AssertionError: 618 columns passed, passed data had 508 columns【已解决】
问题描述
程序中断,报错如下AssertionError: 618 columns passed, passed data had 508 columns
Exception has occurred: ValueError
618 columns passed, passed data had 508 columns
AssertionError: 618 columns passed, passed data had 508 columnsThe above exception was the direct cause of the following exception:File "E:\matlab\CHB-MIT-DATA\epilepsy_eeg_classification\preprocessing.py", line 117, in eeg_preprocessingres = pd.DataFrame(res, columns=column_names)File "E:\matlab\CHB-MIT-DATA\epilepsy_eeg_classification\preprocessing.py", line 334, in <module>res = eeg_preprocessing(file, seizures)
ValueError: 618 columns passed, passed data had 508 columns
terminal报错如下:
Backend Qt5Agg is interactive backend. Turning interactive mode on.

弯路
numpy1.19.4改为了numpy1.21.6
pip list: numpy1.21.6
conda list: numpy1.20.1
发现,报错仍旧一样,没有任何改变。
我的怀疑是数据里面有nan值,而程序中并没有处理的方法,是丢弃是补充为0还是补充为平均值。因为如果丢弃的话。
我发现numpy版本不对,卸载的时候,报错说:
PackageNotInstalledError: Package is not installed in prefix于是我使用
conda udate numpy
报错如下:
(base) PS E:\matlab> conda update numpy
Collecting package metadata (repodata.json): done
Solving environment: -
The environment is inconsistent, please check the package plan carefully
The following packages are causing the inconsistency:- defaults/win-64::anaconda==custom=py37_1- https://repo.anaconda.com/pkgs/main/win-64::bkcharts==0.2=py37_0- https://repo.anaconda.com/pkgs/main/win-64::blaze==0.11.3=py37_0- https://repo.anaconda.com/pkgs/main/win-64::bokeh==0.13.0=py37_0- https://repo.anaconda.com/pkgs/main/win-64::dask==0.19.1=py37_0- https://repo.anaconda.com/pkgs/main/win-64::numpydoc==0.8.0=py37_0- https://repo.anaconda.com/pkgs/main/win-64::odo==0.5.1=py37_0- https://repo.anaconda.com/pkgs/main/win-64::seaborn==0.9.0=py37_0- https://repo.anaconda.com/pkgs/main/win-64::sphinx==1.7.9=py37_0- https://repo.anaconda.com/pkgs/main/win-64::spyder==3.3.1=py37_1- https://repo.anaconda.com/pkgs/main/win-64::statsmodels==0.9.0=py37h452e1ab_0- defaults/win-64::_anaconda_depends==5.3.1=py37_0
failedCondaMemoryError: The conda process ran out of memory. Increase system memory and/or try again.有人说可以直接退到base环境更新conda。
(base) PS E:\matlab> conda update --name base conda
Collecting package metadata (repodata.json): done
Solving environment: |
The environment is inconsistent, please check the package plan carefully
The following packages are causing the inconsistency:- defaults/win-64::anaconda==custom=py37_1- https://repo.anaconda.com/pkgs/main/win-64::bkcharts==0.2=py37_0- https://repo.anaconda.com/pkgs/main/win-64::blaze==0.11.3=py37_0- https://repo.anaconda.com/pkgs/main/win-64::bokeh==0.13.0=py37_0- https://repo.anaconda.com/pkgs/main/win-64::dask==0.19.1=py37_0- https://repo.anaconda.com/pkgs/main/win-64::numpydoc==0.8.0=py37_0- https://repo.anaconda.com/pkgs/main/win-64::odo==0.5.1=py37_0- https://repo.anaconda.com/pkgs/main/win-64::seaborn==0.9.0=py37_0- https://repo.anaconda.com/pkgs/main/win-64::sphinx==1.7.9=py37_0- https://repo.anaconda.com/pkgs/main/win-64::spyder==3.3.1=py37_1- https://repo.anaconda.com/pkgs/main/win-64::statsmodels==0.9.0=py37h452e1ab_0- defaults/win-64::_anaconda_depends==5.3.1=py37_0
failedCondaMemoryError: The conda process ran out of memory. Increase system memory and/or try again.conda update conda,conda update numpy,conda update --name base conda,在cat(自建虚拟环境)和base里都报错:
CondaMemoryError: The conda process ran out of memory. Increase system memory and/or try again.还有的朋友建议:
conda update conda -c conda-canary但是仍旧不行,报错如下,和前面的报错也一样。

CondaMemoryError:conda 进程内存不足答案 - 爱码网
更新anaconda的版本也报同样的错:
(base) PS E:\matlab> conda update anaconda
Collecting package metadata (repodata.json): done
Solving environment: \
The environment is inconsistent, please check the package plan carefully
The following packages are causing the inconsistency:- defaults/win-64::anaconda==custom=py37_1- https://repo.anaconda.com/pkgs/main/win-64::bkcharts==0.2=py37_0- https://repo.anaconda.com/pkgs/main/win-64::blaze==0.11.3=py37_0- https://repo.anaconda.com/pkgs/main/win-64::bokeh==0.13.0=py37_0- https://repo.anaconda.com/pkgs/main/win-64::dask==0.19.1=py37_0- https://repo.anaconda.com/pkgs/main/win-64::numpydoc==0.8.0=py37_0- https://repo.anaconda.com/pkgs/main/win-64::odo==0.5.1=py37_0- https://repo.anaconda.com/pkgs/main/win-64::seaborn==0.9.0=py37_0- https://repo.anaconda.com/pkgs/main/win-64::sphinx==1.7.9=py37_0- https://repo.anaconda.com/pkgs/main/win-64::spyder==3.3.1=py37_1- https://repo.anaconda.com/pkgs/main/win-64::statsmodels==0.9.0=py37h452e1ab_0- defaults/win-64::_anaconda_depends==5.3.1=py37_0
failedCondaMemoryError: The conda process ran out of memory. Increase system memory and/or try again.找到好久找到了一个解决方案:

https://github.com/conda/conda/issues/10751
解决方案
说到最后实在是稀松平常,我检查了一下程序逻辑。我发现在传递参数的过程中。
File "E:\matlab\CHB-MIT-DATA\epilepsy_eeg_classification\preprocessing.py", line 117, in eeg_preprocessing
res = pd.DataFrame(res, columns=column_names)
File "E:\matlab\CHB-MIT-DATA\epilepsy_eeg_classification\preprocessing.py", line 334, in <module>
虽然报错在117处,但是,实际上在传递的这两个数据处,通过debug的方式,发现获取的数据的列数要大于实际列数。那是因为,信号的channel变化的,而不是23个固定不变的,所以,只需要把这个固定的23改为,len(channel)就能获取到具体的数字。
将
for i in range(23):features.extend(eeg_features(temp[i]).tolist())改为
for i in range(len(channels)):features.extend(eeg_features(temp[i]).tolist())即可。
需要特别说明的是,conda创建的虚拟环境不要胡乱删除,否则会报很多错,你可以根据报错内容删除一些相应的文件,但是不能删除过多的文件。否则会报无数的错误。
这会让你非常头疼。这三篇文章都是我删错文件报错的。

你会发现你无意中删除了一些包的依赖,这就麻烦了。
另外,我的程序报错或许和你的虽然报错一样,但是具体错误的地方不一样,这个时候,你就要好好检查你生成的数据和列名是否符合情况。可以参考这篇文章来看看,或许能够解决你的错误:
已解决ValueError: 4 columns passed, passed data had 2 columns_无 羡ღ的博客-CSDN博客
参考文章
Packagenotinstallederror:未安装在前缀中 - IT宝库
相关文章:
AssertionError: 618 columns passed, passed data had 508 columns【已解决】
问题描述 程序中断,报错如下AssertionError: 618 columns passed, passed data had 508 columns Exception has occurred: ValueError 618 columns passed, passed data had 508 columns AssertionError: 618 columns passed, passed data had 508 columnsThe abo…...

166_技巧_Power BI 窗口函数处理连续发生业务问题
166_技巧_Power BI 窗口函数处理连续发生业务问题 一、背景 在生产经营的数据监控中,会有一类指标需要监控是否连续发生,从而根据其在设定区间中的连续频次来评价业务。 例如: 员工连续迟到天数。销售金额连续上升或者下降。用户连续登陆…...

电子科技大学人工智能期末复习笔记(五):机器学习
目录 前言 监督学习 vs 无监督学习 回归 vs 分类 Regression vs Classification 训练集 vs 测试集 vs 验证集 泛化和过拟合 Generalization & Overfitting 线性分类器 Linear Classifiers 激活函数 - 概率决策 ⚠线性回归 决策树 Decision Trees 决策树构建递归…...
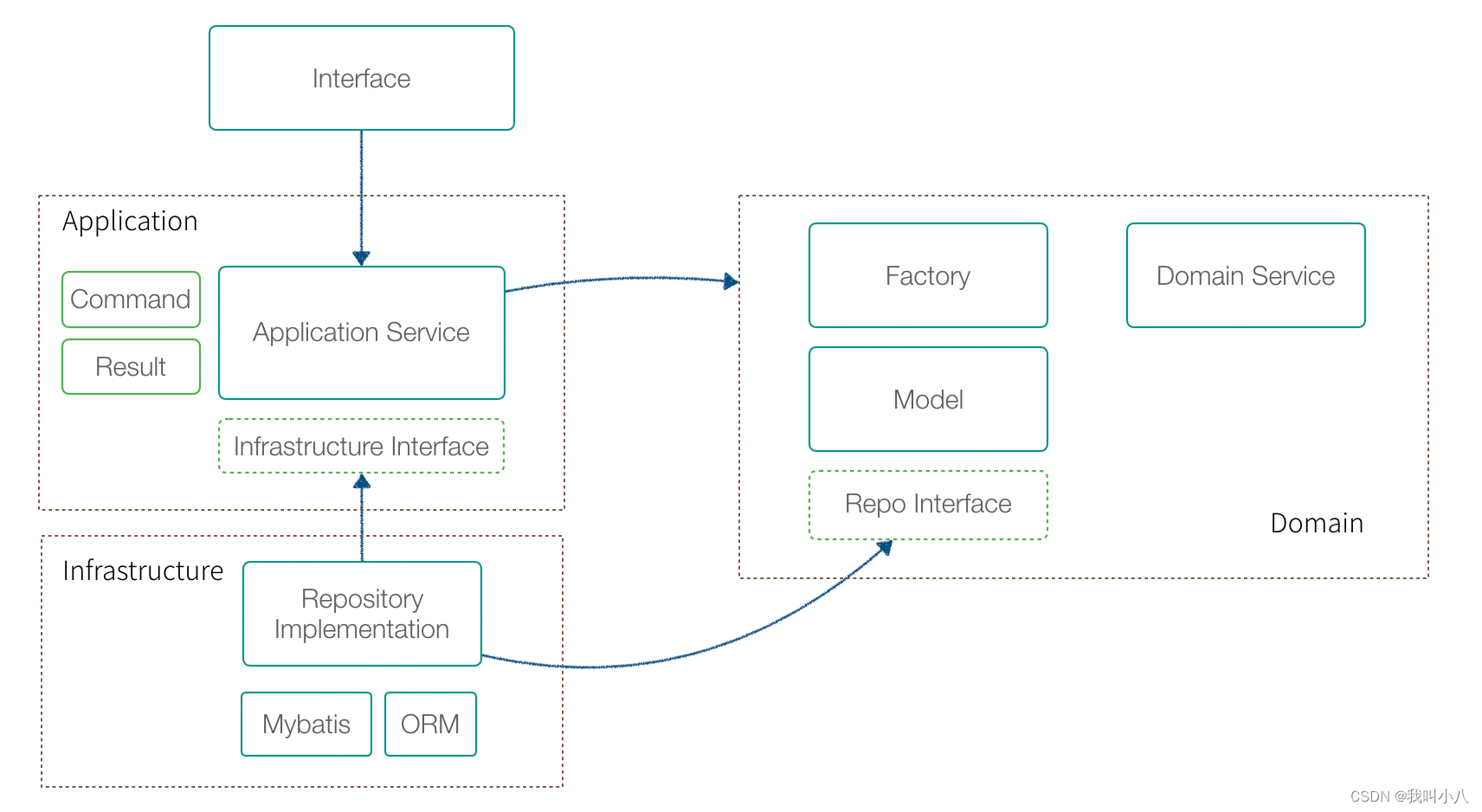
使用DDD指导业务设计的总结思考
领域驱动设计(DDD) 是 Eric Evans 提出的一种软件设计方法和思想,主要解决业务系统的设计和建模。DDD 有大量难以理解的概念,尤其是翻译的原因,某些词汇非常生涩,例如:模型、限界上下文、聚合、…...

面试官问:如何确保缓存和数据库的一致性?
如果你对这个问题有过研究,应该可以发现这个问题其实很好回答,如果第一次听到或者第一次遇到这个问题,估计会有点懵,今天我们来聊聊这个话题。 1、问题分析 首先我们来看看为什么会有这个问题! 我们在日常开发中&am…...

16.数据库Redis
一、基本概念 Redis(Remote Dictionary Server)译为“远程字典服务”,它是一款基于内存实现的键值型 NoSQL 数据库, 通常也被称为数据结构服务器,这是因为它可以存储多种数据类型,比如 string(字…...

【Redis高级-集群分片】
单机安装Redis首先需要安装Redis所需要的依赖:yum install -y gcc tclRedis安装包上传到虚拟机的任意目录:我放到了/tmp目录:解压缩:tar -zxvf /tmp/redis-6.2.4.tar.gz -C /tmp解压后:进入redis目录:cd /t…...

CSDN - CSDN27题解
文章目录幸运数字题目描述解题思路AC代码投篮题目描述解题思路AC代码通货膨胀-x国货币题目描述解题思路AC代码最后一位题目描述解题思路AC代码CSDN编程竞赛报名地址:https://edu.csdn.net/contest/detail/41 这次题目描述刚开始好像有些问题,之后被修正了…...

docker拉取mysql
搜索mysql版本docker search mysql搜索获赞数(星星数量) 大于 1000 的镜像docker search --filterstars1000 mysql搜索官方发布的版本docker search --filter is-officialtrue mysql搜索版本号docker search mysql57拉取docker pull devbeta/mysql57查看下载镜像docker images启…...

在Linux上安装Python3
记录:373场景:在CentOS 7.9操作系统上,安装Python-3.8.9环境。版本:JDK 1.8 Python-3.8.9官网地址:https://www.python.org下载地址:https://www.python.org/ftp/python/1.安装基础依赖1.1安装gcc(1)安装命…...

23 种设计模式的通俗解释,看完秒懂
01 工厂方法 追 MM 少不了请吃饭了,麦当劳的鸡翅和肯德基的鸡翅都是 MM 爱吃的东西,虽然口味有所不同,但不管你带 MM 去麦当劳或肯德基,只管向服务员说「来四个鸡翅」就行了。麦当劳和肯德基就是生产鸡翅的 Factory 工厂模式&…...
如何做好需求管理?经验方法、模型、工具
需求管理能力是衡量产品经理能力的一个重要指标。因为需求是产品的基石,只有选取恰当的方法进行需求分析及管理,才能更好的构建产品方案,从而输出精准的产品定义。结合本人学习和自身经验,打算将需求管理分”需求挖掘”、”需求分…...
)
怎么用期货做风险对冲(如何利用期货对冲风险)
不同期货市场的同一期货品种的对冲交易怎么做 不同 期货市场 的同一期货品种的 对冲交易 。 因为地域和 制度环境 不同,同一种期货品种在不同市场的同一时间的价格很可能是不一样的,并且也是在不断变化的。 这样在一个市场做多头买进࿰…...

C++标准模板库type_traits源码剖析
一、type_traits源码介绍 1、type_traits是C11提供的模板元基础库。 2、type_traits可实现在编译期计算。包括添加修饰、萃取、判断查询、类型推导等等功能。 3、type_traits提供了编译期的true和false。 二、type_traits的作用 1、根据不同类型,模板匹配不同版本…...

Python获取公众号(pc客户端)数据,使用Fiddler抓包工具
前言 嗨喽~大家好呀,这里是魔王呐 ❤ ~! 今天来教大家如何使用Fiddler抓包工具,获取公众号(PC客户端)的数据。 Fiddler是一个http协议调试代理工具,它能够记录并检查所有你的电脑和互联网之间的http通讯,…...
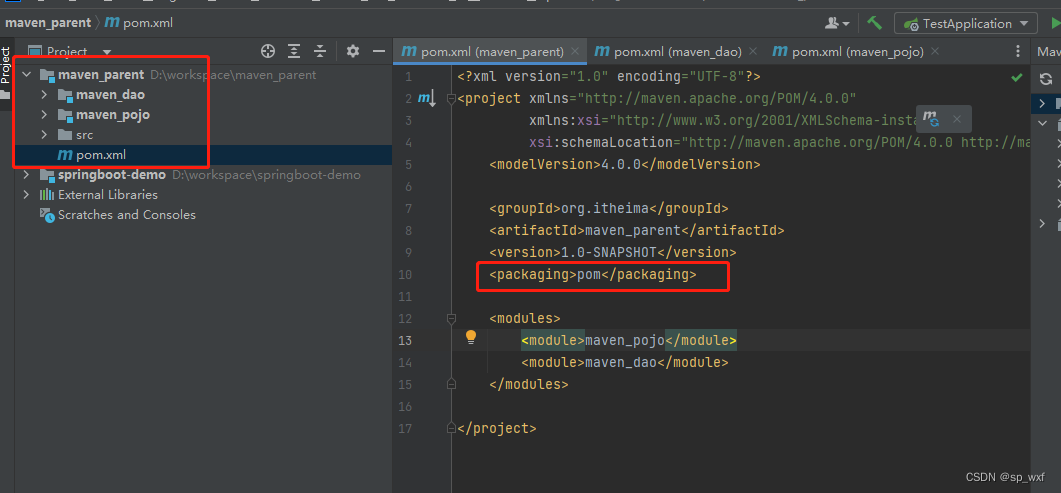
Maven进阶
这里写目录标题1.分模块开发1.1 模块更新后,会造成的影响2.依赖管理2.1 依赖传递2.2 可选依赖(隐藏自己的依赖,不让别人用)2.3 排除依赖(用别人的资源,把不用的去了)3.聚合与继承3.1 为什么要使用聚合工程?3.2 聚合工程开发2.1 聚合工程三级目录1.分模块开发 我们之前做的项目…...
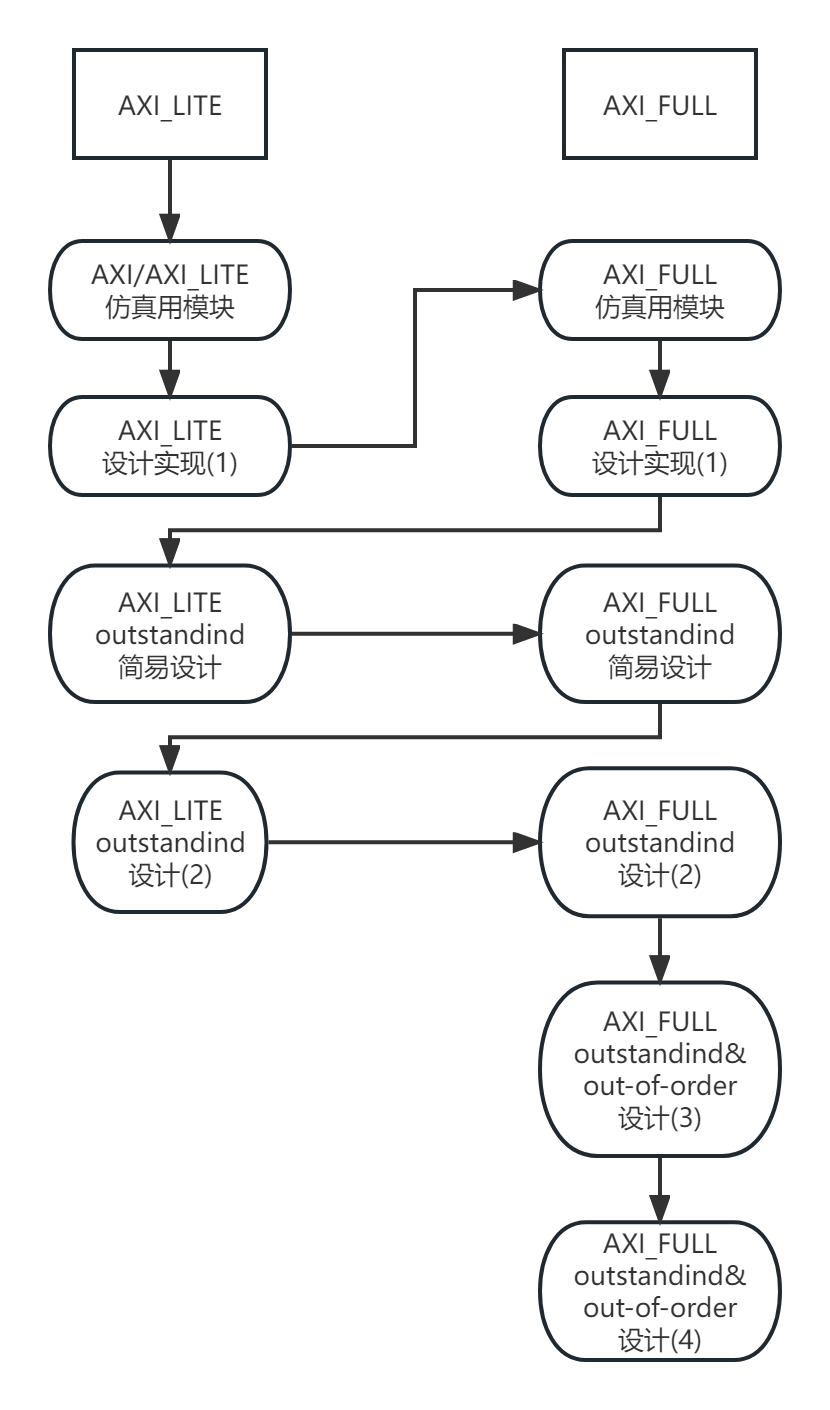
AXI实战(一)-为AXI总线搭建简单的仿真测试环境
AXI实战(一)-搭建简单仿真环境 看完在本文后,你将可能拥有: 一个可以仿真AXI/AXI_Lite总线的完美主端(Master)或从端(Slave)一个使用SystemVerilog仿真模块的船信体验小何的AXI实战系列开更了,以下是初定的大纲安排: 欢迎感兴趣的朋友关注并支持,以下为正文部分 文章目录…...
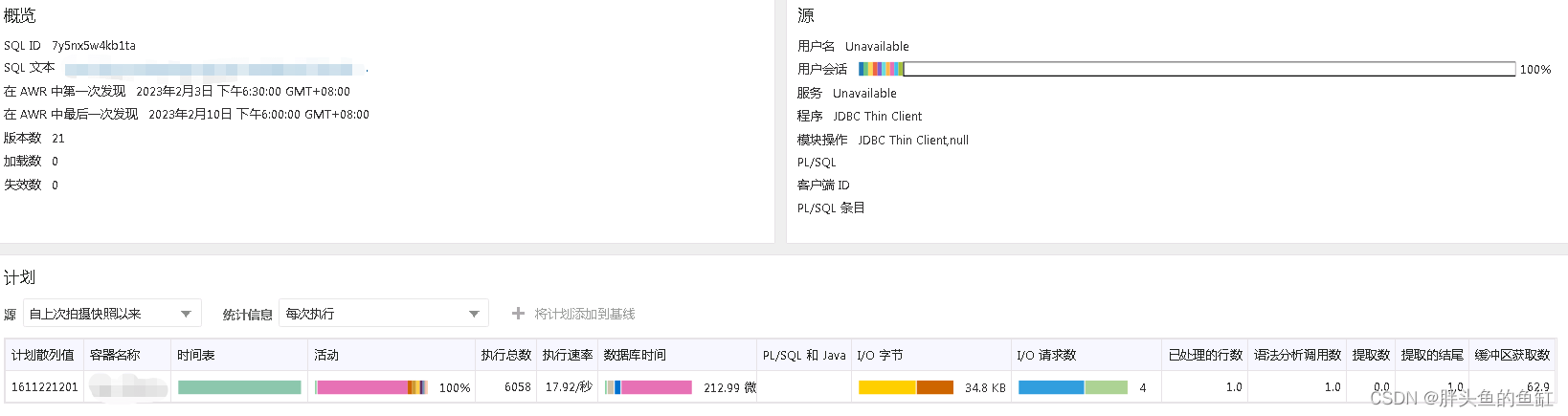
数据库管理-第五十六期 监控(20230210)
数据库管理 2023-02-10第五十六期 监控1 怎么监控2 直观3 历史分析4 另一个BUG总结第五十六期 监控 春节后的7天班过后就来到了2月份,本周对之前发现X8M上的那个bug进行补丁修复和协助从12.2迁移了一套PDB到这个一体机上面,2次割接。这周还和原厂老大哥…...
测试开发,测试架构师为什么能拿50 60k呢需要掌握哪些技能呢
这篇文章是软件工程系列知识总结的第五篇,同样我会以自己的理解来阐述软件工程中关于架构设计相关的知识。相比于我们常见的研发架构师,测试架构师是近几年才出现的一个岗位,当然岗位title其实没有特殊的含义,在我看来测试架构师其…...

Miniblink 入门
miniblink官网:入门之前强烈建议将Miniblink介绍仔细看一遍。 MB内核组件标准版接口文档:这里列举了所有的api以及简单的说明,但是本人建议还是看wke.h更方便,里面都是宏实现的,直接搜相关函数即可。 mb demo下载和参…...

产品兼容性实战:硬件与软件设计的平衡艺术与工程策略
1. 产品兼容性:一个永恒的工程与商业困境在硬件开发,尤其是数据采集、测试测量这类领域里,产品经理和工程师们几乎每天都在面对一个看似无解的难题:新产品的功能要向前狂奔,但老用户的兼容性需求却像一根锚,…...

为OpenClaw智能体工作流配置Taotoken作为稳定后端API
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为OpenClaw智能体工作流配置Taotoken作为稳定后端API OpenClaw是一个用于构建智能体工作流的流行框架,它允许开发者通过…...

Windows上的APK安装革命:如何用开源工具无缝运行安卓应用
Windows上的APK安装革命:如何用开源工具无缝运行安卓应用 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为Windows和安卓生态之间的鸿沟而烦恼吗&…...

学术人必抢的实时检索红利,Perplexity这4个隐藏功能90%研究者至今未启用,错过再等半年!
更多请点击: https://intelliparadigm.com 第一章:Perplexity实时学术搜索怎么用 Perplexity 是一款面向研究者与开发者设计的实时学术搜索引擎,其核心优势在于直接对接 arXiv、PubMed、ACL Anthology、Semantic Scholar 等权威学术数据库&a…...

2026年AI Agent工具淘汰预警:这7个已停止维护/降级为社区版/终止Python 3.12支持的工具请立即停用
更多请点击: https://kaifayun.com 第一章:2026年最佳AI Agent工具推荐 随着多模态推理、自主记忆与跨平台协同能力的成熟,2026年的AI Agent已从实验原型迈入生产级应用阶段。主流工具普遍支持RAG增强、动态工具调用(Tool Calli…...

FanControl深度解析:完全掌控Windows风扇转速的专业级工具
FanControl深度解析:完全掌控Windows风扇转速的专业级工具 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trendin…...

终极网盘直链下载助手完整指南:快速免费获取8大网盘真实下载地址
终极网盘直链下载助手完整指南:快速免费获取8大网盘真实下载地址 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云…...

告别WSL安装玄学:从0x80072f78到0x800701bc,一次搞懂Windows 11下的完整避坑指南
从0x80072f78到0x800701bc:Windows 11下WSL完整避坑手册 每次在Windows 11上安装WSL时,那些神秘的错误代码是否让你抓狂?0x80072f78、0x800701bc...它们像是一道道密码,阻挡着你进入Linux开发环境的大门。作为长期在Windows和Linu…...

争分夺秒与步步为营:Infoseek舆情系统如何重构危机响应的时间哲学
“黄金4小时”甚至“黄金1小时”,是公关行业奉行的铁律。然而,为了追求速度而仓促发出的声明,常常因为事实核查不清、逻辑存在漏洞或情感表达不当,引发更猛烈的“二次翻车”。这种“翻车”对企业公信力的伤害,往往比原…...

MCC-425 协议转换网关:打通制冷机组与 CAN 控制器数据链路
背景在工业精密温控领域,制冷机组的运行参数(如温度、压力、流量)直接决定了工艺流程的稳定性。为了实现生产现场的数字化管理,必须将分布在各工位的制冷机组数据实时汇聚至中控室,以便上位机进行统一监控与逻辑调度 。…...