注意力机制(SE,ECA,CBAM) Pytorch代码
注意力机制
- 1 SENet
- 2 ECANet
- 3 CBAM
- 3.1 通道注意力
- 3.2 空间注意力
- 3.3 CBAM
- 4 展示网络层具体信息
1 SENet
SE注意力机制(Squeeze-and-Excitation Networks):是一种通道类型的注意力机制,就是在通道维度上增加注意力机制,主要内容是是squeeze和excitation.
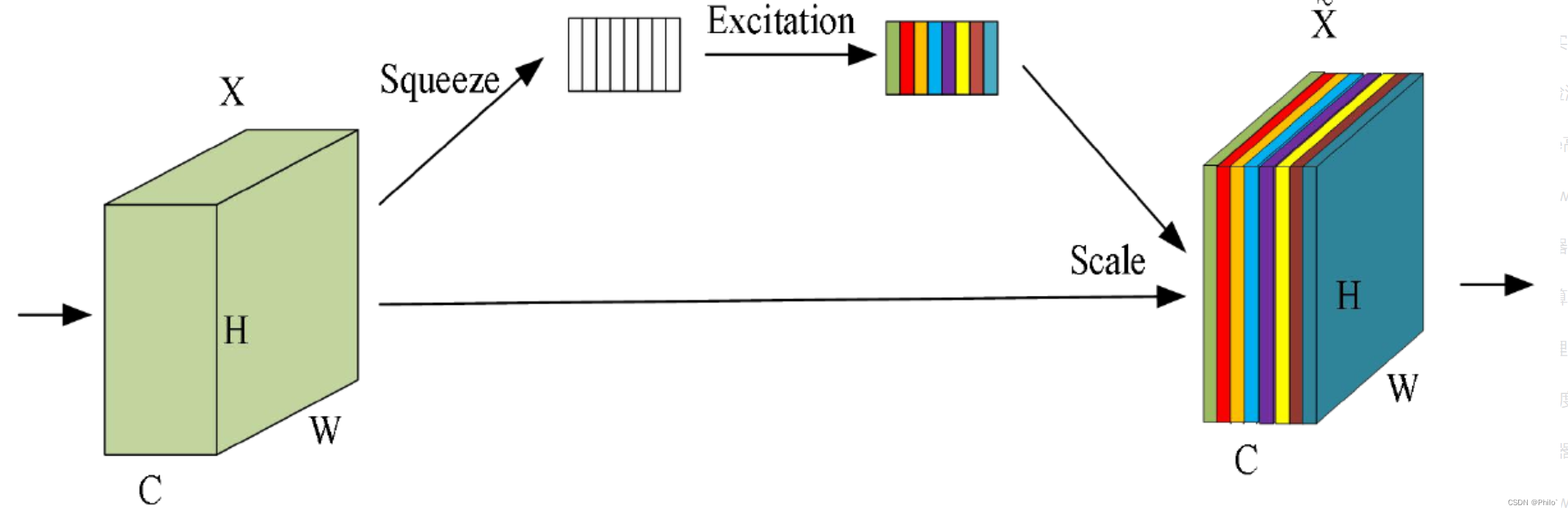
就是使用另外一个新的神经网络(两个Linear层),针对通道维度的数据进行学习,获取到特征图每个通道的重要程度,然后再和原始通道数据相乘即可。
具体参考Blog:
CNN中的注意力机制
小结:
-
SENet的核心思想是通过全连接网络根据loss损失来自动学习特征权重,而不是直接根据特征通道的数值分配来判断,使有效的特征通道的权重大。
-
论文认为excitation操作中使用两个全连接层相比直接使用一个全连接层,它的好处在于,具有更多的非线性,可以更好地拟合通道间的复杂关联。
代码:
拆解步骤,forward代码写的比较细节
import torch
from torch import nn
from torchstat import stat # 查看网络参数# 定义SE注意力机制的类
class se_block(nn.Module):# 初始化, in_channel代表输入特征图的通道数, ratio代表第一个全连接下降通道的倍数def __init__(self, in_channel, ratio=4):# 继承父类初始化方法super(se_block, self).__init__()# 属性分配# 全局平均池化,输出的特征图的宽高=1self.avg_pool = nn.AdaptiveAvgPool2d(output_size=1)# 第一个全连接层将特征图的通道数下降4倍self.fc1 = nn.Linear(in_features=in_channel, out_features=in_channel//ratio, bias=False)# relu激活self.relu = nn.ReLU()# 第二个全连接层恢复通道数self.fc2 = nn.Linear(in_features=in_channel//ratio, out_features=in_channel, bias=False)# sigmoid激活函数,将权值归一化到0-1self.sigmoid = nn.Sigmoid()# 前向传播def forward(self, inputs): # inputs 代表输入特征图# 获取输入特征图的shapeb, c, h, w = inputs.shape# 全局平均池化 [b,c,h,w]==>[b,c,1,1]x = self.avg_pool(inputs)# 维度调整 [b,c,1,1]==>[b,c]x = x.view([b,c])# 第一个全连接下降通道 [b,c]==>[b,c//4] # 这里也是使用Linear层的原因,只是对Channel进行线性变换x = self.fc1(x)x = self.relu(x)# 第二个全连接上升通道 [b,c//4]==>[b,c] # 再通过Linear层恢复Channel数目x = self.fc2(x)# 对通道权重归一化处理 # 将数值转化为(0,1)之间,体现不同通道之间重要程度x = self.sigmoid(x)# 调整维度 [b,c]==>[b,c,1,1] x = x.view([b,c,1,1])# 将输入特征图和通道权重相乘outputs = x * inputsreturn outputs
结果展示:
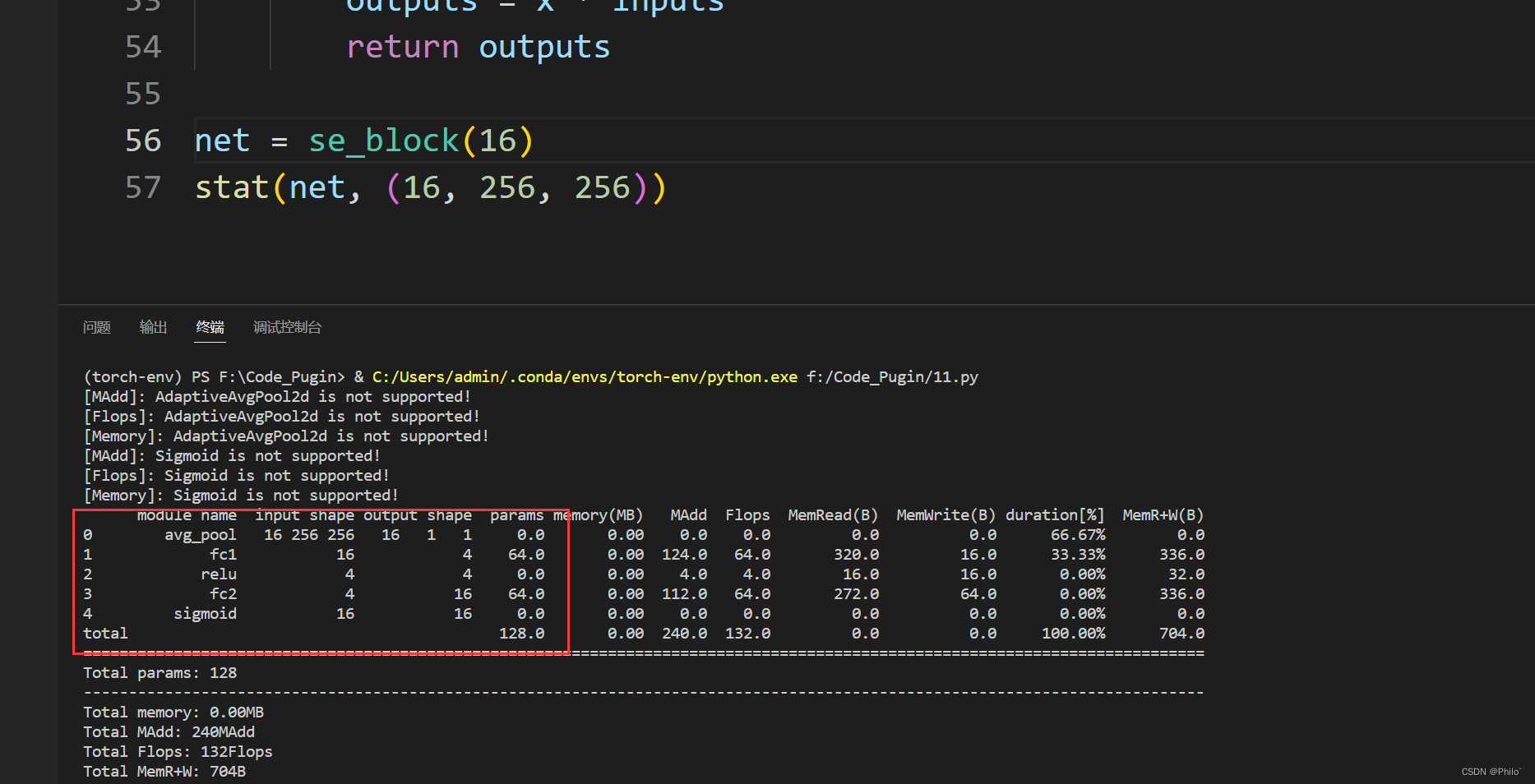
提示: in_channel/ratio需要大于0,否则线性层输入是0维度,没有意义,可以根据自己需求调整ratio的大小。
2 ECANet
作者表明 SENet 中的降维会给通道注意力机制带来副作用,并且捕获所有通道之间的依存关系是效率不高的,而且是不必要的。
参考Blog:
CNN中的注意力机制
代码:
详细版本:在forward中,介绍了每一步的作用
import torch
from torch import nn
import math
from torchstat import stat # 查看网络参数# 定义ECANet的类
class eca_block(nn.Module):# 初始化, in_channel代表特征图的输入通道数, b和gama代表公式中的两个系数def __init__(self, in_channel, b=1, gama=2):# 继承父类初始化super(eca_block, self).__init__()# 根据输入通道数自适应调整卷积核大小kernel_size = int(abs((math.log(in_channel, 2)+b)/gama))# 如果卷积核大小是奇数,就使用它if kernel_size % 2:kernel_size = kernel_size# 如果卷积核大小是偶数,就把它变成奇数else:kernel_size = kernel_size + 1# 卷积时,为例保证卷积前后的size不变,需要0填充的数量padding = kernel_size // 2# 全局平均池化,输出的特征图的宽高=1self.avg_pool = nn.AdaptiveAvgPool2d(output_size=1)# 1D卷积,输入和输出通道数都=1,卷积核大小是自适应的# 这个1维卷积需要好好了解一下机制,这是改进SENet的重要不同点self.conv = nn.Conv1d(in_channels=1, out_channels=1, kernel_size=kernel_size,bias=False, padding=padding)# sigmoid激活函数,权值归一化self.sigmoid = nn.Sigmoid()# 前向传播def forward(self, inputs):# 获得输入图像的shapeb, c, h, w = inputs.shape# 全局平均池化 [b,c,h,w]==>[b,c,1,1]x = self.avg_pool(inputs)# 维度调整,变成序列形式 [b,c,1,1]==>[b,1,c]x = x.view([b,1,c]) # 这是为了给一维卷积# 1D卷积 [b,1,c]==>[b,1,c]x = self.conv(x)# 权值归一化x = self.sigmoid(x)# 维度调整 [b,1,c]==>[b,c,1,1]x = x.view([b,c,1,1])# 将输入特征图和通道权重相乘[b,c,h,w]*[b,c,1,1]==>[b,c,h,w]outputs = x * inputsreturn outputs
精简版:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchinfo import summary
import mathclass EfficientChannelAttention(nn.Module): # Efficient Channel Attention moduledef __init__(self, c, b=1, gamma=2):super(EfficientChannelAttention, self).__init__()t = int(abs((math.log(c, 2) + b) / gamma))k = t if t % 2 else t + 1self.avg_pool = nn.AdaptiveAvgPool2d(1)self.conv1 = nn.Conv1d(1, 1, kernel_size=k, padding=int(k/2), bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):x = self.avg_pool(x)# 这里可以对照上一版代码,理解每一个函数的作用x = self.conv1(x.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)out = self.sigmoid(x)return out
效果展示:
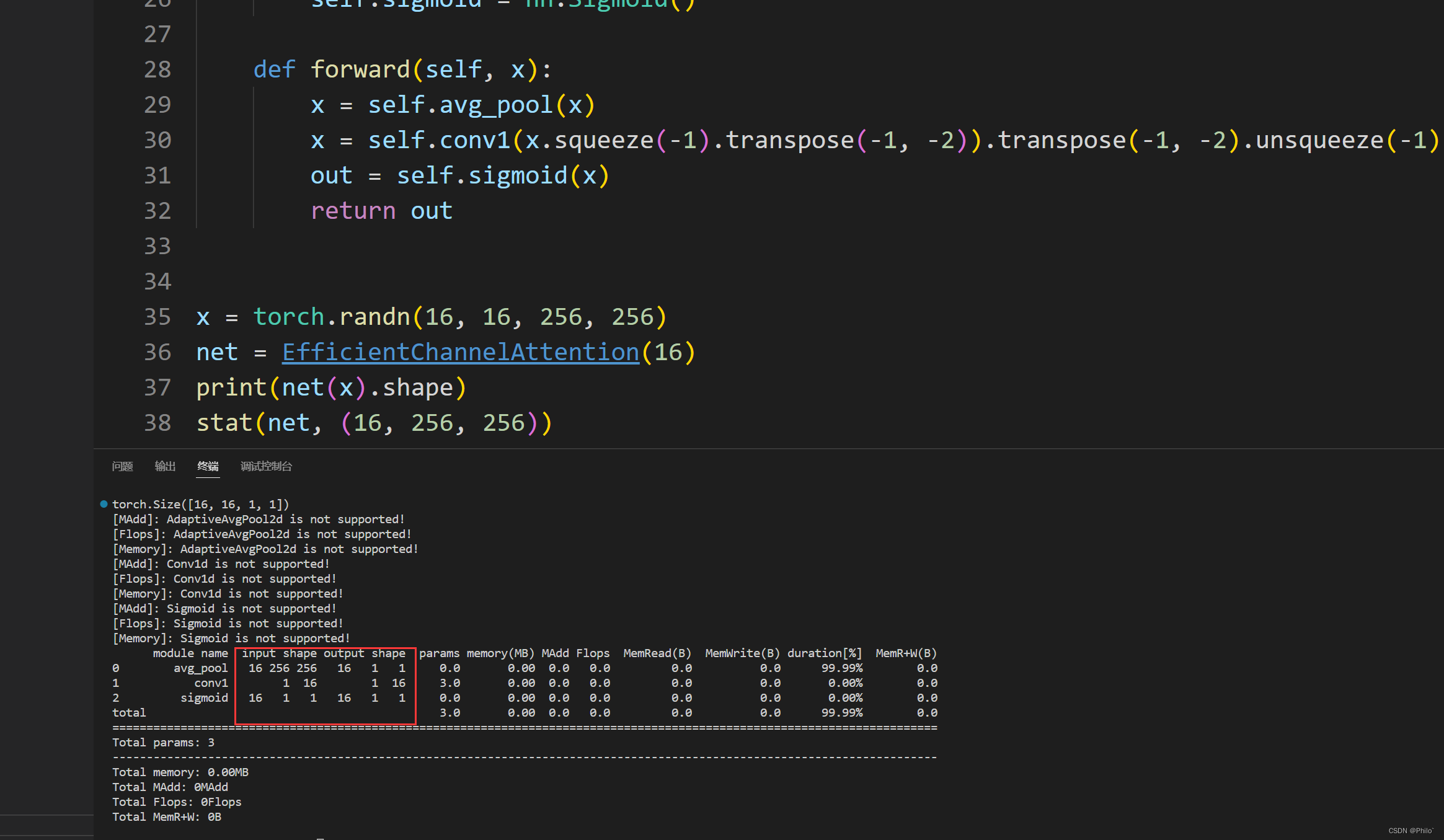
总结:
ECANet参数更少!
3 CBAM
CBAM注意力机制是由**通道注意力机制(channel)和空间注意力机制(spatial)**组成。
先通道注意力,后空间注意力的顺序注意力模块!
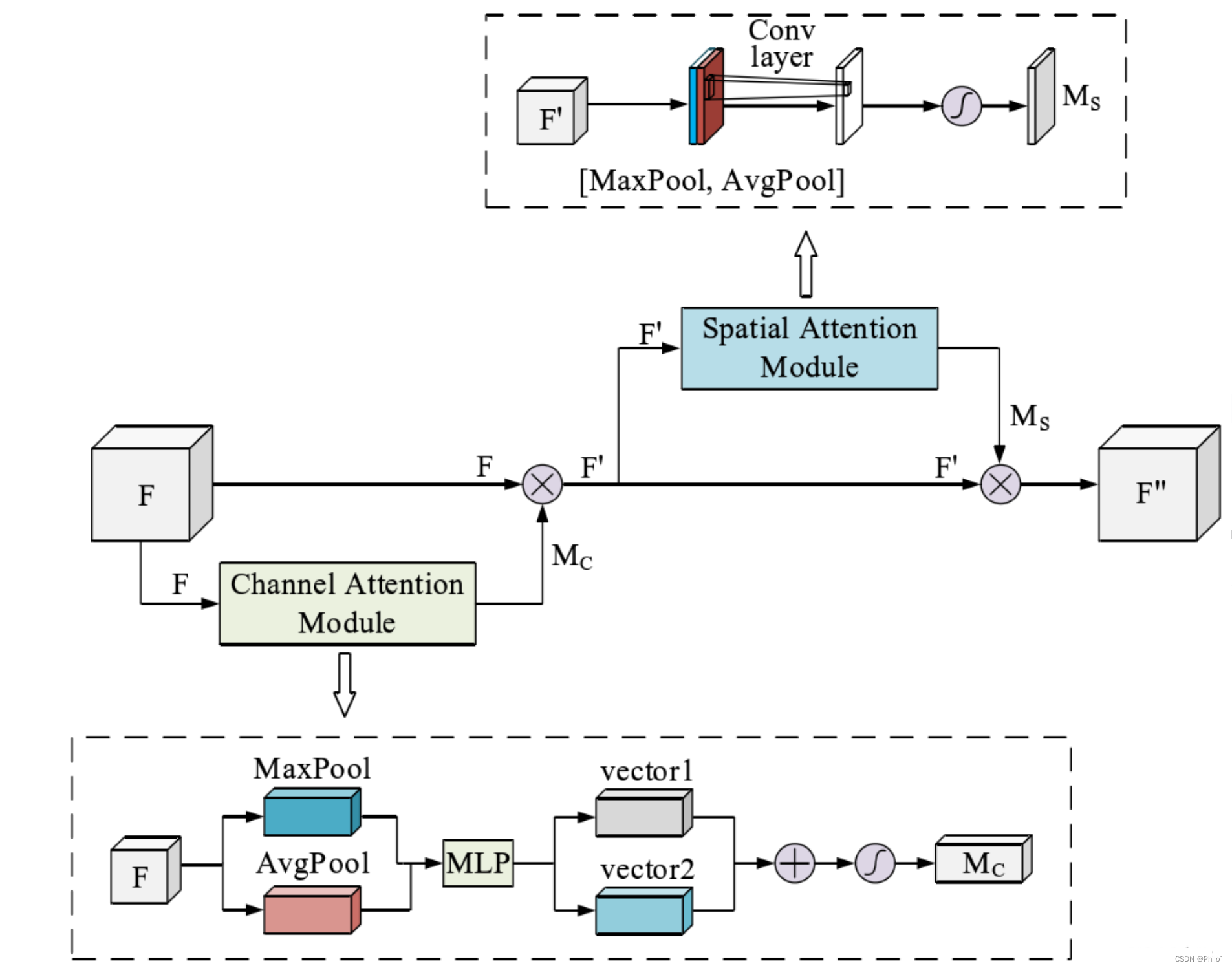
3.1 通道注意力
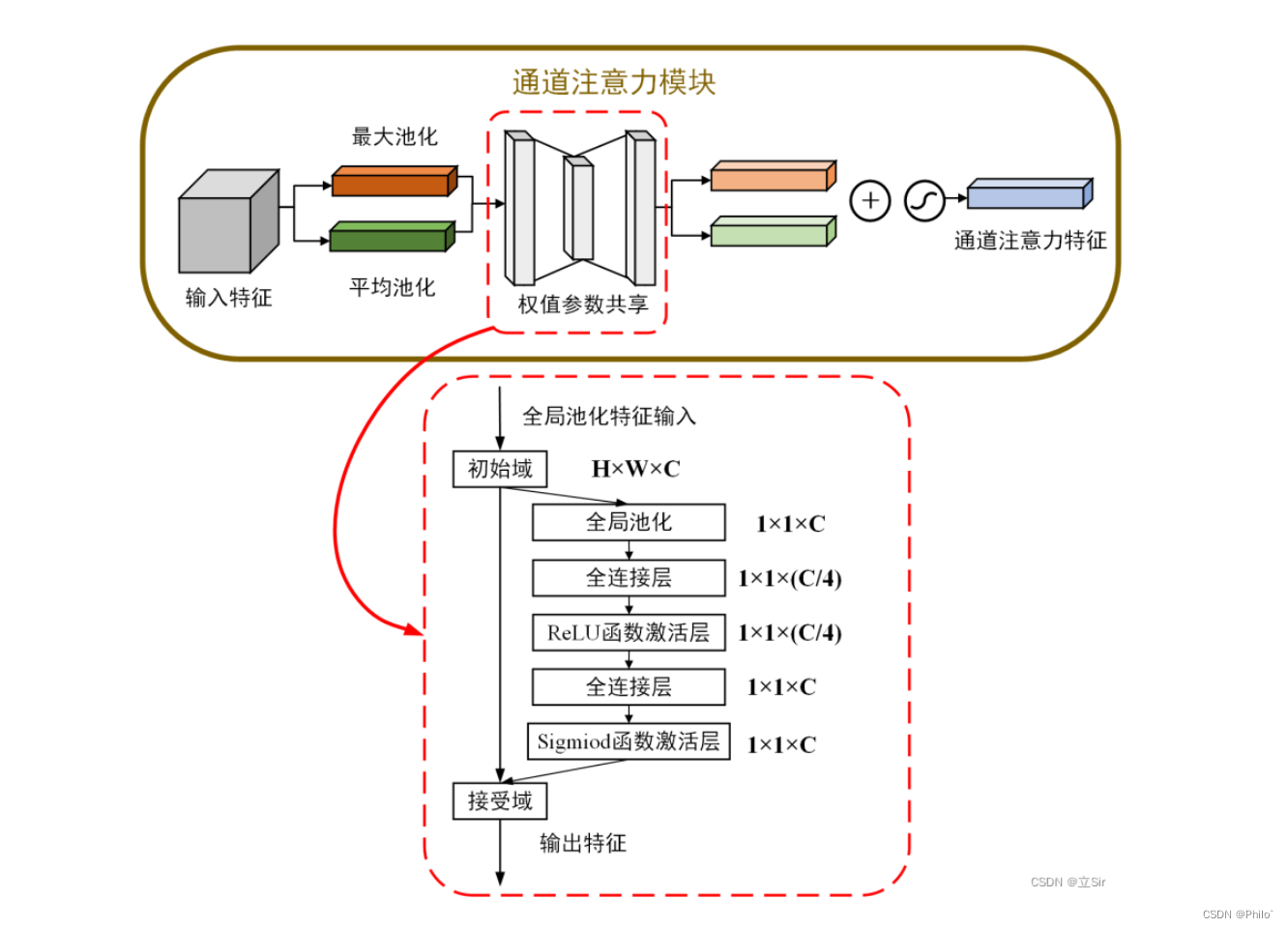
输入数据,对数据分别做最大池化操作和平均池化操作(输出都是batchchannel11),然后使用SENet的方法,针对channel进行先降维后升维操作,之后将输出的两个结果相加,再使用Sigmoid得到通道权重,再之后使用View函数恢复**(batchchannel11)**维度,和原始数据相乘得到通道注意力结果!
通道注意力代码:
#(1)通道注意力机制
class channel_attention(nn.Module):# 初始化, in_channel代表输入特征图的通道数, ratio代表第一个全连接的通道下降倍数def __init__(self, in_channel, ratio=4):# 继承父类初始化方法super(channel_attention, self).__init__()# 全局最大池化 [b,c,h,w]==>[b,c,1,1]self.max_pool = nn.AdaptiveMaxPool2d(output_size=1)# 全局平均池化 [b,c,h,w]==>[b,c,1,1]self.avg_pool = nn.AdaptiveAvgPool2d(output_size=1)# 第一个全连接层, 通道数下降4倍self.fc1 = nn.Linear(in_features=in_channel, out_features=in_channel//ratio, bias=False)# 第二个全连接层, 恢复通道数self.fc2 = nn.Linear(in_features=in_channel//ratio, out_features=in_channel, bias=False)# relu激活函数self.relu = nn.ReLU()# sigmoid激活函数self.sigmoid = nn.Sigmoid()# 前向传播def forward(self, inputs):# 获取输入特征图的shapeb, c, h, w = inputs.shape# 输入图像做全局最大池化 [b,c,h,w]==>[b,c,1,1]max_pool = self.max_pool(inputs)# 输入图像的全局平均池化 [b,c,h,w]==>[b,c,1,1]avg_pool = self.avg_pool(inputs)# 调整池化结果的维度 [b,c,1,1]==>[b,c]max_pool = max_pool.view([b,c])avg_pool = avg_pool.view([b,c])# 第一个全连接层下降通道数 [b,c]==>[b,c//4]x_maxpool = self.fc1(max_pool)x_avgpool = self.fc1(avg_pool)# 激活函数x_maxpool = self.relu(x_maxpool)x_avgpool = self.relu(x_avgpool)# 第二个全连接层恢复通道数 [b,c//4]==>[b,c]x_maxpool = self.fc2(x_maxpool)x_avgpool = self.fc2(x_avgpool)# 将这两种池化结果相加 [b,c]==>[b,c]x = x_maxpool + x_avgpool# sigmoid函数权值归一化x = self.sigmoid(x)# 调整维度 [b,c]==>[b,c,1,1]x = x.view([b,c,1,1])# 输入特征图和通道权重相乘 [b,c,h,w]outputs = inputs * xreturn outputs
3.2 空间注意力
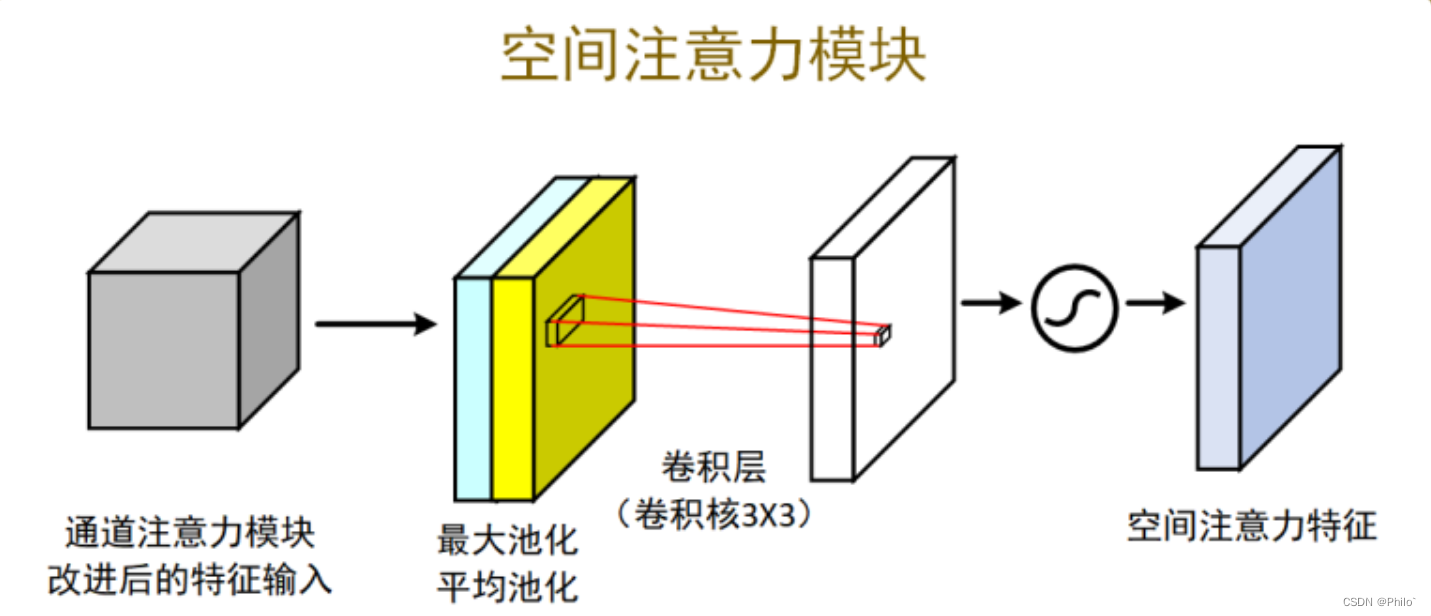
针对输入数据,分别选取数据中最大值所在的维度(batch1h*w),和按照维度进行数据平均操作(batch1hw),然后将两个数据做通道连接(batch2hw),使用卷积操作,将channel维度降为1,之后对结果取sigmoid,得到空间注意力权重,和原始数据相乘得到空间注意力结果。
代码:
#(2)空间注意力机制
class spatial_attention(nn.Module):# 初始化,卷积核大小为7*7def __init__(self, kernel_size=7):# 继承父类初始化方法super(spatial_attention, self).__init__()# 为了保持卷积前后的特征图shape相同,卷积时需要paddingpadding = kernel_size // 2# 7*7卷积融合通道信息 [b,2,h,w]==>[b,1,h,w]self.conv = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=kernel_size,padding=padding, bias=False)# sigmoid函数self.sigmoid = nn.Sigmoid()# 前向传播def forward(self, inputs):# 在通道维度上最大池化 [b,1,h,w] keepdim保留原有深度# 返回值是在某维度的最大值和对应的索引x_maxpool, _ = torch.max(inputs, dim=1, keepdim=True)# 在通道维度上平均池化 [b,1,h,w]x_avgpool = torch.mean(inputs, dim=1, keepdim=True)# 池化后的结果在通道维度上堆叠 [b,2,h,w]x = torch.cat([x_maxpool, x_avgpool], dim=1)# 卷积融合通道信息 [b,2,h,w]==>[b,1,h,w]x = self.conv(x)# 空间权重归一化x = self.sigmoid(x)# 输入特征图和空间权重相乘outputs = inputs * xreturn outputs
3.3 CBAM
将通道注意力模块和空间注意力模块顺序串联得到CBAM模块!
代码:
class cbam(nn.Module):# 初始化,in_channel和ratio=4代表通道注意力机制的输入通道数和第一个全连接下降的通道数# kernel_size代表空间注意力机制的卷积核大小def __init__(self, in_channel, ratio=4, kernel_size=7):# 继承父类初始化方法super(cbam, self).__init__()# 实例化通道注意力机制self.channel_attention = channel_attention(in_channel=in_channel, ratio=ratio)# 实例化空间注意力机制self.spatial_attention = spatial_attention(kernel_size=kernel_size)# 前向传播def forward(self, inputs):# 先将输入图像经过通道注意力机制x = self.channel_attention(inputs)# 然后经过空间注意力机制x = self.spatial_attention(x)return x
结果:
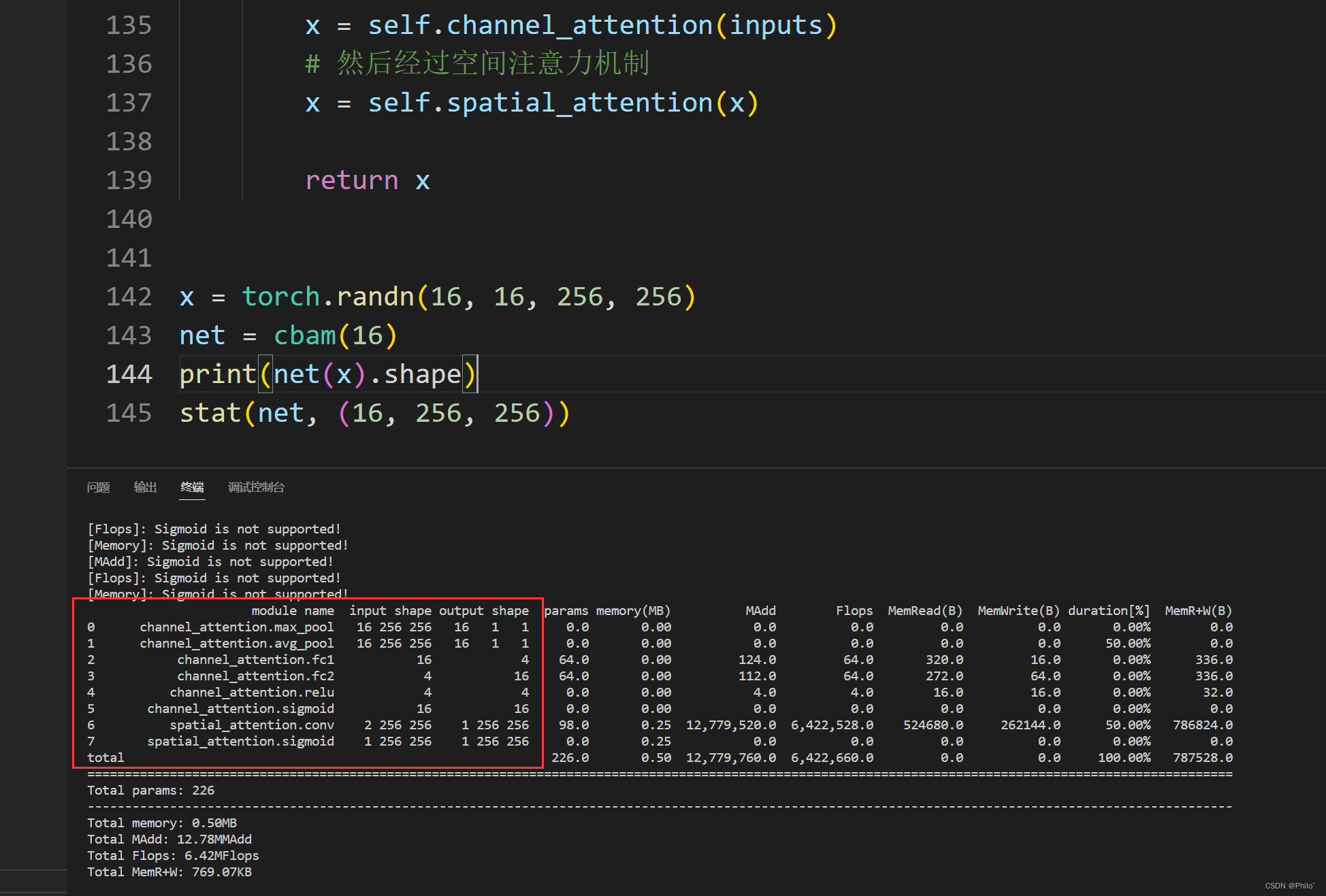
4 展示网络层具体信息
安装包
pip install torchstat
使用
from torchstat import stat net = cbam(16)
stat(net, (16, 256, 256)) # 不需要Batch维度
注意力机制后期学习到再持续更新!!
参考博客:
CNN注意力机制
ECANet
相关文章:
注意力机制(SE,ECA,CBAM) Pytorch代码
注意力机制1 SENet2 ECANet3 CBAM3.1 通道注意力3.2 空间注意力3.3 CBAM4 展示网络层具体信息1 SENet SE注意力机制(Squeeze-and-Excitation Networks):是一种通道类型的注意力机制,就是在通道维度上增加注意力机制,主要内容是是…...

Vue2笔记03 脚手架(项目结构),常用属性配置,ToDoList(本地存储,组件通信)
Vue脚手架 vue-cli 向下兼容可以选择较高版本 初始化 全局安装脚手架 npm install -g vue/cli 创建项目:切换到项目所在目录 vue create xxx 按照指引选择vue版本 创建成功 根据指引依次输入上面指令即可运行项目 也可使用vue ui在界面上完成创建&…...
Java程序的执行顺序、简述对线程池的理解
点个关注,必回关 文章目录一、Java程序是如何执行的二、合理利用线程池能够带来三个好处一、Java程序是如何执行的 我们日常的工作中都使用开发工具(IntelliJ IDEA 或 Eclipse 等)可以很方便的调试程序,或者是通 过打包工具把项目…...

【前言】嵌入式系统简介
随手拍拍💁♂️📷 日期: 2022.12.01 地点: 杭州 介绍: 2022.11.30下午两点时,杭州下了一场特别大的雪。隔天的12月路过食堂时,边上的井盖上发现了这个小雪人。此时边上的雪已经融化殆尽,只有这个雪人依旧维持着原状⛄…...

React设计原理—1框架原理
阅读前须知 本文是笔者学习卡颂的《React设计原理》的读书笔记,对书中有价值内容以Q&A方式进行呈现,同时结合了自己的理解🤔阅读时推荐先看问题,想想自己的答案,再和答案比对一下本文属于前端框架科普,…...

(C00034)基于Springboot+html前后端分离技术的宿舍管理系统-有文档
基于Springboothtml技术的宿舍管理系统-有文档项目简介项目获取开发环境项目技术运行截图项目简介 基于Springboothtml的前后端分离技术的宿舍管理系统项目为了方便对学生宿舍进行管理而设计,分为后勤、宿管、学生三种用户,后勤对整体宿舍进行管理、宿管…...

Flink面试题
一 基础篇Flink的执行图有哪几种?分别有什么作用Flink中的执行图一般是可以分为四类,按照生成顺序分别为:StreamGraph-> JobGraph-> ExecutionGraph->物理执行图。1)StreamGraph顾名思义,这里代表的是我们编写…...
Python学习笔记
前言:又从仓库翻出来了一些以前总结的文档,以下内容是我初学Python时网上找的或是图书馆借书抄写的笔记,现在再看有点零散不成体系,但是也还是纪念一下子吧。 Python学习笔记 对于初学编程的人来说,Python可以缩短编…...

最适合入门的100个深度学习实战项目
🚨注意🚨:最近经粉丝反馈,发现有些订阅者将此专栏内容进行二次售卖,特在此声明,本专栏内容仅供学习,不得以任何方式进行售卖,未经作者许可不得对本专栏内容行使发表权、署名权、修改…...

AssertionError: 618 columns passed, passed data had 508 columns【已解决】
问题描述 程序中断,报错如下AssertionError: 618 columns passed, passed data had 508 columns Exception has occurred: ValueError 618 columns passed, passed data had 508 columns AssertionError: 618 columns passed, passed data had 508 columnsThe abo…...

166_技巧_Power BI 窗口函数处理连续发生业务问题
166_技巧_Power BI 窗口函数处理连续发生业务问题 一、背景 在生产经营的数据监控中,会有一类指标需要监控是否连续发生,从而根据其在设定区间中的连续频次来评价业务。 例如: 员工连续迟到天数。销售金额连续上升或者下降。用户连续登陆…...

电子科技大学人工智能期末复习笔记(五):机器学习
目录 前言 监督学习 vs 无监督学习 回归 vs 分类 Regression vs Classification 训练集 vs 测试集 vs 验证集 泛化和过拟合 Generalization & Overfitting 线性分类器 Linear Classifiers 激活函数 - 概率决策 ⚠线性回归 决策树 Decision Trees 决策树构建递归…...
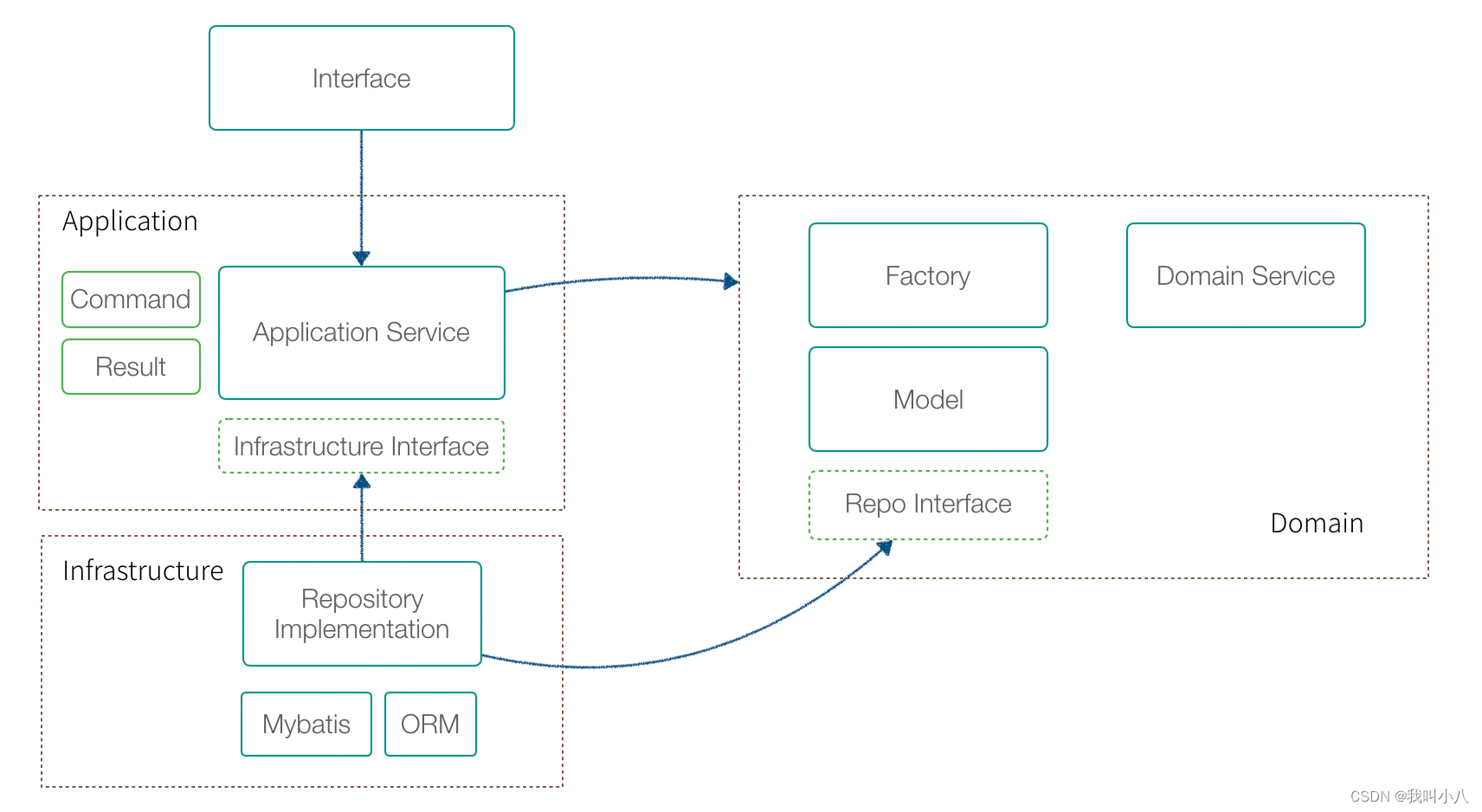
使用DDD指导业务设计的总结思考
领域驱动设计(DDD) 是 Eric Evans 提出的一种软件设计方法和思想,主要解决业务系统的设计和建模。DDD 有大量难以理解的概念,尤其是翻译的原因,某些词汇非常生涩,例如:模型、限界上下文、聚合、…...

面试官问:如何确保缓存和数据库的一致性?
如果你对这个问题有过研究,应该可以发现这个问题其实很好回答,如果第一次听到或者第一次遇到这个问题,估计会有点懵,今天我们来聊聊这个话题。 1、问题分析 首先我们来看看为什么会有这个问题! 我们在日常开发中&am…...

16.数据库Redis
一、基本概念 Redis(Remote Dictionary Server)译为“远程字典服务”,它是一款基于内存实现的键值型 NoSQL 数据库, 通常也被称为数据结构服务器,这是因为它可以存储多种数据类型,比如 string(字…...

【Redis高级-集群分片】
单机安装Redis首先需要安装Redis所需要的依赖:yum install -y gcc tclRedis安装包上传到虚拟机的任意目录:我放到了/tmp目录:解压缩:tar -zxvf /tmp/redis-6.2.4.tar.gz -C /tmp解压后:进入redis目录:cd /t…...

CSDN - CSDN27题解
文章目录幸运数字题目描述解题思路AC代码投篮题目描述解题思路AC代码通货膨胀-x国货币题目描述解题思路AC代码最后一位题目描述解题思路AC代码CSDN编程竞赛报名地址:https://edu.csdn.net/contest/detail/41 这次题目描述刚开始好像有些问题,之后被修正了…...

docker拉取mysql
搜索mysql版本docker search mysql搜索获赞数(星星数量) 大于 1000 的镜像docker search --filterstars1000 mysql搜索官方发布的版本docker search --filter is-officialtrue mysql搜索版本号docker search mysql57拉取docker pull devbeta/mysql57查看下载镜像docker images启…...

在Linux上安装Python3
记录:373场景:在CentOS 7.9操作系统上,安装Python-3.8.9环境。版本:JDK 1.8 Python-3.8.9官网地址:https://www.python.org下载地址:https://www.python.org/ftp/python/1.安装基础依赖1.1安装gcc(1)安装命…...

23 种设计模式的通俗解释,看完秒懂
01 工厂方法 追 MM 少不了请吃饭了,麦当劳的鸡翅和肯德基的鸡翅都是 MM 爱吃的东西,虽然口味有所不同,但不管你带 MM 去麦当劳或肯德基,只管向服务员说「来四个鸡翅」就行了。麦当劳和肯德基就是生产鸡翅的 Factory 工厂模式&…...

别再瞎猜了!LaTeX排版中em、ex、pt、px到底该用哪个?一篇讲透所有单位
LaTeX排版单位全指南:从em到px的精准选择法则 当你第一次打开LaTeX文档,准备调整行距或设置边距时,那些神秘的缩写——em、ex、pt、px——是否让你感到困惑?每个单位似乎都有其存在的理由,但何时使用哪个才是最合适的&…...

ITK-SNAP医学图像分割:从临床需求到精准分析的完整指南
ITK-SNAP医学图像分割:从临床需求到精准分析的完整指南 【免费下载链接】itksnap ITK-SNAP medical image segmentation tool 项目地址: https://gitcode.com/gh_mirrors/it/itksnap 面对复杂的医学影像数据,你是否曾为如何准确提取关键解剖结构而…...

如何快速提升Obsidian笔记体验:AnuPpuccin主题完整指南
如何快速提升Obsidian笔记体验:AnuPpuccin主题完整指南 【免费下载链接】AnuPpuccin Personal theme for Obsidian 项目地址: https://gitcode.com/gh_mirrors/an/AnuPpuccin 还在为单调的Obsidian界面而烦恼吗?想让你的笔记软件既美观又实用吗&a…...

英雄联盟终极自动化工具:LeagueAkari 免费完整指南,告别繁琐操作
英雄联盟终极自动化工具:LeagueAkari 免费完整指南,告别繁琐操作 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否…...
:覆盖12类先锋流派+87个已验证prompt模板)
Midjourney现代主义风格提示词工程(2024权威白皮书首发):覆盖12类先锋流派+87个已验证prompt模板
更多请点击: https://intelliparadigm.com 第一章:Midjourney现代主义风格的美学基因与范式跃迁 现代主义风格在Midjourney中的生成并非对包豪斯或构成主义的简单复刻,而是通过扩散模型对20世纪视觉语法进行概率性重编码——其核心在于将“简…...

Smithbox终极指南:如何免费创建魂系游戏MOD的完整教程
Smithbox终极指南:如何免费创建魂系游戏MOD的完整教程 【免费下载链接】Smithbox Smithbox is a modding tool for Elden Ring, Armored Core VI, Sekiro, Dark Souls 3, Dark Souls 2, Dark Souls, Bloodborne and Demons Souls. 项目地址: https://gitcode.com/…...

靠谱的微晶电热板机构
在实验设备领域,微晶电热板是一款重要的工具,选择靠谱的机构至关重要。微晶电热板的重要性微晶电热板在环境监测、食品安全、农产品检测等分析实验室中应用广泛。它能够为样品前处理提供稳定的加热环境,保障实验结果的准确性。行业报告显示&a…...

ElevenLabs奥里亚文语音SDK集成终极 checklist:从Unicode 13.0字符兼容性到Odia Conjunct Glyph渲染异常修复
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs奥里亚文语音SDK集成终极 checklist:从Unicode 13.0字符兼容性到Odia Conjunct Glyph渲染异常修复 Unicode 13.0 兼容性验证 ElevenLabs v4.2.1 SDK 默认支持 Unicode 13.0&…...

内容做了一大堆,流量就是起不来?初创公司低成本获流的真实解法
内容做了一大堆,流量就是起不来?初创公司低成本获流的真实解法 我见过太多这样的团队:每周雷打不动三篇公众号,两条短视频,外加若干条推特,数据面板安安静静,后台没有咨询,评论区只…...

告别电脑“飞机起飞“噪音:FanControl风扇控制终极指南
告别电脑"飞机起飞"噪音:FanControl风扇控制终极指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Tr…...