【kafka】kafka重要的集群参数配置
如何规划Kafka
对于实际应用的生产环境中,需要尽量先规划设计好集群,避免后期业务上线后费力调整。在考量部署方案时需要通盘考虑,不能仅从单个维度上进行评估,下面是几个重要的维度的考量和建议:
这里重点说说操作系统的因素。Linux系统比其他系统(特别是Windows系统)更加适合部署Kafka,主要体现在三个方面:
- I/O模型的使用
- 数据网络传输效率
- 社区支持度
一句话总结:在Linux部署Kafka能够享受到零拷贝技术带来的快速数据传输特性。
一些重要的集群参数配置
Broker端参数
(1)与存储信息相关的参数
broker.id(node.id): 用于服务的broker id。如果没设置,将生存一个唯一broker id。为了避免ZooKeeper生成的id和用户配置的broker id相冲突,生成的id将在reserved.broker.max.id的值基础上加1。
log.dir :保存日志数据的目录(对log.dirs属性的补充)
log.dirs :线上环境一定要配置多个路径,有条件最好挂载到不同的物理磁盘,可以提高读写性能和实现故障转移。保存日志数据的目录,如果未设置将使用log.dir的配置。
(2)如果版本是2.8之前的版本,有与ZooKeeper相关的参数
zookeeper.connect是与zookeeper相关的最重要的参数,没有之一。格式类似如下:
zookeeper.connect=192.168.2.140:2181,192.168.2.141:2181,192.168.2.142:2181
zookeeper.connect=zk1:2181,zk2:2181,zk3:2181
(3)与Broker连接相关的参数
listeners:监听器,告诉外部连接通过什么协议访问指定主机名和端口的Kafka服务。这里的协议名称可能是标准的名字,比如 PLAINTEXT 表示明文传输、SSL 表示使用 SSL 或 TLS 加密传输等。
PLAINTEXT://0.0.0.0:9092
advertised.listeners:这组监听器是Broker用于对外发布的。如果与listeners配置不同。在IaaS环境,这可能需要与broker绑定不通的接口。如果没有设置,将使用listeners的配置。与listeners不同的是,配置0.0.0.0元地址是无效的。
advertised.listeners=PLAINTEXT://192.168.2.140:9092
(4)关于Topic管理的参数
auto.create.topics.enable:是否允许自动创建topic,建议线上环境将其设置为false,即不允许自动创建Topic。
auto.leader.rebalance.enable:是否允许Kafka定期对一些Topic分区进行Leader重新选举,建议线上环境设置为false,因为换一次Leader成本很高。
(5)关于数据留存的参数
log.retention.{hours|minutes|ms}:这是三个配置,都是控制一条消息数据被保存多长时间。从优先级上来说 ms 设置最高、minutes 次之、hours 最低。
虽然 ms 设置有最高的优先级,但是通常情况下我们还是设置 hours 级别的多一些,比如log.retention.hours=168表示默认保存 7 天的数据,自动删除 7 天前的数据。
log.retention.bytes:这是指定 Broker 为消息保存的总磁盘容量大小,也可以理解为日志删除的大小阈值。
这个值默认是 -1,表明你想在这台 Broker 上保存多少数据都可以,至少在容量方面 Broker 绝对为你开绿灯,不会做任何阻拦。这个参数真正发挥作用的场景其实是在云上构建多租户的 Kafka 集群:设想你要做一个云上的 Kafka 服务,每个租户只能使用 100GB 的磁盘空间,为了避免有个“恶意”租户使用过多的磁盘空间,设置这个参数就显得至关重要了。
message.max.bytes:控制 Broker 能够接收的最大消息大小。
这个值默认的 1000012 太少了,还不到 1MB(1048576)。实际场景中突破 1MB 的消息都是屡见不鲜的,因此在线上环境中设置一个比较大的值还是比较保险的做法。毕竟它只是一个标尺而已,仅仅衡量 Broker 能够处理的最大消息大小,即使设置大一点也不会耗费什么磁盘空间的。
Topic级别参数
retention.ms:如果使用“delete”保留策略,此配置控制保留日志的最长时间,然后将旧日志段丢弃以释放空间。这代表了用户读取数据的速度的SLA。默认是 7 天,即该 Topic 只保存最近 7 天的消息。一旦设置了这个值,它会覆盖掉 Broker 端的全局参数值。
retention.bytes:如果使用“delete”保留策略,此配置控制分区(由日志段组成)在放弃旧日志段以释放空间之前的最大大小。默认情况下,没有大小限制,只有时间限制。由于此限制是在分区级别强制执行的,因此,将其乘以分区数,计算出topic保留值,以字节为单位。。和全局参数作用相似,这个值通常在多租户的 Kafka 集群中会有用武之地。当前默认值是 -1,表示可以无限使用磁盘空间。
对于Topic级别的参数,建议统一使用kafka-configs来修改Topic级别的参数。例如,下面使用了kafka-configs命令将发送消息的最大值修改为10MB。
[root@k8s-m1 kafka_2.13-2.8.0]# bin/kafka-configs.sh --zookeeper localhost:2181 --entity-type topics --entity-name transaction --alter --add-config max.message.bytes=10485760
#可以执行以下命令验证结果
[root@k8s-m1 kafka_2.13-2.8.0]# bin/kafka-configs.sh --zookeeper localhost:2181 --entity-type topics --entity-name transaction --describe
Copy
#移除:
[root@k8s-m1 kafka_2.13-2.8.0]# bin/kafka-configs.sh --zookeeper localhost:2181 --entity-type topics --entity-name my-topic --alter --delete-config max.message.bytes
更多参数可以参考官方文档https://kafka.apachecn.org/documentation.html#configuration
生产者和消费者
bootstrap.servers:host/port,用于和kafka集群建立初始化连接。因为这些服务器地址仅用于初始化连接,并通过现有配置的来发现全部的kafka集群成员(集群随时会变化),所以此列表不需要包含完整的集群地址(但尽量多配置几个,以防止配置的服务器宕机)。
JVM级别参数
KAFKA_HEAP_OPTS:指定堆大小。
KAFKA_JVM_PERFORMANCE_OPTS:指定 GC 参数。
例如,我们可以这样启动 Kafka Broker,即在启动 Kafka Broker 之前,先设置上这两个环境变量:
[root@k8s-m1 kafka_2.13-2.8.0]# export KAFKA_HEAP_OPTS=--Xms6g --Xmx6g
[root@k8s-m1 kafka_2.13-2.8.0]# export KAFKA_JVM_PERFORMANCE_OPTS= -server -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -Djava.awt.headless=true
[root@k8s-m1 kafka_2.13-2.8.0]# bin/kafka-server-start.sh -daemonconfig/server.properties
操作系统级别参数
通常情况下,Kafka 并不需要设置太多的 关于操作系统级别的 参数,下面列出几个经常需要关注的因素:
文件描述符限制
通常情况下将它设置成一个超大的值是合理的做法,比如ulimit -n 1000000。
文件系统类型
根据官网的测试报告,XFS 的性能要强于 ext4,所以生产环境有条件的话最好还是使用 XFS。
Swappiness
建议将 swappniess 配置成一个接近 0 但不为 0 的值,比如 1。
提交时间
这个定期就是由提交时间来确定的,默认是 5 秒。一般情况下我们会认为这个时间太频繁了,可以适当地增加提交间隔时间来降低物理磁盘的写操作。
更多关于kafka的知识分享,请前往博客主页。编写过程中,难免出现差错,敬请指出
相关文章:

【kafka】kafka重要的集群参数配置
如何规划Kafka 对于实际应用的生产环境中,需要尽量先规划设计好集群,避免后期业务上线后费力调整。在考量部署方案时需要通盘考虑,不能仅从单个维度上进行评估,下面是几个重要的维度的考量和建议: 这里重点说说操作系…...

cs224w_colab3_2023 And cs224w_colab4_2023学习笔记
class GNNStack(torch.nn.Module):def __init__(self, input_dim, hidden_dim, output_dim, args, embFalse):super(GNNStack, self).__init__() #这里的继承表示参见 https://blog.csdn.net/wanzew/article/details/106993425 # 继承时运行继承类别的函数 总之 __mro__的目的…...
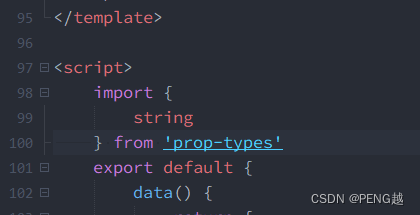
Cannot find module ‘prop-types‘
把这个import删了。...

LeetCode-63-不同路径Ⅱ-动态规划
题目描述: 一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。 机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish”)。 现在考虑网格中有障碍物。那…...
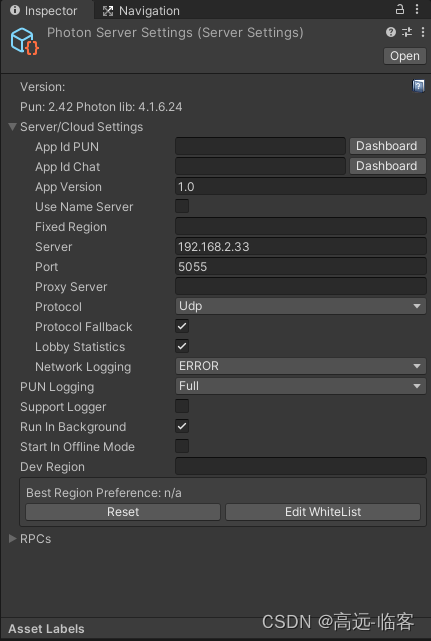
unity 使用Photon进行网络同步
Pun使用教程 第一步:请确保使用的 Unity 版本等于或高于 2017.4(不建议使用测试版)创建一个新项目。 第二步:打开资源商店并找到 PUN 2 资源并下载/安装它。 导入所有资源后,让 Unity 重新编译。 第三步…...

大数据课程M1——ELK的概述
文章作者邮箱:yugongshiyesina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 了解ELK的定义; ⚪ 掌握ELK的使用; 一、什么是ELK 1. 简介 ELK 是elastic公司提供的一套完整的日志收集以及展示的解决方案,是三个…...

C# byte[] 如何转换成byte*
目标:将byte[]转成byte*以方便使用memcpy [DllImport("kernel32.dll", EntryPoint "RtlCopyMemory", CharSet CharSet.Ansi)] public extern static long CopyMemory(IntPtr dest, IntPtr source, int size); private void butTemp_Click(object…...

MySQL与Oracle的分页
MySQL与Oracle的分页 当我们通过SQL去查询一个结果集的时候,并不需要查看所有行,可能只是查看前几行,或者中间的几行。则需要像MySQL的limit或Oracle的ROWNUM与FETCH NEXT来实现。 MySQL 语法 SELECT * FROM table_name LIMIT [offset,] ro…...
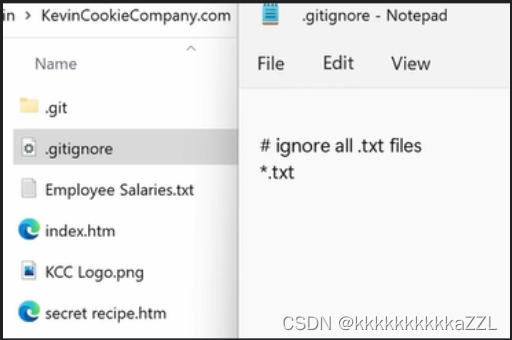
git基本手册
Git and GitHub for Beginners Tutorial - YouTube Kevin Stratvert git config --global user.name “xxx” git config --global user.email xxxxx.com 设置默认分支 git config --global init.default branch main git config -h查看帮助 详细帮助 git help config 清除 cl…...
每日一题(两数相加)
每日一题(两数相加) 2. 两数相加 - 力扣(LeetCode) 思路 思路: 由于链表从头开始向后存储的是低权值位的数据,所以只需要两个指针p1和p2,分别从链表的头节点开始遍历。同时创建一个新的指针new…...

恒运资本:沪指震荡涨0.28%,医药板块强势拉升,金融等板块上扬
15日早盘,沪指盘中震荡上扬,科创50指数表现强势;北向资金小幅净流入。 到午间收盘,沪指涨0.28%报3135.31点,深成指、创业板指涨均0.11%,科创50指数涨1.04%;两市合计成交4357亿元,北…...

【计算机网络】Tcp详解
文章目录 前言Tcp协议段格式TCP的可靠性面向字节流应答机制超时重传流量控制滑动窗口(重要)拥塞控制延迟应答捎带应答标志位具体标志位三次握手四次挥手粘包问题TCP异常情况listen的第二个参数 前言 前面我们学习了传输层协议Udp,今天我们一…...

最简单的laravel不使用任何扩展导出csv
php导出csv是非常常用的操作,网上也有灰常多的扩展。如果只是单纯的导出csv数据,完全没有必要去用扩展。现在做项目,都是代码能少就少,扩展能不用就不用。好了,不废话了,开干! 直接搞一个方法&…...
Android studio 断点调试、日志断点
目录 参考文章参考文章1、运行调试2、调试操作3、断点类型行断点的使用场景属性断点的使用场景异常断点的使用场景方法断点的使用场景条件断点日志断点 4、断点管理区 参考文章 参考文章 1、运行调试 开启 Debug 调试模式有两种方式: Debug Run:直接…...
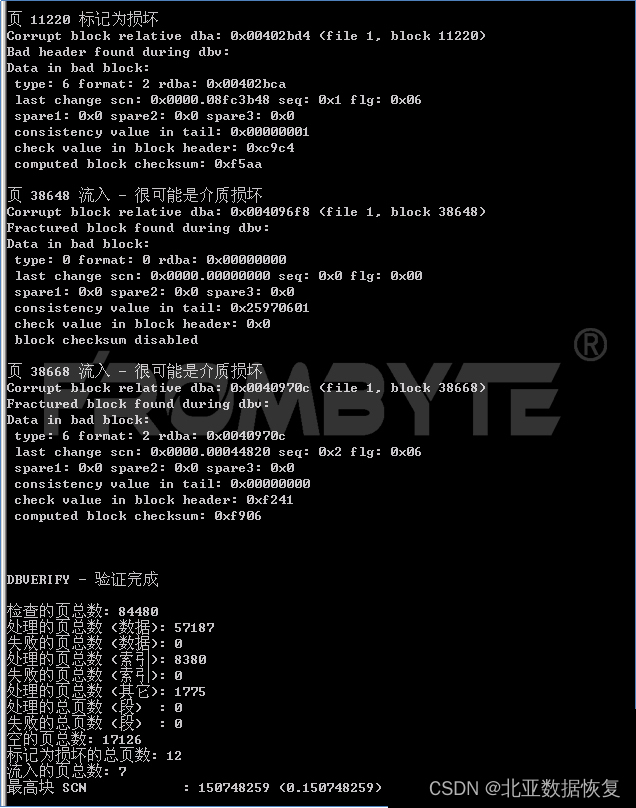
服务器数据恢复-热备盘同步过程中硬盘离线的RAID5数据恢复案例
服务器数据恢复环境: 华为OceanStor某型号存储,11块硬盘组建了一组RAID5阵列,另外1块硬盘作为热备盘使用。基于RAID5阵列的LUN分配给linux系统使用,存放Oracle数据库。 服务器故障: RAID5阵列1块硬盘由于未知原因离线…...

Python 使用input获取用户输入
视频版教程 Python3零基础7天入门实战视频教程 input()函数用于向用户生成一条提示,然后获取用户输入的内容。由于input()函数总会将用户输入的内容放入字符串中,因此用户可以输入任何内容,input()函数总是返回一个字符串。我们可以通过int(…...
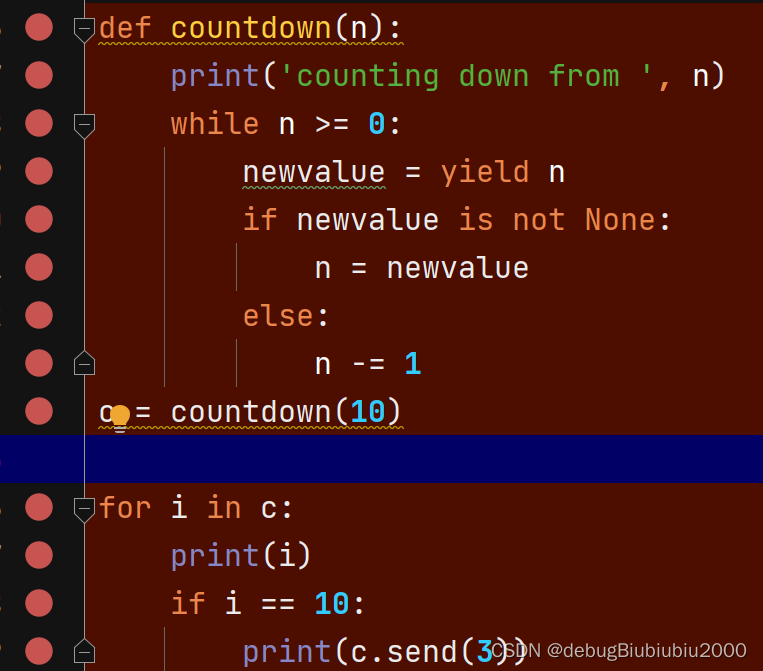
Python 可迭代对象、迭代器、生成器
可迭代对象 定义 在Python的任意对象中,只要它定义了可以返回一个迭代器的 __iter__ 魔法方法,或者定义了可以支持下标索引的 __getitem__ 方法,那么它就是一个可迭代对象,通俗的说就是可以通过 for 循环遍历了。Python 原生的列…...

HTML的有序列表、无序列表、自定义列表
目录 背景: 过程: 有序列表: 简介: 代码展示: 效果展示: 无序列表: 简介: 代码展示: 效果展示: 自定义列表: 简介: 代码展示: 效果展示: 总结: 背景: 1.有序列表(Ordered List): 有序列表是最早的…...

银河麒麟安装Docker-国产化-九五小庞
银河麒麟高级服务器操作系统 V10 是针对企业级关键业务,适应虚拟化、 云计算、大数据、工业互联网时代对主机系统可靠性、安全性、性能、扩展性和 实时性的需求,依据 CMMI 5 级标准研制的提供内生安全、云原生支持、国产 平台深入优化、高性能、易管理的…...
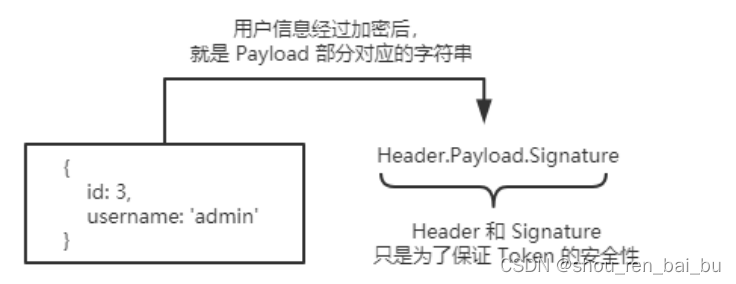
数据库与身份认证
1. 数据库的基本概念 1.1 什么是数据库 数据库(database)是用来组织、存储和管理数据的仓库。 当今世界是一个充满着数据的互联网世界,充斥着大量的数据。数据的来源有很多,比如出行记录、消费记录、浏览的网页、发送的消息…...

使用Nodejs和Taotoken为前端应用构建AI聊天后端
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Node.js和Taotoken为前端应用构建AI聊天后端 基础教程类,指导前端或全栈开发者使用Node.js环境接入Taotoken&#…...

华为2288H V5服务器折腾记:LSI SAS3008阵列卡的IT与IR模式到底该怎么选?
华为2288H V5服务器实战:LSI SAS3008阵列卡IT与IR模式深度解析 当你第一次接触华为2288H V5服务器时,那块小小的LSI SAS3008阵列卡可能会让你陷入选择困难——到底该用IT模式还是IR模式?这个问题看似简单,却直接影响着服务器的存储…...

技术团队的“1对1沟通”:别等员工提离职了才聊真心话
在软件测试领域,我们习惯于用脚本验证系统的稳定性,用压测工具探测性能的边界,却常常忽略了对团队中最重要的“系统”——人——进行定期的健康检查。许多技术管理者,尤其是从资深测试工程师晋升上来的团队负责人,往往…...

NodeMCU PyFlasher:让物联网开发变得简单的固件烧录神器
NodeMCU PyFlasher:让物联网开发变得简单的固件烧录神器 【免费下载链接】nodemcu-pyflasher Self-contained NodeMCU flasher with GUI based on esptool.py and wxPython. 项目地址: https://gitcode.com/gh_mirrors/no/nodemcu-pyflasher 还在为NodeMCU开…...

OpenClaw 消息路由与广播机制深度解析
OpenClaw 消息路由与广播机制深度解析 作者: Social Agent (小社) 日期: 2026-03-18 研究模块: channels/channel-routing + broadcast-groups + group-messages 一、消息路由的核心设计 1.1 确定性路由,而非 AI 决策 OpenClaw 消息路由最重要的设计决策是:路由是确定性的…...

实测推荐!2026年毕业论文5000字范文免费下载AI写作工具排行,查重降AI率全攻略
本文由知学术AIPaperGPT内容团队实测撰写 2026-05-11实测推荐!2026年毕业论文5000字范文免费下载AI写作工具排行,查重降AI率全攻略又是一年毕业季,无数本科、硕士生正为毕业…...

peaqOS 给机器发了一份穆迪式评级,机器经济缺的最后一块零件被补上了
作者:PaperMoon团队 “It’s time for blockchain to live up to its full potential。” 这种句子在 2026 年的 Web3 推文里已经少见了,大部分项目方学会了克制。peaq 这次不克制,而且把"全新资产类别"这种 2017 年级别的措辞重新…...

从V100到A100:手把手教你理解Ampere架构的7个关键性能优化点
从V100到A100:手把手教你理解Ampere架构的7个关键性能优化点 如果你正在使用NVIDIA V100进行深度学习训练或高性能计算,那么升级到A100可能已经在你的考虑范围内。但这次升级究竟能带来多少实际性能提升?本文将带你深入Ampere架构的7个核心优…...

KeymouseGo完全指南:5分钟掌握桌面自动化终极工具
KeymouseGo完全指南:5分钟掌握桌面自动化终极工具 【免费下载链接】KeymouseGo 类似按键精灵的鼠标键盘录制和自动化操作 模拟点击和键入 | automate mouse clicks and keyboard input 项目地址: https://gitcode.com/gh_mirrors/ke/KeymouseGo 你是否厌倦了…...

终极指南:NoSQL数据库大全awesome-bigdata - 文档型数据库实战入门 [特殊字符]
终极指南:NoSQL数据库大全awesome-bigdata - 文档型数据库实战入门 🚀 【免费下载链接】awesome-bigdata A curated list of awesome big data frameworks, ressources and other awesomeness. 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-b…...