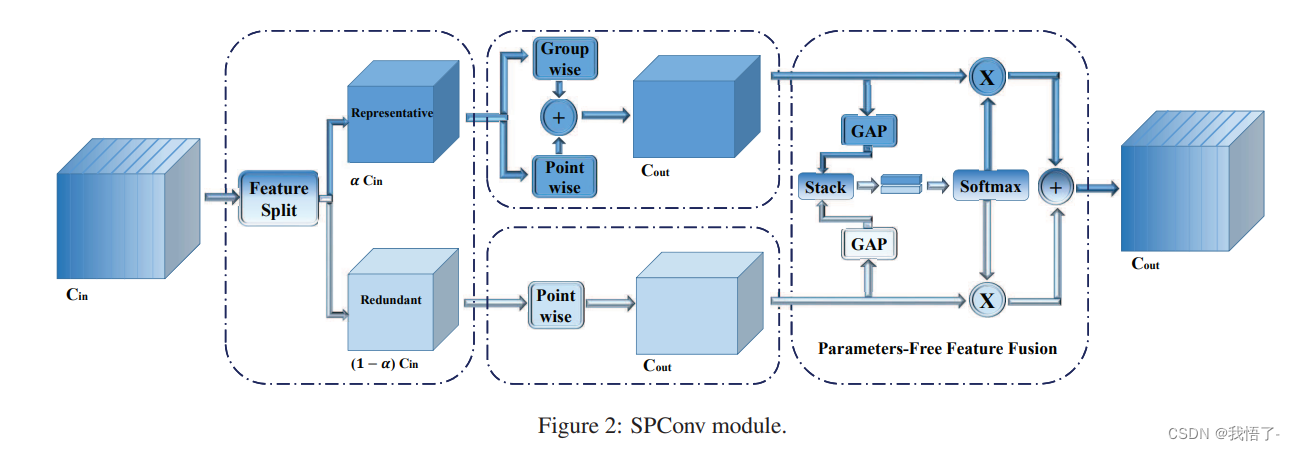
pytorch代码实现之SAConv卷积
SAConv卷积 SAConv卷积模块是一种精度更高、速度更快的“即插即用”卷积,目前很多方法被提出用于降低模型冗余、加速模型推理速度,然而这些方法往往关注于消除不重要的滤波器或构建高效计算单元,反而忽略了特征内部的模式冗余。 原文地址&am…...

一文解析-通过实例讲解 Linux 内存泄漏检测方法
一、mtrace分析内存泄露 mtrace(memory trace),是 GNU Glibc 自带的内存问题检测工具,它可以用来协助定位内存泄露问题。它的实现源码在glibc源码的malloc目录下,其基本设计原理为设计一个函数 void mtrace ()&#x…...

Spring Boot常用的参数验证技巧和使用方法
简介 Spring Boot是一个使用Java编写的开源框架,用于快速构建基于Spring的应用程序。在实际开发中,经常需要对输入参数进行验证,以确保数据的完整性和准确性。Spring Boot提供了多种方式来进行参数验证,并且可以很方便地集成到应…...

手机+卫星的科技狂想
最近硬件圈最火热的话题之一,应该就是突然上线、遥遥领先的华为Mate 60 Pro了。 其中,CPU和类5G网速是怎么实现的,是大家特别关注的问题。相比之下,卫星通话这个功能,讨论度就略低一些(没有说不火的意思&am…...
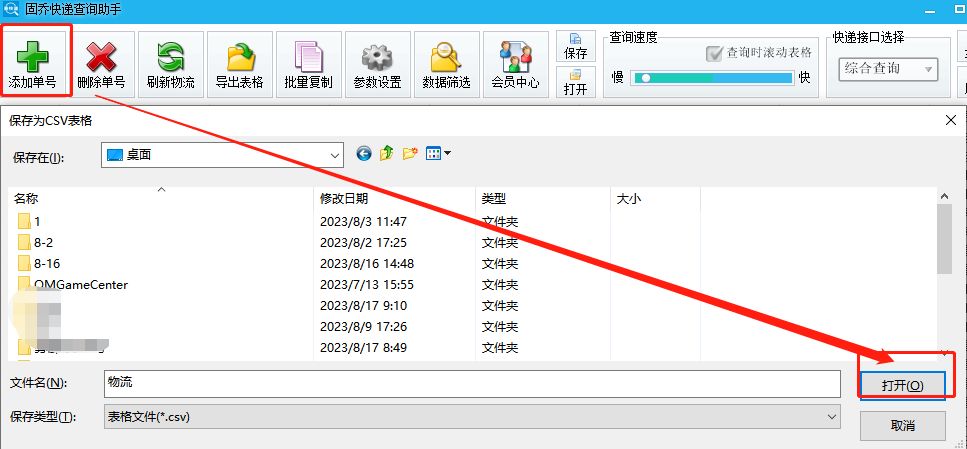
便捷查询中通快递,详细物流信息轻松获取
在如今快节奏的生活中,快递已成为人们生活中不可或缺的一部分。然而,快递查询却常常让人头疼,因为需要分别在不同的快递公司官网上进行查询,耗费时间和精力。为了解决这个问题,固乔科技推出了一款便捷的快递查询助手&a…...
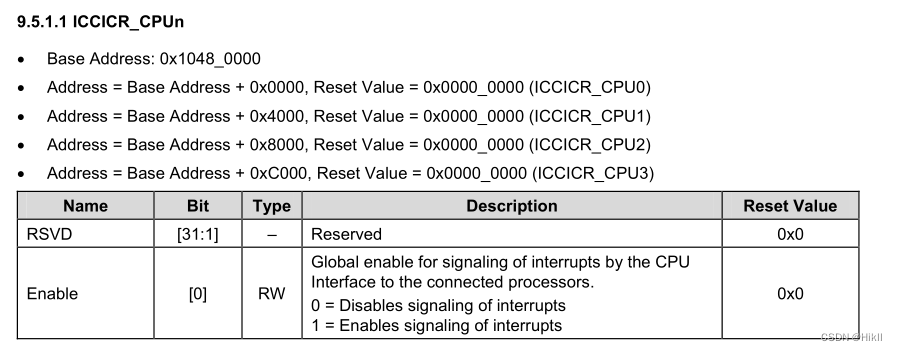
ARM接口编程—Interrupt(exynos 4412平台)
CPU与硬件的交互方式 轮询 CPU执行程序时不断地询问硬件是否需要其服务,若需要则给予其服务,若不需要一段时间后再次询问,周而复始中断 CPU执行程序时若硬件需要其服务,对应的硬件给CPU发送中断信号,CPU接收到中断信号…...

网络安全协议验证不求人:手把手教你用VirtualBox导入SPAN虚拟机跑AVISPA
网络安全协议验证实战:VirtualBoxSPAN虚拟机快速搭建AVISPA实验环境 在网络安全研究领域,协议验证是确保通信安全性的关键环节。AVISPA(Automated Validation of Internet Security Protocols and Applications)作为自动化验证工…...

终极指南:Marketing-for-Engineers心理学应用——影响用户决策的12个心理效应
终极指南:Marketing-for-Engineers心理学应用——影响用户决策的12个心理效应 【免费下载链接】Marketing-for-Engineers A curated collection of marketing articles & tools to grow your product. 项目地址: https://gitcode.com/gh_mirrors/ma/Marketin…...
ChatGPT 2026不是升级,是重构:Transformer-XL²架构、128K动态上下文、本地化模型热插拔——你还在用2023版?这5个信号说明你已被淘汰
更多请点击: https://intelliparadigm.com 第一章:ChatGPT 2026:一场从架构内核出发的范式革命 ChatGPT 2026 并非简单的能力叠加,而是以「动态稀疏混合专家(Dynamic Sparse MoE)」为核心重构推理路径&…...

芯片行业变革:开源硬件、可重构芯片与商业模式创新
1. 行业拐点:传统芯片商业模式为何难以为继?干了十几年芯片设计,从流片工程师到项目负责人,我亲眼见证了行业从“黄金时代”到如今“卷成本、卷工艺”的艰难转型。最近和几个老同事聊天,大家不约而同地提到一个词&…...

加拿大无人机产业:从感知到执行的自主化跃迁与BVLOS破局
1. 加拿大无人机产业的现状与挑战提起无人机,很多人脑海里首先蹦出来的可能是大疆,那个在全球消费级和部分商用市场占据绝对主导地位的中国品牌。这确实是一个不争的事实,也是加拿大本土无人机产业必须直面的现实。我接触过不少加拿大的初创公…...

构建可靠AI智能体:从提示词工程到结构化内容生成的实战指南
1. 项目概述与核心思路最近在折腾AI应用开发,特别是想搞一个能稳定输出、逻辑清晰、还能带点“人味儿”的文本生成工具。市面上现成的方案要么太“机械”,要么定制化程度不够,总感觉差点意思。后来,我在一个开发者社区里看到了一个…...

如何用wxlivespy实现微信视频号直播数据实时抓取与分析
如何用wxlivespy实现微信视频号直播数据实时抓取与分析 【免费下载链接】wxlivespy 微信视频号直播间弹幕信息抓取工具 项目地址: https://gitcode.com/gh_mirrors/wx/wxlivespy wxlivespy是一款专业级的微信视频号直播间弹幕信息抓取工具,能够实时捕获弹幕、…...

为个人AI助手项目集成多模型API实现成本与性能平衡
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为个人AI助手项目集成多模型API实现成本与性能平衡 构建个人AI助手是许多独立开发者热衷的项目。在开发过程中,一个常见…...

SAP IM投资管理:从后台配置到前台应用的实战指南
1. SAP IM投资管理模块入门指南 第一次接触SAP IM模块时,我被这个看似复杂但功能强大的系统深深吸引。IM(Investment Management)投资管理模块是SAP系统中专门用于管理企业资本性支出的核心组件,它能够帮助企业实现从预算分配到最…...

告别笨重模拟器:Windows系统上直接安装APK的终极方案
告别笨重模拟器:Windows系统上直接安装APK的终极方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经为了在电脑上运行一个简单的手机应用而不得…...