【深入浅出C#】章节10: 最佳实践和性能优化:内存管理和资源释放
一、 内存管理基础
1.1 垃圾回收机制
- 垃圾回收概述
垃圾回收(Garbage Collection)是一种计算机科学和编程领域的重要概念,它主要用于自动管理计算机程序中的内存分配和释放。垃圾回收的目标是识别和回收不再被程序使用的内存,以便释放资源并防止内存泄漏,从而提高程序的性能和稳定性。
- 内存管理问题: 在许多编程语言中,程序员需要手动分配和释放内存来存储数据和对象。这种手动管理内存的方式容易导致内存泄漏和悬挂指针等问题,因为程序员可能会忘记释放不再使用的内存,或者释放内存太早,导致程序崩溃或产生不可预测的行为。
- 垃圾对象: 在运行程序时,会创建许多对象和数据结构,其中某些对象会在一段时间后变得不再可达(即程序无法访问它们)。这些不再可达的对象被称为垃圾对象,它们占据着内存空间,但不再对程序的运行产生任何影响。
- 垃圾回收器: 垃圾回收是一种自动化的内存管理机制,它的主要工作是识别和回收不再可达的垃圾对象,以释放内存。垃圾回收器是一段特殊的代码,负责执行这项任务。不同编程语言和运行时环境可能使用不同类型的垃圾回收器,如标记-清除、引用计数、复制算法等。
- 标记和回收过程: 垃圾回收器通常通过标记不再可达的对象,然后将其回收释放内存。标记过程遍历程序的数据结构,标记所有可达的对象,而回收过程则释放未标记的对象所占据的内存。
- 垃圾回收的优点: 垃圾回收帮助程序员减轻了手动内存管理的负担,减少了内存泄漏的风险,并提高了程序的稳定性。它使程序更容易维护,并且可以减少因内存错误引起的程序崩溃和漏洞。
- 垃圾回收的开销: 尽管垃圾回收带来了许多好处,但它也有一些开销,包括在运行时执行垃圾回收的时间和计算资源。为了最小化这些开销,垃圾回收器通常会在程序运行时的适当时机触发,以避免对性能造成过大的影响。
- 垃圾回收器的种类
垃圾回收器根据其工作原理和实现方式可以分为多种不同类型。以下是一些常见的垃圾回收器种类:
- 标记-清除垃圾回收器(Mark and Sweep): 这是最基本的垃圾回收算法之一。它通过标记所有可达对象,然后清除所有未标记的对象来回收内存。标记-清除算法的主要问题是会导致内存碎片化,影响内存分配的效率。
- 引用计数垃圾回收器(Reference Counting): 引用计数垃圾回收器通过跟踪每个对象的引用计数来确定何时回收对象。当引用计数减为零时,对象被认为是垃圾并被回收。这种方法简单,但无法处理循环引用问题。
- 复制式垃圾回收器(Copying Garbage Collector): 复制式垃圾回收器将堆内存分为两个区域,通常是"from"和"to"两个区域。它在"from"区域中分配内存,然后周期性地将活跃对象复制到"to"区域,然后清除"from"区域中的所有对象。这种方法减少了内存碎片化,但需要额外的内存空间。
- 分代垃圾回收器(Generational Garbage Collector): 分代垃圾回收器将堆内存分为不同的代或分代,通常分为年轻代和老年代。大多数对象在年轻代被创建,因此年轻代的垃圾回收更频繁。只有在对象经历了多次垃圾回收后才会晋升到老年代。这种分代策略能够提高垃圾回收的效率。
- 增量式垃圾回收器(Incremental Garbage Collector): 增量式垃圾回收器将垃圾回收过程分成多个步骤,每次只执行一小部分工作,然后让程序继续执行。这可以减少垃圾回收对程序运行的中断时间,但可能会增加总体执行时间。
- 并发垃圾回收器(Concurrent Garbage Collector): 并发垃圾回收器允许垃圾回收过程与程序的其他部分并发执行,以减少对程序性能的影响。这对于需要低延迟的应用程序非常重要。
- 实时垃圾回收器(Real-time Garbage Collector): 实时垃圾回收器旨在确保垃圾回收不会导致不可预测的延迟,适用于对响应时间要求极高的实时应用。
1.2 内存分配
- 堆内存 vs 栈内存
内存分配是计算机编程中一个关键的概念,涉及到将数据存储在计算机的内存中以供程序使用。在许多编程语言中,主要有两种内存分配方式:堆内存分配和栈内存分配。它们之间有很多区别,主要取决于数据的生命周期、访问方式和分配开销等因素。以下是堆内存和栈内存的主要区别:
-
生命周期:
- 堆内存: 堆内存通常用于存储动态分配的对象和数据结构,其生命周期可能是不确定的。数据在堆上分配后,需要手动释放或由垃圾回收器自动回收,具体取决于编程语言和内存管理策略。
- 栈内存: 栈内存用于存储函数调用期间的局部变量和函数调用堆栈信息。栈上的数据的生命周期通常与函数的执行周期相对应,一旦函数执行完毕,栈上的数据就会自动销毁。
-
访问速度:
- 堆内存: 堆内存的访问速度相对较慢,因为它需要在堆中进行查找和分配,而且数据可能不连续存储。
- 栈内存: 栈内存的访问速度较快,因为它是线性的,数据在栈上分配和销毁的开销较低。
-
分配和释放开销:
- 堆内存: 堆内存的分配和释放通常涉及更多的开销,因为它需要在运行时动态分配和管理内存。垃圾回收器的介入也可能增加开销。
- 栈内存: 栈内存的分配和释放非常高效,只需简单地移动栈指针即可。
-
使用方式:
- 堆内存: 堆内存适用于需要长时间存储和共享的数据,以及具有不确定生命周期的数据,例如大型对象、动态数据结构、对象实例等。
- 栈内存: 栈内存适用于函数调用期间的局部变量、临时数据和函数调用堆栈信息。
-
容量:
- 堆内存: 堆内存的容量通常比栈内存大,因为它可以动态扩展以适应不同大小的数据。
- 栈内存: 栈内存的容量通常较小,受限于编程语言和操作系统的限制。
- 内存分配和释放的开销
内存分配和释放的开销是计算机程序中一个重要的性能考虑因素。不同的内存分配和释放策略可能会产生不同的开销,影响程序的性能。以下是内存分配和释放的开销以及如何优化它们的一些考虑因素:
-
堆内存分配和释放开销:
- 分配开销: 在堆上分配内存通常涉及到在堆中搜索可用的空闲内存块,这需要时间。分配较大的内存块可能会更耗时,因为需要找到足够大的连续内存块。
- 释放开销: 堆内存的释放通常需要将内存块标记为可用,并将其添加到内存分配器的可用内存池中。释放大内存块时可能会涉及到合并操作,以减少内存碎片。
-
栈内存分配和释放开销:
- 分配开销: 栈内存的分配非常高效,通常只涉及栈指针的移动,开销很小。
- 释放开销: 栈内存的释放也非常高效,因为只需要将栈指针向下移动,之前的内存就会自动被释放。栈上的数据通常是有序的,所以释放开销很小。
-
内存池和对象池: 为了减少分配和释放的开销,可以使用内存池或对象池。这些池可以预先分配一些内存块,并在需要时分配和释放这些块,而不是每次都进行堆内存分配和释放。这可以显著降低开销,特别是对于具有相似生命周期的对象。
-
分代垃圾回收: 使用分代垃圾回收可以减少堆内存的开销。因为大多数对象的生命周期很短,所以将它们分配到年轻代,年轻代的垃圾回收会更频繁,但也更快速。
-
智能指针: 在某些编程语言中,智能指针可以帮助自动管理内存。它们会在对象不再被引用时自动释放内存,从而减少了手动释放的开销。
-
内存管理工具和分析器: 使用性能分析工具和内存分析器可以帮助识别和解决内存分配和释放方面的性能问题。这些工具可以帮助你找出内存泄漏和性能瓶颈。
1.3 引用类型和值类型
- 区分引用类型和值类型
在许多编程语言中,包括C#,引用类型和值类型是两种不同的数据类型,它们在内存分配、赋值、传递和比较方面有重要的区别。下面是引用类型和值类型的主要区别:
引用类型(Reference Types):
- 内存分配方式: 引用类型的实例通常存储在堆内存中。堆内存是一种动态分配的内存,用于存储不同大小和生命周期的对象,这些对象的数据存储在堆内存中,并且可以由多个引用指向相同的对象。
- 变量存储方式: 引用类型的变量实际上存储的是一个引用(或者可以理解为指针),这个引用指向堆内存中的实际对象。因此,多个变量可以引用相同的对象。
- 生命周期: 引用类型的对象的生命周期通常由垃圾回收器管理,当没有任何引用指向一个对象时,垃圾回收器将回收它。
- 赋值和比较: 引用类型的赋值会导致两个变量引用同一个对象。比较引用类型的变量通常比较的是它们是否引用同一个对象,而不是对象的内容。
- 示例: 在C#中,类、接口、数组、委托等都是引用类型的示例。
值类型(Value Types):
- 内存分配方式: 值类型的实例通常存储在栈内存中。栈内存是一种有限大小的内存区域,用于存储方法调用期间的局部变量和函数调用堆栈信息。
- 变量存储方式: 值类型的变量直接存储实际的数据值,而不是引用。因此,每个值类型的变量都包含其自己的数据副本。
- 生命周期: 值类型的变量的生命周期通常与其所在的作用域(例如,函数)相对应。当离开该作用域时,变量会被自动销毁。
- 赋值和比较: 值类型的赋值会复制实际的数据值,而不是引用。比较值类型的变量通常比较它们的数据值是否相等。
- 示例: 在C#中,整数、浮点数、字符、枚举、结构体等都是值类型的示例。
Tip:引用类型和值类型在内存分配、变量存储、生命周期、赋值和比较等方面有很大的区别。了解这些区别对于正确使用这些数据类型以及避免潜在的错误非常重要。
- 如何选择合适的类型
选择合适的数据类型是编程中的重要决策,它会影响程序的性能、内存使用和可维护性。以下是一些指导原则,帮助你选择合适的数据类型:
- 理解数据的本质: 在选择数据类型之前,首先要深入理解要处理的数据的本质。确定数据的范围、精度、大小、生命周期以及是否需要支持特定的操作,例如算术运算、比较和集合操作。
- 使用内置数据类型: 尽可能使用编程语言提供的内置数据类型,因为它们通常是最高效和最常用的数据类型。例如,整数、浮点数、字符和布尔值都是内置类型。
- 选择合适的容器类型: 如果需要存储多个数据项,考虑使用合适的容器类型,如数组、列表、集合或字典。选择容器类型取决于数据的访问模式(顺序访问或随机访问)、数据的唯一性要求和数据的大小。
- 自定义数据结构: 如果内置数据类型和容器类型不足以满足特定需求,可以考虑自定义数据结构,如结构体或类。这样可以根据需求定义自己的数据类型,并添加自定义行为。
- 考虑性能需求: 如果性能是关键问题,了解数据类型的性能特性非常重要。例如,值类型通常比引用类型具有更高的性能,但内存开销较大。此外,选择适当的数据类型可以减少内存分配和垃圾回收的开销。
- 考虑可读性和维护性: 选择数据类型时,也要考虑代码的可读性和可维护性。使用有意义的命名和自解释的数据类型,可以使代码更易于理解和维护。
- 使用枚举: 如果数据具有一组已知的有限值,可以使用枚举类型来提高代码的可读性和类型安全性。
- 考虑平台兼容性: 在跨平台开发中,确保所选择的数据类型在目标平台上是可用的。某些数据类型可能在不同平台上有差异。
- 进行性能测试和分析: 对于性能关键的应用程序,进行性能测试和分析是必不可少的。这可以帮助你确定是否需要优化数据类型的选择以满足性能需求。
- 注重数据安全性: 在处理敏感数据时,确保选择的数据类型能够提供必要的安全性保护,例如密码哈希存储、数据加密等。
二、 最佳实践:内存管理
2.1 使用对象池
- 对象池的概念和实现
对象池(Object Pool)是一种设计模式,用于管理和重用对象,以减少对象的创建和销毁开销,从而提高性能。对象池通常用于需要频繁创建和销毁对象的情况,如线程、网络连接、数据库连接、大量短暂对象等。下面是一个简单的对象池的概念和示例C#代码:
对象池的概念:
- 创建一个池(Pool)来存储对象实例。
- 当需要一个对象时,首先从池中获取对象。
- 如果池中有可用对象,则返回一个已存在的对象;否则,创建一个新对象。
- 使用完对象后,将其归还到池中而不是销毁它。
- 对象池会维护池的大小,可以根据需要自动扩展或收缩。
C#对象池示例代码:
以下是一个简单的C#对象池示例,用于管理字符串对象。注意,这只是一个示例,实际应用中可以根据需要自定义更复杂的对象池。
using System;
using System.Collections.Generic;public class ObjectPool<T> where T : new()
{private readonly Queue<T> pool = new Queue<T>();private readonly object lockObject = new object();public T GetObject(){lock (lockObject){if (pool.Count > 0){return pool.Dequeue();}else{return new T();}}}public void ReturnObject(T item){lock (lockObject){pool.Enqueue(item);}}
}public class Program
{public static void Main(){ObjectPool<string> stringPool = new ObjectPool<string>();// 使用对象池获取和释放字符串对象string str1 = stringPool.GetObject();str1 = "Hello, Object Pool!";Console.WriteLine(str1);// 归还对象到池中stringPool.ReturnObject(str1);// 再次获取同一个对象string str2 = stringPool.GetObject();Console.WriteLine(str2); // 输出:"Hello, Object Pool!"// 这两个字符串引用的是同一个对象Console.WriteLine(object.ReferenceEquals(str1, str2)); // 输出:True}
}
在上面的示例中,ObjectPool<T> 类用于创建和管理对象池。通过调用 GetObject 方法来获取对象,通过 ReturnObject 方法将对象归还到池中。这可以减少频繁创建和销毁对象的开销,提高性能。注意,这只是一个基本的示例,实际应用中可能需要更复杂的对象池,具体取决于需求。
- 对象池的应用场景
对象池是一种常见的设计模式,适用于多种应用场景,特别是在需要频繁创建和销毁对象时,可以显著提高性能和资源利用率。以下是一些对象池的常见应用场景:
- 数据库连接池: 在数据库访问中,每次创建和销毁数据库连接会产生较大的开销。通过使用数据库连接池,可以重用已创建的数据库连接,减少了连接的创建和销毁成本,提高了数据库访问性能。
- 线程池: 在多线程应用程序中,频繁创建和销毁线程可能会导致资源浪费和性能下降。线程池维护一组空闲线程,以便在需要时将任务分配给它们,而不是创建新线程。这提高了线程的重用性和执行效率。
- 网络连接池: 在网络通信中,如HTTP请求、Socket连接等,频繁创建和关闭连接会带来显著的开销。网络连接池可以管理和重用网络连接,以降低连接建立和关闭的开销,提高网络通信性能。
- 资源管理: 在游戏开发和图形处理中,需要频繁创建和销毁纹理、音频缓冲区、模型等资源。通过使用资源池,可以缓存和重用这些资源,减少资源加载和释放的成本,提高应用程序的性能。
- 对象池: 一般情况下,创建和销毁对象都会带来一定的开销。对象池可用于管理和重用对象实例,特别是对于具有短生命周期的对象,如临时数据容器、字符串、数据库连接、线程等。
- 连接池: 在分布式系统中,频繁创建和关闭连接到其他系统的通信连接(如REST API、SOAP等)可能会产生显著的性能开销。连接池可以重用这些连接,减少连接建立和关闭的成本。
- 数据库连接池: 数据库连接通常是昂贵的资源,频繁地创建和销毁数据库连接可能会影响性能。使用数据库连接池可以缓存和重用数据库连接,降低连接的创建和销毁开销。
- 自定义对象池: 除上述场景外,你还可以根据具体需求创建自定义的对象池,用于管理和重用自定义对象类型,以提高性能和资源利用率。
2.2 避免频繁的装箱和拆箱操作
- 装箱和拆箱的含义
装箱(Boxing)和拆箱(Unboxing)是与值类型(Value Types)和引用类型(Reference Types)之间的相互转换相关的概念,通常出现在C#等编程语言中。
装箱(Boxing):
装箱是将值类型转换为引用类型的过程。当你将值类型赋值给一个接受引用类型的变量或将其存储在引用类型的集合中时,系统会自动执行装箱操作。装箱将值类型的值封装在一个堆分配的对象中,以便与引用类型的变量或集合兼容。装箱后,原始值类型的变量仍然保持不变,但它的值被封装在一个引用类型对象中。以下是一个示例,演示了装箱的过程:
int value = 42; // 值类型
object obj = value; // 装箱操作,将值类型转换为引用类型
在这个示例中,整数值 42 被装箱为一个 object 类型的引用,存储在变量 obj 中。
拆箱(Unboxing):
拆箱是将封装在引用类型中的值类型取回的过程。当你需要从引用类型中获取值类型的值时,需要进行拆箱操作。拆箱将封装在引用类型对象中的值解包成原始的值类型。以下是一个示例,演示了拆箱的过程:
int value = (int)obj; // 拆箱操作,从引用类型中获取值类型的值
在这个示例中,变量 obj 中封装的整数值被拆箱为一个 int 类型的值,存储在变量 value 中。
Tip:装箱和拆箱操作可能会引入性能开销,因为它们涉及从堆内存到栈内存的数据复制。因此,在高性能要求的代码中,应谨慎使用装箱和拆箱,尽量避免不必要的转换操作。此外,在使用装箱和拆箱时,还需要注意类型安全性,以避免运行时错误。
- 如何减少装箱和拆箱的开销
减少装箱和拆箱的开销对于提高性能是至关重要的,尤其是在高性能的应用程序中。以下是一些减少装箱和拆箱开销的方法:
-
使用泛型集合: 当需要在集合中存储值类型时,使用泛型集合(如
List<T>、Dictionary<TKey, TValue>)而不是非泛型集合(如ArrayList、Hashtable)。泛型集合不会导致装箱,因为它们在编译时已知元素的类型。List<int> list = new List<int>(); list.Add(42); // 没有装箱操作 -
使用接口和基类: 如果需要将值类型存储在通用的集合或变量中,可以将其转换为相应的接口或基类,而不是装箱。例如,可以使用
IComparable或IConvertible等接口。List<IComparable> list = new List<IComparable>(); int value = 42; list.Add(value); // 没有装箱操作 -
避免隐式装箱: 避免将值类型隐式地转换为
object或其他引用类型。尽量使用显式装箱和拆箱操作,以便在代码中明确装箱和拆箱发生的地方。int value = 42; object obj = (object)value; // 显式装箱 int newValue = (int)obj; // 显式拆箱 -
使用
ref和out关键字: 在方法参数中使用ref和out关键字可以避免装箱,因为它们允许在方法内部直接操作值类型,而不是通过引用进行操作。void ModifyValue(ref int value) {value = 50; }int number = 42; ModifyValue(ref number); // 没有装箱 -
避免装箱的数据结构: 在自定义数据结构中,尽量避免使用引用类型包装值类型。设计数据结构时,应该考虑使用值类型字段而不是引用类型字段。
public struct Point {public int X;public int Y; } -
性能分析和优化: 使用性能分析工具来识别装箱和拆箱操作的瓶颈,并进行必要的优化。性能分析可以帮助你确定哪些操作导致了装箱和拆箱,以及如何改进性能。
2.3 避免内存泄漏
- 内存泄漏的原因和危害
内存泄漏是指在程序中分配的内存资源(如堆内存)没有被正确释放或回收,导致这些资源永远无法被再次使用,从而占用了系统的内存,最终可能导致应用程序性能下降或崩溃。内存泄漏通常由以下原因引起:
- 未释放动态分配的内存: 如果程序动态分配了内存(例如使用
new或malloc函数),但忘记释放它(例如使用delete或free函数),则分配的内存将永远不会被释放。 - 循环引用: 在具有垃圾回收的语言中(如Java、C#),如果对象之间存在循环引用,并且没有适当的解除引用,垃圾回收器无法确定哪些对象应该回收,因此可能会导致内存泄漏。
- 资源未关闭: 在处理文件、网络连接、数据库连接和其他资源时,如果未正确关闭或释放这些资源,它们可能会一直占用内存,导致内存泄漏。
- 缓存未过期: 缓存是一种常见的内存泄漏来源。如果在缓存中存储对象,但没有为这些对象设置合适的过期策略,缓存中的对象可能会一直存在,占用内存。
- 事件处理未移除: 在事件驱动的编程中,如果订阅了事件但未正确移除订阅,事件处理程序可能会一直存在,防止相关对象被垃圾回收。
内存泄漏的危害包括:
- 性能问题: 内存泄漏会导致程序占用越来越多的内存,最终导致性能下降。内存资源的不断积累可能导致程序变得缓慢和不稳定。
- 资源耗尽: 内存泄漏会导致系统资源(如物理内存)耗尽。在长时间运行的应用程序中,这可能会导致系统崩溃或需要重新启动。
- 不可预测的行为: 内存泄漏可能导致应用程序出现不可预测的错误和崩溃,这些问题可能会在生产环境中出现,影响用户体验和可靠性。
- 难以诊断和修复: 内存泄漏通常很难诊断,因为它们可能会随着时间的推移逐渐累积。找出内存泄漏的根本原因并修复它们可能需要耗费大量的时间和精力。
- 内存泄漏的检测和预防方法
内存泄漏是一个常见的问题,但 fortunately,有一些方法可以帮助你检测和预防内存泄漏。以下是一些常用的方法:
检测内存泄漏:
- 内存分析工具: 使用内存分析工具来检测内存泄漏是一种有效的方法。这些工具可以帮助你跟踪对象的生命周期,发现未释放的对象,以及确定哪些对象占用了大量内存。
- 垃圾回收器日志: 在支持垃圾回收的语言中,可以启用垃圾回收器的详细日志记录,以查看哪些对象被回收,哪些没有被回收。这有助于识别潜在的内存泄漏。
- 代码审查: 审查代码并寻找潜在的内存泄漏是一种有效的方法。特别关注对象的创建和销毁,确保对象在不再需要时被正确释放。
- 性能测试: 在应用程序进行性能测试时,监视内存使用情况。如果发现内存使用不断增长,可能存在内存泄漏问题。
预防内存泄漏:
- 使用合适的数据结构和算法: 使用合适的数据结构和算法可以帮助减少内存泄漏的风险。确保选择的数据结构能够轻松释放不再需要的对象。
- 手动内存管理: 在一些编程语言中,如C和C++,开发人员需要手动管理内存。确保在分配内存后及时释放它,使用
free或delete等函数。 - 使用垃圾回收: 对于支持垃圾回收的语言(如Java、C#),使用垃圾回收器来自动管理内存。但要确保没有循环引用等问题,以免垃圾回收无法正常工作。
- 显式关闭资源: 当使用文件、数据库连接、网络连接等外部资源时,确保在不再需要时显式关闭或释放这些资源,以防止资源泄漏。
- 使用工具和分析器: 使用内存分析工具和性能分析工具来检测内存泄漏并帮助诊断问题。这些工具可以提供有关内存使用情况的详细信息。
- 测试不同情况: 在不同的应用场景下进行测试,包括长时间运行、大规模数据和高负载情况。这有助于发现潜在的内存泄漏问题。
- 定期代码审查: 定期进行代码审查,特别关注资源管理和对象的生命周期。与团队成员一起审查代码,以发现潜在的内存泄漏。
三、 资源释放
3.1 IDisposable接口和using语句
- IDisposable接口的作用
IDisposable接口是在C#中用于资源管理的重要接口之一。它定义了一个Dispose方法,用于释放非托管资源(如文件句柄、数据库连接、网络连接等)以及实现对象的资源清理逻辑。IDisposable接口的作用如下:
- 资源释放: 主要作用是在不再需要对象时,确保释放或关闭对象所持有的非托管资源,以便及时回收这些资源,从而避免内存泄漏和资源泄漏。
- 内存管理: 通过释放资源,可以减少应用程序占用的内存,从而提高应用程序的性能和资源利用率。
- 垃圾回收:
Dispose方法的调用通常伴随着对象的垃圾回收,以确保对象持有的资源得以释放。这有助于避免由于资源泄漏而导致的性能下降和系统资源耗尽。 - 资源安全性: 使用
IDisposable接口可以确保在不再需要资源时,能够正常地关闭或释放资源,从而提高应用程序的安全性。 - 清理操作: 除了释放资源,
Dispose方法还可以执行一些清理操作,例如关闭文件、删除临时文件、断开网络连接等,以确保对象在被销毁之前完成必要的清理工作。 - 代码规范性: 实现
IDisposable接口是一种良好的编码规范,它表明对象负责管理资源,并鼓励开发人员及时释放资源,以减少潜在的问题。
以下是一个使用 IDisposable 接口的示例:
public class MyResource : IDisposable
{private bool disposed = false;// 实现 IDisposable 接口的 Dispose 方法public void Dispose(){Dispose(true);GC.SuppressFinalize(this);}protected virtual void Dispose(bool disposing){if (!disposed){if (disposing){// 释放托管资源}// 释放非托管资源disposed = true;}}~MyResource(){Dispose(false);}
}
在示例中,MyResource 类实现了 IDisposable 接口,重写了 Dispose 方法,并在其中释放托管资源和非托管资源。此外,还实现了析构函数以确保资源在不被手动释放的情况下也能得到释放。
- 使用using语句管理资源
using语句是C#中用于管理资源的一种方便的语法结构。它可用于确保在使用完资源后及时释放资源,而不需要手动调用Dispose方法或使用try-finally块。using语句适用于实现了IDisposable接口的对象,以确保资源被正确释放。以下是使用using语句管理资源的示例:
using (ResourceType resource = new ResourceType())
{// 使用资源// 在 using 代码块结束时,资源将自动释放
}
下面是一些使用 using 语句管理资源的重要注意事项:
- 资源类型必须实现 IDisposable 接口: 要使用
using语句管理资源,资源类型必须实现IDisposable接口,以确保在作用域结束时可以自动调用Dispose方法。 - 资源在 using 代码块内创建: 通常,你应该在
using代码块内创建资源对象。这样,在作用域结束时,资源将自动释放。 - 资源的生命周期由 using 代码块控制: 使用
using语句时,资源的生命周期受限于using代码块。一旦代码块结束,资源就会自动释放,无论是正常结束还是由于异常而结束。 - 无需显式调用 Dispose 方法: 使用
using语句后,无需显式调用资源的Dispose方法。该方法会在代码块结束时自动调用。
下面是一个使用 using 语句管理文件流资源的示例:
using (FileStream fileStream = new FileStream("example.txt", FileMode.Open))
{// 使用文件流读取文件内容// 在 using 代码块结束时,文件流会自动关闭和释放资源
}
使用 using 语句可以帮助确保资源在不再需要时被及时释放,从而减少内存泄漏和资源泄漏的风险,提高代码的可读性和可维护性。
3.2 手动资源释放
- 手动释放资源的情景
手动释放资源通常在以下情景下发生,特别是在使用非托管资源(如文件、数据库连接、网络连接等)时,需要开发人员明确地管理和释放资源:
- 文件操作: 当应用程序打开文件并读取或写入文件内容后,必须显式关闭文件句柄,以确保文件被释放。这通常涉及到使用
FileStream、StreamReader、StreamWriter等类时,需要在使用后调用Close或Dispose方法。 - 数据库连接: 在数据库操作中,必须手动关闭数据库连接,以释放数据库资源。通常,开发人员需要使用
SqlConnection、SqlCommand等数据库相关对象,并在使用后调用Close或Dispose方法来关闭连接。 - 网络连接: 在网络通信中,打开的网络连接必须手动关闭,以释放网络资源。使用
TcpClient、NetworkStream等类时,需要在使用后调用Close或Dispose方法。 - 非托管资源: 在与操作系统或其他本机资源交互时,例如使用 P/Invoke 调用非托管函数、管理操作系统句柄(如窗口句柄、文件句柄)等,通常需要手动释放资源,以防止资源泄漏。
- 数据库事务: 在数据库事务中,如果事务完成后未提交或回滚,数据库资源可能会被锁定,直到事务被释放。因此,需要手动调用
Commit或Rollback来释放数据库资源。 - 自定义资源管理: 在某些情况下,你可能会创建自定义资源管理类,用于管理和释放自定义资源。在这种情况下,你需要实现
IDisposable接口,并在Dispose方法中释放资源。 - 缓存: 如果应用程序使用了自定义缓存,确保在不再需要缓存中的项时,手动从缓存中移除或清理这些项,以释放内存资源。
- 事件订阅: 如果对象订阅了事件,应该手动取消订阅以防止内存泄漏。未取消订阅的事件处理程序可能会阻止对象被垃圾回收。
在以上情况下,手动释放资源是为了确保资源的及时释放,避免内存泄漏和资源泄漏。通常,使用 try-finally 块或 using 语句来确保资源在使用后被正确释放。另外,对于实现了 IDisposable 接口的对象,也可以使用 using 语句来自动释放资源,提高代码的可读性和可维护性。
- 实现自定义资源释放逻辑
如果你需要实现自定义资源释放逻辑,可以通过实现IDisposable接口并在Dispose方法中编写释放资源的代码来完成。下面是一个简单的示例,演示了如何实现自定义资源释放逻辑:
using System;public class CustomResource : IDisposable
{private bool disposed = false;// 这是需要手动释放的资源,如文件句柄、网络连接等private IntPtr nativeResource = IntPtr.Zero;public CustomResource(){// 在构造函数中分配资源nativeResource = AllocateResource();}public void CustomMethod(){// 执行自定义资源的操作if (disposed){throw new ObjectDisposedException(nameof(CustomResource));}Console.WriteLine("Performing custom resource operation.");}public void Dispose(){Dispose(true);GC.SuppressFinalize(this);}protected virtual void Dispose(bool disposing){if (!disposed){if (disposing){// 释放托管资源,如果有的话}// 释放非托管资源if (nativeResource != IntPtr.Zero){DeallocateResource(nativeResource);nativeResource = IntPtr.Zero;}disposed = true;}}~CustomResource(){Dispose(false);}// 用于分配非托管资源的示例方法private IntPtr AllocateResource(){// 在这里执行分配非托管资源的操作,例如打开文件、分配内存等Console.WriteLine("Allocating custom resource.");return new IntPtr(123); // 这里只是示例}// 用于释放非托管资源的示例方法private void DeallocateResource(IntPtr resource){// 在这里执行释放非托管资源的操作,例如关闭文件、释放内存等Console.WriteLine("Deallocating custom resource.");}
}
在上述示例中,CustomResource 类实现了 IDisposable 接口,包括构造函数、自定义方法、Dispose 方法以及释放非托管资源的私有方法。在构造函数中分配了非托管资源,而在 Dispose 方法中释放了这些资源。
使用时,你可以像下面这样使用 CustomResource 类,并确保在不再需要资源时调用 Dispose 方法或使用 using 语句:
using (CustomResource resource = new CustomResource())
{resource.CustomMethod(); // 执行资源操作
} // 在 using 块结束时,资源将自动释放
这样,你就可以自定义资源释放逻辑,确保在不再需要资源时释放它们,避免资源泄漏和内存泄漏。
3.3 垃圾回收与资源释放
- 垃圾回收如何处理资源释放
垃圾回收用于释放不再被引用的对象,以回收它们占用的内存。虽然垃圾回收主要关注托管堆上的托管对象(由CLR或虚拟机管理),但它也可以与资源释放相关。在垃圾回收的上下文中,资源释放通常涉及到以下两种类型的资源:
- 托管资源: 这些资源是托管代码(如C#、Java等)管理的资源,通常包括内存、对象和其他托管资源。垃圾回收会自动处理托管资源的释放,当托管对象不再被引用时,它们将被回收。
- 非托管资源: 这些资源是由托管代码以外的实体管理的资源,例如文件句柄、数据库连接、网络连接、COM对象等。垃圾回收不能直接管理非托管资源,因为它们不在CLR(Common Language Runtime)的控制范围之内。因此,开发人员需要手动管理非托管资源的释放。
在处理非托管资源时,开发人员通常会执行以下步骤:
- 实现 IDisposable 接口: 对于包含非托管资源的类,可以实现
IDisposable接口。这允许开发人员在对象不再需要时手动释放非托管资源。 - Dispose 方法: 在实现
IDisposable接口时,需要在Dispose方法中编写释放非托管资源的逻辑。开发人员可以在此方法中关闭文件、释放句柄、关闭数据库连接等。 - 使用 using 语句或显式调用 Dispose 方法: 使用
using语句或在不再需要资源时显式调用对象的Dispose方法,以确保非托管资源得到释放。这通常是手动资源管理的最佳实践。
示例代码如下所示:
public class CustomResource : IDisposable
{private bool disposed = false;private IntPtr nativeResource = IntPtr.Zero; // 非托管资源public CustomResource(){nativeResource = AllocateResource();}public void Dispose(){Dispose(true);GC.SuppressFinalize(this);}protected virtual void Dispose(bool disposing){if (!disposed){if (disposing){// 释放托管资源}// 释放非托管资源if (nativeResource != IntPtr.Zero){DeallocateResource(nativeResource);nativeResource = IntPtr.Zero;}disposed = true;}}~CustomResource(){Dispose(false);}private IntPtr AllocateResource(){// 分配非托管资源// ...return IntPtr.Zero;}private void DeallocateResource(IntPtr resource){// 释放非托管资源// ...}
}
Tip:垃圾回收主要处理托管资源的释放,而对于非托管资源,开发人员需要自己实现资源的释放逻辑,并通过
IDisposable接口的Dispose方法来进行管理。使用using语句或显式调用Dispose方法是确保及时释放非托管资源的关键。
- 隐式资源释放
隐式资源释放通常是指资源的释放是在某个外部条件或事件发生时自动发生的,而不需要显式调用Dispose方法或使用using语句。这通常与某些特定类型的对象和资源管理模式相关。以下是一些示例情景,其中隐式资源释放可能发生:
- 垃圾回收(GC): 对于托管对象,隐式资源释放是由垃圾回收器(GC)管理的。当垃圾回收器确定某个对象不再被引用时,它会自动回收该对象的内存,并调用该对象的析构函数(如果有的话)。在析构函数中,你可以处理非托管资源的释放。
public class CustomResource {private IntPtr nativeResource = IntPtr.Zero; // 非托管资源public CustomResource(){nativeResource = AllocateResource();}// 析构函数~CustomResource(){// 释放非托管资源DeallocateResource(nativeResource);}private IntPtr AllocateResource(){// 分配非托管资源// ...return IntPtr.Zero;}private void DeallocateResource(IntPtr resource){// 释放非托管资源// ...} }
在上述示例中,当 CustomResource 对象不再被引用时,垃圾回收器会自动调用析构函数,从而实现了隐式资源释放。
- 事件处理: 在事件驱动的编程中,当对象订阅事件并且事件源引发事件时,事件处理程序可能包含资源释放逻辑。事件处理程序会在事件发生时被调用,从而实现了隐式资源释放。
public class EventResourceHandler {private CustomResource resource; // 自定义资源public EventResourceHandler(){resource = new CustomResource();EventSource.SomeEvent += HandleEvent;}private void HandleEvent(object sender, EventArgs e){// 处理事件// 隐式资源释放发生在事件发生时} }
在这些情况下,资源的释放是通过外部条件(例如,对象不再被引用或事件发生)而隐式发生的。虽然隐式资源释放可以减少开发人员的工作量,但需要注意确保在适当的时候释放资源,以避免资源泄漏和性能问题。
四、 性能优化策略
4.1 性能分析和优化工具
- 性能分析的工具和技巧
性能分析是评估和改进应用程序性能的关键步骤。以下是一些常用的性能分析工具和技巧,可以帮助你识别和解决性能问题:
性能分析工具:
- Visual Studio Profiler(Visual Studio 性能分析器): 如果你使用 Visual Studio 进行开发,它内置了功能强大的性能分析器,可以帮助你分析 CPU 使用率、内存占用和函数调用时间等性能方面的数据。
- .NET Memory Profiler: 用于检测和解决.NET应用程序中的内存泄漏和性能问题的专用工具。它可以帮助你分析托管堆上的对象分配和释放情况。
- Profiler for Java: 用于 Java 应用程序性能分析的工具,如 VisualVM、YourKit、JProfiler 等。它们可以监视内存使用、线程活动、方法调用等,以帮助诊断性能问题。
- Performance Monitor(性能监视器): Windows 上的内置工具,用于监视系统性能计数器、进程性能和资源使用情况。它可用于分析操作系统级别的性能问题。
- Chrome DevTools: Chrome 浏览器的开发者工具包括性能面板,可用于分析前端网页性能,包括页面加载时间、JavaScript执行时间等。
- Apache JMeter: 用于性能测试和负载测试的开源工具,可模拟多个用户同时访问你的应用程序,以评估其性能和稳定性。
性能分析技巧:
- 性能基线: 在进行性能分析之前,建立性能基线是很重要的。记录应用程序在正常运行时的性能指标,以便后续的性能分析可以与之进行比较。
- 代码分析: 使用性能分析工具来分析代码,识别潜在的性能瓶颈和内存泄漏。查看函数调用堆栈、内存分配和释放情况等。
- 可视化数据: 将性能数据可视化,以便更容易识别问题。性能分析工具通常提供图表和图形界面,可帮助你直观地分析数据。
- 性能测试: 进行负载测试和性能测试,模拟高负载情况下的应用程序行为,以评估性能和稳定性。
- 代码剖析: 使用代码剖析工具来测量函数执行时间,找出哪些函数占用了大量的 CPU 时间,以便进行优化。
- 内存分析: 使用内存分析工具来检测内存泄漏和资源管理问题,特别是在托管代码中。
- 分析日志: 记录应用程序的日志,包括性能日志,以便在生产环境中诊断性能问题。
- 定期监测: 性能分析不仅限于开发阶段,还应定期监测生产环境中的性能,以及时发现和解决潜在问题。
- 常见性能瓶颈的检测方法
检测和解决性能瓶颈是优化应用程序性能的关键一步。以下是常见性能瓶颈的检测方法:
-
CPU 使用率高:
- 性能分析器: 使用性能分析工具(如Visual Studio Profiler、Java Profilers等)来识别哪些方法或函数占用了大量的CPU时间。这些工具可以生成函数调用图,帮助你找到热点代码。
- 代码剖析: 使用代码剖析工具来测量函数执行时间,找出哪些函数占用了大量的CPU时间。你可以使用
Stopwatch或内置的性能计数器来手动测量代码执行时间。 - 多线程问题: 如果多线程导致CPU争用或死锁,可以使用调试工具来分析线程的状态和争用情况,如Visual Studio的线程窗口。
-
内存占用过高:
- 内存分析工具: 使用内存分析工具(如.NET Memory Profiler、Java Profilers等)来检测内存泄漏和不合理的内存使用。这些工具可以帮助你识别未释放的对象和内存泄漏。
- 垃圾回收性能: 监控垃圾回收性能,了解垃圾回收的频率和开销。高频率的垃圾回收可能表明内存使用不合理。
-
IO 操作慢:
- 性能分析工具: 使用性能分析工具来分析文件操作、数据库查询、网络请求等IO操作的性能。这些工具可以帮助你找到IO操作的性能瓶颈。
- 异步编程: 使用异步编程来优化IO操作,以便应用程序可以继续执行其他任务而不阻塞。
-
数据库性能问题:
- 数据库分析工具: 使用数据库性能分析工具来监视数据库查询的性能。检查慢查询、索引使用和数据库连接池配置等方面是否存在问题。
- 查询优化: 优化数据库查询,确保使用适当的索引、缓存和查询计划。
-
网络延迟:
- 网络分析工具: 使用网络分析工具来检测网络延迟和问题。使用Wireshark等工具来捕获和分析网络数据包。
- 异步网络请求: 使用异步网络请求来避免阻塞应用程序。考虑使用CDN或负载均衡来分散网络负载。
-
前端性能问题:
- 前端工具: 使用前端性能工具(如PageSpeed Insights、Lighthouse、WebPageTest等)来分析网页加载时间、资源大小和渲染性能。
- 浏览器开发者工具: 使用浏览器的开发者工具(如Chrome DevTools)来检查网页性能和资源加载情况。
-
并发和线程问题:
- 线程分析工具: 使用线程分析工具来监视并发应用程序中的线程状态和争用情况。
- 锁和同步问题: 检查是否存在过多的锁争用或死锁情况,并使用合适的并发控制机制来解决问题。
-
第三方库和组件:
- 版本控制: 确保使用的第三方库和组件的版本是最新的,并且没有已知的性能问题。
- 性能测试: 进行性能测试以评估第三方库和组件的性能,确保它们不会成为应用程序的瓶颈。
4.2 多线程和并发编程
- 多线程编程的优势
多线程编程是一种同时运行多个线程以提高应用程序性能和响应性的编程技术。它具有许多优势,可以在合适的情况下带来显著的好处,以下是多线程编程的一些优势:
- 并行处理: 多线程使得应用程序可以同时执行多个任务或操作。这可以显著提高应用程序的性能,特别是在具有多核处理器的计算机上。
- 提高响应性: 多线程允许应用程序保持响应性,即使其中一个线程在执行计算密集型任务时被阻塞,其他线程仍然可以继续响应用户输入或执行其他任务。
- 利用多核处理器: 在多核处理器上运行多线程应用程序可以充分利用硬件资源,提高处理器的利用率。这有助于减少单核处理器的瓶颈。
- 任务并行化: 通过将任务分解成多个线程并行执行,可以更快地完成任务,例如图像处理、数据分析和渲染等。
- 分布式计算: 多线程编程也在分布式系统中发挥作用。它允许多个计算节点并行工作,以处理大规模数据或复杂的计算任务。
- 资源共享: 多线程可以共享内存和其他资源,从而减少了数据复制和通信的开销,提高了资源利用率。
- 并发性: 多线程编程有助于处理并发性问题,例如多个用户同时访问服务器或多个线程同时访问共享数据结构的情况。通过适当的同步机制,可以确保数据的一致性和完整性。
- 任务隔离: 多线程可以将不同的任务隔离开来,避免它们之间的相互影响。这有助于提高应用程序的稳定性和可维护性。
- 实时应用程序: 对于实时应用程序,多线程可以用于确保任务在特定时间内完成,以满足实时性要求,例如音频和视频处理。
- 模块化设计: 多线程编程鼓励将应用程序分解成更小的模块,这有助于提高代码的可维护性和可重用性。
Tip:多线程编程也带来了挑战,如线程安全性、死锁、竞态条件等问题需要妥善处理。因此,在进行多线程编程时,必须小心谨慎,并采取适当的同步和并发控制措施。
- 避免多线程陷阱
避免多线程编程中的陷阱和常见问题是至关重要的,这些问题可能导致竞态条件、死锁、性能下降等。以下是一些避免多线程陷阱的建议:
- 理解并发性问题: 在编写多线程代码之前,深入了解并发性问题,包括竞态条件、死锁、饥饿等。理解问题的本质将有助于更好地预防和解决它们。
- 使用线程安全的数据结构: 在多线程环境中,使用线程安全的数据结构(例如
ConcurrentDictionary、ConcurrentQueue等)可以减少竞态条件的风险。 - 使用锁和同步: 在需要共享资源的地方使用锁和同步机制,确保只有一个线程能够访问共享资源。但要小心死锁问题,确保锁的获取顺序是一致的。
- 避免全局锁: 避免使用过于粗粒度的全局锁,这可能会导致性能瓶颈。使用细粒度的锁来减小锁的范围。
- 使用线程安全的库: 尽量使用线程安全的库和框架,这些库已经处理了许多并发问题,例如并发集合、并发队列等。
- 尽量避免共享状态: 共享状态是并发问题的根本原因之一。尽量设计无状态的函数和对象,以减少共享状态的需求。
- 使用不可变对象: 不可变对象不可被修改,因此它们天然是线程安全的。考虑使用不可变对象来避免竞态条件。
- 了解线程池: 如果使用线程池执行任务,请确保了解线程池的工作原理和限制,以便合理使用它。
- 测试多线程代码: 编写多线程代码时进行详尽的测试是非常重要的。测试可以帮助发现潜在的并发问题。
- 避免死锁: 使用适当的超时机制和资源分配顺序,以防止死锁情况的发生。
- 监控和调试: 使用监控工具来监视多线程应用程序的性能和状态。在遇到问题时,使用调试工具来分析问题。
- 注意性能开销: 同步和锁定操作可能会引入性能开销。要在安全性和性能之间找到平衡。
- 文档和注释: 在多线程代码中提供清晰的文档和注释,以便其他开发人员理解代码的并发逻辑。
- 维护良好的代码结构: 良好的代码结构可以减少共享资源的需求,并降低并发问题的复杂性。
五、 结论
本问涵盖了与内存管理、性能优化以及多线程编程相关的多个主题。
内存管理和资源释放:
- 垃圾回收(GC)是自动管理内存的机制,用于释放不再被引用的对象。
- 垃圾回收器的种类包括标记-清除、标记-整理、分代垃圾回收等。
- 堆内存和栈内存是内存分配的两种不同方式,堆用于动态分配对象,栈用于局部变量。
- 内存分配和释放开销可以影响性能,需要权衡资源管理和性能。
- 引用类型和值类型的区别在于数据存储和传递方式。
- 选择合适的数据类型取决于需求、性能、内存使用和安全性。
多线程编程:
- 多线程编程可提高应用程序性能和响应性。
- 优势包括并行处理、提高响应性、利用多核处理器、任务并行化等。
- 避免多线程陷阱包括理解并发性问题、使用线程安全的数据结构、避免全局锁等。
- 使用锁和同步机制以及了解线程池是多线程编程的关键。
- 测试、监控和调试多线程代码是确保其稳定性和性能的重要部分。
内存管理和资源释放、性能优化以及多线程编程都是构建高性能、可靠应用程序的重要方面。理解这些概念和最佳实践,以及如何避免潜在的问题,对于编写高质量的软件至关重要。不同的应用场景可能需要不同的策略和技术,因此在实际应用中需要根据具体情况进行权衡和选择。
相关文章:

【深入浅出C#】章节10: 最佳实践和性能优化:内存管理和资源释放
一、 内存管理基础 1.1 垃圾回收机制 垃圾回收概述 垃圾回收(Garbage Collection)是一种计算机科学和编程领域的重要概念,它主要用于自动管理计算机程序中的内存分配和释放。垃圾回收的目标是识别和回收不再被程序使用的内存,以…...

我的创作纪念日——1个普通网安人的漫谈
机缘 大家好,我是zangcc。今天突然收到了一条私信,才发现来csdn已经1024天了,不知不觉都搞安全渗透2年半多了🐔,真是光阴似箭。 我写博客的初衷只是记录自己的学习历程,比如打打靶场,写一下通关…...
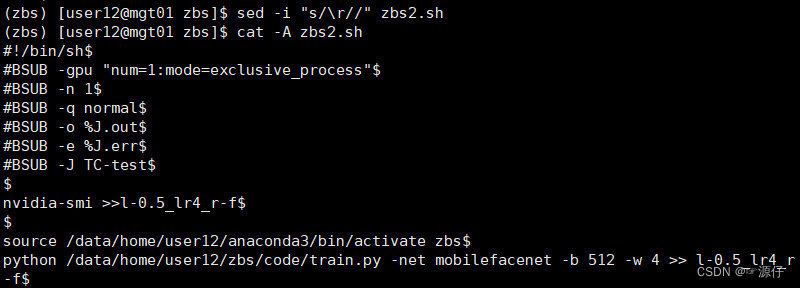
Linux中执行bash脚本报错/bin/bash^M: bad interpreter: No such file or directory
文章目录 参考博客: Linux中执行bash脚本报错/bin/bash^M: bad interpreter: No such file or directory 首先在此对这位博主表示感谢。 运行bash脚本会出现两个文件,1037.err和1037.out。 1037.err的文件内容如下: /data/home/user12/.lsbat…...

期权交易策略主要有哪些?期权交易策略指南
在学习更复杂的看涨和看跌期权策略之前,普通投资者应该彻底了解一些关于期权的基本知识,这样有助你后期的交易能力和理论知识水平提升有很大的帮助,下文科普期权交易策略主要有哪些?期权交易策略指南!本文来自…...

算法通关村第十四关——解析堆在数组中找第K大的元素的应用
力扣215题, 给定整数数组nums和整数k,请返回数组中第k个最大的元素。 请注意,你需要找的是数组排序后的第k个最大的元素,而不是第k个不同的元素。 分析:按照“找最大用小堆,找最小用大堆,找中间…...
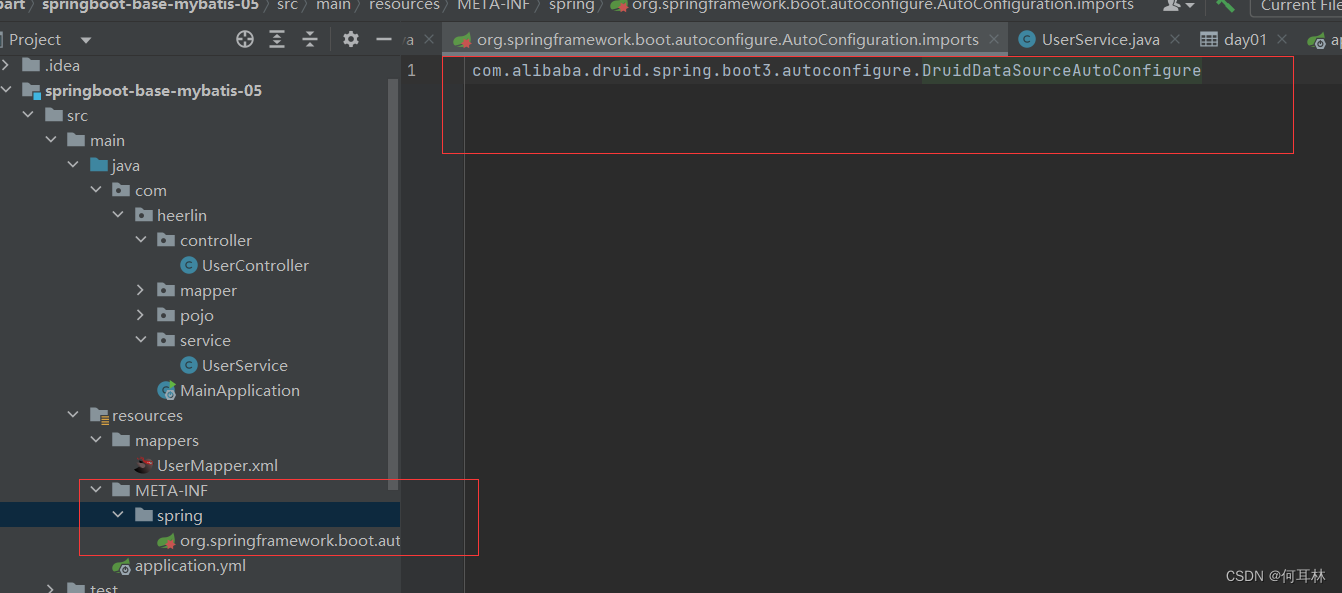
【报错】springboot3启动报错
报错内容:Cannot load driver class: org.h2.Driver Error starting ApplicationContext. To display the condition evaluation report re-run your application with debug enabled. 解决; 通过源码分析,druid-spring-boot-3-starter目前最新版本是1…...
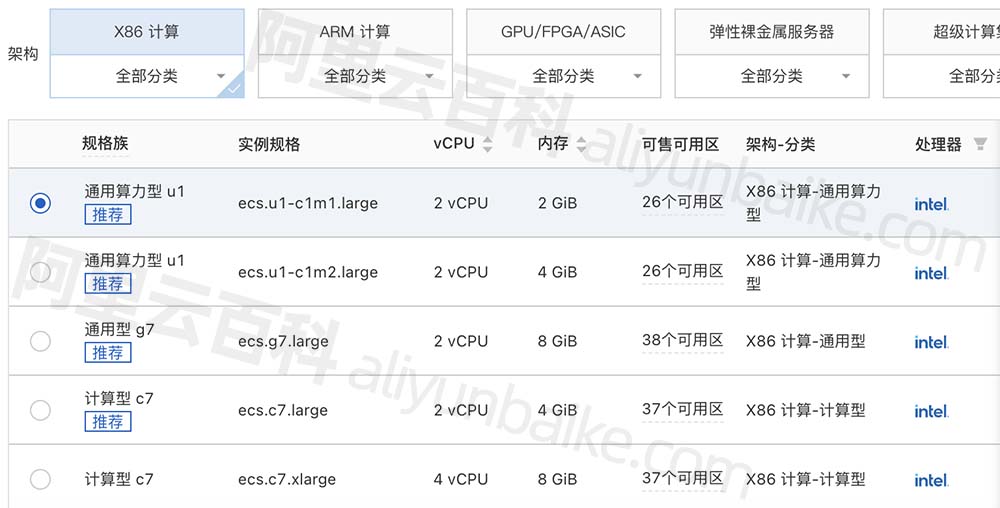
阿里云服务器配置怎么选择?小白攻略
阿里云服务器配置选择_CPU内存/带宽/存储配置_小白指南,阿里云服务器配置选择方法包括云服务器类型、CPU内存、操作系统、公网带宽、系统盘存储、网络带宽选择、安全配置、监控等,阿小云分享阿里云服务器配置选择方法,选择适合自己的云服务器…...
关于 RK3568的linux系统killed用户应用进程(用户现象为崩溃) 的解决方法
若该文为原创文章,转载请注明原文出处 本文章博客地址:https://hpzwl.blog.csdn.net/article/details/132710642 红胖子网络科技博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、OpenCV、OpenGL、ffmpeg、OSG、单片机、软硬…...
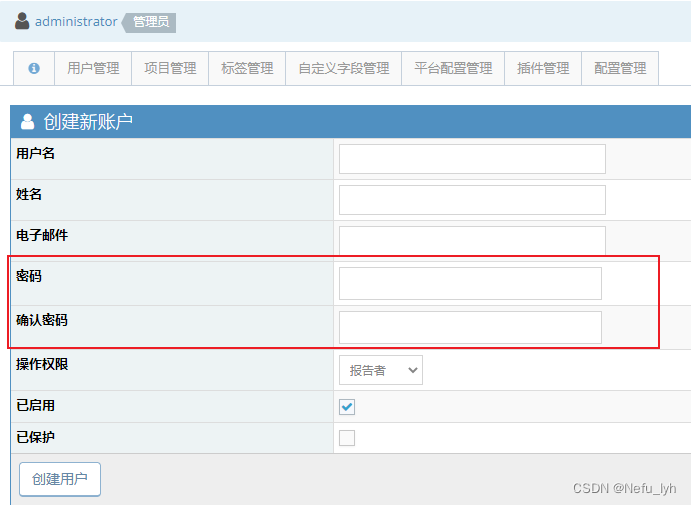
EasyPHP-Devserver-17安装和配置mantisBT
文章目录 1、准备工作2、安装easyphp2.1 http://127.0.0.1 无法访问 3、安装mantisBT和phpMyAdmin3.1 配置浏览器的访问url和端口号(配置局域网内可访问)3.2 安装mantis 4、Administrator 注册新用户时设置登录密码5、附件上传6、邮件配置 文章参考自&am…...

Python打包教程 PyInstaller和cx_Freeze
当我们开发Python应用程序时,通常会将代码保存在.py文件中,然后通过Python解释器运行它。这对于开发和测试是非常方便的,但在将应用程序分享给其他人或在不同环境中部署时,可能会带来一些问题。为了解决这些问题,我们可…...
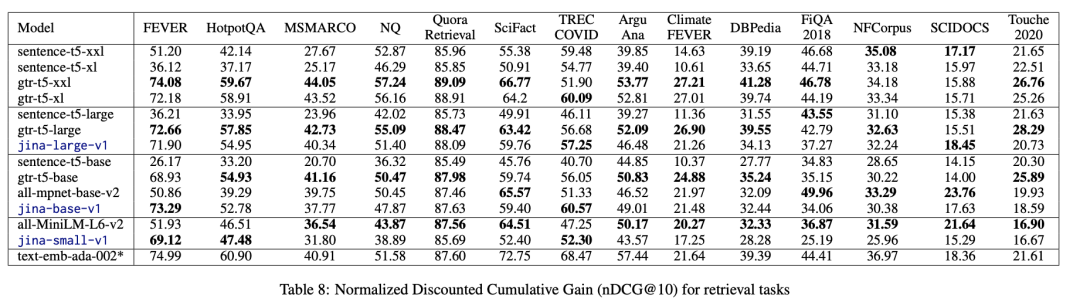
用两成数据也能训练出十成功力的模型,Jina Embeddings 这么做
句向量(Sentence Embeddings)模型在多模态人工智能领域起着至关重要的作用,它通过将句子编码为固定长度的向量表示,将语义信息转化为机器可以处理的形式,在 文本分类、信息检索和相似度计算 等多个方面有着广泛应用。 …...
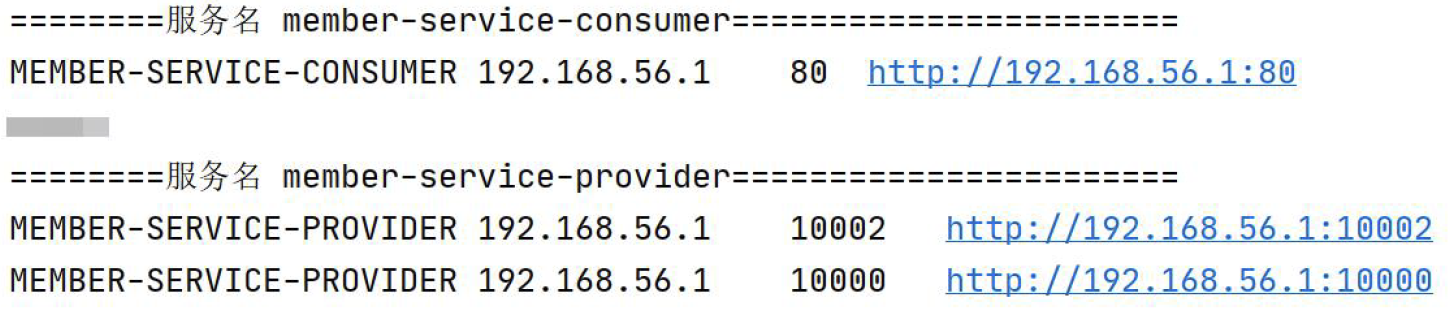
SpringCloud Eureka搭建会员中心服务提供方-集群
😀前言 本篇博文是关于SpringCloud Eureka搭建会员中心服务提供方-集群,希望你能够喜欢 🏠个人主页:晨犀主页 🧑个人简介:大家好,我是晨犀,希望我的文章可以帮助到大家,您…...
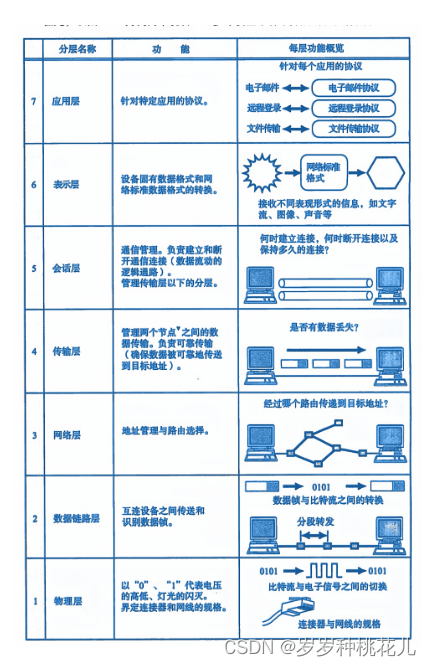
详解TCP/IP协议第二篇:OSI参考模型详解
文章目录 写给自己的话 一:协议分层与OSI参考模型 二:通过对话理解分层 三:OSI参考模型 写给自己的话 不从恶人的计谋,不站罪人的道路,不坐亵慢人的座位,惟喜爱耶和华的律法,昼夜思想&#…...

OpenGL 函数列表
//纹理头文件加载 #define STB_IMAGE_IMPLEMENTATION #include "stb_image.h" //线框模式(Wireframe Mode) //glPolygonMode(GL_FRONT_AND_BACK, GL_LINE); //翻转y轴 stbi_set_flip_vertically_on_load(true); //声明鼠标滚轮回调函数 void scroll_call…...

【C语言】每日一题(半月斩)——day1
目录 😊前言 一.选择题 1.执行下面程序,正确的输出是(c) 2.以下不正确的定义语句是( ) 3.test.c 文件中包括如下语句,文件中定义的四个变量中,是指针类型的变量为【多选】&a…...

Spring MVC 七 - Locale 本地化
Spring各模块都支持国际化,SpringMVC也同样支持。DispatcherServlet通过Locale Resovler自动根据客户端的Locale支持国际化。 request请求上来后,DispatcherServlet查找并设置Locale Resovler,我们可以通过RequestContext.getLocale()获取到…...
算法_C++——替换后的最长重复字符)
力扣(LeetCode)算法_C++——替换后的最长重复字符
给你一个字符串 s 和一个整数 k 。你可以选择字符串中的任一字符,并将其更改为任何其他大写英文字符。该操作最多可执行 k 次。 在执行上述操作后,返回包含相同字母的最长子字符串的长度。 示例 1: 输入:s “ABAB”, k 2 输出…...

unity 编辑器时读取FairyGUI图集单个图像
原因 想要在编辑器扩展也能访问FairyGUI图集里面的小图,随便找了一下没有找到接口自己做一个 方法 使用UIPackage.GetItemByURL获得小图信息。从图集中复制出小图,如果有旋转就逆旋转90度即可 图集里面的小图是有可能旋转的,可以通过访问 …...
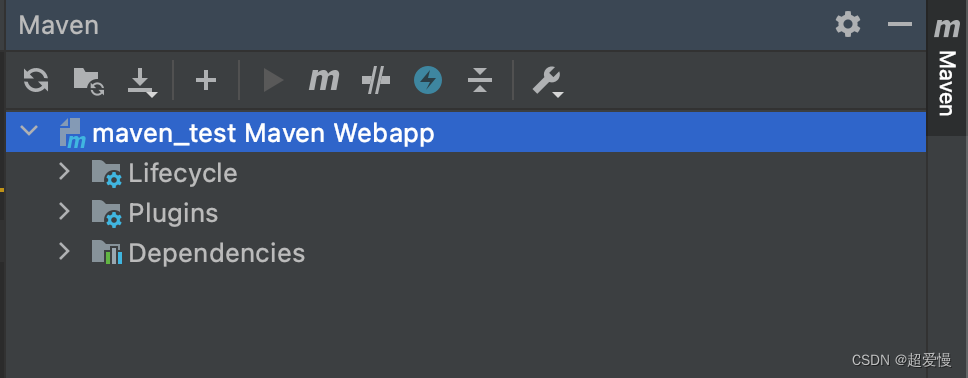
下载配置 maven并在 idea 上应用
目录 一 maven 定义 二 Maven特点 三 Maven仓库 四 安装配置maven 步骤一:准备安装包,解压 步骤二:配置maven的环境变量 步骤三:测试maven的环境变量是否配置成功 步骤四:配置maven本地仓库 步骤五:阿里云、腾讯镜像配置 步骤六:全局配置idea的maven路径 步骤七:创建…...
网站搭建从零开始(0)--域名的选择与解析
目录 确定用途 购买域名 使用可靠的注册商购买域名 想好域名关键词 检查域名是否可用 添加域名到购物车并完成购买 域名的解析 登录注册商账户 选择要配置的域名 进入DNS解析设置 添加DNS记录 保存配置 检查解析是否生效 提示 确定用途 在购买域名之前…...

三步实现跨架构程序兼容:Box64高效架构转换指南
三步实现跨架构程序兼容:Box64高效架构转换指南 【免费下载链接】box64 Box64 - Linux Userspace x86_64 Emulator with a twist, targeted at ARM64, RV64 and LoongArch Linux devices 项目地址: https://gitcode.com/gh_mirrors/bo/box64 你是否曾在ARM64…...

MobX社区资源大全:10个必备工具、插件和扩展库推荐 [特殊字符]
MobX社区资源大全:10个必备工具、插件和扩展库推荐 🚀 【免费下载链接】MobX-Docs-CN MobX 中文文档 项目地址: https://gitcode.com/gh_mirrors/mo/MobX-Docs-CN MobX作为一个简单、可扩展的状态管理库,已经成为React开发者不可或缺的…...

<背包问题>
背包问题是一类组合优化问题,其基本形式是给定一组物品,每个物品都有一个重量和一个价值,以及一个有限的背包容量,目标是在不超过背包容量的前提下,选择物品使得背包中的物品价值最大化。动态规划是解决背包问题的常用…...

BiliRoamingX:彻底解决B站体验限制的完整增强方案
BiliRoamingX:彻底解决B站体验限制的完整增强方案 【免费下载链接】BiliRoamingX-integrations BiliRoamingX integrations and patches powered by ReVanced. 项目地址: https://gitcode.com/gh_mirrors/bi/BiliRoamingX-integrations 你是否曾为B站的内容区…...

DeepSeek模型微调全链路解析:从数据准备、LoRA配置到推理部署的7大关键步骤
更多请点击: https://intelliparadigm.com 第一章:DeepSeek模型微调全链路概览 DeepSeek系列大语言模型(如DeepSeek-V2、DeepSeek-Coder)凭借其开源特性、高性能推理能力与丰富的领域适配性,已成为工业界与学术界微调…...
)
微信聊天图片丢了别慌!保姆级教程:找回并解密DAT文件(支持新旧版微信路径)
微信DAT图片恢复实战:从文件定位到批量解密的完整指南 微信聊天记录中的图片突然消失?别急着放弃!那些看似无法打开的DAT文件里,可能藏着您的重要回忆或工作资料。本文将带您深入微信存储机制,手把手完成从文件定位到…...

DeepSeek-R1代码补全实测报告:37个真实项目、8类编程语言、48小时压测后,我删掉了Copilot
更多请点击: https://intelliparadigm.com 第一章:DeepSeek-R1代码补全实测报告总览 DeepSeek-R1 是深度求索(DeepSeek)推出的开源大语言模型,专为代码理解与生成任务优化。本章聚焦其在主流 IDE 环境中代码补全能力的…...

3步搞定B站缓存视频转换:m4s转MP4的终极解决方案
3步搞定B站缓存视频转换:m4s转MP4的终极解决方案 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经在B站缓存了珍贵的视频&a…...

【国家级攻防演练级建议】:DeepSeek私有化部署中4类隐蔽后门植入路径与实时检测方案
更多请点击: https://kaifayun.com 第一章:DeepSeek私有化部署中隐蔽后门植入的攻防对抗本质 在私有化场景下,DeepSeek模型的部署链路常跨越镜像构建、权重加载、推理服务启动及API网关接入等多个环节。攻击者可利用构建上下文污染、依赖包劫…...

Claude Mythos Preview首月揪万余漏洞、拦截150万美元电诈,网络安全格局将变?
玻璃翼计划首战告捷A厂的玻璃翼计划首战告捷,Mythos 30天内就挖出1万个致命漏洞,甚至拦截了150万美元电诈。面对雪片式的报告,人类程序员崩溃求饶:「求别挖了,根本修不完啊!」就在刚刚,Anthropi…...