时间序列场景下多种数据填充算法实践与对比分析
在时间序列建模任务中,模型往往对于缺失数据是比较敏感的,大量的缺失数据甚至会导致训练出来的模型完全不可用,在我前面的博文中也有写到过数据填充相关的内容,感兴趣的话可以自行移步阅读即可:
《python 基于滑动平均思想实现缺失数据填充》
本文的核心目的主要是因为实际项目中有时间序列预测建模的需求,这里需要做好前期数据的准备提取和处理工作,在这里考虑基于一些常见的处理方法整合实现各种数据填充处理算法,集成应用于项目中。
实例数据如下所示:
01/01/2011,12,6.97,98,40.5,6.36,2.28,0.09,0.17
01/02/2011,11.7,6.97,98,40.8,6.4,2.06,0.09,0.21
01/03/2011,11.4,6.97,93,53.4,6.64,1.81,0.08,0.15
01/04/2011,9.9,6.96,95,33.5,6.39,2.38,0.09,0.2
01/05/2011,9.2,7.01,99,32.2,6.5,2.23,0.08,0.22
01/06/2011,9.9,6.97,98,32.9,6.74,1.74,0.07,0.13
01/07/2011,9.2,6.93,102,22.4,7.02,1.69,0.09,0.19
01/08/2011,9.6,6.97,104,35.1,7.26,1.79,0.07,0.27
01/09/2011,11.9,6.92,103,25.5,6.13,1.61,0.08,0.18
01/10/2011,12.3,6.96,102,30.9,6.66,1.9,0.06,0.08
01/11/2011,10.7,6.99,97,36.1,7.15,3.73,0.09,0.12
01/12/2011,9.3,6.95,97,34.5,7.66,2.33,0.08,0.13
01/13/2011,9.2,6.98,95,42,8.01,3.05,0.1,0.14
01/14/2011,10.5,6.95,98,30.9,7.01,3.05,0.07,0.13
01/15/2011,11.2,6.94,98,27.2,6.61,3.41,0.08,0.13
01/16/2011,9.1,6.93,93,39.6,7.51,3.4,0.12,0.23
01/17/2011,9.1,6.92,96,31.9,7.07,2.97,0.08,0.22
01/18/2011,10,6.93,95,37.6,7.55,2.64,0.08,0.11
01/19/2011,10.8,6.9,99,33.5,7.4,2.96,0.09,0.13
01/20/2011,10.6,6.86,100,31.8,7,3,0.08,0.12
01/21/2011,9.2,6.8,99,32.6,7.32,2.92,0.07,0.07
01/22/2011,9.4,6.76,99,35.8,7.44,3.62,0.12,0.14
01/23/2011,9.9,6.7,97,35.6,7.19,3.35,0.09,0.15
01/24/2011,10,6.66,99,35.9,7.16,3.18,0.07,0.08
01/25/2011,9.7,6.61,98,34.8,7.31,3.27,0.07,0.12
01/26/2011,9.5,6.54,101,33.5,7.08,3.56,0.08,0.21
01/27/2011,9.9,6.51,102,34.8,6.55,3.54,0.08,0.15
01/28/2011,10.4,6.47,98,20.5,6.46,3.38,0.07,0.09
01/29/2011,9.3,6.52,101,29.8,7.39,3.74,0.08,0.13
01/30/2011,8.2,6.53,102,33.8,7.83,3.51,0.08,0.13
01/31/2011,8.7,6.54,101,27.8,7.65,3.3,0.07,0.15
02/01/2011,9.8,6.58,102,31.4,7.02,3.25,0.07,0.11
02/02/2011,9.8,6.63,102,32.5,7.37,3.93,0.09,0.19
02/03/2011,9.9,6.69,102,32,7.27,3.8,0.08,0.14
02/04/2011,11.9,6.72,99,26.5,6.61,3.53,0.07,0.09
02/05/2011,13.7,6.75,97,24.9,6.31,3.37,0.07,0.09
02/06/2011,15.2,6.77,97,26.2,6.04,4.03,0.09,0.14
02/07/2011,16.5,6.76,92,23.2,5.82,3.61,0.07,0.1
02/08/2011,18.3,6.7,89,21.4,4.93,3.93,0.09,0.22
02/09/2011,18.5,6.72,84,17.5,5.33,3.33,0.07,0.1
02/10/2011,18,6.7,85,21.4,5.31,3.71,0.07,0.13
02/11/2011,15,6.72,88,22.1,6.08,3.49,0.06,0.06
02/12/2011,12.8,6.66,84,23.9,7.15,3.52,0.07,0.13
02/13/2011,12.2,6.61,81,26.9,7.39,3.5,0.07,0.11
02/14/2011,10.7,6.57,83,23.8,7.62,3.57,0.08,0.14
02/15/2011,9.5,6.53,84,27.1,7.88,3.53,0.08,0.12
02/16/2011,9.1,6.51,87,35.2,8.35,3.64,0.09,0.17
02/17/2011,9.8,6.46,94,31,7.87,3.38,0.08,0.15
02/18/2011,10.4,6.45,94,35.4,8.13,3.63,0.1,0.22
02/19/2011,10.6,6.39,86,33.5,7.97,3.5,0.1,0.2
02/20/2011,11.3,6.38,88,37,8.41,3.31,0.08,0.11
02/21/2011,12.5,6.37,89,32.1,7.24,3.34,0.08,0.11
02/22/2011,13.2,6.39,87,37.5,8.09,3.93,0.12,0.12
02/23/2011,14.6,6.4,89,25.6,6.87,3.71,0.08,0.14
02/24/2011,15,6.38,87,19.2,6.19,3.6,0.07,0.12
02/25/2011,16.2,6.36,86,19.5,5.57,3.54,0.07,0.13
02/26/2011,16.4,5.61,79,16.8,4.19,3.68,0.07,0.17
02/27/2011,8.9,2.54,29,15,2.42,3.29,0.07,0.09
02/28/2011,23,6.29,86,26.4,5.45,3.85,0.09,0.12
03/01/2011,22.4,6.43,92,27.4,5.71,1.78,0.07,0.13
03/02/2011,17.5,6.33,89,30.2,6.68,2.2,0.07,0.11
03/03/2011,15.4,6.36,91,29.8,7.01,1.97,0.07,0.07
03/04/2011,13.6,6.31,89,29,7.48,1.81,0.07,0.08
03/05/2011,13.2,6.3,92,25.9,6.89,2.54,0.07,0.1
03/06/2011,13.9,6.3,99,29.2,7.16,1.83,0.06,0.08
03/07/2011,14.4,6.27,98,26,7.05,1.62,0.05,0.07
03/08/2011,14.2,6.25,100,30.1,7.21,1.47,0.06,
03/09/2011,14.6,6.2,102,29.5,7.02,1.46,0.06,
03/10/2011,15.2,6.16,105,24.1,6.69,1.57,0.05,0.28
03/11/2011,15.2,6.13,107,32.5,6.78,1.74,0.07,0.43
03/12/2011,14.4,6.1,105,28.1,7.24,1.64,0.06,0.09
03/13/2011,15.2,6.05,102,27,6.97,1.73,0.06,0.09
03/14/2011,18,6,102,26.5,6.34,1.92,0.06,0.1
03/15/2011,19.5,5.99,99,26.4,6.14,2.17,0.06,0.1
03/16/2011,15.1,6.15,111,32.5,7.01,2.83,0.08,0.13
03/17/2011,14.6,6.33,118,33.2,7.25,2.44,0.07,0.06
03/18/2011,14.6,6.38,122,30.1,7.34,2.88,0.08,0.11
03/19/2011,13.5,6.35,124,32.4,7.66,2.69,0.09,
03/20/2011,15.6,6.26,108,53.9,6.79,2.9,0.14,
03/21/2011,20.8,6.17,95,44.2,5.2,2.31,0.1,
03/22/2011,19.9,6.23,99,47.8,6.87,3.09,0.12,0.11
03/23/2011,15.3,6.31,112,48.2,8.74,2.47,0.11,0.07
03/24/2011,14.6,6.22,114,43.5,8.95,2.68,0.13,0.13
03/25/2011,15.8,6.2,113,32.9,8.6,2.63,0.12,0.08
03/26/2011,15.7,6.16,119,35.6,8.97,2.51,0.1,0.06
03/27/2011,12.7,5.35,108,31.8,8.95,2.21,0.09,0.05
03/28/2011,14.2,6.05,126,25.7,6.67,2.23,0.06,
03/29/2011,,,,,,,,
03/30/2011,,,,,,,,
03/31/2011,,,,,,,,
04/01/2011,0.25,0.25,0.25,0.25,0.25,,0.08,0.51
04/02/2011,7.8,6.36,39,8.4,3.83,0.25,0.03,0.19
04/03/2011,17.2,7.56,147,77.8,8.7,1.13,0.08,0.2
04/04/2011,11.9,7.29,148,56.5,6.06,1.99,0.07,0.28
04/05/2011,14.9,7.12,181,96.6,6.15,2.38,0.08,0.44
04/06/2011,15.5,7.12,189,75.3,6.07,2.43,0.08,0.45
04/07/2011,16.3,7.12,199,13.8,5.53,2.46,0.07,0.38
04/08/2011,16.4,7.19,192,124.7,4.61,2.37,0.08,0.17
04/09/2011,16.3,7.1,198,286.6,5.19,2.62,0.07,0.17可以看到:数据集序列中有明显的缺失值现象,如下所示:

首先来看最基础的填充处理方式,就是零值填充,核心实现如下所示:
SI = SimpleImputer(missing_values=np.nan, strategy="constant",fill_value=0)
result = SI.fit_transform(data)这种方式当然也是最不推荐的方式。
接下来来看均值填充方法:
SI = SimpleImputer(missing_values=np.nan, strategy='mean')
result = SI.fit_transform(data)上面两种填充处理都是基于sklearn模块内置的SimpleImputer方法实现的,该方法的参数详情如下所示:
class sklearn.impute.SimpleImputer(*, missing_values=nan, strategy=‘mean’, fill_value=None, verbose=0, copy=True, add_indicator=False)参数含义
missing_values:int, float, str, (默认)np.nan或是None, 即缺失值是什么。
strategy:空值填充的策略,共四种选择(默认)mean、median、most_frequent、constant。mean表示该列的缺失值由该列的均值填充。median为中位数,most_frequent为众数。constant表示将空值填充为自定义的值,但这个自定义的值要通过fill_value来定义。
fill_value:str或数值,默认为Zone。当strategy == "constant"时,fill_value被用来替换所有出现的缺失值(missing_values)。fill_value为Zone,当处理的是数值数据时,缺失值(missing_values)会替换为0,对于字符串或对象数据类型则替换为"missing_value" 这一字符串。
verbose:int,(默认)0,控制imputer的冗长。
copy:boolean,(默认)True,表示对数据的副本进行处理,False对数据原地修改。
add_indicator:boolean,(默认)False,True则会在数据后面加入n列由0和1构成的同样大小的数据,0表示所在位置非缺失值,1表示所在位置为缺失值。
仿照我上面的方式还可以构建基于中位数、众数和自定义常量这几种数据填充方式,如下所示:
#中位数
SI = SimpleImputer(missing_values=np.nan, strategy='median')
result = SI.fit_transform(data)#众数
SI = SimpleImputer(missing_values=np.nan, strategy='most_frequent')
result = SI.fit_transform(data)#自定义常量值
SI = SimpleImputer(missing_values=np.nan, strategy='constant')
result = SI.fit_transform(data)除了这些基于sklearn内置统计方法构建的填充方式之外,还可以基于模型来进行填充,本质的思想就是优先选取最易填充的维度进行填充,之后循环处理即可,这里给出基础的代码实现:
sortInds = np.argsort(X.isnull().sum(axis=0)).values
for i in sortInds:df = Xfillc = df.iloc[:,i]df = df.iloc[:,df.columns != i]dfs =SimpleImputer(missing_values=np.nan,strategy='constant',fill_value=0).fit_transform(df)Ytrain = fillc[fillc.notnull()] Ytest = fillc[fillc.isnull()] Xtrain = dfs[Ytrain.index,:] Xtest = dfs[Ytest.index,:]model.fit(Xtrain, Ytrain)Ypredict = model.predict(Xtest)X.loc[X.iloc[:,i].isnull(),i] = Ypredict
接下来就是滑动平均的数据填充思想了,这部分建议可以看前面的博文实现,更加具体详细,这里就不再展开了,滑动平均的数据填充策略主要包括:平均法和加权平均法,唯一的区别就是在移动加权的处理方法加入了权重处理。
接下来对比一下差异:
#平均
one_index_list=list(range(i-tmp,i))+list(range(i+1,i+tmp+1))
one_value=[data[h] for h in one_index_list]
one_value=[O for O in one_value if not math.isnan(O)]
one_value=[new_col_list[h] for h in one_index_list]
one_value=[O for O in one_value if not math.isnan(O)]
new_col_list[i]=sum(one_value)/len(one_value)#加权
one_index_list=list(range(i-tmp,i))+list(range(i+1,i+tmp+1))
one_value=[one_col_list[h] for h in one_index_list]
weight_list=[abs(1/(B-i)) for B in range(i-tmp,i) if not math.isnan(one_col_list[B])]+[abs(1/(L-i)) for L in range(i+1,i+tmp) if not math.isnan(one_col_list[L])]
one_w=weightGenerate(weight_list)
one_weight_value=[one_value[j]*one_w[j] for j in range(len(one_w)) if not math.isnan(one_value[j])]
new_col_list[i]=sum(one_weight_value)最后一种就是卡尔曼滤波的数据填充方式,这里我主要是基于开源的模块pykalman实现的,很简单,网上也有很多的实例,感兴趣的话可以自行研究下即可。
完成了不同类型数据填充方法的开发后, 我们以实际的数据为例,来对比下填充后的效果:

我们的数据集中共有8个维度的特征数据,依次使用上述不同的数据填充算法来对原始数据集进行填充处理,可以看到不同填充算法的差异还是比较明显的。
数据量比较多,看得可能不够真切,这里对数据集抽稀100倍,看下对比可视化效果,如下所示:

这里数据就变得非常地稀疏了,接下来我们对其加密10倍,再来看下填充算法的对比可视化效果,如下所示:

相关文章:
时间序列场景下多种数据填充算法实践与对比分析
在时间序列建模任务中,模型往往对于缺失数据是比较敏感的,大量的缺失数据甚至会导致训练出来的模型完全不可用,在我前面的博文中也有写到过数据填充相关的内容,感兴趣的话可以自行移步阅读即可: 《python 基于滑动平均…...

Mysql开启binlog
本案例基于mysql5.7.16实验 1、在linux中进入mysql查询binlog是否打开,执行命令如下: mysql -u root -p 2、查询binlog是否开启命令如下,如果log_bin为OFF则证明mysql的binlog没有打开 show variables like %log_bin%; 3、退出mysql终端&…...
【Java Web】HTML 标签 总结
目录 1.HTML 2.标签 1. head 标签 1.图标 2.样式居中 2. body 标签 1.注释 : 2.加载图片 3.加载视频 效果 4.区域 效果 5.上下跳转,页面跳转 效果 6.表格 效果 7.有序列表,无序列表 效果 8.登录 效果 9.按钮 10.多选框…...

前端面试的话术集锦第 4 篇:进阶篇下
这是记录前端面试的话术集锦第四篇博文——进阶篇下,我会不断更新该博文。❗❗❗ 1. 浏览器Eventloop和Node中的有什么区别 众所周知JS是⻔⾮阻塞单线程语⾔,因为在最初JS就是为了和浏览器交互⽽诞⽣的。 如果JS是⻔多线程的语⾔话,我们在多个线程中处理DOM就可能会发⽣问…...
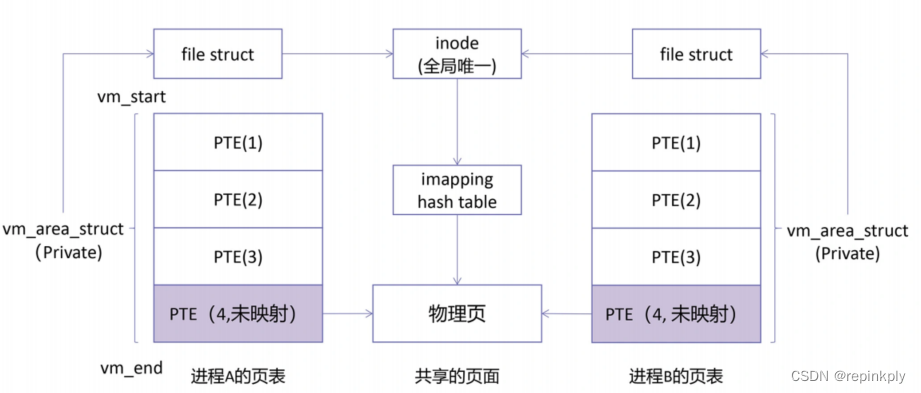
mmap详解
想写一篇文章,详细的介绍一下mmap,主要是原理、用法、mmap泄露来进行介绍。说到mmap,首先得从堆空间说起。 申请堆空间 其实,不管是 32 位系统还是 64 位系统,内核都会维护一个变量 brk,指向堆的顶部&…...
项目02—基于keepalived+mysqlrouter+gtid半同步复制的MySQL集群
文章目录 一.项目介绍1.拓扑图2.详细介绍 二.前期准备1.项目环境2.IP划分 三. 项目步骤1.ansible部署软件环境1.1 安装ansible环境1.2 建立免密通道1.3 ansible批量部署软件1.4 统一5台mysql服务器的数据 2.配置基于GTID的半同步主从复制2.1 在master上安装配置半同步的插件,再…...

【EI征稿】第二届机械电子工程与人工智能国际学术会议(MEAI 2023)
第二届机械电子工程与人工智能国际学术会议(MEAI 2023) The 2nd International Conference on Mechatronic Engineering and Artificial Intelligence 2023年第二届机械电子工程与人工智能国际学术会议(MEAI 2023)计划将于2023年…...

ros2 学习launch文件组织工程 yaml配置文件
简单范例 功能描述 使用launch文件,统一管理工程,实现img转点云,发送到img_pt的topic,然后用reg_pcl节点进行subscribe,进行点云配准处理,输出融合后的点云到map_pt的topic。最后由rviz2进行点云展示。 …...

奇舞周刊第 505 期:实践指南-前端性能提升 270%!
记得点击文章末尾的“ 阅读原文 ”查看哟~ 下面先一起看下本期周刊 摘要 吧~ 奇舞推荐 ■ ■ ■ 实践指南-前端性能提升 270% 当我们疲于开发一个接一个的需求时,很容易忘记去关注网站的性能,到了某一个节点,猛地发现,随着越来越多…...
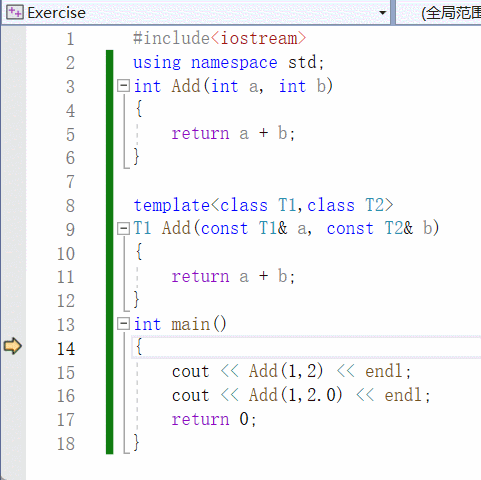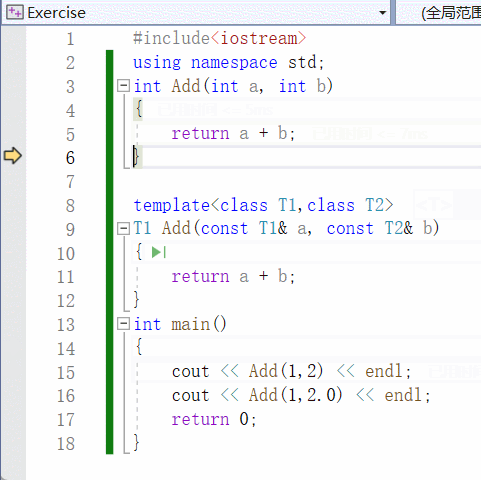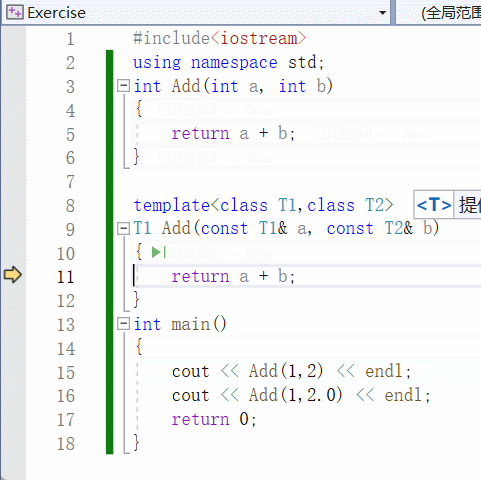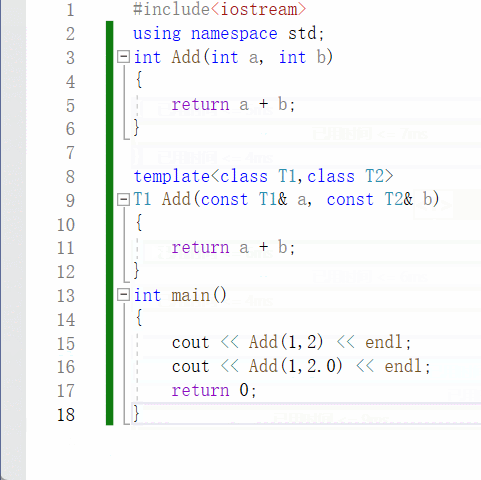
【C++】泛型编程 | 函数模板 | 类模板
一、泛型编程 泛型编程是啥? 编写一种一般化的、可通用的算法出来,是代码复用的一种手段。 类似写一个模板出来,不同的情况,我们都可以往这个模板上去套。 举个例子: void Swap(int& a, int& b) {int tmp …...

web前端——简单的网页布局案列
✨博主:命运之光 🌸专栏:Python星辰秘典 🐳专栏:web开发(简单好用又好看) ❤️专栏:Java经典程序设计 ☀️博主的其他文章:点击进入博主的主页 目录 问题背景 解决样例 …...
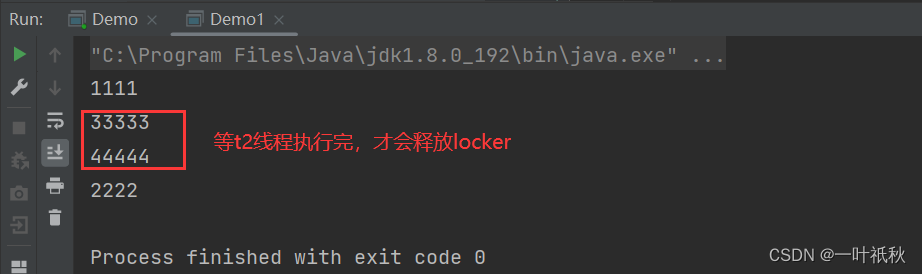
线程安全问题(3)--- wait(),notify()
前言 在多线程的环境下,我们常常要协调多个线程之间的执行顺序,而为了实现这一点,Java提供了一些方法来帮助我们完成这一点。 一,wait() 作用: 使当前线程进入等待状态 释放当前的锁 (即该方法必须和 synchrnized 关键…...
)
【Android知识笔记】进程通信(一)
一、Android Framework 用到了哪些 IPC 方式 Linux 的 IPC 方式有: 管道Socket共享内存信号信号量消息队列管道通信 管道是基于pipefs文件系统实现的,也就是多个进程通过对同一个文件进行读写来实现进程间通信。半双工,单向的,通过 pipe(fds) 系统函数调用可得到一对文件描…...

存储空间压缩6倍 ,多点DMALL零售SaaS场景降本实践
🧑💼 作者简介 冯光普:多点 DMALL 数据库团队负责人,负责数据库稳定性建设与 DB PaaS 平台建设,在多活数据库架构、数据同步方案等方面拥有丰富经验。 杨家鑫:多点高级 DBA,擅长故障分析与性能…...

BGP路由属性
任何一条BGP路由都拥有多个路径属性(Path Attributes),当路由器通告BGP路由给它的对等体时,该路由将会携带多个路径属性,这些属性描述了BGP路由的各项特征,同时在某些场景下也会影响BGP路由优选的决策。 一…...

Java面试常用函数
1. charAt() 方法用于返回字符串指定索引处的字符。索引范围为从 0 到 length() - 1。 map.getOrDefault(num, 0) :如果map存在num这个key,则返回num对应的value,否则返回0. Arrays.sort(nums); 数组排序 Arrays.asList("a","b",&q…...
linux编译curl库(支持https)
openssl下载和编译 https://www.openssl.org/source/old/ 解压 tar -xvf openssl-3.0.1.tar.gz cd openssl-3.0.1/配置 ./config如果是编译静态库加入 -fPIC no-shared 如果指定安装路径,使用 --prefix=/usr/local/openssl/选项指定特定目录 编译和安装 make sodu make i…...
)
Ei Scopus检索 | 2024年第三届能源与环境工程国际会议(CFEEE 2024)
会议简介 Brief Introduction 2024年第三届能源与环境工程国际会议(CFEEE 2024) 会议时间:2024年9月1日-3日 召开地点:新西兰奥克兰 大会官网:https://www.cfeee.org/ 2024年第三届能源与环境工程国际会议(CFEEE 2024) 将于2024年12月12日至1…...
创建定时任务)
thinkphp6(tp6)创建定时任务
使用 thinkphp6 框架中提供的命令行形式实现定时任务 一、创建一个自定义命令类文件 php think make:command Hello 会生成一个 app\command\Hello.php 命令行指令类,我们修改内容如下: <?php declare (strict_types1);namespace app\command;use …...

【学习笔记】C++ 中 static 关键字的作用
目录 前言static 作用在变量上static 作用在全局变量上static 作用在局部变量上static 作用在成员变量上 static 作用在函数上static 作用在函数上static 作用在成员函数上 前言 在 C/C 中,关键字 static 在不同的应用场景下,有不同的作用,这…...

Eclipse框架:插件化架构与开发工具深度解析
1. Eclipse框架的起源与演进Eclipse最初由IBM及其子公司Object Technology International(OTI)在1999年启动开发,初衷是为WebSphere产品线提供更好的应用开发支持。这个完全用Java编写的平台,最初投入了40名开发人员和超过4000万美…...

【权威验证版】Perplexity检索JAMA文章的7个致命误区:哈佛医学院信息学团队实测复现报告
更多请点击: https://intelliparadigm.com 第一章:Perplexity检索JAMA文章的权威验证背景与复现意义 临床证据检索的可信度挑战 在循证医学实践中,JAMA(Journal of the American Medical Association)作为顶级同行评…...

Go语言构建高效命令行工具集:claworc项目架构解析与实战应用
1. 项目概述:一个为开发者赋能的命令行工具集 最近在GitHub上闲逛,发现了一个名为 gluk-w/claworc 的项目。乍一看这个标题,有点摸不着头脑, claworc 听起来像是个自造词,结合 gluk-w 这个用户名,感觉…...

ERP生产模块设计:从BOM到完工
一、基础数据:BOM与工艺路线生产模块的核心是BOM(物料清单)和工艺路线。这两个搞不清楚,生产计划无从谈起。1. BOM表结构CREATE TABLE bd_bom (id BIGINT PRIMARY KEY AUTO_INCREMENT,bom_no VARCHAR(30) NOT NULL UNIQUE,materia…...

GDB与QEMU实现的可逆调试技术详解
1. 可逆调试技术概述可逆调试(Reversible Debugging)是一种革命性的调试技术,它允许开发者在程序执行过程中不仅能够向前执行,还能向后追溯程序状态。想象一下,如果你在调试时发现了一个内存损坏问题,传统的…...

【鸿蒙PC三方库移植适配框架解读系列】第五篇:完整流程图与角色职责
系列导读:本文是 Lycium 适配系列的第五篇,通过一张完整的流程图展示适配者、Lycium 框架和 OHOS SDK 三者之间的交互关系,并总结各环节的角色职责。 欢迎加入【开源鸿蒙PC社区】,一起共建鸿蒙化C/C三方库生态。 前言 项目说明m…...
)
自动化生产管理平台(Automatic)
1,自动化生产管理平台(Automatic) 1.1,重新定义Window样式 添加WindowChrome元素进行自定义定义 <Window x:Class"lzg.Automatic.MainWindow"xmlns"http://schemas.microsoft.com/winfx/2006/xaml/presentation"xmlns:x"…...

免费一键去图片水印的App有哪些?免费去图片水印软件推荐,2026实测好用工具盘点
免费一键去图片水印的App有哪些?免费去图片水印软件推荐,2026实测好用工具盘点 在日常用图的过程中,水印几乎是绕不开的麻烦——从网络下载的素材到平台截图,从拍摄叠加的文字标注到品牌Logo,各种形式的水印让图片用起…...

5分钟Git指南
Git——一个版本控制系统 了解Git当你建立了一个Git版本库,那么存放.git(也就是版本库)的文件夹就被称为工作区,.git内部有一个暂存区,一个叫做master的分支,一个HEAD指针能够指向分支中不同版本的文件&…...

基于Godot引擎的经典游戏重制:OpenClaw项目架构与实现深度解析
1. 项目概述与核心价值最近在独立游戏开发圈里,一个名为“OpenClaw”的开源项目热度不低。它的全称是“GambitGamesLLC/openclaw-godot”,简单说,这是一个基于Godot引擎,对经典DOS平台动作冒险游戏《The Claw》进行的开源重制版。…...