使用Langchain+GPT+向量数据库chromadb 来创建文档对话机器人
使用Langchain+GPT+向量数据库chromadb 来创建文档对话机器人
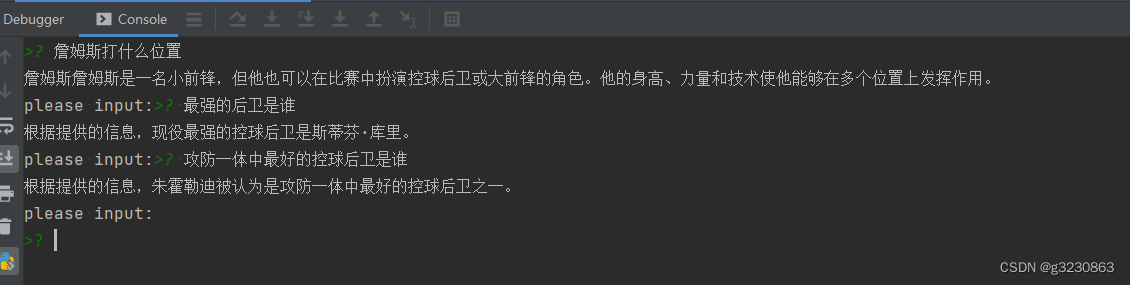
一.效果图如下:
二.安装包
pip install langchainpip install chromadbpip install unstructuredpip install jieba
三.代码如下
#!/usr/bin/python
# -*- coding: UTF-8 -*-import os # 导入os模块,用于操作系统相关的操作import chromadb
import jieba as jb # 导入结巴分词库
from langchain.chains import ConversationalRetrievalChain # 导入用于创建对话检索链的类
from langchain.chat_models import ChatOpenAI # 导入用于创建ChatOpenAI对象的类
from langchain.document_loaders import DirectoryLoader # 导入用于加载文件的类
from langchain.embeddings import OpenAIEmbeddings # 导入用于创建词向量嵌入的类
from langchain.text_splitter import TokenTextSplitter # 导入用于分割文档的类
from langchain.vectorstores import Chroma # 导入用于创建向量数据库的类import os
os.environ["OPENAI_API_KEY"] = 'xxxxxx'# 初始化函数,用于处理输入的文档
def init():files = ['2023NBA.txt'] # 需要处理的文件列表cur_dir = '/'.join(os.path.abspath(__file__).split('/')[:-1])for file in files: # 遍历每个文件data_path = os.path.join(cur_dir, f'data/{file}')with open(data_path, 'r', encoding='utf-8') as f: # 以读模式打开文件data = f.read() # 读取文件内容cut_data = " ".join([w for w in list(jb.cut(data))]) # 对读取的文件内容进行分词处理cut_file =os.path.join(cur_dir, f"data/cut/cut_{file}")with open(cut_file, 'w',encoding='utf-8') as f: # 以写模式打开文件f.write(cut_data) # 将处理后的内容写入文件# 新建一个函数用于加载文档
def load_documents(directory):# 创建DirectoryLoader对象,用于加载指定文件夹内的所有.txt文件loader = DirectoryLoader(directory, glob='**/*.txt')docs = loader.load() # 加载文件return docs # 返回加载的文档# 新建一个函数用于分割文档
def split_documents(docs):# 创建TokenTextSplitter对象,用于分割文档text_splitter = TokenTextSplitter(chunk_size=1000, chunk_overlap=0)docs_texts = text_splitter.split_documents(docs) # 分割加载的文本return docs_texts # 返回分割后的文本# 新建一个函数用于创建词嵌入
def create_embeddings(api_key):# 创建OpenAIEmbeddings对象,用于获取OpenAI的词向量embeddings = OpenAIEmbeddings(openai_api_key=api_key)return embeddings # 返回创建的词嵌入# 新建一个函数用于创建向量数据库
def create_chroma(docs_texts, embeddings, persist_directory):new_client = chromadb.EphemeralClient()vectordb = Chroma.from_documents(docs_texts, embeddings, client=new_client, collection_name="openai_collection")return vectordb # 返回创建的向量数据库# load函数,调用上面定义的具有各个职责的函数 pip install unstructured
def load():docs = load_documents('data/cut') # 调用load_documents函数加载文档docs_texts = split_documents(docs) # 调用split_documents函数分割文档api_key = os.environ.get('OPENAI_API_KEY') # 从环境变量中获取OpenAI的API密钥embeddings = create_embeddings(api_key) # 调用create_embeddings函数创建词嵌入# 调用create_chroma函数创建向量数据库vectordb = create_chroma(docs_texts, embeddings, 'data/cut/')# 创建ChatOpenAI对象,用于进行聊天对话openai_ojb = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")# 从模型和向量检索器创建ConversationalRetrievalChain对象chain = ConversationalRetrievalChain.from_llm(openai_ojb, vectordb.as_retriever())return chain # 返回该对象init()
# 调用load函数,获取ConversationalRetrievalChain对象
# pip install chromadb
# pip install unstructured
# pip install jieba
chain = load()# 定义一个函数,根据输入的问题获取答案
def get_ans(question):chat_history = [] # 初始化聊天历史为空列表result = chain({ # 调用chain对象获取聊天结果'chat_history': chat_history, # 传入聊天历史'question': question, # 传入问题})return result['answer'] # 返回获取的答案if __name__ == '__main__': # 如果此脚本作为主程序运行s = input('please input:') # 获取用户输入while s != 'exit': # 如果用户输入的不是'exit'ans = get_ans(s) # 调用get_ans函数获取答案print(ans) # 打印答案s = input('please input:') # 获取用户输入
文件存放地址

参考:
https://python.langchain.com/docs/integrations/vectorstores/chroma
https://blog.csdn.net/v_JULY_v/article/details/131552592?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522169450205816800226590967%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=169450205816800226590967&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_positive~default-1-131552592-null-null.142v93chatsearchT3_2&utm_term=langchain&spm=1018.2226.3001.4449
相关文章:
使用Langchain+GPT+向量数据库chromadb 来创建文档对话机器人
使用LangchainGPT向量数据库chromadb 来创建文档对话机器人 一.效果图如下: 二.安装包 pip install langchainpip install chromadbpip install unstructuredpip install jieba三.代码如下 #!/usr/bin/python # -*- coding: UTF-8 -*-import os # 导入os模块&…...
系列教程(一) 服务注册与发现(eureka))
Spring Cloud(Finchley版本)系列教程(一) 服务注册与发现(eureka)
Spring Cloud(Finchley版本)系列教程(一) 服务注册与发现(eureka) 为了更好的浏览体验,欢迎光顾勤奋的凯尔森同学个人博客http://www.huerpu.cc:7000 如有错误恳请大家批评指正,与大家共同学习、一起成长,万分感谢。 一、构建环境 Spring Cloud的构建工具可以使用Maven或Gr…...

【大数据】美团 DB 数据同步到数据仓库的架构与实践
美团 DB 数据同步到数据仓库的架构与实践 1.背景2.整体架构3.Binlog 实时采集4.离线还原 MySQL 数据5.Kafka2Hive6.对 Camus 的二次开发7.Checkdone 的检测逻辑8.Merge9.Merge 流程举例10.实践一:分库分表的支持11.实践二:删除事件的支持12.总结与展望 1…...
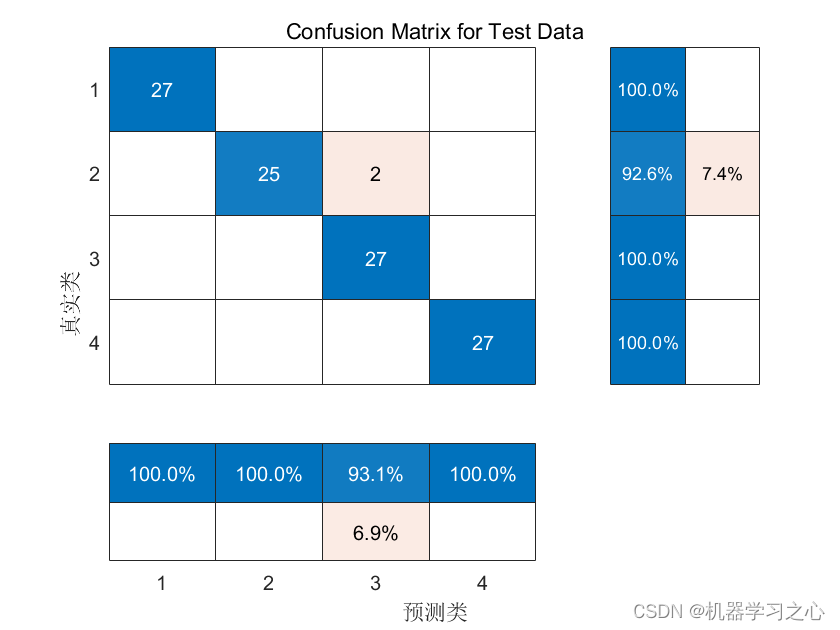
分类预测 | MATLAB实现WOA-CNN-BiGRU鲸鱼算法优化卷积双向门控循环单元数据分类预测
分类预测 | MATLAB实现WOA-CNN-BiGRU鲸鱼算法优化卷积双向门控循环单元数据分类预测 目录 分类预测 | MATLAB实现WOA-CNN-BiGRU鲸鱼算法优化卷积双向门控循环单元数据分类预测分类效果基本描述模型描述程序设计参考资料 分类效果 基本描述 1.Matlab实现WOA-CNN-BiGRU多特征分类…...
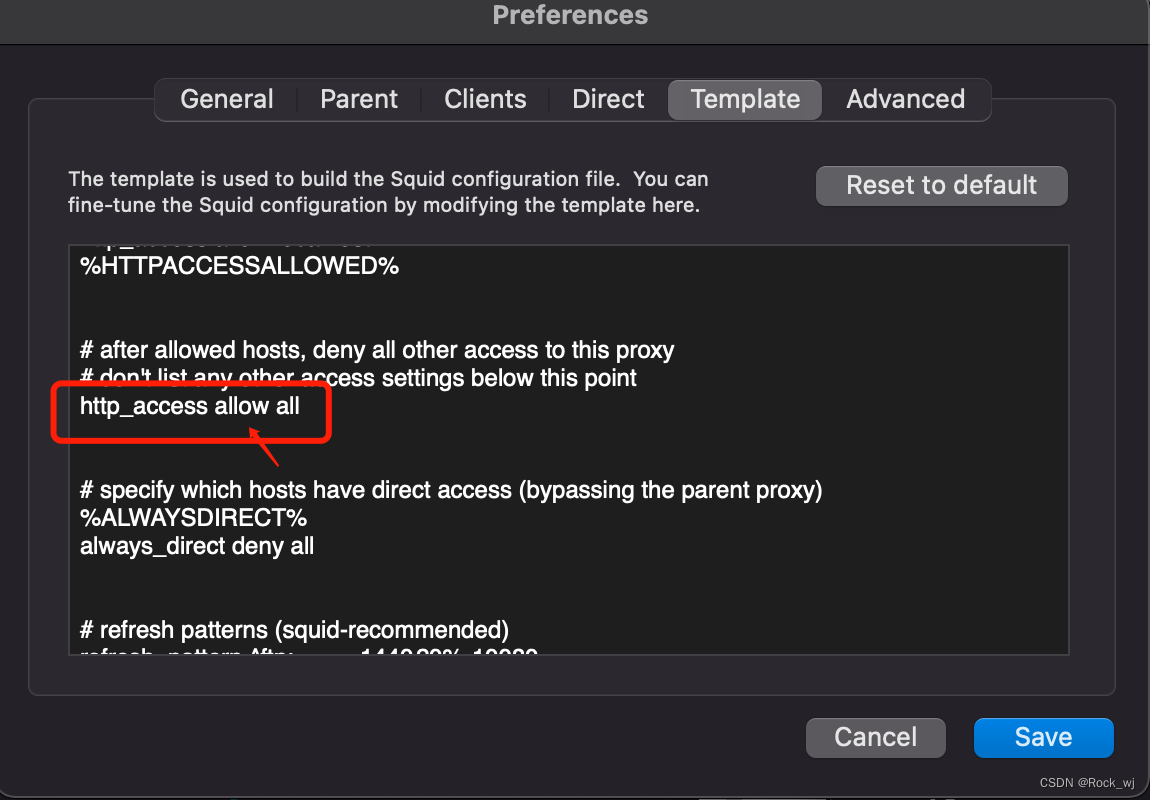
mac使用squidMan设置代理服务器
1,下载squidMan http://squidman.net/squidman/ 2, 配置SquidMan->Preference 3, mac命令窗口配置 export http_proxy export https_porxy 4,客户端配置(centos虚拟机) export http_proxyhttp://服务器ip:8080 export https…...

大数据Flink(七十八):SQL 的水印操作(Watermark)
文章目录 SQL 的水印操作(Watermark) 一、为什么要有 WaterMark...
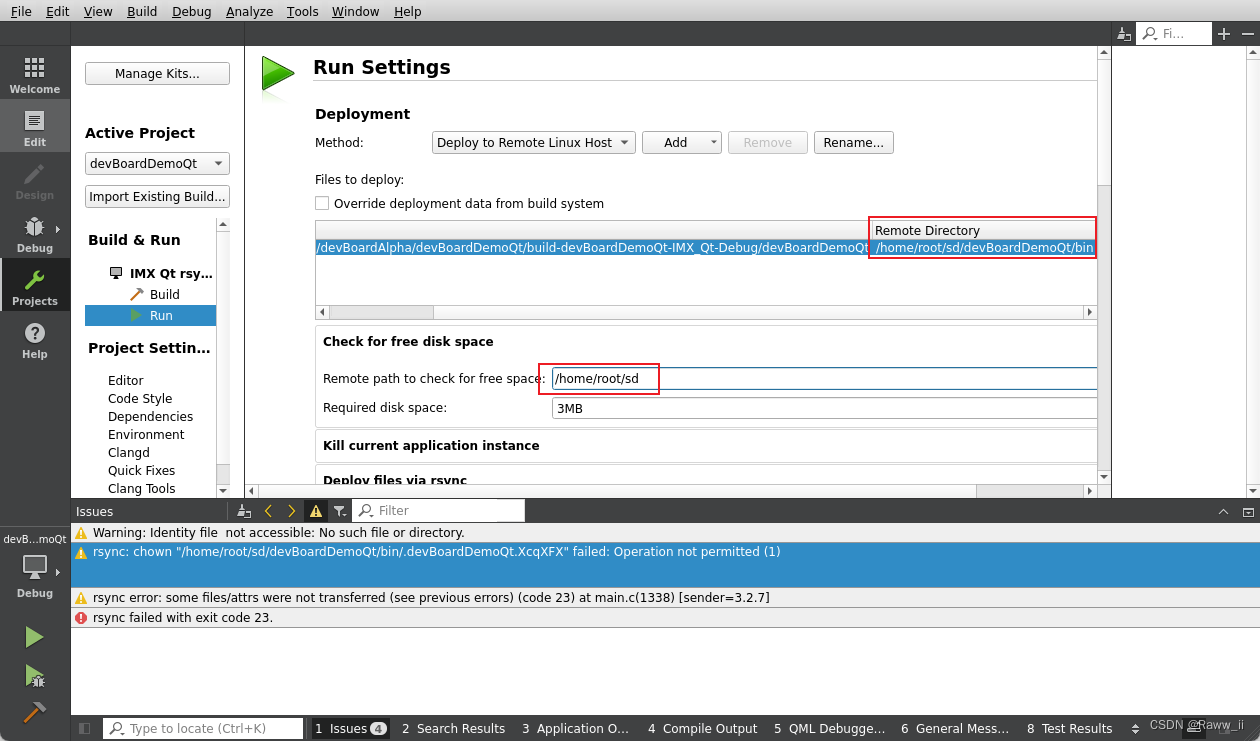
【Linux】Qt Remote之Remote开发环境搭建填坑小记
总体思路 基于WSL2(Ubuntu 22.04 LTS)原子Alpha开发板进行Qt开发实验,基于Win11通过vscode remote到WSL2,再基于WSL2通过Qt 交叉编译,并通过sshrsync远程到开发板,构建起开发工具链。 Step1 基于Win11通过…...

ATFX汇市:离岸人民币大幅升值,昨日盘中跌破7.3关口
ATFX汇市:美国CPI数据即将公布之际,周一美元指数大跌,带动离岸人民币升值0.85%,实现3月14日以来的最大单日升值幅度,当日汇率(USDCNH)最低触及7.292,突破7.3000关口。消息面上&#…...

Spring Boot 配置 Knife4j
一、引入 maven <!-- 引入 knife4j 文档--> <dependency> <groupId>com.github.xiaoymin</groupId> <artifactId>knife4j-openapi2-spring-boot-starter</artifactId> <version>4.1.0</version> </dependency>二…...

Java项目中遇到uv坐标如何转换成经纬度坐标
将UV坐标(通常指平面坐标,如二维地图坐标)转换为经纬度坐标(地理坐标)通常需要知道一个参考点的经纬度坐标,以及两者之间的比例关系。这是因为UV坐标通常用于在地图上绘制图形或标记点,而经纬度…...

std : : unordered_map 、 std : : unordered_set
一.简介 std::unordered_map 是C标准库中的一种关联容器,它提供了一种用于存储键-值对的数据结构,其中键是唯一的,且不会按特定顺序排序。与 std::map 不同,std::unordered_map 使用哈希表作为其底层数据结构,因此它具…...

Python解释器和Pycharm的傻瓜式安装部署
给我家憨憨写的python教程 有惊喜等你找噢 ——雁丘 Python解释器Pycharm的安装部署 关于本专栏一 Python解释器1.1 使用命令提示符编写Python程序1.2 用记事本编写Python程序 二 Pycharm的安装三 Pycharm的部署四 Pycharm基础使用技巧4.1 修改主题颜色4.2 修改字体4.3 快速修…...

14 Python使用网络
概述 在上一节,我们介绍了如何在Python中使用Json,包括:Json序列化、Json反序列化、读Json文件、写Json文件、将类对象转换为Json、将Json转换为类对象等内容。在这一节,我们将介绍如何在Python中使用网络。Python网络编程覆盖的范…...

AI ChatGPT 各大开放平台一览 大模型 Prompt
AI ChatGPT 各大开放平台一览 大模型 Prompt 国内 百度 ERNIE Bot 文心一言阿里巴巴 通义千问腾讯 Hunyuan BOT 混元 (暂未发布)华为 盘古旷视 ChatSpot科大讯飞 讯飞星火网易 子曰(暂未发布)京东 言犀奇安信 Q-GPT商汤科技 商量S…...

全球汽车安全气囊芯片总体规模分析
安全气囊系统是一种被动安全性的保护系统,它与座椅安全带配合使用,可以为乘员提供有效的防撞保护。在汽车相撞时,汽车安全气囊可使头部受伤率减少25%,面部受伤率减少80%左右。 汽车安全气囊芯片是整个系统的控制核心,并…...
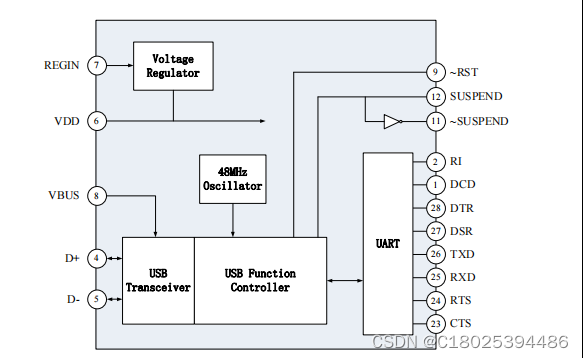
USB适配器应用芯片 国产GP232RL软硬件兼容替代FT232RL DPU02直接替代CP2102
USB适配器,是英文Universal Serial Bus(通用串行总线)的缩写,而其中文简称为“通串线”,是一个外部总线标准,用于规范电脑与外部设备的连接和通讯。是应用在PC领域的接口技术, 移动PC由于没有电池,电源适配…...

卫星物联网生态建设全面加速,如何抓住机遇?
当前,卫星通信无疑是行业最热门的话题之一。近期发布的华为Mate 60 Pro“向上捅破天”技术再次升级,成为全球首款支持卫星通话的大众智能手机,支持拨打和接听卫星电话,还可自由编辑卫星消息。 据悉,华为手机的卫星通话…...
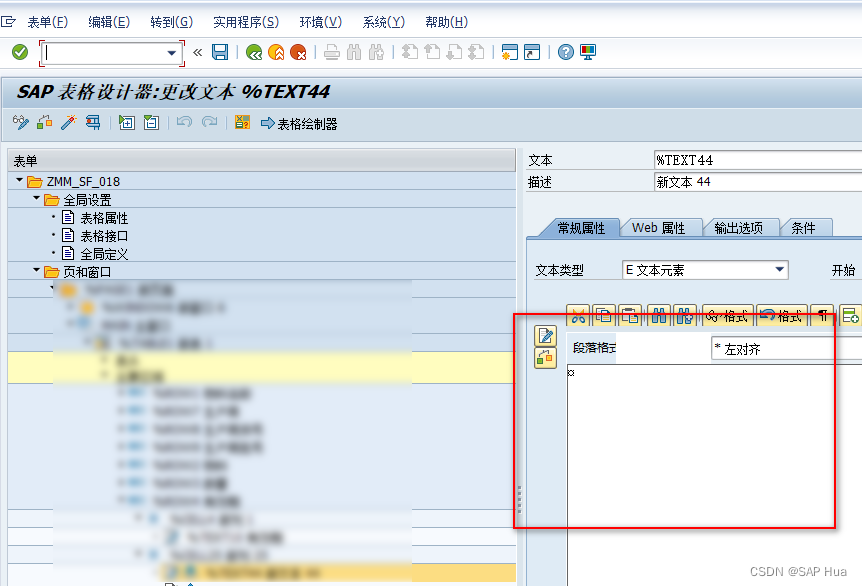
SAP GUI 8.0 SMARTFORMS 使用SCR LEGACY TEXT EDITOR GUI8.00 禁用MSWORD
Smartforms使用WORD作为编辑器是很痛苦的一个事情,不支持拖拽,还很慢,各种不习惯,总之是非常的不舒服,能导致失眠。 在S/4以前的系统,可以使用TCODE I18N或者程序RSCPSETEDITOR或者暴力党直接改表TCP0I来…...
【SpringMVC】JSR303与拦截器的使用
文章目录 一、JSR3031.1 JSR303是什么1.2 JSR 303的好处包括1.3 常用注解1.4 实例1.4.1 导入JSR303依赖1.4.2 规则配置1.4.3 编写校验方法1.4.4 编写前端 二、拦截器2.1 拦截器是什么2.2 拦截器与过滤器的区别2.3.应用场景2.4 快速入门2.5.拦截器链2.6 登录拦截权限案例2.6.1 L…...
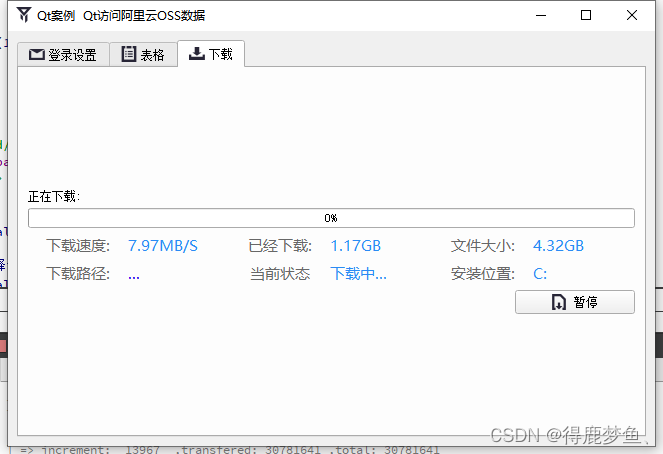
Qt案例-编译阿里云OSS对象存储C++ SDK源码,并进行简单下载,上传数据,显示进度等相关功能
项目中用到了阿里云OSS对象存储来保存数据,由于以前没用过这个库,就下载了C版的sdk源码重新编译了一次,并使用Qt调用;不得不说这可能是我编译源码最轻松的一次。 目录标题 简述OSS图形化管理工具编译源码Qt 添加引用常用 Endpoint…...

开源项目本地化实战:从Presentify翻译项目看国际化协作
1. 项目概述:一个被忽视的开源宝藏如果你是一个经常需要做演示、录屏或者线上教学的开发者、讲师或者知识分享者,那你一定遇到过这个痛点:如何在屏幕上清晰地标注你的鼠标点击、按键操作,让观众能毫不费力地跟上你的思路ÿ…...

ElevenLabs账号被限频?紧急修复手册:3分钟绕过Rate Limit限制,解锁Pro级语音并发权限
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs超写实语音生成教程 ElevenLabs 是当前业界领先的 AI 语音合成平台,其模型在语调自然度、情感表达力与跨语言一致性方面表现卓越。本章将指导你完成从 API 接入到高质量语音生成的…...

告别重复点击!淘金币自动化脚本让你每天多出20分钟自由时间
告别重复点击!淘金币自动化脚本让你每天多出20分钟自由时间 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojinbi …...

浏览器运行Cursor AI编辑器:Docker+KasmVNC部署全攻略
1. 项目概述:在浏览器中运行 Cursor AI 编辑器如果你是一名开发者,大概率听说过或者正在使用 Cursor——这款集成了强大 AI 辅助编程能力的编辑器。它基于 VS Code,但深度整合了类似 ChatGPT 的对话和代码生成功能,能极大提升编码…...

LVGL列表控件实战:5分钟搞定一个带图标和事件响应的菜单界面
LVGL列表控件实战:5分钟打造高交互性嵌入式菜单界面 在嵌入式设备的人机交互设计中,菜单界面是最基础也最关键的组件之一。想象一下,当你需要为智能家居控制面板设计一个简洁明了的操作菜单,或者为工业设备开发一个功能选择界面时…...
)
UWB-IMU、UWB定位对比研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

CanFestival回调函数避坑指南:为什么你的RPDO参数修改了却没生效?
CanFestival回调函数深度解析:RPDO参数修改失效的五大隐蔽原因与实战解决方案 在工业自动化领域,CanFestival作为开源的CANopen协议栈,被广泛应用于各类嵌入式设备中。然而,许多开发者在配置RPDO(接收过程数据对象&…...

抖音下载器底层架构解析:策略模式与异步编排的高性能实现
抖音下载器底层架构解析:策略模式与异步编排的高性能实现 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...

出境游网络解决方案大揭秘:eSIM 与非 eSIM 谁更胜一筹?
海外 eSIM 怎么买?线上直接下单就行最近几年,出境游再度火热起来。每次出发前,搞定酒店和大交通后,还得买手机卡。理论上,可带三大运营商的卡出境并开国际漫游,但买当地号卡和套餐更划算。去年 iPhone Air …...

【DeepSeek开发者垂直搜索实战指南】:3大行业落地案例+5个避坑要点,限时公开内部调优参数
更多请点击: https://intelliparadigm.com 第一章:DeepSeek开发者垂直搜索应用案例全景概览 DeepSeek系列大模型凭借其开源、高性能与强推理能力,正被广泛集成至开发者垂直搜索场景中——从代码片段检索、API文档语义查找,到私有…...