一文了解kafka消息队列,实现kafka的生产者(Producer)和消费者(Consumer)的代码,消息的持久化和消息的同步发送和异步发送
文章目录
- 1. kafka的介绍
- 1.2 Kafka适合的应用场景
- 1.2 Kafka的四个核心API
- 2. 代码实现kafka的生产者和消费者
- 2.1 引入加入jar包
- 2.2 生产者代码
- 2.3 消费者代码
- 2.4 介绍kafka生产者和消费者模式
- 3. 消息持久化
- 4. 消息的同步和异步发送
- 5. 参考文档
1. kafka的介绍
最近在学习kafka相关的知识,特将学习成功记录成文章,以供大家共同学习。
Apache Kafka是 一个分布式流处理平台, 这到底意味着什么呢?
-
它可以让你发布和订阅流式的记录。这一方面与消息队列或者企业消息系统类似。
-
它可以储存流式的记录,并且有较好的容错性。
-
它可以在流式记录产生时就进行处理。
1.2 Kafka适合的应用场景
我们首先要了解kafka的一些概念:
-
Kafka作为一个集群,运行在一台或者多台服务器上. -
Kafka通过topic对存储的流数据进行分类。 -
每条记录中包含一个
key,一个value和一个timestamp(时间戳)。
它可以用于两大类别的应用:
-
构造实时流数据管道,它可以在系统或应用之间可靠地获取数据。 (相当
message queue) -
构建实时流式应用程序,对这些流数据进行转换或者影响。 (就是流处理,通过
kafka stream topic和topic之间内部进行变化)
1.2 Kafka的四个核心API
-
The Producer API允许一个应用程序发布一串流式的数据到一个或者多个Kafka topic。 -
The Consumer API允许一个应用程序订阅一个或多个topic,并且对发布给他们的流式数据进行处理。 -
The Streams API允许一个应用程序作为一个流处理器,消费一个或者多个topic产生的输入流,然后生产一个输出流到一个或多个topic中去,在输入输出流中进行有效的转换。 -
The Connector API允许构建并运行可重用的生产者或者消费者,将Kafka topics连接到已存在的应用程序或者数据系统。比如,连接到一个关系型数据库,捕捉表(table)的所有变更内容。
在Kafka中,客户端和服务器使用一个简单、高性能、支持多语言的TCP协议。此协议版本化并且向下兼容老版本, 为Kafka提供了Java客户端,也支持许多其他语言的客户端。
2. 代码实现kafka的生产者和消费者
2.1 引入加入jar包
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka_2.12</artifactId><version>1.0.0</version><scope>provided</scope>
</dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>1.0.0</version>
</dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-streams</artifactId><version>1.0.0</version>
</dependency>
2.2 生产者代码
/*** @author super先生* @date 2023/02/09 11:26*/
public class KafkaProducerDemo extends Thread {/*** 消息发送者*/private final KafkaProducer<Integer, String> producer;/*** topic*/private final String topic;public KafkaProducerDemo(String topic) {//构建相关属性//@see ProducerConfigProperties properties = new Properties();//Kafka 地址properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.220.135:9092,192.168.220.136:9092");//kafka 客户端 Demoproperties.put(ProducerConfig.CLIENT_ID_CONFIG, "KafkaProducerDemo");//The number of acknowledgments the producer requires the leader to have received before considering a request complete. This controls the durability of records that are sent./**发送端消息确认模式:* 0:消息发送给broker后,不需要确认(性能较高,但是会出现数据丢失,而且风险最大,因为当 server 宕机时,数据将会丢失)* 1:只需要获得集群中的 leader节点的确认即可返回* -1/all:需要 ISR 中的所有的 Replica进行确认(集群中的所有节点确认),最安全的,也有可能出现数据丢失(因为 ISR 可能会缩小到仅包含一个 Replica)*/properties.put(ProducerConfig.ACKS_CONFIG, "-1");/**【调优】* batch.size 参数(默认 16kb)* public static final String BATCH_SIZE_CONFIG = "batch.size";** producer对于同一个 分区 来说,会按照 batch.size 的大小进行统一收集进行批量发送,相当于消息并不会立即发送,而是会收集整理大小至 16kb.若将该值设为0,则不会进行批处理*//**【调优】* linger.ms 参数* public static final String LINGER_MS_CONFIG = "linger.ms";* 一个毫秒值。Kafka 默认会把两次请求的时间间隔之内的消息进行搜集。相当于会有一个 delay 操作。比如定义的是1000(1s),消息一秒钟发送5条,那么这 5条消息不会立马发送,而是会有一个 delay操作进行聚合,* delay以后再次批量发送到 broker。默认是 0,就是不延迟(同 TCP Nagle算法),那么 batch.size 也就不生效了*///linger.ms 参数和batch.size 参数只要满足其中一个都会发送/**【调优】* max.request.size 参数(默认是1M) 设置请求最大字节数* public static final String MAX_REQUEST_SIZE_CONFIG = "max.request.size";* 如果设置的过大,发送的性能会受到影响,同时写入接收的性能也会受到影响。*///设置 key的序列化,key 是 Integer类型,使用 IntegerSerializer//org.apache.kafka.common.serializationproperties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.IntegerSerializer");//设置 value 的序列化properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");//构建 kafka Producer,这里 key 是 Integer 类型,Value 是 String 类型producer = new KafkaProducer<Integer, String>(properties);this.topic = topic;}public static void main(String[] args) {new KafkaProducerDemo("test").start();}@Overridepublic void run() {int num = 0;while (num < 100) {String message = "message--->" + num;System.out.println("start to send message 【 " + message + " 】");producer.send(new ProducerRecord<Integer, String>(topic, message));num++;try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}}
}
2.3 消费者代码
/*** @author super先生* @date 2023/02/09 15:26*/
public class KafkaConsumerDemo extends Thread {private final KafkaConsumer<Integer, String> kafkaConsumer;public KafkaConsumerDemo(String topic) {//构建相关属性//@see ConsumerConfigProperties properties = new Properties();properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.220.135:9092,192.168.220.136:9092");//消费组/*** consumer group是kafka提供的可扩展且具有容错性的消费者机制。既然是一个组,那么组内必然可以有多个消费者或消费者实例((consumer instance),它们共享一个公共的ID,即group ID。组内的所有消费者协调在一起来消费订阅主题(subscribed topics)的所有分区(partition)。当然,每个分区只能由同一个消费组内的一个consumer来消费.后面会进一步介绍。*/properties.put(ConsumerConfig.GROUP_ID_CONFIG, "KafkaConsumerDemo");/** auto.offset.reset 参数 从什么时候开始消费* public static final String AUTO_OFFSET_RESET_CONFIG = "auto.offset.reset";** 这个参数是针对新的groupid中的消费者而言的,当有新groupid的消费者来消费指定的topic时,对于该参数的配置,会有不同的语义* auto.offset.reset=latest情况下,新的消费者将会从其他消费者最后消费的offset处开始消费topic下的消息* auto.offset.reset= earliest情况下,新的消费者会从该topic最早的消息开始消费auto.offset.reset=none情况下,新的消费组加入以后,由于之前不存在 offset,则会直接抛出异常。说白了,新的消费组不要设置这个值*///enable.auto.commit//消费者消费消息以后自动提交,只有当消息提交以后,该消息才不会被再次接收到(如果没有 commit,消息可以重复消费,也没有 offset),还可以配合auto.commit.interval.ms控制自动提交的频率。//当然,我们也可以通过consumer.commitSync()的方式实现手动提交properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");/**max.poll.records*此参数设置限制每次调用poll返回的消息数,这样可以更容易的预测每次poll间隔要处理的最大值。通过调整此值,可以减少poll间隔*///间隔时间properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");//反序列化 keyproperties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.IntegerDeserializer");//反序列化 valueproperties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");//构建 KafkaConsumerkafkaConsumer = new KafkaConsumer<>(properties);//设置 topickafkaConsumer.subscribe(Collections.singletonList(topic));}/*** 接收消息*/@Overridepublic void run() {while (true) {//拉取消息ConsumerRecords<Integer, String> consumerRecord = kafkaConsumer.poll(100000000);for (ConsumerRecord<Integer, String> record : consumerRecord) {System.out.println("message receive 【" + record.value() + "】");}}}public static void main(String[] args) {new KafkaConsumerDemo("test").start();}
}
2.4 介绍kafka生产者和消费者模式
如下图所示,分别有三个消费者,属于两个不同的group,那么对于firstTopic这个topic 来说,这两个组的消费者都能同时消费这个topic中的消息,对于此事的架构来说,这个firstTopic就类似于 ActiveMQ中的topic概念。
(组内是竞争的,不同组之间是不竞争的)
Producer产生一个hello消息,group=1 和 group=2都能消费,但是每个组里面只有一个Consumer可以消费。
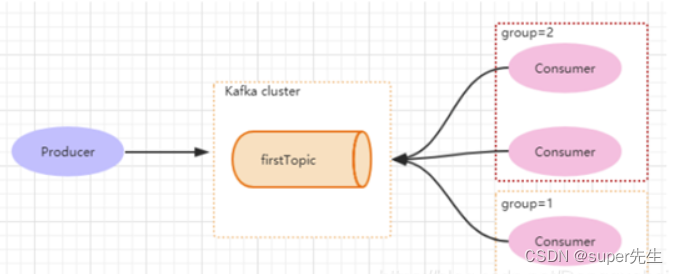
但如果3个消费者都属于同一个group,那么此时firstTopic就是一个Queue的概念。Producer产生一个hello消息,group=1组里面只有一个Consumer可以消费,如下图所示:
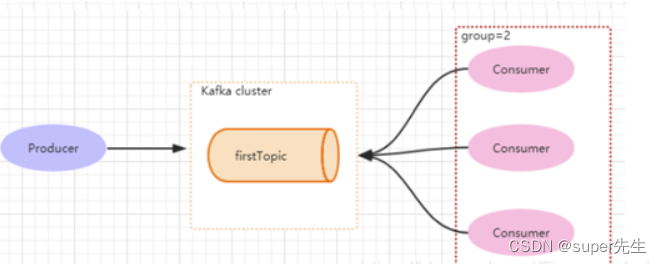
Kafka通过Group就能够实现p2p和发布订阅。一个Group只能消费一次消息。
3. 消息持久化
Kafka的消息都会持久化到磁盘上。
一个Group只能消费一次消息。然后再换一个GroupId,消费者又能够再次消费消息 (只要消息在磁盘上,Kafka默认保存2天)。
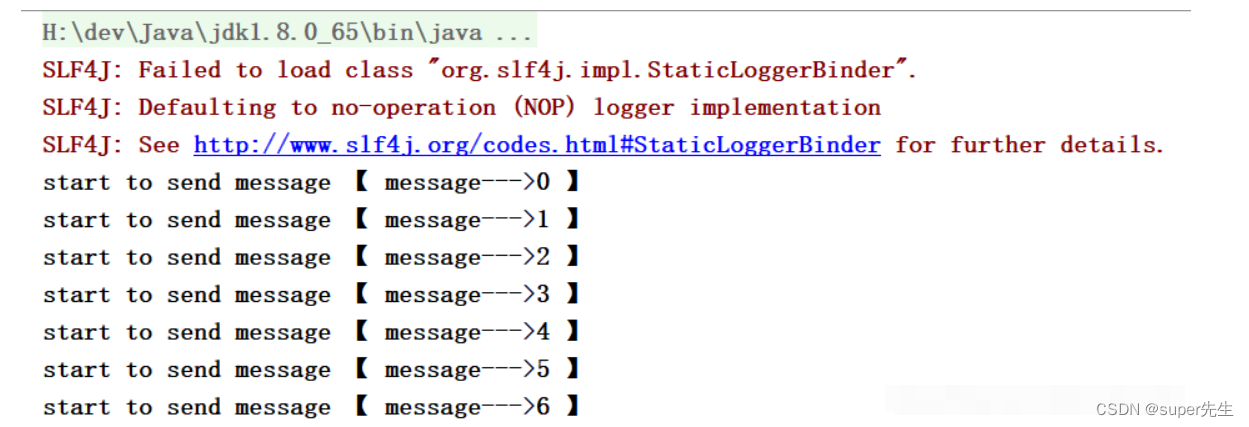
- 启动
Producer:
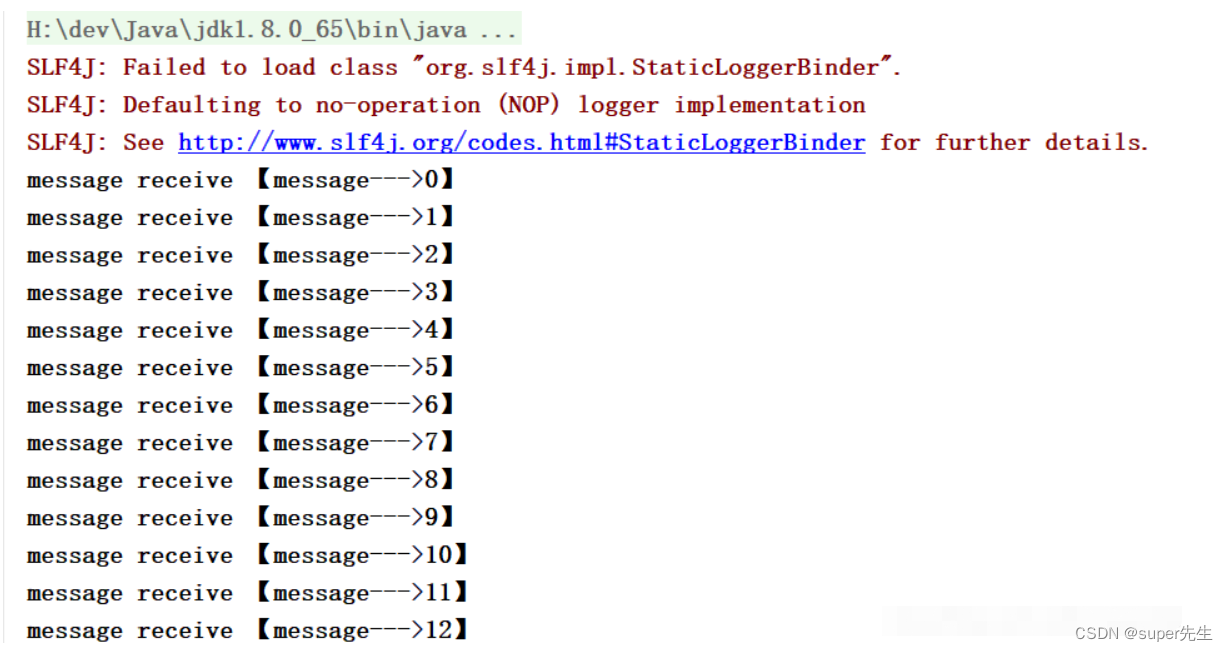
- 启动
Consumer:
4. 消息的同步和异步发送
修改Producer增加异步发送参数,如下代码所示:
/*** @author super先生* @date 2023/02/09 15:00*/
public class KafkaProducerDemo extends Thread {/*** 消息发送者*/private final KafkaProducer<Integer, String> producer;/*** topic*/private final String topic;private final Boolean isAsync;public KafkaProducerDemo(String topic, Boolean isAsync) {this.isAsync = isAsync;//构建相关属性//@see ProducerConfigProperties properties = new Properties();//Kafka 地址properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.220.135:9092,192.168.220.136:9092");//kafka 客户端 Demoproperties.put(ProducerConfig.CLIENT_ID_CONFIG, "KafkaProducerDemo");//The number of acknowledgments the producer requires the leader to have received before considering a request complete. This controls the durability of records that are sent./**发送端消息确认模式:* 0:消息发送给broker后,不需要确认(性能较高,但是会出现数据丢失,而且风险最大,因为当 server 宕机时,数据将会丢失)* 1:只需要获得集群中的 leader节点的确认即可返回* -1/all:需要 ISR 中的所有的 Replica进行确认(集群中的所有节点确认),最安全的,也有可能出现数据丢失(因为 ISR 可能会缩小到仅包含一个 Replica)*/properties.put(ProducerConfig.ACKS_CONFIG, "-1");/**【调优】* batch.size 参数(默认 16kb)* public static final String BATCH_SIZE_CONFIG = "batch.size";** producer对于同一个 分区 来说,会按照 batch.size 的大小进行统一收集进行批量发送,相当于消息并不会立即发送,而是会收集整理大小至 16kb.若将该值设为0,则不会进行批处理*//**【调优】* linger.ms 参数* public static final String LINGER_MS_CONFIG = "linger.ms";* 一个毫秒值。Kafka 默认会把两次请求的时间间隔之内的消息进行搜集。相当于会有一个 delay 操作。比如定义的是1000(1s),消息一秒钟发送5条,那么这 5条消息不会立马发送,而是会有一个 delay操作进行聚合,* delay以后再次批量发送到 broker。默认是 0,就是不延迟(同 TCP Nagle算法),那么 batch.size 也就不生效了*///linger.ms 参数和batch.size 参数只要满足其中一个都会发送/**【调优】* max.request.size 参数(默认是1M) 设置请求最大字节数* public static final String MAX_REQUEST_SIZE_CONFIG = "max.request.size";* 如果设置的过大,发送的性能会受到影响,同时写入接收的性能也会受到影响。*///设置 key的序列化,key 是 Integer类型,使用 IntegerSerializer//org.apache.kafka.common.serializationproperties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.IntegerSerializer");//设置 value 的序列化properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");//构建 kafka Producer,这里 key 是 Integer 类型,Value 是 String 类型producer = new KafkaProducer<Integer, String>(properties);this.topic = topic;}public static void main(String[] args) {new KafkaProducerDemo("test",true).start();}@Overridepublic void run() {int num = 0;while (num < 100) {String message = "message--->" + num;System.out.println("start to send message 【 " + message + " 】");if (isAsync) { //如果是异步发送producer.send(new ProducerRecord<Integer, String>(topic, message), new Callback() {@Overridepublic void onCompletion(RecordMetadata metadata, Exception exception) {if (metadata!=null){System.out.println("async-offset:"+metadata.offset()+"-> partition"+metadata.partition());}}});} else { //同步发送try {RecordMetadata metadata = producer.send(new ProducerRecord<Integer, String>(topic, message)).get();System.out.println("sync-offset:"+metadata.offset()+"-> partition"+metadata.partition());} catch (InterruptedException | ExecutionException e) {e.printStackTrace();}}num++;try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}}
}
在Kafka 1.0 以后,客户端默认发送都是异步发送,简单说就是都是会发到一个队列中,然后在一个线程中不断的从队列中发送数据。
异步发送发送成功后会有一个回调,执行相应的操作。
同步发送也只是基于Future#get而已,相当于是同步获取结果,这个就很好理解了。
5. 参考文档
- https://blog.csdn.net/Dongguabai/article/details/86520617
相关文章:
一文了解kafka消息队列,实现kafka的生产者(Producer)和消费者(Consumer)的代码,消息的持久化和消息的同步发送和异步发送
文章目录1. kafka的介绍1.2 Kafka适合的应用场景1.2 Kafka的四个核心API2. 代码实现kafka的生产者和消费者2.1 引入加入jar包2.2 生产者代码2.3 消费者代码2.4 介绍kafka生产者和消费者模式3. 消息持久化4. 消息的同步和异步发送5. 参考文档1. kafka的介绍 最近在学习kafka相关…...
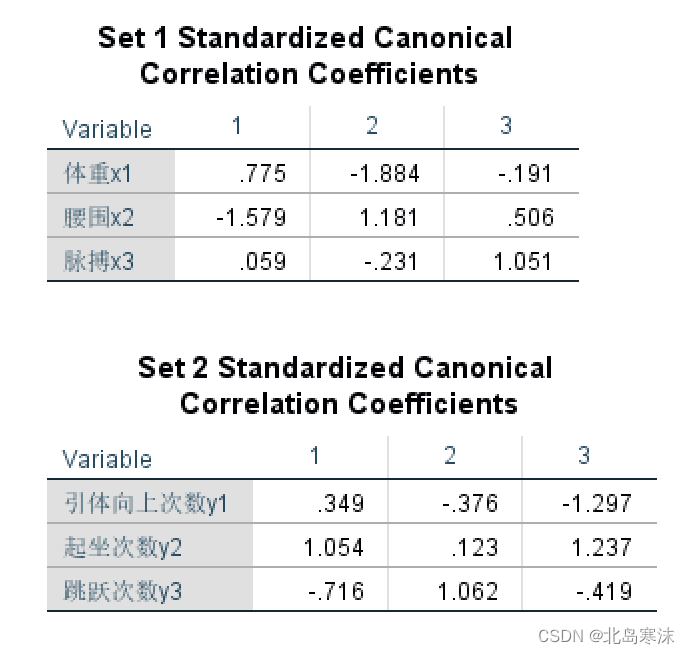
数学建模学习笔记(20)典型相关分析
典型相关分析概述:研究两组变量(每组变量都可能有多个指标)之间的相关关系的一种多元统计方法,能够揭示两组变量之间的内在联系。 典型相关分析的思想:把多个变量和多个变量之间的相关化为两个具有代表性的变量之间的…...
EL表达式
EL的概念JSP表达式语言(EL)使得访问存储在JavaBean中的数据变得非常简单。EL的作用用于替换作用域对象.getAttribute("name");3. EL的应用(获取基本类型、字符串)既可以用来创建算术表达式也可以用来创建逻辑表达式。在…...
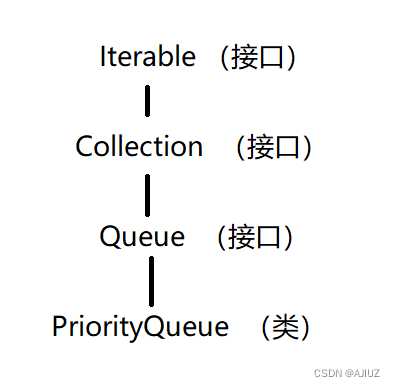
优先级队列(PriorityQueue 和 Top-K问题)
一、PriorityQueue java中提供了两种优先级队列:PriorityQueue 和 PriorityBlockingQueue。其中 PriorityQueue 是线程不安全的,PriorityBolckingQueue 是线程安全的。 PriorityQueue 使用的是堆,且默认情况下是小堆——每次获取到的元素都是…...

计算机组成与设计04——处理器
系列文章目录 本系列博客重点在深圳大学计算机系统(3)课程的核心内容梳理,参考书目《计算机组成与设计》(有问题欢迎在评论区讨论指出,或直接私信联系我)。 第一章 计算机组成与设计01——计算机概要与技…...

IT行业那么辛苦,我们为什么还要选择它?
疫情三年,我们学会了什么?工作诚可贵,技能价更高。 搞IT辛苦?有啥辛苦的?说什么辛苦?能有工作,工资又高,还要什么自行车,有啥搞啥吧!每次看到网络上有人问有…...

PyTorch学习笔记:nn.CrossEntropyLoss——交叉熵损失
PyTorch学习笔记:nn.CrossEntropyLoss——交叉熵损失 torch.nn.CrossEntropyLoss(weightNone, size_averageNone, ignore_index-100, reduceNone, reductionmean, label_smoothing0.0)功能:创建一个交叉熵损失函数: l(x,y)L{l1,…,lN}T&…...

【VictoriaMetrics】什么是VictoriaMetrics
VictoriaMetrics是一个快速、经济、可扩展的监控解决方案和时间序列数据库,有单机版和集群版本,基础功能及集群版本基本功能不收费,VictoriaMetrics有二进制安装版本、Docker安装版本等多种安装方式,其源码及部署包更新迭代很快,VictoriaMetrics具有以下突出特点: 它可以作…...

(第五章)OpenGL超级宝典学习:统一变量(uniform variable)
统一变量 前言 本篇在讲什么 本篇记录对glsl中的变量uniform的认知和学习 本篇适合什么 适合初学Open的小白 适合想要学习OpenGL中uniform的人 本篇需要什么 对C语法有简单认知 对OpenGL有简单认知 最好是有OpenGL超级宝典蓝宝书 依赖Visual Studio编辑器 本篇的特色 …...
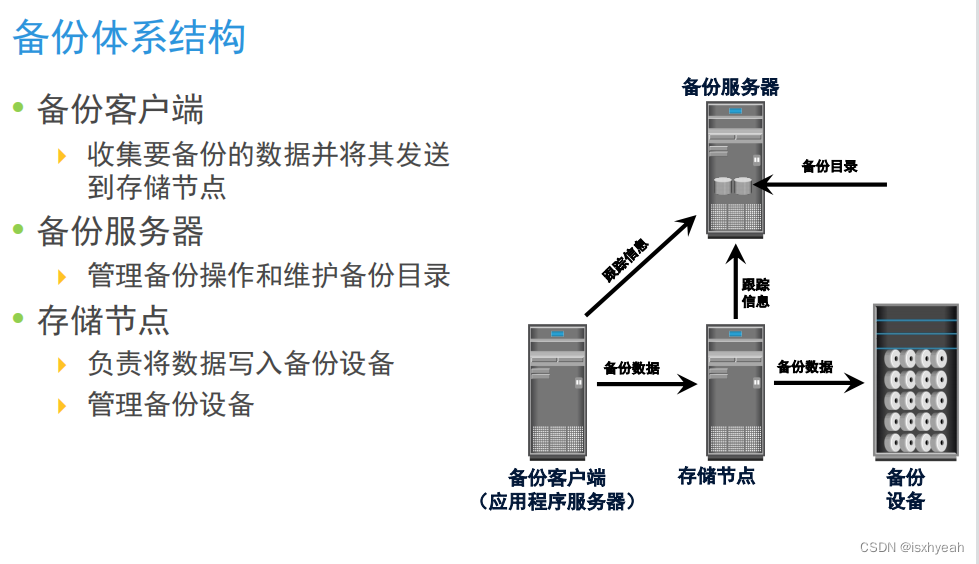
数据存储技术复习(四)未完
1.什么是NAS。一般用途服务器与NAS设备之间有何不同。NAS是一个基于IP的专用高性能文件共享和存储设备。—般用途服务器可用于托管任何应用程序,因为它运行的是一般用途操作系统NAS设备专用于文件服务。它具有专门的操作系统,专用于通过使用行业标准协议…...

Rust编码的信息窃取恶意软件源代码公布,专家警告已被利用
黑客论坛上发布了一个 用Rust编码的信息窃取恶意软件源代码 ,安全分析师警告,该恶意软件已被积极用于攻击。 该恶意软件的开发者称,仅用6个小时就开发完成,相当隐蔽, VirusTotal的检测率约为22% 。 恶意软件开发者在…...

diffusers编写自己的推理管道
英文文献:Stable Diffusion with 🧨 Diffusers 编写自己的推理管道 最后,我们展示了如何使用diffusers. 编写自定义推理管道是对diffusers库的高级使用,可用于切换某些组件,例如上面解释的 VAE 或调度程序。 例如&a…...
计算机操作系统 左万利 第二章课后习题答案
计算机操作系统 左万利 第二章课后习题答案 1、为何引进多道程序设计,在多道程序设计中,内存中作业的道数是否越多越好?说明原因。 引入多道程序设计技术是为了提高计算机系统资源的利用率。在多道程序系统中,内存中作业的道数并…...
CODESYS开发教程10-文件读写(SysFile库)
今天继续我们的小白教程,老鸟就不要在这浪费时间了😊。 前面一期我们介绍了CODESYS的文件操作库CAA File。这一期主要介绍CODESYS的SysFile库所包含的文件读写功能块,主要包括文件路径、名称、大小的获取以及文件的创建、打开、读、写、拷贝…...
Linux安装redis
Linux安装redis一.下载二.解压配置1.创建文件夹2.上传文件3.解压4.编译配置三.启动测试1.启动2.防火墙配置3.测试四.设置开机自启1.配置脚本2.添加服务3.测试一.下载 redis官网:https://redis.io/ redis官方下载地址:http://download.redis.io/releases…...
计算机组成与体系结构 性能设计 William Stallings 第2章 性能问题
2.1 优化性能设计例如,当前需要微处理器强大功能的桌面应用程序包括:图像处理、三维渲染、语音识别、视频会议、多媒体创作、文件的声音和视频注释、仿真建模从计算机组成与体系结构的角度来看,一方面,现代计算机的基本组成与50多…...
anaconda详细介绍、安装及使用(python)
anaconda详细介绍、安装及使用1 介绍1.1 简介1.2 特点1.3 版本下载2 Anaconda管理Python包命令3 安装3.1 windows安装4 操作4.1 Conda 操作4.2 Anaconda Navigator 操作4.3 Spyder 操作4.4 Jupyter Notebook 操作5 示例参考1 介绍 1.1 简介 Anaconda是用于科学计算(…...

雅思经验(6)
反正我是希望遇到的雅思听力section 4.里面填空的地方多一些,之后单选的部分少一些。练了一下剑9 test3 的section 4,感觉还是不难的,都是在复现,而且绕的弯子也不是很多。本次考试的目标就是先弄一个六分,也就是说&am…...

CentOS9源码编译libvirtd工具
卸载原有版本libvirt [rootcentos9 ~]# yum remove libvirt Centos9配置网络源 [rootcentos9 ~]# dnf config-manager --set-enabled crb [rootcentos9 ~]# dnf install epel-release epel-next-release 安装依赖包 [rootcentos9 ~]# yum install -y libtirpc-devel libxml2-de…...

搭建内网穿透
文章目录摘要npsfrp服务提供商摘要 内网穿透是一种方便的技术,可以让用户随时随地访问内网设备。有两种方式可以使用内网穿透:自己搭建,使用nps/frps软件;购买服务,快速享受内网穿透带来的便利。 nps 内网穿透。参考…...

百度网盘Mac版加速插件:突破下载限制的实用方案
百度网盘Mac版加速插件:突破下载限制的实用方案 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 对于经常使用百度网盘的Mac用户来说&#x…...

Vim多光标编辑插件vim-visual-multi:提升批量文本处理效率
1. 项目概述:一个能改变你Vim多光标编辑体验的插件 如果你是一个Vim或Neovim的深度用户,并且对现代编辑器(比如VSCode、Sublime Text)里那种流畅的多光标编辑功能念念不忘,那么你肯定不止一次地搜索过“Vim multiple c…...

构建自动化编译系统:Makefile递归遍历与智能目录生成实践
1. 为什么需要自动化编译系统 如果你曾经维护过一个包含几十个源文件的中大型C/C项目,肯定经历过这样的痛苦:每次新增一个源文件,都要手动修改Makefile;项目结构调整时,编译规则需要全部重写;不同模块之间的…...

终极音乐解锁指南:让加密音频在浏览器中重获自由
终极音乐解锁指南:让加密音频在浏览器中重获自由 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https://gi…...

Arccos Golf数据获取与Python分析实战:开源工具包逆向工程API
1. 项目概述:一个高尔夫数据爱好者的开源工具箱 如果你和我一样,既是个高尔夫爱好者,又对数据分析和自动化工具着迷,那么你很可能听说过Arccos Golf这个平台。它是一个通过传感器和手机应用来追踪每一次击球、分析球场表现的系统。…...

深度解析RSA加密机制:3种Beyond Compare 5授权验证方案实战指南
深度解析RSA加密机制:3种Beyond Compare 5授权验证方案实战指南 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen Beyond Compare 5作为专业文件对比工具的佼佼者,其授权验…...

低价轻小件承压明显之后跨境卖家如何重设利润安全线
薄利之困:跨境卖家如何重塑利润防线当全球电商平台的促销战鼓擂响,价格一降再降,那些曾经依赖“低价轻小件”策略的跨境卖家们,正感受到前所未有的压力。物流成本波动、平台佣金上涨、同质化竞争加剧……多重因素交织下࿰…...

Zotero Duplicates Merger终极指南:3步告别文献重复困扰
Zotero Duplicates Merger终极指南:3步告别文献重复困扰 【免费下载链接】ZoteroDuplicatesMerger A zotero plugin to automatically merge duplicate items 项目地址: https://gitcode.com/gh_mirrors/zo/ZoteroDuplicatesMerger 还在为Zotero文献库中堆积…...
)
从IMU到GPS:手把手教你用ESKF实现机器人定位(附代码避坑指南)
从IMU到GPS:手把手教你用ESKF实现机器人定位(附代码避坑指南) 在机器人定位领域,误差状态卡尔曼滤波(Error-State Kalman Filter, ESKF)正逐渐成为处理IMU和GPS数据融合的主流方法。本文将带您深入理解ESK…...

管道工程必看避坑指南粮油储罐通气帽选型要点
在粮油仓储的体系当中,通气帽看起来是一个不显得很起眼的小零件,却常常在关键的时候出现变化。我们看到很多项目,前期设计的时候非常华丽色彩很鲜艳,到后期运行的时候经常出现故障,去探究原因,原来是通气帽…...