PyTorch学习笔记:nn.CrossEntropyLoss——交叉熵损失
PyTorch学习笔记:nn.CrossEntropyLoss——交叉熵损失
torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean', label_smoothing=0.0)
功能:创建一个交叉熵损失函数:
l(x,y)=L={l1,…,lN}T,ln=−∑c=1Cwclogexn,c∑i=1Cexn,i⋅yn,cl(x,y)=L=\{l_1,\dots,l_N\}^T,l_n=-\sum^C_{c=1}w_c\log\frac{e^{x_{n,c}}}{\sum^C_{i=1}e^{x_{n,i}}}· y_{n,c} l(x,y)=L={l1,…,lN}T,ln=−c=1∑Cwclog∑i=1Cexn,iexn,c⋅yn,c
其中xxx是输入,yn,cy_{n,c}yn,c是标签向量元素(来自经过独热编码后的标签向量),www是类别权重,CCC是类别总数,NNN表示batch size。
输入:
-
size_average与reduce已被弃用,具体功能由参数reduction代替 -
weight:赋予每个类的权重,指定的权重必须是一维并且长度为CCC的数组,数据类型必须为tensor格式 -
ignore_index:指定一个被忽略,并且不影响网络参数更新的目标类别,数据类型必须是整数,即只能指定一个类别 -
reduction:指定损失输出的形式,有三种选择:none|mean|sum。none:损失不做任何处理,直接输出一个数组;mean:将得到的损失求平均值再输出,会输出一个数;sum:将得到的损失求和再输出,会输出一个数注意:如果指定了ignore_index,则首先将ignore_index代表的类别损失删去,在剩下的损失数据里求均值,因此ignore_index所代表的的类别完全不会影响网络参数的更新
-
label_smoothing:指定计算损失时的平滑量,其中0.0表示不平滑,关于平滑量可参考论文《Rethinking the Inception Architecture for Computer Vision》
注意:
- 输入应该包含原始、未经过标准化的预测值,
CrossEntropyLoss函数已经内置softmax处理 - 对于输入张量xxx,尺寸必须为(minibatch,C)(minibatch,C)(minibatch,C)或者(minibatch,C,d1,…,dK)(minibatch,C,d_1,\dots,d_K)(minibatch,C,d1,…,dK),后者对于计算高维输入时很有用,如计算二维图像中每个像素点的交叉熵损失,注意:K≥1K≥1K≥1
- 输入的张量yyy,尺寸必须为(minibatch)(minibatch)(minibatch)或者(minibatch,d1,…,dK)(minibatch,d_1,\dots,d_K)(minibatch,d1,…,dK),与xxx的尺寸相对应,后者也是用于高维数据的计算
- 注意xxx的第二维度尺寸与类别数量一一对应,并且yyy只需要输入物体类别序号即可,无需输入独热编码(该函数会自动对yyy做独热编码),yyy里面数据的大小不能超过xxx第二维度尺寸的大小减一(减一是因为标签yyy是从000开始计算)
代码案例
一般用法
import torch.nn as nn
import torchx = torch.randn((2, 8))
# 在0-7范围内,随机生成两个数,当做标签
y = torch.randint(0, 8, [2])
ce = nn.CrossEntropyLoss()
out = ce(x, y)
print(x)
print(y)
print(out)
输出
# x
tensor([[ 1.3712, 0.4903, -1.3202, 0.1297, -1.6004, -0.1809, -2.8812, -0.3088],[ 0.5855, -0.4926, 0.7647, -0.1717, -1.0418, -0.0381, -0.1307, -0.6390]])
# y
tensor([5, 0])
# 得到的交叉熵损失,默认返回损失的平均值
tensor(1.9324)
参数weight的用法
import torch.nn as nn
import torchx = torch.randn((2, 2))
y = torch.tensor([0, 1])
# 不添加weight
ce = nn.CrossEntropyLoss(reduction='none')
# 添加weight
ce_w = nn.CrossEntropyLoss(weight=torch.tensor([0.5, 1.5]), reduction='none')
out = ce(x, y)
out_w = ce_w(x, y)
print(x)
print(y)
print(out)
print(out_w)
输出
# x
tensor([[-1.1011, 0.6231],[ 0.2384, -0.3223]])
# y
tensor([0, 1])
# 不添加weight时的损失输出
tensor([1.8883, 1.0123])
# weight定义为[0.5, 1.5]时的损失
# 第一个数据(batch中第一个元素)由于标签为0
# 因此对应的损失乘以weight中第一个权重
# 第二个数据类似
tensor([0.9441, 1.5184])
参数ignore_index的用法
import torch.nn as nn
import torchx = torch.randn((2, 2))
y = torch.tensor([0, 1])
# 不添加ignore_index
ce = nn.CrossEntropyLoss(reduction='none')
# 添加ignore_index
ce_i = nn.CrossEntropyLoss(ignore_index = 0, reduction='none')
out = ce(x, y)
out_i = ce_i(x, y)
print(x)
print(y)
print(out)
print(out_i)
输出
# x
tensor([[-0.9390, -0.6169],[-0.7700, 0.3602]])
# y
tensor([0, 1])
# 不添加ignore_index时的损失输出
tensor([0.8671, 0.2799])
# ignore_index设置为0,表示忽略类别序号为0的损失
# 这里第一个数据标签设置为0,因此第一个损失清零
tensor([0.0000, 0.2799])
输入高维数据时
这里以对二维的预测图做损失为例
import torch.nn as nn
import torch
# 这里表示随机生成batch为1,图片尺寸为3*3
# 并且每个点有两个类别的预测图
x = torch.randn((1, 2, 3, 3))
# 这里表示预测图x对应的标签y
# 预测图x每个位置都会对应一个标签值
# x删去第二维度后的尺寸,就是标签y的尺寸
y = torch.randint(0, 2, [1, 3, 3])
ce = nn.CrossEntropyLoss(reduction='none')
out = ce(x, y)
print(x)
print(y)
print(out)
输出
# 输入的高维数据x
tensor([[[[ 0.8859, -2.0889, -0.6026],[-1.6448, 0.7807, 0.9609],[-0.0646, 0.2204, -0.7471]],[[ 0.7075, -0.7013, -0.9280],[-0.6913, 2.1507, -0.0758],[ 0.2139, 0.8387, 0.3743]]]])
# 对应的标签,预测图x长宽为多少,标签y的长宽就为多少
tensor([[[0, 0, 1],[0, 0, 0],[1, 0, 1]]])
# 输出的损失
# 函数会为预测图x上每个位置都生成一个损失,这里一共生成3*3个损失(对应长乘宽)
tensor([[[0.6079, 1.6105, 0.8690],[1.2794, 1.5964, 0.3035],[0.5635, 1.0493, 0.2820]]])
官方文档
nn.CrossEntropyLoss:https://pytorch.org/docs/stable/generated/torch.nn.CrossEntropyLoss.html#torch.nn.CrossEntropyLoss
初步完稿于:2022年1月29日
相关文章:

PyTorch学习笔记:nn.CrossEntropyLoss——交叉熵损失
PyTorch学习笔记:nn.CrossEntropyLoss——交叉熵损失 torch.nn.CrossEntropyLoss(weightNone, size_averageNone, ignore_index-100, reduceNone, reductionmean, label_smoothing0.0)功能:创建一个交叉熵损失函数: l(x,y)L{l1,…,lN}T&…...

【VictoriaMetrics】什么是VictoriaMetrics
VictoriaMetrics是一个快速、经济、可扩展的监控解决方案和时间序列数据库,有单机版和集群版本,基础功能及集群版本基本功能不收费,VictoriaMetrics有二进制安装版本、Docker安装版本等多种安装方式,其源码及部署包更新迭代很快,VictoriaMetrics具有以下突出特点: 它可以作…...

(第五章)OpenGL超级宝典学习:统一变量(uniform variable)
统一变量 前言 本篇在讲什么 本篇记录对glsl中的变量uniform的认知和学习 本篇适合什么 适合初学Open的小白 适合想要学习OpenGL中uniform的人 本篇需要什么 对C语法有简单认知 对OpenGL有简单认知 最好是有OpenGL超级宝典蓝宝书 依赖Visual Studio编辑器 本篇的特色 …...
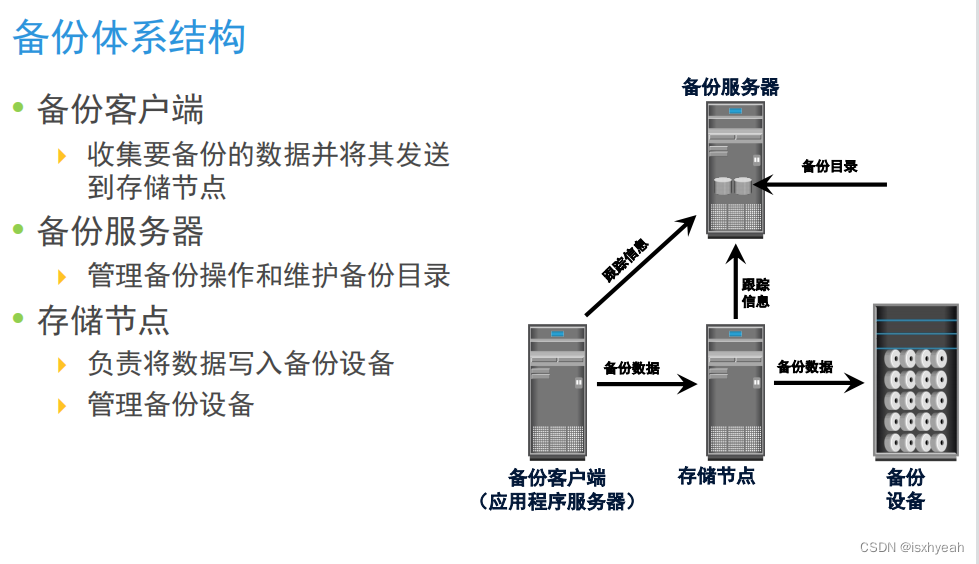
数据存储技术复习(四)未完
1.什么是NAS。一般用途服务器与NAS设备之间有何不同。NAS是一个基于IP的专用高性能文件共享和存储设备。—般用途服务器可用于托管任何应用程序,因为它运行的是一般用途操作系统NAS设备专用于文件服务。它具有专门的操作系统,专用于通过使用行业标准协议…...

Rust编码的信息窃取恶意软件源代码公布,专家警告已被利用
黑客论坛上发布了一个 用Rust编码的信息窃取恶意软件源代码 ,安全分析师警告,该恶意软件已被积极用于攻击。 该恶意软件的开发者称,仅用6个小时就开发完成,相当隐蔽, VirusTotal的检测率约为22% 。 恶意软件开发者在…...

diffusers编写自己的推理管道
英文文献:Stable Diffusion with 🧨 Diffusers 编写自己的推理管道 最后,我们展示了如何使用diffusers. 编写自定义推理管道是对diffusers库的高级使用,可用于切换某些组件,例如上面解释的 VAE 或调度程序。 例如&a…...
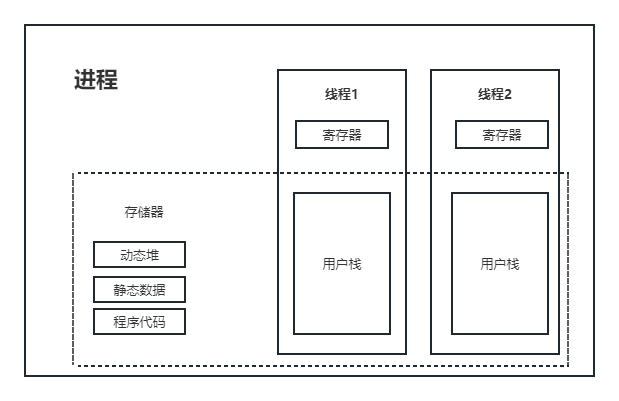
计算机操作系统 左万利 第二章课后习题答案
计算机操作系统 左万利 第二章课后习题答案 1、为何引进多道程序设计,在多道程序设计中,内存中作业的道数是否越多越好?说明原因。 引入多道程序设计技术是为了提高计算机系统资源的利用率。在多道程序系统中,内存中作业的道数并…...
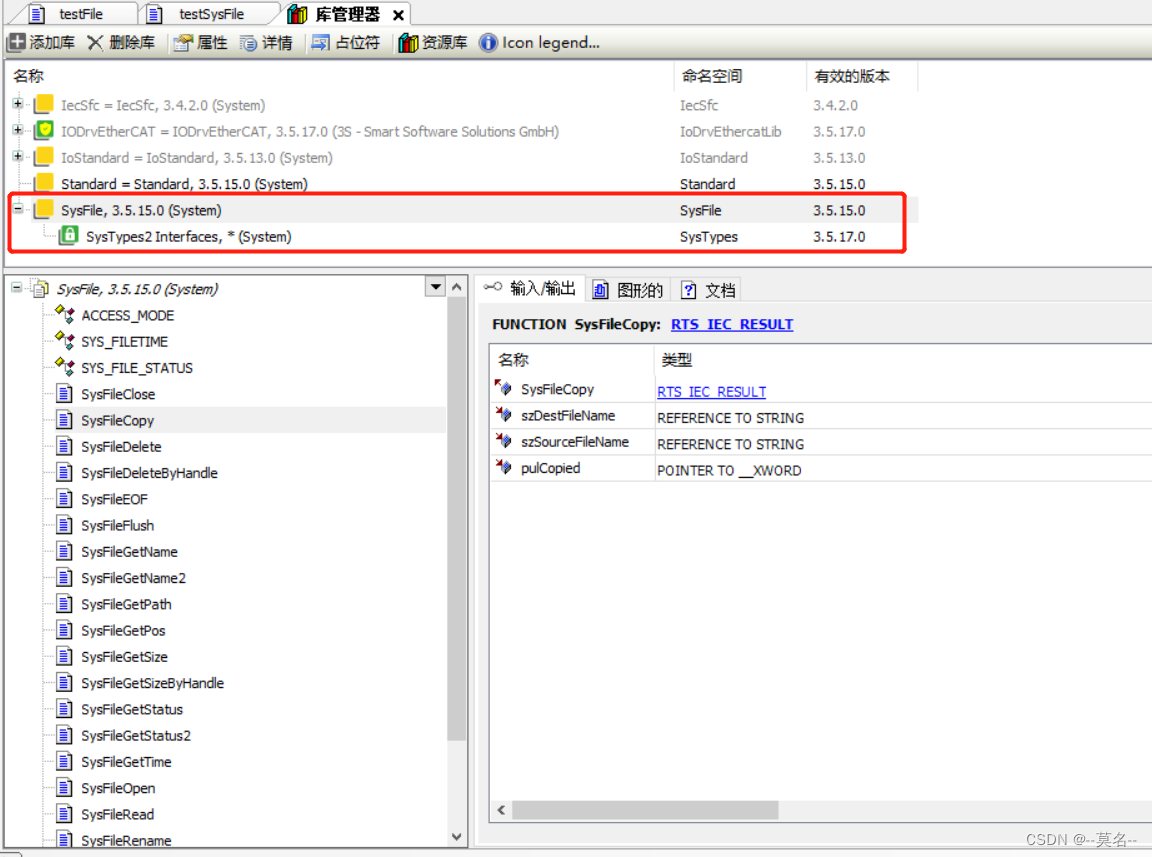
CODESYS开发教程10-文件读写(SysFile库)
今天继续我们的小白教程,老鸟就不要在这浪费时间了😊。 前面一期我们介绍了CODESYS的文件操作库CAA File。这一期主要介绍CODESYS的SysFile库所包含的文件读写功能块,主要包括文件路径、名称、大小的获取以及文件的创建、打开、读、写、拷贝…...
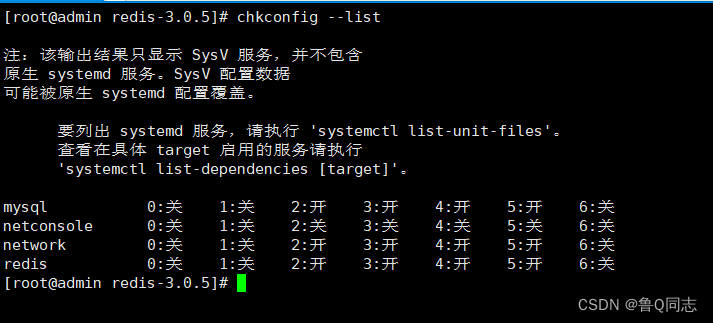
Linux安装redis
Linux安装redis一.下载二.解压配置1.创建文件夹2.上传文件3.解压4.编译配置三.启动测试1.启动2.防火墙配置3.测试四.设置开机自启1.配置脚本2.添加服务3.测试一.下载 redis官网:https://redis.io/ redis官方下载地址:http://download.redis.io/releases…...
计算机组成与体系结构 性能设计 William Stallings 第2章 性能问题
2.1 优化性能设计例如,当前需要微处理器强大功能的桌面应用程序包括:图像处理、三维渲染、语音识别、视频会议、多媒体创作、文件的声音和视频注释、仿真建模从计算机组成与体系结构的角度来看,一方面,现代计算机的基本组成与50多…...
anaconda详细介绍、安装及使用(python)
anaconda详细介绍、安装及使用1 介绍1.1 简介1.2 特点1.3 版本下载2 Anaconda管理Python包命令3 安装3.1 windows安装4 操作4.1 Conda 操作4.2 Anaconda Navigator 操作4.3 Spyder 操作4.4 Jupyter Notebook 操作5 示例参考1 介绍 1.1 简介 Anaconda是用于科学计算(…...

雅思经验(6)
反正我是希望遇到的雅思听力section 4.里面填空的地方多一些,之后单选的部分少一些。练了一下剑9 test3 的section 4,感觉还是不难的,都是在复现,而且绕的弯子也不是很多。本次考试的目标就是先弄一个六分,也就是说&am…...

CentOS9源码编译libvirtd工具
卸载原有版本libvirt [rootcentos9 ~]# yum remove libvirt Centos9配置网络源 [rootcentos9 ~]# dnf config-manager --set-enabled crb [rootcentos9 ~]# dnf install epel-release epel-next-release 安装依赖包 [rootcentos9 ~]# yum install -y libtirpc-devel libxml2-de…...

搭建内网穿透
文章目录摘要npsfrp服务提供商摘要 内网穿透是一种方便的技术,可以让用户随时随地访问内网设备。有两种方式可以使用内网穿透:自己搭建,使用nps/frps软件;购买服务,快速享受内网穿透带来的便利。 nps 内网穿透。参考…...

vue3组件库项目学习笔记(八):Git 使用总结
目前组件库的开发已经接近尾声,因为这次是使用 git 进行协作的开发模式,在团队协作的时候遇到很多的问题,开发过程中发现小伙伴们对于 git 的使用还不是很熟练,这里就简单总结一下常用的 git 的操作,大致有:…...

ISO7320FCQDRQ1数字隔离器LMG1025QDEETQ1半桥GaN驱动器
1、数字隔离器 DGTL ISO 3000VRMS 2CH 8SOIC型号:ISO7320FCQDRQ1批次:新技术:容性耦合类型:通用隔离式电源:无通道数:2输入 - 侧 1/侧 2:2/0通道类型:单向电压 - 隔离:30…...
openmmlab 语义分割算法基础
本文是openmmlab AI实战营的第六次课程的笔记,以下是我比较关注的部分。简要介绍语义分割:如下图,左边原图,右边语义分割图,对每个像数进行分类应用语义分割在个各种场景下都非常重要,特别是在自动驾驶和医…...

2023年深圳/东莞/惠州CPDA数据分析师认证报名入口
CPDA数据分析师认证是中国大数据领域有一定权威度的中高端人才认证,它不仅是中国较早大数据专业技术人才认证、更是中国大数据时代先行者,具有广泛的社会认知度和权威性。 无论是地方政府引进人才、公务员报考、各大企业选聘人才,还是招投标加…...

RabbitMQ-客户端源码之AMQChannel
AMQChannel是一个抽象类,是ChannelN的父类。其中包含唯一的抽象方法: /*** Protected API - called by nextCommand to check possibly handle an incoming Command before it is returned to the caller of nextCommand. If this method* returns true…...
注意力机制(SE,ECA,CBAM) Pytorch代码
注意力机制1 SENet2 ECANet3 CBAM3.1 通道注意力3.2 空间注意力3.3 CBAM4 展示网络层具体信息1 SENet SE注意力机制(Squeeze-and-Excitation Networks):是一种通道类型的注意力机制,就是在通道维度上增加注意力机制,主要内容是是…...

Windows上的安卓应用革命:APK安装器终极指南
Windows上的安卓应用革命:APK安装器终极指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 在Windows电脑上直接运行安卓应用,这听起来像是科幻…...

智能图像去重引擎:解放数字存储空间的完整解决方案
智能图像去重引擎:解放数字存储空间的完整解决方案 【免费下载链接】AntiDupl A program to search similar and defect pictures on the disk 项目地址: https://gitcode.com/gh_mirrors/an/AntiDupl 在数字内容爆炸的时代,重复图片问题已成为技…...

5个简单步骤:在Windows电脑上直接安装Android应用的终极指南
5个简单步骤:在Windows电脑上直接安装Android应用的终极指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否厌倦了在Windows电脑上使用Android模拟器…...

革新Mac软件管理体验:Applite智能图形化工具深度解析
革新Mac软件管理体验:Applite智能图形化工具深度解析 【免费下载链接】Applite User-friendly GUI macOS application for Homebrew Casks 项目地址: https://gitcode.com/gh_mirrors/ap/Applite 还在为繁琐的命令行安装而烦恼?是否曾因复杂的Hom…...
)
别再手动查字典了!用EggNOG-mapper 5.0一键搞定GO/KEGG/COG注释(附完整流程)
基因功能注释自动化:EggNOG-mapper 5.0实战指南 在基因组学研究中,功能注释是连接序列数据与生物学意义的关键桥梁。传统的手动注释流程往往需要研究人员在多数据库间反复切换,不仅耗时费力,还容易引入人为误差。而EggNOG-mapper…...

Degrees of Lewdity汉化版全攻略:从入门到精通的四象限实战指南
Degrees of Lewdity汉化版全攻略:从入门到精通的四象限实战指南 价值定位:为什么选择模组化汉化方案? 你是否曾因语言障碍与心仪的开源游戏失之交臂?Degrees of Lewdity作为一款备受欢迎的开源游戏,其丰富的剧情和自…...

基于Python与yfinance构建本地化股票量化筛选器:以PKScreener为例
1. 项目概述与核心价值 最近在和一些做量化交易的朋友交流时,发现大家普遍面临一个痛点:虽然市面上有各种股票数据接口和量化平台,但真正能快速、灵活地根据自定义条件进行股票筛选,并且能本地化部署、深度定制的工具却不多。要么…...

如何用AEUX在30分钟内完成Figma到After Effects的无缝动画转换
如何用AEUX在30分钟内完成Figma到After Effects的无缝动画转换 【免费下载链接】AEUX Editable After Effects layers from Sketch artboards 项目地址: https://gitcode.com/gh_mirrors/ae/AEUX 你有没有经历过这样的场景?在Figma中精心设计了完美的UI界面&…...

刚续费Basic的你务必立刻阅读:官方未公告的API调用封禁、历史图库自动归档及导出格式缩水清单
更多请点击: https://intelliparadigm.com 第一章:Midjourney Basic计划的核心定位与续费陷阱警示 Midjourney Basic 计划面向轻量级创作者,提供每月 200 张图像生成额度、标准排队优先级及基础风格控制能力。其核心定位并非长期主力生产工具…...

无国界技术创业:构建全球化产品支持与远程协作体系
1. 从“车库”到“云端”:无国界创业的底层逻辑变迁 十年前,如果你在硅谷创立一家芯片设计工具(EDA)或嵌入式软件公司,头两年的客户拜访路线图大概就是101号公路沿线。工程师可以早上开车去圣何塞的客户办公室…...