关于一个Java程序员马上要笔试了,临时抱佛脚,一晚上恶补45道简单SQL题,希望笔试能通过
MySQL随手练 / DQL篇
MySQL随手练——DQL篇
题目网盘下载:https://pan.baidu.com/s/1Ky-RJRNyfvlEJldNL_yQEQ?pwd=lana
初始数据
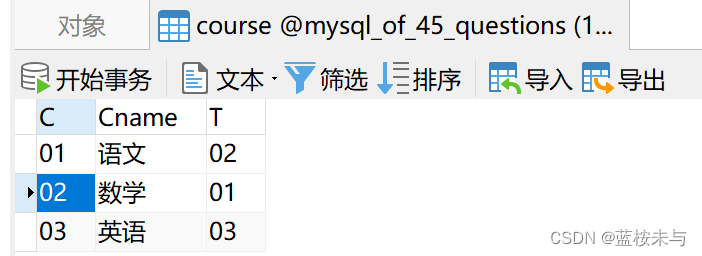 表 course 表 course | 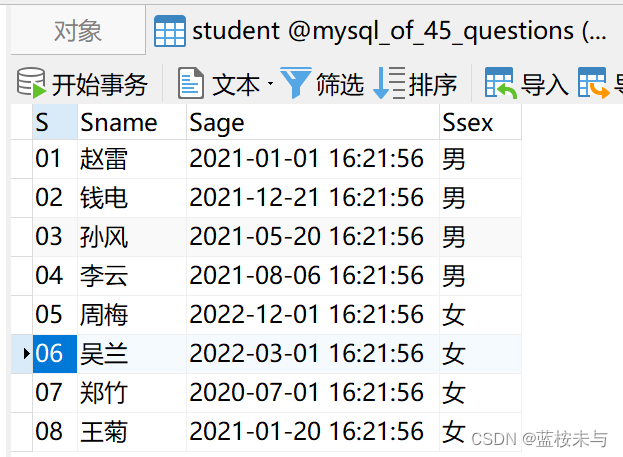 表 student 表 student | 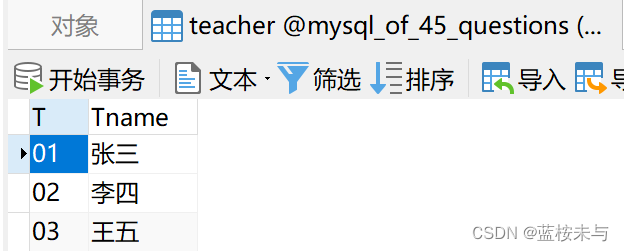 表 teacher 表 teacher | 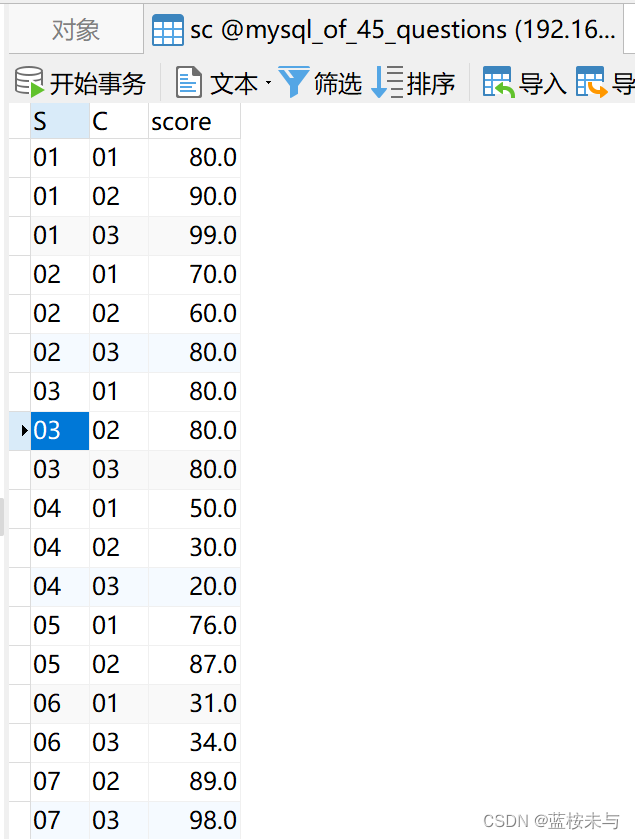 表 sc 表 sc |
答案 :) —> :( —> :)
1. 查询 "01"课程比"02"课程成绩高的学生的信息及课程分数
SELECTc.S,c.Sage,c.Sname,c.Ssex,a.C AS C1,a.score AS score1,b.C AS C2,b.score AS score2
FROMsc aINNER JOIN sc b ON a.S = b.SINNER JOIN student c ON b.S = c.S
WHEREa.C = '01' AND b.C = '02' AND a.score > b.score
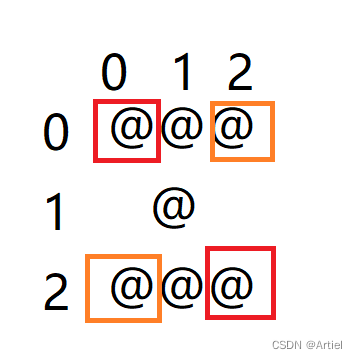
1.1 查询同时存在" 01 “课程和” 02 "课程的情况
SELECTa.S,a.C AS C1,a.score AS score1,b.C AS C2,b.score AS score2
FROMsc aINNER JOIN sc b ON a.S = b.S AND a.C = '01' AND b.C = '02'
1.2 查询存在" 01 “课程但可能不存在” 02 "课程的情况(不存在时显示为 null )
SELECTa.S,a.C AS C1,a.score AS score1,b.C AS C2,b.score AS score2
FROMsc aLEFT JOIN sc b # RIGHT JOIN sc bON a.S = b.S AND b.C = '02'
WHEREa.C = '01'
1.3 查询不存在"01 “课程但存在” 02 "课程的情况
SELECTa.S,a.C,a.score
FROMsc aLEFT JOIN sc b ON a.S = b.S AND b.C = '01'
WHEREa.C = '02' AND IFNULL( b.c, 'null' ) = 'null'
# WHERE a.C = '02' AND b.c IS NULL
问题环节:
一、题1.2中为什么LEFT JOIN ON后面接AND 左表a.C = '01’无效?题1.2中为什么RIGHT JOIN ON 后面接AND 右表b.C = '02’无效?题1.1中为什么INNER JOIN ON 后面接AND 左表a.C = ‘01’ AND 右表b.C = '02’却有效呢?
实现INNER JOIN和OUTER JOIN都是按照ON后面条件进行条件判断后进行笛卡尔积拼接,将符合条件的数据行标记为true,最后根据各自的特性生成临时表。而区别就在这特性上面,INNER JOIN是全连接,只有两表中都符合ON AND后面条件的数据才会保留;OUTER JOIN是左外连接(右外连接),以左表(右表)为主体,右表(左表)有符合的数据就保留,没有展示null。通俗点讲:INNER JOIN和OUTER JOIN都是将两表中都符合ON AND后面条件的数据进行保留,但OUTER JOIN要满足自己的特性,所以会把不符合条件的数据用null展示,所以LEFT JOIN ON后面接AND 左表a.C = '01’无效和RIGHT JOIN ON 后面接AND 右表b.C = '02’无效,单纯就是进行了暗箱操作,我们没看到
二、IS NULL能不能优化一下?
IFNULL() > IS NULL > ISNULL()
2. 查询平均成绩大于等于60分的同学的学生编号,姓名和平均成绩
SELECTa.S,a.Sname,AVG( b.score ) AS score_avg
FROMstudent aINNER JOIN sc b ON a.S = b.S
GROUP BYa.Sname
HAVINGscore_avg >= 60
问题环节:
一、分组聚合函数作用域?
DQL执行顺序:FROM > ON >JOIN > WHERE > GROUP BY > HAVING > SELECT > DISTINCT > ORDER BY > LIMIT
GROUP BY分组后才能使用,所以HAVING、SELECT、ORDER BY 都可以
二、DQL有执行顺序,那DML呢?
MySQL 采用了一种 WAL(先写日志再写磁盘) 技术,涉及两个日志文件和MySQL服务层及引擎层(InnoDB)(bin log和redo log:这部分不懂的,先去了解)。
下面针对以下这句DML语句进行分析:update table set value = ‘newValue‘ where id = 1;
简单推演: 从内存中取出id=1的那行数据(如果内存中不存在就从磁盘中查询并放入内存),修改对应字段数据,存入内存,等待回刷到磁盘。<解说存在一致性问题:服务层记录bin log,引擎层记录redo log>
初级推演:采用2PC保证 DML经过MySQL服务层执行器进入引擎层,InnoDB 引擎去查看当前内存中是否存在该数据行,如果存在之间从内存中取出,如果不在那么会从磁盘中 load 到内存之后再从内存中取出相应数据行,然后将数据行进行更新并将新行写入内存中,之后就会开始写日志,首先是 redo log的写入(此时进入prepare状态),最后进行事务的提交, bin log、redo log的写入(此时进入commit状态)
进阶推演: redo log三种形态(内存< redo log buffer >、文件系统缓存< page cache >、磁盘< disk >)。
DML经过MySQL服务层执行器进入引擎层,InnoDB 引擎去 引擎层buffer pool中获取id=1的数据行,不存在就从disk中获取然后load到 buffer pool。存在就从相应的数据页中取出给数据行进行修改再放入 buffer pool,同时将操作经过write position记录到redo log buffer(prepare状态)并且返回结果,事务提交, bin log、redo log的写入(此时进入commit状态)
究极推演: 由你完成,我顶不住了。。。。。。
三、简单介绍MySQL 8.0服务层
一条SQL语句的旅程:
- 1、解析阶段:解析为一颗Parser Tree
- 2、准备阶段:经历Resolve和Transform形成Abstract Syntax Tree
- 3、优化阶段:SQL语句优化
- 4、执行阶段:推向引擎层
3. 查询在sc表存在成绩的学生信息
SELECTa.S,a.Sname,a.Sage,a.Ssex
FROMstudent aLEFT JOIN sc b ON a.S = b.S
WHEREIFNULL( b.score, 'null' ) != 'null'
GROUP BYa.S
问题环节:
一、DISTINCT a.S,a.Sname,a.Sage,a.Ssex失效?怎么指针对a.S去重?
首先并没有失效,需要a.S,a.Sname,a.Sage,a.Ssex都相同才能去重。
针对a.S去重,可以用GROUP BY a.S、DISTINCT(a.S)、GROUP_CONCAT(DISTINCT a.S)结合GROUP BY a.S
4. 查询所有同学的学生编号,学生姓名,选课总数,所有课程总成绩(没成绩显示为0)
SELECTa.S,a.Sname,COUNT( a.S ) AS course_sum,IFNULL( SUM( b.score ), 0 ) AS score_sum
FROMstudent aLEFT JOIN sc b ON a.S = b.S
GROUP BYa.S
问题环节:
一、替换函数?
IFNULL(b.score,0.0),COALESCE(b.score,0.0)
5. 查询李姓老师的数量
SELECTCOUNT( t.T )
FROMteacher t
WHEREt.Tname LIKE '李%'
6. 查询学过张三老师授课的同学信息
SELECTa.S,a.Sage,a.Sname,a.Ssex
FROMteacher tLEFT JOIN course c ON t.T = c.TRIGHT JOIN sc b ON c.C = b.CRIGHT JOIN student a ON a.S = b.S
WHEREt.Tname = '张三'
7. 查询没有学全所有课程的同学的信息
SELECTa.S,a.Sname,a.Sage,a.Ssex
FROMstudent aLEFT JOIN sc b ON a.S = b.S
GROUP BYa.S
HAVINGCOUNT( a.S ) < ( SELECT COUNT( 1 ) FROM course );
8.查询至少有一门课与学号为" 01 "的同学所学相同的同学的信息
SELECTa.S,a.Sname,a.Sage,a.Ssex
FROMsc bINNER JOIN sc d ON b.C = d.CLEFT JOIN student a ON d.S = a.S
WHEREb.S = '01' AND d.S <> '01'
GROUP BYd.S
9. 查询和’01’号同学学习的课程完全相同的其它同学的信息
SELECTa.S,a.Sname,a.Sage,a.Ssex
FROMsc bINNER JOIN sc d ON b.C = d.CLEFT JOIN student a ON d.S = a.S
WHEREb.S = '01' AND d.S <> '01'
GROUP BYd.S
HAVINGCOUNT( d.s ) = ( SELECT COUNT( S ) FROM sc WHERE S = '01' );
问题环节:
一、in会影响查询速度吗?
因值而定,in 的值不要超过 500 个,in 操作可以更有效的利用索引,那500哪里来的:IN查询字段值的个数受eq_range_index_dive_limit这个参数影响,建议个数不要超过该参数所配置的大小。
对于in值大的,可以分批查询,然后union all
10. 查询没有学过"张三"老师任意一门课程的学生信息
SELECTd.S,d.Sname,d.Sage,d.Ssex
FROMcourse cINNER JOIN teacher t ON c.T = t.T AND t.Tname = '张三'LEFT JOIN sc b ON c.C = b.CINNER JOIN student a ON a.S = b.SRIGHT JOIN student d ON a.S = d.S
WHEREIFNULL( a.S, 'null' ) = 'null'
11. 查询两门课及以上不及格课程的同学的学号,姓名以及平均成绩
SELECTa.S,a.Sname,AVG( b.score ) AS score_avg
FROMsc bINNER JOIN student a ON b.S = a.S AND b.score < 60 LEFT JOIN sc d ON b.S = d.S GROUP BY b.S HAVING COUNT( b.S ) >= 2
问题环节:
一、笛卡尔积乘积会不会影响求平均值?
以上面答案中出现的情况是LEFT JOIN sc d 因为ON b.S = d.S都不是唯一id导致出现笛卡尔积乘积现象,但,并不会影响b.score求平均值,因为(SUM(b.score)*n)/(COUNT(b.score)*n),分子分母都乘上n
12. 检索" 01 "课程分数小于 60,按分数降序排列的学生信息
SELECT*
FROMsc bINNER JOIN student a ON b.S = a.S AND b.score < 60
WHEREb.C = '01'
ORDER BYb.S DESC
13. 按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
SELECTa.S,a.Sname,d.score,k.score_avg
FROM(SELECTb.S,AVG( b.score ) AS score_avg FROMsc b GROUP BYb.S ORDER BYAVG( b.score ) DESC ) kLEFT JOIN sc d ON k.S = d.SLEFT JOIN student a ON k.S = a.S
14. 查询各科成绩最高分、最低分和平均分:
以如下形式显示:课程 ID,课程 name,最高分,最低分,平均分,及格率,中等率,优良率,优秀率 及格为>=60,中等为:70-80,优良为:80-90,优秀为:>=90 要求输出课程号和选修人数,查询结果按人数降序排列,若人数相同,按课程号升序排列.
SELECTb.C,c.Cname,MAX( b.score ) AS score_max,MIN( b.score ) AS score_min,AVG( b.score ) AS score_avg,SUM(IF( b.score >= 60, 1, 0 ))/ COUNT( b.S ) AS pass_rate,SUM(IF( b.score >= 70 AND b.score < 80, 1, 0 ))/ COUNT( b.S ) AS medium_rate,SUM(IF( b.score >= 80 AND b.score < 90, 1, 0 ))/ COUNT( b.S ) AS excellent_rate,SUM(IF( b.score >= 90, 1, 0 ))/ COUNT( b.S ) AS excellence_rate,COUNT( 1 ) AS cons
FROMsc bINNER JOIN course c ON b.C = c.C
GROUP BYb.C
ORDER BYCOUNT( 1 ) DESC,b.C ASC
15. 按各科成绩进行排序,并显示排名
SELECTb.C,b.S,b.score,@rank := @rank + 1 AS rk
FROMsc b,(SELECT@rank := 0 ) AS t
ORDER BYb.score DESC
15.1 按各科成绩进行排序,并显示排名, Score 重复时合并名次
SELECTb.C,b.S,@score := score AS score,
CASEWHEN @score = b.score THEN@rank ELSE @rank := @rank + 1 END AS rk
FROMsc b,(SELECT@rank := 0,@score := 0 ) AS t
ORDER BYb.score DESC
16. 查询学生的总成绩,并进行排名,总分重复时保留名次空缺
SELECT
CASEWHEN@score = s.score_sum THEN'' ELSE @rank := @rank + 1 END AS rk,@score := s.score_sum AS score FROM( SELECT SUM( score ) AS score_sum FROM sc GROUP BY S ORDER BY score_sum DESC ) s,(SELECT@rank := 0,@score := NULL ) t
17. 统计各科成绩各分数段人数:课程编号,课程名称,[100-85) ,[85-70),[70-60),[60-0]及所占百分比
SELECTc.C,c.Cname,COUNT( 1 ) AS '人数',SUM(IF( b.score > 85 AND b.score <= 100, 1, 0 ))/ COUNT( 1 ) AS '[100-85)',SUM(IF( b.score > 70 AND b.score <= 85, 1, 0 ))/ COUNT( 1 ) AS '[85-70)',SUM(IF( b.score > 60 AND b.score <= 70, 1, 0 ))/ COUNT( 1 ) AS '[70-60)',SUM(IF( b.score > 0 AND b.score <= 60, 1, 0 ))/ COUNT( 1 ) AS '[60-0]'
FROMsc bINNER JOIN course c ON b.C = c.C
GROUP BYb.C
18. 查询各科成绩前三名的记录
SELECTa.S,a.Sname,b.C,b.score
FROMsc bLEFT JOIN sc d ON b.C = d.C AND b.score < d.scoreRIGHT JOIN student a ON b.S = a.S
GROUP BYb.S,b.C,b.score
HAVINGCOUNT( 1 ) < 3
ORDER BYb.C,b.score DESC19. 查询每门课程被选修的学生数
SELECTb.C,COUNT( 1 )
FROMsc b
GROUP BYb.C
20 . 查询出只选修两门课程的学生学号和姓名
SELECT*
FROMsc b
GROUP BYb.S
HAVINGCOUNT( 1 )=2
21. 查询男生女生人数
SELECTa.Ssex,COUNT( a.Ssex ) AS sex_count
FROMstudent a
GROUP BYa.Ssex
22. 查询名字中含有「风」字的学生信息
SELECTa.S,a.Sname,a.Sage,a.Ssex
FROMstudent a
WHERELOCATE( '风', a.Sname ) > 0
问题环节:
一、给’%风%'提提速
LOCATE(substr,str)、LOCATE(substr,str, pos)、POSITION(‘substr’ INfield)、FIND_IN_SET(str,strlist)
23. 查询同名同性学生名单,并统计同名人数
SELECTa.Sname,COUNT( 1 ) AS name_count
FROMstudent aINNER JOIN student d ON a.Sname = d.Sname AND a.S <> d.S
24. 查询 1990 年出生的学生名单
SELECTa.Sname
FROMstudent a
WHEREYEAR ( a.Sage ) = '2022'
25.查询每门课程的平均成绩,结果按平均成绩降序排列,平均成绩相同时,按课程编号升序排列
SELECT*,AVG( a.score )
FROMsc a
GROUP BYa.C
ORDER BYAVG( a.score ) DESC,a.C ASC
26.查询平均成绩大于等于 85 的所有学生的学号、姓名和平均成绩
SELECTa.S,a.Sname,AVG( b.score ) AS score_avg
FROMstudent aINNER JOIN sc b ON a.S = b.S
GROUP BYa.S
HAVINGscore_avg >= 85
27. 查询课程名称为「数学」,且分数低于 60 的学生姓名和分数
SELECTa.Sname,b.score
FROMsc bINNER JOIN course c ON b.C = c.C AND c.Cname = '数学'INNER JOIN student a ON b.S = a.S
WHEREb.score < 60
28. 查询所有学生的课程及分数情况(存在学生没成绩,没选课的情况)
SELECTa.S,a.Sname,IFNULL( b.C, '未选修' ) AS C,IFNULL( b.score, 0 ) AS score
FROMstudent aLEFT JOIN sc b ON a.S = b.S
29. 查询任何一门课程成绩在 70 分以上的姓名、课程名称和分数
SELECTa.Sname,c.Cname,b.score
FROMsc bLEFT JOIN student a ON b.S = a.SLEFT JOIN course c ON b.C = c.C
WHEREb.score > 70;
30. 查询不及格的课程
SELECT DISTINCTb.C
FROMsc b
WHEREb.score < 60
31. 查询课程编号为 01 且课程成绩在 80 分以上的学生的学号和姓名
SELECTa.S,a.Sname
FROMsc bLEFT JOIN student a ON b.S = a.S
WHEREb.C = '01' AND b.score > 80
32. 求每门课程的学生人数
SELECTb.C,COUNT( b.C ) AS c_count
FROMsc b
GROUP BYb.C
33. 成绩不重复,查询选修「张三」老师所授课程的学生中,成绩最高的学生信息及其成绩
SELECTa.S,a.Sname,a.Sage,a.Ssex,b.score
FROMsc bLEFT JOIN student a ON b.S = a.SLEFT JOIN course c ON b.C = c.CINNER JOIN teacher t ON c.T = t.T AND t.Tname = '张三'
ORDER BYb.score DESC LIMIT 1
34. 成绩有重复的情况下,查询选修「张三」老师所授课程的学生中,成绩最高的学生信息及其成绩
SELECTt.S,t.Sname,t.Sage,t.Ssex,t.score
FROM(SELECTa.S,a.Sname,a.Sage,a.Ssex,b.score,dense_rank() over ( PARTITION BY b.C ORDER BY b.score DESC ) AS rk FROMsc bLEFT JOIN student a ON b.S = a.SLEFT JOIN course c ON b.C = c.CINNER JOIN teacher t ON c.T = t.T AND t.Tname = '张三' ) t
WHEREt.rk = 1
35. 查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩
SELECTb.S,b.C,b.score
FROMsc bINNER JOIN sc d ON b.S = d.S AND b.C <> d.C AND b.score = d.score
GROUP BYb.S,b.C
36. 查询每门功成绩最好的前两名
SELECTb.C,b.S,b.score
FROMsc bLEFT JOIN sc d ON b.C = d.C AND b.score < d.score
GROUP BYb.S,b.C,b.score
HAVINGCOUNT( 1 ) <= 1
ORDER BYb.C
37. 统计每门课程的学生选修人数(超过 5 人的课程才统计)
SELECTb.C,COUNT( 1 ) AS c_count
FROMsc b
GROUP BYb.C
HAVINGCOUNT( 1 ) > 5
38. 检索至少选修两门课程的学生学号
SELECTb.S,COUNT( 1 ) AS c_count
FROMsc b
GROUP BYb.S
HAVINGCOUNT( 1 ) >= 2
39. 查询选修了全部课程的学生信息
SELECTa.S,a.Sname,a.Sage,a.Ssex
FROMsc bINNER JOIN student a ON a.S = b.S
GROUP BYb.S
HAVINGcount( b.C )=(SELECTcount( 1 )
FROMcourse)
40. 查询各学生的年龄,只按年份来算
SELECTa.S,a.Sname,a.Ssex,YEAR (now())- YEAR ( a.Sage ) AS age
FROMstudent a
41. 按照出生日期来算,当前月日 < 出生年月的月日则,年龄减一
SELECTa.S,a.Sname,a.Ssex,TIMESTAMPDIFF(YEAR,a.Sage,NOW()) AS 年龄
FROMstudent a
42. 查询本周过生日的学生
SELECTa.S,a.Sname,a.Sage,a.Ssex,SUBSTR( YEARWEEK( a.Sage ), 5, 2 ) AS birth_week,SUBSTR( YEARWEEK( CURDATE()), 5, 2 ) AS now_week
FROMstudent a
WHERESUBSTR( YEARWEEK( a.Sage ), 5, 2 ) = SUBSTR( YEARWEEK( CURDATE()), 5, 2 )
43. 查询下周过生日的学生
SELECTa.S,a.Sname,a.Sage,a.Ssex,SUBSTR( YEARWEEK( a.Sage ), 5, 2 ) AS birth_week,SUBSTR( YEARWEEK( CURDATE()), 5, 2 ) AS now_week
FROMstudent a
WHERESUBSTR( YEARWEEK( a.Sage ), 5, 2 ) = SUBSTR( YEARWEEK( CURDATE()), 5, 2 )+1
44. 查询本月过生日的学生
SELECT*
FROMstudent a
WHEREEXTRACT( MONTH FROM a.Sage )= EXTRACT(MONTH
FROMCURDATE());
45. 查询下月过生日的学生
SELECT*
FROMstudent a
WHEREEXTRACT( MONTH FROM a.Sage )= EXTRACT(MONTH
FROMDATE_ADD( CURDATE(), INTERVAL 1 MONTH ));
相关文章:
关于一个Java程序员马上要笔试了,临时抱佛脚,一晚上恶补45道简单SQL题,希望笔试能通过
MySQL随手练 / DQL篇 MySQL随手练——DQL篇 题目网盘下载:https://pan.baidu.com/s/1Ky-RJRNyfvlEJldNL_yQEQ?pwdlana 初始数据 表 course 表 student 表 teacher 表 sc 答案 :) —> :( —> :) 1. 查询 "01"课程比"02"课程成绩高的学生…...

PyTorch深度学习实战
本专栏分为两大部分,专栏内容如下: 第1部分 探讨PyTorch与其他深度学习框架的区别。 如何在PyTorch Hub中下载和运行模型。 PyTorch的基本构建组件——张量 展示不同类型的数据如何被表示为张量,以及深度学习模型期望构造什么样的张量。 梯度…...
leetcode 1011. Capacity To Ship Packages Within D Days(D天内运送包裹的容量)
数组的每个元素代表每个货物的重量,注意这个货物是有先后顺序的,先来的要先运输,所以不能改变这些元素的顺序。 要days天内把这些货物全部运输出去,问所需船的最小载重量。 思路: 数组内数字顺序不能变,就…...

支持向量机SVM详细原理,Libsvm工具箱详解,svm参数说明,svm应用实例,神经网络1000案例之15
目录 支持向量机SVM的详细原理 SVM的定义 SVM理论 Libsvm工具箱详解 简介 参数说明 易错及常见问题 SVM应用实例,基于SVM的股票价格预测 支持向量机SVM的详细原理 SVM的定义 支持向量机(support vector machines, SVM)是一种二分类模型&a…...
Mac 上搭建 iOS WebDriverAgent 环境
文章目录Mac环境搭建配置 Xcode 生成 WDA常见问题brew 安装失败Mac环境搭建 macOS 系统电脑:12.6.2 Xcode:14.0.1(xcodebuild -version) appium Desktop:1.21.0 (下载链接) Appium Desktop 1.22.0 ,从该版…...

python学习笔记之例题篇NO.3
获得用户输入的一个整数N,输出N中所出现不同数字的和。 s list(set(list(input())))# ① r…...
【Kubernetes】第七篇 - Service 服务介绍和使用
一,前言 上一篇,通过配置一个 Deployment 对象,在内部创建副本集对象,副本集帮我们创建了 3 个 pod 副本 由于 pod 存在 IP 漂移现象,pod 的创建和重启会导致 IP 变化; 本篇,介绍 Service 服…...
Linux 终端复用器Tmux
目录 Tmux讲解 配置tmux 配置tmux会话 配置tmux窗口(在会话界面进行配置) 配置tmux面板 配置窗口共享同步 Tmux讲解 RHEL5/6/7使用的是screen软件包 RHEL8使用的是tumx软件包(功能更强大,更易用) tmux的三个基本…...

Hadoop集群模式安装(Cluster mode)
1、Hadoop源码编译 安装包、源码包下载地址 Index of /dist/hadoop/common/hadoop-3.3.0为什么要重新编译Hadoop源码? 匹配不同操作系统本地库环境,Hadoop某些操作比如压缩、IO需要调用系统本地库(*.so|*.dll) 修改源码、重构源码 如何…...
PTA L1-054 福到了(详解)
前言:内容包括:题目,代码实现,大致思路,代码解读 题目: “福”字倒着贴,寓意“福到”。不论到底算不算民俗,本题且请你编写程序,把各种汉字倒过来输出。这里要处理的每…...

python -- 魔术方法
魔术方法就算定义在类里面的一些特殊的方法 特点:这些func的名字前面都有两个下划线 __new__方法 相当于一个类的创建一个对象的过程 __init__方法 相当于为这个类创建好的对象分配地址初始化的过程 __del__方法 一个类声明这个方法后,创建的对象如果…...

「JVM 编译优化」提前编译器
1996 年 JDK 1.0 发布,同年 7 月 外挂即时编译器发布(JDK 1.0.2),而 Java 提前编译发布在之后几个月(IBM High Performance Compiler for Java),1998 年 GNU 组织公布 GCC 家族新成员 GNU Compi…...

Golang channel 用法与实现原理
文章目录1.简介2.用法3.三种状态4.实现原理数据结构原理概述5.小结参考文献1.简介 Golang channel 是一种并发原语,用于在不同 goroutine 之间进行通信和同步。本质上,channel 是一种类型安全的 FIFO 队列,它可以实现多个 goroutine 之间的同…...
)
jackson 序列化、反序列化的时候第一个大写单词变成小写了(属性设置不成功)
参考链接:https://www.baeldung.com/jackson-annotations 遇到的问题 之前和第三方对接,返回的接口中的属性名称是拼音字母大写,奇怪,反序列化的时候好多字段都为空,没设置进去。 因为对接前,我先用 IntelliJ IDEA …...

如何判断机器学习数据集是否是线性的
首先,线性和非线性函数之间的区别: 左边是线性函数,右边是非线性函数。 线性函数:可以简单定义为始终遵循以下原则的函数: 输入/输出=常数。 线性方程总是1次多项式(例如x+2y+3=0)。在二维情况下,它们总是形成直线;在其他维度中,它们也可以形成平面、点或超平面。它们的…...

后端基础SQL
SQL基础语法: sql对大小写不敏感,eg: SELECT 等效于 select;select: select用于从表中查找数据,select 列名 from 表名 —> 结果集::仅有查询列的结果表; SELECT * FROM 表名称 ----> 结果集: 查找表的所有数据…...
)
Ubuntu 18.04 上编译和安装内核(内核源码版本)
Ubuntu 18.04 上编译和安装内核(内核源码版本) linux发行版本为,ubuntu18.04。内核版本为5.15.7。其他版本类似。 1.下载内核源代码。可以从官方网站下载最新的内核源代码,也可以使用 Git 命令从 Linux 内核的 Git 仓库中获取最新…...

day 53|● 1143.最长公共子序列 ● 1035.不相交的线 ● 53. 最大子序和 动态规划
1143. 最长公共子序列 给定两个字符串 text1 和 text2,返回这两个字符串的最长 公共子序列 的长度。如果不存在 公共子序列 ,返回 0 。 一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些…...

运维工程师必知的十项Linux常识
1、GNU和GPL GNU计划(又称革奴计划),是由Richard Stallman(理查德斯托曼)在1983年9月27日公开发起的软件集体协作计划。它的目标是创建一套完全的操作系统。GNU也称为软件工程项目。GPL是GNU的通用公共许可证…...

C++ 11 之右值引用和移动语义
文章目录左值引用与右值引用1、左值与右值2、纯右值、将亡值3、左值引用与右值引用4、右值引用和 std::move 使用场景引用限定符移动语义—std::move()完美转发emplace_back 减少内存拷贝和移动总结c11中引用了右值引用和移动语义,可以避免无谓的复制,提…...

AArch64断点异常机制与调试实践详解
1. AArch64断点异常机制概述断点异常是处理器调试功能的核心机制,它允许开发者在特定条件下暂停程序执行,进入调试状态。在AArch64架构中,断点异常通过DBGBCR_EL1(调试断点控制寄存器)和DBGBVR_EL1(调试断点…...

人工智能通识课:深度学习框架 PyTorch
深度学习框架是连接算法理论与工程实践的重要工具。它让开发者不必从零实现张量运算、自动求导、参数更新、GPU 调度和模型保存等底层细节,而可以把主要精力放在数据处理、模型结构设计、训练策略和实验验证上。在众多深度学习框架中,PyTorch 凭借直观的…...

服务网格安全策略:定义和执行服务间的安全规则
服务网格安全策略:定义和执行服务间的安全规则 一、服务网格安全策略概述 1.1 服务网格安全策略的定义 服务网格安全策略是指在服务网格中定义和执行的安全规则,用于保护服务间通信的安全性。它包括认证、授权、加密和流量控制等方面,确保服务…...

2026保姆级教程:免费一键去图片水印的App有哪些?这几种方法一看就会
你是不是也遇到过这种抓狂的时刻?好不容易在网上找到一张绝美壁纸或实用素材,保存下来一看,角落那个水印直接毁掉了整张图的氛围。更气人的是,你尝试用相册自带的编辑功能去涂抹,结果越涂越糊,最后只能无奈…...

K210开发板固件烧录:使用kflash_gui图形化工具的完整指南
K210开发板固件烧录:使用kflash_gui图形化工具的完整指南 【免费下载链接】kflash_gui Cross platform GUI wrapper for kflash.py (download(/burn) tool for k210) 项目地址: https://gitcode.com/gh_mirrors/kf/kflash_gui 在K210开发板生态系统中&#x…...

2026亲测:专业降AI率平台选这款就对了
2026 年降 AIGC 工具已从“基础语义改写”进化为多维度智能优化系统,核心评测指标涵盖 AI 生成痕迹识别精准度、专业领域术语匹配度、文本格式完整性、长篇内容逻辑一致性、降重效果稳定性以及高校检测平台兼容性。本次测评涵盖 8 款主流工具,测试场景覆…...

云安全与合规
云安全与合规 1. 技术分析 1.1 云安全概述 云安全是云计算的关键考量: 云安全维度数据安全: 加密、访问控制网络安全: 防火墙、VPN身份管理: IAM、SSO合规性: GDPR、SOC2安全责任:服务商: 基础设施安全用户: 数据和应用安全1.2 云安全架构 安全层次物理层: 数据…...

2026年一键生成论文工具实测精选:5款神器从构思到提交全流程护航
写论文的焦虑,是每个科研人和学生都无法回避的日常。选题无从下手,文献检索耗时费力,格式排版反复调整,查重降重更是让人抓耳挠腮。到了2026年,AI工具早已不再只是“敲字机器”,而是进化成了能陪你从构思到…...

利用 Taotoken 为不同业务场景动态选择最合适的大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用 Taotoken 为不同业务场景动态选择最合适的大模型 在构建一个集成了大模型能力的应用时,一个常见的挑战是如何为不…...

Python之ansimagic包语法、参数和实际应用案例
Python ansimagic包完整详解:功能、安装、语法、案例、排错 ansimagic 是Python轻量级终端动画/字符动画工具包,专注于在命令行(CMD、Terminal、PowerShell)中生成流畅的动态字符效果、进度条、加载动画、文字动画、ASCII动画等。…...