浅谈常用的日志框架
文章目录
- 1.为什么需要日志框架
- 2.常见日志框架
- 2.1.日志框架介绍
- 2.2.市面上的日志框架
- 3.Slf4j使用
- 3.1.如何在系统中使用SLF4j
- 3.2.可能存在的问题
- 4.SpringBoot日志的默认配置
- 5.SpringBoot指定日志文件
- 6.切换日志框架
1.为什么需要日志框架
通过日志的方式记录系统运行的过程或错误以便定位问题。日志收集,方便后期日志分析!
2.常见日志框架
2.1.日志框架介绍
对于我们日常开发日志是经常使用的,当然以前的我们可能还傻傻的各种System.out.println("重要数据")在控制台输出各种重要数据呢,投入生产的时候再注释掉。到现在为止呢,已经有很多日志可供选择了,而市面上常见的日志框架有很多,比如:JCL、SLF4J、Jboss-logging、jUL(Java Util Logging)、log4j、log4j2、logback等等,我们该如何选择呢?
2.2.市面上的日志框架
JUL、JCL、Jboss-logging、logback、log4j、log4j2、slf4j…
| 日志的抽象层 | 日志实现 |
|---|---|
| Log4j JUL(java.util.logging) Log4j2 Logback |
左边选一个抽象层、右边来选一个实现;类似与我们经常使用的JDBC一样,选择不同的数据库驱动。
下面我们先看看日志的抽象层:JCL大家应该很熟悉,Commons Logging,spring中常用的框架最后一次更新2014年~~~;jboss-logging使用的场景太少了;就剩下SLF4j了也是我们springboot中使用的日志抽象层。
日志实现:大家应该看着都很熟悉把Log4j大家应该用的挺多的,Logback是Log4j的升级版本出至于同一个人开发的,考虑到以后的升级使用等问题,又写出了SLF4j的日志抽象层使用起来更加灵活。JUL(java.util.logging)一看就知道是java util包下的;Log4j2 咋一看像是Log4j的升级版本,其实并不是,它是apache下生产的日志框架。
SpringBoot底层是Spring框架 , Spring框架默认使用JCL.
SpringBoot选用SLF4j 和 Logback
3.Slf4j使用
3.1.如何在系统中使用SLF4j
slf4j官网: https://www.slf4j.org
开发的时候,日志记录方法的调用,不应该来直接调用日志的实现类,而是调用日志抽象层里面的方法;
给系统里面导入slf4j的jar和 logback的实现jar就可以。
使用示例:
package com.bruceliu.controller;import org.slf4j.Logger;
import org.slf4j.LoggerFactory;public class HelloWorld {public static void main(String[] args) {Logger logger = LoggerFactory.getLogger(HelloWorld.class);logger.info("Hello World");}
}
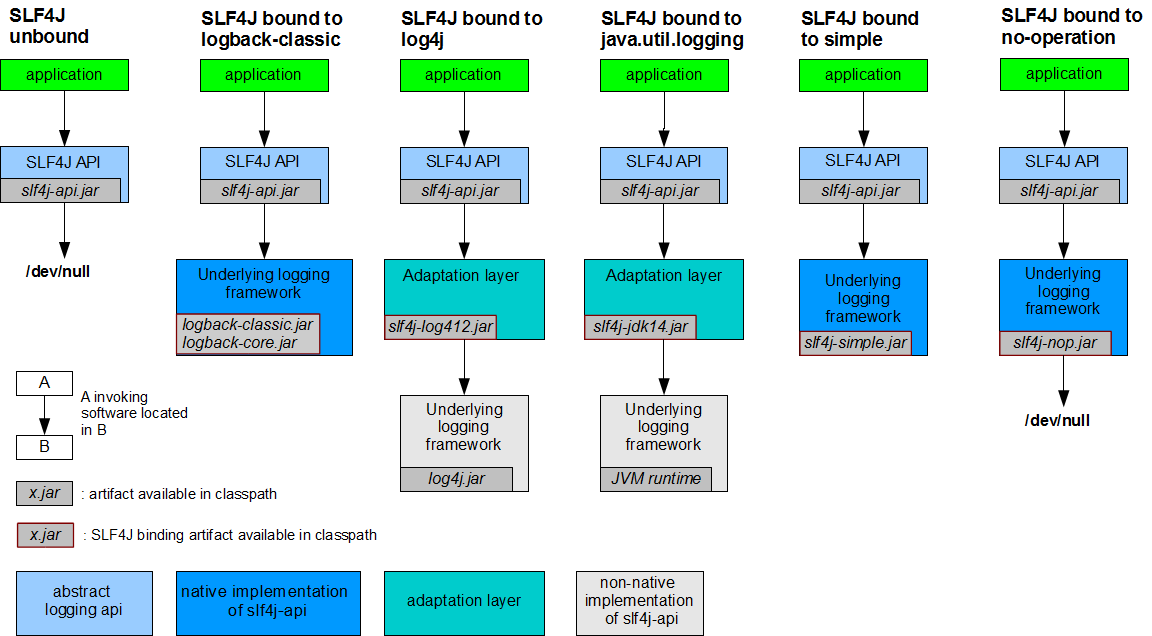
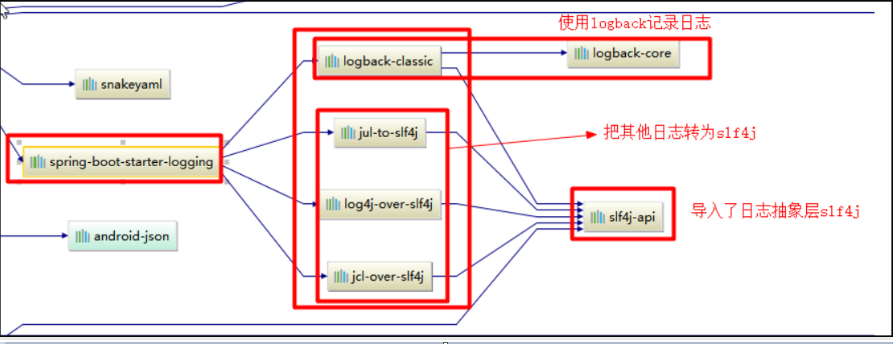
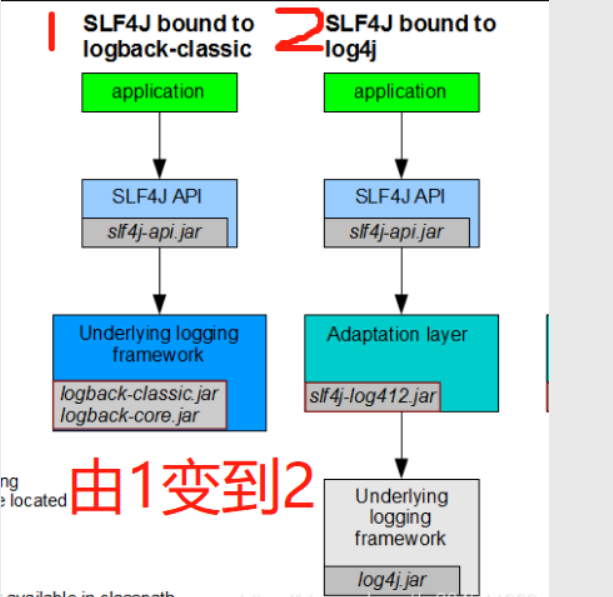
我们现在已经知道了springboot中使用的是 SLF4j和logback,但是如果我们想使用log4j该怎么办呢,从上面的图示中我们可以看出想要使用log4j我们肯定还是要使用 SLF4j作为抽象层,但是中间给我们加入了一层适配层(Adaptation layer)然后使用log4j进行实现,那么我们需要导入图示中的jar包即可,其他的也是一样了。所以说,以后开发的时候,日志记录方法的调用,不应该来直接调用日志的实现类,而是调用日志抽象层里面的方法; 每一个日志的实现框架都有自己的配置文件。使用slf4j以后,配置文件还是做成日志实现框架自己本身的配置文件;
3.2.可能存在的问题
现在开发中我么想使用slf4j+logback,但是对于一些遗留项目中例如Spring(commons-logging)、Hibernate(jboss-logging)…等等,如何去做到日志同一呢?
你想到的问题SLF4j能想不到吗?答案是可以的,我们看看下面的图就明白了
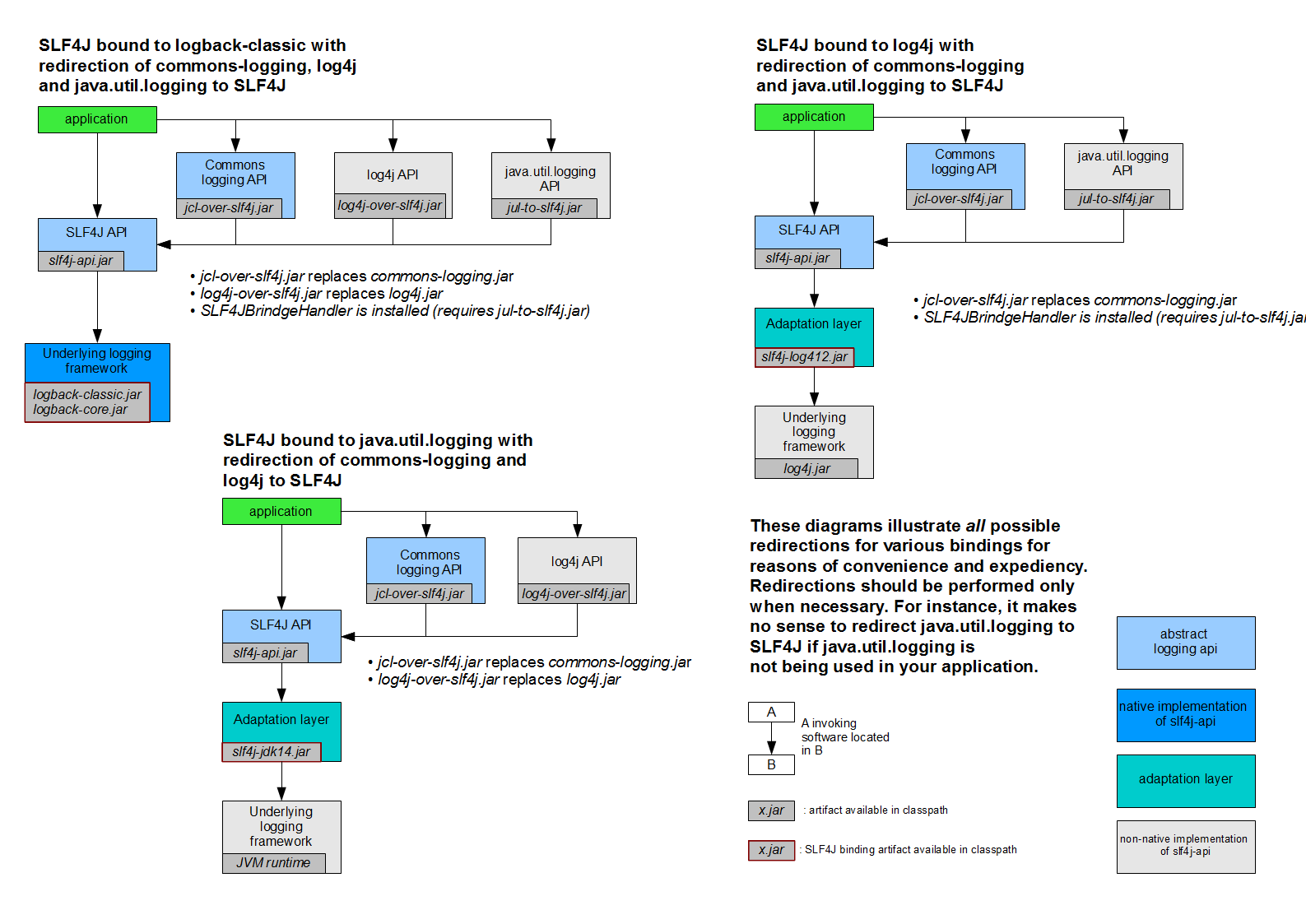
如何让系统中所有的日志都统一到slf4j;
1、将系统中其他日志框架先排除出去;
2、用中间包来替换原有的日志框架;
3、我们导入slf4j其他的实现
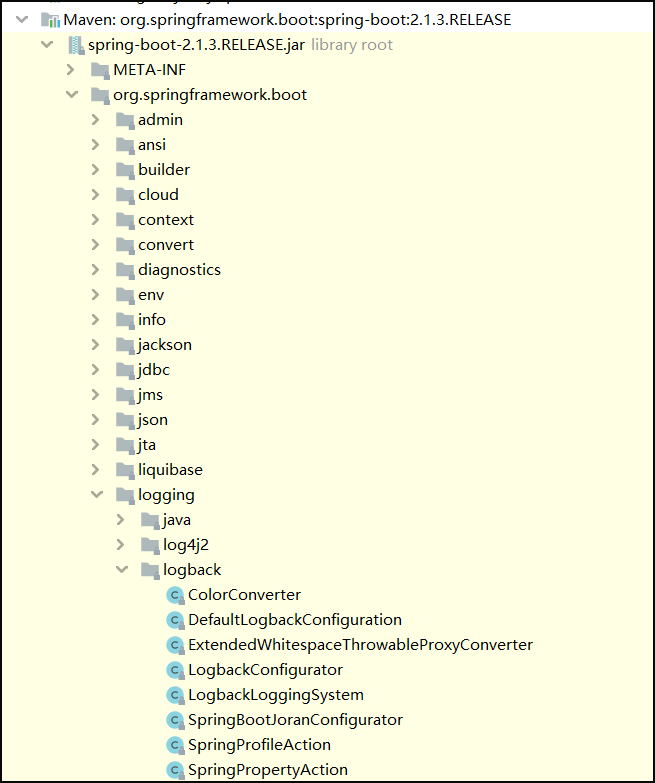
其实通过idea我们创建一个springboot项目也可以查看日志依赖(截取其中部分):
SpringBoot使用它来做日志功能:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-logging</artifactId>
</dependency>
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>1.3.2.RELEASE</version><relativePath/> <!-- lookup parent from repository -->
</parent>
总结:
1)、SpringBoot底层也是使用slf4j+logback的方式进行日志记录
2)、SpringBoot也把其他的框架的日志都替换成了slf4j;
3)、如果我们要引入其他框架?
SpringBoot能自动适配所有的日志,而且底层使用slf4j+logback的方式记录日志,引入其他框架的时候,只需要把这个框架依赖的日志框架排除掉即可
示例:
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId><exclusions><exclusion><groupId>commons-logging</groupId><artifactId>commons-logging</artifactId></exclusion></exclusions>
</dependency>
4.SpringBoot日志的默认配置
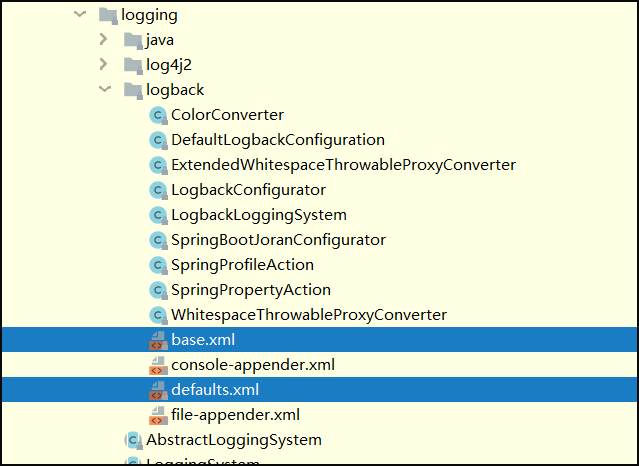
SpringBoot日志的默认配置的位置:
package com.bruceliu;import org.junit.Test;
import org.junit.runner.RunWith;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;@RunWith(SpringRunner.class)
@SpringBootTest
public class Springboot1ApplicationTests {// 日志记录器private Logger logger = LoggerFactory.getLogger(getClass());@Testpublic void contextLoads() {// System.out.println();// 日志的级别:由低到高// trace<debug<info<warn<error// 可以调整需要输出的日志级别: 日志就只会在这个级别及以后的高级别生效logger.trace("这是trace日志...");logger.debug("这是debug日志...");// SpringBoot默认使用的是info级别的, 没有指定级别的就使用SpringBoot默认规定的级别logger.info("这是info日志...");logger.warn("这是warn日志...");logger.error("这是error日志...");}}
其他配置
设置日志的级别: logging.level
#修改日志的级别,默认root是info
logging.level.root=trace
指定日志的文件名: logging.file ,会在当前项目下生成springboot.log日志
# 不指定路径在当前项目下生成springboot.log日志
logging.file=springboot.log# 可以指定完整的路径;
logging.file=d://springboot.log
指定日志的文件的目录: logging.path , 日志文件名称使用SpringBoot默认的输出日志文件名.
# 在当前磁盘的根路径下创建spring文件夹和里面的log文件夹;使用spring.log 作为默认文件
logging.path=/spring/log
如果同时指定了 logging.file , 则使用 logging.file , 不会使用 logging.path

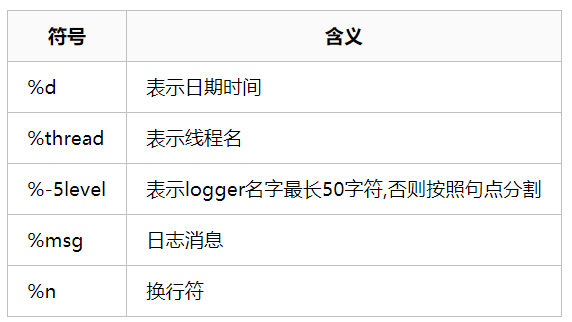
指定日志在控制台输出的格式: logging.pattern.console
# 在控制台输出的日志的格式
logging.pattern.console=%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n
指定文件中日志输出的格式: logging.pattern.file
# 指定文件中日志输出的格式
logging.pattern.file=%d{yyyy-MM-dd} === [%thread] === %-5level === %logger{50} ==== %msg%n
日志的输出格式
5.SpringBoot指定日志文件
如果还是不够用的话,可以自定义配置。给类路径下放上每个日志框架自己的配置文件即可;SpringBoot就不使用他默认配置的
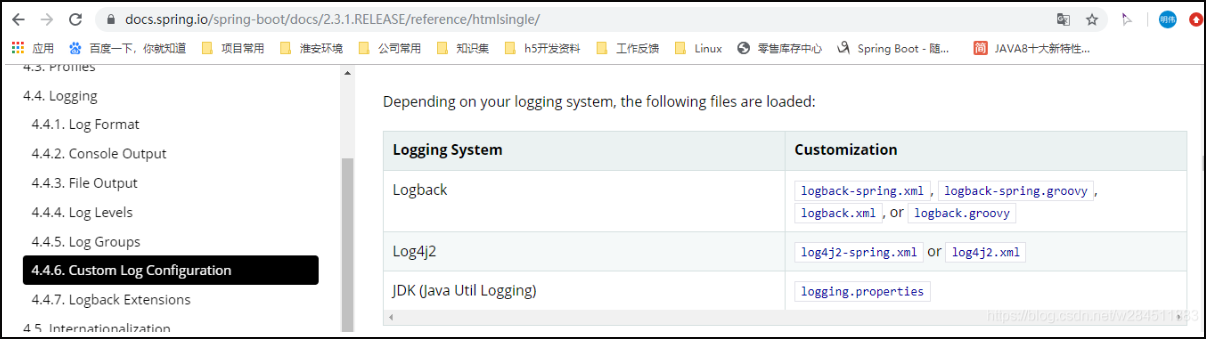
logback.xml示例
logback.xml:直接就被日志框架识别了;
<?xml version="1.0" encoding="UTF-8"?><configuration><jmxConfigurator /><!-- 日志添加到控制台 --><appender name="console" class="ch.qos.logback.core.ConsoleAppender"><encoder><pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern></encoder></appender><!-- 滚动记录文件,先将日志记录到指定文件,当符合某个条件时,将日志记录到其他文件 --><appender name="rollingFile" class="ch.qos.logback.core.rolling.RollingFileAppender"><file>logs/quickstart.log</file><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><fileNamePattern>logs/smt.%d{yyyy-MM-dd}.log</fileNamePattern></rollingPolicy><encoder><pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern></encoder></appender><appender name="businessLogFile" class="ch.qos.logback.core.rolling.RollingFileAppender"><!-- 按每小时滚动文件,如果一个小时内达到10M也会滚动文件, 滚动文件将会压缩成zip格式 --><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><fileNamePattern>logs/smt-%d{yyyy-MM-dd_HH}.%i.zip</fileNamePattern><timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP"><maxFileSize>10MB</maxFileSize></timeBasedFileNamingAndTriggeringPolicy></rollingPolicy><!-- 独立的pattern --><encoder><pattern>%d{HH:mm:ss.SSS},%msg%n</pattern></encoder></appender><!-- project default level 本身没有指定appender不打印 传递给上级root--><logger name="com.github.miemiedev.smt" level="DEBUG" /><logger name="org.mybatis.spring.SqlSessionFactoryBean" level="DEBUG" /><!--log4jdbc --><!-- <logger name="jdbc.sqltiming" level="INFO"/> --><root level="WARN"><appender-ref ref="console" /><appender-ref ref="rollingFile" /></root></configuration>
logback-spring.xml:日志框架就不直接加载日志的配置项,由SpringBoot解析日志配置,可以使用SpringBoot 的高级Profile功能
<!-- 日志添加到控制台 --><appender name="console" class="ch.qos.logback.core.ConsoleAppender"><layout class="ch.qos.logback.classic.PatternLayout"><springProfile name="dev"><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} ----> [%thread] ---> %-5level %logger{50} - %msg%n</pattern></springProfile><springProfile name="!dev"><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} ==== [%thread] ==== %-5level %logger{50} - %msg%n</pattern></springProfile></layout></appender>
#指定当前模式
spring:profiles:active: dev
如果使用logback.xml作为日志配置文件,还要使用profile功能,会有以下错误 no applicable action for [springProfile]
6.切换日志框架
弃用SpringBoot官方指定的logback日志框架,改用别的日志框架实现。但没太大实际意义,因为logback是最先进的版本,一般没有必要替换。(不推荐,只是教大家如何切换)
pom.xml
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId><exclusions><exclusion><artifactId>logback-classic</artifactId><groupId>ch.qos.logback</groupId></exclusion><exclusion><artifactId>log4j-over-slf4j</artifactId><groupId>org.slf4j</groupId></exclusion></exclusions>
</dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId>
</dependency>
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope>
</dependency>
在resource目录下添加log4j.properties
log4j.rootCategory=DEBUG, CONSOLE,LOGFILElog4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender
log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout
log4j.appender.CONSOLE.layout.ConversionPattern=-%p-%d{yyyy/MM/dd HH:mm:ss,SSS}-%l-%L-%m%nlog4j.appender.LOGFILE=org.apache.log4j.FileAppender
log4j.appender.logFile.Threshold=DEBUG
log4j.appender.logFile.ImmediateFlush=true
log4j.appender.LOGFILE.Append=true
log4j.appender.LOGFILE.File=mylog.log
log4j.appender.LOGFILE.layout=org.apache.log4j.PatternLayout
log4j.appender.LOGFILE.layout.ConversionPattern=-%p-%d{yyyy/MM/dd HH:mm:ss,SSS}-%l-%L-%m%n
相关文章:
浅谈常用的日志框架
文章目录1.为什么需要日志框架2.常见日志框架2.1.日志框架介绍2.2.市面上的日志框架3.Slf4j使用3.1.如何在系统中使用SLF4j3.2.可能存在的问题4.SpringBoot日志的默认配置5.SpringBoot指定日志文件6.切换日志框架1.为什么需要日志框架 通过日志的方式记录系统运行的过程或错误以…...

字节是真的难进,测开4面终上岸,压抑5个月,终于可以放声呐喊
这次字节的面试,给我的感触很深,意识到基础的重要性。一共经历了五轮面试:技术4面+HR面。 下面看正文 本人自动专业毕业,压抑了五个多月,终于鼓起勇气,去字节面试,下面是我的面试过…...

Bash初识
Bash初识 1.简介: 一.什么是shell? 用过计算机的人知道,我只要点点鼠标计算机就能按照我们的要求来进行相应的操作,那么,你有没有想过计算机为什么能够识别我们的操作呢?俗话说,人有人语,机有机…...
ElasticSearch Script 操作数据最详细介绍
文章目录ElasticSearch Script基础介绍基础用法List类型数据新增、删除nested数据新增、删除根据指定条件修改数据根据指定条件修改多个字段数据-查询条件也使用脚本根据指定条件删除nested中子数据数据根据条件删除数据删除之后结果创建脚本,通过脚本调用根据条件查…...

【黑盒模糊测试】路由器固件漏洞挖掘实战--AFL++ qemu_mode
前言 很久之前就想写AFL++的qemu_mode了,只是模糊测试专题的文章有些过于耗费时间,加上工作原因导致一直搁置。最近需要出差会用到黑盒模糊测试,所以就当做复习一遍,我记得Fuzzing 101也有一个qemu_mode的练习,有空的话下一篇文章更新吧~ 编写不易,如果能够帮助到你,希望…...

【java实现Word模板导出】Xdocreport和Freemaker
如果只是生成简单的word文件的话可以使用 Hutool 上手简单使用方便。 但如果需要导出内容比较复杂的word文件的话用那个就不合适了,这时候就需要Xdocreport这玩意了。 制作模板 新建一个word文档在需要插入变量的地方使用快捷键 Crtl F9 来生成一个域 然后右键单…...

Stable-Baselines 3 部分源代码解读 3 ppo.py
Stable-Baselines 3 部分源代码解读 ./ppo/ppo.py 前言 阅读PPO相关的源码,了解一下标准库是如何建立PPO算法以及各种tricks的,以便于自己的复现。 在Pycharm里面一直跳转,可以看到PPO类是最终继承于基类,也就是这个py文件的内…...
[业务逻辑] 订单超时怎么处理
文章目录1.订单的过程分析2.JDK自带的延时队列 (单机)3.RabbitMQ的延时消息 (消息队列方案)4.RocketMQ的定时消息 (消息队列方案)5.Redis过期监听 (Redis方案)6.定时任务分布式批处理 (扫表轮训方案)7.总结1.订单的过程分析 一个订单流程中有许多环节要用到超时处理 买家超时未…...
iOS上架及证书最新创建流程
目前使用uniapp框架开发app,大大节省了我们兼容多端应用的工作量和人手,所以目前非常缺乏ios上架和证书创建流程流程的文档假如你没有任何的打包或上架经验,参考本文有很大的收益。通常申请ios证书和上架ipa应用,是需要MAC电脑的&…...

python入门
Python是一种高级编程语言,由荷兰计算机科学家Guido van Rossum于1991年发明。Python语言具有简洁、清晰和易于阅读的语法,同时也拥有广泛的应用领域,包括Web开发、数据分析、人工智能、科学计算等。Python的特点是能够快速开发原型和简单易读…...
Linux部署java项目
Linux部署java项目启动虚拟机这部分的操作之前学习虚拟机时已经做过,可以参照之前的笔记即可推荐大家重新解压纯净版的RockyLinux来实现启动后登录rockylinuxsudo su -修改root用户密码passwd下面就切换到客户端软件连接虚拟机ifconfigifconfig | more查看ip地址使用Bvssh软件连…...

elisp 从简单实例开始.
elisp 从简单实例开始. 我们怎样用elisp 与电脑交互,先从简单实例开始, 逐渐掌握它的几个对象. 与电脑交互,总要有输入,输出,先看两个简单例子. 输入从minibuffer,输出可以是minibuffer 或者缓冲区. 一: 从minibuffer 中输入, 在指定缓冲中插入文字(insert)x ;;;;;;;;;;;;;;;;…...

ThreeJS加载geojson数据实现3D地图
ThreeJS加载geojson数据实现3D地图,主要通过借助geojson地理信息数据转摩托尔坐标实现,中间借助了d3.js的地图处理方法,最后通过threejs渲染到页面上: 通过平台获取GeoJson格式的行政区域借助d3的方法,将坐标系转摩托尔坐标利用ThreeJS中的自定义Shape,绘制地图利用Three…...
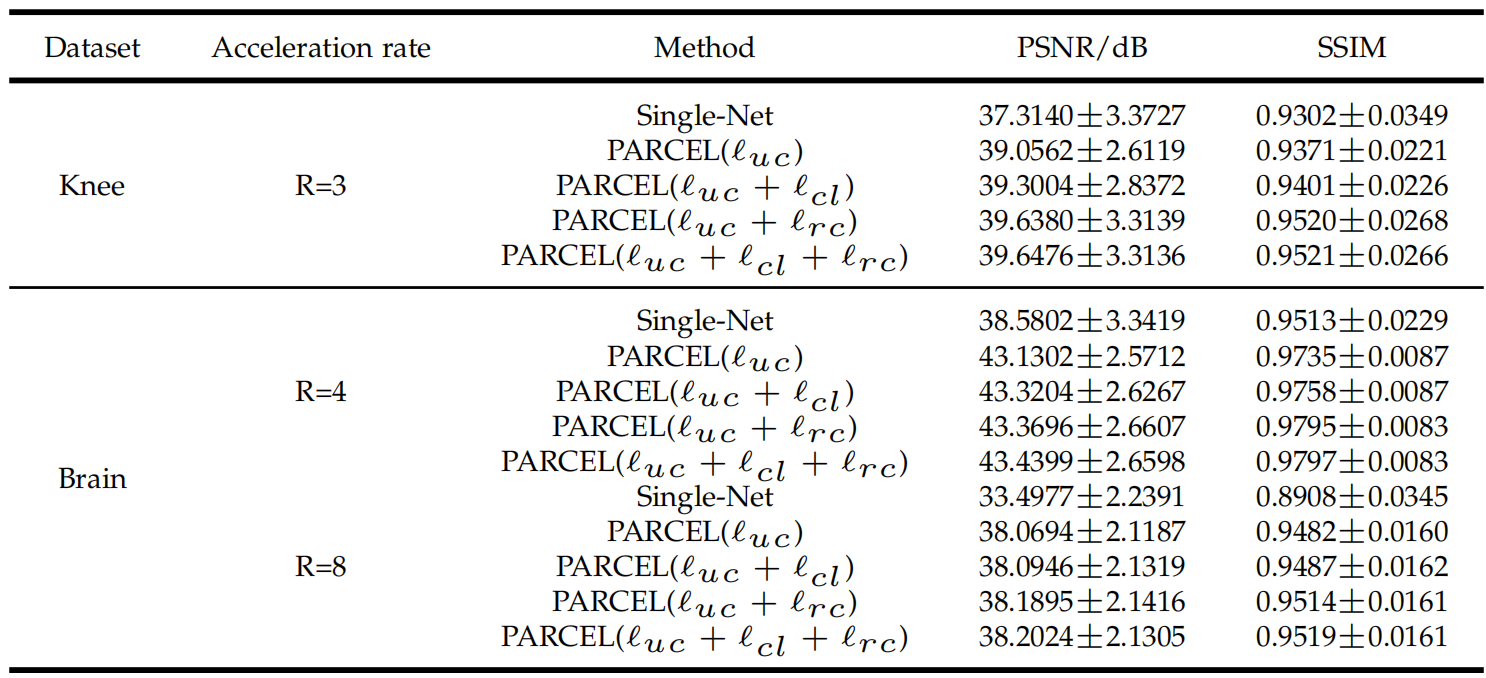
深度学习无监督磁共振重建方法调研(二)
深度学习无监督磁共振重建方法调研(二)Self-supervised learning of physics-guided reconstruction neural networks without fully sampled reference data(Magnetic Resonance in Medicine 2020)模型设计实验结果PARCEL: Physi…...
蓝桥杯入门即劝退(十九)两两交换链表
-----持续更新蓝桥杯入门系列算法实例-------- 如果你也喜欢Java和算法,欢迎订阅专栏共同学习交流! 你的点赞、关注、评论、是我创作的动力! -------希望我的文章对你有所帮助-------- 一、题目描述 给你一个链表,两两交换其中…...

【Java 面试合集】接口以及抽象类
接口以及抽象类 1. 概述 嗨,【Java 面试合集】又来了,今天给大家分享的内容是接口以及抽象类。一看这个概念很多人都知道,但是方方面面的细节不一定知道哦,今天我们就从方方面面的细节来讲讲 2. 相同点: 都是上层的抽…...

LeetCode 2391. 收集垃圾的最少总时间
给你一个下标从 0 开始的字符串数组 garbage ,其中 garbage[i] 表示第 i 个房子的垃圾集合。garbage[i] 只包含字符 ‘M’ ,‘P’ 和 ‘G’ ,但可能包含多个相同字符,每个字符分别表示一单位的金属、纸和玻璃。垃圾车收拾 一 单位…...

【PMP考试最新解读】第七版《PMBOK》应该如何备考?(含最新资料)
PMP新版大纲加入了ACP敏捷管理的内容,而且还不少,敏捷混合题型占到了 50%,前不久官方也发了通知8月启用第七版《PMBOK》,大家都觉得考试难度提升了,我从新考纲考完下来,最开始也被折磨过一段时间࿰…...

金三银四软件测试面试如何拿捏面试官?【接口测试篇】
九、接口测试 9.1 接口测试怎么测 (jmeter版本) 首先开发会给我们一个接口文档,我们根据开发给的接口文档,进行测试点的分析,主要是考虑正常场景与异常场景,正常场景,条件的组合,…...

Hive基操
数据交换 //hive导出到hdfs /outstudentpt 目录 0: jdbc:hive2://guo146:10000> export table student_pt to /outstudentpt; //从hdfs导入到hive 0: jdbc:hive2://guo146:10000> import table studentpt from /outstudentpt; 数据排序 Order by会对所给的全部数据进行…...

2026保姆级免费照片去水印教程:不用下载App,微信小程序3步搞定!
你是不是也遇到过这种崩溃瞬间?刷到一张绝美壁纸想存下来当背景,结果水印刚好挡住主角的脸;看到一段搞笑视频想转发给朋友,结果水印横在中间像个挡箭牌;想拿一张素材做作业PPT,结果水印比内容还显眼。更烦的…...

2026.5.24-要闻
宁波大学附属康宁医院李广学副主任医师指出,每天刷手机超5小时会显著增加肥胖风险(儿童群体风险增幅达74%),并导致前额叶等脑区代谢减弱,引发注意力、记忆力下降。1 8小时前...

【Java EE】IPv6
IPv6引言IPv6 地址表示IPv6 地址类型地址范围详解多播地址结构IPv6 与 IPv4 的主要区别IPv6 首部格式扩展首部IPv6 地址配置方式无状态地址自动配置(SLAAC)有状态配置(DHCPv6)手动配置邻居发现协议(NDP)IPv…...

卖切削液怎么找客户?下游工厂在哪里
卖切削液找客户,本质是找用切削液的下游工厂,核心难点是拿到这些下游厂的名单和联系人。切削液不像消费品,它的消耗量和工厂的机床数量、加工班次直接挂钩——有金属切削车间的工厂才是真客户,没有机加工产线的工厂对你毫无意义。…...

一直怕大模型幻觉,发现针对性harness约束能大大消除
我让AI写长文,然后人工审核,发现大量胡编乱造。 如果人工一个个消除,实在太累了,这就不是LLM自动化办公的路子了 尝试了 harness (engineering)的实操路子, 试用发现: 大模型正在把长文中我人工审核发现的幻…...
)
【小红书算法偏爱的文案结构】:ChatGPT无法自学的3层语义嵌套技巧(含2024Q2平台最新流量权重白皮书节选)
更多请点击: https://kaifayun.com 第一章:小红书算法偏爱的文案结构本质解构 小红书的推荐算法并非仅依赖关键词或标签匹配,其核心是通过多模态语义理解与用户行为反馈闭环,对文案的信息密度、情绪节奏和结构可读性进行加权评估…...

【限时解析】DeepSeek 2024 Q3计费规则更新:2项重大变更将影响92%高频用户
更多请点击: https://kaifayun.com 第一章:DeepSeek计费模式分析 DeepSeek 提供的 API 服务采用按量计费(Pay-as-you-go)模式,核心计费维度为模型调用所消耗的 Token 总数,包含输入(prompt&…...

5分钟快速上手:DouYinBot抖音无水印视频解析工具终极指南
5分钟快速上手:DouYinBot抖音无水印视频解析工具终极指南 【免费下载链接】DouYinBot 该项目仅自用,不提供抖音视频下载 项目地址: https://gitcode.com/gh_mirrors/do/DouYinBot 在短视频创作火爆的今天,你是否曾为抖音视频上的水印而…...

OpenAI破解80年数学猜想:AI首次完成原创性科学突破
2026年5月21日,一个普通的工作日,数学界却迎来了一场地震。OpenAI的内部通用推理模型,独立证明了离散几何领域一个悬置近80年的核心猜想——而且不是证明了它成立,而是直接推翻了它。 目录 引言:一个简单到小学生都能理解的问题 Erdős单位距离猜想:80年的数学悬案 AI突破…...

信念网络与LSTM在工业物联网实时控制中的应用
1. 信念网络在实时控制系统中的应用原理在工业物联网环境中,无线网络控制系统(WNCS)面临着独特的挑战。不同于有线网络的稳定传输特性,无线信道会受到多径衰落、同频干扰和设备移动性等因素影响,导致控制更新的传输具有显著的不确定性。传统的…...