华为开源自研AI框架昇思MindSpore应用案例:消噪的Diffusion扩散模型
目录
- 一、环境准备
- 1.进入ModelArts官网
- 2.使用CodeLab体验Notebook实例
- 二、案例实现
- 构建Diffusion模型
- 位置向量
- ResNet/ConvNeXT块
- Attention模块
- 组归一化
- 条件U-Net
- 正向扩散
- 数据准备与处理
- 采样
- 训练过程
- 推理过程(从模型中采样)
本文基于Hugging Face:The Annotated Diffusion Model一文翻译迁移而来,同时参考了由浅入深了解Diffusion Model一文。
本教程在Jupyter Notebook上成功运行。如您下载本文档为Python文件,执行Python文件时,请确保执行环境安装了GUI界面。
关于扩散模型(Diffusion Models)有很多种理解,本文的介绍是基于denoising diffusion probabilistic model (DDPM),DDPM已经在(无)条件图像/音频/视频生成领域取得了较多显著的成果,现有的比较受欢迎的的例子包括由OpenAI主导的GLIDE和DALL-E 2、由海德堡大学主导的潜在扩散和由Google Brain主导的图像生成。
实际上生成模型的扩散概念已经在(Sohl-Dickstein et al., 2015)中介绍过。然而,直到(Song et al., 2019)(斯坦福大学)和(Ho et al., 2020)(在Google Brain)才各自独立地改进了这种方法。
本文是在Phil Wang基于PyTorch框架的复现的基础上(而它本身又是基于TensorFlow实现),迁移到MindSpore AI框架上实现的。

如果你对MindSpore感兴趣,可以关注昇思MindSpore社区
一、环境准备
1.进入ModelArts官网
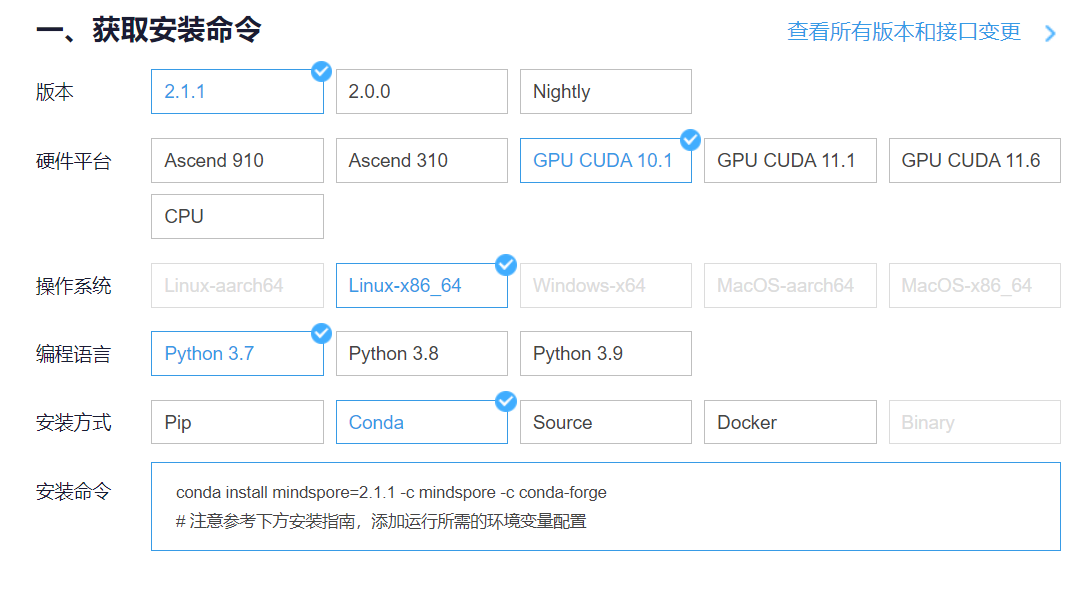
云平台帮助用户快速创建和部署模型,管理全周期AI工作流,选择下面的云平台以开始使用昇思MindSpore,获取安装命令,安装MindSpore2.1.1版本,可以在昇思教程中进入ModelArts官网
选择下方CodeLab立即体验
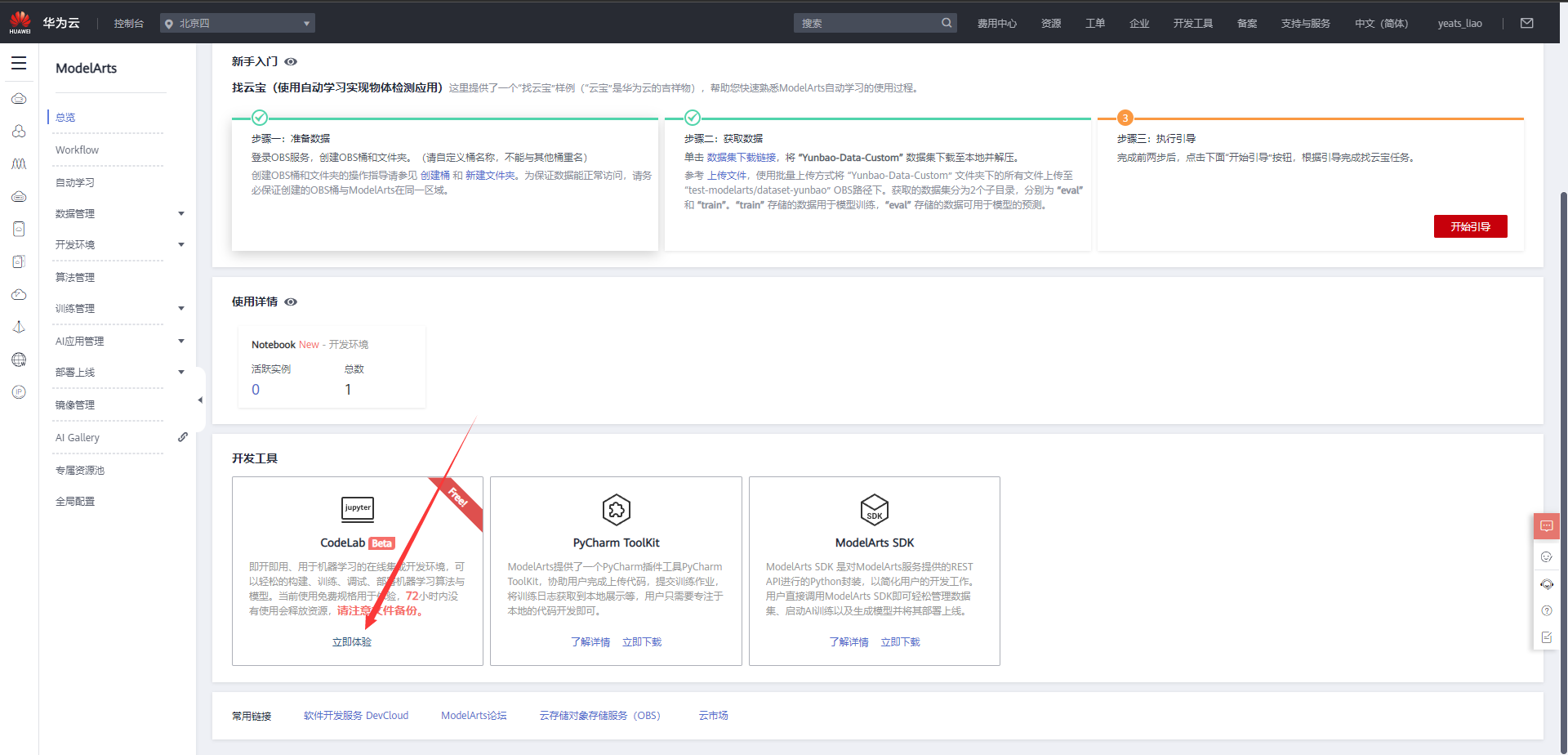
等待环境搭建完成
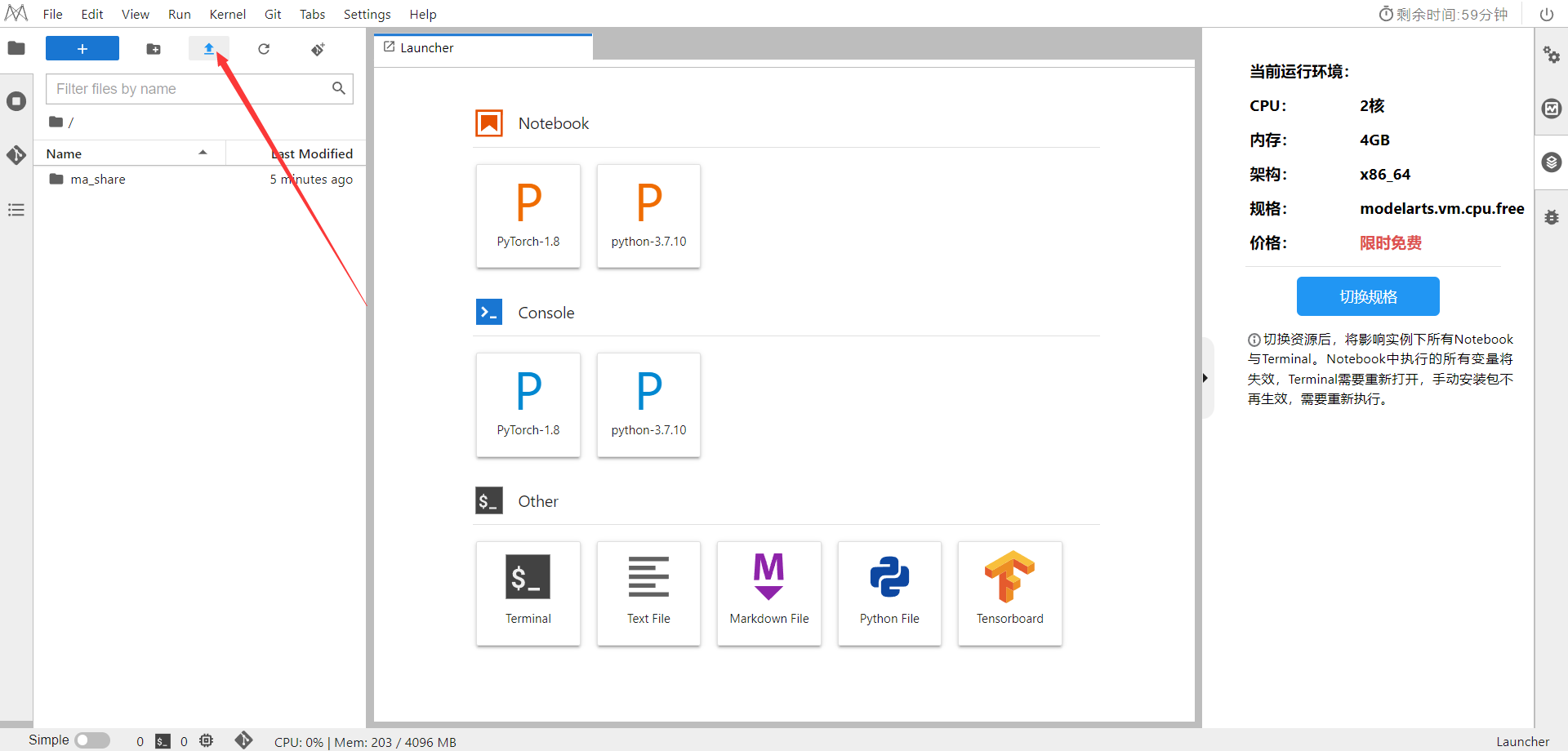
2.使用CodeLab体验Notebook实例
下载NoteBook样例代码,Diffusion扩散模型 ,.ipynb为样例代码

选择ModelArts Upload Files上传.ipynb文件
选择Kernel环境
切换至GPU环境,切换成第一个限时免费
进入昇思MindSpore官网,点击上方的安装

获取安装命令

回到Notebook中,在第一块代码前加入命令
conda update -n base -c defaults conda
安装MindSpore 2.1 GPU版本
conda install mindspore=2.1.1 -c mindspore -c conda-forge
安装mindvision
pip install mindvision
安装下载download
pip install download
二、案例实现
实验开始之前请确保安装并导入所需的库(假设您已经安装了MindSpore、download、dataset、matplotlib以及tqdm)。
import math
from functools import partial
%matplotlib inline
import matplotlib.pyplot as plt
from tqdm.auto import tqdm
import numpy as np
from multiprocessing import cpu_count
from download import downloadimport mindspore as ms
import mindspore.nn as nn
import mindspore.ops as ops
from mindspore import Tensor, Parameter
from mindspore import dtype as mstype
from mindspore.dataset.vision import Resize, Inter, CenterCrop, ToTensor, RandomHorizontalFlip, ToPIL
from mindspore.common.initializer import initializer
from mindspore.amp import DynamicLossScalerms.set_seed(0)
构建Diffusion模型
def rearrange(head, inputs):b, hc, x, y = inputs.shapec = hc // headreturn inputs.reshape((b, head, c, x * y))def rsqrt(x):res = ops.sqrt(x)return ops.inv(res)def randn_like(x, dtype=None):if dtype is None:dtype = x.dtyperes = ops.standard_normal(x.shape).astype(dtype)return resdef randn(shape, dtype=None):if dtype is None:dtype = ms.float32res = ops.standard_normal(shape).astype(dtype)return resdef randint(low, high, size, dtype=ms.int32):res = ops.uniform(size, Tensor(low, dtype), Tensor(high, dtype), dtype=dtype)return resdef exists(x):return x is not Nonedef default(val, d):if exists(val):return valreturn d() if callable(d) else ddef _check_dtype(d1, d2):if ms.float32 in (d1, d2):return ms.float32if d1 == d2:return d1raise ValueError('dtype is not supported.')class Residual(nn.Cell):def __init__(self, fn):super().__init__()self.fn = fndef construct(self, x, *args, **kwargs):return self.fn(x, *args, **kwargs) + x定义了上采样和下采样操作的别名。
def Upsample(dim):return nn.Conv2dTranspose(dim, dim, 4, 2, pad_mode="pad", padding=1)def Downsample(dim):return nn.Conv2d(dim, dim, 4, 2, pad_mode="pad", padding=1)位置向量
由于神经网络的参数在时间(噪声水平)上共享,作者使用正弦位置嵌入来编码t
,灵感来自Transformer(Vaswani et al., 2017)。对于批处理中的每一张图像,神经网络“知道”它在哪个特定时间步长(噪声水平)上运行。
SinusoidalPositionEmbeddings模块采用(batch_size, 1)形状的张量作为输入(即批处理中几个有噪声图像的噪声水平),并将其转换为(batch_size, dim)形状的张量,其中dim是位置嵌入的尺寸。然后,我们将其添加到每个剩余块中。
class SinusoidalPositionEmbeddings(nn.Cell):def __init__(self, dim):super().__init__()self.dim = dimhalf_dim = self.dim // 2emb = math.log(10000) / (half_dim - 1)emb = np.exp(np.arange(half_dim) * - emb)self.emb = Tensor(emb, ms.float32)def construct(self, x):emb = x[:, None] * self.emb[None, :]emb = ops.concat((ops.sin(emb), ops.cos(emb)), axis=-1)return embResNet/ConvNeXT块
接下来,我们定义U-Net模型的核心构建块。DDPM作者使用了一个Wide ResNet块(Zagoruyko et al., 2016),但Phil Wang决定添加ConvNeXT(Liu et al., 2022)替换ResNet,因为后者在图像领域取得了巨大成功。
在最终的U-Net架构中,可以选择其中一个或另一个,本文选择ConvNeXT块构建U-Net模型。
class Block(nn.Cell):def __init__(self, dim, dim_out, groups=1):super().__init__()self.proj = nn.Conv2d(dim, dim_out, 3, pad_mode="pad", padding=1)self.proj = c(dim, dim_out, 3, padding=1, pad_mode='pad')self.norm = nn.GroupNorm(groups, dim_out)self.act = nn.SiLU()def construct(self, x, scale_shift=None):x = self.proj(x)x = self.norm(x)if exists(scale_shift):scale, shift = scale_shiftx = x * (scale + 1) + shiftx = self.act(x)return xclass ConvNextBlock(nn.Cell):def __init__(self, dim, dim_out, *, time_emb_dim=None, mult=2, norm=True):super().__init__()self.mlp = (nn.SequentialCell(nn.GELU(), nn.Dense(time_emb_dim, dim))if exists(time_emb_dim)else None)self.ds_conv = nn.Conv2d(dim, dim, 7, padding=3, group=dim, pad_mode="pad")self.net = nn.SequentialCell(nn.GroupNorm(1, dim) if norm else nn.Identity(),nn.Conv2d(dim, dim_out * mult, 3, padding=1, pad_mode="pad"),nn.GELU(),nn.GroupNorm(1, dim_out * mult),nn.Conv2d(dim_out * mult, dim_out, 3, padding=1, pad_mode="pad"),)self.res_conv = nn.Conv2d(dim, dim_out, 1) if dim != dim_out else nn.Identity()def construct(self, x, time_emb=None):h = self.ds_conv(x)if exists(self.mlp) and exists(time_emb):assert exists(time_emb), "time embedding must be passed in"condition = self.mlp(time_emb)condition = condition.expand_dims(-1).expand_dims(-1)h = h + conditionh = self.net(h)return h + self.res_conv(x)Attention模块
接下来,我们定义SiLU模块,DDPM作者将其添加到卷积块之间。SiLU是著名的Transformer架构(Vaswani et al., 2017),在人工智能的各个领域都取得了巨大的成功,从NLP到蛋白质折叠。Phil Wang使用了两种注意力变体:一种是常规的multi-head self-attention(如Transformer中使用的),另一种是LinearAttention(Shen et al., 2018),其时间和内存要求在序列长度上线性缩放,而不是在常规注意力中缩放。
class Attention(nn.Cell):def __init__(self, dim, heads=4, dim_head=32):super().__init__()self.scale = dim_head ** -0.5self.heads = headshidden_dim = dim_head * headsself.to_qkv = nn.Conv2d(dim, hidden_dim * 3, 1, pad_mode='valid', has_bias=False)self.to_out = nn.Conv2d(hidden_dim, dim, 1, pad_mode='valid', has_bias=True)self.map = ops.Map()self.partial = ops.Partial()def construct(self, x):b, _, h, w = x.shapeqkv = self.to_qkv(x).chunk(3, 1)q, k, v = self.map(self.partial(rearrange, self.heads), qkv)q = q * self.scale# 'b h d i, b h d j -> b h i j'sim = ops.bmm(q.swapaxes(2, 3), k)attn = ops.softmax(sim, axis=-1)# 'b h i j, b h d j -> b h i d'out = ops.bmm(attn, v.swapaxes(2, 3))out = out.swapaxes(-1, -2).reshape((b, -1, h, w))return self.to_out(out)class LayerNorm(nn.Cell):def __init__(self, dim):super().__init__()self.g = Parameter(initializer('ones', (1, dim, 1, 1)), name='g')def construct(self, x):eps = 1e-5var = x.var(1, keepdims=True)mean = x.mean(1, keep_dims=True)return (x - mean) * rsqrt((var + eps)) * self.gclass LinearAttention(nn.Cell):def __init__(self, dim, heads=4, dim_head=32):super().__init__()self.scale = dim_head ** -0.5self.heads = headshidden_dim = dim_head * headsself.to_qkv = nn.Conv2d(dim, hidden_dim * 3, 1, pad_mode='valid', has_bias=False)self.to_out = nn.SequentialCell(nn.Conv2d(hidden_dim, dim, 1, pad_mode='valid', has_bias=True),LayerNorm(dim))self.map = ops.Map()self.partial = ops.Partial()def construct(self, x):b, _, h, w = x.shapeqkv = self.to_qkv(x).chunk(3, 1)q, k, v = self.map(self.partial(rearrange, self.heads), qkv)q = ops.softmax(q, -2)k = ops.softmax(k, -1)q = q * self.scalev = v / (h * w)# 'b h d n, b h e n -> b h d e'context = ops.bmm(k, v.swapaxes(2, 3))# 'b h d e, b h d n -> b h e n'out = ops.bmm(context.swapaxes(2, 3), q)out = out.reshape((b, -1, h, w))return self.to_out(out)组归一化
DDPM作者将U-Net的卷积/注意层与群归一化(Wu et al., 2018)。下面,我们定义一个PreNorm类,将用于在注意层之前应用groupnorm。
class PreNorm(nn.Cell):def __init__(self, dim, fn):super().__init__()self.fn = fnself.norm = nn.GroupNorm(1, dim)def construct(self, x):x = self.norm(x)return self.fn(x)条件U-Net
class Unet(nn.Cell):def __init__(self,dim,init_dim=None,out_dim=None,dim_mults=(1, 2, 4, 8),channels=3,with_time_emb=True,convnext_mult=2,):super().__init__()self.channels = channelsinit_dim = default(init_dim, dim // 3 * 2)self.init_conv = nn.Conv2d(channels, init_dim, 7, padding=3, pad_mode="pad", has_bias=True)dims = [init_dim, *map(lambda m: dim * m, dim_mults)]in_out = list(zip(dims[:-1], dims[1:]))block_klass = partial(ConvNextBlock, mult=convnext_mult)if with_time_emb:time_dim = dim * 4self.time_mlp = nn.SequentialCell(SinusoidalPositionEmbeddings(dim),nn.Dense(dim, time_dim),nn.GELU(),nn.Dense(time_dim, time_dim),)else:time_dim = Noneself.time_mlp = Noneself.downs = nn.CellList([])self.ups = nn.CellList([])num_resolutions = len(in_out)for ind, (dim_in, dim_out) in enumerate(in_out):is_last = ind >= (num_resolutions - 1)self.downs.append(nn.CellList([block_klass(dim_in, dim_out, time_emb_dim=time_dim),block_klass(dim_out, dim_out, time_emb_dim=time_dim),Residual(PreNorm(dim_out, LinearAttention(dim_out))),Downsample(dim_out) if not is_last else nn.Identity(),]))mid_dim = dims[-1]self.mid_block1 = block_klass(mid_dim, mid_dim, time_emb_dim=time_dim)self.mid_attn = Residual(PreNorm(mid_dim, Attention(mid_dim)))self.mid_block2 = block_klass(mid_dim, mid_dim, time_emb_dim=time_dim)for ind, (dim_in, dim_out) in enumerate(reversed(in_out[1:])):is_last = ind >= (num_resolutions - 1)self.ups.append(nn.CellList([block_klass(dim_out * 2, dim_in, time_emb_dim=time_dim),block_klass(dim_in, dim_in, time_emb_dim=time_dim),Residual(PreNorm(dim_in, LinearAttention(dim_in))),Upsample(dim_in) if not is_last else nn.Identity(),]))out_dim = default(out_dim, channels)self.final_conv = nn.SequentialCell(block_klass(dim, dim), nn.Conv2d(dim, out_dim, 1))def construct(self, x, time):x = self.init_conv(x)t = self.time_mlp(time) if exists(self.time_mlp) else Noneh = []for block1, block2, attn, downsample in self.downs:x = block1(x, t)x = block2(x, t)x = attn(x)h.append(x)x = downsample(x)x = self.mid_block1(x, t)x = self.mid_attn(x)x = self.mid_block2(x, t)len_h = len(h) - 1for block1, block2, attn, upsample in self.ups:x = ops.concat((x, h[len_h]), 1)len_h -= 1x = block1(x, t)x = block2(x, t)x = attn(x)x = upsample(x)return self.final_conv(x)正向扩散
def linear_beta_schedule(timesteps):beta_start = 0.0001beta_end = 0.02return np.linspace(beta_start, beta_end, timesteps).astype(np.float32)# 扩散200步
timesteps = 200# 定义 beta schedule
betas = linear_beta_schedule(timesteps=timesteps)# 定义 alphas
alphas = 1. - betas
alphas_cumprod = np.cumprod(alphas, axis=0)
alphas_cumprod_prev = np.pad(alphas_cumprod[:-1], (1, 0), constant_values=1)sqrt_recip_alphas = Tensor(np.sqrt(1. / alphas))
sqrt_alphas_cumprod = Tensor(np.sqrt(alphas_cumprod))
sqrt_one_minus_alphas_cumprod = Tensor(np.sqrt(1. - alphas_cumprod))# 计算 q(x_{t-1} | x_t, x_0)
posterior_variance = betas * (1. - alphas_cumprod_prev) / (1. - alphas_cumprod)p2_loss_weight = (1 + alphas_cumprod / (1 - alphas_cumprod)) ** -0.
p2_loss_weight = Tensor(p2_loss_weight)def extract(a, t, x_shape):b = t.shape[0]out = Tensor(a).gather(t, -1)return out.reshape(b, *((1,) * (len(x_shape) - 1)))用猫图像说明如何在扩散过程的每个时间步骤中添加噪音。
# 下载猫猫图像
url = 'https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/image_cat.zip'
path = download(url, './', kind="zip", replace=True)from PIL import Imageimage = Image.open('./image_cat/jpg/000000039769.jpg')
base_width = 160
image = image.resize((base_width, int(float(image.size[1]) * float(base_width / float(image.size[0])))))
image.show()噪声被添加到mindspore张量中,而不是Pillow图像。我们将首先定义图像转换,允许我们从PIL图像转换到mindspore张量(我们可以在其上添加噪声),反之亦然。
from mindspore.dataset import ImageFolderDatasetimage_size = 128
transforms = [Resize(image_size, Inter.BILINEAR),CenterCrop(image_size),ToTensor(),lambda t: (t * 2) - 1
]path = './image_cat'
dataset = ImageFolderDataset(dataset_dir=path, num_parallel_workers=cpu_count(),extensions=['.jpg', '.jpeg', '.png', '.tiff'],num_shards=1, shard_id=0, shuffle=False, decode=True)
dataset = dataset.project('image')
transforms.insert(1, RandomHorizontalFlip())
dataset_1 = dataset.map(transforms, 'image')
dataset_2 = dataset_1.batch(1, drop_remainder=True)
x_start = next(dataset_2.create_tuple_iterator())[0]
print(x_start.shape)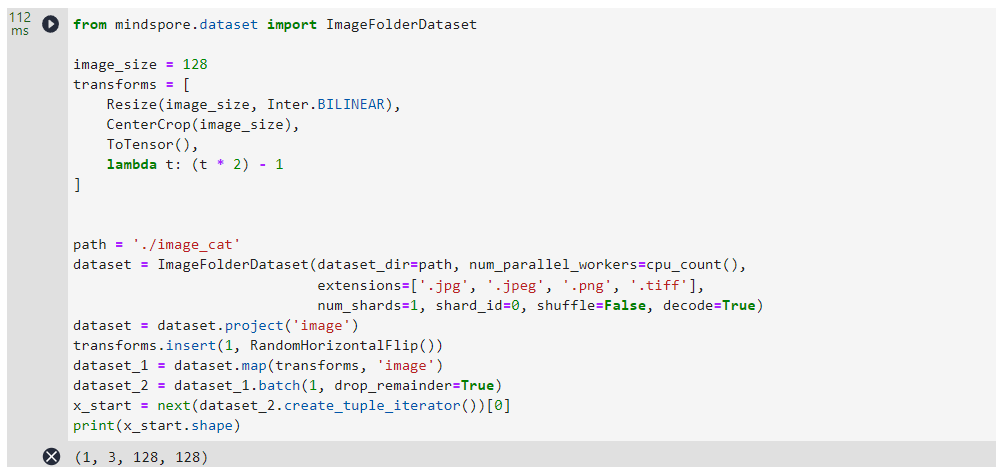
定义了反向变换,它接收一个包含 [−1,1]中的张量,并将它们转回 PIL 图像:
import numpy as npreverse_transform = [lambda t: (t + 1) / 2,lambda t: ops.permute(t, (1, 2, 0)), # CHW to HWClambda t: t * 255.,lambda t: t.asnumpy().astype(np.uint8),ToPIL()
]def compose(transform, x):for d in transform:x = d(x)return xreverse_image = compose(reverse_transform, x_start[0])
reverse_image.show()我们现在可以定义前向扩散过程,如本文所示:
def q_sample(x_start, t, noise=None):if noise is None:noise = randn_like(x_start)return (extract(sqrt_alphas_cumprod, t, x_start.shape) * x_start +extract(sqrt_one_minus_alphas_cumprod, t, x_start.shape) * noise)让我们在特定的时间步长上测试它:
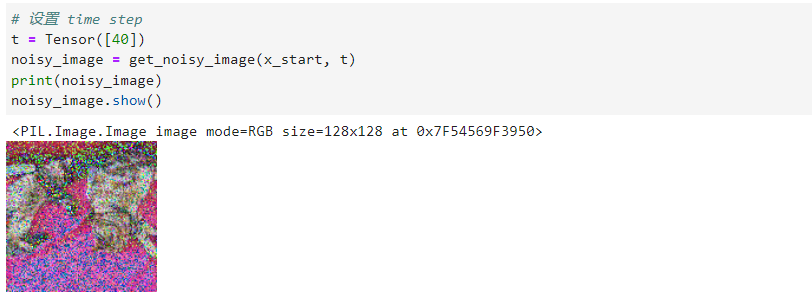
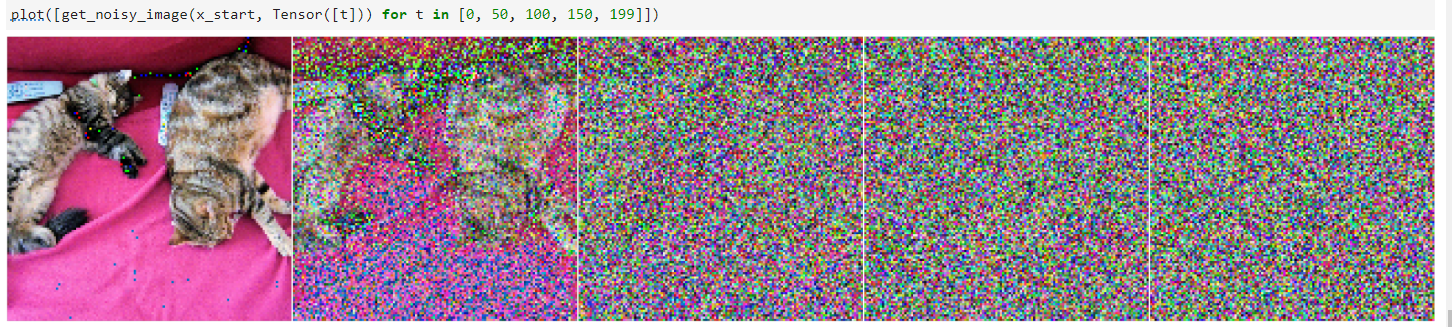
让我们为不同的时间步骤可视化此情况:
可以定义给定模型的损失函数,如下所示:
def p_losses(unet_model, x_start, t, noise=None):if noise is None:noise = randn_like(x_start)x_noisy = q_sample(x_start=x_start, t=t, noise=noise)predicted_noise = unet_model(x_noisy, t)loss = nn.SmoothL1Loss()(noise, predicted_noise)# todoloss = loss.reshape(loss.shape[0], -1)loss = loss * extract(p2_loss_weight, t, loss.shape)return loss.mean()denoise_model将是我们上面定义的U-Net。我们将在真实噪声和预测噪声之间使用Huber损失。
数据准备与处理
在这里我们定义一个正则数据集。数据集可以来自简单的真实数据集的图像组成,如Fashion-MNIST、CIFAR-10或ImageNet,其中线性缩放为 [−1,1]
。
# 下载MNIST数据集
url = 'https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/dataset.zip'
path = download(url, './', kind="zip", replace=True)
from mindspore.dataset import FashionMnistDatasetimage_size = 28
channels = 1
batch_size = 16fashion_mnist_dataset_dir = "./dataset"
dataset = FashionMnistDataset(dataset_dir=fashion_mnist_dataset_dir, usage="train", num_parallel_workers=cpu_count(), shuffle=True, num_shards=1, shard_id=0)接下来定义一个transform操作,将在整个数据集上动态应用该操作。该操作应用一些基本的图像预处理:随机水平翻转、重新调整,最后使它们的值在 [−1,1]范围内。
transforms = [RandomHorizontalFlip(),ToTensor(),lambda t: (t * 2) - 1
]dataset = dataset.project('image')
dataset = dataset.shuffle(64)
dataset = dataset.map(transforms, 'image')
dataset = dataset.batch(16, drop_remainder=True)x = next(dataset.create_dict_iterator())
print(x.keys())
采样
def p_sample(model, x, t, t_index):betas_t = extract(betas, t, x.shape)sqrt_one_minus_alphas_cumprod_t = extract(sqrt_one_minus_alphas_cumprod, t, x.shape)sqrt_recip_alphas_t = extract(sqrt_recip_alphas, t, x.shape)model_mean = sqrt_recip_alphas_t * (x - betas_t * model(x, t) / sqrt_one_minus_alphas_cumprod_t)if t_index == 0:return model_meanposterior_variance_t = extract(posterior_variance, t, x.shape)noise = randn_like(x)return model_mean + ops.sqrt(posterior_variance_t) * noisedef p_sample_loop(model, shape):b = shape[0]# 从纯噪声开始img = randn(shape, dtype=None)imgs = []for i in tqdm(reversed(range(0, timesteps)), desc='sampling loop time step', total=timesteps):img = p_sample(model, img, ms.numpy.full((b,), i, dtype=mstype.int32), i)imgs.append(img.asnumpy())return imgsdef sample(model, image_size, batch_size=16, channels=3):return p_sample_loop(model, shape=(batch_size, channels, image_size, image_size))请注意,上面的代码是原始实现的简化版本。
训练过程
# 定义动态学习率
lr = nn.cosine_decay_lr(min_lr=1e-7, max_lr=1e-4, total_step=10*3750, step_per_epoch=3750, decay_epoch=10)# 定义 Unet模型
unet_model = Unet(dim=image_size,channels=channels,dim_mults=(1, 2, 4,)
)name_list = []
for (name, par) in list(unet_model.parameters_and_names()):name_list.append(name)
i = 0
for item in list(unet_model.trainable_params()):item.name = name_list[i]i += 1# 定义优化器
optimizer = nn.Adam(unet_model.trainable_params(), learning_rate=lr)
loss_scaler = DynamicLossScaler(65536, 2, 1000)# 定义前向过程
def forward_fn(data, t, noise=None):loss = p_losses(unet_model, data, t, noise)return loss# 计算梯度
grad_fn = ms.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=False)# 梯度更新
def train_step(data, t, noise):loss, grads = grad_fn(data, t, noise)optimizer(grads)return lossimport timeepochs = 10for epoch in range(epochs):begin_time = time.time()for step, batch in enumerate(dataset.create_tuple_iterator()):unet_model.set_train()batch_size = batch[0].shape[0]t = randint(0, timesteps, (batch_size,), dtype=ms.int32)noise = randn_like(batch[0])loss = train_step(batch[0], t, noise)if step % 500 == 0:print(" epoch: ", epoch, " step: ", step, " Loss: ", loss)end_time = time.time()times = end_time - begin_timeprint("training time:", times, "s")# 展示随机采样效果unet_model.set_train(False)samples = sample(unet_model, image_size=image_size, batch_size=64, channels=channels)plt.imshow(samples[-1][5].reshape(image_size, image_size, channels), cmap="gray")
print("Training Success!")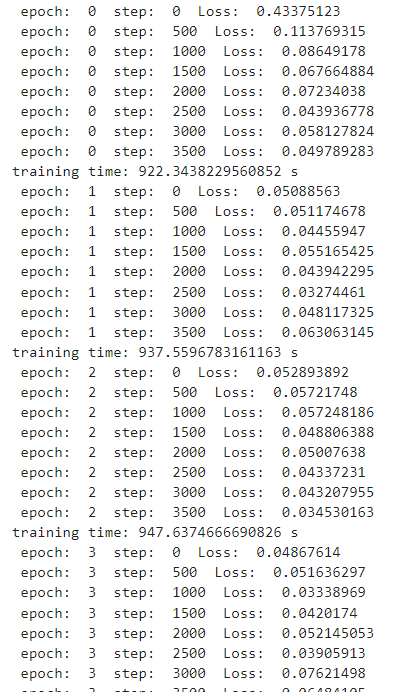
推理过程(从模型中采样)
# 采样64个图片
unet_model.set_train(False)
samples = sample(unet_model, image_size=image_size, batch_size=64, channels=channels)# 展示一个随机效果
random_index = 5
plt.imshow(samples[-1][random_index].reshape(image_size, image_size, channels), cmap="gray")创建去噪过程的gif:
import matplotlib.animation as animationrandom_index = 53fig = plt.figure()
ims = []
for i in range(timesteps):im = plt.imshow(samples[i][random_index].reshape(image_size, image_size, channels), cmap="gray", animated=True)ims.append([im])animate = animation.ArtistAnimation(fig, ims, interval=50, blit=True, repeat_delay=100)
animate.save('diffusion.gif')
plt.show()相关文章:
华为开源自研AI框架昇思MindSpore应用案例:消噪的Diffusion扩散模型
目录 一、环境准备1.进入ModelArts官网2.使用CodeLab体验Notebook实例 二、案例实现构建Diffusion模型位置向量ResNet/ConvNeXT块Attention模块组归一化条件U-Net正向扩散数据准备与处理采样训练过程推理过程(从模型中采样) 本文基于Hugging Face&#x…...
华为CD32键盘使用教程
华为CD32键盘使用教程 用爱发电写的教程! 最后更新时间:2023.9.12 型号:华为有线键盘CD32 基本使用 此键盘在不安装驱动的情况下可以直接使用,但是不安装驱动指纹识别是无法使用的!并且NFC功能只支持华为的部分电脑…...

第三节:在WORD为应用主窗口下关闭EXCEL的操作(2)
【分享成果,随喜正能量】凡事好坏,多半自作自受,既不是神为我们安排,也不是天意偏私袒护。业力之前,机会均等,毫无特殊例外;好坏与否,端看自己是否能应机把握,随缘得度。…...
(04))
Layui + Flask | 弹出层(组件篇)(04)
提示:点击阅读原文体验更佳 https://layui.dev/docs/2.8/layer/ 弹出层组件 layer 是 Layui 最古老的组件,也是使用覆盖面最广泛的代表性组件。在实现网页弹出层的首选交互方案,使用的非常频繁。 打开弹层 layer.open(options); 参数 options : 基础属性配置项。打开弹层的核…...

Electron和vue3集成(推荐仅用于开发)
本篇我们仅实现Electron和vue3通过先运行起vue3项目,再将vue3的url地址交由Electron打开的方案,仅由Electron在vue3项目上套一层壳来达到脱离本机浏览器运行目的 1、参考快速上手 | Vue.js搭建起vue3初始项目 npm install -g vue npm install -g vue/c…...
Vue.js和TypeScript:如何完美结合
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...

034:vue项目利用qrcodejs2生成二维码示例
第034个 查看专栏目录: VUE ------ element UI 专栏目标 在vue和element UI联合技术栈的操控下,本专栏提供行之有效的源代码示例和信息点介绍,做到灵活运用。 (1)提供vue2的一些基本操作:安装、引用,模板使…...
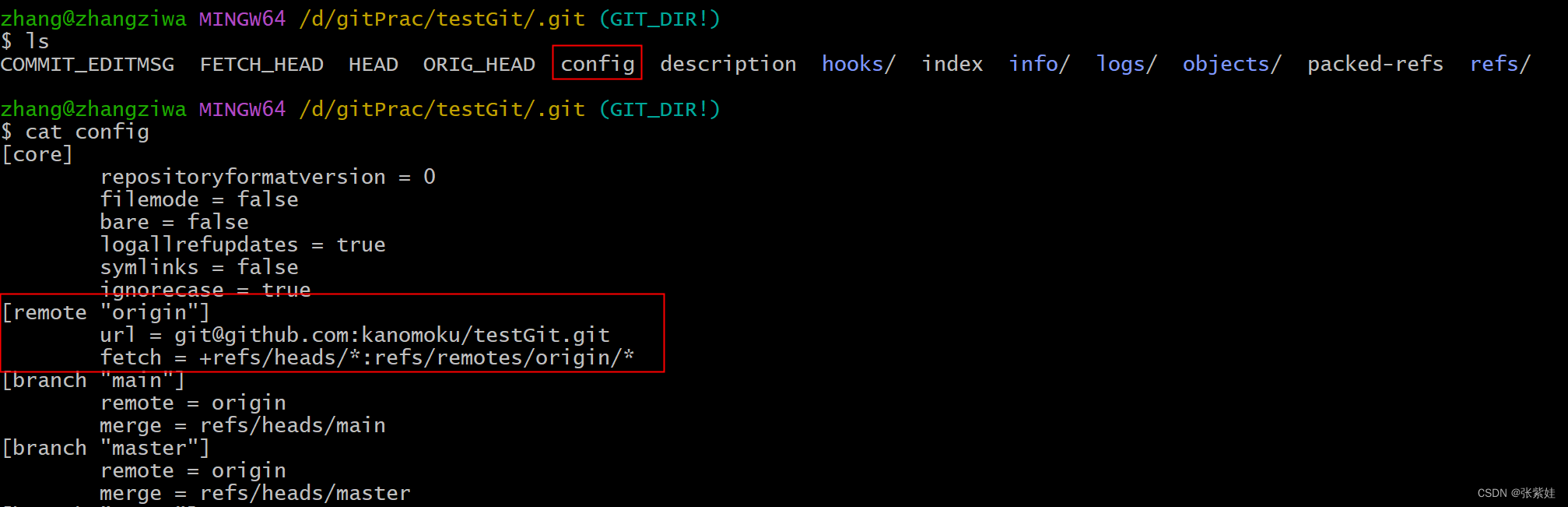
执行 git remote add github git@github.com:xxxx/testGit.git时,git内部做了啥?
git remote add 往 .git/config 中写入了一个叫 [remote "origin"] 配置 url → 表示该远程名称对应的远程仓库地址fetch 参数分为两部分,以冒号 : 进行分割冒号左边 ☞ 本地仓库文件夹冒号右边 ☞ 远程仓库在本地的副本文件夹 ☞ 往里面添加数据的意思 可…...

Makefile基础
迷途小书童 读完需要 4分钟 速读仅需 2 分钟 1 引言 下面这个 C 语言的代码非常简单 #include <stdio.h>int main() {printf("Hello World!.\n");return 0; } 在 Linux 下面,我们使用下面的命令编译就可以 gcc hello.c -o hello 但是随着项目的变大…...

【PickerView案例08-国旗搭建界面加载数据 Objective-C预言】
一、来看我们第三个案例 1.来看我们第三个关于PickerView的一个案例, 首先呢,我要问大家一下, 咱们这个是几组数据呢, 这是一个pickerView,只不过,它显示的是什么,一个界面, 前面两个案例,都是文字 这个案例,开始有图片了, 总结一下这三个案例: 1)第一个案例…...

2023-09-15力扣每日一题
链接: [LCP 50. 宝石补给](https://leetcode.cn/problems/queens-that-can-attack-the-king/) 题意 略 解: 简单题 模拟 实际代码: int giveGem(vector<int>& gem, vector<vector<int>>& operations) {for(…...
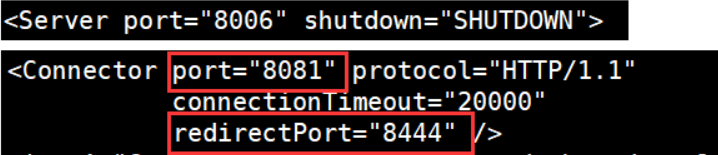
系列七、Nginx负载均衡配置
一、目标 浏览器中访问http://{IP地址}:9002/edu/index.html,浏览器交替打印清华大学8080、清华大学8081. 二、步骤 2.1、在tomcat8080、tomcat8081的webapps中分别创建edu文件夹 2.2、将index.html分别上传至edu文件夹 注意事项:tomcat8080的edu文件…...

Python爬虫(二十)_动态爬取影评信息
本案例介绍从JavaScript中采集加载的数据。更多内容请参考:Python学习指南 #-*- coding:utf-8 -*- import requests import re import time import json#数据下载器 class HtmlDownloader(object):def download(self, url, paramsNone):if url is None:return Noneuser_agent …...
基于 Flink CDC 高效构建入湖通道
本文整理自阿里云 Flink 数据通道负责人、Flink CDC 开源社区负责人, Apache Flink PMC Member & Committer 徐榜江(雪尽),在 Streaming Lakehouse Meetup 的分享。内容主要分为四个部分: Flink CDC 核心技术解析数…...
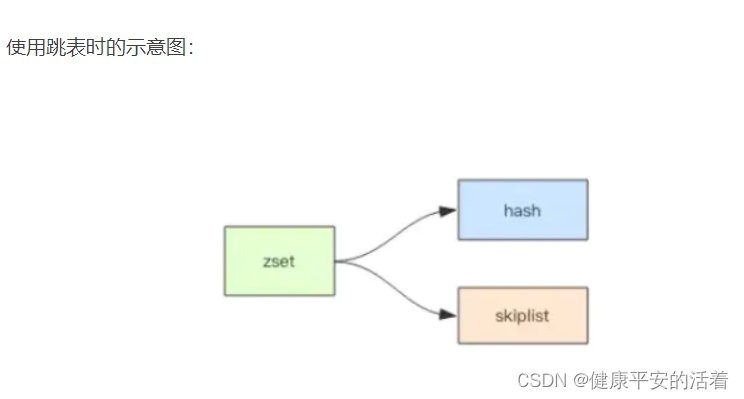
redis的基础底层篇 zset的详解
一 zset的作用以及结构 1.1 zset作用 redis的zset是一个有序的集合,和普通集合set非常相似,是一个没有重复元素的字符串集合。常用作排行榜等功能,以用户 id 为 value,关注时间或者分数作为 score 进行排序。 1.2 zset的底层结…...

数据分享|R语言逻辑回归、线性判别分析LDA、GAM、MARS、KNN、QDA、决策树、随机森林、SVM分类葡萄酒交叉验证ROC...
全文链接:http://tecdat.cn/?p27384 在本文中,数据包含有关葡萄牙“Vinho Verde”葡萄酒的信息(点击文末“阅读原文”获取完整代码数据)。 介绍 该数据集(查看文末了解数据获取方式)有1599个观测值和12个变量…...
 点云旋转的轴角表示法和罗德里格斯公式)
Open3D(C++) 点云旋转的轴角表示法和罗德里格斯公式
目录 一、算法原理1、轴角表示法2、罗德里格斯公式二、代码实现三、结果展示四、相关链接一、算法原理 1、轴角表示法 假设刚体坐标系为B(Oxyz)绕单位向量 ω ⃗ \vec{ω}...
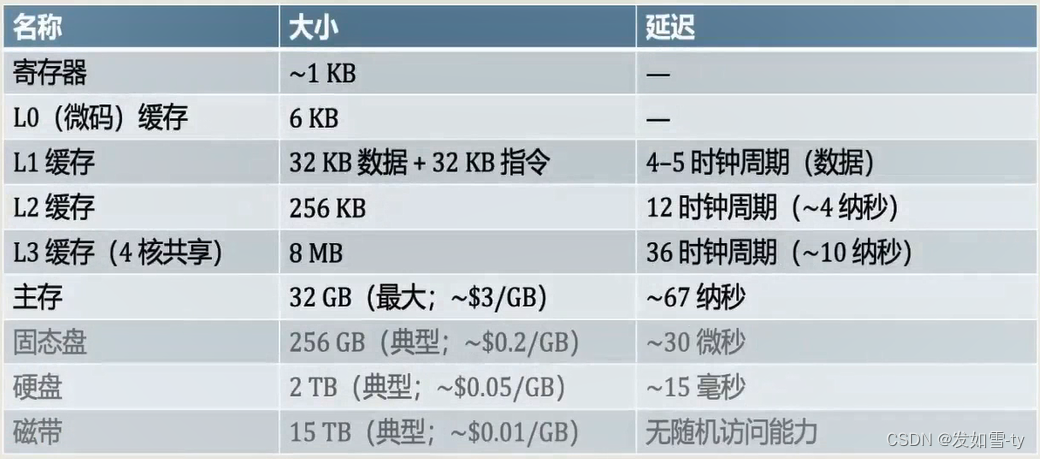
CPU的三级缓存
CPU缓存(Cache Memory)是位于CPU与内存之间的临时存储器,它的容量比内存小的多但是交换速度却比内存要快得多。高速缓存的出现主要是为了解决CPU运算速度与内存读写速度不匹配的矛盾,因为CPU运算速度要比内存读写速度快很多&#…...

pgzrun 拼图游戏制作过程详解(6,7)
6. 检查拼图完成 初始化标记成功的变量Is_Win Is_WinFalse 当鼠标点击小拼图时,判断所有小拼图是否都在正确的位置,并更新Is_Win。 def on_mouse_down(pos,button): # 当鼠标被点击时# 略is_win Truefor i in range(6):for j in range(4):Square S…...

laravel框架 - 集合篇
Laravel Eloquent 通常返回一个集合作为结果,集合包含很多有用的、功能强大的方法。 你可以很方便的对集合进行过滤、修改等操作。 本次教程就一起来看一看集合的常用方法及功能。 你可以使用助手函数 collect 将数组转化为集合。 $data collect([1, 2, 3]); 1…...

Fillinger智能填充算法深度解析:从三角剖分到工程化实现
Fillinger智能填充算法深度解析:从三角剖分到工程化实现 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 在矢量图形设计领域,复杂形状内的元素填充是一个常见…...

嵌入式处理器IP选型指南:从ARM到RISC-V的权衡与实战
1. 从一场早餐会聊起:为什么32位处理器IP依然是嵌入式开发的硬通货最近在整理资料时,翻到一篇十多年前的老新闻,说的是IP供应商CAST要在DesignCon 2012上办一场免费的早餐研讨会,主题是他们新推出的BA22 32位处理器IP核。新闻里笔…...

使用Node.js在虚拟机后端服务中集成Taotoken多模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Node.js在虚拟机后端服务中集成Taotoken多模型调用 在虚拟机环境中部署Node.js后端服务时,直接对接多个大模型厂商…...

SKILLS All-in-one:开源AI Agent技能库,标准化Prompt与工具函数,提升开发效率
1. 项目定位与核心价值如果你和我一样,在过去一年里深度使用过 Claude Code、ChatGPT 或者尝试搭建自己的 AI Agent 工作流,那你一定遇到过这个痛点:每次想给 AI 装个新“技能”,都得自己从头写 Prompt、设计工具调用逻辑、处理错…...

终极指南:如何快速筛选高质量免费股票资源的5大核心标准
终极指南:如何快速筛选高质量免费股票资源的5大核心标准 【免费下载链接】awesome-stock-resources :city_sunrise: A collection of links for free stock photography, video and Illustration websites 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-s…...

Doramagic:AI助手开源项目专家技能提取引擎架构与实战
1. 项目概述:Doramagic,一个为AI助手注入项目“灵魂”的提取引擎如果你和我一样,每天都在和各种各样的开源项目打交道,从FastAPI到Home Assistant,从Next.js到LangChain,那你肯定也遇到过这样的困境&#x…...

基于python-telegram-bot的审批按钮系统设计与实现
1. 项目概述:一个为Telegram机器人设计的审批按钮系统如果你在团队协作、内容审核或者自动化流程中,经常需要通过Telegram机器人来处理“同意”或“拒绝”这类审批请求,那么你很可能遇到过这样的困扰:用户发来一条需要审核的消息&…...

MANT量化技术:大语言模型推理的硬件架构革新
1. MANT量化技术:大语言模型推理的硬件架构革新在人工智能领域,大语言模型(LLM)的推理效率一直是制约其实际应用的关键瓶颈。传统量化方法往往面临精度损失与硬件适配的双重挑战,而MANT技术的出现为这一困境提供了创新解决方案。作为一名深耕…...
:Agent 的记忆危机与 Mem0 的三阶段管道——为什么 RAG 不够用?)
【Mem0】 源码剖析(一):Agent 的记忆危机与 Mem0 的三阶段管道——为什么 RAG 不够用?
【Mem0】 源码剖析(一):Agent 的记忆危机与 Mem0 的三阶段管道——为什么 RAG 不够用? 写在前面:54K Star,论文被 arXiv 收录,LOCOMO 基准 SOTA——Mem0 是当前 Agent 记忆层的事实标准。它的核…...
,搞定业务中的因果推断难题)
别再只做AB测试了!用Python实战倾向性得分匹配(PSM),搞定业务中的因果推断难题
用Python实战倾向性得分匹配(PSM):超越AB测试的因果推断利器 在数据驱动的决策时代,企业经常面临一个核心问题:如何准确评估策略或干预措施的真实效果?传统AB测试虽然简单直观,但在面对历史数据、观测数据等非随机实验…...