网络层IP协议
目录
前言
1.如何理解IP协议
2.IP协议格式
3.网段划分
4.特殊的IP地址
5.IP地址的数量限制
6.私有IP地址和公网IP地址
7.路由
总结
前言
在前面的文章中介绍了关于传输层常用的两个协议,UDP协议和TCP协议,当数据经过传输层之后,进入网络层,在网络层中使用IP协议添加报头封装数据交付给下一层,下面我们就一起来具体看看IP协议是实现和使用的。
1.如何理解IP协议
IP协议是:将数据A跨网络送到B主机的能力
1.路径选择中,目标IP非常重要,决定了我们路径该如何走
2.IP =目标网络+目标主机.
如图所示:
假设数据从主机B到达主机C中间需要经过许多的路由器节点,每个路由器节点又是属于不同的局域网,所以IP协议的存在可以在中间路由的过程中准确选择出下一次要达到的目标网络,最终数据经过不断的路由最终达到主机C。

2.IP协议格式

IP协议标准头部长度20字节,4位首部长度基本单位是4字节[0000,1111] ->[0,15],规定每个字节*4即总长度60字节,因为标准头部20字节,所以标准4位首部长度填写0101。
16位总长度(total length): IP数据报整体占多少个字节,用来将报头和有效载荷进行分离
8位协议:标识上层协议的类型用来将数据向上交付
16位首部校验和:校验数据发送是否完整
8位生存时间:数据到达目的地的最大跳数,一般是64,每次经过一个路由,TTL-=1,一直减到0还没有到达就直接丢弃了,这个字段主要是用来防止出现路由循环
4位版本:指定IP协议的版本,一般是IPV4
8位服务类型表示的是数据在路由的时候以什么标准优先选择进行路由为什么存在16位标识,3位标志,13位片偏移?
数据在传输的过程中,是要经过数据链路层的,在数据链路层中MAC帧协议规定自己的有效载荷不能超过1500字节(MTU)
对于IP层来说,无法决定报文的大小,所以为了满足数据链路层协议的规定, IP对报文按照1 500字节的大小分片,到对端IP层再进行组装,所以上面字段存在的本质上是为了分片和组装
分片和组装存在的问题:
1.如何知道一个报文被分片了呢?
2.同-个报文的分片都能够被识别出来
3.哪个是第一个,哪个是最后一个,有没有收全,有没有秩
4.哪个在前,哪个在后,如何正确的组装?
5.如何保证合起来的报文是正确的?16位标识:如果IP报文因为数据链路层被分片了,那么每一个片里面的这个id都是相同的
3位标志字段:第一位保留(现在不用,不确定以后是否会使用),第二个位置为1标识禁止分片,这时候如果IP报文长度超过MTU,IP模块就会丢弃报文,第三个位置表示”更多分片”,如果分片了的话,最后一个分片位置置为0,它是1,类似于一个结束标志
13位分片偏移:分片相比于原始IP报文开始处的偏移,实就是在表示当前分片在原报文中处在哪个位置实际偏移的字节数是这个值*8得到的,因此,除了最后一个报文之外,其他报文的长度必须是8的整数倍(否则报文就不连续了)。第一个问题:
答案: a.如果更多分片是1,就证明该报文被分片了b.如果更多分片是0 &&片偏移>0说明是分片,否则不是!
第二个问题:
答案:根据16位标识,每个分片的id都是相同的
第三个问题:
答案: a.更多分片是1,片偏移是0 b.更多 分片是0 &&片偏移>0 c.当前的起始位置+自身的长度=下一个报文中填充的偏移大小
第四个问题:
答案:按照片偏移升序排序即可
第五个问题:
答案:因为TCP/IP有校验和
分片好吗?
答案:分片不好,增加了传输数据时,报文丢失重传的可能性!
对tcp/udp/ip本身有什么影响?
一个报文被拆成多个,任意一个报文分片丢失, 就会造成拼接组装失败,进而导致对端对整个报文进行重传!
3.网段划分
1.为什么会进行网段划分?
网段划分是通过不同的IP来进行划分为一个个不同的子网,划分出一个个的子网之后,数据在从A主机发送B主机的时候,能够更加快速的找到B主机
本质上:网段划分可以提高查找效率,每次在查询的时候都够排除一群主机
2.如何进行网段划分?
IP地址有32位,而IP地址是被运营商设计过的,每个不同的地区,会根据不同的条件划分为一个指定的IP,依次类推,从国际网络划分到个人主机
3.具体了解网段划分:
IP地址分为两个部分:网络号和主机号
网络号:保证相互连接的两个网段有不同的标识
主机号:同一网段内,主机之间具有相同的网络号,但是必须有不同的主机号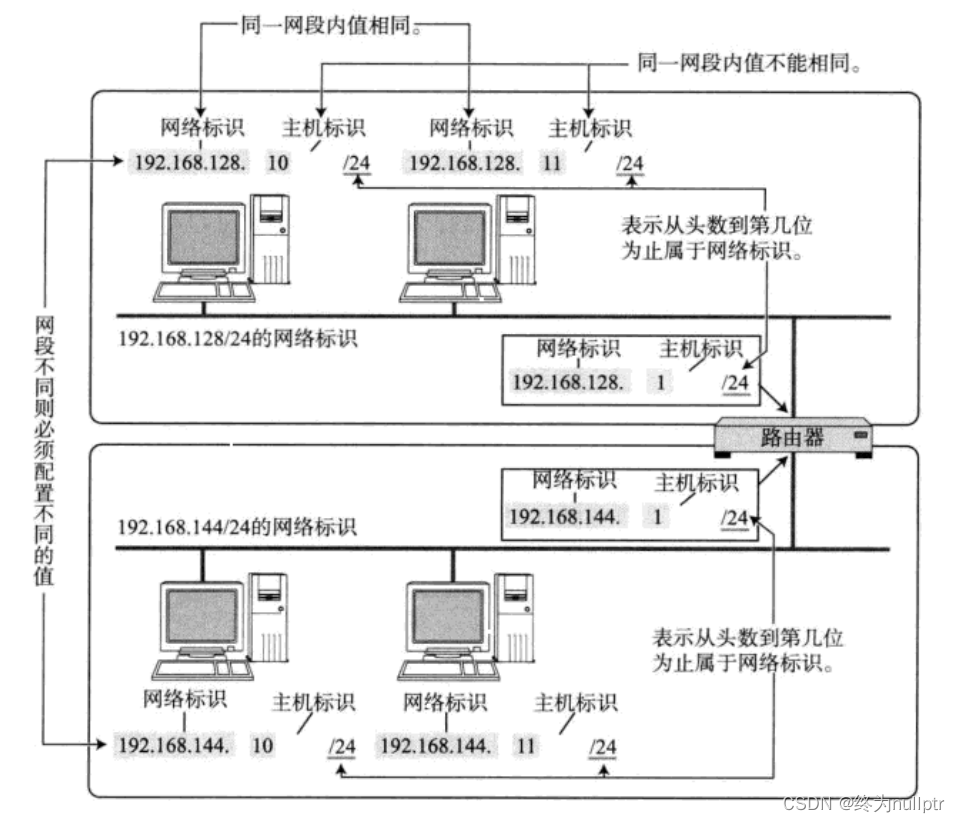
不同的子网其实就是把网络号相同的主机放到一起.
如果在子网中新增一台主机, 则这台主机的网络号和这个子网的网络号一致, 但是主机号必须不能和子网中的其他主机重复
通过合理设置主机号和网络号, 就可以保证在相互连接的网络中, 每台主机的IP地址都不相同.
那么问题来了, 手动管理子网内的IP, 是一个相当麻烦的事情.
有一种技术叫做DHCP, 能够自动的给子网内新增主机节点分配IP地址, 避免了手动管理IP的不便.
一般的路由器都带有DHCP功能. 因此路由器也可以看做一个DHCP服务器.
过去曾经提出一种划分网络号和主机号的方案, 把所有IP 地址分为五类, 如下图所示:
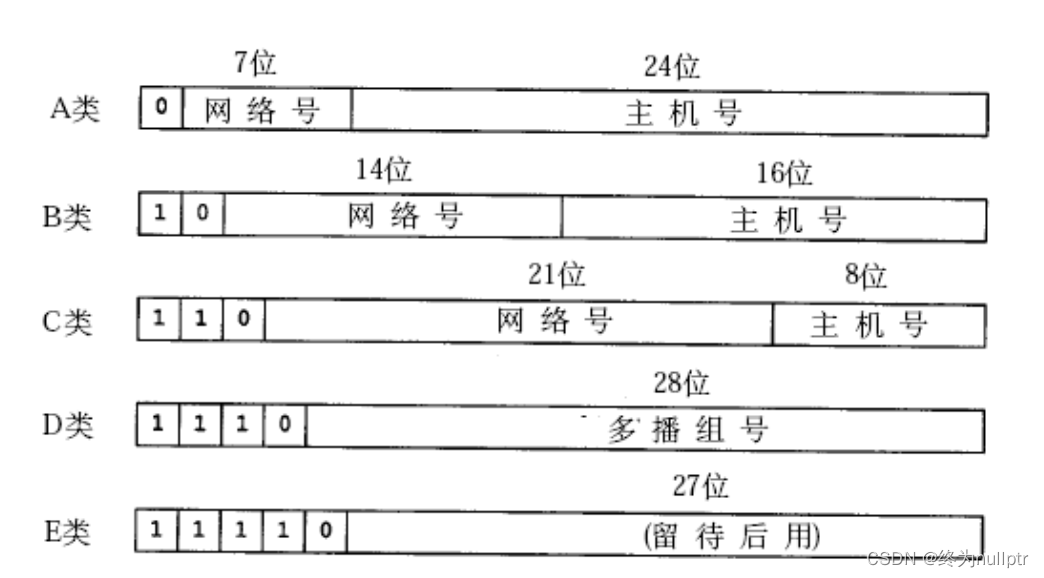
A类 0.0.0.0到127.255.255.255
B类 128.0.0.0到191.255.255.255
C类 192.0.0.0到223.255.255.255
D类 224.0.0.0到239.255.255.255
E类 240.0.0.0到247.255.255.255
随着Internet的飞速发展,这种划分方案的局限性很快显现出来,大多数组织都申请B类网络地址, 导致B类地址很快就分配完了, 而A类却浪费了大量地址;
例如, 申请了一个B类地址, 理论上一个子网内能允许6万5千多个主机. A类地址的子网内的主机数更多.
然而实际网络架设中, 不会存在一个子网内有这么多的情况. 因此大量的IP地址都被浪费掉了.
针对这种情况提出了新的划分方案, 称为CIDR(Classless Interdomain Routing):
引入一个额外的子网掩码(subnet mask)来区分网络号和主机号;
子网掩码也是一个32位的正整数. 通常用一串 "0" 来结尾;
将IP地址和子网掩码进行 "按位与" 操作, 得到的结果就是网络号;
网络号和主机号的划分与这个IP地址是A类、B类还是C类无关;

可见,IP地址与子网掩码做与运算可以得到网络号, 主机号从全0到全1就是子网的地址范围;
IP地址和子网掩码还有一种更简洁的表示方法,例如140.252.20.68/24,表示IP地址为140.252.20.68,子网掩码的高24位是1,也就是255.255.255.0
4.特殊的IP地址
将IP地址中的主机地址全部设为0, 就成为了网络号, 代表这个局域网;
将IP地址中的主机地址全部设为1, 就成为了广播地址, 用于给同一个链路中相互连接的所有主机发送数据包;
127.*的IP地址用于本机环回(loop back)测试,通常是127.0.0.1
5.IP地址的数量限制
我们知道, IP地址(IPv4)是一个4字节32位的正整数. 那么一共只有 2的32次方 个IP地址, 大概是43亿左右. 而TCP/IP协议规定, 每个主机都需要有一个IP地址.
这意味着, 一共只有43亿台主机能接入网络么?
实际上, 由于一些特殊的IP地址的存在, 数量远不足43亿; 另外IP地址并非是按照主机台数来配置的, 而是每一个网卡都需要配置一个或多个IP地址.
CIDR在一定程度上缓解了IP地址不够用的问题(提高了利用率, 减少了浪费, 但是IP地址的绝对上限并没有增加), 仍然不是很够用. 这时候有三种方式来解决:
动态分配IP地址: 只给接入网络的设备分配IP地址. 因此同一个MAC地址的设备, 每次接入互联网中, 得到的IP地址不一定是相同的;
NAT技术:在后面的文章中介绍
IPv6: IPv6并不是IPv4的简单升级版. 这是互不相干的两个协议, 彼此并不兼容; IPv6用16字节128位来表示一个IP地址; 但是目前IPv6还没有普及;
6.私有IP地址和公网IP地址
如果一个组织内部组建局域网,IP地址只用于局域网内的通信,而不直接连到Internet上,理论上使用任意的IP地址都可以,但是RFC 1918规定了用于组建局域网的私有IP地址
10.*,前8位是网络号,共16,777,216个地址
172.16.到172.31.,前12位是网络号,共1,048,576个地址
192.168.*,前16位是网络号,共65,536个地址
包含在这个范围中的, 都称为私有IP, 其余的则称为全局IP(或公网IP);
局域网和公网转发的流程:
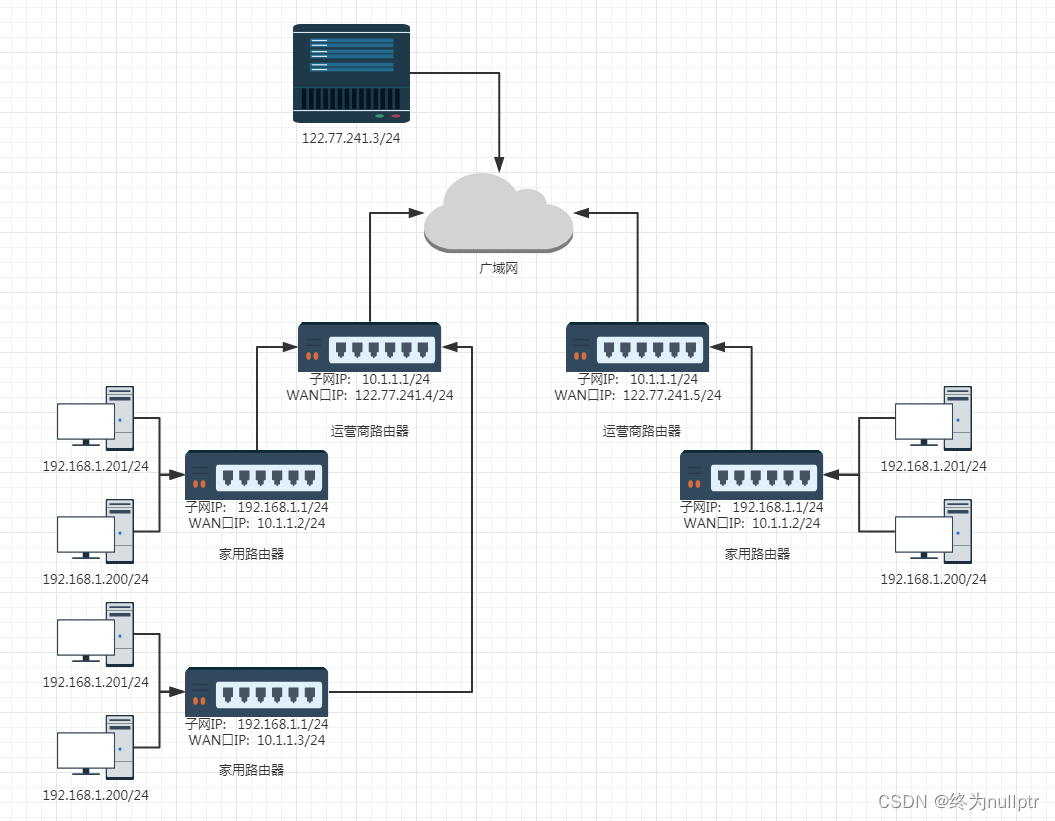
一个路由器可以配置两个IP地址: 一个是WAN口IP, 一个是LAN口IP
WAN口IP:对外
LAN口IP:对内
当局域网向公网转发数据的时候,局域网IP会被替换成WAN口IP,向上交付
当公网向局域网转发数据的时候,公网IP会被替换成L AN口IP,向下交付
不同的路由器,子网IP其实都是一样的, 子网内的主机IP地址不能重复,但是子网之间的IP地址可以重复了
7.路由
在复杂的网络结构中,找出一条通往终点的路线
路由的过程,就是一跳一跳“问路”的过程
如图所示:
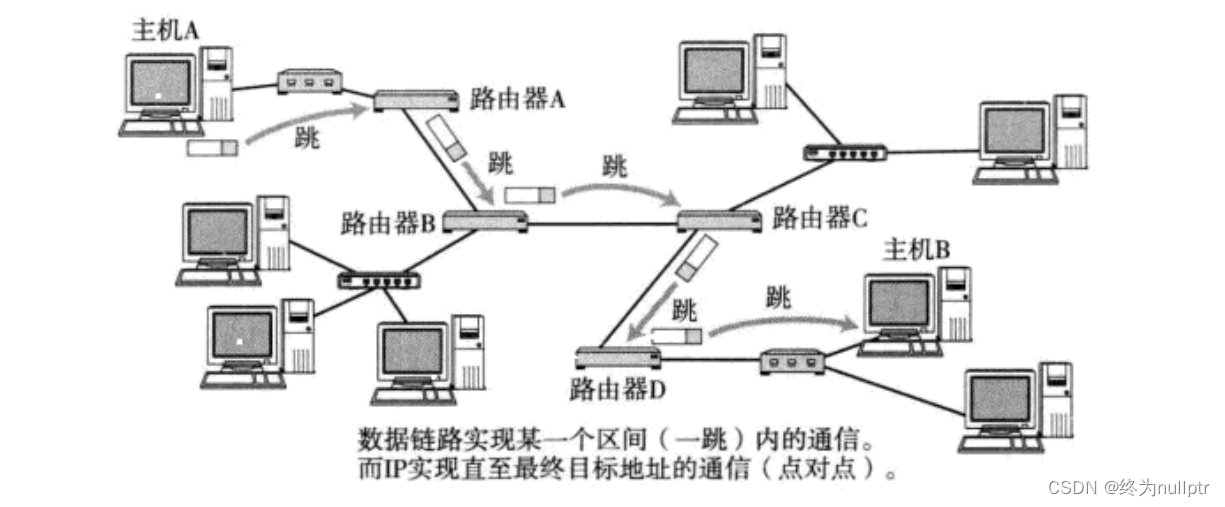
IP数据包的传输过程也和问路一样.
当IP数据包, 到达路由器时, 路由器会先查看目的IP;
路由器决定这个数据包是能直接发送给目标主机, 还是需要发送给下一个路由器;
依次反复, 一直到达目标IP地址;那么如何判定当前这个数据包该发送到哪里呢? 这个就依靠每个节点内部维护一个路由表;
路由表可以使用route命令查看
如果目的IP命中了路由表, 就直接转发即可;
路由表中的最后一行,主要由下一跳地址和发送接口两部分组成,当目的地址与路由表中其它行都不匹配时,就按缺省路由条目规定的接口发送到下一跳地址。
路由表:如图所示
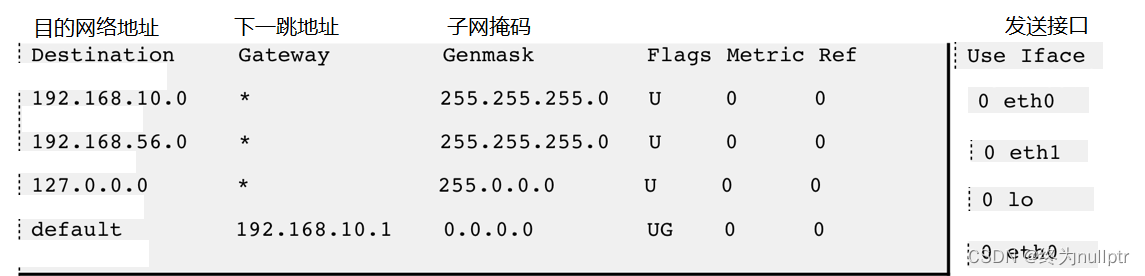
Flags中的U标志表示此条有效(可以禁用某些条目),G标志表示此条目的下一跳地址 是某个路由器的地址,没有G标志的条目表示目的网络地址是与本机接口直接相连的网络,不必经路由器转发;
转发过程:
1.遍历路由表
2.目的IP &路由表中配置的子网掩码,确定该报文要去的目标网络
3.对比结果和destination
4.通过Iface接口发出报文
转发过程例1: 如果要发送的数据包的目的地址是192.168.56.3
跟第一行的子网掩码做与运算得 到192.168.56.0,与第一行的目的网络地址不符
再跟第二行的子网掩码做与运算得 到192.168.56.0,正是第二行的目的网络地址,因此从eth1接口发送出去;
由于192.168.56.0/24正是与eth1接口直接相连的网络,因此可以直接发到目的主机,不需要经路由器转发;
转发过程例2: 如果要发送的数据包的目的地址是202.10.1.2
依次和路由表前几项进行对比, 发现都不匹配;
按缺省路由条目, 从eth0接口发出去, 发往192.168.10.1路由器;
由192.168.10.1路由器根据它的路由表决定下一跳地址;
总结
以上就是关于IP协议的所有内容,包含IP协议在实现网络数据传输过程的作用和IP协议报头格式字段以及IP地址的问题,感谢大家的阅读,希望对大家所有帮助,我们下次再见!
相关文章:
网络层IP协议
目录 前言 1.如何理解IP协议 2.IP协议格式 3.网段划分 4.特殊的IP地址 5.IP地址的数量限制 6.私有IP地址和公网IP地址 7.路由 总结 前言 在前面的文章中介绍了关于传输层常用的两个协议,UDP协议和TCP协议,当数据经过传输层之后,进入网…...
C++ Day4
目录 仿照string类,完成myString 类 思维导图 仿照string类,完成myString 类 #include <iostream> #include<cstring>using namespace std;class myString {private:char *str; //记录c风格的字符串int size; //记录…...
)
2024字节跳动校招面试真题汇总及其解答(二)
1. 微服务的好处,划分原则 微服务是软件架构的一种模式,它将应用程序划分为一系列小型、独立的服务。每个服务都提供一个单独的功能,并使用轻量级的接口相互通信。 微服务架构具有以下好处: 灵活性:微服务可以独立部署、扩展和更新,这使得它们能够随着业务需求的变化而…...
|(使用okhttp3实现websocket))
SpringBoot集成websocket(4)|(使用okhttp3实现websocket)
SpringBoot集成websocket(4)|(使用okhttp3实现websocket) 文章目录 SpringBoot集成websocket(4)|(使用okhttp3实现websocket)[TOC] 前言一、实现步骤1.实现步骤 二、websocket服务代…...
【MySQL】JDBC编程
MySQL-JDBC编程 文章目录 MySQL-JDBC编程Java的数据库编程JDBC工作原理JDBC的使用驱动包下载导入代码编写 Java的数据库编程 JDBC,即Java Database Connectivity,java数据库连接。是一种用于执行SQL语句的Java API,它是 Java中的数据库连接…...
数据结构——二叉树线索化遍历(前中后序遍历)
二叉树线索化 线索化概念: 为什么要转换为线索化 二叉树线索化是一种将普通二叉树转换为具有特殊线索(指向前驱和后继节点)的二叉树的过程。这种线索化的目的是为了提高对二叉树的遍历效率,特别是在不使用递归或栈的情况下进行遍历…...
GO语言网络编程(并发编程)Channel
GO语言网络编程(并发编程)Channel 1、Channel 1.1.1 Channel 单纯地将函数并发执行是没有意义的。函数与函数间需要交换数据才能体现并发执行函数的意义。 虽然可以使用共享内存进行数据交换,但是共享内存在不同的goroutine中容易发生竞态…...

c++day3
stack.h #ifndef STACK_H #define STACK_H #include <iostream> //#define max 128 using namespace std; class Stack { private:int* stack;//数组指针int top;//栈顶元素int max;//栈容量 public://构造函数Stack();//析构函数~Stack();//定义拷贝构造函数Stack(cons…...
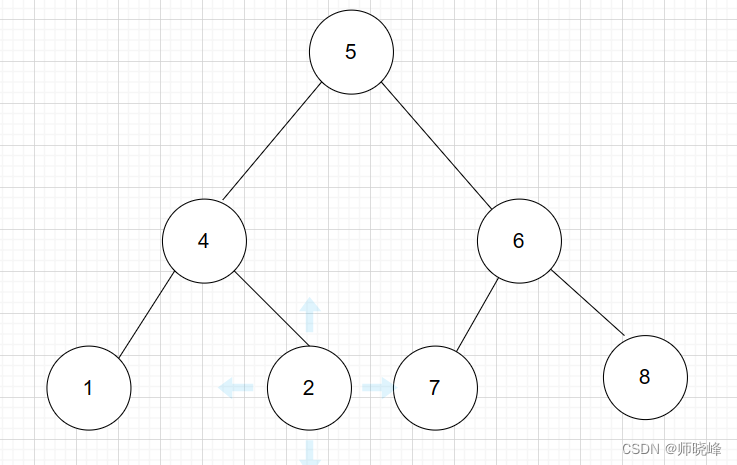
算法通过村第六关-树青铜笔记|中序后序
文章目录 前言1. 树的常见概念2. 树的性质3. 树的定义与存储方式4. 树的遍历方式5. 通过序列构建二叉树5.1 前中序列恢复二叉树5.2 中后序列恢复二叉树 总结 前言 提示:瑞秋是个小甜心,她只喜欢被爱,不懂的去爱人。 --几米《你们 我们 他们》…...

C++动态内存管理+模板
💓博主个人主页:不是笨小孩👀 ⏩专栏分类:数据结构与算法👀 C👀 刷题专栏👀 C语言👀 🚚代码仓库:笨小孩的代码库👀 ⏩社区:不是笨小孩👀 🌹欢迎大…...
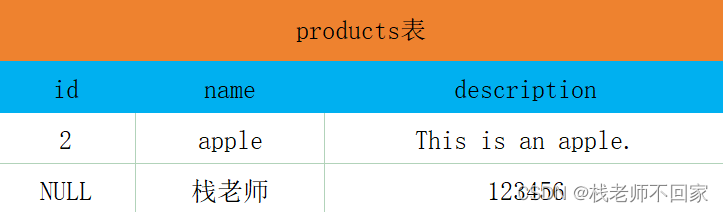
SQL 注入漏洞攻击
文章目录 1. 介绍2. 无密码登录3. 无用户名无密码登录4. 合并表获取用户名密码 1. 介绍 假设你用自己的用户名和密码登录了一个付费网站,网站服务器就会查询一下你是不是 VIP 用户,而用户数据都是放在数据库中的,服务器通常都会向数据库进行查…...

一篇五分生信临床模型预测文章代码复现——Figure 10.机制及肿瘤免疫浸润(四)
之前讲过临床模型预测的专栏,但那只是基础版本,下面我们以自噬相关基因为例子,模仿一篇五分文章,将图和代码复现出来,学会本专栏课程,可以具备发一篇五分左右文章的水平: 本专栏目录如下: Figure 1:差异表达基因及预后基因筛选(图片仅供参考) Figure 2. 生存分析,…...
Transformer 模型中常见的特殊符号
Transformer 模型中常见的特殊符号 通过代码一起理解一下 Transformer 模型中常见的特殊符号, 示例代码, special_tokens{unk_token: [UNK], sep_token: [SEP], pad_token: [PAD], cls_token: [CLS], mask_token: [MASK]}这段代码是定义了一个字典spec…...

C# halcon SubImage的使用
SubImage(HObject imageMinuend, HObject imageSubtrahend, out HObject imageSub, HTuple mult, HTuple add) 公式 x1imageMinuend此行此列的灰度 x2imageSubtrahend此行此列的灰度 则imageSub此行此列的灰度为;(x1-x2)*multadd 溢出裁剪 以byte图为例,小于0&a…...
)
每天几道Java面试题:异常机制(第三天)
目录 第三幕、第一场)异常机制面试题 友情提醒 背面试题很枯燥,加入一些戏剧场景故事人物来加深记忆。PS:点击文章目录可直接跳转到文章指定位置。 第三幕、 第一场)异常机制面试题 【面试官老吉,面试官潘安,面试者…...

Linux 中的 chattr 命令及示例
Linux 中的chattr命令是一个文件系统命令,用于更改目录中文件的属性。该命令的主要用途是使多个文件无法被超级用户以外的用户更改。管理员表示,众所周知,Linux 是一个多用户操作系统,一个用户有可能删除另一个用户非常关心的文件。为了避免这种情况,Linux 提供了“ chatt…...

LeetCode 2605. Form Smallest Number From Two Digit Arrays【数组,哈希表,枚举;位运算】1241
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...

VoxWeekly|The Sandbox 生态周报|20230904
欢迎来到由 The Sandbox 发布的《VoxWeekly》。我们会在每周发布,对上一周 The Sandbox 生态系统所发生的事情进行总结。 如果你喜欢我们内容,欢迎与朋友和家人分享。请订阅我们的 Medium 、关注我们的 Twitter,并加入 Discord 社区…...

antd setFieldsValue 设置初始值无效AutoComplete 设置默认值失败
antd form setFieldsValue 设置初始值无效 解决方案 setTimeout(()>{setFieldsValue(values)},100)antd AutoComplete 设置默认值失败 defaultValue 设置无效 解决方案 设置value,搭配onChange来设置修改...

01-Redis核心数据结构与高性能原理
上一篇: 1.Redis安装 下载地址:http://redis.io/download 安装步骤: # 安装gcc yum install gcc# 把下载好的redis-5.0.3.tar.gz放在/usr/local文件夹下,并解压 wget http://download.redis.io/releases/redis-5.0.3.tar.gz…...

LLamaSharp实战指南:在.NET应用中本地部署与集成大语言模型
1. 项目概述:LLamaSharp,一个让大语言模型在本地跑起来的C#利器 如果你是一名C#或.NET开发者,最近肯定被ChatGPT和各种大语言模型(LLM)刷屏了。但你是否想过,不依赖OpenAI的API,不担心网络延迟…...

构建本地AI编码助手分析工具:数据监控与可视化实践
1. 项目概述:一个本地优先的AI编码助手分析工具如果你和我一样,日常开发重度依赖Cursor、Windsurf、Zed这些内置了AI能力的编辑器,或者频繁使用GitHub Copilot、Claude Code这类AI编码助手,那你肯定有过这样的困惑:这些…...

Windows右键菜单为何变得臃肿?ContextMenuManager帮你重新掌控
Windows右键菜单为何变得臃肿?ContextMenuManager帮你重新掌控 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 你是否曾为Windows右键菜单的混乱而烦…...

工业缺陷检测实战:用‘非均衡’数据增强搞定样本不足与类别不平衡难题
工业缺陷检测实战:破解样本不足与类别失衡的数据增强策略 在半导体、汽车零部件等精密制造领域,一个肉眼难辨的微小缺陷可能导致整批产品报废。传统人工质检不仅效率低下,且漏检率常高达15%-30%。当我们尝试用深度学习构建缺陷检测系统时&…...

移动端优化awesome-stock-resources:响应式素材适配终极指南
移动端优化awesome-stock-resources:响应式素材适配终极指南 【免费下载链接】awesome-stock-resources :city_sunrise: A collection of links for free stock photography, video and Illustration websites 项目地址: https://gitcode.com/gh_mirrors/aw/aweso…...

小熊猫Dev-C++:零配置C/C++开发环境的终极指南
小熊猫Dev-C:零配置C/C开发环境的终极指南 【免费下载链接】Dev-CPP A greatly improved Dev-Cpp 项目地址: https://gitcode.com/gh_mirrors/dev/Dev-CPP 小熊猫Dev-C(Red Panda Dev-C)是一款专为C/C开发者设计的现代化集成开发环境&…...
:团雾识别+车流量统计全流程落地)
【YOLO26实战全攻略】20——智慧交通(二):团雾识别+车流量统计全流程落地
摘要:团雾作为高速公路"流动杀手",常导致能见度骤降、事故频发,而传统监测手段响应滞后、统计粗放;车流量数据则是交通管控的核心依据,但精细化分类统计一直是行业痛点。本文基于YOLO26的边缘友好特性,结合FAENet特征增强网络与ByteTrack跟踪算法,打造了一套&…...

CMS三十年:从“手工建站”到“智能基座”
一个从业者的观察与思考不知不觉,跟CMS打交道已经十几年了。从早期的织梦、帝国,到后来的WordPress,再到现在的各类无头CMS和低代码平台,这个领域的变化比想象中要快得多。写这篇文章,算是对CMS发展历程的一次梳理&…...

告别AT指令恐惧症:用ESP-01S和51单片机,5分钟搞定手机远程开关灯
从零到一的智能家居初体验:ESP-01S与51单片机极简联动方案 第一次接触物联网硬件开发时,那些密密麻麻的AT指令确实容易让人望而生畏。但当我真正用ESP-01S模块配合最基础的51单片机,在五分钟内实现了手机远程开关LED灯的那一刻,所…...

计算机视觉十年演进:从手工特征到工业落地实战
1. 计算机视觉的十年跃迁:从手工特征到端到端理解2012年,AlexNet在ImageNet大赛上以15.3%的错误率碾压第二名10.8个百分点,整个计算机视觉领域像被按下了快进键。那会儿我在实验室调试SIFT特征匹配,光是调一个尺度参数就要跑三小时…...