深度学习无监督磁共振重建方法调研(二)
深度学习无监督磁共振重建方法调研(二)
- Self-supervised learning of physics-guided reconstruction neural networks without fully sampled reference data(Magnetic Resonance in Medicine 2020)
- 模型设计
- 实验结果
- PARCEL: Physics-based Unsupervised Contrastive Representation Learning for Multi-coil MR Imaging(IEEE/ACM TRANSACTIONS ON COMPUTATIONAL BIOLOGY AND BIOINFORMATICS)
- 问题定义与模型设计
- 损失函数
- Undersample Calibration Loss
- Reconstructed Calibration Loss
- Contrastive Representaion Loss
- 实验结果
Self-supervised learning of physics-guided reconstruction neural networks without fully sampled reference data(Magnetic Resonance in Medicine 2020)
本文提出了一种基于自监督方式训练神经网络用于磁共振重建的方式,并通过在公开数据集(fastMRI multi-coil knee)以及前瞻性加速脑成像图(没有GT数据的?)上的数值和人工衡量,证明了方法的有效性。
模型设计
对于完整采样的mask Ω\OmegaΩ,作者将其划分成为了两个mask,Θ\ThetaΘ和Λ\LambdaΛ,其中Θ\ThetaΘ用于训练(生成输入的降采样数据和应用数据一致层),Λ\LambdaΛ用于定义损失函数,即衡量输出结果在Λ\LambdaΛ采样的部分是否和真实数据一致。注意测试时会将所有采样点全部输入生成结果。
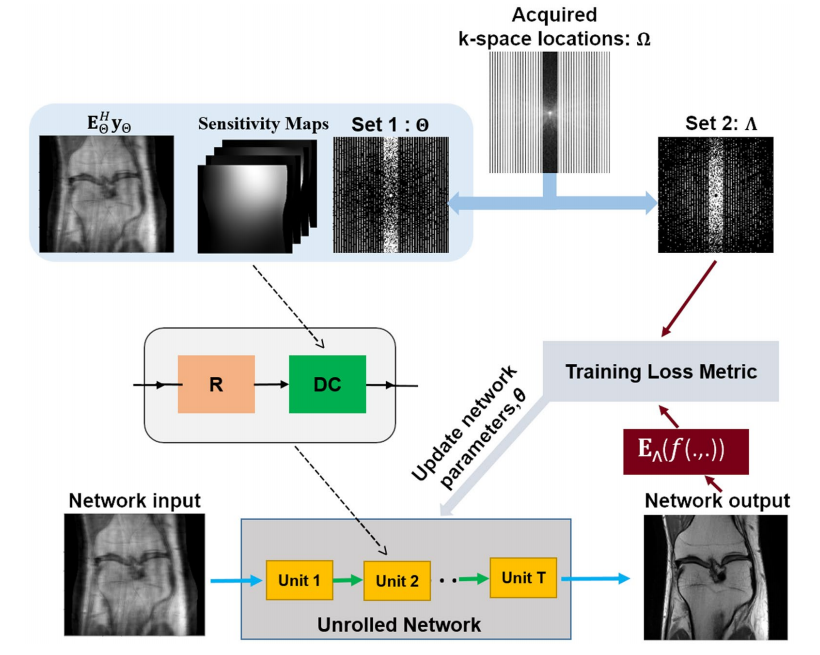
作者采用了normalized l2-l1损失进行训练,模型方法和对标的有监督方法都在K空间定义损失:
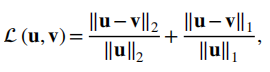
在Mask选择上,作者定义ρ=∣Λ∣/∣Ω∣\rho=|\Lambda|/|\Omega|ρ=∣Λ∣/∣Ω∣,选择了表现最好的值(膝盖数据集是0.4),并且做了三个变体,主要区别是Λ\LambdaΛ和Θ\ThetaΘ的重叠:
- 无重叠(原始设定)
- 重叠50%
- 重叠100%
最后发现原始设定最好。作者还在不同的ρ\rhoρ下验证了不同的随机降采样方式,发现高斯比均匀降采样好,因此选择高斯降采样。
实验结果
作者在fastMRI的多线圈Knee上做了实验(4倍降采样),对比了有监督方法,无监督方法和传统CS重建方法,看起来提出的方法好于传统方法,和有监督方法相当。
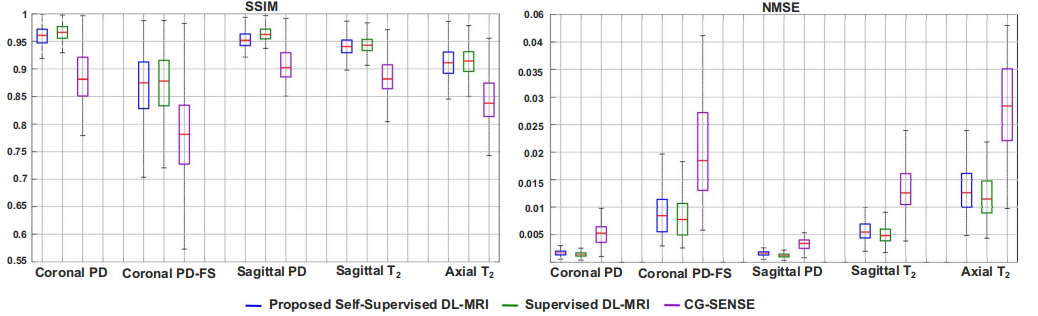
其它实验结果就不赘述了。
PARCEL: Physics-based Unsupervised Contrastive Representation Learning for Multi-coil MR Imaging(IEEE/ACM TRANSACTIONS ON COMPUTATIONAL BIOLOGY AND BIOINFORMATICS)
同样是王珊珊团队的工作,可以看作是SelfCoLearn的进阶版,对多线圈成像做了更多的讨论。
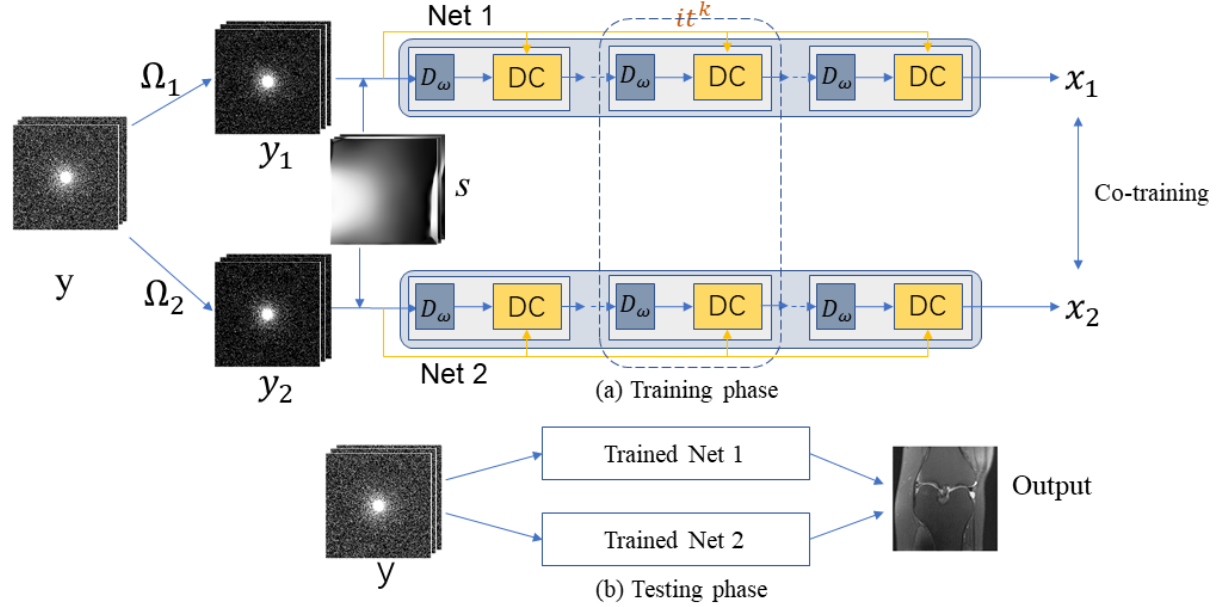
问题定义与模型设计
和单线圈磁共振成像不同的是,除了降采样矩阵Ω\mathbf{\Omega}Ω和傅里叶变换FFF外,还包括了线圈敏感度信息SSS,下式中ϵ\epsilonϵ表示噪声,下标iii表示线圈,CCC为线圈数:
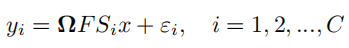
和SelfCoLearn一样,模型也分为了两个子网络,输入的数据经过了re-降采样(AjA_jAj),求解的问题的表示如下所示:
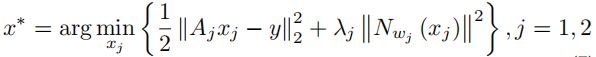
其中Aj=ΩiFSA_j=\mathbf{\Omega_i}FSAj=ΩiFS,jjj用于表示两个子网络。网络用DwD_wDw表示,采用MoDL结构(因为是在每次迭代中共享权重,所以DwD_wDw也可以用来表示整个网络),输出为x1x_1x1和x2x_2x2。
损失函数
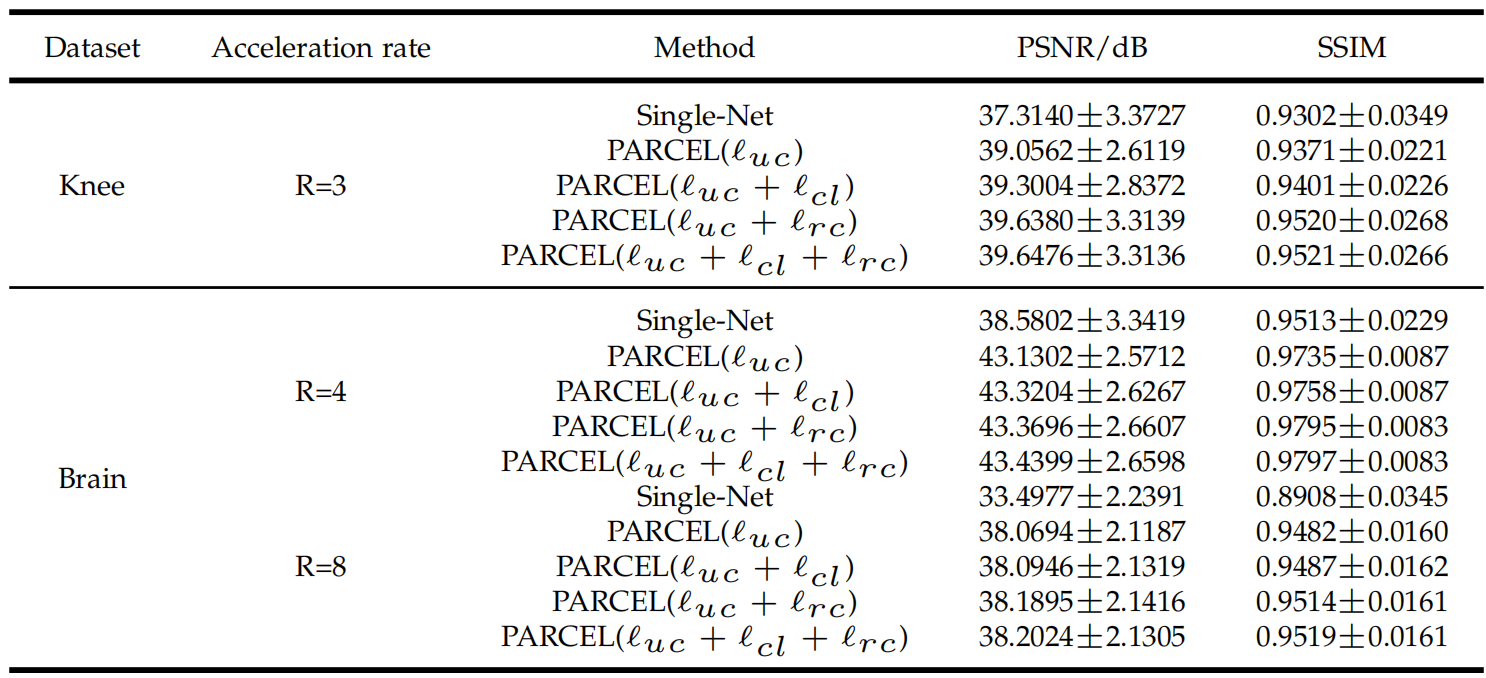
模型设计了精巧的co-training loss,包含三个部分,总公式如下,LLL为样本总数,不过根据代码,三种损失并不是1:1:1,而是1:0.1:0.1。
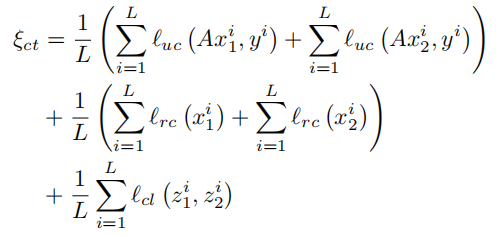
Undersample Calibration Loss
表示为lucl_{uc}luc,主要是确保重建后的结果在所有采样位置(未经过re-降采样)和已知的结果一致:
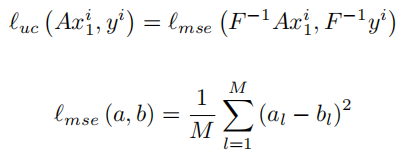
Reconstructed Calibration Loss
表示为lrcl_{rc}lrc,其将xxx(这里只是表示损失函数的输入,实际使用中的输入就是两个子网络的输出x1x_1x1或者x2x_2x2),EEE表示FSFSFS,EHE^HEH表示SF−1SF^{-1}SF−1。
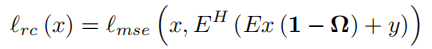
从式子上看,是希望将输出的重建结果的真实采样部分替换为真实值yyy后得到的图像,和不替换也尽可能相似。不过这样的话似乎和lucl_{uc}luc没什么区别?只不过一个比的是零填充其余部分,一个比的是用重建值填充其余部分的图像的MSE损失,这有影响吗?
Contrastive Representaion Loss
表示为lcll_{cl}lcl,用来尽可能增加两个自网络输出结果的相似性:

特别注意的是这里的zzz是输出经过额外一个1024大小的全连接层+ReLU的expander来实现的,z1=h1(x1)z_1=h_1(x_1)z1=h1(x1),z2=h2(x2)z_2=h_2(x_2)z2=h2(x2)。sim()sim()sim()采用余弦相似度,作者通过该损失函数最大化两个网络输出的相似。不过从代码上来看h1=h2h_1=h_2h1=h2。
实验结果
作者在fastMRI的多线圈膝盖数据集和一个自己的大脑数据集上做了实验,尝试了三种不容的降采样mask。对比了SENSE,Variational-Net,U-Net-256,SSDU(上一篇文章),Supervised-MoDL。反正结果基本是仅次于Supervised MoDL。
作者验证了Contrastive Loss的作用,使用只使用单个网络自监督Single-Net(没说什么方法,应该是UC损失),只使用UC的PARCEL模型Parallel-Net,加入了CL损失的PARCEL模型CL,对比如下:
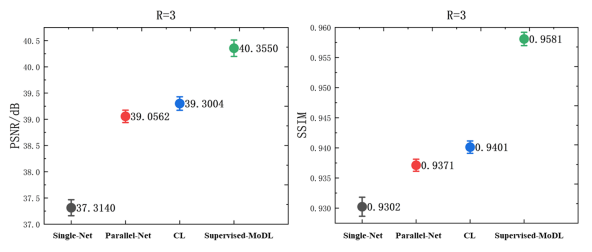
下一节中进行了更详细的比较,如下:
相关文章:
深度学习无监督磁共振重建方法调研(二)
深度学习无监督磁共振重建方法调研(二)Self-supervised learning of physics-guided reconstruction neural networks without fully sampled reference data(Magnetic Resonance in Medicine 2020)模型设计实验结果PARCEL: Physi…...
蓝桥杯入门即劝退(十九)两两交换链表
-----持续更新蓝桥杯入门系列算法实例-------- 如果你也喜欢Java和算法,欢迎订阅专栏共同学习交流! 你的点赞、关注、评论、是我创作的动力! -------希望我的文章对你有所帮助-------- 一、题目描述 给你一个链表,两两交换其中…...

【Java 面试合集】接口以及抽象类
接口以及抽象类 1. 概述 嗨,【Java 面试合集】又来了,今天给大家分享的内容是接口以及抽象类。一看这个概念很多人都知道,但是方方面面的细节不一定知道哦,今天我们就从方方面面的细节来讲讲 2. 相同点: 都是上层的抽…...

LeetCode 2391. 收集垃圾的最少总时间
给你一个下标从 0 开始的字符串数组 garbage ,其中 garbage[i] 表示第 i 个房子的垃圾集合。garbage[i] 只包含字符 ‘M’ ,‘P’ 和 ‘G’ ,但可能包含多个相同字符,每个字符分别表示一单位的金属、纸和玻璃。垃圾车收拾 一 单位…...

【PMP考试最新解读】第七版《PMBOK》应该如何备考?(含最新资料)
PMP新版大纲加入了ACP敏捷管理的内容,而且还不少,敏捷混合题型占到了 50%,前不久官方也发了通知8月启用第七版《PMBOK》,大家都觉得考试难度提升了,我从新考纲考完下来,最开始也被折磨过一段时间࿰…...

金三银四软件测试面试如何拿捏面试官?【接口测试篇】
九、接口测试 9.1 接口测试怎么测 (jmeter版本) 首先开发会给我们一个接口文档,我们根据开发给的接口文档,进行测试点的分析,主要是考虑正常场景与异常场景,正常场景,条件的组合,…...

Hive基操
数据交换 //hive导出到hdfs /outstudentpt 目录 0: jdbc:hive2://guo146:10000> export table student_pt to /outstudentpt; //从hdfs导入到hive 0: jdbc:hive2://guo146:10000> import table studentpt from /outstudentpt; 数据排序 Order by会对所给的全部数据进行…...

CSS(配合html的网页编程)
续上一篇博客,CSS是前端三大将中其中的一位,主要负责前端的皮,也就是负责html的装饰.一、基本语法规则也就是:选择器若干属性声明(选中一个元素然然后进行属性声明)CSS代码是放在style标签中,它可以放在head中也可以放在body中 ,可以放到代码的任意位置.color也就是设置想要输入…...
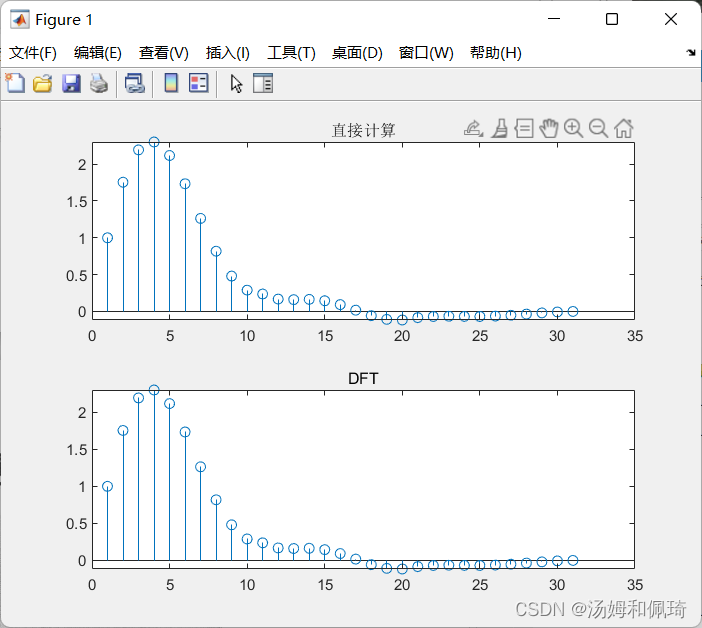
MATLAB/Simulink 通信原理及仿真学习(三)
文章目录MATLAB/Simulink 通信原理及仿真学习(三)3. 通信信号与系统分析3.1 离散信号和系统3.1.1 离散信号3.1.2 离散时间信号3.1.3 信号的能量和功率3.2 傅里叶(Fourier)分析3.2.1 连续时间信号的Fourier变换3.2.2 离散时间信号的…...
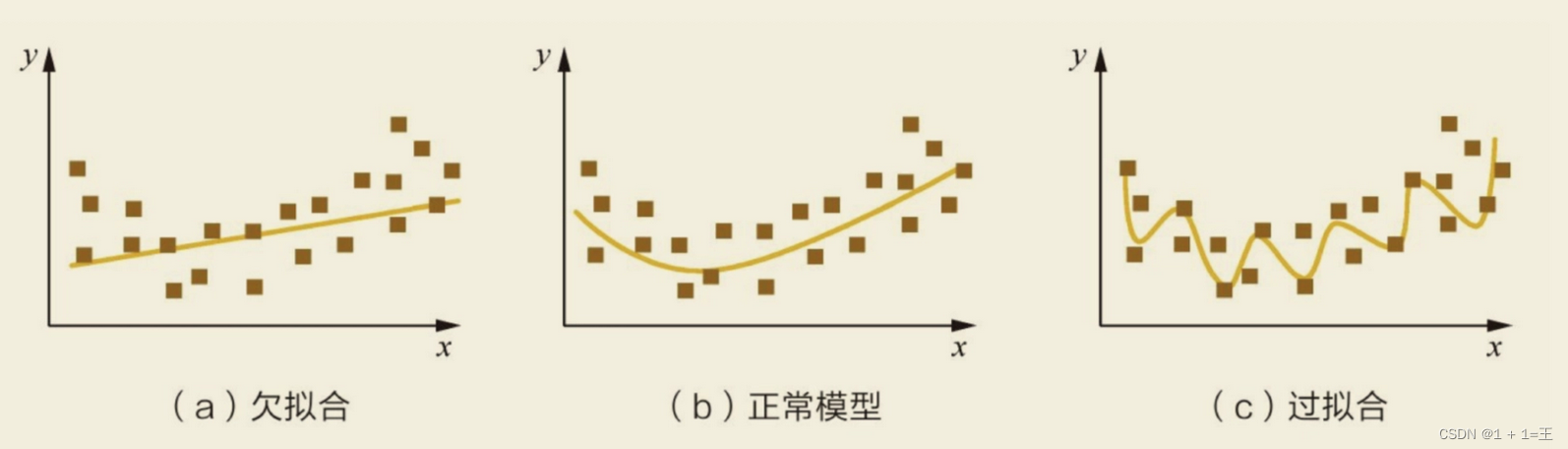
如何解决过拟合与欠拟合,及理解k折交叉验证
模型欠拟合:在训练集以及测试集上同时具有较⾼的误差,此时模型的偏差较⼤; 模型过拟合:在训练集上具有较低的误差,在测试集上具有较⾼的误差,此时模型的⽅差较⼤。 如何解决⽋拟合: 添加其他特…...
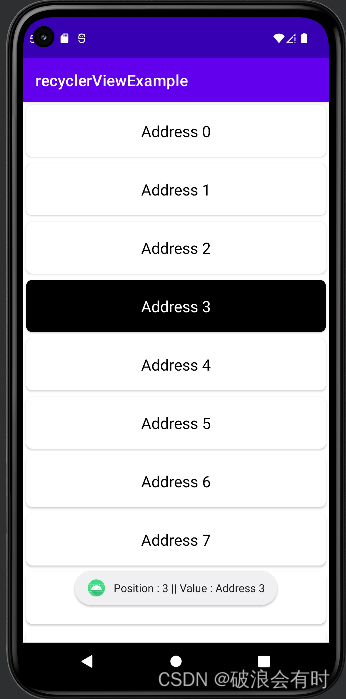
Kotlin 34. recyclerView 案例:显示列表
Kotlin 案例1. recyclerView:显示列表 这里,我们将通过几个案例来介绍如何使用recyclerView。RecyclerView 是 ListView 的高级版本。 当我们有很长的项目列表需要显示的时候,我们就可以使用 RecyclerView。 它具有重用其视图的能力。 在 Re…...

JAVA练习58-汉明距离、颠倒二进制位
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 前言 一、题目1-汉明距离 1.题目描述 2.思路与代码 2.1 思路 2.2 代码 二、题目2-颠倒二进制位 1.题目描述 2.思路与代码 2.1 思路 2.2 代码 总结 前言 提示…...

优炫数据库百城巡展,成都首站圆满举行
2月17日,由四川省大数据发展研究会、北京优炫软件股份有限公司联合举办的“首届四川省推进信息技术应用创新产业服务研讨会暨优炫数据库百城巡展成都首站隆重举行。此次活动是优炫数据库百城巡展的起点站,更是国产数据库市场美好乐章的一次强力鸣奏。 来…...

【20230210】二叉树小结
二叉树的种类二叉树的主要形式:满二叉树和完全二叉树。满二叉树深度为k,有2^k-1个节点的二叉树完全二叉树除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。二叉搜索树…...
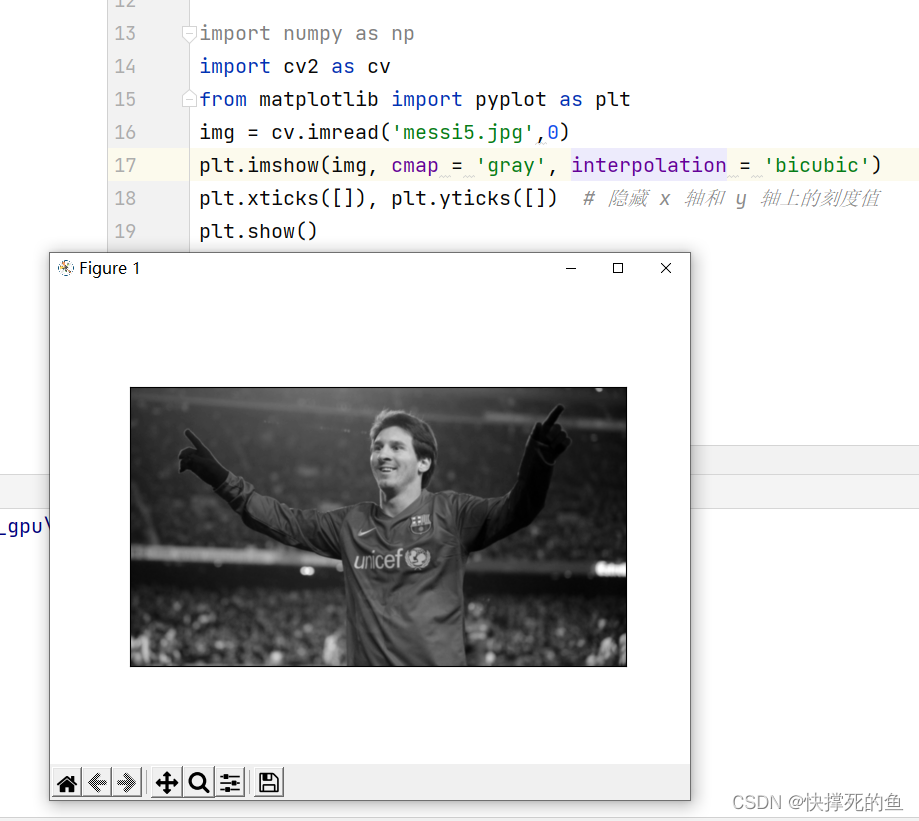
openCV—图像入门(python)
目录 目标 使用OpenCV 显示图像 写入图像 总结使用 使用Matplotlib 注:图片后续补充 目标 在这里,你将了解如何使用Python编程语言中的OpenCV库,实现读取、显示和保存图像的功能。具体来说,你将学习以下函数的用法…...
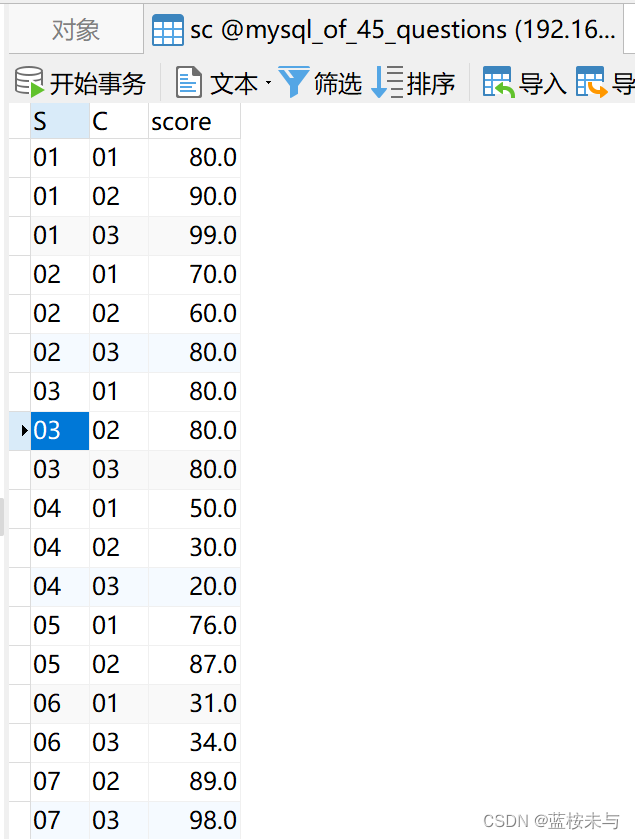
关于一个Java程序员马上要笔试了,临时抱佛脚,一晚上恶补45道简单SQL题,希望笔试能通过
MySQL随手练 / DQL篇 MySQL随手练——DQL篇 题目网盘下载:https://pan.baidu.com/s/1Ky-RJRNyfvlEJldNL_yQEQ?pwdlana 初始数据 表 course 表 student 表 teacher 表 sc 答案 :) —> :( —> :) 1. 查询 "01"课程比"02"课程成绩高的学生…...

PyTorch深度学习实战
本专栏分为两大部分,专栏内容如下: 第1部分 探讨PyTorch与其他深度学习框架的区别。 如何在PyTorch Hub中下载和运行模型。 PyTorch的基本构建组件——张量 展示不同类型的数据如何被表示为张量,以及深度学习模型期望构造什么样的张量。 梯度…...
leetcode 1011. Capacity To Ship Packages Within D Days(D天内运送包裹的容量)
数组的每个元素代表每个货物的重量,注意这个货物是有先后顺序的,先来的要先运输,所以不能改变这些元素的顺序。 要days天内把这些货物全部运输出去,问所需船的最小载重量。 思路: 数组内数字顺序不能变,就…...

支持向量机SVM详细原理,Libsvm工具箱详解,svm参数说明,svm应用实例,神经网络1000案例之15
目录 支持向量机SVM的详细原理 SVM的定义 SVM理论 Libsvm工具箱详解 简介 参数说明 易错及常见问题 SVM应用实例,基于SVM的股票价格预测 支持向量机SVM的详细原理 SVM的定义 支持向量机(support vector machines, SVM)是一种二分类模型&a…...
Mac 上搭建 iOS WebDriverAgent 环境
文章目录Mac环境搭建配置 Xcode 生成 WDA常见问题brew 安装失败Mac环境搭建 macOS 系统电脑:12.6.2 Xcode:14.0.1(xcodebuild -version) appium Desktop:1.21.0 (下载链接) Appium Desktop 1.22.0 ,从该版…...
:输入你的GPU型号/任务类型/预算,3步锁定最优解)
DeepSeek模型版本选择终极决策树(2024Q3权威更新):输入你的GPU型号/任务类型/预算,3步锁定最优解
更多请点击: https://codechina.net 第一章:DeepSeek模型版本选择终极决策树(2024Q3权威更新):输入你的GPU型号/任务类型/预算,3步锁定最优解 选择适配的 DeepSeek 模型版本是高效落地大模型应用的关键前提…...

2026论文写作工具红黑榜:AI论文工具怎么选?别再瞎找了!
2026年论文写作工具红黑榜出炉,红榜优先推荐千笔AI、ThouPen、豆包,适配国内学术规范,提升写作效率;黑榜需避开低质免费工具、无真实引用平台、过度依赖全文生成的工具。选择时应按需求匹配三维模型(需求匹配度 - 数据…...

卖电机怎么找客户?下游工厂在哪里
卖电机找客户,本质是找用电机的下游工厂,核心难点是拿到这些下游厂的名单和联系方式。展会遇到的多半是同行,百度搜来的多半是询价投机客,真正批量采购电机的工厂躲在各地产业带里,不主动露面。这篇从下游映射、传统渠…...

BooruDatasetTagManager:如何用AI智能标注工具将图像数据集处理效率提升10倍
BooruDatasetTagManager:如何用AI智能标注工具将图像数据集处理效率提升10倍 【免费下载链接】BooruDatasetTagManager 项目地址: https://gitcode.com/gh_mirrors/bo/BooruDatasetTagManager 你是否曾经为AI模型训练准备数据集时,面对数千张需要…...

终极指南:5分钟快速上手Eclipse Ditto数字孪生平台
终极指南:5分钟快速上手Eclipse Ditto数字孪生平台 【免费下载链接】ditto Eclipse Ditto™: Digital Twin framework of Eclipse IoT - main repository 项目地址: https://gitcode.com/gh_mirrors/ditto6/ditto 想要在物联网项目中轻松管理成千上万的设备吗…...

Codex vs. Claude Code:我的发现
“你试过 Codex 搭配 GPT-5.5 了吗?我刚用 40 分钟重建了整个认证模块。上周用 Claude 做同样的事花了三个小时。” 我回复了一句"有意思",然后继续做手头的事。我使用 Claude Code 已近一年,已经围绕它建立了整套工作流——CLAUD…...

Taotoken 的 API Key 分级管理与审计日志功能在安全合规中的实际价值
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken 的 API Key 分级管理与审计日志功能在安全合规中的实际价值 在企业级应用开发中,将大模型能力集成到业务系统…...

如何永久解锁Cursor Pro功能:面向开发者的完整解决方案
如何永久解锁Cursor Pro功能:面向开发者的完整解决方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your tr…...

Java中的Comparator 和JS中的回调函数好相似
Comparator 在 Java 中的地位,非常像 JavaScript 中 Array.prototype.sort() 那个接收的 回调函数 (Comparison Function)。1. Comparator 是什么?在 Java 中,Comparator 是一个接口,它的核心作用是定义“比较逻辑”。在 Java 8 之…...

如何用3个步骤建立完全私有的点对点文件同步网络?
如何用3个步骤建立完全私有的点对点文件同步网络? 【免费下载链接】syncthing-android Wrapper of syncthing for Android. 项目地址: https://gitcode.com/gh_mirrors/sy/syncthing-android 你是否曾因云端服务的隐私隐患而犹豫不决?是否厌倦了每…...