Pytorch Advanced(一) Generative Adversarial Networks
生成对抗神经网络GAN,发挥神经网络的想象力,可以说是十分厉害了
参考
1、AI作家
2、将模糊图变清晰(去雨,去雾,去抖动,去马赛克等),这需要AI具有“想象力”,能脑补情节;
3、进行数据增强,根据已有数据生成更多新数据供以feed,可以减缓模型过拟合现象。
那到底是怎么实现的呢?
GAN中有两大组成部分G和D
G是generator,生成器: 负责凭空捏造数据出来
D是discriminator,判别器: 负责判断数据是不是真数据
示例图如下:

给一个随机噪声z,通过G生成一张假图,然后用D去分辨是真图还是假图。假设G生成了一张图,在D那里的得分很高,那么G就很成功的骗过了D,如果D很轻松的分辨出了假图,那么G的效果不好,那么就需要调整参数了。
G和D是两个单独的网络,那么他们的参数都是训练好的吗?并不是,两个网络的参数是需要在博弈的过程中分别优化的。
下面就是一个训练的过程:

GAN在一轮反向传播中分为两步,先训练D在训练G。
训练D时,上一轮G产生的图片,和真实图片一起作为x进行输入,假图为0,真图标签为1,通过x生成一个score,通过score和标签y计算损失,就可以进行反向传播了。
训练G时,G和D是一个整体,取名为D_on_G。输入随机噪声,G产生一个假图,D去分辨,score = 1就是需要我们需要优化的目标,意思就是我们要让生成的图片变成真的。这里的D是不需要参与梯度计算的,我们通过反向传播来优化G,让他生成更加真实的图片。这就好比:如果你参加考试,你别指望能改变老师的评分标准
GAN无监督学习,(cGAN是有监督的),以后会学习的。怎么理解无监督学习呢?这里给的真图是没有经过人工标注的,只知道这是真的,D是不知道这是什么的,只需要分辨真假。G也不知道生成了什么,只需要学真图去骗D。
具体如何实施呢?
import os
import torch
import torchvision
import torch.nn as nn
from torchvision import transforms
from torchvision.utils import save_imagedevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')latent_size = 64
hidden_size = 256
image_size = 784
num_epochs = 200
batch_size = 100
sample_dir = 'samples'注意这里有个归一化的过程,MNIST是单通道,但是如果mean=(0.5,0.5,0.5)会报错,因为是对3通道操作 。
if not os.path.exists(sample_dir):os.makedirs(sample_dir)transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=(0.5,), # 3 for RGB channelsstd=(0.5,))])# MNIST dataset
mnist = torchvision.datasets.MNIST(root='./data/',train=True,transform=transform,download=True)
# Data loader
data_loader = torch.utils.data.DataLoader(dataset=mnist,batch_size=batch_size, shuffle=True)定义生成器和判别器:
生成器:可以看到输入的维度为64,是一组噪声图像,通过生成器将特征扩大到了MNIST图像大小784。
判别器:输入维度为图像大小,最后输出特征个数为1,采用sigmoid激活(不用softmax的)
# Discriminator
D = nn.Sequential(nn.Linear(image_size, hidden_size),nn.LeakyReLU(0.2),nn.Linear(hidden_size, hidden_size),nn.LeakyReLU(0.2),nn.Linear(hidden_size, 1),nn.Sigmoid())# Generator
G = nn.Sequential(nn.Linear(latent_size, hidden_size),nn.ReLU(),nn.Linear(hidden_size, hidden_size),nn.ReLU(),nn.Linear(hidden_size, image_size),nn.Tanh())# Device setting
D = D.to(device)
G = G.to(device)# Binary cross entropy loss and optimizer
criterion = nn.BCELoss()
d_optimizer = torch.optim.Adam(D.parameters(), lr=0.0002)
g_optimizer = torch.optim.Adam(G.parameters(), lr=0.0002)def denorm(x):out = (x + 1) / 2return out.clamp(0, 1)def reset_grad():d_optimizer.zero_grad()g_optimizer.zero_grad()重点看训练部分,我们到底是如何来训练GAN的。
判别器部分:判别器的损失值分为两部分,(一)将mini_batch定义为正样本,告诉他我是正品,所以设置标签为1。优化判别器判断正品的能力;(二)生成一幅赝品,再给判别器判别,这时候赝品的标签为0,优化判断赝品的能力。所以总损失为这两部分之和,计算梯度,优化判别器参数。
G_on_D:输入一个噪声,让生成器生成一幅图像,然后让D去判别,计算和正品之间的距离,即损失。反向传播,优化G的参数。
# Start training
total_step = len(data_loader)
for epoch in range(num_epochs):for i, (images, _) in enumerate(data_loader):images = images.reshape(batch_size, -1).to(device)# Create the labels which are later used as input for the BCE lossreal_labels = torch.ones(batch_size, 1).to(device)fake_labels = torch.zeros(batch_size, 1).to(device)# ================================================================== ## Train the discriminator ## ================================================================== ## Compute BCE_Loss using real images where BCE_Loss(x, y): - y * log(D(x)) - (1-y) * log(1 - D(x))# Second term of the loss is always zero since real_labels == 1outputs = D(images)d_loss_real = criterion(outputs, real_labels)real_score = outputs# Compute BCELoss using fake images# First term of the loss is always zero since fake_labels == 0z = torch.randn(batch_size, latent_size).to(device)fake_images = G(z)outputs = D(fake_images)d_loss_fake = criterion(outputs, fake_labels)fake_score = outputs# Backprop and optimized_loss = d_loss_real + d_loss_fakereset_grad()d_loss.backward()d_optimizer.step()# ================================================================== ## Train the generator ## ================================================================== ## Compute loss with fake imagesz = torch.randn(batch_size, latent_size).to(device)fake_images = G(z)outputs = D(fake_images)# We train G to maximize log(D(G(z)) instead of minimizing log(1-D(G(z)))# For the reason, see the last paragraph of section 3. https://arxiv.org/pdf/1406.2661.pdfg_loss = criterion(outputs, real_labels)# Backprop and optimizereset_grad()g_loss.backward()g_optimizer.step()if (i+1) % 200 == 0:print('Epoch [{}/{}], Step [{}/{}], d_loss: {:.4f}, g_loss: {:.4f}, D(x): {:.2f}, D(G(z)): {:.2f}' .format(epoch, num_epochs, i+1, total_step, d_loss.item(), g_loss.item(), real_score.mean().item(), fake_score.mean().item()))# Save real imagesif (epoch+1) == 1:images = images.reshape(images.size(0), 1, 28, 28)save_image(denorm(images), os.path.join(sample_dir, 'real_images.png'))# Save sampled imagesfake_images = fake_images.reshape(fake_images.size(0), 1, 28, 28)save_image(denorm(fake_images), os.path.join(sample_dir, 'fake_images-{}.png'.format(epoch+1)))训练完了怎么用?
只要用我们的生成器就可以随意生成了。
import matplotlib.pyplot as plt
z = torch.randn(1,latent_size).to(device)
output = G(z)
plt.imshow(output.cpu().data.numpy().reshape(28,28),cmap='gray')
plt.show()下面就是随机生成的图像了!


相关文章:
Pytorch Advanced(一) Generative Adversarial Networks
生成对抗神经网络GAN,发挥神经网络的想象力,可以说是十分厉害了 参考 1、AI作家 2、将模糊图变清晰(去雨,去雾,去抖动,去马赛克等),这需要AI具有“想象力”,能脑补情节; 3、进行数…...

Python实操如何去除EXCEL表格中的公式并保留原有的数值
import xlwings as xw app xw.App(visibleTrue, add_bookFalse) # 创建一个不可见的Excel应用程序实例 wb app.books.open(rE:\公式.xlsx) # 打开Excel文件 sheet wb.sheets[DC] # 修改为你的工作表名称 # 假设需要清除公式的范围是A1到B10range_to_clear sheet.range(A…...
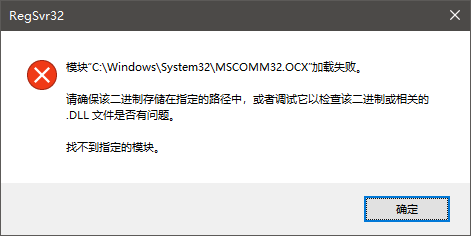
MFC串口通信控件MSCOMM32.OCX的安装注册
MSCOMM32.OCX是一个与Microsoft Corporation开发的MSComm控件相关联的文件。MSComm控件是软件应用程序用来与调制解调器、条形码读取器和其他串行设备等设备建立串行通信的通信控件。 下载地址1 https://download.csdn.net/download/m0_60352504/88345092 下载地址2 https://ww…...
(2023王道数据结构2.2.3前8题))
27.顺序表练习题目(1)(2023王道数据结构2.2.3前8题)
【这里所有解答都写的是全部代码,目的是让大家能够直接复制上手运行,感受代码的运行过程,而不单单只是写了一个函数】 试题1:(王道2023数据结构综合应用题1) 从顺序表中删除具有最小值的元素(…...
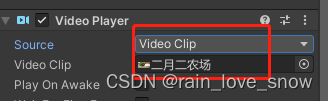
Unity VideoPlayer 指定位置开始播放
如果 source是 videoclip(以下两种方式都可以): _videoPlayer.Play();Debug.Log("time: " _videoPlayer.clip.length);_videoPlayer.time 10; [SerializeField] VideoPlayer videoPlayer;public void SetClipWithTime(VideoClip…...
美团多场景建模的探索与实践
本文介绍了美团到家/站外投放团队在多场景建模技术方向上的探索与实践。基于外部投放的业务背景,本文提出了一种自适应的场景知识迁移和场景聚合技术,解决了在投放中面临外部海量流量带来的场景数量丰富、场景间差异大的问题,取得了明显的效果…...
第11篇:ESP32vscode_platformio_idf框架helloworld点亮LED
第1篇:Arduino与ESP32开发板的安装方法 第2篇:ESP32 helloword第一个程序示范点亮板载LED 第3篇:vscode搭建esp32 arduino开发环境 第4篇:vscodeplatformio搭建esp32 arduino开发环境 第5篇:doit_esp32_devkit_v1使用pmw呼吸灯实验 第6篇:ESP32连接无源喇叭播…...

React中的页面跳转方式详解
在React中,页面跳转通常通过路由来实现。React有多种路由库可供选择,其中最常用的是React Router。React Router提供了几种不同的跳转方式,包括使用组件进行页面跳转、使用组件进行重定向,以及使用编程式导航进行跳转。 使用组件进…...
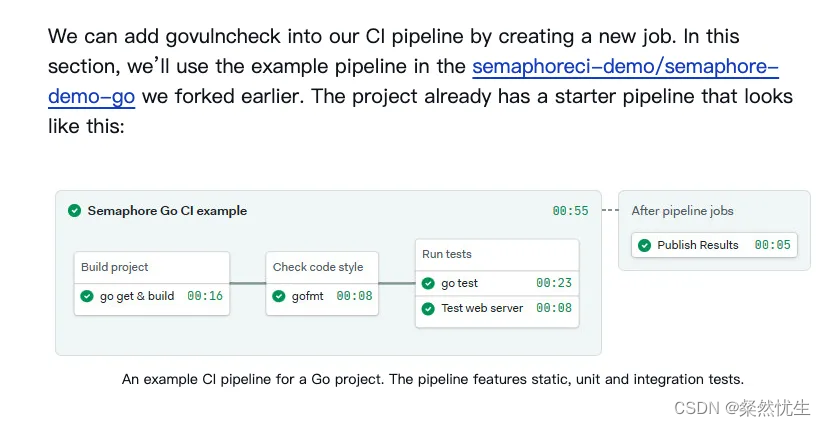
Golang代码漏洞扫描工具介绍——govulncheck
Golang Golang作为一款近年来最火热的服务端语言之一,深受广大程序员的喜爱,笔者最近也在用,特别是高并发的场景下,golang易用性的优势十分明显,但笔者这次想要介绍的并不是golang本身,而且golang代码的漏洞…...
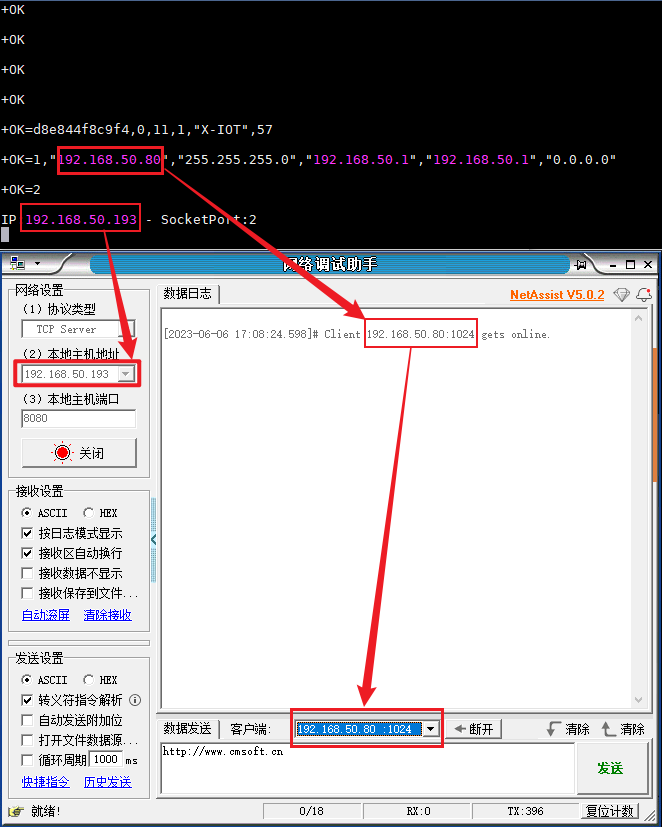
第31章_瑞萨MCU零基础入门系列教程之WIFI蓝牙模块驱动实验
本教程基于韦东山百问网出的 DShanMCU-RA6M5开发板 进行编写,需要的同学可以在这里获取: https://item.taobao.com/item.htm?id728461040949 配套资料获取:https://renesas-docs.100ask.net 瑞萨MCU零基础入门系列教程汇总: ht…...

arkworks工具栈概览
1. 引言 arkworks定位为zkSNARK编程的Rust生态。其开源代码见: https://github.com/arkworks-rs/ arkworks目前已广泛用于大量项目中,如:Aleo、anoma、celo、Espresso、Findora、Manta、Mina、Nimiq、penumbra等等。 参与arkworks开源实现…...
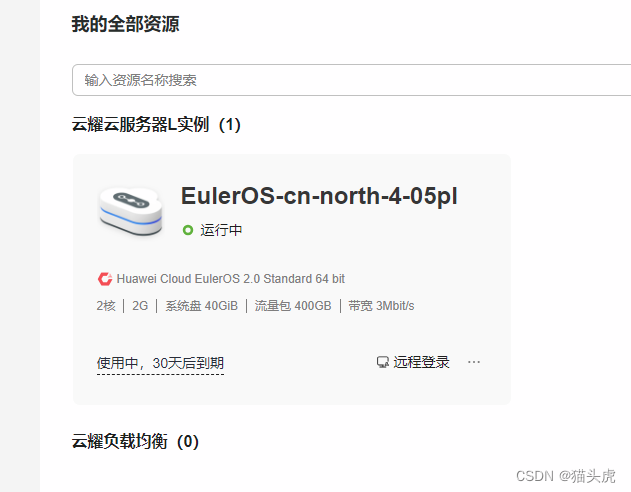
华为云云服务器云耀L实例评测 | 在华为云耀L实例上搭建电商店铺管理系统:一次场景体验
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...
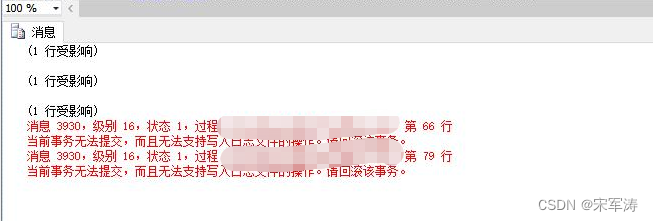
sqlserver存储过程报错:当前事务无法提交,而且无法支持写入日志文件的操作。请回滚该事务。
现象: 系统出现异常,手动执行过程提示如上。 问题排查: 1.直接执行的过程事务挂起(排除) 2.重启数据库实例(重启后无效) 3.过程中套用过程,套用的过程中使用事务,因为…...

二刷力扣--字符串
字符串 摘自Python文档-标准库: 在Python中, 字符串是由 Unicode 码位构成的不可变序列。 由于不存在单独的“字符”类型,对字符串做索引操作将产生一个长度为 1 的字符串。 也就是说,对于一个非空字符串 s, s[0] s[0:1]。 不存…...
如何将 OBJ 模型转换和压缩为 GLTF 以与 AWS IoT TwinMaker 配合使用
推荐:使用NSDT场景编辑器快速搭建3D应用场景 概述 在这篇博文中,引用了几种文件扩展名和模型格式。在开始之前,最好了解以下内容: OBJ – 对象文件,一种标准的 3D 图像格式,可以通过各种 3D 图像编辑程序…...

零基础学前端(四)重点讲解 CSS
1. 该篇适用于从零基础学习前端的小白 2. 初学者不懂代码得含义也要坚持模仿逐行敲代码,以身体感悟带动头脑去理解新知识 3. 初学者切忌,不要眼花缭乱,不要四处找其它文档,要坚定一个教授者的方式,将其学通透ÿ…...

类和对象【初始化列表与友元】
全文目录 初始化列表特性 explicit关键字static成员特性 友元友元函数友元类内部类特性 初始化列表 构造函数体中的语句只能将其称为赋初值,而不能称作初始化。因为初始化只能初始化一次,而构造函数体内可以多次赋值。 对象的初始化是在初始化列表进行…...

ActiveRecord::Migration.maintain_test_schema!
测试gem: rspec-rails 问题描述 在使用 rspec-rails 进行测试时,出现了以下错误 ActiveRecord::StatementInvalid: UndefinedFunction: ERROR: function init_id() does not exist这个错误与数据库架构有关。 schema.rb中 create_table "users…...

逆向-beginners之helloworld
#include <stdio.h> int _main() { printf("hello world.\n"); return 0; } // 上面的代码等效于: char *SG3830[] {"hello, world\n"}; int main() { printf("%s", *SG3830); return 0; } #if 0 /* * i…...

如何微调甜甜圈模型——使用示例
Python 中的 Donut 模型可用于从给定图像中提取文本。这在各种场景中都很有用,例如扫描收据。 您可以轻松地。但与人工智能模型一样,您应该根据您的特定需求微调模型。 我编写本教程是因为我没有找到任何资源来准确展示如何使用我的数据集微调 Donut 模型。因此,我必须从其…...

构建本地AI记忆系统:五大记忆库与心跳回忆机制详解
1. 项目概述:一个让AI助手真正“记住你”的本地记忆系统 如果你用过OpenClaw、Claude Code或者任何AI助手,肯定遇到过这样的场景:昨天刚跟它详细讨论了一个项目方案,今天再问,它要么含糊其辞,要么又得从头解…...

MSP 盈利、留客、提口碑,核心就盯这12个 KPI
很多 MSP(托管服务提供商)都会陷入一个误区,手里握着一堆散落在各个看板的运营数据,却始终搞不清哪些指标能真正帮自己提升服务质量、拉高利润、留住客户。忙忙碌碌做了一堆报表,最终还是凭感觉做决策,业务…...

告别硬件依赖:用Virtual ZPL Printer构建完整的标签打印测试环境
告别硬件依赖:用Virtual ZPL Printer构建完整的标签打印测试环境 【免费下载链接】Virtual-ZPL-Printer An ethernet based virtual Zebra Label Printer that can be used to test applications that produce bar code labels. 项目地址: https://gitcode.com/gh…...

LVGL列表控件实战:5分钟搞定一个带图标和事件响应的菜单界面
LVGL列表控件实战:5分钟打造高交互性嵌入式菜单界面 在嵌入式设备的人机交互设计中,菜单界面是最基础也最关键的组件之一。想象一下,当你需要为智能家居控制面板设计一个简洁明了的操作菜单,或者为工业设备开发一个功能选择界面时…...
让人惊讶的AI)
图解人工智能(11)让人惊讶的AI
人工智能已经融入到我们的生活之中,如便捷的刷脸支付,帮我们扫地的机器人。想一想,你身边还有哪些有趣的人工智能设备?以一种设备为例,搜索它的相关信息,看它为我们的生活带来了哪些便利。开放讨论题&#…...

如何快速搭建AI聊天前端:SillyTavern完整教程与角色扮演系统指南
如何快速搭建AI聊天前端:SillyTavern完整教程与角色扮演系统指南 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern 想象一下,你能够与任何AI角色进行沉浸式对话&#…...

终极免费文档下载指南:如何用kill-doc脚本轻松获取百度文库、豆丁网等30+平台资源
终极免费文档下载指南:如何用kill-doc脚本轻松获取百度文库、豆丁网等30平台资源 【免费下载链接】kill-doc 看到经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档&a…...

HarnessGate:专为AI Agent设计的纯消息网关,实现多平台无缝桥接
1. 项目概述:一个纯粹的AI Agent消息网关如果你正在构建一个需要对接多个聊天平台(比如Telegram、Discord、Slack)的AI助手或客服机器人,你很可能已经踩过这样的坑:市面上主流的机器人框架,比如Botpress、L…...

如何快速恢复加密压缩包密码:ArchivePasswordTestTool完整指南
如何快速恢复加密压缩包密码:ArchivePasswordTestTool完整指南 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 你是否曾经遇到过…...

打破高频、高速四种材料混压
打破高频、高速四种材料混压,铸就PCB行业硬核实力。在航空航天领域,每一次技术的突破都意味着对材料与工艺的极致追求。今天,我们要聊的这款产品,堪称多材料混压天花板,——16层、四种材料混压、三次压合、板厚5.0mm、…...