PyTorch深度学习实战
本专栏分为两大部分,专栏内容如下:
第1部分
探讨PyTorch与其他深度学习框架的区别。
如何在PyTorch Hub中下载和运行模型。
PyTorch的基本构建组件——张量
展示不同类型的数据如何被表示为张量,以及深度学习模型期望构造什么样的张量。
梯度下降机制,以及PyTorch如何实现自动微分。
利用PyTorch的神经网络(nn)和优化(optim)模块来建立和训练一个用于回归的神经网络的过程。
构建一个用于图像分类的全连接层模型,并扩展介绍PyTorch API的知识。
探讨关于构建神经网络模型及其PyTorch实现方面更高级的概念。
第2部分
从CT成像开始,介绍用于肺肿瘤分类的端到端策略。
使用标准PyTorch API加载人工标注数据和CT扫描的图像,并将相关信息转换为张量。
第1个分类模型,该模型基于第10章介绍的训练数据构建。本章还会介绍对模型进行训练,收集基本的性能指标,并使用张量可视化工具TensorBoard来监控训练。
探讨并介绍实现标准性能指标,以及使用这些指标来识别之前完成的训练中的缺陷。然后,介绍通过使用经过数据平衡和数据增强方法改进过的数据集来弥补这些缺陷。
介绍分割,即像素到像素的模型架构,以及使用它来生成覆盖整个CT扫描的可能结节位置的热力图。这张热力图可以用来在CT扫描中找到非人工标注数据的结节。
介绍实现最终的端到端项目:使用新的分割模型和分类方法对癌症患者进行诊断。
相关文章:

PyTorch深度学习实战
本专栏分为两大部分,专栏内容如下: 第1部分 探讨PyTorch与其他深度学习框架的区别。 如何在PyTorch Hub中下载和运行模型。 PyTorch的基本构建组件——张量 展示不同类型的数据如何被表示为张量,以及深度学习模型期望构造什么样的张量。 梯度…...
leetcode 1011. Capacity To Ship Packages Within D Days(D天内运送包裹的容量)
数组的每个元素代表每个货物的重量,注意这个货物是有先后顺序的,先来的要先运输,所以不能改变这些元素的顺序。 要days天内把这些货物全部运输出去,问所需船的最小载重量。 思路: 数组内数字顺序不能变,就…...

支持向量机SVM详细原理,Libsvm工具箱详解,svm参数说明,svm应用实例,神经网络1000案例之15
目录 支持向量机SVM的详细原理 SVM的定义 SVM理论 Libsvm工具箱详解 简介 参数说明 易错及常见问题 SVM应用实例,基于SVM的股票价格预测 支持向量机SVM的详细原理 SVM的定义 支持向量机(support vector machines, SVM)是一种二分类模型&a…...
Mac 上搭建 iOS WebDriverAgent 环境
文章目录Mac环境搭建配置 Xcode 生成 WDA常见问题brew 安装失败Mac环境搭建 macOS 系统电脑:12.6.2 Xcode:14.0.1(xcodebuild -version) appium Desktop:1.21.0 (下载链接) Appium Desktop 1.22.0 ,从该版…...

python学习笔记之例题篇NO.3
获得用户输入的一个整数N,输出N中所出现不同数字的和。 s list(set(list(input())))# ① r…...
【Kubernetes】第七篇 - Service 服务介绍和使用
一,前言 上一篇,通过配置一个 Deployment 对象,在内部创建副本集对象,副本集帮我们创建了 3 个 pod 副本 由于 pod 存在 IP 漂移现象,pod 的创建和重启会导致 IP 变化; 本篇,介绍 Service 服…...
Linux 终端复用器Tmux
目录 Tmux讲解 配置tmux 配置tmux会话 配置tmux窗口(在会话界面进行配置) 配置tmux面板 配置窗口共享同步 Tmux讲解 RHEL5/6/7使用的是screen软件包 RHEL8使用的是tumx软件包(功能更强大,更易用) tmux的三个基本…...

Hadoop集群模式安装(Cluster mode)
1、Hadoop源码编译 安装包、源码包下载地址 Index of /dist/hadoop/common/hadoop-3.3.0为什么要重新编译Hadoop源码? 匹配不同操作系统本地库环境,Hadoop某些操作比如压缩、IO需要调用系统本地库(*.so|*.dll) 修改源码、重构源码 如何…...
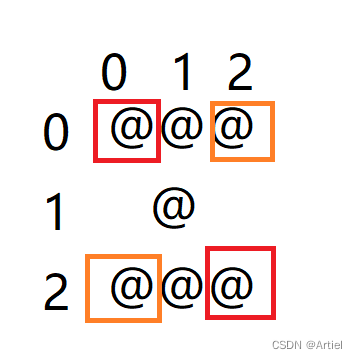
PTA L1-054 福到了(详解)
前言:内容包括:题目,代码实现,大致思路,代码解读 题目: “福”字倒着贴,寓意“福到”。不论到底算不算民俗,本题且请你编写程序,把各种汉字倒过来输出。这里要处理的每…...

python -- 魔术方法
魔术方法就算定义在类里面的一些特殊的方法 特点:这些func的名字前面都有两个下划线 __new__方法 相当于一个类的创建一个对象的过程 __init__方法 相当于为这个类创建好的对象分配地址初始化的过程 __del__方法 一个类声明这个方法后,创建的对象如果…...

「JVM 编译优化」提前编译器
1996 年 JDK 1.0 发布,同年 7 月 外挂即时编译器发布(JDK 1.0.2),而 Java 提前编译发布在之后几个月(IBM High Performance Compiler for Java),1998 年 GNU 组织公布 GCC 家族新成员 GNU Compi…...

Golang channel 用法与实现原理
文章目录1.简介2.用法3.三种状态4.实现原理数据结构原理概述5.小结参考文献1.简介 Golang channel 是一种并发原语,用于在不同 goroutine 之间进行通信和同步。本质上,channel 是一种类型安全的 FIFO 队列,它可以实现多个 goroutine 之间的同…...
)
jackson 序列化、反序列化的时候第一个大写单词变成小写了(属性设置不成功)
参考链接:https://www.baeldung.com/jackson-annotations 遇到的问题 之前和第三方对接,返回的接口中的属性名称是拼音字母大写,奇怪,反序列化的时候好多字段都为空,没设置进去。 因为对接前,我先用 IntelliJ IDEA …...

如何判断机器学习数据集是否是线性的
首先,线性和非线性函数之间的区别: 左边是线性函数,右边是非线性函数。 线性函数:可以简单定义为始终遵循以下原则的函数: 输入/输出=常数。 线性方程总是1次多项式(例如x+2y+3=0)。在二维情况下,它们总是形成直线;在其他维度中,它们也可以形成平面、点或超平面。它们的…...

后端基础SQL
SQL基础语法: sql对大小写不敏感,eg: SELECT 等效于 select;select: select用于从表中查找数据,select 列名 from 表名 —> 结果集::仅有查询列的结果表; SELECT * FROM 表名称 ----> 结果集: 查找表的所有数据…...
)
Ubuntu 18.04 上编译和安装内核(内核源码版本)
Ubuntu 18.04 上编译和安装内核(内核源码版本) linux发行版本为,ubuntu18.04。内核版本为5.15.7。其他版本类似。 1.下载内核源代码。可以从官方网站下载最新的内核源代码,也可以使用 Git 命令从 Linux 内核的 Git 仓库中获取最新…...

day 53|● 1143.最长公共子序列 ● 1035.不相交的线 ● 53. 最大子序和 动态规划
1143. 最长公共子序列 给定两个字符串 text1 和 text2,返回这两个字符串的最长 公共子序列 的长度。如果不存在 公共子序列 ,返回 0 。 一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些…...

运维工程师必知的十项Linux常识
1、GNU和GPL GNU计划(又称革奴计划),是由Richard Stallman(理查德斯托曼)在1983年9月27日公开发起的软件集体协作计划。它的目标是创建一套完全的操作系统。GNU也称为软件工程项目。GPL是GNU的通用公共许可证…...

C++ 11 之右值引用和移动语义
文章目录左值引用与右值引用1、左值与右值2、纯右值、将亡值3、左值引用与右值引用4、右值引用和 std::move 使用场景引用限定符移动语义—std::move()完美转发emplace_back 减少内存拷贝和移动总结c11中引用了右值引用和移动语义,可以避免无谓的复制,提…...
【第一章:Spring概述、特点、IOC容器、IOC操作bean管理(基于xml方式)】
第一章:Spring概述、特点、IOC容器、IOC操作bean管理(基于xml方式) 1.Spring是什么? ①Spring是一款主流的java EE 轻量级开源框架。 ②广义的Spring:Spring技术栈,Spring不再是一个单纯的应用框架&#x…...

李白的思乡诗 / 山水诗 / 豪放诗有哪些?诗词在线app手工整理
"酒入豪肠,七分酿成了月光,余下的三分啸成剑气,绣口一吐就半个盛唐。" 李白的诗,是盛唐最耀眼的星,既有 "天生我材必有用" 的豪放,也有 "低头思故乡" 的柔情,更有…...

Leetcode 剑指 Offer II 172. 统计目标成绩的出现次数
题目难度: 简单 原题链接 今天继续更新 Leetcode 的剑指 Offer(专项突击版)系列, 大家在公众号 算法精选 里回复 剑指offer2 就能看到该系列当前连载的所有文章了, 记得关注哦~ 题目描述 某班级考试成绩按非严格递增顺序记录于整数数组 scoresÿ…...

初创公司如何借助Taotoken低成本启动AI产品开发
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创公司如何借助Taotoken低成本启动AI产品开发 对于初创公司而言,在资源有限的情况下启动AI产品开发,面临…...

Chrome抓包失败原因与Burp代理设置全解析
1. 这不是“装个插件就完事”的操作,而是理解代理本质的第一课很多人点开Burp Suite,双击启动,看到界面就以为“抓包开始了”——结果在谷歌浏览器里按F12,Network标签页刷半天,连个请求影子都看不到;或者点…...

等保2.0三级Linux服务器合规基线重建实战指南
1. 为什么等保2.0整改不是“打补丁”,而是重装操作系统级的系统工程你刚接手一台跑了三年的CentOS 7服务器,业务跑得稳,监控没告警,运维日志里连个WARNING都少见——但等保测评报告第一页就写着:“操作系统未满足等保2…...

对比直接使用原厂API,Taotoken在计费透明性上给我们的感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用原厂API,Taotoken在计费透明性上给我们的感受 在集成大模型能力到业务系统的过程中,API调用成…...

CleanMyWechat:一键解放你的PC微信存储空间
CleanMyWechat:一键解放你的PC微信存储空间 【免费下载链接】CleanMyWechat 自动删除 PC 端微信缓存数据,包括从所有聊天中自动下载的大量文件、视频、图片等数据内容,解放你的空间。 项目地址: https://gitcode.com/gh_mirrors/cl/CleanMy…...

机器学习势函数在暗物质探测中的应用:计算晶体缺陷存储能
1. 项目概述:当机器学习势函数遇上暗物质探测在粒子物理与凝聚态物理的交叉前沿,有一个看似微小却至关重要的物理细节,正困扰着新一代的暗物质与中微子探测实验:当一个来自宇宙的弱相互作用粒子(WIMP)或一个…...

告别黄牛票:用DamaiHelper脚本轻松抢到大麦网演唱会门票
告别黄牛票:用DamaiHelper脚本轻松抢到大麦网演唱会门票 【免费下载链接】DamaiHelper 大麦网演唱会演出抢票脚本。 项目地址: https://gitcode.com/gh_mirrors/dama/DamaiHelper 还在为抢不到心仪的演唱会门票而烦恼吗?面对秒光的票源和黄牛的高…...
)
ChatGPT桌面客户端安装失败真相大揭秘(含微软Store/官网直链/第三方镜像三通道对比测试报告)
更多请点击: https://intelliparadigm.com 第一章:ChatGPT桌面客户端安装失败真相大揭秘(含微软Store/官网直链/第三方镜像三通道对比测试报告) ChatGPT官方并未发布真正意义上的“桌面客户端”,当前所有标称为“Chat…...