步态识别常见模块解读及代码实现:基于OpenGait框架
步态识别常见模块解读及代码实现:基于OpenGait框架
最近在看步态识别相关论文,但是因为记忆力下降的原因,老是忘记一些内容。因此记录下来方便以后查阅,仅供自己学习参考,没有背景知识和论文介绍。
目录
- 步态识别常见模块解读及代码实现:基于OpenGait框架
- 一、GaitSet: Set-Based Recognition
- 1, set_block:提取空间特征信息
- 2, gl_block:提取各种层次的set信息
- 3, set_pooling:提取时序信息
- 4, Horizontal Pooling Matching (HPM)
- 5, SeparateFCs
- 6,forward
- 二、GaitPart: Part-based **(Local)** Recognition
- 1, backbone
- 2,HPP
- 3, Temporal Feature Aggregator (TFA)
- 4, forward
- 三、GLN: feature pyramid
- 1,backbone (encoder)
- 2, lateral (decoder)
- 3, Compact Block
- 四、GaitGL: Global and Local
- 1,GLConv:提取时空特征
- 2,LTA: Local Temporal Aggregation
- 3, Gait Recognition Head
- motivation: HPP对所有数据集采用相同的处理方式(指按固定比例混合全局池化和平均池化),不能自适应处理。
- method: 公式如下,通过参数p来自适应调整比例。当p=1,等价于平均池化;当p趋于无穷,等价于最大池化。 Y T F M Y_{TFM} YTFM表示TP后的特征。
- 4, forward
- 五、SMPLGait:
- 1,SLN:Silhouette Learning Network
- 2, 3D-STN: 3D Spatial Transformation Network
- 3, 3D Spatial Transformation Module: 融合多模态特征
- 六、GaitEdge
- 1,pre-process:提取边缘信息和内部信息
- 2, Gait Synthesis: 依据边缘信息和内部信息对分割出的人体信息进行增强
- 3, Gait Align
- 七、GaitBase
- 1, backbone: ResNet-9
- 2, TP和HPP
- 3,BNNeck
一、GaitSet: Set-Based Recognition
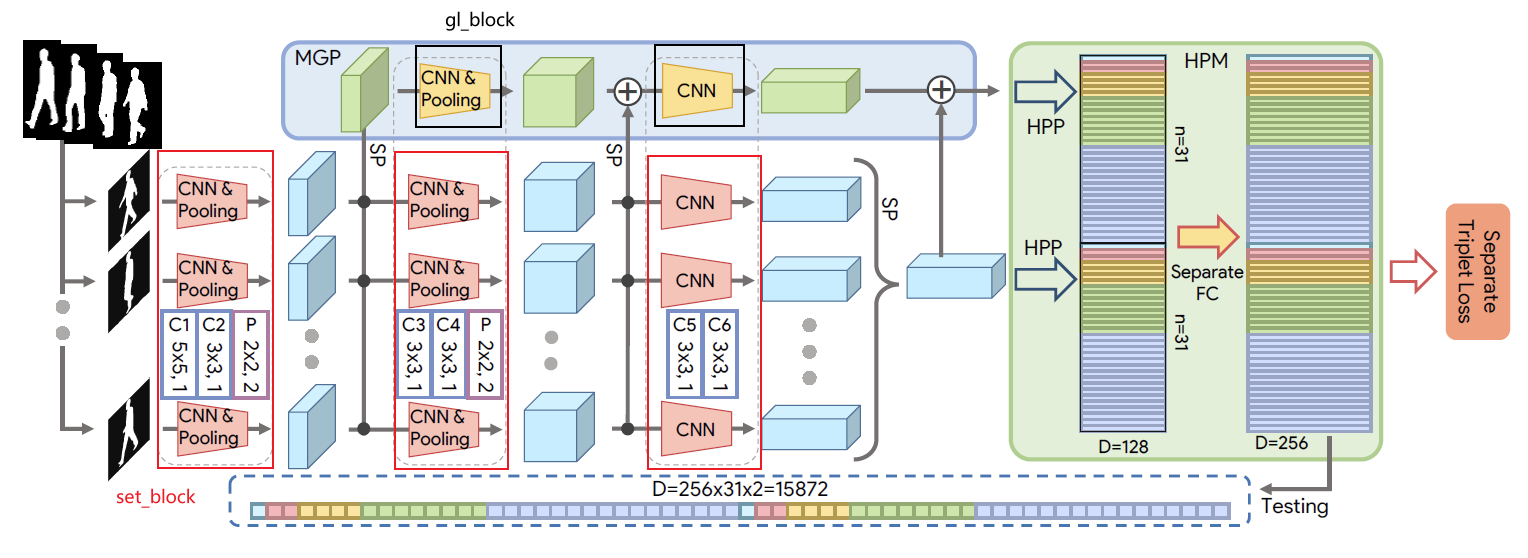
1, set_block:提取空间特征信息
Gaitset中共有3个set_block,前两个set_block带有MaxPooling层,代码如下:
self.set_block1 = nn.Sequential(BasicConv2d(in_c[0], in_c[1], 5, 1, 2),nn.LeakyReLU(inplace=True),BasicConv2d(in_c[1], in_c[1], 3, 1, 1),nn.LeakyReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2))self.set_block2 = nn.Sequential(BasicConv2d(in_c[1], in_c[2], 3, 1, 1),nn.LeakyReLU(inplace=True),BasicConv2d(in_c[2], in_c[2], 3, 1, 1),nn.LeakyReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2))self.set_block3 = nn.Sequential(BasicConv2d(in_c[2], in_c[3], 3, 1, 1),nn.LeakyReLU(inplace=True),BasicConv2d(in_c[3], in_c[3], 3, 1, 1),nn.LeakyReLU(inplace=True))
所有的set_block会用SetBlockWrapper进行封装,代码如下:
self.set_block1 = SetBlockWrapper(self.set_block1)self.set_block2 = SetBlockWrapper(self.set_block2)self.set_block3 = SetBlockWrapper(self.set_block3)
SetBlockWrapper用于reshape数据,保证conv是在[c, h, w]维度上进行,代码如下:
class SetBlockWrapper(nn.Module):def __init__(self, forward_block):super(SetBlockWrapper, self).__init__()self.forward_block = forward_blockdef forward(self, x, *args, **kwargs):"""n是bacth_size,也就是当前batch中序列的总数; s是序列中的帧数In x: [n, c_in, s, h_in, w_in]Out x: [n, c_out, s, h_out, w_out]"""n, c, s, h, w = x.size()# conv2d会将输入数据的最后三个维度视为[c, h, w],所以此处需要先reshapex = self.forward_block(x.transpose(1, 2).reshape(-1, c, h, w), *args, **kwargs) output_size = x.size()return x.reshape(n, s, *output_size[1:]).transpose(1, 2).contiguous()
2, gl_block:提取各种层次的set信息
GaitSet中有2个gl_block,其结构与SetBlockWrapper前的set_block相同:
self.gl_block2 = copy.deepcopy(self.set_block2)self.gl_block3 = copy.deepcopy(self.set_block3)
进入gl_block前,特征会进行以此set_pooling, shape从[n, c, s, h, w]变为[n, c, h, w],所以gl_block无需SetBlockWrapper。
3, set_pooling:提取时序信息
set_pooling采用的是max_pooling,会在frame-level进行,代码如下:
self.set_pooling = PackSequenceWrapper(torch.max)
PackSequenceWrapper定义如下:
class PackSequenceWrapper(nn.Module):def __init__(self, pooling_func):super(PackSequenceWrapper, self).__init__()self.pooling_func = pooling_funcdef forward(self, seqs, seqL, dim=2, options={}):"""In seqs: [n, c, s, ...]Out rets: [n, ...]"""if seqL is None:# 对s维度进行pooling,[n, c, s, h, w]->[n, c, h, w]return self.pooling_func(seqs, **options)seqL = seqL[0].data.cpu().numpy().tolist()start = [0] + np.cumsum(seqL).tolist()[:-1]rets = []for curr_start, curr_seqL in zip(start, seqL):narrowed_seq = seqs.narrow(dim, curr_start, curr_seqL)rets.append(self.pooling_func(narrowed_seq, **options))if len(rets) > 0 and is_list_or_tuple(rets[0]):return [torch.cat([ret[j] for ret in rets])for j in range(len(rets[0]))]return torch.cat(rets)
4, Horizontal Pooling Matching (HPM)
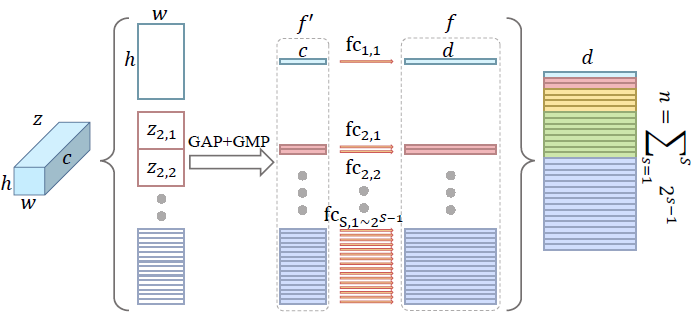
HPM会把特征在h维度上进行不同尺度的均分,然后再进行pooling,代码如下:
self.HPP = HorizontalPoolingPyramid(bin_num=model_cfg['bin_num'])class HorizontalPoolingPyramid():"""Horizontal Pyramid Matching for Person Re-identificationArxiv: https://arxiv.org/abs/1804.05275Github: https://github.com/SHI-Labs/Horizontal-Pyramid-Matching"""def __init__(self, bin_num=None):if bin_num is None:# GaitSet论文中HPP分别按16, 8, 4, 2, 1等分,所以n=31bin_num = [16, 8, 4, 2, 1]self.bin_num = bin_numdef __call__(self, x):"""x : [n, c, h, w]ret: [n, c, p] """n, c = x.size()[:2]features = []for b in self.bin_num:z = x.view(n, c, b, -1)z = z.mean(-1) + z.max(-1)[0]features.append(z)return torch.cat(features, -1)
5, SeparateFCs
SeparateFCs对HPP的结果,按部分(part)分别进行fc映射,代码如下:
self.Head = SeparateFCs(**model_cfg['SeparateFCs'])class SeparateFCs(nn.Module):def __init__(self, parts_num, in_channels, out_channels, norm=False):super(SeparateFCs, self).__init__()self.p = parts_numself.fc_bin = nn.Parameter(nn.init.xavier_uniform_(torch.zeros(parts_num, in_channels, out_channels)))self.norm = normdef forward(self, x):"""x: [n, c_in, p]out: [n, c_out, p]"""x = x.permute(2, 0, 1).contiguous()if self.norm:out = x.matmul(F.normalize(self.fc_bin, dim=1))else:out = x.matmul(self.fc_bin)return out.permute(1, 2, 0).contiguous()
最后计算loss的时候也是按照不同的part去计算triplet loss,然后取平均。
6,forward
def forward(self, inputs):ipts, labs, _, _, seqL = inputssils = ipts[0] # [n, s, h, w]if len(sils.size()) == 4:sils = sils.unsqueeze(1) # [n, c, s, h, w]del iptsouts = self.set_block1(sils) # [n, c, s, h, w]gl = self.set_pooling(outs, seqL, options={"dim": 2})[0] # [n, c, h, w]gl = self.gl_block2(gl)outs = self.set_block2(outs)gl = gl + self.set_pooling(outs, seqL, options={"dim": 2})[0]gl = self.gl_block3(gl)outs = self.set_block3(outs)outs = self.set_pooling(outs, seqL, options={"dim": 2})[0]gl = gl + outs# Horizontal Pooling Matching, HPMfeature1 = self.HPP(outs) # [n, c, p]feature2 = self.HPP(gl) # [n, c, p]feature = torch.cat([feature1, feature2], -1) # [n, c, p]embs = self.Head(feature)n, _, s, h, w = sils.size()retval = {'training_feat': {'triplet': {'embeddings': embs, 'labels': labs}},'visual_summary': {'image/sils': sils.view(n*s, 1, h, w)},'inference_feat': {'embeddings': embs}}return retval
二、GaitPart: Part-based (Local) Recognition

1, backbone
GaitPart中backbone主要由三个部分组成:Basic Conv2d (BC), MaxPool2d (M), Focal Conv2d (FC)。BC和M的结构很好理解,不多介绍。Focal Conv2d的代码如下:
class FocalConv2d(nn.Module):"""GaitPart: Temporal Part-based Model for Gait RecognitionCVPR2020: https://openaccess.thecvf.com/content_CVPR_2020/papers/Fan_GaitPart_Temporal_Part-Based_Model_for_Gait_Recognition_CVPR_2020_paper.pdfGithub: https://github.com/ChaoFan96/GaitPart"""def __init__(self, in_channels, out_channels, kernel_size, halving, **kwargs):super(FocalConv2d, self).__init__()self.halving = halvingself.conv = nn.Conv2d(in_channels, out_channels,kernel_size, bias=False, **kwargs)def forward(self, x):# x.shape [B, C, H, W]if self.halving == 0:z = self.conv(x) # 等同于普通的Conv2delse:h = x.size(2)# halving表示进行几次二等分split_size = int(h // 2**self.halving)z = x.split(split_size, 2) # 在h维度均分z = torch.cat([self.conv(_) for _ in z], 2) # 拼接return z
整个backbone用SetBlockWrapper进行封装。
2,HPP
由于GaitPart的backbone提取特征后,没有进行set_pooling,所以HPP也需要用SetBlockWrapper进行封装。HPP会在在h维度将特征均分为16份
self.HPP = SetBlockWrapper(HorizontalPoolingPyramid(bin_num=model_cfg['bin_num']))
3, Temporal Feature Aggregator (TFA)
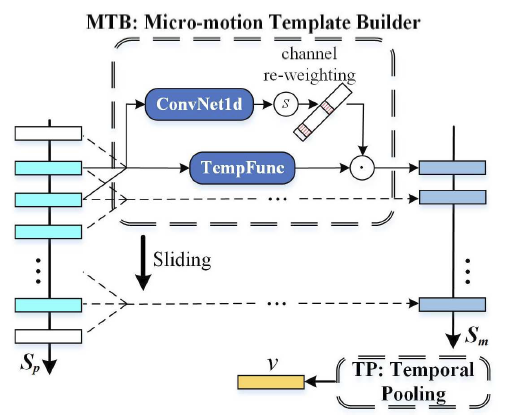
TFA模块针对每一个part来进行时间聚合,由两个MCM模块(Conv1d提取相邻帧特征)和时间池化模块(s维度的最大池化)组成。共有16个part,所以每个MCM模块都要深度拷贝16次(参数不共享)。代码如下:
class TemporalFeatureAggregator(nn.Module):def __init__(self, in_channels, squeeze=4, parts_num=16):super(TemporalFeatureAggregator, self).__init__()hidden_dim = int(in_channels // squeeze)self.parts_num = parts_num# MTB1, 主要是conv1d来聚合相邻帧之间的信息conv3x1 = nn.Sequential(BasicConv1d(in_channels, hidden_dim, 3, padding=1),nn.LeakyReLU(inplace=True),BasicConv1d(hidden_dim, in_channels, 1))self.conv1d3x1 = clones(conv3x1, parts_num)# template function: avg_pool, max_poolself.avg_pool3x1 = nn.AvgPool1d(3, stride=1, padding=1)self.max_pool3x1 = nn.MaxPool1d(3, stride=1, padding=1)# MTB2conv3x3 = nn.Sequential(BasicConv1d(in_channels, hidden_dim, 3, padding=1),nn.LeakyReLU(inplace=True),BasicConv1d(hidden_dim, in_channels, 3, padding=1))self.conv1d3x3 = clones(conv3x3, parts_num)self.avg_pool3x3 = nn.AvgPool1d(5, stride=1, padding=2)self.max_pool3x3 = nn.MaxPool1d(5, stride=1, padding=2)# Temporal Pooling, TPself.TP = torch.maxdef forward(self, x):"""Input: x, [n, c, s, p]Output: ret, [n, c, p]"""n, c, s, p = x.size()x = x.permute(3, 0, 1, 2).contiguous() # [p, n, c, s]feature = x.split(1, 0) # [[1, n, c, s], ...]x = x.view(-1, c, s)# MTB1: ConvNet1d & Sigmoidlogits3x1 = torch.cat([conv(_.squeeze(0)).unsqueeze(0)for conv, _ in zip(self.conv1d3x1, feature)], 0)scores3x1 = torch.sigmoid(logits3x1) # [p, n, c, s]# MTB1: Template Functionfeature3x1 = self.avg_pool3x1(x) + self.max_pool3x1(x) #[n*p, c, s]feature3x1 = feature3x1.view(p, n, c, s)feature3x1 = feature3x1 * scores3x1 # [p, n, c, s]# MTB2: ConvNet1d & Sigmoidlogits3x3 = torch.cat([conv(_.squeeze(0)).unsqueeze(0)for conv, _ in zip(self.conv1d3x3, feature)], 0)scores3x3 = torch.sigmoid(logits3x3)# MTB2: Template Functionfeature3x3 = self.avg_pool3x3(x) + self.max_pool3x3(x)feature3x3 = feature3x3.view(p, n, c, s)feature3x3 = feature3x3 * scores3x3 # Temporal Poolingret = self.TP(feature3x1 + feature3x3, dim=-1)[0] # [p, n, c]ret = ret.permute(1, 2, 0).contiguous() # [n, p, c]return ret
4, forward
def forward(self, inputs):ipts, labs, _, _, seqL = inputssils = ipts[0]if len(sils.size()) == 4:sils = sils.unsqueeze(1)del iptsout = self.Backbone(sils) # [n, c, s, h, w]out = self.HPP(out) # [n, c, s, p]out = self.TFA(out, seqL) # [n, c, p]embs = self.Head(out) # [n, c, p]n, _, s, h, w = sils.size()retval = {'training_feat': {'triplet': {'embeddings': embs, 'labels': labs}},'visual_summary': {'image/sils': sils.view(n*s, 1, h, w)},'inference_feat': {'embeddings': embs}}return retval
三、GLN: feature pyramid
GLN可以看作是一个U-shape结构的编码器-解码器网络,先看看编码器部分。
1,backbone (encoder)
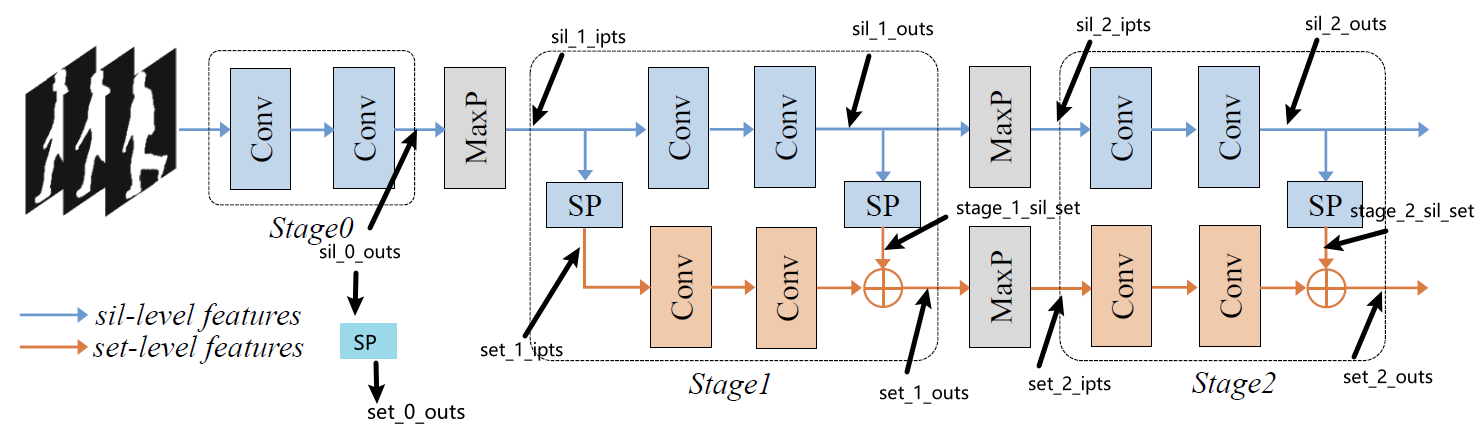
backbone包含三个stage,每个stage的sil_outs和set_outs会拼接作为当前stage的特征输出。在图中stage0没有进行set_pooling来获取set_outs,但是代码中有进行相关操作。该模块forward过程如下:
### stage 0 sil ###sil_0_outs = self.sil_stage_0(sils)stage_0_sil_set = self.set_pooling(sil_0_outs, seqL, options={"dim": 2})[0]### stage 1 sil ###sil_1_ipts = self.MaxP_sil(sil_0_outs)sil_1_outs = self.sil_stage_1(sil_1_ipts)### stage 2 sil ###sil_2_ipts = self.MaxP_sil(sil_1_outs)sil_2_outs = self.sil_stage_2(sil_2_ipts)### stage 1 set ###set_1_ipts = self.set_pooling(sil_1_ipts, seqL, options={"dim": 2})[0]stage_1_sil_set = self.set_pooling(sil_1_outs, seqL, options={"dim": 2})[0]set_1_outs = self.set_stage_1(set_1_ipts) + stage_1_sil_set### stage 2 set ###set_2_ipts = self.MaxP_set(set_1_outs)stage_2_sil_set = self.set_pooling(sil_2_outs, seqL, options={"dim": 2})[0]set_2_outs = self.set_stage_2(set_2_ipts) + stage_2_sil_setset1 = torch.cat((stage_0_sil_set, stage_0_sil_set), dim=1)set2 = torch.cat((stage_1_sil_set, set_1_outs), dim=1)set3 = torch.cat((stage_2_sil_set, set_2_outs), dim=1)
编码器中,sil_stage需要用SetBlockWrapper封装,而set_stage由于输入会进行set_pooling,所以无需SetBlockWrapper封装。
2, lateral (decoder)
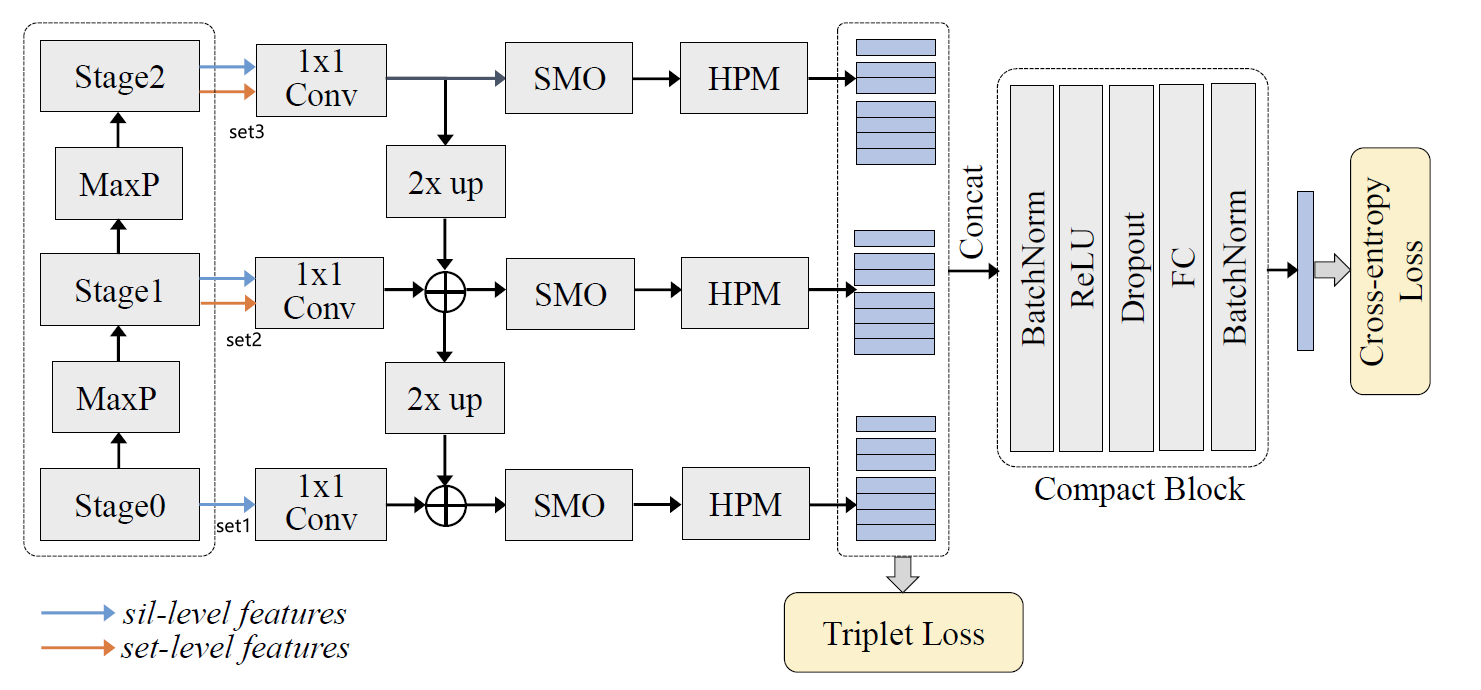
解码器部分,从上到下逐层up_add,然后进行平滑,最后HPP。最终,三个stage的代码会拼接并经过SeparateFCs,forward代码如下:
set3 = self.lateral_layer3(set3) # Conv2dset2 = self.upsample_add(set3, self.lateral_layer2(set2))set1 = self.upsample_add(set2, self.lateral_layer1(set1))set3 = self.smooth_layer3(set3) # Conv2dset2 = self.smooth_layer2(set2)set1 = self.smooth_layer1(set1)set1 = self.HPP(set1)set2 = self.HPP(set2)set3 = self.HPP(set3)feature = torch.cat([set1, set2, set3], -1)feature = self.Head(feature) # SeparateFCs
可以看到示意图中对于stage0只用了sil_features, 但是代码中实际做法为:对sil_features进行set_pooling获得set_features。
3, Compact Block
作者认为在GaitSet的HPM中,将特征沿h维度划分为不同的区域时,会存在特征冗余。例如,(s, t) = (4, 1) 和(s, t) = {(8, 1), (8, 2)}就表示相同的区域,其中s是划分的尺度,t是区域的index。(换言之,”四等分的第一块“等价于”八等分的第一块和第二块“)。由于HPM最终一共会产生 1 + 2 + 4 + 8 + 16 = 31 1+2+4+8+16=31 1+2+4+8+16=31个part,每个part的dimension都是256,所以最终的特征维度为 31 × 256 = 7936 31\times256=7936 31×256=7936。为此,GLN提出了Compact Block来对特征维度进行压缩。定义如下:
self.encoder_bn = nn.BatchNorm1d(sum(self.bin_num)*3*self.hidden_dim)self.encoder_bn.bias.requires_grad_(False)self.reduce_dp = nn.Dropout(p=model_cfg['dropout'])self.reduce_ac = nn.ReLU(inplace=True)self.reduce_fc = nn.Linear(sum(self.bin_num)*3*self.hidden_dim, reduce_dim, bias=False)self.reduce_bn = nn.BatchNorm1d(reduce_dim)self.reduce_bn.bias.requires_grad_(False)self.reduce_cls = nn.Linear(reduce_dim, model_cfg['class_num'], bias=False)
forward过程如下:
bn_feature = self.encoder_bn(feature.view(n, -1))bn_feature = bn_feature.view(*feature.shape).contiguous()reduce_feature = self.reduce_dp(bn_feature)reduce_feature = self.reduce_ac(reduce_feature)reduce_feature = self.reduce_fc(reduce_feature.view(n, -1))bn_reduce_feature = self.reduce_bn(reduce_feature)logits = self.reduce_cls(bn_reduce_feature).unsqueeze(1) # n creduce_feature = reduce_feature.unsqueeze(1).contiguous()bn_reduce_feature = bn_reduce_feature.unsqueeze(1).contiguous()
Compact Block可以把三个stage的特征维度从 3 × 7936 = 23808 3\times7936=23808 3×7936=23808降到hidden_dim = 256。
四、GaitGL: Global and Local
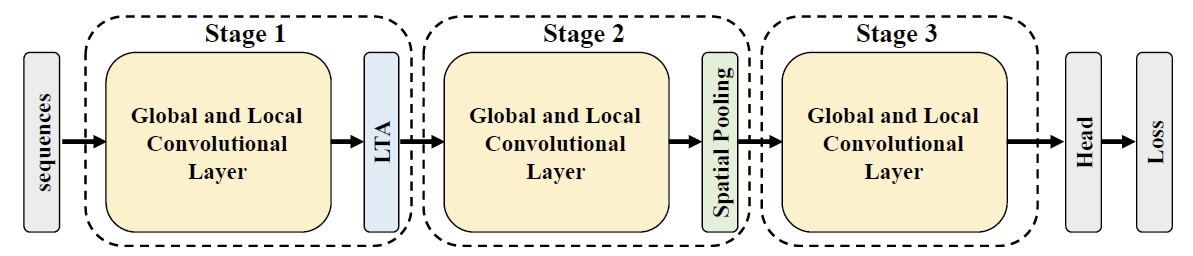
GaitGL有两套配置,分别用于数据集"OUMVLP and GREW",以及其他数据集。这两套配置主要结构都差多,只不过前者卷积层的数量会多一些。由于GaitGL使用3d卷积和池化来提取[s, h, w]三个维度的信息,所以backbone部分不需要SetBlockWrapper封装。
1,GLConv:提取时空特征

GLConv包含两个部分:global_conv3d和local_conv3d。global_conv3d直接用BasicConv3d(即nn.Conv3d)来提取全局特征,local_conv3d采用了和GaitPart中FocalConv类似的方式来提取局部特征(即在h维度进行划分,然后分块提取特征)。用相加或者拼接这两种方式来融合全局和局部特征。
class GLConv(nn.Module):def __init__(self, in_channels, out_channels, halving, fm_sign=False, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1), bias=False, **kwargs):super(GLConv, self).__init__()self.halving = halvingself.fm_sign = fm_signself.global_conv3d = BasicConv3d(in_channels, out_channels, kernel_size, stride, padding, bias, **kwargs)self.local_conv3d = BasicConv3d(in_channels, out_channels, kernel_size, stride, padding, bias, **kwargs)def forward(self, x):'''x: [n, c, s, h, w]'''gob_feat = self.global_conv3d(x)if self.halving == 0:lcl_feat = self.local_conv3d(x)else:h = x.size(3)split_size = int(h // 2**self.halving)lcl_feat = x.split(split_size, 3)lcl_feat = torch.cat([self.local_conv3d(_) for _ in lcl_feat], 3)if not self.fm_sign:feat = F.leaky_relu(gob_feat) + F.leaky_relu(lcl_feat)else:feat = F.leaky_relu(torch.cat([gob_feat, lcl_feat], dim=3))return feat
2,LTA: Local Temporal Aggregation
该模块就是一个Conv3d用于聚合相邻帧之间的特征,定义如下:
self.LTA = nn.Sequential(BasicConv3d(in_c[0], in_c[0], kernel_size=(3, 1, 1), stride=(3, 1, 1), padding=(0, 0, 0)),nn.LeakyReLU(inplace=True))
3, Gait Recognition Head
head部分由时序特征池化TP、空间特征池化GeMHPP、以及SeparateFCs组成。TP和SeparateFCs结构与GaitSet一样,重点在于将HPP改为了GeMHPP。
motivation: HPP对所有数据集采用相同的处理方式(指按固定比例混合全局池化和平均池化),不能自适应处理。
method: 公式如下,通过参数p来自适应调整比例。当p=1,等价于平均池化;当p趋于无穷,等价于最大池化。 Y T F M Y_{TFM} YTFM表示TP后的特征。
Y S F M G e M = F G e M ( Y T F M ) F G e M ( Y T F M ) = ( F Avg 1 × 1 × 1 × W f m ( ( Y T F M ) p ) ) 1 p \begin{gathered} Y_{S F M}^{G e M}=F_{G e M}\left(Y_{T F M}\right) \\ F_{G e M}\left(Y_{T F M}\right)=\left(F_{\text {Avg }}^{1 \times 1 \times 1 \times W_{f m}}\left(\left(Y_{T F M}\right)^p\right)\right)^{\frac{1}{p}} \end{gathered} YSFMGeM=FGeM(YTFM)FGeM(YTFM)=(FAvg 1×1×1×Wfm((YTFM)p))p1
代码如下:做法和HPP差不多,先分成不同的part,然后再在每个part内进行池化。
class GeMHPP(nn.Module):def __init__(self, bin_num=[64], p=6.5, eps=1.0e-6):super(GeMHPP, self).__init__()self.bin_num = bin_numself.p = nn.Parameter(torch.ones(1)*p)self.eps = epsdef gem(self, ipts):return F.avg_pool2d(ipts.clamp(min=self.eps).pow(self.p), (1, ipts.size(-1))).pow(1. / self.p)def forward(self, x):"""x : [n, c, h, w]ret: [n, c, p] """n, c = x.size()[:2]features = []for b in self.bin_num:z = x.view(n, c, b, -1)z = self.gem(z).squeeze(-1)features.append(z)return torch.cat(features, -1)
从代码中可以看出,对于每个part,p的值是共享的。是否对于每个part用不同的p值会更好?不过按论文的说法,p是针对dataset的,所以同一个数据集内用同一个p就可以了。
4, forward
def forward(self, inputs):ipts, labs, _, _, seqL = inputsseqL = None if not self.training else seqLif not self.training and len(labs) != 1:raise ValueError('The input size of each GPU must be 1 in testing mode, but got {}!'.format(len(labs)))sils = ipts[0].unsqueeze(1)del iptsn, _, s, h, w = sils.size()if s < 3:repeat = 3 if s == 1 else 2sils = sils.repeat(1, 1, repeat, 1, 1)outs = self.conv3d(sils)outs = self.LTA(outs)outs = self.GLConvA0(outs)outs = self.MaxPool0(outs)outs = self.GLConvA1(outs)outs = self.GLConvB2(outs) # [n, c, s, h, w]outs = self.TP(outs, seqL=seqL, options={"dim": 2})[0] # [n, c, h, w]outs = self.HPP(outs) # [n, c, p]gait = self.Head0(outs) # [n, c, p]if self.Bn_head: # Original GaitGL Headbnft = self.Bn(gait) # [n, c, p]logi = self.Head1(bnft) # [n, c, p]embed = bnftelse: # BNNechk as Headbnft, logi = self.BNNecks(gait) # [n, c, p]embed = gaitn, _, s, h, w = sils.size()retval = {'training_feat': {'triplet': {'embeddings': embed, 'labels': labs},'softmax': {'logits': logi, 'labels': labs}},'visual_summary': {'image/sils': sils.view(n*s, 1, h, w)},'inference_feat': {'embeddings': embed}}return retval
五、SMPLGait:
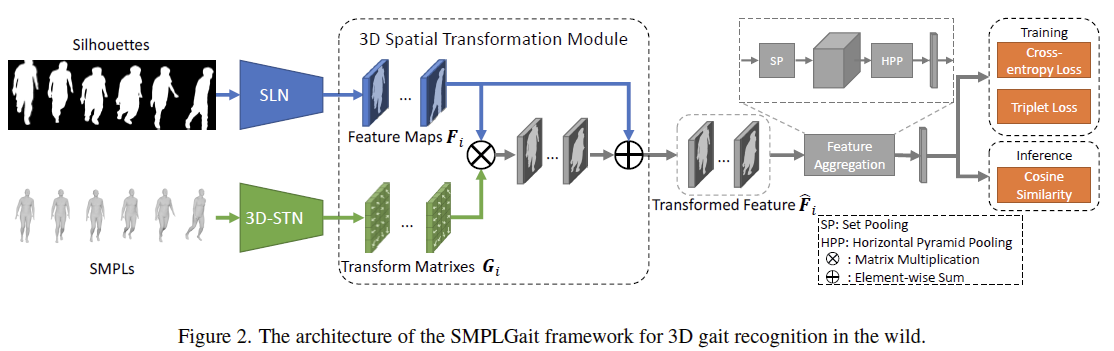
SMPLGait是一个多模态步态识别框架,利用silhouettes和SMPLs两种模态的信息来提取特征,分别对应于SLN和3D-STN模块。
1,SLN:Silhouette Learning Network
SLN网络和GaitSet类似,都是用Conv2d+Pooling来提取特征,因此需要用SetBlockWrapper封装。
self.Backbone = self.get_backbone(model_cfg['backbone_cfg'])self.Backbone = SetBlockWrapper(self.Backbone)
2, 3D-STN: 3D Spatial Transformation Network
3D-STN由三个全连接层组成,用于把SMPL的输入从一维向量转为二位的特征图(input dimension->128->256->h*w)。
# for SMPLself.fc1 = nn.Linear(85, 128)self.fc2 = nn.Linear(128, 256)self.fc3 = nn.Linear(256, 256)self.bn1 = nn.BatchNorm1d(128)self.bn2 = nn.BatchNorm1d(256)self.bn3 = nn.BatchNorm1d(256)self.dropout2 = nn.Dropout(p=0.2)self.dropout3 = nn.Dropout(p=0.2)
3, 3D Spatial Transformation Module: 融合多模态特征
# extract SMPL featuressmpls = ipts[1] # [n, s, d]n, s, d = smpls.size()sps = smpls.view(-1, d)sps = F.relu(self.bn1(self.fc1(sps)))sps = F.relu(self.bn2(self.dropout2(self.fc2(sps)))) # (B, 256)sps = F.relu(self.bn3(self.dropout3(self.fc3(sps)))) # (B, 256)sps = sps.reshape(n, 1, s, 16, 16)iden = Variable(torch.eye(16)).unsqueeze(0).repeat(n, 1, s, 1, 1) # [n, 1, s, 16, 16]if sps.is_cuda:iden = iden.cuda()sps_trans = sps + iden # [n, 1, s, 16, 16]. I+G in paper# extract SMPL featuressils = ipts[0] # [n, s, h, w]outs = self.Backbone(sils) # [n, c, s, h, w]outs_n, outs_c, outs_s, outs_h, outs_w = outs.size()zero_tensor = Variable(torch.zeros((outs_n, outs_c, outs_s, outs_h, outs_h-outs_w)))if outs.is_cuda:zero_tensor = zero_tensor.cuda()# [n, s, c, h, h] [n, s, c, 16, 16]outs = torch.cat([outs, zero_tensor], -1) # zero padding on the short edge (i.e., w) outs = outs.reshape(outs_n*outs_c*outs_s, outs_h,outs_h) # [n*c*s, 16, 16]sps = sps_trans.repeat(1, outs_c, 1, 1, 1).reshape(outs_n * outs_c * outs_s, 16, 16) # repeat on the dimension c, i.e., 1->couts_trans = torch.bmm(outs, sps) # batch matrix multiplicationouts_trans = outs_trans.reshape(outs_n, outs_c, outs_s, outs_h, outs_h) # fused features
剩下的就是TP,HPP和SeparateFCs了。
六、GaitEdge
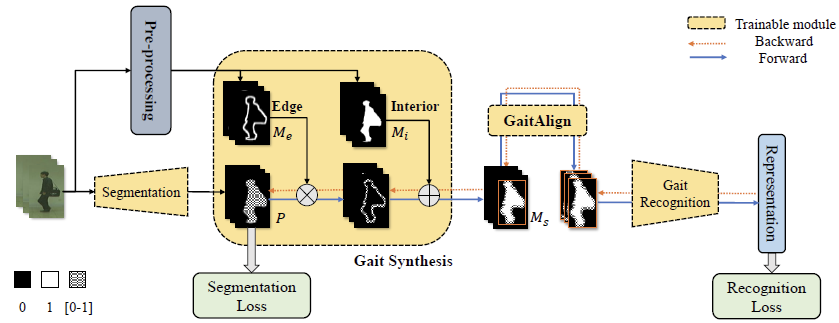
GaitEdge的网络由三个部分组成:Silhouette Segmentation网络, Gait Synthesis模块和Gait Recognition网络,训练也是分两阶段进行。Segmentation网络的主干为U-net,用于分割人体信息,训练损失为bce loss; Gait Synthesis模块用于对分割出的人体信息进行增强,Recognition网络的主干为GaitGL。
1,pre-process:提取边缘信息和内部信息
预处理过程旨在通过膨胀腐蚀等形态学操作来从轮廓图像中提取边缘信息和内部信息,如下图所示。公式中, M M M表示轮廓图, M e M_e Me表示边缘信息, M i M_i Mi是内部信息。
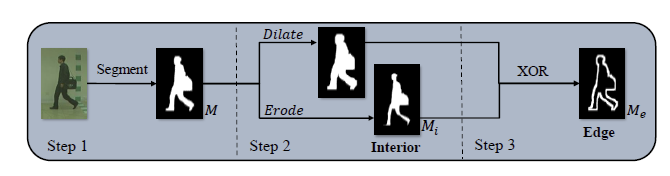
M i = erode ( M ) M e = M i ∨ ‾ dilate ( M ) \begin{aligned} & M_i=\operatorname{erode}(M) \\ & M_e=M_i \underline{\vee} \operatorname{dilate}(M) \end{aligned} Mi=erode(M)Me=Mi∨dilate(M)
def preprocess(self, sils):dilated_mask = (morph.dilation(sils, self.kernel.to(sils.device)).detach()) > 0.5 # Dilationeroded_mask = (morph.erosion(sils, self.kernel.to(sils.device)).detach()) > 0.5 # Erosionedge_mask = dilated_mask ^ eroded_maskreturn edge_mask, eroded_mas
2, Gait Synthesis: 依据边缘信息和内部信息对分割出的人体信息进行增强
P P P是U-net分割结果, M s M_s Ms是Gait Synthesis的输出。
M s = M e × P + M i M_s=M_e \times P+M_i Ms=Me×P+Mi
ratios = ipts[0]rgbs = ipts[1]sils = ipts[2]n, s, c, h, w = rgbs.size()rgbs = rgbs.view(n*s, c, h, w)sils = sils.view(n*s, 1, h, w)logis = self.Backbone(rgbs) # [n, s, c, h, w]logits = torch.sigmoid(logis)mask = torch.round(logits).float() # U-net segmentation result if self.is_edge:edge_mask, eroded_mask = self.preprocess(sils)# Gait Synthesisnew_logits = edge_mask*logits+eroded_mask*sils
3, Gait Align
Gait Align模块用于将增强后的人体信息与轮廓图进行对齐,代码如下:
self.gait_align = GaitAlign()# forwardratios = ipts[0]cropped_logits = self.gait_align(new_logits, sils, ratios)
GaitAlign的定义如下:

class GaitAlign(nn.Module):"""GaitEdge: Beyond Plain End-to-end Gait Recognition for Better PracticalityECCV2022: https://arxiv.org/pdf/2203.03972v2.pdfGithub: https://github.com/ShiqiYu/OpenGait/tree/master/configs/gaitedge"""def __init__(self, H=64, W=44, eps=1, **kwargs):super(GaitAlign, self).__init__()self.H, self.W, self.eps = H, W, epsself.Pad = nn.ZeroPad2d((int(self.W / 2), int(self.W / 2), 0, 0))self.RoiPool = RoIAlign((self.H, self.W), 1, sampling_ratio=-1)def forward(self, feature_map, binary_mask, w_h_ratio):"""In sils: [n, c, h, w]w_h_ratio: [n, 1]Out aligned_sils: [n, c, H, W]"""n, c, h, w = feature_map.size()# w_h_ratio = w_h_ratio.repeat(1, 1) # [n, 1]w_h_ratio = w_h_ratio.view(-1, 1) # [n, 1]h_sum = binary_mask.sum(-1) # [n, c, h]_ = (h_sum >= self.eps).float().cumsum(axis=-1) # [n, c, h]h_top = (_ == 0).float().sum(-1) # [n, c]h_bot = (_ != torch.max(_, dim=-1, keepdim=True)[0]).float().sum(-1) + 1. # [n, c]w_sum = binary_mask.sum(-2) # [n, c, w]w_cumsum = w_sum.cumsum(axis=-1) # [n, c, w]w_h_sum = w_sum.sum(-1).unsqueeze(-1) # [n, c, 1]w_center = (w_cumsum < w_h_sum / 2.).float().sum(-1) # [n, c]p1 = self.W - self.H * w_h_ratiop1 = p1 / 2.p1 = torch.clamp(p1, min=0) # [n, c]t_w = w_h_ratio * self.H / wp2 = p1 / t_w # [n, c]height = h_bot - h_top # [n, c]width = height * w / h # [n, c]width_p = int(self.W / 2)feature_map = self.Pad(feature_map)w_center = w_center + width_p # [n, c]w_left = w_center - width / 2 - p2 # [n, c]w_right = w_center + width / 2 + p2 # [n, c]w_left = torch.clamp(w_left, min=0., max=w+2*width_p)w_right = torch.clamp(w_right, min=0., max=w+2*width_p)boxes = torch.cat([w_left, h_top, w_right, h_bot], dim=-1)# index of bbox in batchbox_index = torch.arange(n, device=feature_map.device)rois = torch.cat([box_index.view(-1, 1), boxes], -1)crops = self.RoiPool(feature_map, rois) # [n, c, H, W]return crops
最终将cropped_logits送入GaitGL进行步态识别。
七、GaitBase
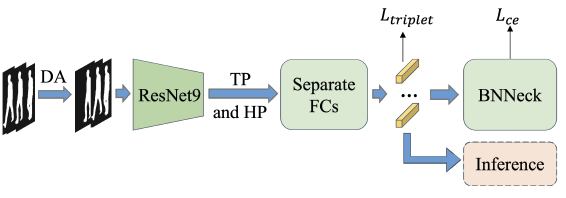
GaitBase是OpenGait中的Baseline,其用很简单的模型,在多个数据集上取得了很好的效果。
1, backbone: ResNet-9
GaitBase的backbone采用ResNet-9并用SetBlockWrapper封装。
2, TP和HPP
TP、HPP模块与GaitSet相同。
3,BNNeck
BNNeck是在特征层之后、分类层FC层之前添加一个BN(batch normalization)层,BN层之前的特征表示为 embed1 , embed1 经过BN层归一化之后得到特征 embed2 ,分别用 embed1和 embed2去计算triplet loss和CE loss。代码如下:
class SeparateBNNecks(nn.Module):"""Bag of Tricks and a Strong Baseline for Deep Person Re-IdentificationCVPR Workshop: https://openaccess.thecvf.com/content_CVPRW_2019/papers/TRMTMCT/Luo_Bag_of_Tricks_and_a_Strong_Baseline_for_Deep_Person_CVPRW_2019_paper.pdfGithub: https://github.com/michuanhaohao/reid-strong-baseline"""def __init__(self, parts_num, in_channels, class_num, norm=True, parallel_BN1d=True):super(SeparateBNNecks, self).__init__()self.p = parts_numself.class_num = class_numself.norm = normself.fc_bin = nn.Parameter(nn.init.xavier_uniform_(torch.zeros(parts_num, in_channels, class_num)))if parallel_BN1d: # 为True,则BN在不同part之间共享self.bn1d = nn.BatchNorm1d(in_channels * parts_num)else:self.bn1d = clones(nn.BatchNorm1d(in_channels), parts_num)self.parallel_BN1d = parallel_BN1ddef forward(self, x):"""x: [n, c, p]"""if self.parallel_BN1d:n, c, p = x.size()x = x.view(n, -1) # [n, c*p]x = self.bn1d(x)x = x.view(n, c, p)else:x = torch.cat([bn(_x) for _x, bn in zip(x.split(1, 2), self.bn1d)], 2) # [p, n, c]feature = x.permute(2, 0, 1).contiguous()if self.norm:feature = F.normalize(feature, dim=-1) # [p, n, c]logits = feature.matmul(F.normalize(self.fc_bin, dim=1)) # [p, n, c]else:logits = feature.matmul(self.fc_bin)return feature.permute(1, 2, 0).contiguous(), logits.permute(1, 2, 0).contiguous()
相关文章:
步态识别常见模块解读及代码实现:基于OpenGait框架
步态识别常见模块解读及代码实现:基于OpenGait框架 最近在看步态识别相关论文,但是因为记忆力下降的原因,老是忘记一些内容。因此记录下来方便以后查阅,仅供自己学习参考,没有背景知识和论文介绍。 目录 步态识别常见…...

前端八股文之“闭包”
一、定义 一句话概括闭包:能够访问函数内部变量的函数与这个变量的组合构成了闭包结构。如下代码 function fuc1(){let num 999return function fuc2(){console.log(num)}}fuc1()(); 如代码所示,fuc2和父级变量num构成了一个闭包环境。 二、原理 子…...

数据可视化:掌握数据领域的万金油技能
⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️ 🐴作者:秋无之地 🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据开发、数据分析等。 🐴欢迎小伙伴们点赞👍🏻、收藏⭐️、…...
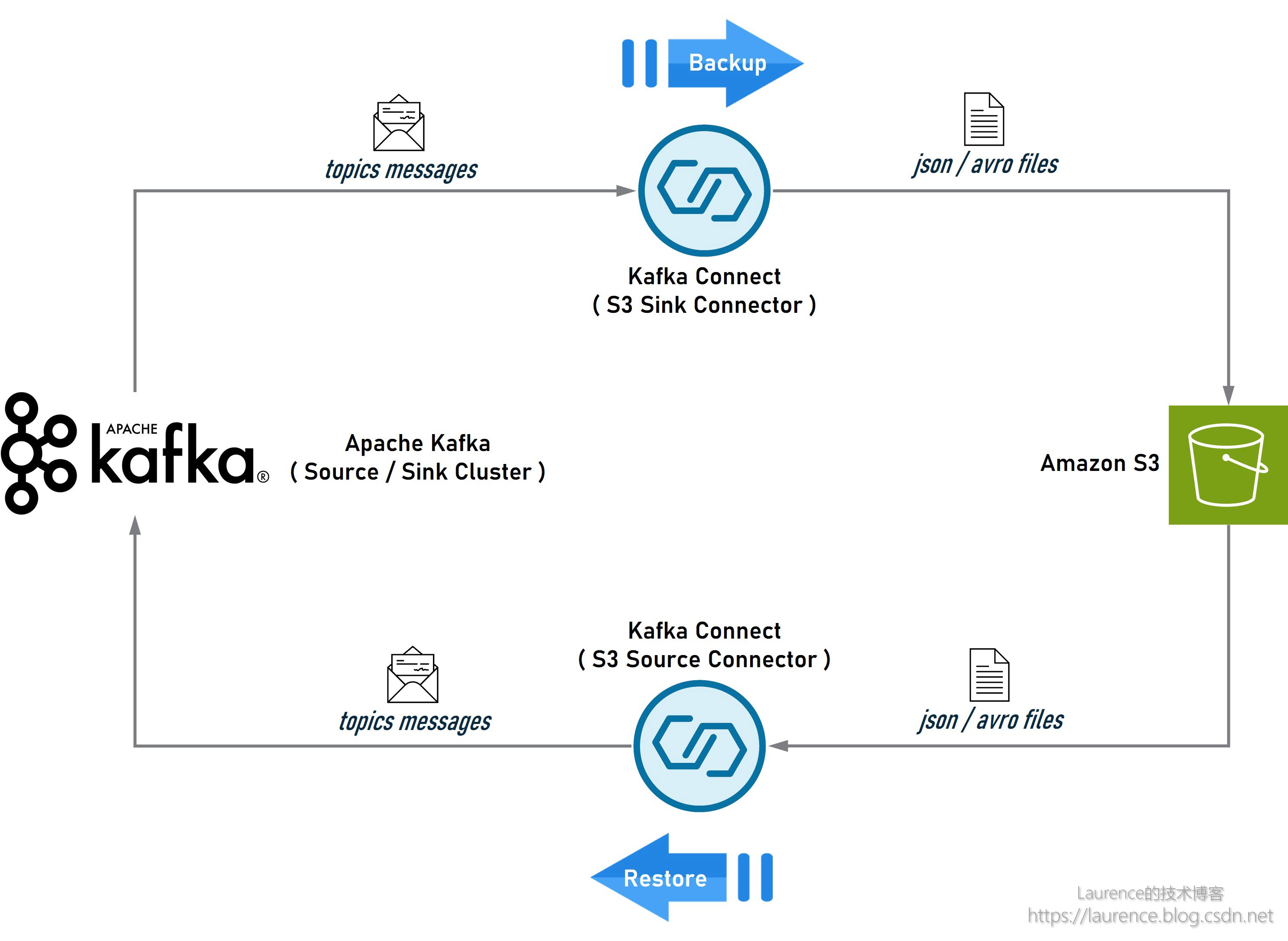
Apache Kafka 基于 S3 的数据导出、导入、备份、还原、迁移方案
在系统升级或迁移时,用户常常需要将一个 Kafka 集群中的数据导出(备份),然后在新集群或另一个集群中再将数据导入(还原)。通常,Kafka集群间的数据复制和同步多采用 Kafka MirrorMaker࿰…...

事务管理AOP
事务管理 事务回顾 概念:事务是一组操作的集合,它是一个不可分割的工作单位,这些操作要么同时成功,要么同时失败 操作: 开启事务:一组操作开始前,开启事务-start transaction/be…...

Java从Tif中抽取最大的那张图进行裁剪成x*y份
之前我有一篇帖子《kfb格式文件转jpg格式》讲述到 kfb > tif > jpg,但是针对于超大tif中的大图是无法顺利提取的,就算是能顺利提取,试想一下,2G的tif文件,如果能提取处理最大的那张图,并且在不压缩的…...

人工智能AI界的龙头企业,炸裂的“英伟达”时代能走多远
原创 | 文 BFT机器人 1、AI芯片的竞争格局已趋白热化 尽管各类具有不同功能和定位的AI芯片在一定程度上可实现互补,但同时也在机遇与挑战并存中持续调整定位。在AI训练端,英伟达的GPU凭着高算力的门槛,一直都是训练端的首选。 只有少数芯片能…...

【实战】H5 页面同时适配 PC 移动端 —— 旋转横屏
文章目录 一、场景二、方案三、书单推荐01 《深入实践Kotlin元编程》02 《Spring Boot学习指南》03 《Kotlin编程实战》 一、场景 一个做数据监控的单页面,页面主要内容是一个整体必须是宽屏才能正常展示,这时就不能用传统的适配方案了,需要…...
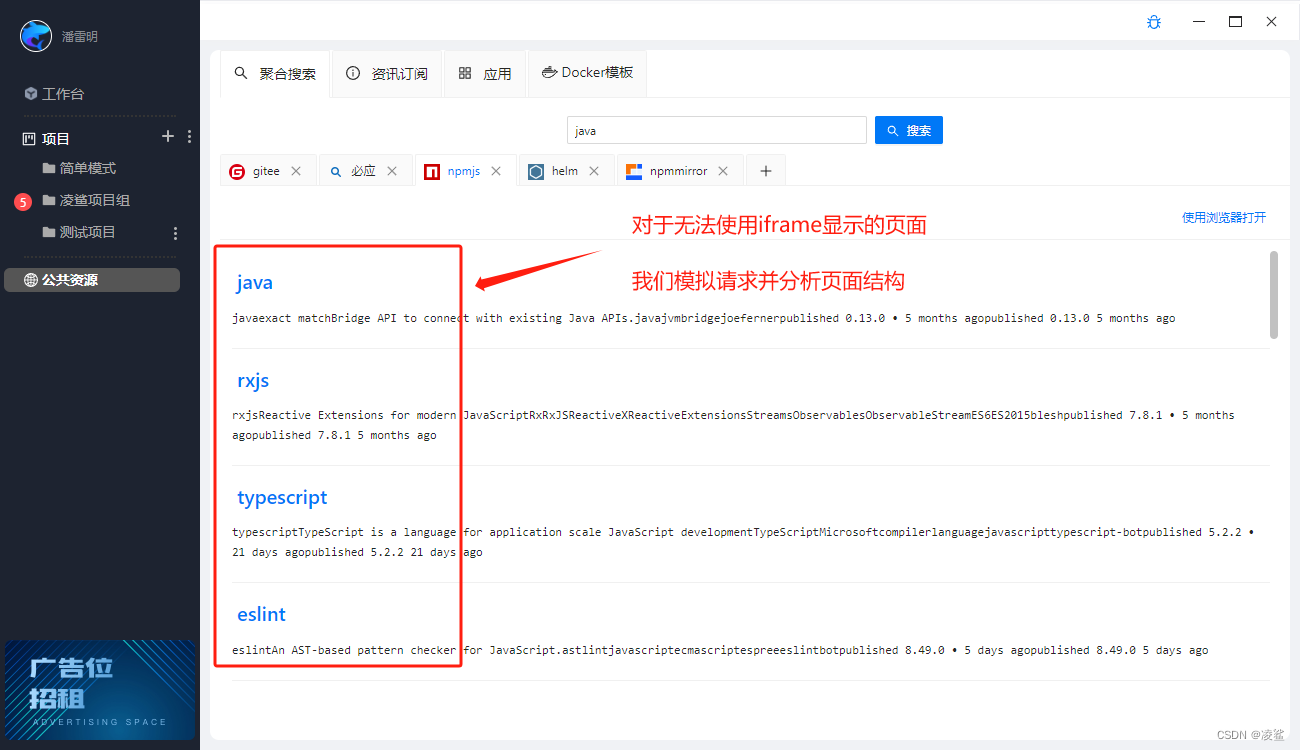
使用凌鲨进行聚合搜索
作为研发人员,我们经常需要在多个来源之间查找信息,以便进行研发工作。除了常用的搜索引擎如百度和必应之外,我们还需要查阅各种代码文档和依赖包等资源。这些资源通常分散在各个网站和文档库中,需要花费一定的时间和精力才能找到…...

程序设计之——手把手教你如何从Excel文件中读取学生信息
在当今信息化时代,计算机技术已经深入到各个领域,而程序设计则成为推动信息化建设的关键技术之一。在众多领域中,学生信息管理系统无疑是其中一个重要的应用。本文将从学生信息管理系统的开发入手,探讨开如何高效且保证质量的完成…...

Docker容器化技术(从零学会Docker)
文章目录 前言一、初识Docker1.初识Docker-Docker概述2.初识Docker-安装Docker3.初识Docker-Docker架构4.初识Docker-配置镜像加速器 二、Docker命令1.Docker命令-服务相关命令2.Docker命令-镜像相关命令3.Docker命令-容器相关命令 三、Docker容器的数据卷1.Docker容器数据卷-数…...

【新版】系统架构设计师 - 案例分析 - 总览
个人总结,仅供参考,欢迎加好友一起讨论 架构 - 案例分析 - 总览 新旧大纲对应 旧版新版系统规划软件架构设计设计模式系统设计系统建模分布式系统设计嵌入式系统设计系统的可靠性分析与设计系统的安全性和保密性设计系统计划信息系统架构的设计理论和实…...
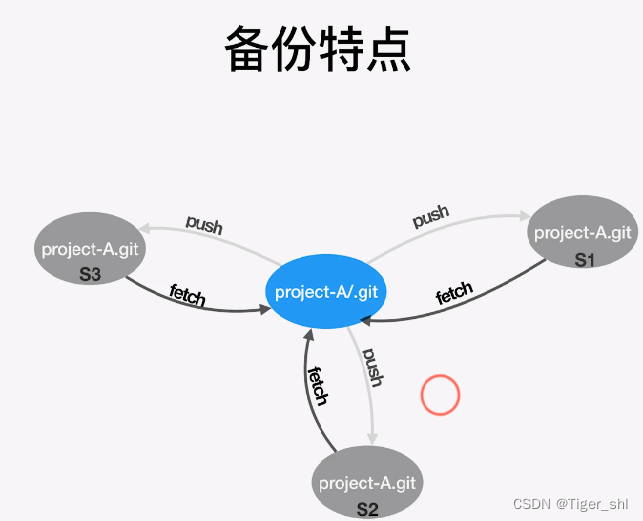
【Git】02-Git常见应用
文章目录 1. 删除不需要分支2. 修改最新Commit的Message3. 修改之前Commit的Message4. 连续多个Commit整理为一个5. 不连续的Commit整理为一个6. 比较暂存区和HEAD中文件差异7. 比较工作区和暂存区中文件差异8. 将暂存区恢复为HEAD相同9. 工作区文件恢复和暂存区相同10. 取消暂…...

YOLO物体检测-系列教程2:YOLOV2整体解读
🎈🎈🎈YOLO 系列教程 总目录 YOLOV1整体解读 YOLOV2整体解读 YOLOV2提出论文:YOLO9000: Better, Faster, Stronger 1、YOLOV1 优点:快速,简单!问题1:每个Cell只预测一个类别&…...

u盘传输数据的时候拔出会怎么样?小心这些危害
U盘是我们日常生活和工作中常使用的一种便携式存储设备。然而,在使用U盘传输数据时,有时我们会不小心将它拔出,而这个看似微不足道的行为实际上可能会带来严重的后果。本文将向您介绍U盘在传输数据时突然拔出可能导致的各种危害,其…...

【踩坑纪实】URL 特殊字符 400 异常
URL 特殊字符 400 异常 笔者之前在写后端或者前端时,在处理表单时,经常有对特殊字符的检验处理,但自己也不清楚为什么要这么做,浅浅地以为可能是特殊字符不好看或者存取可能会造成异常?不过一直没遇到过问题ÿ…...

Contents:帮助公司为营销目的创建内容
【产品介绍】 名称 Contents上线时间 2017年5月 具体描述 Contents是一家提供基于人工智能的内容生成平台的企业,可以帮助用户在各种网站和工具中使用最先进的机器学习模型,实现视频编辑、图像生成、3D建模等内容创作。【团队介绍…...

1397: 图的遍历——广度优先搜索
题目描述 广度优先搜索遍历类似于树的按层次遍历的过程。其过程为:假设从图中的某顶点v出发,在访问了v之后依次访问v的各个未曾被访问过的邻接点,然后分别从这些邻接点出发依次访问它们的邻接点,并使“先被访问的顶点的邻接点”先…...
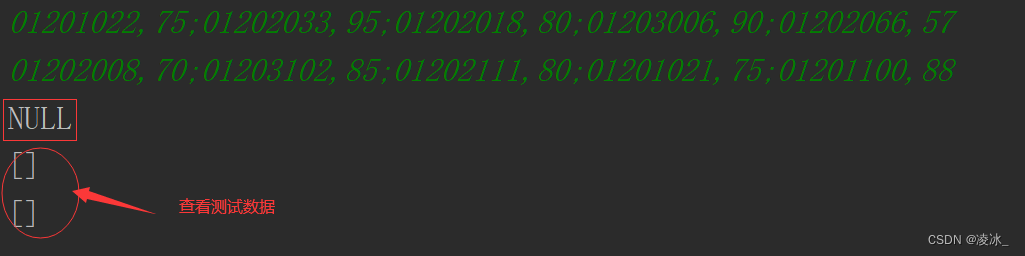
Java 华为真题-选修课
需求: 现有两门选修课,每门选修课都有一部分学生选修,每个学生都有选修课的成绩,需要你找出同时选修了两门选修课的学生,先按照班级进行划分,班级编号小的先输出,每个班级按照两门选修课成绩和的…...

Invalid access token: Invalid header string: ‘utf-8‘ codec can‘t decode byte
报错:在运行一个txt文档时报Invalid access token: Invalid header string: ‘utf-8’ codec can’t decode byte 原因:文档编码方式的原因,电脑默认的是UFT-8格式的编码 解决方法:用notepad改一下文档编码就好...


3分钟掌握PC端聊天软件防撤回:RevokeMsgPatcher实战指南
3分钟掌握PC端聊天软件防撤回:RevokeMsgPatcher实战指南 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) 项目地址: https://gitcode.…...
的紧急处理)
Kafka 场景化面试题top4: 消息积压(Lag)的紧急处理
场景:凌晨 3 点,监控系统报警,发现某个核心 Topic 的消息积压了上千万条,且消费速度远远跟不上生产速度。作为值班工程师,你该如何快速恢复业务,减少积压? 紧急处理四步走(SOP&#…...

反PUA30天 Day15:“你格局小“——当这句话出现时,通常意味着对方已经没有别的论据了 |乐想屋
“本文来自「乐想屋」公众号,系列更新[职场反PUA30天觉醒计][职场生存暗规则],每天一篇清醒认知,拒绝内耗,少踩坑,快速成长。”绩效沟通那天,leader跟我说了一句话:「你不要老盯着自己那一亩三分…...
:企业级生产环境已验证)
DeepSeek R1模型API接入全流程(含鉴权失效应急手册):企业级生产环境已验证
更多请点击: https://intelliparadigm.com 第一章:DeepSeek R1模型API接入全流程(含鉴权失效应急手册):企业级生产环境已验证 DeepSeek R1 是当前高性能开源大语言模型之一,其官方 API 提供稳定、低延迟的…...

React 18 + Vite + Tailwind CSS 构建现代化SaaS落地页实战
1. 项目概述与设计思路最近在做一个保险科技(InsurTech)相关的概念项目,需要为这个名为“Insura”的SaaS平台打造一个现代化的落地页(Landing Page)。这个页面的核心目标很明确:向潜在客户(主要…...

2026浏览器插件指纹溯源机制与插件环境安全优化实战指南
一、前言:插件特征成为批量虚拟环境识别的新型突破口在矩阵运营行业精细化风控对抗背景下,UA 修改、IP 切换、基础指纹伪装已经成为行业标配操作,平台逐渐放弃基础参数检测,转向高隐蔽、高区分度、极易被忽略的插件指纹进行设备识…...

ComfyUI-FramePackWrapper终极指南:8GB显存玩转高质量AI视频生成
ComfyUI-FramePackWrapper终极指南:8GB显存玩转高质量AI视频生成 【免费下载链接】ComfyUI-FramePackWrapper 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-FramePackWrapper 想要在有限硬件条件下实现专业级AI视频生成吗?ComfyUI-Fram…...

独立开发者工具箱:模块化架构与全栈实践指南
1. 项目概述:一个独立开发者的工具箱 如果你是一个独立开发者,或者正在尝试构建自己的数字产品,那么你一定经历过这样的时刻:一个想法在脑海中成型,你迫不及待地想把它变成现实,但当你打开编辑器࿰…...

基于STC89C51单片机的多波形信号发生器设计与Proteus仿真
基于STC89C51单片机的多波形信号发生器设计与Proteus仿真 摘 要 随着电子技术和集成电路的飞速发展,信号发生器作为电子测量领域的基础设备,其性能和智能化水平不断提升。本设计以STC89C51单片机为控制核心,设计了一款多波形信号发生器。系统…...