spring-kafka中ContainerProperties.AckMode详解
近期,我们线上遇到了一个性能问题,几乎快引起线上故障,后来仅仅是修改了一行代码,性能就提升了几十倍。一行代码几十倍,数据听起来很夸张,不过这是真实的数据,线上错误的配置的确有可能导致性能有数量级上的差异,等我说完我们这个性能问题你就清楚了。
我们线上是对接了腾讯云的IOT平台,任何iot设备的上传事件都是通过腾讯云的ckafka传递给我们的,随着设备量以及事件数据量的增加,我们消费腾讯云ckafka出现了性能瓶颈,数据高峰期会有数据拥堵,从而因数据处理延迟导致业务的问题。解决最简单的方案就是扩partition和consumer,实际上半年前我们发生性能问题的时候就是这么做的,扩了一倍的partition提升了一倍的性能,然而半年后的今天又到了瓶颈。
经过排查发现,单条kafka消息处理需要6ms,拆分所有执行逻辑后发现这6ms的延迟主要是向腾讯云发送ack的时间,我们机房到腾讯云的rtt恰好就是6ms左右,所以几乎所有的事件都耗费在消息的网络传输上面了。然而这个是受物理距离所限制,无法减减少的。后来偶然发现我们在代码中使用了spring-kafka的AckMode中的MANUAL_IMMEDIATE,这个模式下kafka的consumer会向服务端手动确认每一条消息,后来我们将这个配置调整成了AckMode.MANUAL,单条消息的处理时长从原来的6ms降低到不到0.2ms,提升了30多倍,这下即便不扩容我们的性能冗余也足够支持很多年了。 为什么简简单单改个配置就会有如此的提升? 是否还有其他的配置类型?
实际上在spring-kafka中并不是只提供了MANUAL和MANUAL_IMMEDIATE两种ack模式,而是有以下七种,每种都有各种的作用和适合的场景。
- RECORD:每处理一条记录后就立即进行确认。
- BATCH:每次调用poll()方法后,只确认返回的最后一条记录。
- TIME:每次过了设定的时间间隔后,确认最后一条在这段时间内处理的记录。
- COUNT:每处理设定数量的记录后,确认最后一条处理的记录。
- COUNT_TIME:组合了TIME和COUNT,即满足任意一个条件时,确认最后一条处理的记录。
- MANUAL:用户需要手动调用acknowledgement.acknowledge()批量来确认消息。
- MANUAL_IMMEDIATE:用户需要手动调用acknowledgement.acknowledge()来确认消息,每条消息都会确认一次。
以上7种模式如果分类的话可以分成2中,手动确认和自动确认,其中MANUAL和MANUAL_IMMEDIATE是手动确认,其余的都是自动确认。手动确认和自动确定的核心区别就在于你是否需要在代码中显示调用Acknowledgment.acknowledge(),我们挨个来看下。
手动确认
MANUAL:
在此模式下,消费者需要在处理完消息后手动调用Acknowledgment.acknowledge()方法来确认消息。确认操作会被批量进行,即确认操作被延迟到一批消息都处理完毕后再发送给Kafka。这种模式的优点是可以提高效率,因为减少了与Kafka服务器的交互次数。但缺点是如果一批消息消费了一半,consumer突然异常宕机,因为数据没有及时向kafka服务端确认,下次就会重复拉取到消息,导致部分数据被重复消费。
MANUAL_IMMEDIATE:
在此模式下,消费者需要在处理完消息后手动调用Acknowledgment.acknowledge()方法来确认消息。不过,与MANUAL模式不同的是,一旦调用了acknowledge()方法,确认信息会立即发送给Kafka,而不是等待一批消息都处理完毕后再发送。这种模式可能会增加与Kafka服务器的交互次数,在网络延迟较大的情况下会出现显著的性能消费瓶颈,但可以尽快将确认信息发送给Kafka,即便是consumer异常宕机,也只是会导致单条消息被重复消费。
手动确认的优势在于consumer可以在代码逻辑中自行判断数据是否消费成功,未消费成功的数据不确认,这样可以保证数据不丢失,手动模式可以保证数据的完整性,也就是分布式数据系统中所说的at least once。而这两种模式的核心差异就是单条确认和批量确认,批量的方式可以显著提升性能, 我在上个月的博客IO密集型服务提升性能的三种方法详细介绍过,有兴趣可以看下。
自动确认
RECORD、BATCH、TIME、COUNT、TIME_COUNT这5种都是属于自动确认,也就是你不需要在代码中显式调用Acknowledgment.acknowledge(),只要consumer拉到消息就是自动确认,才不管是否真的消费成功,所以自动确认的模式可能会导致数据丢失,但要注意相对于手动确认,自动确认即可能导致数据丢失,也可能导致数据重复,所以它也不是at most once语义级别的。 虽然同为自动确认,但其实这5种模式还有自己的差异。
RECORD和BATCH
首先我们先来看下RECORD、BATCH,这两种模式其实就是上文中MANUAL和MANUAL_IMMEDIATE对应的自动版本。RECORD是一条就确认一次,同样如果是在网络延迟较大的情况下也会出现性能问题。BATCH是批量确认,每次poll()后会确认这一批的消息,同样的如果consumer异常宕机也会导致未成功确认消息,从而导致消息被重复拉取到。当然如果是consumer因其他原因导致数据处理失败,但正常确认了,这种情况下会丢失消息。
TIME
TIME模式是定时确认,比如你设置了确认时间间隔为5S,consumer就会每5s向kafka确认这5s内消费完的消息,这里有个问题是如果是高频数据流且时间间隔设置较大,可能导致堆积大量消息未被确认,然后异常宕机后重复拉取到这些消息,我们接下来要说的COUNT模式可以避免这种情况。
COUNT
COUNT模式确认的时机是由消费数据条数触发的,比如每消费100条就确认一次,完美的避免了堆积大量未确认数据的情况。但是,如果是极低频的数据流,比如几分钟才一条数据,攒够100条得好几个小时,数据消费后长时间得不到确认,甚至可能导致kafka认为数据消费超时失败,从而导致数据被重复消费。
TIME_COUNT
针对于TIME和COUNT的优缺点,TIME_COUNT结合了两者的特点,只要是时间间隔或者消息条数满足其一就确认,具有更强的适应性,所以当你想从TIME、COUT、TIME_COUNT三者中选一个的话,我个人觉得可以盲选TIME_COUNT,除非你特别清楚你数据的特征,知道那种更合适。
总结
简单总结下以上几种模式,如果是不能容忍数据丢失那一定要选手动模式,如果是网络延时比较高,可以选MANUAL(批处理)的模式,但是注意即便是手动模式它也不能保证数据不重复,要想做到完全幂等还得依赖其他的方式,比如数据库事务。 如果可以接受部分数据丢失(例:监控数据),那就可以考虑自动模式了,但我个人还是不推荐RECORD模式,因为这种模式会在高网络延迟的情况下啊产生比较严重的性能问题,剩下的几种模式可以根据自己的数据量、网络情况选取,不同的情况用不同的模式可能会有明显的性能差异。
相关文章:

spring-kafka中ContainerProperties.AckMode详解
近期,我们线上遇到了一个性能问题,几乎快引起线上故障,后来仅仅是修改了一行代码,性能就提升了几十倍。一行代码几十倍,数据听起来很夸张,不过这是真实的数据,线上错误的配置的确有可能导致性能…...
)
【rpc】Dubbo和Zookeeper结合使用,它们的作用与联系(通俗易懂,一文理解)
目录 Dubbo是什么? 把系统模块变成分布式,有哪些好处,本来能在一台机子上运行,为什么还要远程调用 Zookeeper是什么? 它们进行配合使用时,之间的关系 服务注册 服务发现 动态地址管理 Dubbo是…...

ChatGPT的未来
随着人工智能的快速发展,ChatGPT作为一种自然语言生成模型,在各个领域都展现出了巨大的潜力。它不仅可以用于日常对话、创意助手和知识查询,还可以应用于教育、医疗、商业等各个领域,为人们带来更多便利和创新。 在教育领域&#…...

Pytorch模型转ONNX部署
开始以为会很困难,但是其实非常方便,下边分两步走:1. pytorch模型转onnx;2. 使用onnx进行inference 0. 准备工作 0.1 安装onnx 安装onnx和onnxruntime,onnx貌似是个环境。。倒是没有直接使用,onnxruntim…...

k8s优雅停服
在应用程序的整个生命周期中,正在运行的 pod 会由于多种原因而终止。在某些情况下,Kubernetes 会因用户输入(例如更新或删除 Deployment 时)而终止 pod。在其他情况下,Kubernetes 需要释放给定节点上的资源时会终止 po…...

面试题五:computed的使用
题记 大部分的工作中使用computed的频次很低的,所以今天拿出来一文对于computed进行详细的介绍,因为Vue的灵魂之一就是computed。 模板内的表达式非常便利,但是设计它们的初衷是用于简单运算的。在模板中放入太多的逻辑会让模板过重且难以维护…...
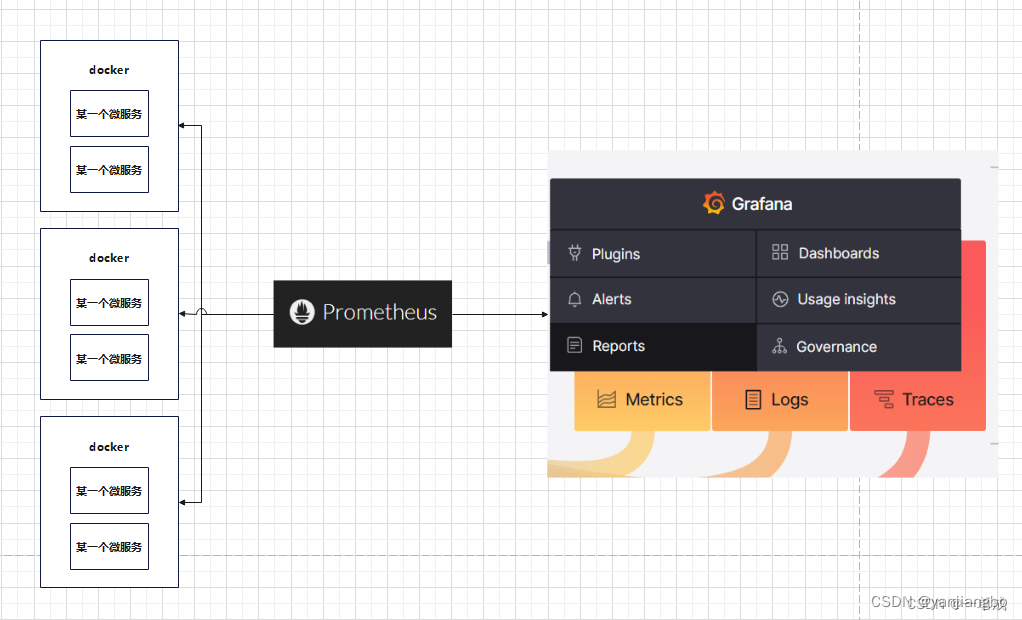
完美的分布式监控系统 Prometheus与优雅的开源可视化平台 Grafana
1、之间的关系 prometheus与grafana之间是相辅相成的关系。简而言之Grafana作为可视化的平台,平台的数据从Prometheus中取到来进行仪表盘的展示。而Prometheus这源源不断的给Grafana提供数据的支持。 Prometheus是一个开源的系统监控和报警系统,能够监…...
黑马JVM总结(九)
(1)StringTable_调优1 我们知道StringTable底层是一个哈希表,哈希表的性能是跟它的大小相关的,如果哈希表这个桶的个数比较多,元素相对分散,哈希碰撞的几率就会减少,查找的速度较快,…...

如何使用 RunwayML 进行创意 AI 创作
标题:如何使用 RunwayML 进行创意 AI 创作 介绍 RunwayML 是一个基于浏览器的人工智能创作工具,可让用户使用各种 AI 功能来生成图像、视频、音乐、文字和其他创意内容。RunwayML 的功能包括: * 图像生成:使用生成式对抗网络 (…...

【css】能被4整除 css :class,判断一个数能否被另外一个数整除,余数
判断一个数能否被另外一个数整除 一个数能被4整除的表达式可以表示为:num%40,其中,num为待判断的数,% 为取模运算符,为等于运算符。这个表达式的意思是,如果num除以4的余数为0,则返回true&…...

ChatGPT与日本首相交流核废水事件-精准Prompt...
了解更多请点击:ChatGPT与日本首相交流核废水事件-精准Prompt...https://mp.weixin.qq.com/s?__bizMzg2NDY3NjY5NA&mid2247490070&idx1&snebdc608acd419bb3e71ca46acee04890&chksmce64e42ff9136d39743d16059e2c9509cc799a7b15e8f4d4f71caa25968554…...
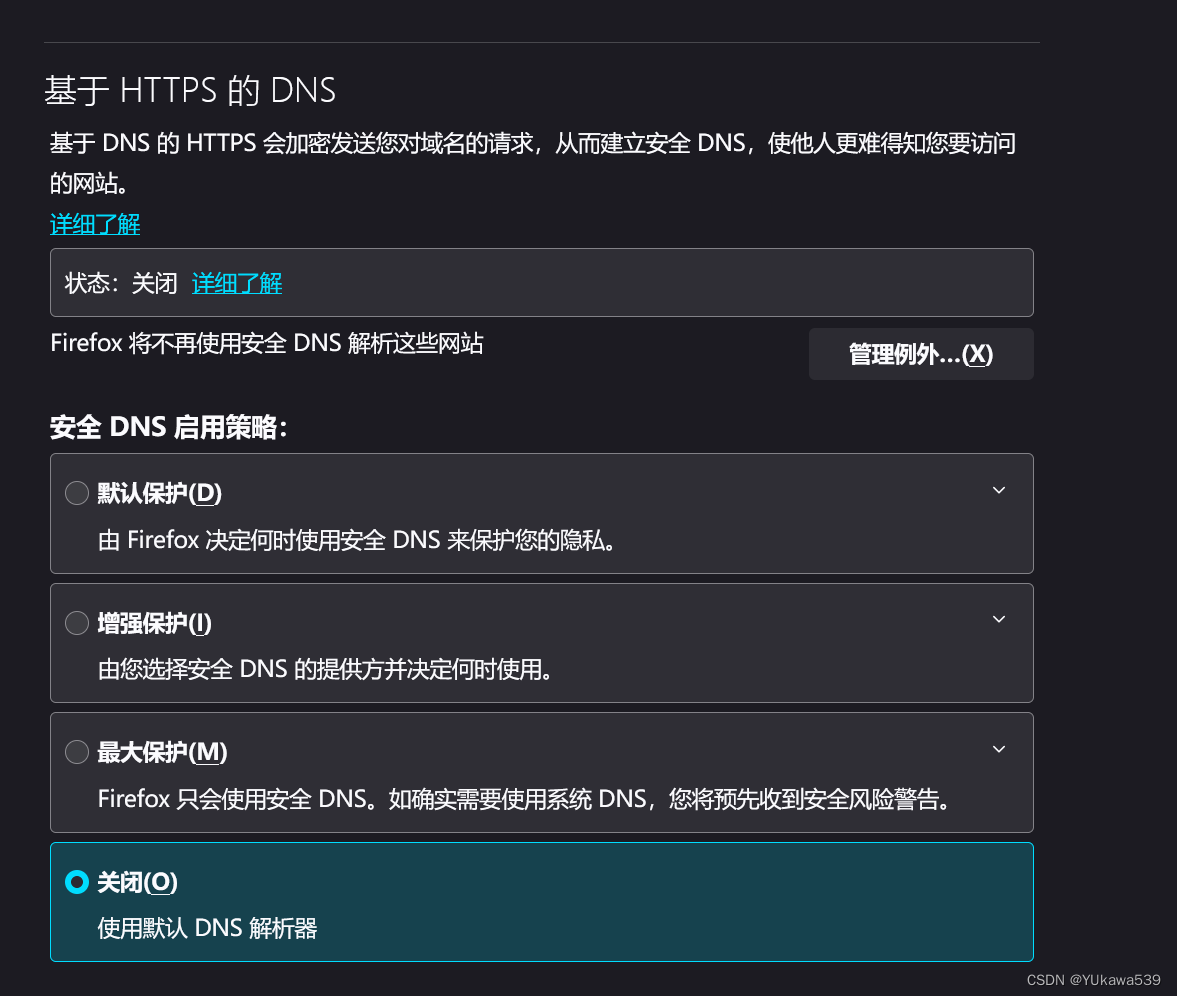
关于 firefox 不能访问 http 的解决
情景: 我在虚拟机 192.168.x.111 上配置了 DNS 服务器,在 kali 上设置 192.168.x.111 为 DNS 服务器后,使用 firefox 地址栏搜索域名 www.xxx.com ,访问在 192.168.x.111 搭建的网站,本来经 192.168.x.111 DNS 服务器解…...
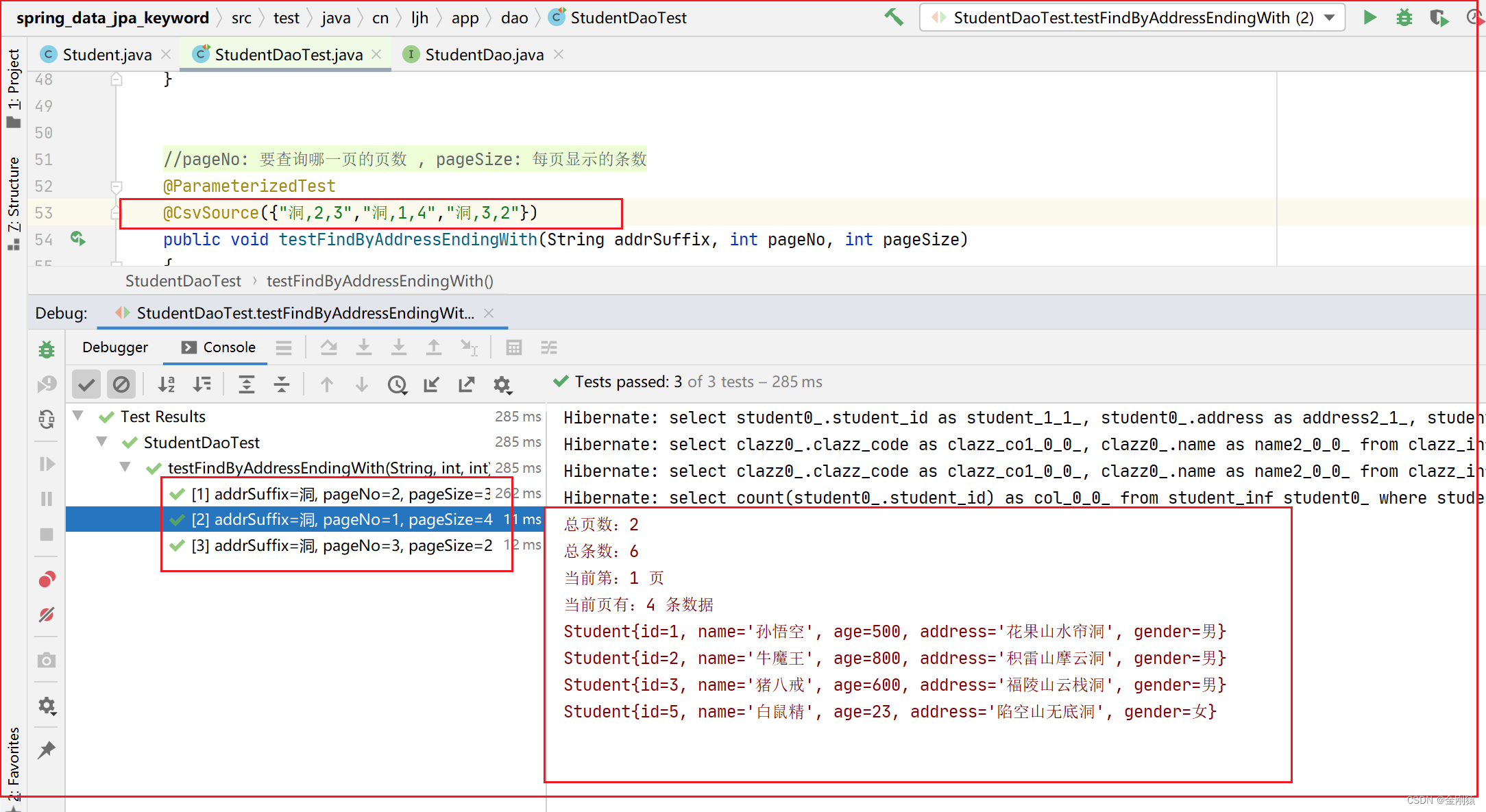
68、Spring Data JPA 的 方法名关键字查询
★ 方法名关键字查询(全自动) (1)继承 CrudRepository 接口 的 DAO 组件可按特定规则来定义查询方法,只要这些查询方法的 方法名 遵守特定的规则,Spring Data 将会自动为这些方法生成 查询语句、提供 方法…...
Brother CNC联网数采集和远程控制
兄弟CNC IP地址设定参考:https://www.sohu.com/a/544461221_121353733没有能力写代码的兄弟可以提前下载好网络调试助手NetAssist,这样就不用写代码来测试连接CNC了。 以上是网络调试助手抓取CNC的产出命令,结果有多个行string需要自行解析&…...
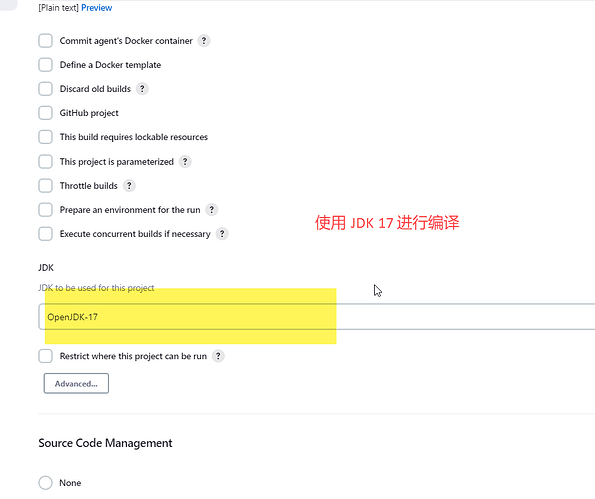
Jenkins 编译 Maven 项目提示错误 version 17
在最近使用集成工具的时候,对项目进行编译提示下面的错误信息: maven-compiler-plugin:3.11.0:compile (default-compile) on project mq-service: Fatal error compiling: error: release version 17 not supported 问题和解决 上面提示的错误信息原…...
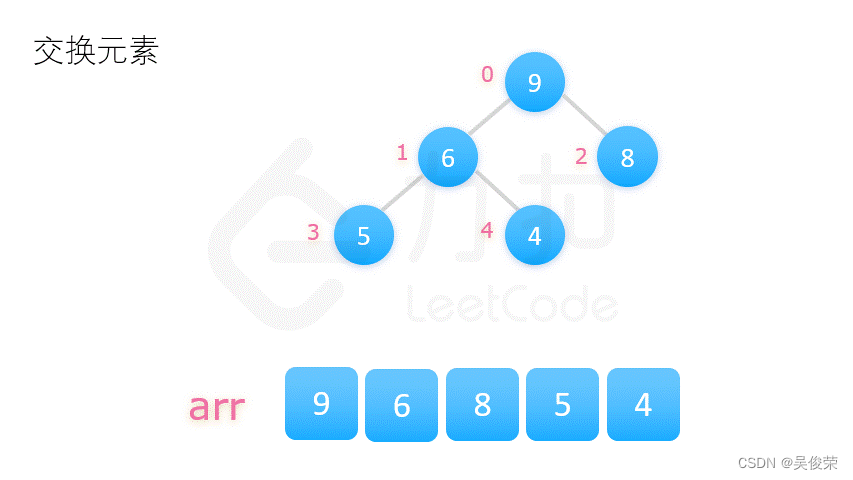
数据结构——排序算法——堆排序
堆排序过程如下: 1.用数列构建出一个大顶堆,取出堆顶的数字; 2.调整剩余的数字,构建出新的大顶堆,再次取出堆顶的数字; 3.循环往复,完成整个排序。 构建大顶堆有两种方式: 1.从 0 开…...

【Spring事务底层实现原理】
Transactional注解 Spring使用了TransactionInterceptor拦截器,该拦截器主要负责事务的管理,包括开启、提交、回滚等操作。当在方法上添加Transactional注解时,Spring会在AOP框架中对该方法进行拦截,TransactionInterceptor会在该…...

docker快速安装redis,mysql,minio,nacos等常用软件【持续更新】
redis ①拉取镜像 docker pull redis② 创建容器 docker run -d --name redis --restartalways -p 6379:6379 redis --requirepass "PASSWORD"–requirepass “输入你的redis密码” nacos ①:docker拉取镜像 docker pull nacos/nacos-server:1.2.0②…...
SCRUM产品负责人(CSPO)认证培训课程
课程简介 Scrum是目前运用最为广泛的敏捷开发方法,是一个轻量级的项目管理和产品研发管理框架。产品负责人是Scrum的三个角色之一,产品负责人在Scrum产品开发当中扮演舵手的角色,他决定产品的愿景、路线图以及投资回报,他需要回答…...
python连接mysql数据库的练习
一、导入pandas内置的sqlite3模块,连接的信息:ip地址是本机, 端口号port 是3306, 用户user是root, 密码password是123456, 数据库database是lambda-xiaozhang import pymysql# 打开数据库连接,参数1:主机名或IP;参数…...

Notero终极指南:打通Zotero与Notion的学术工作流桥梁
Notero终极指南:打通Zotero与Notion的学术工作流桥梁 【免费下载链接】notero A Zotero plugin for syncing items and notes into Notion 项目地址: https://gitcode.com/gh_mirrors/no/notero 当你在Zotero中积累了数百篇文献,却发现整理和引用它…...

3分钟掌握Windows任务栏投资助手:打造你的桌面股票监控中心
3分钟掌握Windows任务栏投资助手:打造你的桌面股票监控中心 【免费下载链接】TrafficMonitorPlugins 用于TrafficMonitor的插件 项目地址: https://gitcode.com/gh_mirrors/tr/TrafficMonitorPlugins 想在Windows任务栏上实时监控股票行情,又不想…...

阵列天线方向图综合算法与应用【附代码】
✨ 长期致力于方向图综合算法、交替投影迭代、交替方向乘子法、子阵方向图综合、相控阵系统、软件设计研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)…...

终极实时窗口分辨率调整工具SRWE:打破屏幕限制的完整指南
终极实时窗口分辨率调整工具SRWE:打破屏幕限制的完整指南 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE 你是否曾为游戏截图分辨率太低而烦恼?是否需要在不同设备上测试UI布局却要反复重…...

微信自动化终极指南:5个强大功能助你高效管理微信数据
微信自动化终极指南:5个强大功能助你高效管理微信数据 【免费下载链接】wechat-toolbox WeChat toolbox(微信工具箱) 项目地址: https://gitcode.com/gh_mirrors/we/wechat-toolbox 还在为繁琐的微信数据管理而烦恼吗?微信…...

GTX 1660实战AI视频生成:低显存环境下的模型瘦身与帧插值方案
1. 项目概述:在入门级显卡上跑通AI视频生成最近看到不少朋友对AI视频生成很感兴趣,但总被“需要RTX 4090”、“至少24GB显存”这类硬件门槛劝退。作为一个常年混迹于“丐版”硬件圈的老玩家,我决定用我手头这块服役多年的GTX 1660(…...

Next.js功能开关实践:用happykit/flags实现灰度发布与A/B测试
1. 项目概述:为什么我们需要一个功能开关系统?在软件开发,尤其是现代Web应用和微服务架构的迭代过程中,我们经常面临一个经典困境:新功能开发完成后,是直接全量发布给所有用户,还是先小范围灰度…...

时间序列自监督学习实战:VIbCReg框架迁移与性能优化
1. 项目概述:当计算机视觉的自监督学习遇上时间序列在机器学习领域,获取高质量、大规模的标注数据一直是个老大难问题,尤其是在时间序列分析这个方向。无论是工业设备的振动监测、医疗心电信号分析,还是金融市场的波动预测&#x…...
)
保姆级教程:手把手教你用Keil 5为APM32F030C6搭建第一个工程(附固件库下载与常见编译错误解决)
从零到一:APM32F030C6在Keil 5上的工程搭建实战指南 第一次接触极海APM32系列芯片的开发者,往往会被陌生的开发环境和复杂的固件库结构弄得手足无措。不同于常见的STM32生态,APM32虽然硬件兼容但软件配置上存在不少差异点。本文将带你用Keil …...
 深度诊断与流量整形方案)
lsyncd rsyncssh同步中断:Broken pipe (32) 深度诊断与流量整形方案
1. 问题现象与初步诊断 最近在帮客户部署lsyncdrsyncssh方案时,遇到了一个典型问题:同步25GB目录时,总是在传输4GB左右中断。日志里反复出现"Broken pipe (32)"错误,就像下面这样: packet_write_wait: Conne…...