卷积神经网络实现咖啡豆分类 - P7
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
- 🚀 文章来源:K同学的学习圈子
目录
- 环境
- 步骤
- 环境设置
- 包引用
- 全局设备对象
- 数据准备
- 查看图像的信息
- 制作数据集
- 模型设计
- 手动搭建的vgg16网络
- 精简后的咖啡豆识别网络
- 模型训练
- 编写训练函数
- 编写测试函数
- 开始训练
- 展示训练过程
- 模型效果展示
- 总结与心得体会
环境
- 系统: Linux
- 语言: Python3.8.10
- 深度学习框架: Pytorch2.0.0+cu118
- 显卡:A5000 24G
步骤
环境设置
包引用
import torch
import torch.nn as nn # 网络
import torch.optim as optim # 优化器
from torch.utils.data import DataLoader, random_split # 数据集划分
from torchvision import datasets, transforms # 数据集加载,转换import pathlib, random, copy # 文件夹遍历,实现模型深拷贝
from PIL import Image # python自带的图像类
import matplotlib.pyplot as plt # 图表
import numpy as np
from torchinfo import summary # 打印模型参数
全局设备对象
方便将模型和数据统一拷贝到目标设备中
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
数据准备
查看图像的信息
data_path = 'coffee_data'
data_lib = pathlib.Path(data_path)
coffee_images = list(data_lib.glob('*/*'))# 打印5张图像的信息
for _ in range(5):image = random.choice(coffee_images)print(np.array(Image.open(str(image))).shape)
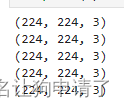
通过打印的信息,可以看出图像的尺寸都是224x224的,这是一个CV经常使用的图像大小,所以后面我就不使用Resize来缩放图像了。
# 打印20张图像粗略的看一下
plt.figure(figsize=(20, 4))
for i in range(20):plt.subplot(2, 10, i+1)plt.axis('off')image = random.choice(coffee_images) # 随机选出一个图像plt.title(image.parts[-2]) # 通过glob对象取出它的文件夹名称,也就是分类名plt.imshow(Image.open(str(image))) # 展示

通过展示,对数据集内的图像有个大概的了解
制作数据集
先编写数据的预处理过程,用来使用pytorch的api加载文件夹中的图像
transform = transforms.Compose([transforms.ToTensor(), # 先把图像转成张量transforms.Normalize( # 对像素值做归一化,将数据范围弄到-1,1mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225],),
])
加载文件夹
dataset = datasets.ImageFolder(data_path, transform=transform)
从数据中取所有的分类名
class_names = [k for k in dataset.class_to_idx]
print(class_names)
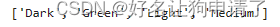
将数据集划分出训练集和验证集
train_size = int(len(dataset) * 0.8)
test_size = len(dataset) - train_sizetrain_dataset, test_dataset = random_split(dataset, [train_size, test_size])
将数据集按划分成批次,以便使用小批量梯度下降
batch_size = 32
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_loader = DataLoader(test_dataset, batch_size=batch_size)
模型设计
在一开始时,直接手动创建了Vgg-16网络,发现少数几个迭代后模型就收敛了,于是开始精简模型。
手动搭建的vgg16网络
class Vgg16(nn.Module):def __init__(self, num_classes):super().__init__()self.block1 = nn.Sequential(nn.Conv2d(3, 64, 3, padding=1),nn.BatchNorm2d(64),nn.ReLU(),nn.Conv2d(64, 64, 3, padding=1),nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(2),)self.block2 = nn.Sequential(nn.Conv2d(64, 128, 3, padding=1),nn.BatchNorm2d(128),nn.ReLU(),nn.Conv2d(128, 128, 3, padding=1),nn.BatchNorm2d(128),nn.ReLU(),nn.MaxPool2d(2),)self.block3 = nn.Sequential(nn.Conv2d(128, 256, 3, padding=1),nn.BatchNorm2d(256),nn.ReLU(),nn.Conv2d(256, 256, 3, padding=1),nn.BatchNorm2d(256),nn.ReLU(),nn.Conv2d(256, 256, 3, padding=1),nn.BatchNorm2d(256),nn.ReLU(),nn.MaxPool2d(2),)self.block4 = nn.Sequential(nn.Conv2d(256, 512, 3, padding=1),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(512, 512, 3, padding=1),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(512, 512, 3, padding=1),nn.BatchNorm2d(512),nn.ReLU(),nn.MaxPool2d(2),)self.block5 = nn.Sequential(nn.Conv2d(512, 512, 3, padding=1),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(512, 512, 3, padding=1),nn.BatchNorm2d(512),nn.ReLU(),nn.Conv2d(512, 512, 3, padding=1),nn.BatchNorm2d(512),nn.ReLU(),nn.MaxPool2d(2),)self.pool = nn.AdaptiveAvgPool2d(7)self.classifier = nn.Sequential(nn.Linear(7*7*512, 4096),nn.Dropout(0.5),nn.ReLU(),nn.Linear(4096, 4096),nn.Dropout(0.5),nn.ReLU(),nn.Linear(4096, num_classes),)def forward(self, x):x = self.block1(x)x = self.block2(x)x = self.block3(x)x = self.block4(x)x = self.block5(x)x = self.pool(x)x = x.view(x.size(0),-1)x = self.classifier(x)return x
vgg = Vgg16(len(class_names)).to(device)
summary(vgg, input_size=(32, 3, 224, 224))
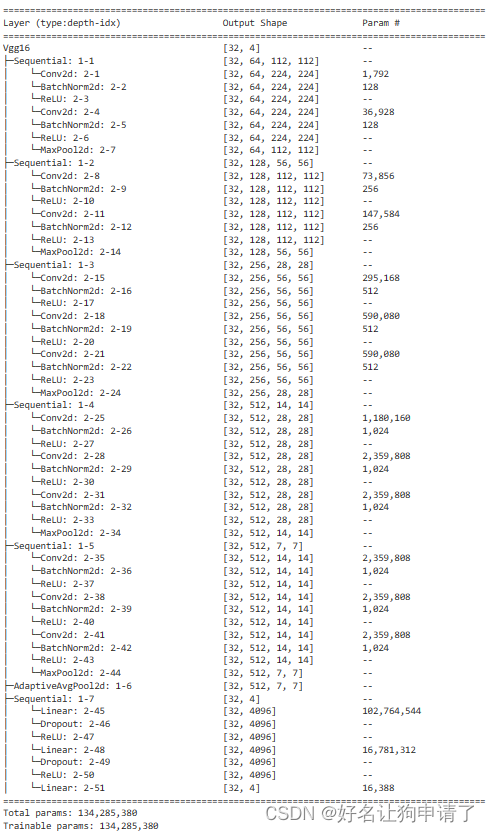
通过模型结构的打印可以发现,VGG-16网络共有134285380个可训练参数(我加了BatchNorm,和官方的比会稍微多出一些),参数量非常巨大,对于咖啡豆识别这种小场景,这么多可训练参数肯定浪费,于是对原始的VGG-16网络结构进行精简。
精简后的咖啡豆识别网络
class Network(nn.Module):def __init__(self, num_classes):super().__init__()self.block1 = nn.Sequential(nn.Conv2d(3, 64, 3, padding=1),nn.BatchNorm2d(64),nn.ReLU(),nn.Conv2d(64, 64, 3, padding=1),nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(2),)self.block2 = nn.Sequential(nn.Conv2d(64, 128, 3, padding=1),nn.BatchNorm2d(128),nn.ReLU(),nn.Conv2d(128, 128, 3, padding=1),nn.BatchNorm2d(128),nn.ReLU(),nn.MaxPool2d(2),)self.block3 = nn.Sequential(nn.Conv2d(128, 64, 3, padding=1),nn.BatchNorm2d(64),nn.ReLU(),nn.Conv2d(64, 64, 3, padding=1),nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(2),)self.pool = nn.AdaptiveAvgPool2d(7),self.classifier = nn.Sequential(nn.Linear(7*7*64, 64),nn.Dropout(0.4),nn.ReLU(),nn.Linear(64, num_classes))def forward(self, x):x = self.block1(x)x = self.block2(x)x = self.block3(x)x = self.pool(x)x = x.view(x.size(0), -1)x = self.classifier(x)return x
model = Network(len(class_names)).to(device)
summary(model, input_size=(32, 3, 224, 224))
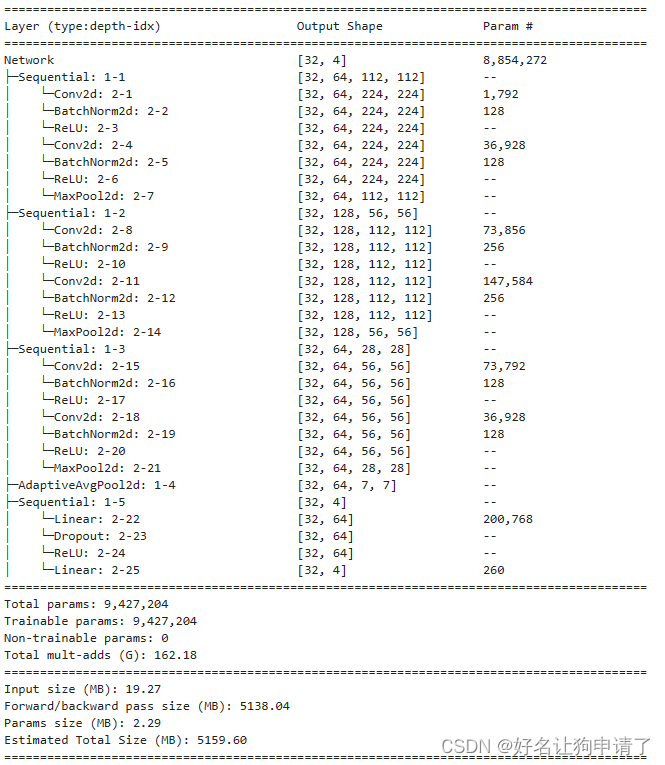
可以看到精简后的网络模型参数量还不到原来的1/10,但是其在测试集上的正确率依然能够达到100%!
模型训练
编写训练函数
def train(train_loader, model, loss_fn, optimizer):size = len(train_loader.dataset)num_batches = len(train_loader)train_loss, train_acc = 0, 0for x, y in train_loader:x, y = x.to(device), y.to(device)pred = model(x)loss = loss_fn(pred, y)optimizer.zero_grad()loss.backward()optimizer.step()train_loss += loss.item()train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss /= num_batchestrain_acc /= sizereturn train_loss, train_acc
编写测试函数
def test(test_loader, model, loss_fn):size = len(test_loader.dataset)num_batches = len(test_loader)test_loss, test_acc = 0, 0for x, y in test_loader:x, y = x.to(device), y.to(device)pred = model(x)loss = loss_fn(pred, y)test_loss += loss.item()test_acc += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss /= num_batchestest_acc /= sizereturn test_loss, test_acc
开始训练
首先定义损失函数,优化器设置学习率,这里我们再弄一个学习率的衰减,再加上总的迭代次数,最佳模型的保存位置
epochs = 30
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
scheduler = optim.lr_scheduler.LambdaLR(optimizer=optimizer, lr_lambda=lambda epoch: 0.92**(epoch//2))
best_model_path = 'best_coffee_model.pth'
然后编写训练+测试的循环,并记录训练过程的数据
best_acc = 0
train_loss, train_acc = [], []
test_loss, test_acc = [], []
for epoch in epochs:model.train()epoch_train_loss, epoch_train_acc = train(train_loader, model, loss_fn, optimizer)scheduler.step()model.eval()with torch.no_grad();epoch_test_loss, epoch_test_acc = test(test_loader, model, loss_fn)train_loss.append(epoch_train_loss)train_acc.append(epoch_train_acc)test_loss.append(epoch_test_loss)test_acc.append(epoch_test_acc)lr = optimizer.state_dict()['param_groups'][0]['lr']if best_acc < epoch_test_acc:best_acc = epoch_test_accbest_model = copy.deepcopy(model)print(f"Epoch: {epoch+1}, Lr:{lr}, TrainAcc: {epoch_train_acc*100:.1f}, TrainLoss: {epoch_train_loss:.3f}, TestAcc: {epoch_test_acc*100:.1f}, TestLoss: {epoch_test_loss:.3f}")print(f"Saving Best Model with Accuracy: {best_acc*100:.1f} to {best_model_path}")
torch.save(best_model.state_dict(), best_model_path)
print('Done')
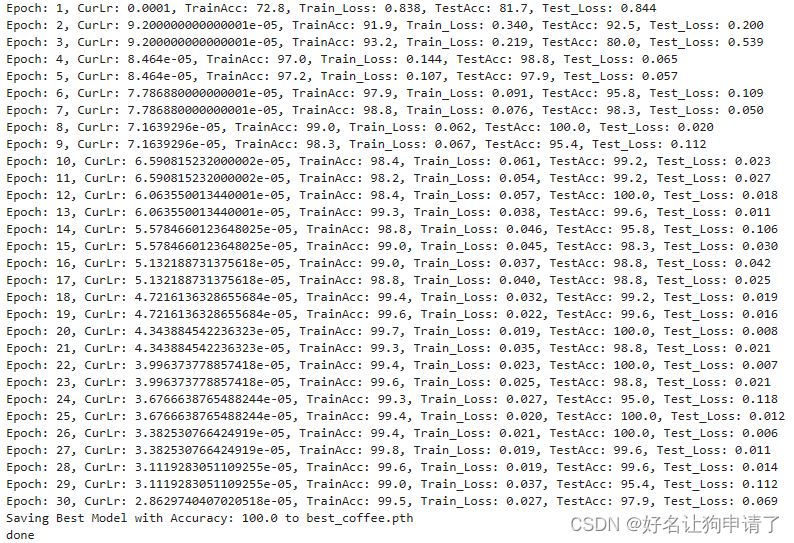
可以看出,模型在测试集上的正确率最高达到了100%
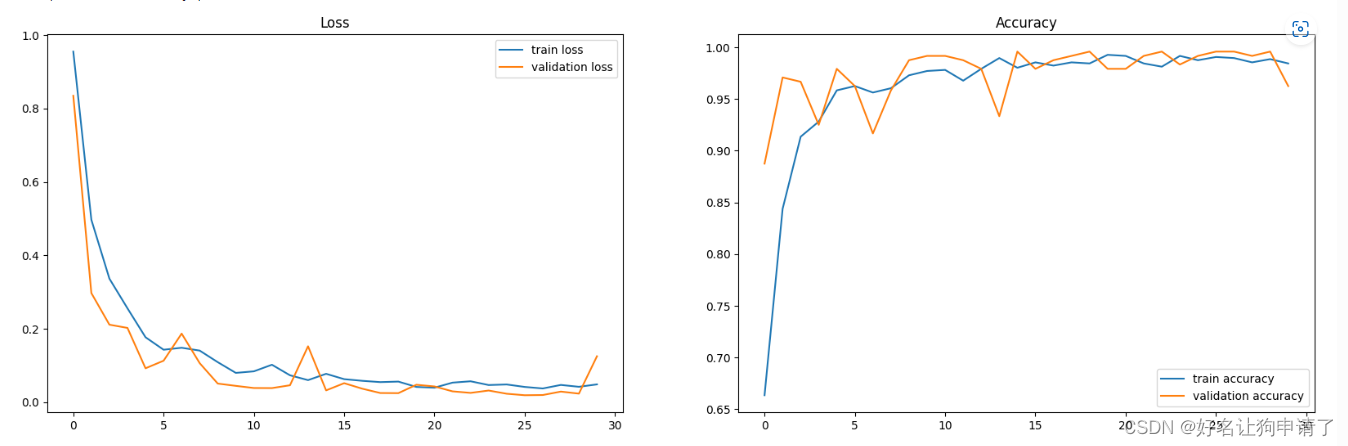
展示训练过程
epoch_ranges = range(epochs)
plt.figure(figsize=(20,6))
plt.subplot(121)
plt.plot(epoch_ranges, train_loss, label='train loss')
plt.plot(epoch_ranges, test_loss, label='validation loss')
plt.legend(loc='upper right')
plt.title('Loss')plt.figure(figsize=(20,6))
plt.subplot(122)
plt.plot(epoch_ranges, train_acc, label='train accuracy')
plt.plot(epoch_ranges, test_acc, label='validation accuracy')
plt.legend(loc='lower right')
plt.title('Accuracy')
模型效果展示
model.load_state_dict(torch.load(best_model_path))
model.to(device)
model.eval()plt.figure(figsize=(20,4))
for i in range(20):plt.subplot(2, 10, i+1)plt.axis('off')image = random.choice(coffee_images)input = transform(Image.open(str(image))).to(device).unsqueeze(0)pred = model(input)plt.title(f'T:{image.parts[-2]}, P:{class_names[pred.argmax()]}')plt.imshow(Image.open(str(image)))

通过结果可以看出,确实是所有的咖啡豆都正确的识别了。
总结与心得体会
- 因为目前网络还是很快就收敛到一个很高的水平,所以应该还有很大的精简的空间,但是可能会稍微牺牲一些正确率。
- 模型的选取要根据实际任务来确定,像咖啡豆种类识别这种任务,使用VGG-16太浪费了。
- 在精简的过程中,没有感觉到训练速度有明显的变化 ,说明参数量和训练速度并没有直接的相关关系。
- 连续多层参数一样的卷积操作好像比只用一层效果要好。
相关文章:
卷积神经网络实现咖啡豆分类 - P7
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 | 接辅导、项目定制🚀 文章来源:K同学的学习圈子 目录 环境步骤环境设置包引用全局设备对象 数据准备查看图像的信息制作数据集 模型设…...

C++之默认与自定义构造函数问题(二百一十七)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 人生格言: 人生…...
Docker从认识到实践再到底层原理(五)|Docker镜像
前言 那么这里博主先安利一些干货满满的专栏了! 首先是博主的高质量博客的汇总,这个专栏里面的博客,都是博主最最用心写的一部分,干货满满,希望对大家有帮助。 高质量博客汇总 然后就是博主最近最花时间的一个专栏…...

【Flowable】任务监听器(五)
前言 之前有需要使用到Flowable,鉴于网上的资料不是很多也不是很全也是捣鼓了半天,因此争取能在这里简单分享一下经验,帮助有需要的朋友,也非常欢迎大家指出不足的地方。 一、监听器 在Flowable中,我们可以使用监听…...

spring-kafka中ContainerProperties.AckMode详解
近期,我们线上遇到了一个性能问题,几乎快引起线上故障,后来仅仅是修改了一行代码,性能就提升了几十倍。一行代码几十倍,数据听起来很夸张,不过这是真实的数据,线上错误的配置的确有可能导致性能…...
)
【rpc】Dubbo和Zookeeper结合使用,它们的作用与联系(通俗易懂,一文理解)
目录 Dubbo是什么? 把系统模块变成分布式,有哪些好处,本来能在一台机子上运行,为什么还要远程调用 Zookeeper是什么? 它们进行配合使用时,之间的关系 服务注册 服务发现 动态地址管理 Dubbo是…...

ChatGPT的未来
随着人工智能的快速发展,ChatGPT作为一种自然语言生成模型,在各个领域都展现出了巨大的潜力。它不仅可以用于日常对话、创意助手和知识查询,还可以应用于教育、医疗、商业等各个领域,为人们带来更多便利和创新。 在教育领域&#…...

Pytorch模型转ONNX部署
开始以为会很困难,但是其实非常方便,下边分两步走:1. pytorch模型转onnx;2. 使用onnx进行inference 0. 准备工作 0.1 安装onnx 安装onnx和onnxruntime,onnx貌似是个环境。。倒是没有直接使用,onnxruntim…...

k8s优雅停服
在应用程序的整个生命周期中,正在运行的 pod 会由于多种原因而终止。在某些情况下,Kubernetes 会因用户输入(例如更新或删除 Deployment 时)而终止 pod。在其他情况下,Kubernetes 需要释放给定节点上的资源时会终止 po…...

面试题五:computed的使用
题记 大部分的工作中使用computed的频次很低的,所以今天拿出来一文对于computed进行详细的介绍,因为Vue的灵魂之一就是computed。 模板内的表达式非常便利,但是设计它们的初衷是用于简单运算的。在模板中放入太多的逻辑会让模板过重且难以维护…...
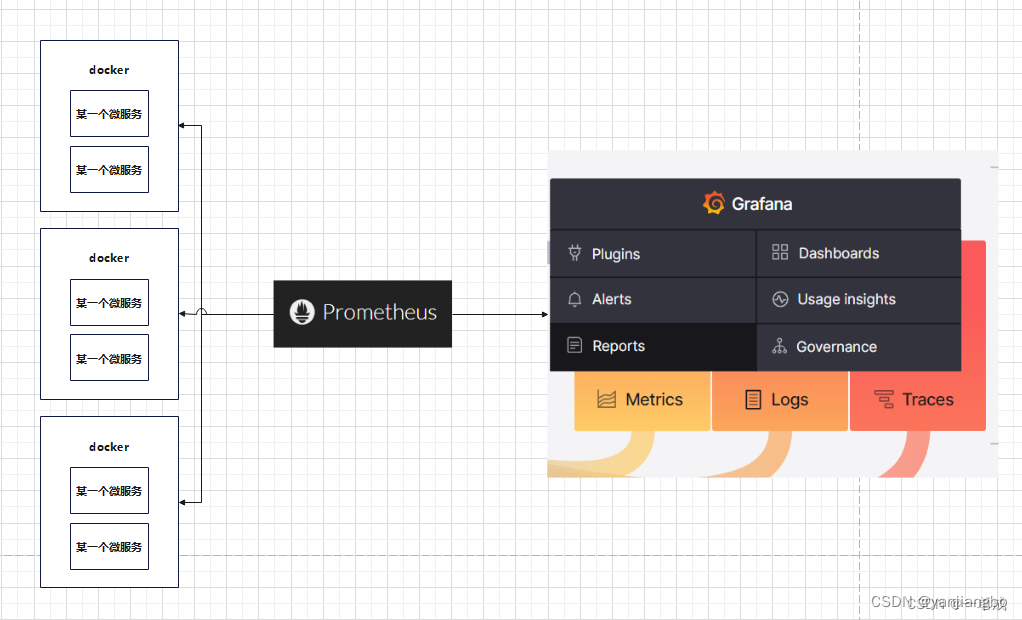
完美的分布式监控系统 Prometheus与优雅的开源可视化平台 Grafana
1、之间的关系 prometheus与grafana之间是相辅相成的关系。简而言之Grafana作为可视化的平台,平台的数据从Prometheus中取到来进行仪表盘的展示。而Prometheus这源源不断的给Grafana提供数据的支持。 Prometheus是一个开源的系统监控和报警系统,能够监…...
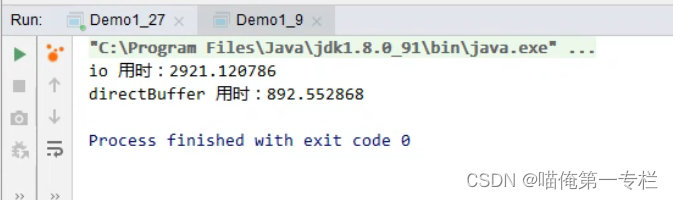
黑马JVM总结(九)
(1)StringTable_调优1 我们知道StringTable底层是一个哈希表,哈希表的性能是跟它的大小相关的,如果哈希表这个桶的个数比较多,元素相对分散,哈希碰撞的几率就会减少,查找的速度较快,…...

如何使用 RunwayML 进行创意 AI 创作
标题:如何使用 RunwayML 进行创意 AI 创作 介绍 RunwayML 是一个基于浏览器的人工智能创作工具,可让用户使用各种 AI 功能来生成图像、视频、音乐、文字和其他创意内容。RunwayML 的功能包括: * 图像生成:使用生成式对抗网络 (…...

【css】能被4整除 css :class,判断一个数能否被另外一个数整除,余数
判断一个数能否被另外一个数整除 一个数能被4整除的表达式可以表示为:num%40,其中,num为待判断的数,% 为取模运算符,为等于运算符。这个表达式的意思是,如果num除以4的余数为0,则返回true&…...

ChatGPT与日本首相交流核废水事件-精准Prompt...
了解更多请点击:ChatGPT与日本首相交流核废水事件-精准Prompt...https://mp.weixin.qq.com/s?__bizMzg2NDY3NjY5NA&mid2247490070&idx1&snebdc608acd419bb3e71ca46acee04890&chksmce64e42ff9136d39743d16059e2c9509cc799a7b15e8f4d4f71caa25968554…...
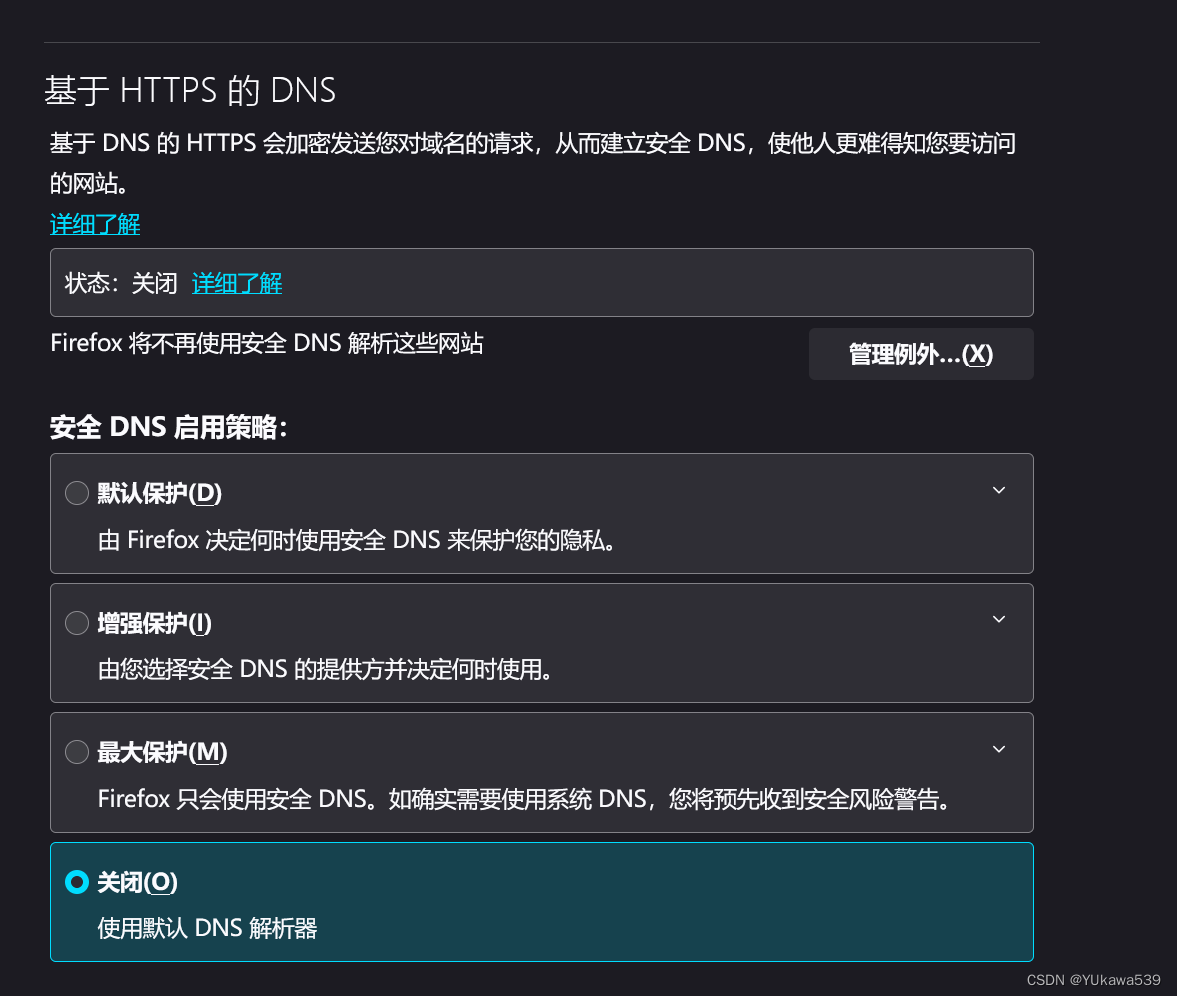
关于 firefox 不能访问 http 的解决
情景: 我在虚拟机 192.168.x.111 上配置了 DNS 服务器,在 kali 上设置 192.168.x.111 为 DNS 服务器后,使用 firefox 地址栏搜索域名 www.xxx.com ,访问在 192.168.x.111 搭建的网站,本来经 192.168.x.111 DNS 服务器解…...
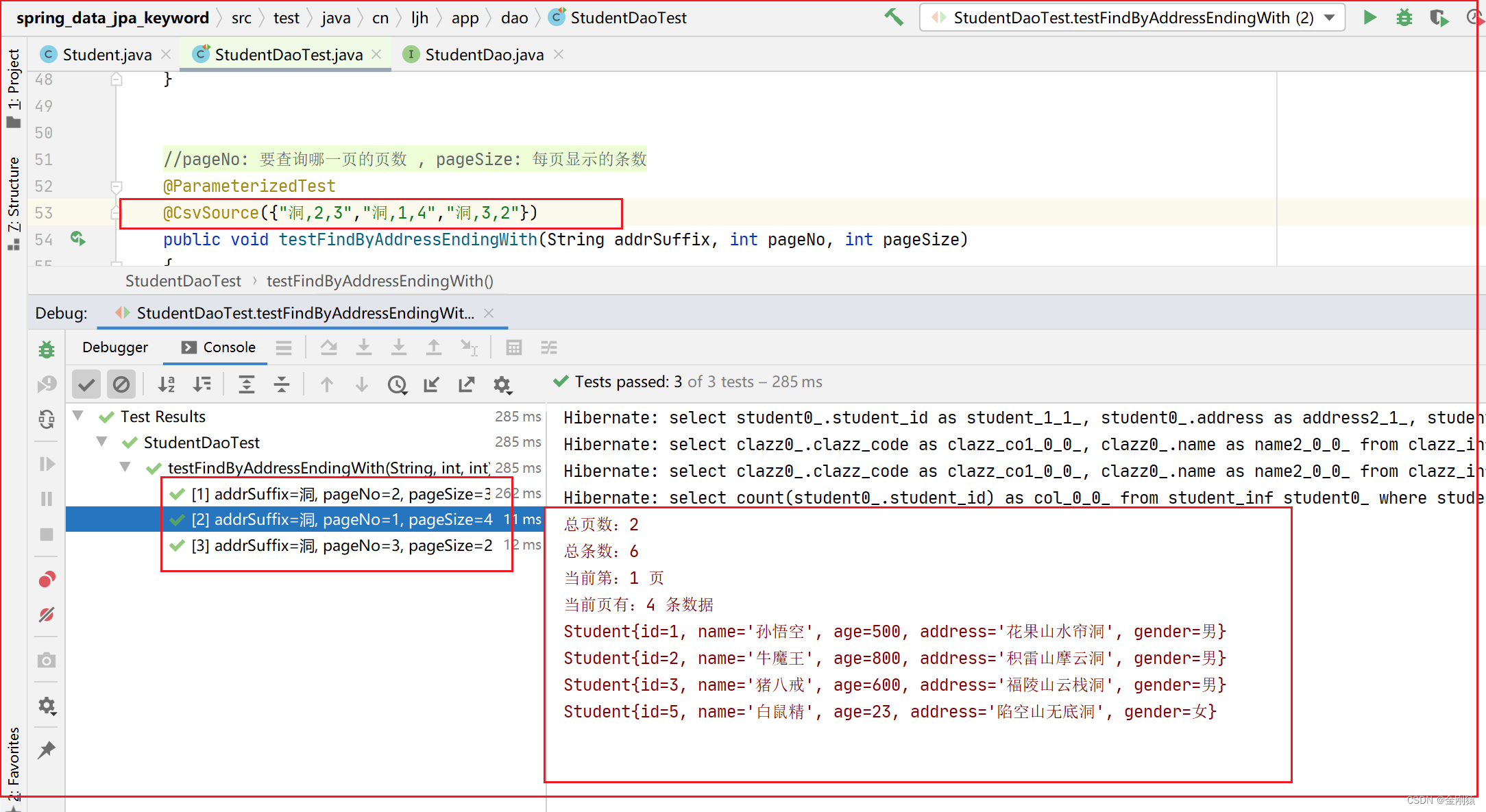
68、Spring Data JPA 的 方法名关键字查询
★ 方法名关键字查询(全自动) (1)继承 CrudRepository 接口 的 DAO 组件可按特定规则来定义查询方法,只要这些查询方法的 方法名 遵守特定的规则,Spring Data 将会自动为这些方法生成 查询语句、提供 方法…...
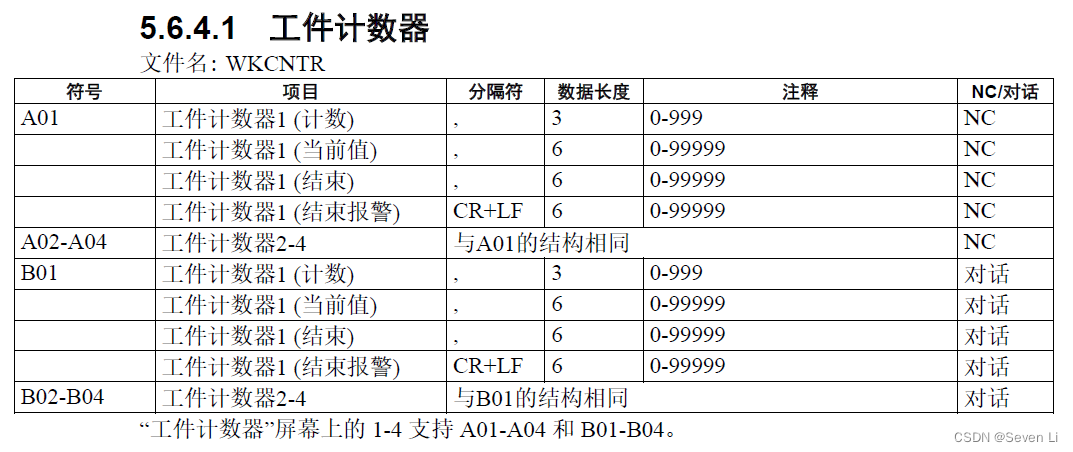
Brother CNC联网数采集和远程控制
兄弟CNC IP地址设定参考:https://www.sohu.com/a/544461221_121353733没有能力写代码的兄弟可以提前下载好网络调试助手NetAssist,这样就不用写代码来测试连接CNC了。 以上是网络调试助手抓取CNC的产出命令,结果有多个行string需要自行解析&…...
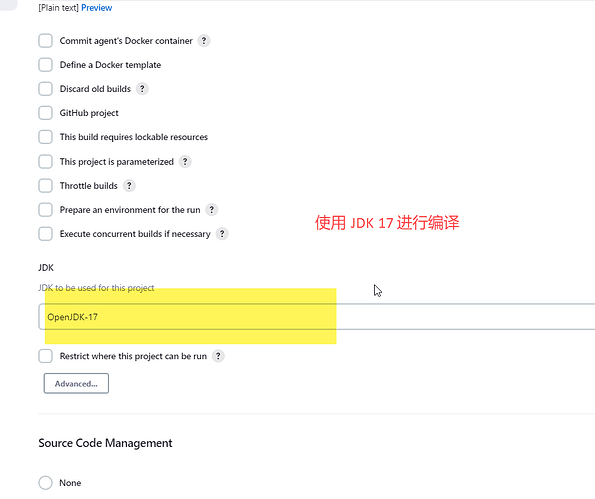
Jenkins 编译 Maven 项目提示错误 version 17
在最近使用集成工具的时候,对项目进行编译提示下面的错误信息: maven-compiler-plugin:3.11.0:compile (default-compile) on project mq-service: Fatal error compiling: error: release version 17 not supported 问题和解决 上面提示的错误信息原…...
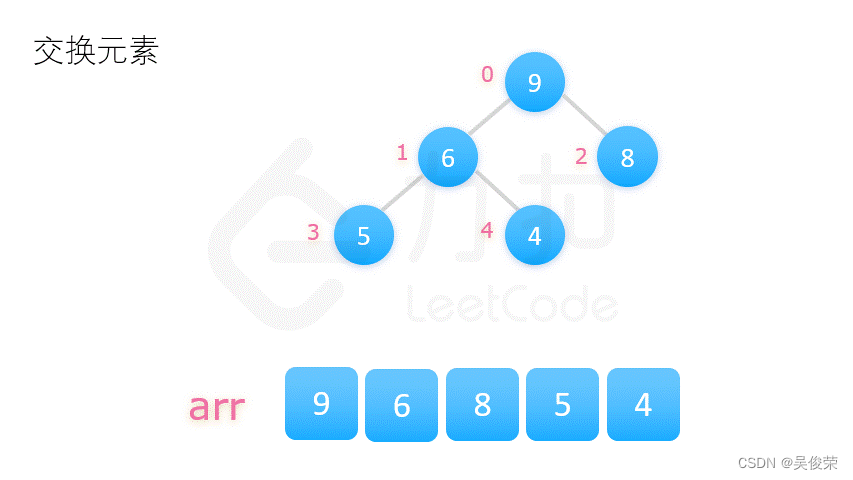
数据结构——排序算法——堆排序
堆排序过程如下: 1.用数列构建出一个大顶堆,取出堆顶的数字; 2.调整剩余的数字,构建出新的大顶堆,再次取出堆顶的数字; 3.循环往复,完成整个排序。 构建大顶堆有两种方式: 1.从 0 开…...
自动做化学实验的机器)
图解人工智能(12)自动做化学实验的机器
近年来,人工智能和传统科学的结合备受瞩目。2019年,英国利物浦大学在《自然》杂志发表论文,介绍了一种可以自动做化学实验的机器人。查找相关资料,并讨论一下类似的工作能给人类社会带来怎样的变革。首先,实验人员的培…...

那些“假装很忙”的员工,正成为中小企业老板最大的管理黑洞
作为一名常年给企业做数字化诊断的顾问,我发现很多老板都有一个共同的“心病”:走进办公室,满屋子都是噼里啪啦的打字声,每个人看起来都在埋头苦干,但一到交付节点,进度总是莫名其妙地卡壳。这种“办公室伪…...
)
告别托盘“隐身术”:Total Commander 9.5 最小化任务栏设置详解(附F12配置技巧)
告别托盘“隐身术”:Total Commander 9.5 最小化任务栏设置详解(附F12配置技巧) 第一次打开Total Commander(以下简称TC)时,许多用户会被它的"消失术"困扰——点击窗口右上角的减号按钮后&#x…...
)
STM32L4低功耗实战:用RTC内部唤醒定时1秒,让设备续航翻倍(附CubeIDE配置)
STM32L4低功耗实战:RTC唤醒中断与CubeIDE配置全解析 在电池供电的物联网终端设计中,每微安电流都关乎产品寿命。曾有个智能农业项目,原本预计6个月的传感器续航,因未优化低功耗模式,实际仅维持了3周。这促使我们深入研…...

技术指标库 Pandas TA 详细使用手册
Pandas TA 详细使用手册:从入门到精通 一、简介与安装 Pandas TA 是一个专为金融时间序列分析打造的技术分析库,它扩展了 Pandas DataFrame,提供 130 种技术指标、60 种K线形态识别功能。它的核心优势在于与 Pandas 深度集成,让你…...

谷歌seo如何发布外链? 新站首月发布的频率与节奏
域名注册后的前30天,谷歌爬虫会对新站点进行密集的抓取与记录。这个阶段的站点就像一张白纸,每一个外源信号都会被放大记录。很多站长习惯在上线首周就去购买几百条低质链接,试图拉高权重,但这往往会导致站点在沙盒期停留更久。根…...

先进制程重塑晶圆代工格局:从HPC需求到供应链博弈
1. 行业现状:先进制程如何重塑晶圆代工格局最近和几位在芯片设计公司负责流片的朋友聊天,大家讨论最激烈的,除了产能紧张,就是到底要不要、以及何时上更先进的工艺节点。一个普遍的共识是:7纳米和5纳米这类所谓“先进制…...

企业级长文档AI落地避坑指南,从PDF解析失真到语义断裂修复——Claude 2026六大隐性能力详解
更多请点击: https://intelliparadigm.com 第一章:PDF解析失真问题的根源与本质诊断 PDF 文件虽为“便携式文档格式”,但其内部结构高度异构——文本可能嵌入在图形路径中、字体被子集化或完全缺失、字符编码映射断裂,甚至存在跨…...

原神帧率解锁技术解析:三步突破60FPS限制的完整方案
原神帧率解锁技术解析:三步突破60FPS限制的完整方案 【免费下载链接】genshin-fps-unlock unlocks the 60 fps cap 项目地址: https://gitcode.com/gh_mirrors/ge/genshin-fps-unlock 你是否曾为《原神》PC版的60FPS限制感到困扰?当你的高性能显卡…...
)
告别Keil!用VSCode+OpenOCD+STLink一键下载STM32程序(保姆级教程)
用VSCodeOpenOCDSTLink打造高效STM32开发环境 在嵌入式开发领域,Keil和IAR等传统IDE长期占据主导地位,但它们臃肿的安装包、昂贵的授权费用和略显陈旧的用户界面让许多开发者开始寻找更现代化的替代方案。Visual Studio Code(VSCodeÿ…...