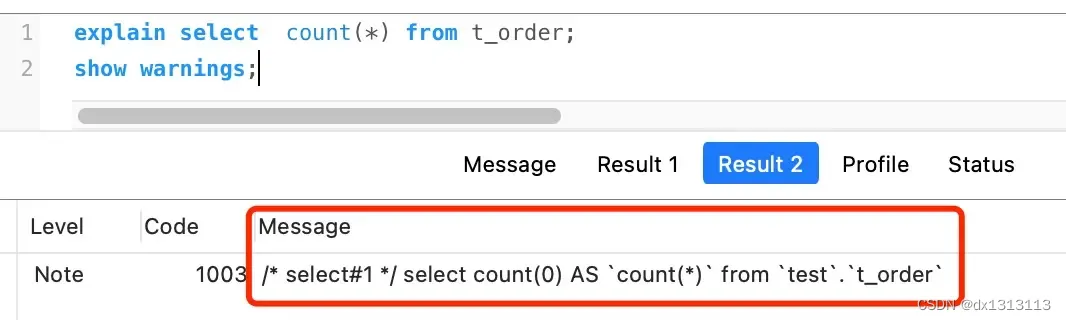
count(*) 和 count(1) 有什么区别?哪个性能最好?
哪种 count 性能最好?

count() 是什么?
count() 是一个聚合函数,函数的参数不仅可以是字段名,也可以是其他任意表达式,该函数的作用是统计符合查询条件的记录中,函数指定的参数不为 NULL 的记录由多少条。
假设 count() 函数的参数是字段名,如下:
select count(name) from t_order这条语句统计的是 [ t_order 表中,name 字段不为 NULL 的记录] 有多少个。
也就是说,如果某一条记录中的 name 字段的值为 NULL ,则就不会被统计进去。
再来假设 count() 函数的参数是数字 1 这个表达式,如下:
select count(1) from t_order;这条语句是统计 [t_order 表中, 1 这个表达式不为 NULL 的记录] 有多少个。
1 这个表达式就是单纯数字,它永远都不是 NULL 所以上面这条语句,其实是在统计 t_order 表中有多少条记录。
count(主键字段) 执行过程是怎样的?
在通过 count 函数统计有多少个记录时,MySQL 的 server 层会维护一个名叫 count 的变量。
server 层会循环向 InnoDB 读取一条记录,如果 count 函数指定的参数不为 NULL,那么就会将变量 count 加 1,直到符合查询的全部记录被读完,就退出循环,最后将 count 变量的值发送给客户端。
InnoDB 是通过 B+Tree 来保存记录的,根据索引的类型又分为聚簇索引和二级索引,它们的区别在于,聚簇索引的叶子节点存放的是实际数据,而二级索引的叶子节点存放的是主键值,而不是实际数据。
eg:
select count(id) from t_order;如果表里只有主键索引,没有二级索引时,那么,InnoDB 循环遍历聚簇索引,将读取到的记录返回给 server 层,然后读取记录中的 id 值,判断id值是否为 NULL,如果不为 NULL ,就将 count 变量加 1。
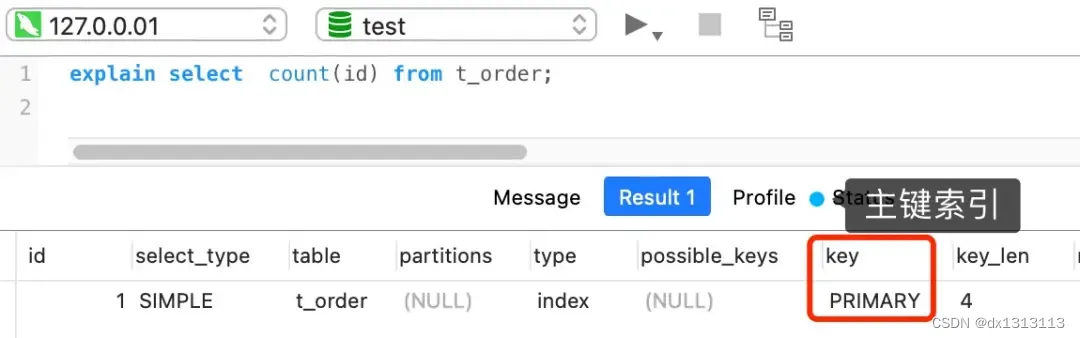
但是如果表里有二级索引时,InnoDB 循环遍历的对象就不是聚簇索引,而是二级索引。
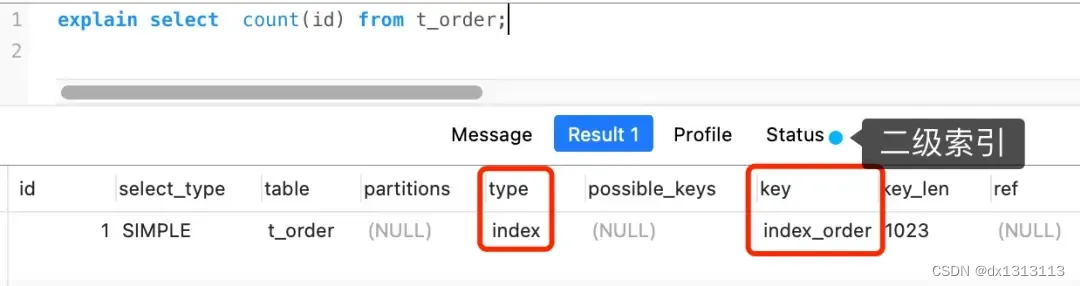
这是因为相同数量的二级索引记录可以比聚簇索引记录占用更少的存储空间,所以二级索引树比聚簇索引树小,这样遍历二级索引的I/O成本比遍历聚簇索引的I/O成本小,因此 [优化器] 优先选择的是二级索引。
count(1) 执行过程是怎样的?
select count(1) from t_order;如果表里只有主键索引,没有二级索引时。
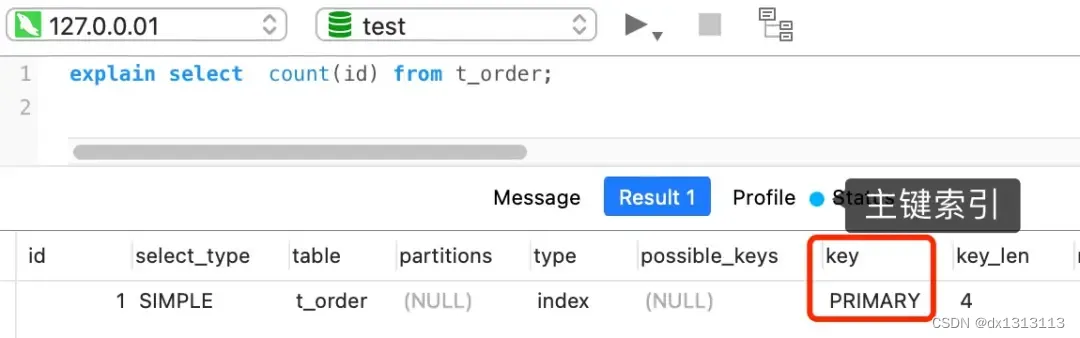
那么,InnoDB 循环遍历聚簇索引(主键索引),将读取到的记录返回给 server 层,但是不会读取记录中任何字段的值,因为 count 函数的参数是 1,不是字段,所以不需要读取记录中的字段值。参数 1 很明显并不是 NULL,因此 server 层每从 InnoDB 读取到一条数据,就将 count 变量加 1.
可以看到,count(1) 相比 count(主键字段)少了一个步骤,就是不需要读取记录中的字段值,所以通常会说 count(1)的执行效率会比 count(主键字段) 高一点。
但是,如果表里有二级索引的时候,InnoDB 循环遍历的对象就是二级索引了。
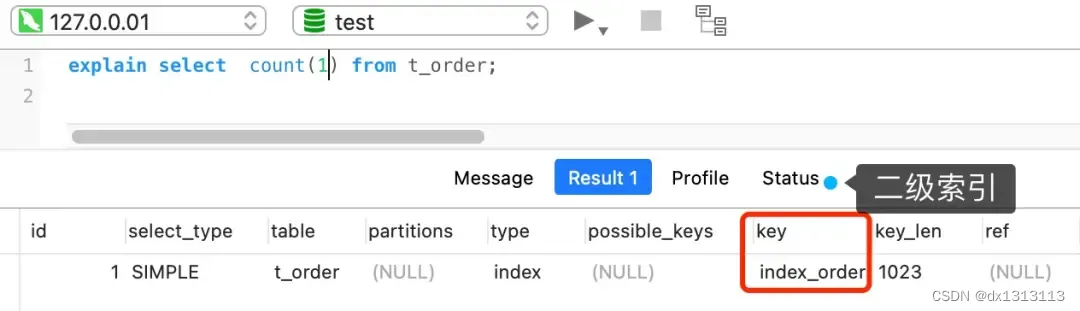
count(*) 执行过程是怎样的?
count(*) 其实等于 count(0) ,也就是说,当使用后 count(*) 时,MySQL会将 * 参数转换为 参数 0 来处理。
所以 count(*) 执行过程跟 count(1) 执行过程基本一样,性能没有什么差异。
而且 MySQL 会对 count(*) 和 count(1) 优化,如果有多个二级索引的时候,优化器会使用 key_len 最小的二级索引进行扫描。
只有当没有二级索引的时候,才会采用主键索引来进行统计。
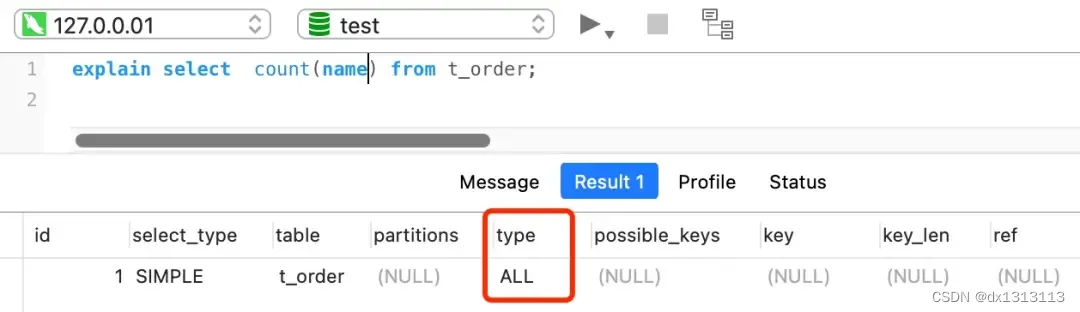
count(字段) 执行过程是怎样的?
count(字段) 的执行效率相比前面的 count(1) 、count(*)、count(主键字段)执行效率是最差的。
select count(name) from t_order对于这个查询来说,会采用全表扫描的方式来技术。,所以它的执行效率是比较差的
小结
count(1)、count(*)、count(主键字段) 在执行的时候,如果表里存在二级索引,优化器就会选择二级索引进行扫描。
所以,如果要执行 count(1)、count(*)、count(主键字段)的时候,尽量在数据表上建立二级索引,这样优化器会自动采用 key_len 最小的二级索引进行扫描,相比于主键索引效率会高一些。
再来,就是不要用count(字段) 来统计记录个数,因为它的效率是最差的,会采用全表扫描的方式来统计。如果非要统计表中该字段不为 NULL 的记录个数,建议给该字段建立一个二级索引。
为什么要通过遍历的方式来计数?
前面的案例都是基于 InnoDB 存储引擎的,但是在 MyISAM 存储引擎里,执行 count 函数的方式是不一样的,通常在没有任何查询条件下的 count(*) ,MyISAM 的查询速度要明显快与 InnoDB。
使用 MyISAM 引擎时,执行 count 函数 只需要 O(1) 复杂度,因为每张 MyISAM 的数据表都有一个 meta 信息有存储了 row_count 值,由表级锁保证一致性,所以直接读取 row_count 的值就是 count函数的执行结果。
而 InnoDB 存储引擎是支持事务的,同一个时刻的多个查询,由于多版本并发控制(MVCC)的原因,InnoDB表应该返回多少行是不确定的,所以无法像 MyISAM 一样,只维护一个 row_count 变量。
举个例子,假设表 t_order 有 100 条记录,现在有两个会话并行执行以下语句:

在会话A和会话 B 的最后一个时刻,同时查表 t_order 的记录总个数,可以发现,显示的结果不一样。所以,在使用 InnoDB 存储引擎时,就需要扫描表来统计具体的记录。
如何优化 count(*)
如果对一张大表经常用 count(*) 来做统计,其实是很不友好的。
比如下面这个案例中,t_order表有 1200+ 万条记录,同时也创建了二级索引,但是执行一次 select count(*) from t_order 要花费差不多 5 秒

优化方法:
第一种、近似值
如果你的业务对于统计个数不需要很准确,比如搜索引擎在搜索关键词的时候,给出的搜索结果条数是一个大概值。
这时,我们就可以使用 show table status 或者 explain 命令来进行表的估算
执行 explain 命令效率很高,因为它并不会真正的去查询,下图中的 rows 字段值就是 explain 命令对表 t_order 记录的估算值。

第二种、额外表保存计数值
如果想精确地获取表的记录总数,我们可以将这个计数值保存到单独的一张计数表中。
当我们在数据表中插入一条数据的同时,将计数表中的计数字段 + 1 。也就说,在新增和删除操作时,我们需要额外维护这个计数表。
相关文章:
count(*) 和 count(1) 有什么区别?哪个性能最好?
哪种 count 性能最好? count() 是什么? count() 是一个聚合函数,函数的参数不仅可以是字段名,也可以是其他任意表达式,该函数的作用是统计符合查询条件的记录中,函数指定的参数不为 NULL 的记录由多少条。…...

橡胶密封件为什么会老化?
橡胶密封件以其优良的密封性能被广泛应用于各个行业。然而,随着时间的推移,这些橡胶密封件往往会恶化和老化。在这篇文章中,我们将探讨橡胶密封件老化的原因。 1,导致橡胶密封件老化的主要因素之一是暴露在阳光和紫外线(UV)辐射下…...

Uboot中bootargs以及bootcmd设置
Uboot命令 一、Uboot基础命令 查看帮助信息: uboot#help打印环境变量: uboot#printenv其他命令: uboot#help ? - 帮助命令,等同于 help base - 打印或设置地址偏移量 bdinfo - 打印板级信息结构 boot …...

冠达管理:减肥药概念再度爆发,常山药业两连板,翰宇药业等大涨
减肥药概念12日盘中再度拉升,到发稿,常山药业“20cm”涨停,翰宇药业涨超14%,德展健康涨停,金凯生科涨近9%,争气股份、普利制药、昊帆生物涨约5%,诺泰生物、圣诺生物、华森制药等涨超4%。 常山药…...
实现在外网SSH远程访问内网树莓派的详细教程
文章目录 如何在局域网外SSH远程访问连接到家里的树莓派?如何通过 SSH 连接到树莓派步骤1. 在 Raspberry Pi 上启用 SSH步骤2. 查找树莓派的 IP 地址步骤3. SSH 到你的树莓派步骤 4. 在任何地点访问家中的树莓派4.1 安装 Cpolar4.2 cpolar进行token认证4.3 配置cpol…...

Pytorch框架详解
文章目录 引言1. 安装与配置1.1 如何安装PyTorch1.2 验证安装 2. 基础概念2.1 张量(Tensors)2.1.1 张量的基本特性2.1.2 创建张量2.1.3 张量操作 2.2 自动微分(Autograd)2.2.1 基本使用2.2.2 计算梯度2.2.3 停止追踪历史2.2.4 自定…...

2023年9月制造业NPDP产品经理国际认证报名来这错不了
产品经理国际资格认证NPDP是新产品开发方面的认证,集理论、方法与实践为一体的全方位的知识体系,为公司组织层级进行规划、决策、执行提供良好的方法体系支撑。 【认证机构】 产品开发与管理协会(PDMA)成立于1979年,是…...
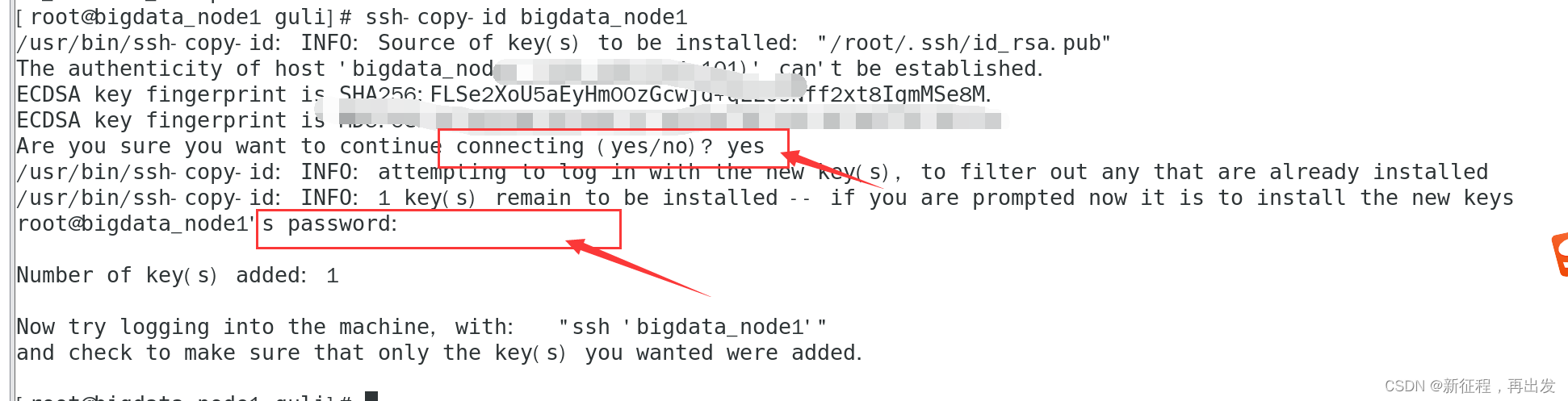
linux(centos7)配置SSH免密登录
给三台机器配置主机名映射 在Windows系统中修改hosts文件,新增以下内容; 192.168.xxx.xxx bigdata_node1 192.168.xxx.xxx bigdata_node2 192.168.xxx.xxx bigdata_node33台Linux的/etc/hosts文件中,填入如下内容。 192.168.xxx.xxx bigda…...
cf 交互题
今天cf遇到了交互题,这个交互题的算法很很很简单,但是在交互上卡了,导致交上的代码都不算罚时。(更伤心了。 所以,现在写一下交互题的做法,印象深刻嘛。 交互题,就是跟机器进行交互。你代码运…...

成都瀚网科技有限公司:抖音怎么绑定抖音小店才好?
抖音是一款非常流行的短视频应用,为用户提供了一个展示才华、分享生活的平台。在抖音上,用户可以通过绑定抖音商店来销售自己的产品或服务,从而实现商业变现。那么,抖音如何绑定抖音商店呢? 1、抖音如何绑定抖音商店&a…...

大数据组件-Flink环境搭建
🥇🥇【大数据学习记录篇】-持续更新中~🥇🥇 个人主页:beixi 本文章收录于专栏(点击传送):【大数据学习】 💓💓持续更新中,感谢各位前辈朋友们支持…...

Java——》synchronized互斥性
推荐链接: 总结——》【Java】 总结——》【Mysql】 总结——》【Redis】 总结——》【Kafka】 总结——》【Spring】 总结——》【SpringBoot】 总结——》【MyBatis、MyBatis-Plus】 总结——》【Linux】 总结——》【MongoD…...
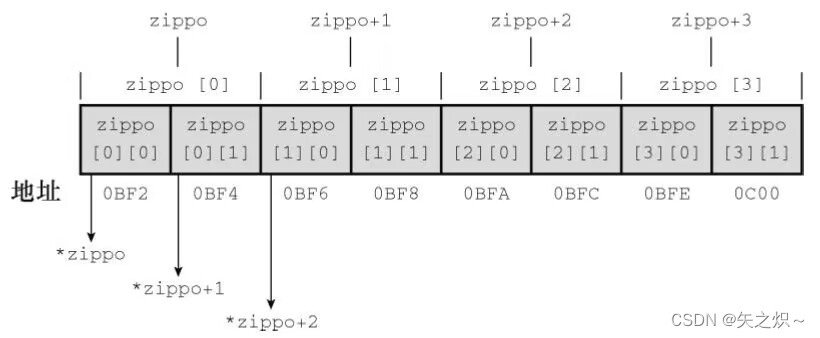
第十章 数组和指针
本章介绍以下内容: 关键字:static 运算符:&、*(一元) 如何创建并初始化数组 指针(在已学过的基础上)、指针和数组的关系 编写处理数组的函数 二维数组 人们通常借助计算机完成统计每月的支出…...
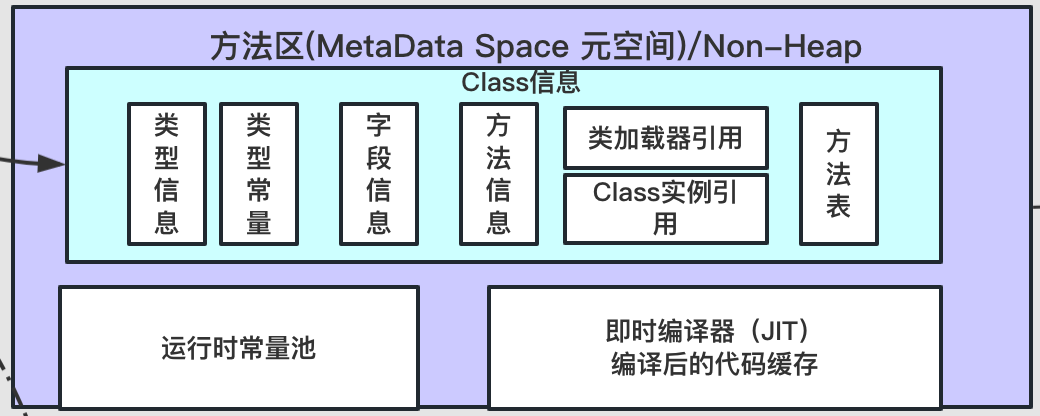
JVM系列 运行时数据区
系列文章目录 第一章 运行区实验 文章目录 系列文章目录前言一、堆(Heap)1.1、新生代/Young区1.1.1、Eden区1.1.2、Survival区 1.2、年老代(old区) 二、虚拟机栈(Stack)2.1、栈顶缓存技术2.2、溢出2.3、栈…...

软件测试/测试开发丨突破传统,革新测试:ChatGpt指引下的测试方案编写
点此获取更多相关资料 简介 测试方案是指描述需要被测产品的特性、测试的方法、测试环境的规划、测试工具的设计和选择、测试用例的设计方法、测试代码的设计方案。 我们常常需要根据产品的特性、测试策略等几个方向输出对应的测试方案。在写测试方案的过程中,常…...
JVM-垃圾回收器详解、参数配置
相关概念 并行和并发 并行(Parallel) 指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。 并发(Concurrent) 指用户线程与垃圾收集线程同时执行(但不一定是并行的,可能会交替执行…...

计算机算法分析与设计(1)---求算法时间复杂性(手写例题)
文章目录 一、主定理求解二、递归树求解三、递归树求解含O的递归方程 一、主定理求解 二、递归树求解 三、递归树求解含O的递归方程...

MyBatisPlus 分页查询
首先要定义一个配置类 MybatisConfig 放在 config 类下 他的生效是通过拦截生效的 所以是要写拦截器的 (这段拦截器的配置是固定的 CV 也可以) Configuration public class MybatisConfig{Beanpublic MybatisPlusInterceptor mybatisPlusInterceptor(){// 1.定义MybatisPlu…...

Kafka3.1部署和Topic主题数据生产与消费
文章目录 前言一、Kafka3.1X版本在Windows11主机部署二、Kafk生产Topic主题数据1.kafka生产数据2.JAVA kafka客户端消费数据 总结 前言 本章节主要讲述Kafka3.1X版本在Windows11主机下部署以及JAVA对Kafka应用: 一、Kafka3.1X版本在Windows11主机部署 1.安装JDK配…...

ICIF2023化工展首亮相,宏工科技解决方案助力制造升级
ICIF China 2023中国国际化工展览会于9月4日-6日在上海新国际博览中心举办。宏工科技携化工物料处理一站式解决方案首次亮相,同化工行业全产业链共叙物料处理自动化未来。 宏工科技是一家提供物料处理自动化设备、系统与服务的国家级高新技术企业,业务覆…...

电商客服外包怎么选|避坑指南[特殊字符]2026 商家必看
做电商绕不开客服外包,但低价陷阱、转包兼职、大促掉链、响应超时、售后甩锅真的太坑了!今天整理一套不踩雷选型攻略,全是行业干货,新手也能直接抄作业👇 🚫先避坑:这些雷区千万别碰 超低价诱惑…...

GLM-4V-9B在智能客服场景的应用:快速搭建图片问答机器人
GLM-4V-9B在智能客服场景的应用:快速搭建图片问答机器人 1. 引言:智能客服的新需求 在电商和在线服务领域,每天都有大量用户上传产品图片、截图或文档,询问相关问题。传统客服系统只能处理文字咨询,面对图片类问题往…...
Hunyuan-MT-7B企业部署案例:出海SaaS公司集成Pixel Language Portal构建内部翻译中台
Hunyuan-MT-7B企业部署案例:出海SaaS公司集成Pixel Language Portal构建内部翻译中台 1. 项目背景与挑战 随着全球化业务扩张,某出海SaaS公司面临多语言支持的核心痛点: 翻译需求激增:产品文档、用户界面、客服对话等需要支持3…...

巴旦木脱青皮的设计【solidworks三维、cad图纸、论文、答辩稿】
巴旦木脱青皮设计是农产品加工领域的关键环节,其核心作用在于通过机械结构与工艺参数的协同优化,实现青皮与果仁的高效分离,同时避免果仁损伤。该设计需综合考虑物料特性、动力传递效率及设备稳定性,通过三维建模与二维图纸的精准…...

OpenMV串口数据收发实战:如何与Arduino/STM32稳定通信并解析指令
OpenMV与微控制器串口通信实战:从基础协议到工业级稳定性优化 在智能机器人、自动化检测设备等嵌入式视觉系统中,OpenMV常作为"视觉传感器"与主控微控制器(如Arduino/STM32)协同工作。我曾参与过一个AGV小车项目&#x…...

Qwen All-in-One场景解析:如何用轻量模型赋能边缘计算应用
Qwen All-in-One场景解析:如何用轻量模型赋能边缘计算应用 1. 引言:当边缘计算遇上大模型 想象一下,在一个智能工厂的质检工位上,摄像头捕捉到产品表面的微小瑕疵。传统的做法是:将图像上传到云端服务器,…...

解锁AI编程新范式:Continue插件的颠覆性开发体验
解锁AI编程新范式:Continue插件的颠覆性开发体验 【免费下载链接】continue ⏩ Source-controlled AI checks, enforceable in CI. Powered by the open-source Continue CLI 项目地址: https://gitcode.com/GitHub_Trending/co/continue 你是否曾在深夜调试…...

C语言开发者视角:Kandinsky-5.0-I2V-Lite-5s高性能推理引擎调用
C语言开发者视角:Kandinsky-5.0-I2V-Lite-5s高性能推理引擎调用 1. 引言:当静态告警遇上动态生成 想象一下这样的场景:工业监控系统捕捉到设备异常,触发静态告警图片。传统方案中,这张图片需要人工介入分析ÿ…...

OEC-turbo变废为宝:从吃灰PCDN盒子到家庭服务器,Armbian/OpenWrt刷机实战记录
OEC-turbo硬件改造指南:从闲置PCDN设备到全能家庭服务器 手上闲置的OEC-turbo盒子除了吃灰还能做什么?这款搭载RK3568芯片的设备实际上是一块被低估的硬件宝藏。相比市面上热门的斐讯N1等矿渣设备,OEC-turbo在处理器性能、内存配置和扩展性方…...

Adobe软件非正版弹窗终极解决方案:PS/Ai/PR/AE禁用提示一键清除指南
1. Adobe弹窗问题的根源分析 最近不少朋友打开Photoshop、Illustrator这些Adobe软件时,突然跳出一个烦人的提示框:"Your non-genuine Adobe app will be disabled soon"。这个警告不仅影响使用体验,严重时还会导致软件直接罢工。作…...