【Java】采用 Tabula 技术对 PDF 文件内表格进行数据提取
某天项目组来了个需求说需要提取 PDF 文件中数据作为数据沉淀使用,这是因为第三方系统不提供数据接口所以只能够出此下策。
就据我所知,PDF 文件内数据提取目前有 3 种解决方案:
第一种,资金足够的话可以直接通过人工智能对 PDF 内容进行解析,按照你需要的规格数据进行输出即可;
第二种,采用 OCR 识别技术对内容进行提取;
第三种,通过工具实现(也是我将为您呈现的)。在开源社区中 PDFbox 人气很高,文字的识别率也很不错,但是对于表格支持不太友好,涉及到表格数据提取的我选用了 Tabula 来实现;
Tabula 是什么?
Tabula是一个开源工具,用于从PDF文档中提取表格数据。它的主要技术包括:
- PDF 解析:Tabula 使用 Java 的 PDFBox 库来解析 PDF 文档的内容和布局。它可以定位到每个页的文本块和图像的坐标;
- 表格识别:Tabula 通过分析页面上的线条和文本块的布局来识别表格的结构。它会查找垂直和水平的线条作为列和行的分隔符;
- 单元格提取:在确定了表格的结构后,Tabula 会分析每个单元格对应的文本块,并提取出单元格中的文本内容;
- 数据整理:Tabula 会尝试自动整理从表格中提取的数据,例如:纵向和横向合并单元格,处理跨页的表格等。它也会执行一定的文本清理;
- 导出格式:Tabula 支持将提取出来的数据导出为 CSV 和 JSON 格式。用户可以导入到 Excel 等其他工具中进行后续分析。
- 优化算法:Tabula 在表格分析和数据提取方面使用了一些优化的算法和启发式规则,以提高正确率。同时它也提供了交互式的编辑接口供用户校正结果。
怎么用 Tabula?
首先肯定是引入 pom 文件依赖,如下图:
<dependency><groupId>technology.tabula</groupId><artifactId>tabula</artifactId><version>1.0.5</version>
</dependency>
接着就可以创建 PDF 工具类了(PdfUtil)
public class PdfUtil {...private static final SpreadsheetExtractionAlgorithm SPREADSHEEET_EXTRACTION_ALGORITHM = new SpreadsheetExtractionAlgorithm();private static final ThreadLocal<List<String>> THREAD_LOCAL = new ThreadLocal<>();.../*** @description: 解析pdf表格(私有方法)* 使用 tabula-java 的 sdk 基本上都是这样来解析 pdf 中的表格的,所以可以将程序提取出来,直到 cell* 单元格为止* @param {*} String pdf 路径* @param {*} int 自定义起始行* @param {*} PdfCellCallback 特殊回调处理* @return {*}*/private static JSONArray parsePdfTable(String pdfPath, int customStart, PdfCellCustomProcess callback) {JSONArray reJsonArr = new JSONArray(); // 存储解析后的JSON数组try (PDDocument document = PDDocument.load(new File(pdfPath))) {PageIterator pi = new ObjectExtractor(document).extract(); // 获取页面迭代器// 遍历所有页面while (pi.hasNext()) {Page page = pi.next(); // 获取当前页List<Table> tableList = SPREADSHEEET_EXTRACTION_ALGORITHM.extract(page); // 解析页面上的所有表格// 遍历所有表格for (Table table : tableList) {List<List<RectangularTextContainer>> rowList = table.getRows(); // 获取表格中的每一行// 遍历所有行并获取每个单元格信息for (int rowIndex = customStart; rowIndex < rowList.size(); rowIndex++) {List<RectangularTextContainer> cellList = rowList.get(rowIndex); // 获取行中的每个单元格callback.handler(cellList, rowIndex, reJsonArr);}}}} catch (IOException e) {LOGGER.error(MARKER,"function[PdfUtil.parsePdfTable] Exception [{} - {}] stackTrace[{}]",e.getCause(), e.getMessage(), e.getStackTrace());} finally {THREAD_LOCAL.remove();}return reJsonArr; // 返回解析后的JSON数组}...}
这里我们先按照官网样例代码来实现 pdf 表格解析先。大致的思路就是:
- 创建一个空的 JSONArray 对象 reJsonArr ,用于存储解析后的表格数据;
- 使用 PDDocument.load 方法加载指定路径的 PDF 文件,并使用 try-with-resources 语句创建一个 PDDocument 对象 document ;
- 使用 ObjectExtractor 从 document 中提取页面迭代器 pi ;
- 使用 while 循环遍历每个页面,使用 pi.hasNext 方法判断是否还有下一个页面,如果有则进入循环;
- 使用 pi.next 方法获取当前页面对象 page ;
- 使用 SPREADSHEEET_EXTRACTION_ALGORITHM 解析 page 中的所有表格,并将结果存储在 tableList 中;
- 使用 for 循环遍历 tableList 中的每个表格,对于每个表格执行以下操作:
a. 使用 table.getRows 方法获取表格中的每一行,并将结果存储在 rowList 中;
b. 使用 for 循环遍历 rowList 中的每一行,从 customStart 位置开始,对于每一行执行以下操作:
i. 使用 rowList.get 方法获取行中的每个单元格,并将结果存储在 cellList 中;
ii. 将 cellList 、 rowIndex 和 reJsonArr 作为参数传递给回调函数 callback 的 handler 方法进行处理; - 使用 try-catch 语句捕获可能发生的 IOException 异常,并记录错误信息;
- 使用 finally 语句移除 THREAD_LOCAL 中的数据;
- 返回解析后的 JSONArray 对象 reJsonArr ;
这里要加上一个 callback.handler 回调函数主要的目的是为了将“单元格操作”跟 pdf 解析两部分代码进行解耦,那么这个回调接口的接口定义如下:
@FunctionalInterface
public interface PdfCellCustomProcess {/*** @description: 自定义单元格回调处理* @return {*}*/void handler(List<RectangularTextContainer> cellList, int rowIndex, JSONArray reJsonArr);
}
其中 cellList 传入的是这一行的所有单元格的集合,rowIndex 传入的是当前行码,reJsonArr 是返回值。具体的实现代码如下:
public class PdfUtil {.../*** @description: 解析 pdf 中简单的表格并返回 json 数组* @param {*} String PDF文件路径* @param {*} int 自定义起始行* @return {*}*/public static JSONArray parsePdfSimpleTable(String pdfPath, int customStart) {return parsePdfTable(pdfPath, customStart, (cellList, rowIndex, reArr) -> {JSONObject jsonObj = new JSONObject();// 遍历单元格获取每个单元格内字段内容List<String> headList = ObjectUtil.isNullObj(THREAD_LOCAL.get()) ? new ArrayList<>(): THREAD_LOCAL.get();for (int colIndex = 0; colIndex < cellList.size(); colIndex++) {String text = cellList.get(colIndex).getText().replace("\r", " ");if (rowIndex == customStart) {headList.add(text);} else {jsonObj.put(headList.get(colIndex), text);}}if (rowIndex == customStart) {THREAD_LOCAL.set(headList);}if (!jsonObj.isEmpty()) {reArr.add(jsonObj);}});}...}
代码的主要部分是一个 Lambda 表达式,它作为参数传递给 parsePdfTable 方法。Lambda 表达式做了PdfCellCustomProcess 接口的实现。Lambda 表达式的代码块首先创建一个 JSONObject 对象,然后遍历单元格列表,获取每个单元格的文本内容。
如果当前行索引等于自定义起始行索引,将文本内容添加到 headList 列表中;否则,将文本内容作为键值对添加到jsonObj 对象中。最后,如果 jsonObj 对象不为空,则将其添加到 reArr 数组中。 代码还包含了一些其他操作。如果当前行索引等于自定义起始行索引,将 headList 列表设置为 THREAD_LOCAL 线程局部变量。最后,返回 reArr数组作为方法的结果。
最后只需要补上 main 方法调用即可获取到解析后的 JsonArray 集合。但是直接输出 JsonArray 数据并不直观,于是我又写了一个解析 JsonArray 数据的方法,并将里面的数据转换为 Markdown 格式,如下图:
private static String outputMdFormatForVerify(JSONArray jsonArr) {StringBuilder mdStrBld = new StringBuilder();StringBuilder headerStrBld = new StringBuilder("|");StringBuilder segmentStrBld = new StringBuilder("|");for (int row = 0; row < jsonArr.size(); row++) {StringBuilder bodyStrBld = new StringBuilder("|");JSONObject rowObj = (JSONObject) jsonArr.get(row);if (row == 0) {rowObj.forEach((k, v) -> {headerStrBld.append(" ").append(k).append(" |");segmentStrBld.append(" ").append("---").append(" |");});headerStrBld.append("\n");segmentStrBld.append("\n");mdStrBld.append(headerStrBld).append(segmentStrBld);}rowObj.forEach((k, v) -> bodyStrBld.append("").append(v).append("|"));bodyStrBld.append("\n");mdStrBld.append(bodyStrBld);}return mdStrBld.toString();
}
这个应该比较好理解吧,这里就不再详述了。
以上的代码对于一般的 PDF 表格解析是基本没有问题的,但是对于带有合并单元格的解析就不能满足了。合并单元格需要考虑横向合并、纵向合并和混合合并三种合并模式,不是说 tabula-java 的 sdk 不能做只是比较麻烦,在 tabula-java 方案中我们可以获取到单元格的高和宽,那么先做一次全遍历获取二维数组对于单元格定位后,根据高和宽进行虚拟表格的建设,最后根据二维数组对数据进行回填即可。这也是用回调将单元格操作分离的原因之一,为了后面做合并单元格解析做准备的。
但其实上面说这么多,合并单元格解析的代码我还没写呢(以上都是我吹的),等完成后再给大家分享。
相关文章:

【Java】采用 Tabula 技术对 PDF 文件内表格进行数据提取
某天项目组来了个需求说需要提取 PDF 文件中数据作为数据沉淀使用,这是因为第三方系统不提供数据接口所以只能够出此下策。 就据我所知,PDF 文件内数据提取目前有 3 种解决方案: 第一种,资金足够的话可以直接通过人工智能对 PDF…...
完全保密的以太坊交易:Aztec网络的隐私架构
1. 引言 Aztec为隐私优先的以太坊zkRollup:即其为具有完全隐私保护的L2。 为了理解私有交易的范式变化性质,以及为什么将隐私直接构建到网络架构中很重要,必须首先讨论为什么以太坊不是私有的。 2. 以太坊:公有链 以太坊为具有…...

初识Java 9-1 内部类
目录 创建内部类 到外部类的链接 使用.this和.new 内部类和向上转型 在方法和作用域中的内部类 匿名内部类 嵌套类 接口中的类 从多嵌套的内部类中访问外部人员 本笔记参考自: 《On Java 中文版》 定义在另一个类中的类称为内部类。利用内部类,…...
)
合宙Air724UG LuatOS-Air LVGL API控件-屏幕横屏竖屏切换(Rotation)
屏幕横屏竖屏切换(Rotation) lvgl.disp_set_rotation(nil, lvgl.DISP_ROT_angle) 屏幕横屏竖屏切换显示,core版本号要>3202参数 参数类型释义取值nil无意义nilangle显示角度0,90,270,360 返回值nil 例子 lvgl.init()- -初始化 lvgl.disp_set_rotation(nil,…...

在Unity中,Instantiate函数用于在场景中创建一个新的游戏对象实例
在Unity中,Instantiate函数用于在场景中创建一个新的游戏对象实例。它的语法如下所示: public static Object Instantiate(Object original, Vector3 position, Quaternion rotation); original:要实例化的原始游戏对象。position࿱…...

解决 tesserocr报错 Failed to init API, possibly an invalid tessdata path : ./
问题描述 我们在初次使用tesserocr库的时候,可能会报以下错误: RuntimeError: Failed to init API, possibly an invalid tessdata path: ./ 这是因为我们在使用 conda 创建的环境中找不到"tessdata"这个文件夹。 解决办法 这时候把Tessera…...

使用Python CV2融合人脸到新图片--优化版
优化说明 上一版本人脸跟奥特曼图片合并后边界感很严重,于是查找资料发现CV2还有一个泊松函数很适合融合图像。具体代码如下: import numpy as np import cv2usrFilePath "newpic22.jpg" atmFilePath "atm2.jpg" src cv2.imrea…...

Python分享之对象的属性
Python一切皆对象(object),每个对象都可能有多个属性(attribute)。Python的属性有一套统一的管理方案。 属性的__dict__系统 对象的属性可能来自于其类定义,叫做类属性(class attribute)。类属性可能来自类定义自身,也可能根据类定义继承来的…...

编程参考 - std::exchange和std::swap的区别
这两个功能是C standard library中的Standard template library中的一部分。容易混淆,我们来看下它们的区别。 exchange: 这个函数是一个返回原先值的set函数。 std::exchange is a setter returning the old value. int z std::exchange(x, y); Af…...

Sentinel整合RestTemplate
resttemplate开启sentinel保护配置resttemplate.sentinel.enabledtrue配置sentinel-dashboard地址spring.cloud.sentinel.transport.dashboardlocalhost:8858\ spring.cloud.sentinel.transport.dashboard.port8739 实例化RestTemplate并加入SentinelRestTemplate注解Configura…...
)
微前端学习(下)
一、课程目标 qiankun 整体运行流程微前端实现方案二、课程大纲 qiankun 整体流程微前端方案实现DIY微前端核心能力1、微前端方案实现 基于 iframe 完全隔离的方案、使用纯的Web Components构建应用EMP基于webpack module federationqiankun、icestark 自己实现JS以及样式隔离2…...

Android Splash实现
1、创建Activity package com.wsy.knowledge.ui.splashimport android.animation.Animator import android.animation.AnimatorListenerAdapter import android.annotation.SuppressLint import android.os.Build import android.os.Looper import android.util.Log import an…...
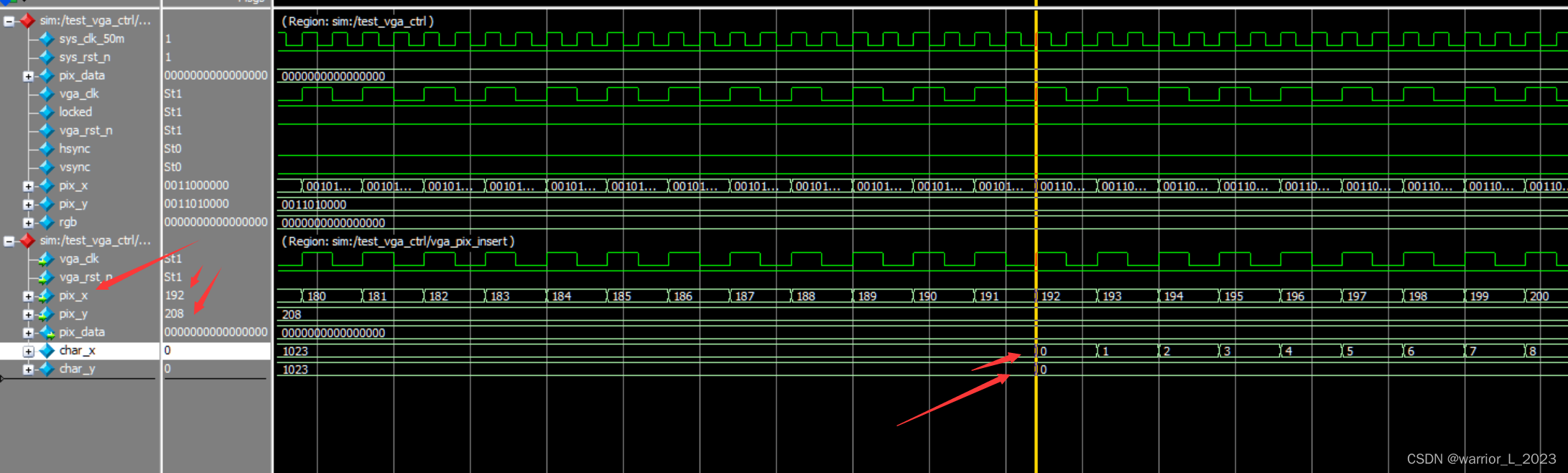
FPGA projet : VGA
在vga屏幕上显示 : 野火科技 相比于上个工程,只需要修改 vga_pix 模块即可。 注意存储器类型变量的定义:reg 【宽度】<名称>【深度】 赋值 always (poseedge vga_clk)begin 为每一行赋值,不可位赋…...
JDK8 升级至JDK19
优质博文IT-BLOG-CN 目前部分项目使用JDK8,部分项目使用JDK19因此,环境变量中还是保持JDK8,只需要下载JDK19免安装版本,通过配置IDEA就可以完成本地开发。 一、IDEA 环境设置 【1】通过快捷键CTRL SHIFT ALT S或者File->P…...

Python3.10 IDLE更换主题
前言 自定义主题网上有很多,3.10IDLE的UI有一些新的东西,直接扣过来会有些地方覆盖不到,需要自己测试着添几行配置,以下做个记录。 配置文件路径 Python安装目录下的Lib\idlelib\config-highlight.def。如果是默认安装…...
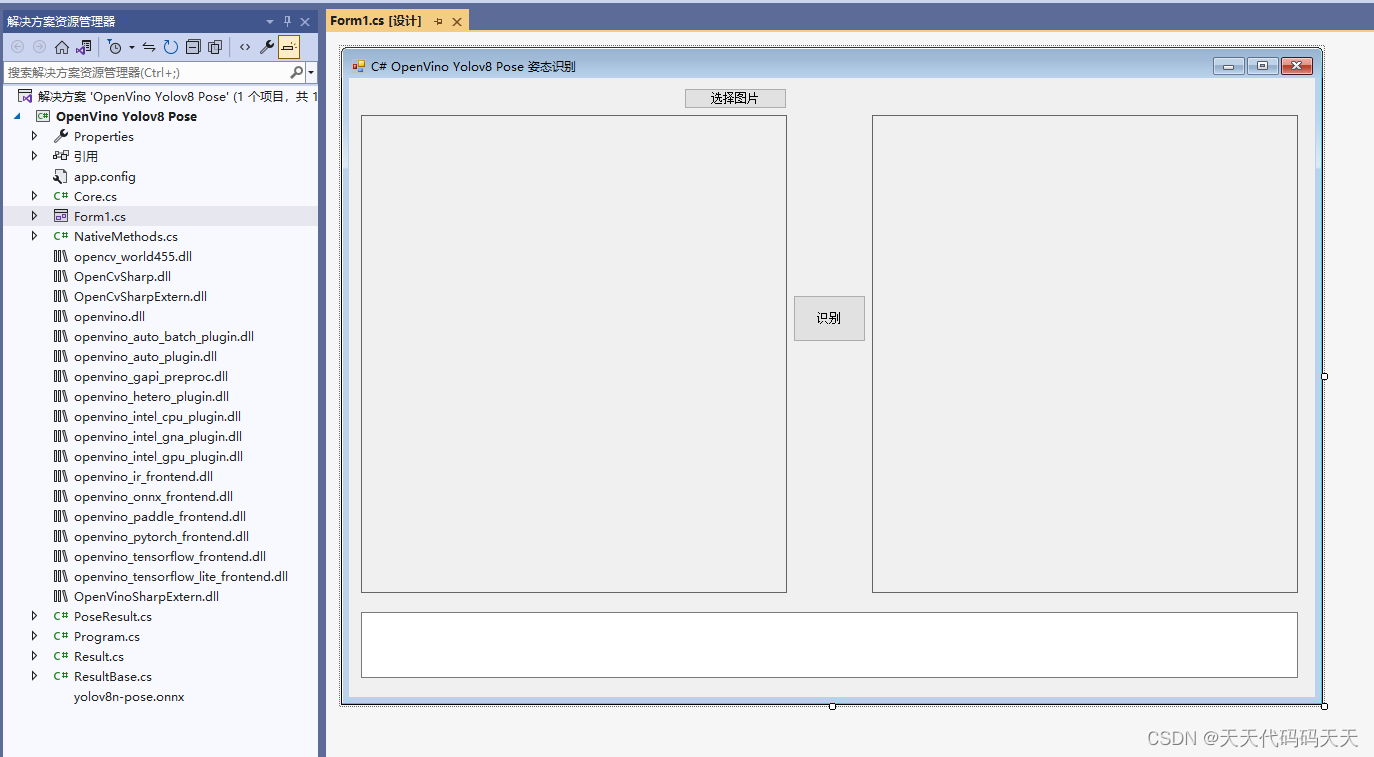
C# OpenVino Yolov8 Pose 姿态识别
效果 项目 代码 using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.Linq; using System.Text; using System.Windows.Forms; using OpenCvSharp;namespace OpenVino_Yolov8_Demo {public…...
北邮22级信通院数电:Verilog-FPGA(1)实验一“跑通第一个例程” 过程中遇到的常见问题与解决方案汇总(持续更新中)
北邮22信通一枚~ 跟随课程进度更新北邮信通院数字系统设计的笔记、代码和文章 持续关注作者 迎接数电实验学习~ 获取更多文章,请访问专栏: 北邮22级信通院数电实验_青山如墨雨如画的博客-CSDN博客 目录 问题一:Verilog代码没有跑通 报…...
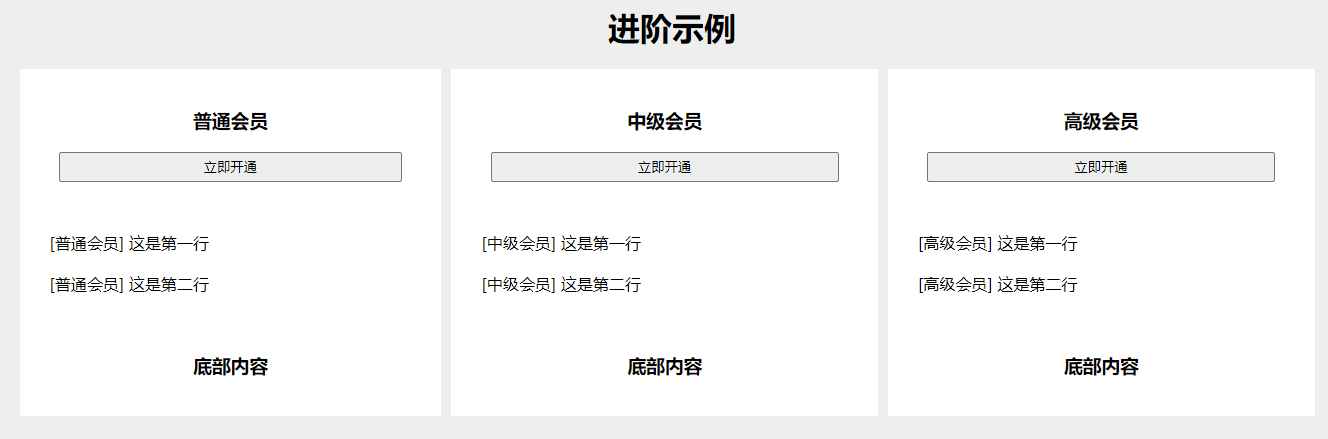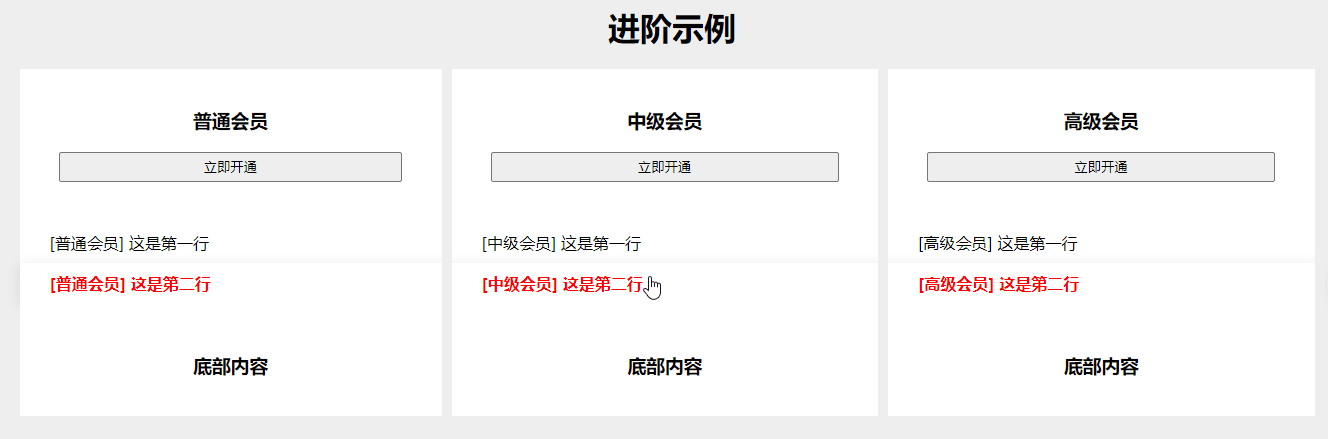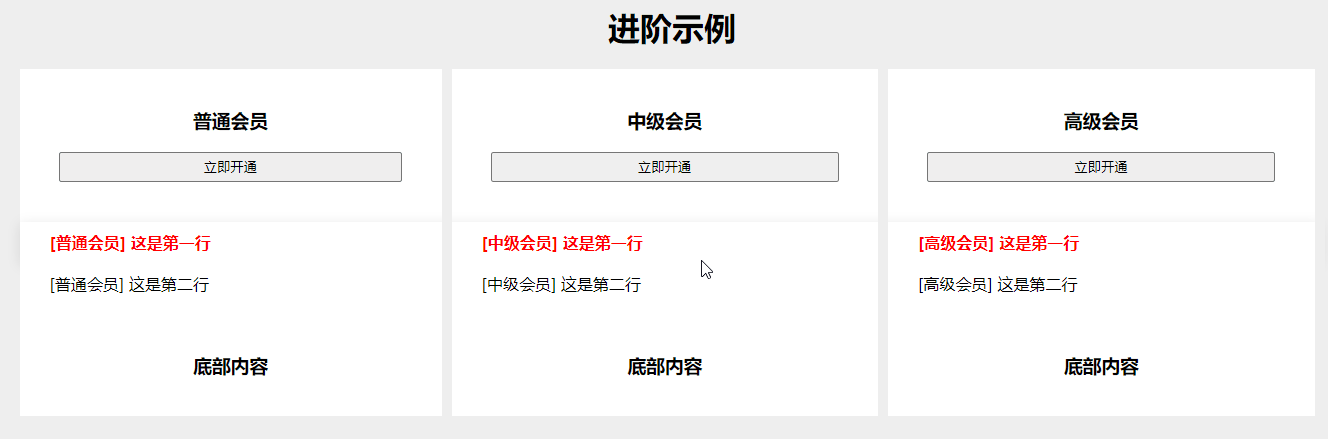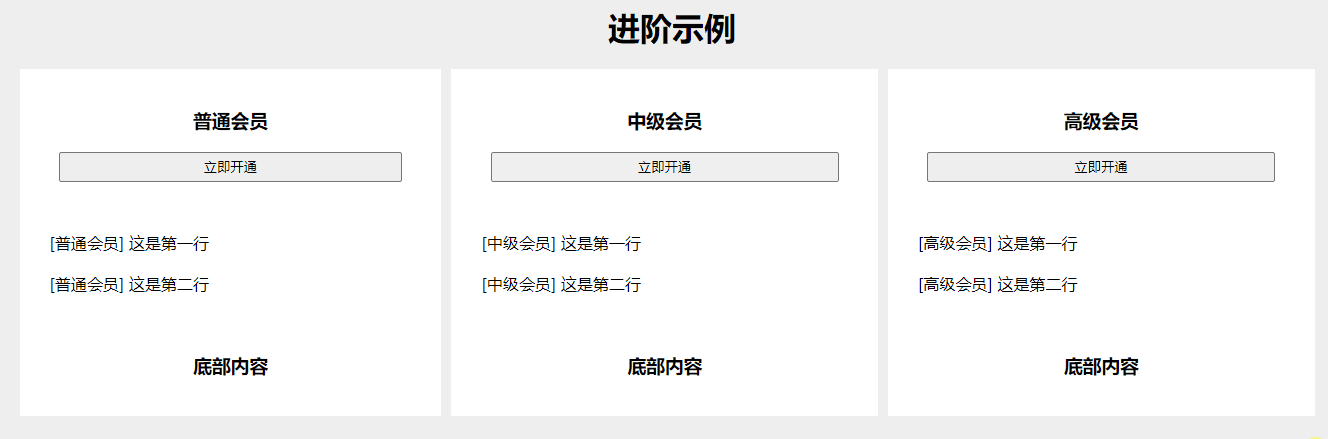
CSS - 鼠标移入整行高亮显示,适用于会员套餐各参数对比页面(display: table,div 转表格形式)
效果图 可根据基础示例和进阶示例,复制进行改造样式。 如下图所示,本文提供 2 个示例。 基础示例 找个 HTML 页面,一键复制运行。 <body><h1 style"text-align: center;">基础示例</h1><section class"…...

无涯教程-JavaScript - ATAN2函数
描述 The ATAN2 function returns the arctangent, or inverse tangent, of the specified x- and ycoordinates, in radians, between -π/2 and π/2. 语法 ATAN2 (x_num, y_num)争论 Argument描述Required/OptionalX_numThe x-coordinate of the point.RequiredY_numThe…...

Tomcat 下部署 jFinal
1、检查web.xml 配置,在 tomcat 下部署需要检查 web.xml 是否存在,并且要确保配置正确,配置格式如下。 <?xml version"1.0" encoding"UTF-8"?> <web-app xmlns:xsi"http://www.w3.org/2001/XMLSchema-i…...

从RIPv2到RIPng:IPv6时代路由协议的演进与实战部署
1. 从RIPv2到RIPng:为什么IPv6需要新的路由协议? 第一次在实验室配置RIPv2时,我盯着那些IPv4地址看了整整三天。直到某天客户突然要求支持IPv6,才发现这个诞生于1988年的老协议已经跟不上时代——就像用传呼机收发4K视频ÿ…...

终极指南:如何一键下载国家智慧教育平台电子课本PDF
终极指南:如何一键下载国家智慧教育平台电子课本PDF 【免费下载链接】tchMaterial-parser 国家中小学智慧教育平台 电子课本下载工具,帮助您从智慧教育平台中获取电子课本的 PDF 文件网址并进行下载,让您更方便地获取课本内容。 项目地址: …...

如何突破窗口限制:3分钟掌握WindowResizer强制调整技巧
如何突破窗口限制:3分钟掌握WindowResizer强制调整技巧 【免费下载链接】WindowResizer 一个可以强制调整应用程序窗口大小的工具 项目地址: https://gitcode.com/gh_mirrors/wi/WindowResizer 还在为那些无法拖拽大小的应用程序窗口而烦恼吗?Win…...

对比体验Taotoken平台不同大模型在创意生成上的差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比体验Taotoken平台不同大模型在创意生成上的差异 对于内容创作者而言,大模型是激发灵感、提升效率的得力工具。然而…...

DavyBot开源框架:构建智能对话机器人的模块化实践指南
1. 项目概述:一个开箱即用的智能对话机器人框架最近在折腾聊天机器人项目,发现了一个挺有意思的开源项目,叫geluzhiwei1/davybot。乍一看这个名字,可能觉得有点陌生,但如果你在GitHub上搜索过聊天机器人、智能客服或者…...

Unity3D游戏马赛克清除终极指南:7种高效技术深度解析
Unity3D游戏马赛克清除终极指南:7种高效技术深度解析 【免费下载链接】UniversalUnityDemosaics A collection of universal demosaic BepInEx plugins for games made in Unity3D engine 项目地址: https://gitcode.com/gh_mirrors/un/UniversalUnityDemosaics …...

从FPGA工程师的视角看AMBA总线:手把手教你用Verilog实现一个简易APB外设
从FPGA工程师的视角看AMBA总线:手把手教你用Verilog实现一个简易APB外设 在FPGA和数字IC设计领域,AMBA总线协议就像城市中的交通网络,负责协调各个功能模块之间的数据流动。而APB(Advanced Peripheral Bus)作为AMBA家族…...

面试官追问LDA与PCA区别?用这张对比图+3个核心公式轻松讲明白
LDA与PCA本质区别:3个核心公式实战对比解析 当面试官要求你解释LDA和PCA的区别时,他们真正想考察的是什么?不是简单的概念复述,而是对两种降维技术底层逻辑的深刻理解。本文将用几何直觉、数学本质和代码实例,带你穿透…...

文心一言深度解析:国产多模态大模型的破局之路
文心一言深度解析:国产多模态大模型的破局之路 引言 在ChatGPT引爆全球AI热潮的背景下,国产大模型如何突围?百度推出的文心一言(ERNIE Bot)作为中国AI产业的一面旗帜,凭借其在多模态理解与生成、中文场景深…...

【2026实测】论文AI率从81%降至个位数?8款降AIGC工具深度横测
内容ai率检测数值太高,不得不熬夜改了一遍又一遍,润色到想吐,结果检测报告上数字还是不尽人意,截止日期越逼越近,真的是没办法了。 我花了整整三天,把2026全网热门的几十款降AI工具通通测了个遍࿰…...